Самое краткое руководство по проектированию Баз Данных
Время на прочтение
4 мин
Количество просмотров 4.7K
Приключилось мне в рамках одного проекта импортировать существующую базу. База эта была создана в аксесе и собствен6но суть проекта заключалась в создании веб-приложения, предоставляющего схожую функциональность, но с учетом нынешних реалий (веб-интерфейс, разделение полномочий и т.п.). Если рассматривать в обсуждаемом ключе, разработка строилась так:
1. создаю свою систему, удовлетворяющую требованиям
2. импортирую данные из исходной базы
Эта заметка о пункте номер два.
Я впервые столкнулся с полностью ненормализованной базой. Т.е. в ней были нарушены практически все принципы построения реляционных БД. Но тем не менее эта база использовалась продолжительное время. Не стану вдаваться в подробности, отмечу лишь что вызвало первый шок — таблицы с именами «январь», «февраль» и т.д. для графика работы. Поверьте, дальше все было гораздо хуже. Я понимаю, что не мне судить человека, который это создал — система, использовалась не один год и в какой-то мере удовлетворяла потребности заказчика. Просто я не хочу больше сталкиваться с такими «базами». Надеюсь данная заметка поможет в этом.
Самое краткое руководство по проектированию Баз Данных.
В качестве примера будем проектировать базу по учету товаров. С древовидным каталогом и данными о производителях.
1. Объекты
Первое что надо сделать — выделить виды объектов предметной области. В нашем случае это «товар», «раздел каталога» и «производитель». Для каждого вида создается своя таблица. Каждая запись (строка) таблицы содержит данные об одном объекте. Порядок следования записей не определен. Если данные добавляются в алфавитном порядке — при запросе на получение записей этот порядок будет нарушен.
Необходимо избегать дублирования данных. Например недопустимо хранить в каждой записи таблицы «товар» полную информацию о производителе. Т.к. при изменении каких-то данных производителя, придется искать все упоминания о нем в таблице «товары». Назовем нашим таблицы item, node и company.
2. Первичный ключ
Что бы «обращаться» к конкретному объекту необходимо дать ему уникальный номер. Вообще говоря это может быть любое уникальное поле или группа полей (например, в случае учета сотрудников — номер паспорта или фамилия, имя, отчество), однако по многим причинам гораздо удобней сделать отдельное поле с уникальным значением. Это поле и есть первичный ключ. Обычно это поле называют «id» (идентификатор).
3. Связи, внешние ключи
Все объекты каким-то образом связаны друг с другом — производители производят товары, товары размещаются в каталоге и т.п. Отношения бывают трех видов:
один-ко-многим
один производитель может создавать много разных товаров. Реализуется просто — в таблице объектов, которых «много» создается поле с id объекта, который «один». В случае товаров и производителей нужно в таблицу item добавить поле company_id, которое будет содержать id производителя данного товара. Такое поле называют внешним ключем.
многие-ко-многим
любой товар может присутствовать сразу в нескольких разделах каталога. Такая связь хранится в отдельной таблице с полями id товара и id раздела. Таким образом каждая запись таблицы означает присутствие товара в разделе каталога.
один-к-одному
допустим наш товар это книги и диски. Их общая информация и тип товара хранятся в таблице item, а данные специфичные для книг и для дисков будем хранить в таблицах book и disk соответственно. Т.е. для каждой записи в таблице book есть ровно одна запись в item. По сути это один объект хранится в двух таблицах.
Реализуется так — первичный ключ таблицы book содержит id из таблицы item. Т.е. первичный ключ одновременно является внешним ключем.
дерево
по сути это тоже что и один-ко-многим. Один раздел каталога содержит много других. Реализация такая же — запись таблицы node содержит id родительского раздела (parent_id)
4. обеспечение целостности
Все связи и ключи должны быть описаны должным образом, что бы избежать противоречий. Тогда система управления базой не позволит удалить производителя, на которого ссылается товар или раздел каталога, содержащий подразделы. Так же возможны другие виды реакции. Главное, что база всегда будет находится в корректном состоянии, т.е. не будет внешних ключей ссылающихся на несуществующие записи.
То же самое на SQL
1. создаем таблицы
-- раздел каталога
create table node (
id numeric not null, -- первичный ключ
parent_id numeric not null, -- внешний ключ. ссылается на родительский раздел
name varchar(200)
);
-- компания-производитель
create table company (
id numeric not null, -- первичный ключ
name varchar(1000),
);
-- товар
create table item (
id numeric not null, -- первичный ключ
company_id numeric not null, -- внешний ключ. ссылается на компанию-производителя
type varchar(10) NOT NULL, -- 'book' или 'disc'
name varchar(1000), -- наименование
qty numeric, -- кол-во товара
price numeric -- цена за единицу
);
2-3-4. Создаем недостающие связи и указываем какие поля являются первичными и внешними ключами.
-- товар - книга
create table book (
id numeric not null, -- одновременно первичный и внешний ключ, ссылающийся на item
author varchar(1000)
);
-- товар - диск
create table disk (
id numeric not null, -- одновременно первичный и внешний ключ, ссылающийся на item
play_time numeric
);
create table node_item (
node_id numeric not null,
item_id numeric not null
);
-- для каждой таблицы указываем ее первичный ключ
alter table node add constraint "PK_NODE" primary key (id);
alter table item add constraint "PK_ITEM" primary key (id);
alter table company add constraint "PK_COMPANY" primary key (id);
alter table book add constraint "PK_BOOK" primary key (id);
alter table disk add constraint "PK_DISK" primary key (id);
-- у таблицы, реализующей отношение многие-ко-многим, первичный ключ составной.
alter table node_item add constraint "PK_NODE_ITEM" primary key (node_id, item_id);
-- указываем внешние ключи и на что они ссылаются
alter table node add constraint "FK_NODE_PARENT" foreign key (parent_id) references node(id);
alter table item add constraint "FK_ITEM_COMPANY" foreign key (company_id) references company(id);
alter table node_item add constraint "FK_NODEITEM_NODE" foreign key (node_id) references node(id);
alter table node_item add constraint "FK_NODEITEM_ITEM" foreign key (item_id) references item(id);
alter table book add constraint "FK_BOOK_ITEM" foreign key (id) references item(id);
alter table disk add constraint "FK_DISK_ITEM" foreign key (id) references item(id);
SQL – это язык структурированных запросов. СУРБД – система управления реляционными базами данных. Существуют следующие разновидности баз данных:
- Система управления файлами
- Иерархические
- Сетевые
- Реляционные
- Объектно-ориентированные
- Гибридные
1) Иерархические – первые базы данных. Иерархическая база данных основана на древовидной структуре хранения информации и напоминает файловую систему компьютера. С точки зрения организации хранения информации, иерархическая база данных состоит из упорядоченного набора деревьев одного типа – каждая
запись в базе данных реализована в виде отношений предок-потомок. Основной недостаток иерархической структуры базы данных –невозможность реализовать отношения многие ко многим. Иерархические базы данных наиболее пригодны для моделирования структур, являющихся иерархическими по своей природе. Иерархия подразумевает только одного родителя.
2) Сетевые базы данных – являются расширением иерархических баз данных. Иерархические базы данных из-за большого количества недостатков просуществовали недолго и были заменены на сетевые базы данных.Сетевые базы данных представляют собой организацию данных в виде железнодорожных путей, где каждая крупная станция имеет связи с несколькими другими станциями. В сетевых базах данных имеется связь многие ко многим. Недостатком сетевых баз данных является сложность разработки больших приложений.
3) Реляционные базы данных – произвели настоящий прорыв в развитии теории баз данных. Основная задача реляционной модели была упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении
которых расположены данные.Особенности реляционной базы данных:
- Данные хранятся в таблицах, состоящих из столбцов и строк
- На пересечении каждого столбца и строки находится только одно значение
- У каждого столбца есть свое имя, которое служит его названием, и все значения в одном столбце имеют один тип.
- Столбцы располагаются в определенном порядке, который задается при создании таблицы, в отличие от строк, которые располагаются в произвольном порядке.
- В таблице может не быть ни одной строчки, но должен быть хотя бы один столбец.
- Запросы к базе данных возвращают результат в виде таблиц, которые тоже могут выступать как объект запросов.
Первичные ключи
Строки в реляционной базе данных неупорядоченные. Для выбора в таблице конкретной строки создается один или несколько столбцов, значения которых во всех строках уникальны. Такой столбец называется первичным ключом.
Первичный ключ (primary key) – является уникальным значением в столбце. Никакие из двух записей таблицы не могут иметь одинаковых значений первичного ключа.
По способу задания первичных ключей различают логические (естественные) ключи и суррогатные (искусственные).
Логический ключ – представляет собой значение, определяющее запись естественным образом.
Суррогатный ключ – представляет собой дополнительное поле в базе данных, предназначенное для обеспечения записей первичным ключом.
Нормализация базы данных
Нормализацией схемы базы данных – называется процедура, производимая над базой данных с целью удаления в ней избыточности.
Централизованная архитектура
При централизованной архитектуре и приложение, СУБД и база данных размещаются на одном центральном мэйнфрейме – базовой универсальной вычислительной машине. Пользователи подключаются к нему посредством терминалов. Терминал представлял собой клавиатуру, монитор и сетевую карту, посредством которой происходит обмен данных терминала с мэйнфреймом. Роль приложения состоит в принятии вводимых данных с пользовательского терминала по сети и передаче их на обработку СУБД с последующей передачей полученного от СУБД ответа на монитор терминала.
Архитектура клиент-сервер
В клиент-серверной архитектуре персональные компьютеры объединены в локальную сеть, в этой же сети находится и сервер баз данных, на котором содержатся общие для всех клиентом базы данные и СУБД. Вычислительные возможности сервера полностью сосредоточены на обслуживании СУБД.
Трехуровневая архитектура интернета
Трехуровневая модель позволяет отделить клиентское программное обеспечение от серверной части, а на серверной стороне отделить веб-сервер от сервера базы данных.
Несколько серверов, работающих над одной и той же задачей, функционируют надежнее и обходятся дешевле, чем один сервер высокой производительности.
Кластерная модель
Кластеры часто называют дешевыми супер ЭВМ. Ряд маломощных машин объединяют в локальную сеть. Специальное программное обеспечение распределяет вычисления между отдельными хостами сети. Выход из строя одного из хостов никак не отражается на работе все сети, а сам кластер легко расширяется за счет ввода дополнительных машин.
Как работают базы данных.
По сути, база данных – это набор файлов, в которых хранится информация. СУБД – система управления базами данных, управляет данными, берет на себя все низкоуровневые операции по работе с файлами, благодаря чему программист при работе с базой данных может оперировать лишь логическими конструкциями при помощи
языка программирования, не прибегая к низкоуровневым операциям.
Язык структурированных запросов SQL позволяет производить следующие операции:
- Выборку данных – извлечение из базы данных содержащейся в ней информации.
- Организацию данных – определение структуры базы данных и установления отношений между ее элементами.
- Обработку данных – добавление, изменение, удаление.
- Управление доступом – ограничение возможностей ряда пользователей на доступ к некоторым категориям данных, защита данных от несанкционированного доступа.
- Обеспечение целостности данных – защита базы данных от разрушения.
- Управление состоянием СУБД.
Достоинства системы управления базами данных MySQL:
- Скорость выполнения запросов.
- СУБД MySQL разработана с использованием языков C/C++ и оттестирована более чем на 23 платформах.
- Открытый код доступен для просмотра и модернизации всем желающим.
- Высокое качество и устойчивость работы.
- Поддержка API для различных языков программирования
- Наличие встроенного сервера. СУБД MySQL может быть использован как с внешним сервером, поддерживающим соединение с локальной машиной и с удаленным хостом, так и в качестве встроенного сервера.
- Широкий выбор типов таблиц позволяет реализовать оптимальную для решаемой задачи производительность и функциональность.
- Локализация выполнена корректна.
- Совместимость с другими базами данных и полностью удовлетворяет стандарту SQL.
Индексы
Индексы – основной способ ускорения работы баз данных. Чтобы найти нужную запись, необходимо сканировать всю таблицу, на что уходит большое количество времени.
Идея индексов состоит в том, чтобы создать для столбца копию, которая постоянно будет поддерживаться в отсортированном состоянии. Это позволяет очень быстро осуществлять поиск по такому столбцу, так, как заранее известно, где необходимо искать значение.
Добавление или удаление записи требует дополнительного времени на сортировку столбца, кроме того, создание копии увеличивает объем памяти, необходимый для размещения таблицы на жестком диске.
Существует несколько видов индексов:
- Первичный ключ – главный индекс таблицы. В таблице может быть только один первичный ключ, и все значения такого индекса должны отличаться друг от друга, являться уникальными в пределах одного столбца.
- Обычный индекс – таких индексов может быть несколько.
- Уникальный индекс – уникальных индексов также может быть несколько, на значения индекса не должны повторяться.
- Полнотекстовый индекс – специальный вид индекса для столбцов типа TEXT, позволяющий производить полнотекстовый поиск.
Типы и структура таблиц
СУБД MySQL поддерживает несколько видов таблиц, каждая из которых имеет свои возможности и ограничения.
MyISAM
MyISAM – является родным типом таблиц для базы СУБД MySQL. База данных в MySQL организуется как каталог. Таблицы базы данных организуются как файлы данного каталога. Каждая MyISAM таблица хранится на диске в трех файлах, имена которых совпадают с названием таблицы, а расширение может принимать одно из следующих значений:
- Frm – содержит структуру таблицы, в файле данного типа хранится информация об именах и типах столбцов и индексов.
- Myd – файл, в котором содержатся данные таблицы.
- Myi – файл, котором содержатся индексы таблицы.
Особенности типа таблиц MyISAM:
- Данные хранятся в кросс-платформенном формате, это позволяет переносить базы данных с сервера непосредственным копированием файлов, минуя промежуточные форматы.
- Максимальное число индексов в таблице составляет 64. Каждый индекс может состоять максимум из 16 столбцов.
- Для каждого из текстовых столбцов может быть назначена своя кодировка.
- Допускается индексирования текстовых столбцов, в том числе и переменной длины.
- Поддерживается полнотекстовый поиск.
- Каждая таблица имеет специальный флаг, указывающий правильность закрытия таблиц. Если сервер останавливается аварийно, то при его повторном старте незакрытые флаги сигнализируют о возможных сбойных таблицах, сервер автоматически проверяет их и пытается восстановить.
MERGE
Тип таблиц MERGE позволяет сгруппировать несколько таблиц типа MyISAM в одну. Такой тип таблиц применяется для снятия ограничения на объем таблиц MyISAM. Таблицы MyISAM, которые подвергаются объединению в одну таблицу MERGE, должны иметь одинаковую структуру, то есть, одинаковые столбцы и индексы, а также порядок их следования.
При создании таблицы типа MERGE будут образованы файлы структуры таблицы с расширением frm и файлы с расширением mrg. Файл mrgсодержит список индексных файлов, работа с которыми должна осуществляться как с единым файлом.
MEMORY (HEAP)
Тип таблиц MEMORY хранится в оперативной памяти, поэтому все запросы к такой таблице выполняются очень быстро. Недостатком является полная потеря данных в случае сбоя работы сервера, поэтому в таблице данного типа хранят только временную информацию, которую можно легко восстановить заново.
При создании таблицы типа MEMORY она ассоциируется с одним-единственным файлом, имеющим расширение frm, в котором определяется структура таблицы.
При остановке или перезапуске сервера данный файл остается в текущей азе данных, но содержимое таблицы, которое хранится в оперативной памяти, теряется.
Ограничения MEMORY таблиц:
- Индексы используются только в операциях сравнения совместимо с операторами = и <=>, с другими операторами, такими как > или < индексирование столбцов не имеет смысла
- Возможно использование только неуникальных индексов.
- Можно использовать записи фиксированной длины, поэтому в них не допустимы столбцы типов TEXT и BLOD.
- В версиях, предшествующих MySQL 4.0.2, не поддерживается индексирование столбцов, содержащих NULL-значения.
EXAMPLE
Данный тип таблиц является заглушкой: можно создать таблицу данного типа, но хранить или получить из нее данные нельзя. При создании таблиц данного тип, точно также как и в случае MEMORY, создается один файл с расширением frm, в котором определяется структура таблицы.
EXAMPLE был введен для удобства сторонних разработчиков и демонстрирует, каким образом следует создавать собственные типы таблиц.
BDB (BerkeleyDB)
Таблицы типа BDB обслуживаются транзакционным обработчиком Berkeley DB, разработанным компанией Sleepycat. При создании таблиц данного типа формируются два файла: первый с расширением frm, в котором определяется структура базы данных, а второй с расширением db, в котором размещаются данные и индексы.
Особенности типа BDB:
- Для каждой таблицы ведется журнал. Это позволяет значительно повысить устойчивость базы и увеличить вероятность успешного восстановления после сбоя.
- Таблицы BDB хранятся в виде бинарных деревьев. Такое представление замедляет сканирование таблицы и увеличивает занимаемое место на жестком диске по сравнению с другими типами таблиц. С другой стороны, поиск отдельных значений в таких таблицах осуществляется быстрее.
- Каждая таблица BDB должна иметь первичный ключ, в случае его отсутствия создается скрытый первичный ключ, снабженный атрибутом AUTO_INCREMENT.
- Поддерживаются транзакции на уровне страниц.
- Подсчет числа строк в таблице при помощи встроенной функции count() осуществляется медленнее, чем для MyISAM, так как в отличие от последних, для BDB-таблиц не поддерживается подсчет количества строк в таблице, и MySQL вынужден каждый раз сканировать таблицу заново.
- Ключи не являются упакованными, и ключи занимают больше места.
- Если таблица займет все пространство на диске, то будет выведено сообщение об ошибке и выполнен откат транзакции.
- Для обеспечения блокировок таблиц на уровне операционной системы в файл db в момент создания таблицы записывается путь к файлу. Это приводит к тому, что файлы нельзя перемещать из текущего каталога в другой каталог.
- При создании резервных копий таблиц необходимо использовать утилиту mysqldump или создать резервные копии всех db файлов и файлов журналов. Обработчик таблицы хранит незавершенные транзакции в файлах журналов, их наличие требуется при запуске сервера MySQL.
InnoDB
Данный тип таблиц обеспечивает высокую производительность и устойчивое хранение данных в таблицах объемом вплоть до 1 Тбайт и нагрузкой на
сервер до 800 вставок/обновлений в секунду.Особенности таблиц типа InnoDB:
- Таблицы не создаются в базах данных, и для каждой из таблиц не выделяется отдельный файл данных. Исключение – файл определения с расширением frm, который создается по умолчанию. Все таблицы хранятся в едином табличном пространстве, поэтому имена таблиц должны быть уникальными.
- Хранение данных в едином табличном пространстве позволяет снять ограничение на объем таблиц, так как файл с таблицами может быть разбит не несколько частей и распределен по нескольким дискам или даже хостам.
- Данный тип таблиц поддерживает автоматическое восстановление после сбоев.
- Обеспечивается поддержка транзакций.
- Единственный тип таблиц, поддерживающий внешние ключи и каскадное удаление.
- Выполняется блокировка на уровне отдельных записей.
- Расширенная поддержка кодировок.
- Рушатся при достижении объема в несколько гигабайт, однако заметно уступают в скорости и не поддерживают полнотекстовый поиск.
NDB Cluster
Этот тип таблиц предназначен для организации кластеров, когда таблицы распределены между несколькими компьютерами, объединенными в локальную сеть.
ARCHIVE
Этот тип введен для хранения большого объема данных в сжатом формате. При создании данного типа MySQL, так же как и для таблиц любого другого типа, создает файл с именем, совпадающим с именем таблицы, и расширением frm. В этом файле хранится определение структуры таблицы. Помимо этого создаются два файла с расширением arz и arm, в которых хранятся данные и мета-данные.
CSV
Представляет собой обычный текстовой файл, записи в котором хранятся в строках, а поля разделены точкой с запятой. При создании таблицы в каталоге с текущей базой данных формируется два файла с именами, совпадающими с именем таблицы, и расширениями frm и csv.
FEDERATED
Позволяет хранить данные в удаленных таблицах, расположенных на другой машине сети. Во время создания таблицы в локальном каталоге создается только файл определения структуры таблицы с расширением frm, никакие другие файлы не создаются, так как все данные хранятся на удаленной машине.
BLACKHOLE
Таблица этого типа дословно переводится как черная дыра. Любые данные, помещаемые в таблицы этого типа, уничтожаются. Основное применение таблицы – это проверка синтаксиса дампов, когда необходимо проверить дамп на наличие ошибок, чтобы не производить реальное развертывание базы данных.
Транзакции
Транзакция – это последовательность операторов SQL, выполняющихся как единая операция, которая не прерывается другими клиентами. То есть пока происходит работа с записями таблицы, никто другой не может получить доступ к этим записям. Доступ к записям автоматически блокируется.
Репликация
Репликация позволяет дублировать данные основного сервера на одном или более подчиненных серверов. Репликация может осуществляться в режиме онлайн, или время от времени – подчиненный сервер может загружаться только для того, чтобы загрузить обновления.
Хранимые процедуры
Хранимые процедуры позволяют объединить последовательность запросов и сохранить их на сервере.
Преимущества хранимых процедур:
- Повторное использование кода
- Сокращение сетевого трафика.
- Безопасность.
- Простота доступа.
- Выполнение деловой логики.
Триггеры
Триггер – эта хранимая процедура, привязанная к событию на изменения содержимого таблицы: вставка, обновление, удаление.
Представления
Представление – это запрос на выборку, которому присваивается уникальное имя и который может сохранять или удалять из базы данных как обычную хранимую процедуру.
Информационная схема – это стандартный набор представлений системной таблицы.
Представление CHARACTER_SETS
Содержит список и характеристики кодировок, доступных текущему пользователю.
Представление COLLATIONS
Содержит список и характеристики сортировок, доступных текущему пользователю.
Представление COLLATION_CHARACTER_SET_APPLICABILITY
Содержит всевозможные комбинации кодировок и сортировок, доступные текущему пользователю.
Представление COLUMN_PRIVILEGES
Содержит информацию о привилегиях текущего пользователя на столбцы таблиц.
Представление COLUMNS
Содержит информацию о доступных текущему пользователю столбцах во всех таблицах всех баз данных.
Представление KEY_COLUMN_USAGE
Содержит информацию об индексированных столбцах, доступных текущему пользователю.
Представление ROUTINES
Содержит список и параметры хранимых процедур и функций, доступных текущему пользователю для выполнения.
Представление SCHEMA_PRIVILEGES
Содержит глобальные привилегии всех пользователей сервера MySQL.
Представление SCHEMATA
Содержит список и характеристики баз данных, доступных текущему пользователю.
Представление STATISTICS
Содержит разнообразную информацию об индексах.
Представление TABLE_CONSTRAINTS
Содержит информацию об ограничивающих индексах, которые имеют ограничение уникальности значения (PRIMARY KEY, UNIQUE) или ограничение внешнего ключа (FOREIGN KEY).
Представление TABLE_PRIVILEGES
Содержит информацию о табличных привилегиях.
Представление TABLES
Содержит список таблиц и их характеристики.
Представление USER_PRIVILEGES
Содержит информацию о глобальных привилегиях базы данных.
Представление VIEWS
Содержит информацию о глобальных привилегиях базы данных.
Реляционные базы данных
Реляционная модель базы данных состоит из трех частей:
Структурная часть – описывает, какие объекты рассматриваются реляционной моделью. Реляционная база данных состоит из набора отношений. Схемой реляционной базы данных называется набор заголовков отношений, входящих в базу данных.
Целостная часть – описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность внешних ключей.
Манипуляционная часть – описывает два эквивалентных способа манипулирования реляционными данными – реляционную алгебру и реляционное исчисление.
Термины реляционных баз данных.
| Реляционный термин | Описание |
| Отношение | Таблица |
| Заголовок отношения | Заголовок таблицы |
| Тело отношения | Тело таблицы |
| Атрибут отношения | Наименование столбца (поля) таблицы |
| Кортеж отношения | Строка (запись) таблицы |
| Степень отношения | Количество столбцов таблицы |
| Мощность (кардинальность) отношения |
Количество строк таблицы |
| Домен | Базовый или пользовательский тип данных |
Атрибуты
Атрибуты сущности – это именованная характеристика, являющаяся некоторым свойством сущности.
При проектировании атрибутов полезно задавать такие вопросы:
- Какие данные о сущности мы хотим хранить?
- Какие свойства есть у экземпляра этой сущности, даже если вокруг нее больше ничего нет?
- Есть ли у экземпляра этой сущности только один экземпляр этой вещи?
- Может ли изменяться описанная атрибутом характеристика сущности с течением времени?
Бинарные связи
Бинарные связи – это связи, в которые вступают ровно две сущности. Важнейшее свойство связи – кардинальное число.
Типы бинарных связей:
- Связь типа «один-к-одному» означает, что один экземпляр первой сущности связан не более чем с одним экземпляром второй сущности и, наоборот, один экземпляр второй сущности связан не более чем с одним экземпляром первой сущности.
- Связь типа «один-ко-многим» означает, что один экземпляр первой сущности связан с несколькими экземплярами второй сущности, но при этом один экземпляр второй сущности связан не более чем с один экземпляром первой сущности.
- Связь типа «много-ко-многим» означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Эта связь должна быть заменена двумя связями типа один-ко-многим путем создания промежуточной сущности.
Ролевые связи
Ролевые связи необходимы, когда:
- Экземпляры одной и той же сущности вступают в связи между собой.
- В зависимости от значения одного из атрибутов сущности по-разному определяется само множество других ее атрибутов.
- В зависимости от значения одного из атрибутов сущности она по-разному вступает в связи с другими сущностями.
Рекурсивные связи
Рекурсивная связь – это связь, в которой одни и те же сущности учувствуют несколько раз или в разных ролях. Классический пример рекурсивной связи –
это связь сущности с самой собой.
Различают три варианта рекурсивной связи:
- Рекурсивная связь «один-к-одному», моделирующая цепочку.
- Рекурсивная связь «один-ко-многим» или иерархическая рекурсивная связь.
- Рекурсивная связь «много-ко-многим» или сетевая рекурсивная связь.
Логическое проектирование и оптимизация
OLTP – обработка транзакций в режиме реального времени. Способ организации БД, при котором система работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом клиенту требуется от системы минимальное время отклика. Примерами OLTP приложений могут быть системы складского учета, системы заказов билетов, банковские системы, выполняющие операции по переводу денег.
Особенности OLTP приложений:
- Транзакций очень много.
- Транзакции выполняются одновременно.
- При возникновении ошибки транзакция должна целиком откатиться и вернуть систему к состоянию, которое было до начала транзакции (не должно быть ситуации, когда деньги сняты со счета, но не поступили на другой счет).
- Все запросы к базе данных, которые должны выполняться в реальном времени, состоят из команд вставки, обновления, удаления.
OLAP системы характеризуются следующими признаками:
- Добавление в систему новых данных происходит относительно редко крупными блоками.
- Данные, добавленные в систему, обычно никогда не удаляются.
- Перед загрузкой данные проходят различные процедуры очистки, связанные с тем, что в одну систему могут поступать данные из многих источников, имеющих различные форматы представления для одних и тех же понятий, данные могут быть некорректны, ошибочны
- Запросы к системе являются нерегламентированными и, как правило, достаточно сложными. Очень часто новый запрос формулируется аналитиком для уточнения результата, полученного при выполнении предыдущего запроса.
- Скорость выполнения запросов важна, но не критична.
Уровни моделирования реляционной базы данных
Внешний уровень – уровень представления базы данных с точки зрения пользователя.
Концептуальный – описывает какие данные хранятся в базе данных, а также, какие связи имеются между этими данными.
Внутренний – описывает физическое представление базы данных в компьютере, то есть отвечает на вопрос, как информация хранится в базе данных.
Вводятся следующие понятия:
- Модель предметной области – знания о предметной области, описанные с помощью некоторого формального общепринятого способа.
- Логическая (концептуальная) модель данных – является органической составляющей модели предметной области, описывает понятия предметной области в реляционных терминах данных.
- Физическая модель данных – описывает данные средствами конкретной реляционной СУБД.
- База данных и приложение – средства, реализованные на конкретной программно-аппаратной основе.
Критерии оценки качества логической модели
Критерии важные с точки зрения получения качественной базы данных:
1. Адекватность базы данных предметной области.
2. Скорость выполнения операций обновления данных.
3. Скорость выполнения операций выборки данных.
4. Легкость разработки и сопровождения базы данных.
5. Отсутствие неоправданной избыточности данных.
Физическое представление базы данных
Проблемы, которые приходится решать при проектировании физического представления базы данных:
- Определение требований к системным ресурсам.
- Выбор файловой структуры и определение группы файлов.
- Анализ запросов и транзакций с целью корректного размещения базовых таблиц и индексов по группам файлов.
- Определение вторичных индексов и размещение их в группах файлов.
- Анализ адекватности базы данных, с точки зрения возможности выполнения всех заданных транзакций при допустимом уровне их конфликтности и приемлемом совокупном быстродействии.
- Анализ необходимости введения контролируемой избыточности данных и средств ее реализации.
- Определение необходимости применения специфических настроек сервера для конкретной системной конфигурации.
- Разработка механизмов защиты.
СУБД – Обзор
База данных представляет собой набор связанных данных, а данные представляют собой набор фактов и цифр, которые могут быть обработаны для получения информации.
В основном данные представляют собой записываемые факты. Данные помогают в получении информации, которая основана на фактах. Например, если у нас есть данные о оценках, полученных всеми учащимися, мы можем сделать вывод о баллах и средних оценках.
Система управления базами данных хранит данные таким образом, что становится легче получать, манипулировать и производить информацию.
Характеристики
Традиционно данные были организованы в файловых форматах. СУБД была новой концепцией, и все исследования были проведены для того, чтобы преодолеть недостатки традиционного стиля управления данными. Современная СУБД имеет следующие характеристики –
-
Реальная сущность – современная СУБД более реалистична и использует реальные сущности для проектирования своей архитектуры. Он использует поведение и атрибуты тоже. Например, школьная база данных может использовать учащихся как сущность, а их возраст – как атрибут.
-
Таблицы на основе отношений – СУБД позволяет сущностям и отношениям между ними формировать таблицы. Пользователь может понять архитектуру базы данных, просто взглянув на имена таблиц.
-
Изоляция данных и приложений. Система баз данных полностью отличается от своих данных. База данных является активной сущностью, тогда как данные называются пассивными, на которых база данных работает и организует. СУБД также хранит метаданные, которые представляют собой данные о данных, чтобы упростить собственный процесс.
-
Меньшая избыточность – СУБД следует правилам нормализации, которая разделяет отношение, когда любой из ее атрибутов имеет избыточность в значениях. Нормализация – это математически насыщенный и научный процесс, который уменьшает избыточность данных.
-
Согласованность. Согласованность – это состояние, при котором каждое отношение в базе данных остается согласованным. Существуют методы и приемы, которые могут обнаружить попытку перевода базы данных в несогласованное состояние. СУБД может обеспечить большую согласованность по сравнению с более ранними формами приложений для хранения данных, таких как системы обработки файлов.
-
Язык запросов – СУБД оснащена языком запросов, что делает его более эффективным для извлечения и обработки данных. Пользователь может применить столько разных вариантов фильтрации, сколько требуется для получения набора данных. Традиционно это было невозможно, когда использовалась система обработки файлов.
-
Свойства ACID – СУБД следует концепциям Tomicity, C- согласованности, I- солирования и устойчивости (обычно сокращается до ACID). Эти понятия применяются к транзакциям, которые манипулируют данными в базе данных. Свойства ACID помогают базе данных оставаться работоспособной в мультитранзакционных средах и в случае сбоя.
-
Многопользовательский и параллельный доступ – СУБД поддерживает многопользовательскую среду и позволяет им получать доступ к данным и управлять ими параллельно. Хотя существуют ограничения на транзакции, когда пользователи пытаются обрабатывать один и тот же элемент данных, но пользователи всегда не знают о них.
-
Несколько представлений – СУБД предлагает несколько представлений для разных пользователей. Пользователь, который находится в отделе продаж, будет иметь другое представление о базе данных, чем человек, работающий в отделе производства. Эта функция позволяет пользователям иметь общее представление о базе данных в соответствии с их требованиями.
-
Безопасность. Такие функции, как множественные представления, в некоторой степени обеспечивают безопасность, когда пользователи не могут получить доступ к данным других пользователей и отделов. СУБД предлагает методы наложения ограничений при вводе данных в базу данных и извлечении их на более позднем этапе. СУБД предлагает много разных уровней функций безопасности, что позволяет нескольким пользователям иметь разные представления с разными функциями. Например, пользователь в отделе продаж не может видеть данные, принадлежащие отделу закупок. Кроме того, также можно управлять тем, сколько данных отдела продаж должно быть отображено пользователю. Поскольку СУБД не сохраняется на диске как традиционные файловые системы, злоумышленникам очень сложно взломать код.
Реальная сущность – современная СУБД более реалистична и использует реальные сущности для проектирования своей архитектуры. Он использует поведение и атрибуты тоже. Например, школьная база данных может использовать учащихся как сущность, а их возраст – как атрибут.
Таблицы на основе отношений – СУБД позволяет сущностям и отношениям между ними формировать таблицы. Пользователь может понять архитектуру базы данных, просто взглянув на имена таблиц.
Изоляция данных и приложений. Система баз данных полностью отличается от своих данных. База данных является активной сущностью, тогда как данные называются пассивными, на которых база данных работает и организует. СУБД также хранит метаданные, которые представляют собой данные о данных, чтобы упростить собственный процесс.
Меньшая избыточность – СУБД следует правилам нормализации, которая разделяет отношение, когда любой из ее атрибутов имеет избыточность в значениях. Нормализация – это математически насыщенный и научный процесс, который уменьшает избыточность данных.
Согласованность. Согласованность – это состояние, при котором каждое отношение в базе данных остается согласованным. Существуют методы и приемы, которые могут обнаружить попытку перевода базы данных в несогласованное состояние. СУБД может обеспечить большую согласованность по сравнению с более ранними формами приложений для хранения данных, таких как системы обработки файлов.
Язык запросов – СУБД оснащена языком запросов, что делает его более эффективным для извлечения и обработки данных. Пользователь может применить столько разных вариантов фильтрации, сколько требуется для получения набора данных. Традиционно это было невозможно, когда использовалась система обработки файлов.
Свойства ACID – СУБД следует концепциям Tomicity, C- согласованности, I- солирования и устойчивости (обычно сокращается до ACID). Эти понятия применяются к транзакциям, которые манипулируют данными в базе данных. Свойства ACID помогают базе данных оставаться работоспособной в мультитранзакционных средах и в случае сбоя.
Многопользовательский и параллельный доступ – СУБД поддерживает многопользовательскую среду и позволяет им получать доступ к данным и управлять ими параллельно. Хотя существуют ограничения на транзакции, когда пользователи пытаются обрабатывать один и тот же элемент данных, но пользователи всегда не знают о них.
Несколько представлений – СУБД предлагает несколько представлений для разных пользователей. Пользователь, который находится в отделе продаж, будет иметь другое представление о базе данных, чем человек, работающий в отделе производства. Эта функция позволяет пользователям иметь общее представление о базе данных в соответствии с их требованиями.
Безопасность. Такие функции, как множественные представления, в некоторой степени обеспечивают безопасность, когда пользователи не могут получить доступ к данным других пользователей и отделов. СУБД предлагает методы наложения ограничений при вводе данных в базу данных и извлечении их на более позднем этапе. СУБД предлагает много разных уровней функций безопасности, что позволяет нескольким пользователям иметь разные представления с разными функциями. Например, пользователь в отделе продаж не может видеть данные, принадлежащие отделу закупок. Кроме того, также можно управлять тем, сколько данных отдела продаж должно быть отображено пользователю. Поскольку СУБД не сохраняется на диске как традиционные файловые системы, злоумышленникам очень сложно взломать код.
пользователей
Типичная СУБД имеет пользователей с разными правами и разрешениями, которые используют ее для разных целей. Некоторые пользователи получают данные, а некоторые их поддерживают. Пользователи СУБД можно в общих чертах классифицировать следующим образом:
-
Администраторы. Администраторы обслуживают СУБД и несут ответственность за администрирование базы данных. Они несут ответственность за его использование и кем оно должно быть использовано. Они создают профили доступа для пользователей и применяют ограничения для обеспечения изоляции и обеспечения безопасности. Администраторы также следят за ресурсами СУБД, такими как системная лицензия, необходимые инструменты и другое техническое обслуживание программного и аппаратного обеспечения.
-
Дизайнеры. Дизайнеры – это группа людей, которые фактически работают над частью проектирования базы данных. Они внимательно следят за тем, какие данные следует хранить и в каком формате. Они идентифицируют и проектируют весь набор объектов, отношений, ограничений и представлений.
-
Конечные пользователи. Конечные пользователи – это те, кто действительно получает выгоду от наличия СУБД. Конечные пользователи могут варьироваться от простых зрителей, которые обращают внимание на журналы или рыночные ставки, до искушенных пользователей, таких как бизнес-аналитики.
Администраторы. Администраторы обслуживают СУБД и несут ответственность за администрирование базы данных. Они несут ответственность за его использование и кем оно должно быть использовано. Они создают профили доступа для пользователей и применяют ограничения для обеспечения изоляции и обеспечения безопасности. Администраторы также следят за ресурсами СУБД, такими как системная лицензия, необходимые инструменты и другое техническое обслуживание программного и аппаратного обеспечения.
Дизайнеры. Дизайнеры – это группа людей, которые фактически работают над частью проектирования базы данных. Они внимательно следят за тем, какие данные следует хранить и в каком формате. Они идентифицируют и проектируют весь набор объектов, отношений, ограничений и представлений.
Конечные пользователи. Конечные пользователи – это те, кто действительно получает выгоду от наличия СУБД. Конечные пользователи могут варьироваться от простых зрителей, которые обращают внимание на журналы или рыночные ставки, до искушенных пользователей, таких как бизнес-аналитики.
СУБД – Архитектура
Дизайн СУБД зависит от ее архитектуры. Он может быть централизованным или децентрализованным или иерархическим. Архитектура СУБД может рассматриваться как одноуровневая или многоуровневая. N-уровневая архитектура делит всю систему на связанные, но независимые n модулей, которые могут быть независимо изменены, изменены, изменены или заменены.
В одноуровневой архитектуре СУБД является единственным объектом, где пользователь непосредственно сидит в СУБД и использует ее. Любые изменения, сделанные здесь, будут сделаны непосредственно в самой СУБД. Он не предоставляет удобных инструментов для конечных пользователей. Разработчики баз данных и программисты обычно предпочитают использовать одноуровневую архитектуру.
Если архитектура СУБД является двухуровневой, то у нее должно быть приложение, через которое можно получить доступ к СУБД. Программисты используют двухуровневую архитектуру, где они получают доступ к СУБД с помощью приложения. Здесь уровень приложения полностью независим от базы данных с точки зрения работы, дизайна и программирования.
3-х уровневая архитектура
3-уровневая архитектура отделяет свои уровни друг от друга на основе сложности пользователей и того, как они используют данные, представленные в базе данных. Это наиболее широко используемая архитектура для проектирования СУБД.
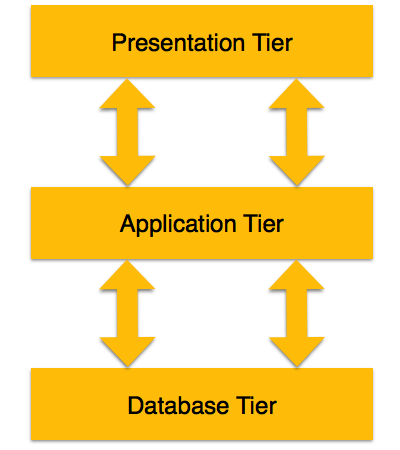
-
Уровень базы данных (данных) – на этом уровне база данных находится вместе с ее языками обработки запросов. У нас также есть отношения, которые определяют данные и их ограничения на этом уровне.
-
Уровень приложений (средний) – на этом уровне находятся сервер приложений и программы, обращающиеся к базе данных. Для пользователя этот уровень приложения представляет собой абстрактное представление базы данных. Конечные пользователи не знают о существовании базы данных за пределами приложения. С другой стороны, уровень базы данных не знает ни о каком другом пользователе, кроме уровня приложения. Следовательно, прикладной уровень находится посередине и действует как посредник между конечным пользователем и базой данных.
-
Пользовательский (презентационный) уровень – конечные пользователи работают на этом уровне, и они ничего не знают о существовании базы данных за пределами этого уровня. На этом уровне приложение может предоставить несколько представлений базы данных. Все представления создаются приложениями, которые находятся на уровне приложений.
Уровень базы данных (данных) – на этом уровне база данных находится вместе с ее языками обработки запросов. У нас также есть отношения, которые определяют данные и их ограничения на этом уровне.
Уровень приложений (средний) – на этом уровне находятся сервер приложений и программы, обращающиеся к базе данных. Для пользователя этот уровень приложения представляет собой абстрактное представление базы данных. Конечные пользователи не знают о существовании базы данных за пределами приложения. С другой стороны, уровень базы данных не знает ни о каком другом пользователе, кроме уровня приложения. Следовательно, прикладной уровень находится посередине и действует как посредник между конечным пользователем и базой данных.
Пользовательский (презентационный) уровень – конечные пользователи работают на этом уровне, и они ничего не знают о существовании базы данных за пределами этого уровня. На этом уровне приложение может предоставить несколько представлений базы данных. Все представления создаются приложениями, которые находятся на уровне приложений.
Многоуровневая архитектура базы данных легко модифицируется, так как почти все ее компоненты независимы и могут быть изменены независимо.
СУБД – Модели данных
Модели данных определяют, как моделируется логическая структура базы данных. Модели данных являются фундаментальными объектами для введения абстракции в СУБД. Модели данных определяют, как данные связаны друг с другом и как они обрабатываются и хранятся в системе.
Самой первой моделью данных могут быть плоские модели данных, где все используемые данные должны храниться в одной плоскости. Более ранние модели данных не были настолько научными, поэтому они были склонны вводить много дублирования и обновлять аномалии.
Модель сущности-отношения
Модель Entity-Relationship (ER) основана на представлении о сущностях реального мира и отношениях между ними. При формулировании реального сценария в модель базы данных модель ER создает набор сущностей, набор отношений, общие атрибуты и ограничения.
Модель ER лучше всего использовать для концептуального проектирования базы данных.
Модель ER основана на:
-
Сущности и их атрибуты.
-
Отношения между сущностями.
Сущности и их атрибуты.
Отношения между сущностями.
Эти понятия объяснены ниже.
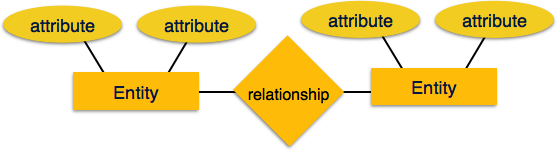
-
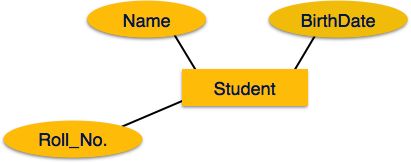
Сущность – Сущность в модели ER – это сущность реального мира, имеющая свойства, называемые атрибутами . Каждый атрибут определяется своим набором значений, называемых доменом . Например, в школьной базе данных ученик рассматривается как сущность. Студент имеет различные атрибуты, такие как имя, возраст, класс и т. Д.
-
Отношения – логическая связь между сущностями называется отношениями . Отношения отображаются с сущностями различными способами. Кардинальности отображения определяют количество ассоциаций между двумя объектами.
Отображение кардиналов –
- один к одному
- один ко многим
- много к одному
- много ко многим
Сущность – Сущность в модели ER – это сущность реального мира, имеющая свойства, называемые атрибутами . Каждый атрибут определяется своим набором значений, называемых доменом . Например, в школьной базе данных ученик рассматривается как сущность. Студент имеет различные атрибуты, такие как имя, возраст, класс и т. Д.
Отношения – логическая связь между сущностями называется отношениями . Отношения отображаются с сущностями различными способами. Кардинальности отображения определяют количество ассоциаций между двумя объектами.
Отображение кардиналов –
Реляционная модель
Наиболее популярной моделью данных в СУБД является реляционная модель. Это более научная модель, чем другие. Эта модель основана на логике предикатов первого порядка и определяет таблицу как n-арное отношение .
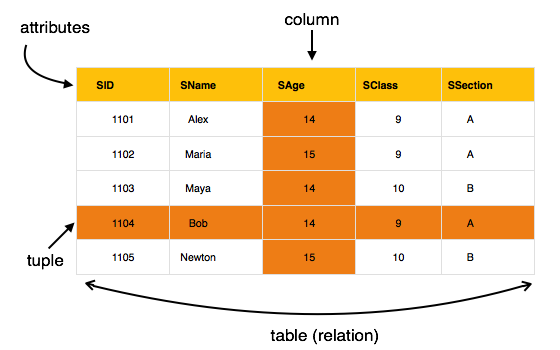
Основные моменты этой модели –
- Данные хранятся в таблицах, называемых отношениями .
- Отношения могут быть нормализованы.
- В нормализованных отношениях сохраненные значения являются атомарными.
- Каждая строка в отношении содержит уникальное значение.
- Каждый столбец в отношении содержит значения из одного домена.
СУБД – Схемы данных
Схема базы данных
Схема базы данных – это каркасная структура, которая представляет логическое представление всей базы данных. Он определяет, как организованы данные и как связаны между собой отношения. Он формулирует все ограничения, которые должны применяться к данным.
Схема базы данных определяет ее сущности и отношения между ними. Он содержит описательную деталь базы данных, которая может быть изображена с помощью схематических представлений. Именно дизайнеры базы данных разрабатывают схему, чтобы помочь программистам понять базу данных и сделать ее полезной.
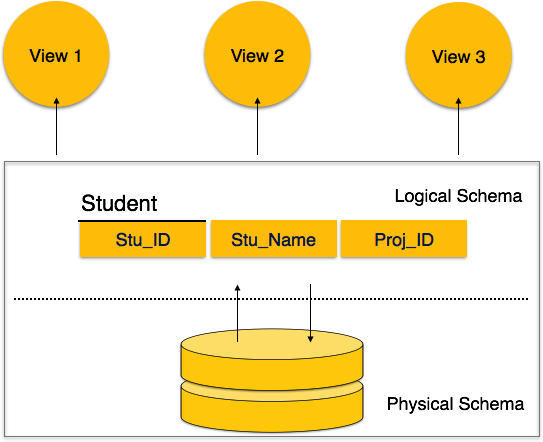
Схема базы данных может быть разделена на две категории:
-
Физическая схема базы данных – эта схема относится к фактическому хранилищу данных и его форме хранения, такой как файлы, индексы и т. Д. Она определяет, как данные будут храниться во вторичном хранилище.
-
Схема логической базы данных – эта схема определяет все логические ограничения, которые необходимо применить к хранимым данным. Он определяет таблицы, представления и ограничения целостности.
Физическая схема базы данных – эта схема относится к фактическому хранилищу данных и его форме хранения, такой как файлы, индексы и т. Д. Она определяет, как данные будут храниться во вторичном хранилище.
Схема логической базы данных – эта схема определяет все логические ограничения, которые необходимо применить к хранимым данным. Он определяет таблицы, представления и ограничения целостности.
Экземпляр базы данных
Важно, чтобы мы различали эти два термина по отдельности. Схема базы данных является каркасом базы данных. Он разработан, когда база данных не существует вообще. После того, как база данных заработает, в нее очень сложно внести какие-либо изменения. Схема базы данных не содержит никаких данных или информации.
Экземпляр базы данных – это состояние оперативной базы данных с данными в любой момент времени. Он содержит снимок базы данных. Экземпляры базы данных имеют тенденцию меняться со временем. СУБД гарантирует, что каждый ее экземпляр (состояние) находится в допустимом состоянии, старательно следуя всем валидациям, ограничениям и условиям, наложенным разработчиками базы данных.
СУБД – Независимость данных
Если система базы данных не является многоуровневой, то становится трудно вносить какие-либо изменения в систему базы данных. Системы баз данных спроектированы в несколько слоев, как мы узнали ранее.
Независимость данных
Система баз данных обычно содержит много данных в дополнение к данным пользователей. Например, он хранит данные о данных, известные как метаданные, чтобы легко находить и получать данные. Довольно сложно изменить или обновить набор метаданных после их сохранения в базе данных. Но по мере расширения СУБД она должна со временем меняться, чтобы удовлетворить требования пользователей. Если все данные зависят, это станет утомительной и очень сложной задачей.
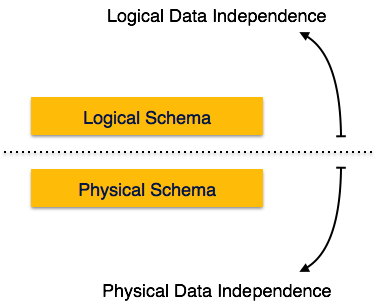
Метаданные сами по себе следуют многоуровневой архитектуре, поэтому при изменении данных на одном уровне они не влияют на данные на другом уровне. Эти данные независимы, но сопоставлены друг с другом.
Независимость логических данных
Логические данные – это данные о базе данных, то есть они хранят информацию об управлении данными внутри. Например, таблица (отношение), хранящаяся в базе данных, и все ее ограничения, примененные к этому отношению.
Независимость логических данных – это своего рода механизм, который освобождает себя от фактических данных, хранящихся на диске. Если мы внесем некоторые изменения в формат таблицы, это не должно изменить данные, хранящиеся на диске.
Независимость физических данных
Все схемы являются логическими, а фактические данные хранятся в битовом формате на диске. Независимость от физических данных – это возможность изменять физические данные без влияния на схему или логические данные.
Например, в случае, если мы хотим изменить или обновить саму систему хранения – предположим, что мы хотим заменить жесткие диски на SSD – это не должно оказывать никакого влияния на логические данные или схемы.
Модель ER – Основные понятия
Модель ER определяет концептуальное представление базы данных. Он работает вокруг сущностей реального мира и их ассоциаций. На уровне представления модель ER считается хорошим вариантом для проектирования баз данных.
сущность
Сущность может быть объектом реального мира, одушевленным или неодушевленным, который можно легко идентифицировать. Например, в школьной базе данных учащиеся, учителя, классы и предлагаемые курсы могут рассматриваться как объекты. Все эти объекты имеют некоторые атрибуты или свойства, которые придают им идентичность.
Набор сущностей – это совокупность сущностей схожего типа. Набор сущностей может содержать сущности с атрибутами, имеющими сходные значения. Например, набор учеников может содержать всех учеников школы; аналогичным образом, в набор учителей могут входить все учителя школы со всех факультетов. Наборы сущностей не должны быть непересекающимися.
Атрибуты
Объекты представлены с помощью их свойств, называемых атрибутами . Все атрибуты имеют значения. Например, учащийся может иметь имя, класс и возраст в качестве атрибутов.
Существует домен или диапазон значений, которые могут быть назначены атрибутам. Например, имя студента не может быть числовым значением. Это должно быть буквенным. Возраст ученика не может быть отрицательным и т. Д.
Типы атрибутов
-
Простой атрибут. Простые атрибуты представляют собой атомарные значения, которые не могут быть разделены далее. Например, телефонный номер учащегося является атомным значением из 10 цифр.
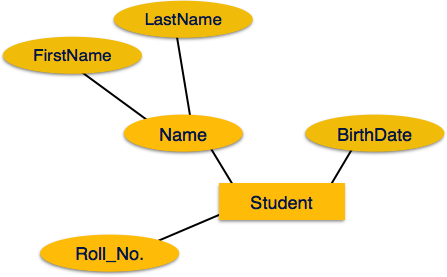
-
Составной атрибут – Составные атрибуты состоят из нескольких простых атрибутов. Например, полное имя учащегося может иметь имя_имя и фамилия.
-
Производный атрибут – Производные атрибуты – это атрибуты, которые не существуют в физической базе данных, но их значения получены из других атрибутов, присутствующих в базе данных. Например, Average_salary в отделе не следует сохранять непосредственно в базе данных, вместо этого его можно получить. Для другого примера, возраст может быть получен из data_of_birth.
-
Атрибут с одним значением – Атрибуты с одним значением содержат одно значение. Например – Social_Security_Number.
-
Многозначный атрибут – многозначные атрибуты могут содержать более одного значения. Например, человек может иметь более одного номера телефона, адрес электронной почты и т. Д.
Простой атрибут. Простые атрибуты представляют собой атомарные значения, которые не могут быть разделены далее. Например, телефонный номер учащегося является атомным значением из 10 цифр.
Составной атрибут – Составные атрибуты состоят из нескольких простых атрибутов. Например, полное имя учащегося может иметь имя_имя и фамилия.
Производный атрибут – Производные атрибуты – это атрибуты, которые не существуют в физической базе данных, но их значения получены из других атрибутов, присутствующих в базе данных. Например, Average_salary в отделе не следует сохранять непосредственно в базе данных, вместо этого его можно получить. Для другого примера, возраст может быть получен из data_of_birth.
Атрибут с одним значением – Атрибуты с одним значением содержат одно значение. Например – Social_Security_Number.
Многозначный атрибут – многозначные атрибуты могут содержать более одного значения. Например, человек может иметь более одного номера телефона, адрес электронной почты и т. Д.
Эти типы атрибутов могут объединяться таким образом, как –
- простые однозначные атрибуты
- простые многозначные атрибуты
- составные однозначные атрибуты
- составные многозначные атрибуты
Набор сущностей и ключи
Ключ – это атрибут или набор атрибутов, который однозначно идентифицирует сущность среди множества сущностей.
Например, номер студента делает его идентифицируемым среди студентов.
-
Super Key – Набор атрибутов (один или несколько), которые совместно идентифицируют объект в наборе объектов.
-
Ключ-кандидат – минимальный супер-ключ называется ключом-кандидатом. Набор объектов может иметь более одного ключа-кандидата.
-
Первичный ключ – первичный ключ – это один из ключей-кандидатов, выбранных разработчиком базы данных для однозначной идентификации набора сущностей.
Super Key – Набор атрибутов (один или несколько), которые совместно идентифицируют объект в наборе объектов.
Ключ-кандидат – минимальный супер-ключ называется ключом-кандидатом. Набор объектов может иметь более одного ключа-кандидата.
Первичный ключ – первичный ключ – это один из ключей-кандидатов, выбранных разработчиком базы данных для однозначной идентификации набора сущностей.
отношения
Ассоциация между сущностями называется отношениями. Например, сотрудник работает на кафедре, студент записывается на курс. Здесь Works_at и Enrolls называются отношениями.
Набор отношений
Набор отношений подобного типа называется набором отношений. Как и сущности, отношения тоже могут иметь атрибуты. Эти атрибуты называются описательными атрибутами .
Степень Отношения
Количество участвующих субъектов в отношениях определяет степень отношений.
- Двоичный = степень 2
- Троичный = степень 3
- n-ary = степень
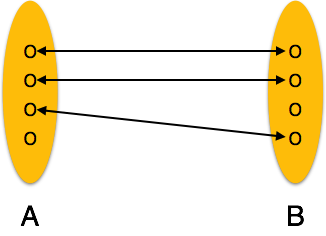
Отображение мощности
Количество элементов определяет количество объектов в одном наборе объектов, которое может быть связано с количеством объектов другого набора через набор отношений.
-
Один-к-одному. Один объект из набора объектов A может быть связан не более чем с одним объектом из набора объектов B и наоборот.
-
Один-ко-многим. Один объект из набора объектов A может быть связан с более чем одним объектом из набора B объектов, однако объект из набора B объектов может быть связан не более чем с одним объектом.
-
Много-к-одному – более одного объекта из набора объектов A могут быть связаны не более чем с одним объектом набора объектов B, однако объект из набора объектов B может быть связан с несколькими объектами из набора объектов A.
-
Многие ко многим – Один объект из A может быть связан с несколькими объектами из B и наоборот.
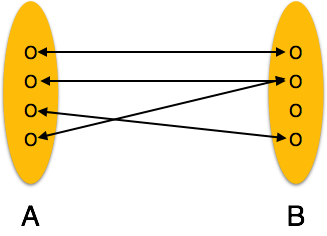
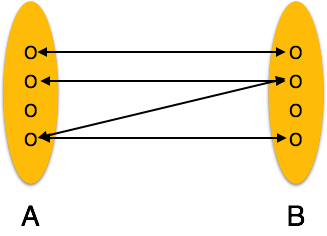
Один-к-одному. Один объект из набора объектов A может быть связан не более чем с одним объектом из набора объектов B и наоборот.
Один-ко-многим. Один объект из набора объектов A может быть связан с более чем одним объектом из набора B объектов, однако объект из набора B объектов может быть связан не более чем с одним объектом.
Много-к-одному – более одного объекта из набора объектов A могут быть связаны не более чем с одним объектом набора объектов B, однако объект из набора объектов B может быть связан с несколькими объектами из набора объектов A.
Многие ко многим – Один объект из A может быть связан с несколькими объектами из B и наоборот.
Представление ER-диаграммы
Давайте теперь узнаем, как модель ER представлена с помощью диаграммы ER. Любой объект, например, объекты, атрибуты объекта, наборы отношений и атрибуты наборов отношений, могут быть представлены с помощью диаграммы ER.
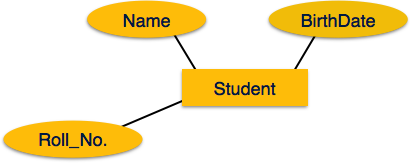
сущность
Сущности представлены с помощью прямоугольников. Прямоугольники именуются набором сущностей, который они представляют.

Атрибуты
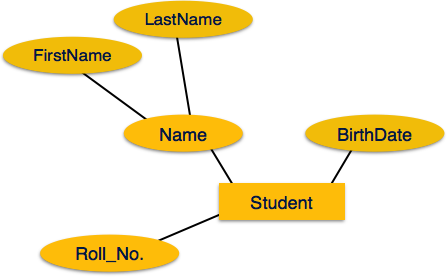
Атрибуты являются свойствами сущностей. Атрибуты представлены с помощью эллипсов. Каждый эллипс представляет один атрибут и напрямую связан с его сущностью (прямоугольником).
Если атрибуты составные , они далее делятся на древовидную структуру. Каждый узел затем подключается к своему атрибуту. То есть составные атрибуты представлены эллипсами, которые связаны с эллипсом.
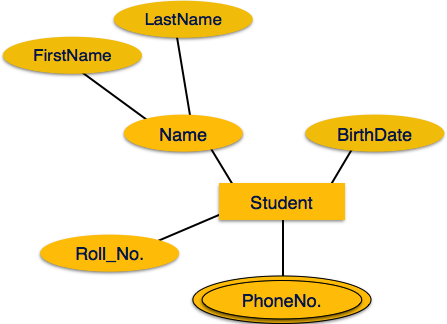
Многозначные атрибуты изображены двойным эллипсом.
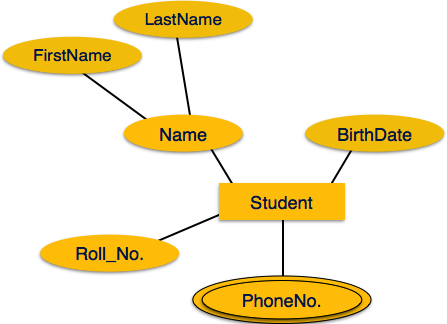
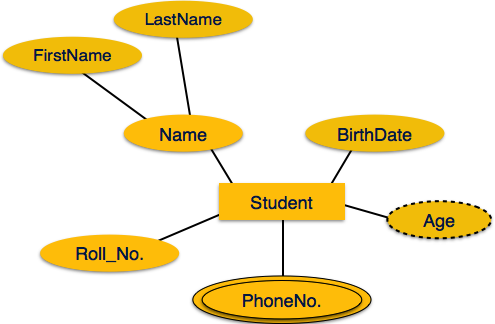
Производные атрибуты изображены пунктирным эллипсом.
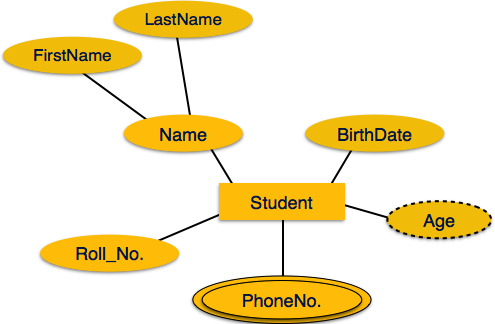
отношения
Отношения представлены ромбовидной коробкой. Название отношений написано внутри алмазной коробки. Все сущности (прямоугольники), участвующие в отношениях, связаны с ней линией.
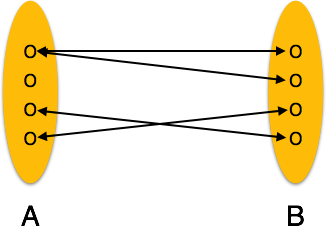
Бинарные отношения и мощность
Отношение, в котором участвуют два объекта, называется бинарным отношением . Количество элементов – это число экземпляров объекта из отношения, которое может быть связано с отношением.
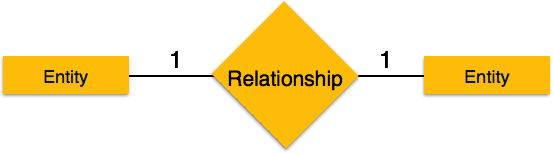
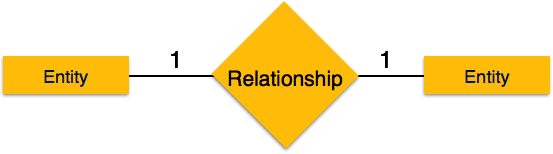
-
Один-к-одному – когда только один экземпляр объекта связан с отношением, он помечается как «1: 1». На следующем рисунке показано, что только один экземпляр каждого объекта должен быть связан с отношением. Он изображает отношения один-к-одному.
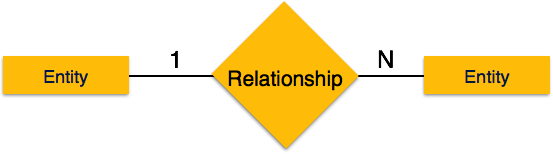
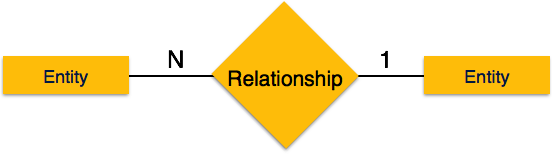
-
Один-ко-многим – когда более чем один экземпляр объекта связан с отношением, он помечается как «1: N». На следующем рисунке показано, что только один экземпляр объекта слева и более одного экземпляра объекта справа могут быть связаны с отношением. Он изображает отношения один ко многим.
-
Много-к-одному – когда с отношением связано более одного экземпляра объекта, оно помечается как «N: 1». На следующем рисунке показано, что более одного экземпляра объекта слева и только один экземпляр объекта справа могут быть связаны с отношением. Он изображает отношения многие-к-одному.
-
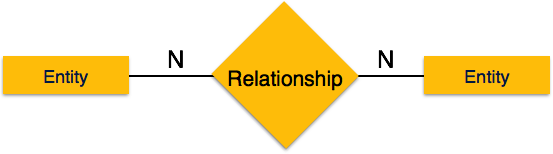
Многие ко многим – следующее изображение отражает то, что с этим отношением может быть связано более одного экземпляра объекта слева и более одного экземпляра объекта справа. Он изображает отношения многих ко многим.
Один-к-одному – когда только один экземпляр объекта связан с отношением, он помечается как «1: 1». На следующем рисунке показано, что только один экземпляр каждого объекта должен быть связан с отношением. Он изображает отношения один-к-одному.
Один-ко-многим – когда более чем один экземпляр объекта связан с отношением, он помечается как «1: N». На следующем рисунке показано, что только один экземпляр объекта слева и более одного экземпляра объекта справа могут быть связаны с отношением. Он изображает отношения один ко многим.
Много-к-одному – когда с отношением связано более одного экземпляра объекта, оно помечается как «N: 1». На следующем рисунке показано, что более одного экземпляра объекта слева и только один экземпляр объекта справа могут быть связаны с отношением. Он изображает отношения многие-к-одному.
Многие ко многим – следующее изображение отражает то, что с этим отношением может быть связано более одного экземпляра объекта слева и более одного экземпляра объекта справа. Он изображает отношения многих ко многим.
Ограничения участия
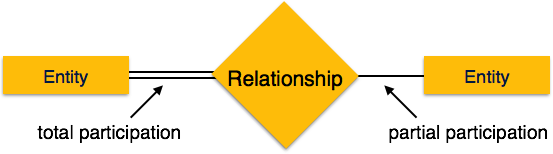
-
Общее участие – каждая организация участвует в отношениях. Общее участие представлено двойными линиями.
-
Частичное участие – не все лица вовлечены в отношения. Частичное участие представлено отдельными строчками.
Общее участие – каждая организация участвует в отношениях. Общее участие представлено двойными линиями.
Частичное участие – не все лица вовлечены в отношения. Частичное участие представлено отдельными строчками.
Генерализация Агрегация
Давайте теперь узнаем, как модель ER представлена с помощью диаграммы ER. Любой объект, например, объекты, атрибуты объекта, наборы отношений и атрибуты наборов отношений, могут быть представлены с помощью диаграммы ER.
сущность
Сущности представлены с помощью прямоугольников. Прямоугольники именуются набором сущностей, который они представляют.

Атрибуты
Атрибуты являются свойствами сущностей. Атрибуты представлены с помощью эллипсов. Каждый эллипс представляет один атрибут и напрямую связан с его сущностью (прямоугольником).
Если атрибуты составные , они далее делятся на древовидную структуру. Каждый узел затем подключается к своему атрибуту. То есть составные атрибуты представлены эллипсами, которые связаны с эллипсом.
Многозначные атрибуты изображены двойным эллипсом.
Производные атрибуты изображены пунктирным эллипсом.
отношения
Отношения представлены ромбовидной коробкой. Название отношений написано внутри алмазной коробки. Все сущности (прямоугольники), участвующие в отношениях, связаны с ней линией.
Бинарные отношения и мощность
Отношение, в котором участвуют два объекта, называется бинарным отношением . Количество элементов – это число экземпляров объекта из отношения, которое может быть связано с отношением.
-
Один-к-одному – когда только один экземпляр объекта связан с отношением, он помечается как «1: 1». На следующем рисунке показано, что только один экземпляр каждого объекта должен быть связан с отношением. Он изображает отношения один-к-одному.
-
Один-ко-многим – когда более чем один экземпляр объекта связан с отношением, он помечается как «1: N». На следующем рисунке показано, что только один экземпляр объекта слева и более одного экземпляра объекта справа могут быть связаны с отношением. Он изображает отношения один ко многим.
-
Много-к-одному – когда с отношением связано более одного экземпляра объекта, оно помечается как «N: 1». На следующем рисунке показано, что более одного экземпляра объекта слева и только один экземпляр объекта справа могут быть связаны с отношением. Он изображает отношения многие-к-одному.
-
Многие ко многим – следующее изображение отражает то, что с этим отношением может быть связано более одного экземпляра объекта слева и более одного экземпляра объекта справа. Он изображает отношения многих ко многим.
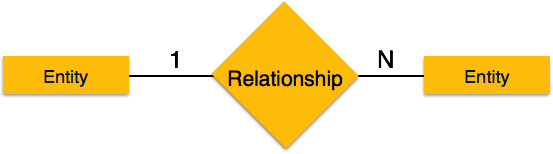
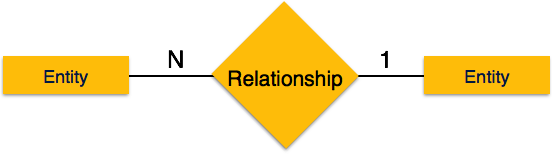
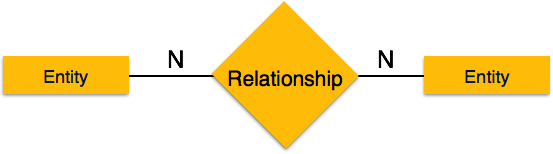
Один-к-одному – когда только один экземпляр объекта связан с отношением, он помечается как «1: 1». На следующем рисунке показано, что только один экземпляр каждого объекта должен быть связан с отношением. Он изображает отношения один-к-одному.
Один-ко-многим – когда более чем один экземпляр объекта связан с отношением, он помечается как «1: N». На следующем рисунке показано, что только один экземпляр объекта слева и более одного экземпляра объекта справа могут быть связаны с отношением. Он изображает отношения один ко многим.
Много-к-одному – когда с отношением связано более одного экземпляра объекта, оно помечается как «N: 1». На следующем рисунке показано, что более одного экземпляра объекта слева и только один экземпляр объекта справа могут быть связаны с отношением. Он изображает отношения многие-к-одному.
Многие ко многим – следующее изображение отражает то, что с этим отношением может быть связано более одного экземпляра объекта слева и более одного экземпляра объекта справа. Он изображает отношения многих ко многим.
Ограничения участия
-
Общее участие – каждая организация участвует в отношениях. Общее участие представлено двойными линиями.
-
Частичное участие – не все лица вовлечены в отношения. Частичное участие представлено отдельными строчками.
Общее участие – каждая организация участвует в отношениях. Общее участие представлено двойными линиями.
Частичное участие – не все лица вовлечены в отношения. Частичное участие представлено отдельными строчками.
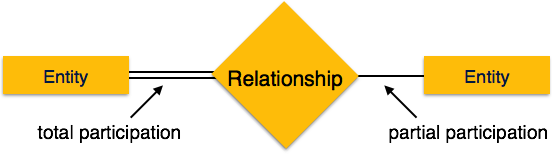
Генерализация Агрегация
Модель ER обладает способностью выражать сущности базы данных в концептуальной иерархической манере. Когда иерархия повышается, она обобщает представление о сущностях, а когда мы углубляемся в иерархию, она дает нам детали каждой включенной сущности.
Подъем в эту структуру называется обобщением , когда сущности объединяются, чтобы представить более обобщенное представление. Например, конкретного ученика по имени Мира можно обобщить вместе со всеми учениками. Субъект должен быть студентом, и далее студент является человеком. Обратное называется специализацией, где человек – студент, а этот студент – Мира.
Обобщение
Как упомянуто выше, процесс обобщения сущностей, где обобщенные сущности содержат свойства всех обобщенных сущностей, называется обобщением. В общем, несколько объектов объединяются в один обобщенный объект на основе их сходных характеристик. Например, голубь, воробей, ворона и голубь могут быть обобщены как птицы.

специализация
Специализация противоположна обобщению. По специализации группа субъектов делится на подгруппы в зависимости от их характеристик. Возьмем, к примеру, группу «Персона». У человека есть имя, дата рождения, пол и т. Д. Эти свойства являются общими для всех людей, людей. Но в компании люди могут быть определены как работник, работодатель, клиент или продавец, в зависимости от того, какую роль они играют в компании.
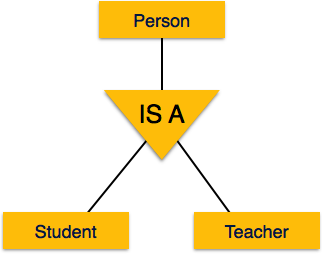
Аналогичным образом, в базе данных школы люди могут быть специализированы как учитель, ученик или персонал, в зависимости от того, какую роль они играют в школе как субъекты.
наследование
Мы используем все вышеперечисленные возможности ER-модели для создания классов объектов в объектно-ориентированном программировании. Детали сущностей обычно скрыты от пользователя; этот процесс известен как абстракция .
Наследование является важной особенностью обобщения и специализации. Это позволяет объектам более низкого уровня наследовать атрибуты объектов более высокого уровня.
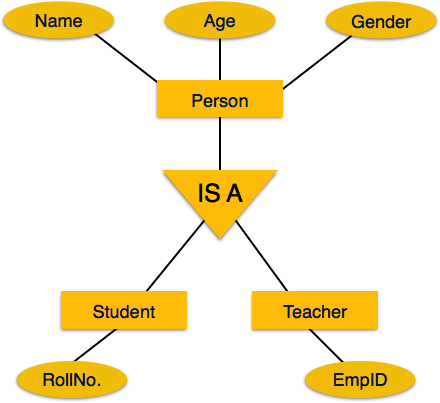
Например, атрибуты класса Person, такие как имя, возраст и пол, могут наследоваться объектами более низкого уровня, такими как ученик или учитель.
12 правил Кодда
Д-р Эдгар Ф. Кодд, после своего обширного исследования реляционной модели систем баз данных, разработал двенадцать собственных правил, которые, по его мнению, должны подчиняться базе данных, чтобы считаться истинной реляционной базой данных.
Эти правила могут применяться в любой системе баз данных, которая управляет сохраненными данными, используя только свои реляционные возможности. Это базовое правило, которое служит основой для всех остальных правил.
Правило 1: Информационное Правило
Данные, хранящиеся в базе данных, могут быть пользовательские данные или метаданные, должны быть значением некоторой ячейки таблицы. Все в базе данных должно храниться в табличном формате.
Правило 2: Правило гарантированного доступа
Каждый отдельный элемент данных (значение) гарантированно доступен логически с комбинацией имени таблицы, первичного ключа (значение строки) и имени атрибута (значение столбца). Никакие другие средства, такие как указатели, не могут быть использованы для доступа к данным.
Правило 3: Систематическое лечение значений NULL
Значения NULL в базе данных должны обрабатываться систематически и единообразно. Это очень важное правило, потому что NULL может интерпретироваться как одно из следующих: данные отсутствуют, данные неизвестны или данные неприменимы.
Правило 4: Активный онлайн-каталог
Описание структуры всей базы данных должно храниться в онлайн-каталоге, известном как словарь данных , к которому могут обращаться авторизованные пользователи. Пользователи могут использовать один и тот же язык запросов для доступа к каталогу, который они используют для доступа к самой базе данных.
Правило 5: Правило всеобъемлющего подъязыка данных
Доступ к базе данных возможен только с использованием языка, имеющего линейный синтаксис, который поддерживает определение данных, манипулирование данными и операции управления транзакциями. Этот язык можно использовать напрямую или с помощью какого-либо приложения. Если база данных разрешает доступ к данным без помощи этого языка, то это считается нарушением.
Правило 6: просмотр правила обновления
Все представления базы данных, которые теоретически могут быть обновлены, также должны обновляться системой.
Правило 7: правило высокого уровня для вставки, обновления и удаления
База данных должна поддерживать высокоуровневую вставку, обновление и удаление. Это не должно быть ограничено одной строкой, то есть оно также должно поддерживать операции объединения, пересечения и минуса для получения наборов записей данных.
Правило 8: физическая независимость данных
Данные, хранящиеся в базе данных, должны быть независимыми от приложений, которые обращаются к базе данных. Любые изменения в физической структуре базы данных не должны влиять на доступ к данным со стороны внешних приложений.
Правило 9: логическая независимость данных
Логические данные в базе данных должны быть независимы от представления пользователя (приложения). Любые изменения в логических данных не должны влиять на приложения, использующие их. Например, если две таблицы объединены или одна разбита на две разные таблицы, это не должно повлиять или изменить пользовательское приложение. Это одно из самых сложных правил для применения.
Правило 10: Честность Независимость
База данных должна быть независимой от приложения, которое ее использует. Все ограничения целостности могут быть независимо изменены без каких-либо изменений в приложении. Это правило делает базу данных независимой от интерфейсного приложения и его интерфейса.
Правило 11: Независимость распределения
Конечный пользователь не должен видеть, что данные распределены по разным местам. У пользователей всегда должно быть впечатление, что данные расположены только на одном сайте. Это правило считается основой распределенных систем баз данных.
Правило 12: Правило без подрывной деятельности
Если в системе имеется интерфейс, обеспечивающий доступ к записям низкого уровня, то интерфейс не должен быть способен подорвать систему и обойти ограничения безопасности и целостности.
Модель данных отношений
Реляционная модель данных является основной моделью данных, которая широко используется во всем мире для хранения и обработки данных. Эта модель проста и обладает всеми свойствами и возможностями, необходимыми для обработки данных с эффективностью хранения.
Концепции
Таблицы. В реляционной модели данных отношения сохраняются в формате таблиц. Этот формат хранит отношения между сущностями. В таблице есть строки и столбцы, где строки представляют записи, а столбцы представляют атрибуты.
Кортеж – одна строка таблицы, которая содержит одну запись для этого отношения, называется кортежем.
Экземпляр отношения – конечный набор кортежей в системе реляционной базы данных представляет экземпляр отношения. Экземпляры отношений не имеют повторяющихся кортежей.
Схема отношений – схема отношений описывает имя отношения (имя таблицы), атрибуты и их имена.
Ключ отношения – каждая строка имеет один или несколько атрибутов, известных как ключ отношения, которые могут однозначно идентифицировать строку в отношении (таблице).
Домен атрибута – каждый атрибут имеет некоторую предопределенную область значений, известную как домен атрибута.
Ограничения
Каждое отношение имеет некоторые условия, которые должны выполняться, чтобы оно было действительным. Эти условия называются ограничениями реляционной целостности . Есть три основных ограничения целостности –
- Ключевые ограничения
- Доменные ограничения
- Ограничения ссылочной целостности
Ключевые ограничения
В отношении должно быть хотя бы одно минимальное подмножество атрибутов, которое может однозначно идентифицировать кортеж. Это минимальное подмножество атрибутов называется ключом для этого отношения. Если существует более одного такого минимального подмножества, они называются ключами-кандидатами .
Ключевые ограничения заставляют это –
-
в отношении с ключевым атрибутом никакие два кортежа не могут иметь одинаковые значения для ключевых атрибутов.
-
ключевой атрибут не может иметь значения NULL.
в отношении с ключевым атрибутом никакие два кортежа не могут иметь одинаковые значения для ключевых атрибутов.
ключевой атрибут не может иметь значения NULL.
Ключевые ограничения также называются сущностными ограничениями.
Ограничения домена
Атрибуты имеют конкретные значения в реальном сценарии. Например, возраст может быть только положительным целым числом. Те же ограничения пытались использовать для атрибутов отношения. Каждый атрибут должен иметь определенный диапазон значений. Например, возраст не может быть меньше нуля, а телефонные номера не могут содержать цифры за пределами 0-9.
Ограничения ссылочной целостности
Ограничения ссылочной целостности работают над концепцией внешних ключей. Внешний ключ – это ключевой атрибут отношения, на который можно ссылаться в другом отношении.
Ограничение ссылочной целостности гласит, что если отношение ссылается на ключевой атрибут другого или того же отношения, то этот ключевой элемент должен существовать.
Реляционная алгебра
Предполагается, что реляционные системы баз данных будут оснащены языком запросов, который поможет пользователям запрашивать экземпляры базы данных. Существует два вида языков запросов – реляционная алгебра и реляционное исчисление.
Реляционная алгебра
Реляционная алгебра – это процедурный язык запросов, который принимает экземпляры отношений в качестве входных данных и выдает экземпляры отношений в качестве выходных. Он использует операторы для выполнения запросов. Оператор может быть как унарным, так и двоичным . Они принимают отношения как свой вклад и дают отношения как свой выход. Реляционная алгебра выполняется рекурсивно в отношении, и промежуточные результаты также считаются отношениями.
Основные операции реляционной алгебры следующие:
- Выбрать
- проект
- союз
- Установить разные
- Декартово произведение
- переименовывать
Мы обсудим все эти операции в следующих разделах.
Выберите операцию (σ)
Он выбирает кортежи, которые удовлетворяют данному предикату из отношения.
Обозначение – σ p (r)
Где σ обозначает предикат выбора, а r обозначает отношение. p – логическая формула предложения, которая может использовать соединители, такие как и, или, и нет . В этих терминах могут использоваться реляционные операторы, такие как – =, ≠, ≥, <,>, ≤.
Например –
σ subject="database" (Books)
σ subject=”database” (Books)
Вывод – выбирает кортежи из книг, предметом которых является «база данных».
σ subject="database" and price="450" (Books)
σ subject=”database” and price=”450″ (Books)
Вывод – выбирает кортежи из книг, где предметом является «база данных», а «цена» – 450.
σ subject="database" and price < "450" or year > "2010" (Books)
σ subject=”database” and price < “450” or year > “2010” (Books)
Выходные данные – выбирает кортежи из книг, где предметом является «база данных», а «цена» составляет 450, или тех книг, которые были опубликованы после 2010 года.
Операция проекта (∏)
Он проецирует столбцы, которые удовлетворяют данному предикату.
Обозначения – ∏ A 1 , A 2 , A n (r)
Где A 1 , A 2 , A n являются именами атрибутов отношения r .
Дублирующиеся строки автоматически удаляются, так как отношение является множеством.
Например –
∏ subject, author (Books)
∏ subject, author (Books)
Выбирает и проецирует столбцы, названные как субъект и автор из книги отношений.
Союз Операция (∪)
Он выполняет двоичное соединение между двумя данными отношениями и определяется как –
r ∪ s = { t | t ∈ r or t ∈ s}
r ∪ s = { t | t ∈ r or t ∈ s}
Обозначения – r U s
Где r и s – это либо отношения базы данных, либо набор результатов отношений (временное отношение).
Чтобы операция объединения была действительной, должны выполняться следующие условия:
- r и s должны иметь одинаковое количество атрибутов.
- Домены атрибутов должны быть совместимы.
- Дублирующиеся кортежи автоматически удаляются.
∏ author (Books) ∪ ∏ author (Articles)
∏ author (Books) ∪ ∏ author (Articles)
Вывод – проецирует имена авторов, написавших книгу, статью или обоих.
Установить разницу (-)
Результатом операции установки разности являются кортежи, которые присутствуют в одном отношении, но не во втором.
Обозначения – r – s
Находит все кортежи, которые присутствуют в r, но не в s .
∏ author (Books) − ∏ author (Articles)
∏ author (Books) − ∏ author (Articles)
Вывод – содержит имена авторов, которые написали книги, но не статьи.
Декартово произведение (Χ)
Объединяет информацию двух разных отношений в одно.
Обозначение – r Χ s
Где r и s – отношения, и их выходные данные будут определены как –
r Χ s = {qt | q ∈ r и t ∈ s}
∏ author = 'tutorialspoint' (Books Χ Articles)
∏ author = ‘tutorialspoint’ (Books Χ Articles)
Выходные данные – возвращает отношение, которое показывает все книги и статьи, написанные tutorialspoint.
Переименовать операцию (ρ)
Результаты реляционной алгебры также являются отношениями, но без какого-либо имени. Операция переименования позволяет нам переименовать выходное отношение. Операция переименования обозначается маленькой греческой буквой rho .
Обозначение – ρ x (E)
Где результат выражения E сохраняется с именем x .
Дополнительные операции –
- Установить пересечение
- присваивание
- Естественное соединение
Реляционное исчисление
В отличие от реляционной алгебры, реляционное исчисление – это непроцедурный язык запросов, то есть он говорит, что делать, но никогда не объясняет, как это сделать.
Реляционное исчисление существует в двух формах –
Реляционное исчисление кортежей (TRC)
Фильтрация диапазонов переменных по кортежам
Обозначение – {T | Состояние}
Возвращает все кортежи T, которые удовлетворяют условию.
Например –
{ T.name | Author(T) AND T.article = 'database' }
Выходные данные – возвращает кортежи с именем name от автора, который написал статью о «базе данных».
TRC может быть определена количественно. Мы можем использовать Existential (∃) и Universal Quantifiers (∀).
Например –
{ R| ∃T ∈ Authors(T.article='database' AND R.name=T.name)}
Вывод. Приведенный выше запрос даст тот же результат, что и предыдущий.
Доменное реляционное исчисление (DRC)
В DRC фильтрующая переменная использует область атрибутов вместо целых значений кортежа (как сделано в TRC, упомянутом выше).
Запись –
{a 1 , a 2 , a 3 , …, a n | P (a 1 , a 2 , a 3 , …, a n )}
Где a1, a2 – атрибуты, а P – формулы, построенные из внутренних атрибутов.
Например –
{< article, page, subject > |
∈ TutorialsPoint ∧ subject = 'database'}
{< article, page, subject > |
Выходные данные – возвращает статью, страницу и тему из отношения TutorialsPoint, где тема – это база данных.
Как и TRC, DRC также может быть записан с использованием экзистенциальных и универсальных квантификаторов. В DRC также участвуют реляционные операторы.
Выражение силы Tuple Relation Calculus и Domain Relation Calculus эквивалентно реляционной алгебре.
ER модель для реляционной модели
Модель ER, представленная в виде диаграмм, дает хороший обзор взаимоотношений сущностей, который легче понять. ER-диаграммы могут быть сопоставлены с реляционной схемой, то есть можно создать реляционную схему, используя ER-диаграмму. Мы не можем импортировать все ограничения ER в реляционную модель, но можно создать приблизительную схему.
Есть несколько процессов и алгоритмов, доступных для преобразования ER-диаграмм в реляционную схему. Некоторые из них автоматизированы, а некоторые – ручные. Мы можем сосредоточиться здесь на отображении содержимого схемы на реляционные основы.
Диаграммы ER в основном состоят из –
- Сущность и ее атрибуты
- Отношения, которые являются ассоциацией между сущностями.
Картографическая сущность
Сущность – это объект реального мира с некоторыми атрибутами.
Процесс картирования (алгоритм)
- Создать таблицу для каждой сущности.
- Атрибуты объекта должны стать полями таблиц с соответствующими типами данных.
- Объявите первичный ключ.
Картографическая связь
Отношения – это ассоциация между сущностями.
Процесс картирования
- Создать таблицу для отношений.
- Добавьте первичные ключи всех участвующих сущностей в виде полей таблицы с соответствующими им типами данных.
- Если отношение имеет какой-либо атрибут, добавьте каждый атрибут в качестве поля таблицы.
- Объявите первичный ключ, составляющий все первичные ключи участвующих субъектов.
- Объявите все ограничения внешнего ключа.
Отображение слабых наборов сущностей
Слабым набором сущностей является тот, который не имеет никакого первичного ключа, связанного с ним.
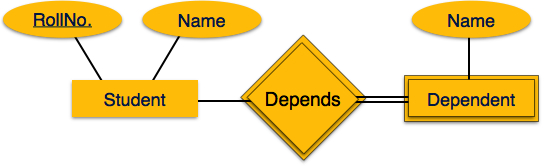
Процесс картирования
- Создать таблицу для набора слабых сущностей.
- Добавьте все его атрибуты в таблицу как поле.
- Добавьте первичный ключ идентифицирующего набора сущностей.
- Объявите все ограничения внешнего ключа.
Отображение иерархических объектов
ER специализация или обобщение происходит в форме иерархических наборов сущностей.
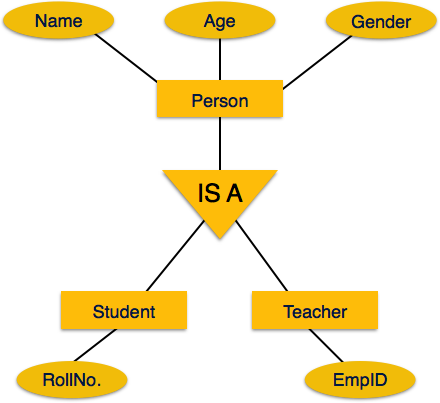
Процесс картирования
-
Создать таблицы для всех объектов более высокого уровня.
-
Создайте таблицы для объектов более низкого уровня.
-
Добавьте первичные ключи объектов более высокого уровня в таблицу объектов более низкого уровня.
-
В таблицах нижнего уровня добавьте все остальные атрибуты сущностей нижнего уровня.
-
Объявите первичный ключ таблицы более высокого уровня и первичный ключ таблицы более низкого уровня.
-
Объявите ограничения внешнего ключа.
Создать таблицы для всех объектов более высокого уровня.
Создайте таблицы для объектов более низкого уровня.
Добавьте первичные ключи объектов более высокого уровня в таблицу объектов более низкого уровня.
В таблицах нижнего уровня добавьте все остальные атрибуты сущностей нижнего уровня.
Объявите первичный ключ таблицы более высокого уровня и первичный ключ таблицы более низкого уровня.
Объявите ограничения внешнего ключа.
Обзор SQL
SQL – это язык программирования для реляционных баз данных. Он разработан на основе реляционной алгебры и кортежного реляционного исчисления. SQL поставляется в виде пакета со всеми основными дистрибутивами RDBMS.
SQL включает в себя как определения данных, так и языки манипулирования данными. Используя свойства определения данных SQL, можно проектировать и модифицировать схему базы данных, тогда как свойства манипулирования данными позволяют SQL хранить и извлекать данные из базы данных.
Язык определения данных
SQL использует следующий набор команд для определения схемы базы данных –
СОЗДАЙТЕ
Создает новые базы данных, таблицы и представления из RDBMS.
Например –
Create database tutorialspoint; Create table article; Create view for_students;
DROP
Удаляет команды, представления, таблицы и базы данных из RDBMS.
Например –
Drop object_type object_name; Drop database tutorialspoint; Drop table article; Drop view for_students;
ALTER
Изменяет схему базы данных.
Alter object_type object_name parameters;
Например –
Alter table article add subject varchar;
Эта команда добавляет атрибут в статью отношений с именем субъекта строкового типа.
Язык манипулирования данными
SQL оснащен языком манипулирования данными (DML). DML изменяет экземпляр базы данных, вставляя, обновляя и удаляя ее данные. DML отвечает за изменение данных всех форм в базе данных. SQL содержит следующий набор команд в своем разделе DML –
- SELECT / FROM / WHERE
- INSERT INTO / VALUES
- UPDATE / SET / WHERE
- УДАЛИТЬ ИЗ / ГДЕ
Эти базовые конструкции позволяют программистам и пользователям баз данных вводить данные и информацию в базу данных и эффективно извлекать их с использованием ряда параметров фильтра.
SELECT / FROM / WHERE
-
SELECT – это одна из основных команд запроса SQL. Это похоже на операцию проекции реляционной алгебры. Он выбирает атрибуты на основе условия, описанного предложением WHERE.
-
FROM – это предложение принимает имя отношения в качестве аргумента, из которого должны быть выбраны / спроектированы атрибуты. Если дано более одного имени отношения, этот пункт соответствует декартовому произведению.
-
WHERE – этот пункт определяет предикат или условия, которые должны совпадать, чтобы квалифицировать атрибуты, которые должны быть спроецированы.
SELECT – это одна из основных команд запроса SQL. Это похоже на операцию проекции реляционной алгебры. Он выбирает атрибуты на основе условия, описанного предложением WHERE.
FROM – это предложение принимает имя отношения в качестве аргумента, из которого должны быть выбраны / спроектированы атрибуты. Если дано более одного имени отношения, этот пункт соответствует декартовому произведению.
WHERE – этот пункт определяет предикат или условия, которые должны совпадать, чтобы квалифицировать атрибуты, которые должны быть спроецированы.
Например –
Select author_name From book_author Where age > 50;
Эта команда выдаст имена авторов из отношения book_author, чей возраст превышает 50.
INSERT INTO / VALUES
Эта команда используется для вставки значений в строки таблицы (отношения).
Синтаксис –
INSERT INTO table (column1 [, column2, column3 ... ]) VALUES (value1 [, value2, value3 ... ])
Или же
INSERT INTO table VALUES (value1, [value2, ... ])
Например –
INSERT INTO tutorialspoint (Author, Subject) VALUES ("anonymous", "computers");
UPDATE / SET / WHERE
Эта команда используется для обновления или изменения значений столбцов в таблице (отношение).
Синтаксис –
UPDATE table_name SET column_name = value [, column_name = value ...] [WHERE condition]
Например –
UPDATE tutorialspoint SET Author="webmaster" WHERE Author="anonymous";
DELETE / ОТ / ГДЕ
Эта команда используется для удаления одной или нескольких строк из таблицы (отношения).
Синтаксис –
DELETE FROM table_name [WHERE condition];
Например –
DELETE FROM tutorialspoints WHERE Author="unknown";
СУБД – нормализация
Функциональная зависимость
Функциональная зависимость (FD) – это набор ограничений между двумя атрибутами в отношении. Функциональная зависимость говорит, что если два кортежа имеют одинаковые значения для атрибутов A1, A2, …, An, то эти два кортежа должны иметь одинаковые значения для атрибутов B1, B2, …, Bn.
Функциональная зависимость представлена знаком стрелки (→), то есть X → Y, где X функционально определяет Y. Атрибуты левой стороны определяют значения атрибутов с правой стороны.
Аксиомы Армстронга
Если F представляет собой набор функциональных зависимостей, то замыкание F, обозначаемое как F + , представляет собой набор всех функциональных зависимостей, логически подразумеваемых F. Аксиомы Армстронга представляют собой набор правил, которые при многократном применении генерируют замыкание функциональных зависимостей. ,
-
Правило рефлексии – если альфа является набором атрибутов и бета-версией is_subset_of альфа, то альфа содержит бета-версию.
-
Правило аугментации – если a → b выполнено, а y является установленным атрибутом, то также выполняется ay → by. То есть добавление атрибутов в зависимости не меняет основных зависимостей.
-
Правило транзитивности – То же самое, что и транзитивное правило в алгебре, если выполняется a → b и b → c, то также выполняется a → c. a → b называется функционально определяющим b.
Правило рефлексии – если альфа является набором атрибутов и бета-версией is_subset_of альфа, то альфа содержит бета-версию.
Правило аугментации – если a → b выполнено, а y является установленным атрибутом, то также выполняется ay → by. То есть добавление атрибутов в зависимости не меняет основных зависимостей.
Правило транзитивности – То же самое, что и транзитивное правило в алгебре, если выполняется a → b и b → c, то также выполняется a → c. a → b называется функционально определяющим b.
Тривиальная функциональная зависимость
-
Trivial – если выполняется функциональная зависимость (FD) X → Y, где Y – подмножество X, то она называется тривиальной FD. Тривиальные ФД всегда держатся.
-
Нетривиальный. Если выполняется FD X → Y, где Y не является подмножеством X, то он называется нетривиальным FD.
-
Полностью нетривиальный – если выполняется FD X → Y, где x пересекается с Y = Φ, он называется совершенно нетривиальным FD.
Trivial – если выполняется функциональная зависимость (FD) X → Y, где Y – подмножество X, то она называется тривиальной FD. Тривиальные ФД всегда держатся.
Нетривиальный. Если выполняется FD X → Y, где Y не является подмножеством X, то он называется нетривиальным FD.
Полностью нетривиальный – если выполняется FD X → Y, где x пересекается с Y = Φ, он называется совершенно нетривиальным FD.
нормализация
Если дизайн базы данных не идеален, он может содержать аномалии, которые кажутся плохим сном для любого администратора базы данных. Управление базой данных с аномалиями практически невозможно.
-
Обновление аномалий – если элементы данных разбросаны и не связаны должным образом друг с другом, это может привести к странным ситуациям. Например, когда мы пытаемся обновить один элемент данных, копии которого разбросаны по нескольким местам, несколько экземпляров обновляются должным образом, а несколько других остаются со старыми значениями. Такие экземпляры оставляют базу данных в несогласованном состоянии.
-
Аномалии удаления – мы пытались удалить запись, но ее части остались неосознанными из-за неосведомленности, данные также сохраняются в другом месте.
-
Вставить аномалии – мы попытались вставить данные в запись, которая вообще не существует.
Обновление аномалий – если элементы данных разбросаны и не связаны должным образом друг с другом, это может привести к странным ситуациям. Например, когда мы пытаемся обновить один элемент данных, копии которого разбросаны по нескольким местам, несколько экземпляров обновляются должным образом, а несколько других остаются со старыми значениями. Такие экземпляры оставляют базу данных в несогласованном состоянии.
Аномалии удаления – мы пытались удалить запись, но ее части остались неосознанными из-за неосведомленности, данные также сохраняются в другом месте.
Вставить аномалии – мы попытались вставить данные в запись, которая вообще не существует.
Нормализация – это метод устранения всех этих аномалий и приведения базы данных в согласованное состояние.
Первая нормальная форма
Первая нормальная форма определяется в определении самих отношений (таблиц). Это правило определяет, что все атрибуты в отношении должны иметь атомарные домены. Значения в атомной области являются неделимыми единицами.
Мы переупорядочиваем отношение (таблицу), как показано ниже, чтобы преобразовать его в первую нормальную форму.
Каждый атрибут должен содержать только одно значение из своего предварительно определенного домена.
Вторая нормальная форма
Прежде чем мы узнаем о второй нормальной форме, мы должны понять следующее –
-
Основной атрибут . Атрибут, являющийся частью ключа-кандидата, называется основным атрибутом.
-
Непростой атрибут . Атрибут, который не является частью простого ключа, называется непростым атрибутом.
Основной атрибут . Атрибут, являющийся частью ключа-кандидата, называется основным атрибутом.
Непростой атрибут . Атрибут, который не является частью простого ключа, называется непростым атрибутом.
Если мы следуем второй нормальной форме, то каждый непростой атрибут должен полностью функционально зависеть от атрибута первичного ключа. То есть, если X → A выполнено, то не должно быть никакого собственного подмножества Y в X, для которого Y → A также верно.
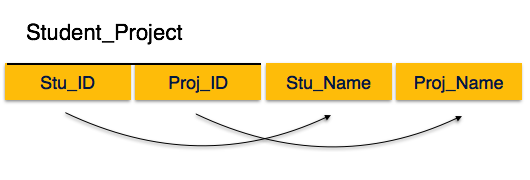
Здесь мы видим в отношении Student_Project, что атрибутами простого ключа являются Stu_ID и Proj_ID. В соответствии с правилом неключевые атрибуты, то есть Stu_Name и Proj_Name, должны зависеть от обоих, а не от какого-либо отдельного атрибута первичного ключа. Но мы обнаруживаем, что Stu_Name может быть идентифицировано Stu_ID, а Proj_Name может быть идентифицировано Proj_ID независимо. Это называется частичной зависимостью , которая не допускается во второй нормальной форме.
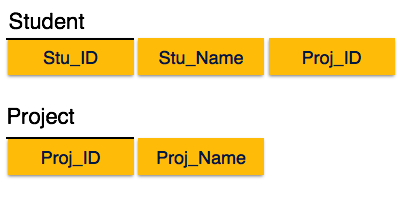
Мы разорвали отношения на две части, как показано на картинке выше. Таким образом, не существует частичной зависимости.
Третья нормальная форма
Чтобы отношение было в третьей нормальной форме, оно должно быть во второй нормальной форме, а следующее должно удовлетворять:
- Ни один не простой атрибут не является транзитивно зависимым от атрибута простого ключа.
- Для любой нетривиальной функциональной зависимости X → A, тогда либо –
- Х это суперключ или,
- А является основным атрибутом.

Мы обнаруживаем, что в приведенном выше отношении Student_detail Stu_ID является ключевым и единственным атрибутом простого ключа. Мы находим, что Город может быть идентифицирован как Stu_ID, так и самим Zip. Ни Zip не является суперключем, ни City не является главным атрибутом. Кроме того, Stu_ID → Zip → City, поэтому существует транзитивная зависимость .
Чтобы привести это отношение в третью нормальную форму, мы разбиваем отношение на два отношения следующим образом:
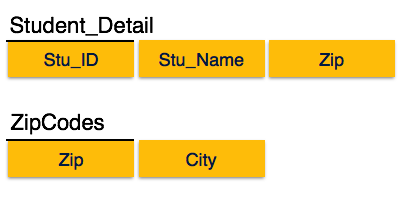
Бойс-Кодд Нормальная форма
Нормальная форма Бойса-Кодда (BCNF) является продолжением третьей нормальной формы на строгих условиях. BCNF заявляет, что –
- Для любой нетривиальной функциональной зависимости X → A, X должен быть суперключом.
На изображении выше Stu_ID – это супер-ключ в отношении Student_Detail, а Zip – это супер-ключ в отношении ZipCodes. Так,
Stu_ID → Stu_Name, Zip
а также
Zip → Город
Что подтверждает, что оба отношения находятся в BCNF.
СУБД – Объединения
Мы понимаем преимущества взятия декартова произведения двух отношений, что дает нам все возможные кортежи, соединенные вместе. Но в некоторых случаях для нас может оказаться невозможным взять декартово произведение, где мы сталкиваемся с огромными отношениями с тысячами кортежей, имеющих значительное количество атрибутов.
Join – это комбинация декартового произведения, за которым следует процесс выбора. Операция Join объединяет два кортежа из разных отношений, если и только если удовлетворяется заданное условие соединения.
Мы кратко опишем различные типы соединений в следующих разделах.
Тета (θ) Присоединиться
Тета-соединение объединяет кортежи из разных отношений при условии, что они удовлетворяют условию тета. Условие соединения обозначается символом θ .
нотация
R1 ⋈ θ R2
R1 и R2 являются отношениями, имеющими атрибуты (A1, A2, .., An) и (B1, B2, .., Bn), так что атрибуты не имеют ничего общего, то есть R1 ∩ R2 = Φ.
Тета-соединение может использовать все виды операторов сравнения.
| Ученик | ||
|---|---|---|
| SID | название | Std |
| 101 | Alex | 10 |
| 102 | Мария | 11 |
| Предметы | |
|---|---|
| Учебный класс | Предмет |
| 10 | математический |
| 10 | английский |
| 11 | Музыка |
| 11 | Спортивный |
Student_Detail =
STUDENT ⋈ Student.Std = Subject.Class SUBJECT
| Student_detail | ||||
|---|---|---|---|---|
| SID | название | Std | Учебный класс | Предмет |
| 101 | Alex | 10 | 10 | математический |
| 101 | Alex | 10 | 10 | английский |
| 102 | Мария | 11 | 11 | Музыка |
| 102 | Мария | 11 | 11 | Спортивный |
эквисоединения
Когда соединение Theta использует только оператор сравнения на равенство , оно называется equijoin. Приведенный выше пример соответствует equijoin.
Естественное соединение ( ⋈ )
Естественное объединение не использует оператор сравнения. Он не объединяет способ декартовых произведений. Мы можем выполнить естественное соединение, только если между двумя отношениями существует хотя бы один общий атрибут. Кроме того, атрибуты должны иметь одинаковые имя и домен.
Естественное объединение действует для тех совпадающих атрибутов, где значения атрибутов в обоих отношениях одинаковы.
| Курсы | ||
|---|---|---|
| ИДС | Курс | Отдел |
| CS01 | База данных | CS |
| ME01 | механика | МНЕ |
| EE01 | электроника | EE |
| HoD | |
|---|---|
| Отдел | Голова |
| CS | Alex |
| МНЕ | майя |
| EE | Мир |
| Курсы ⋈ HoD | |||
|---|---|---|---|
| Отдел | ИДС | Курс | Голова |
| CS | CS01 | База данных | Alex |
| МНЕ | ME01 | механика | майя |
| EE | EE01 | электроника | Мир |
Внешние соединения
Theta Join, Equijoin и Natural Join называются внутренними объединениями. Внутреннее объединение включает только те кортежи с соответствующими атрибутами, а остальные отбрасываются в результирующем отношении. Поэтому нам нужно использовать внешние объединения, чтобы включить все кортежи из участвующих отношений в результирующее отношение. Существует три вида внешних объединений – левое внешнее соединение, правое внешнее соединение и полное внешнее соединение.
Левое внешнее соединение (R  S)
S)
Все кортежи из отношения Left, R, включены в результирующее отношение. Если в R есть кортежи без соответствующих кортежей в правом отношении S, то S-атрибуты результирующего отношения становятся равными NULL.
| Оставил | |
|---|---|
| В | |
| 100 | База данных |
| 101 | механика |
| 102 | электроника |
| Правильно | |
|---|---|
| В | |
| 100 | Alex |
| 102 | майя |
| 104 | Мир |
| Курсы |
|||
|---|---|---|---|
| В | С | D | |
| 100 | База данных | 100 | Alex |
| 101 | механика | — | — |
| 102 | электроника | 102 | майя |
Правое внешнее соединение: (R  S)
S)
Все кортежи из отношения Right, S, включены в результирующее отношение. Если в S есть кортежи без соответствующих кортежей в R, то R-атрибуты результирующего отношения становятся равными NULL.
| Курсы |
|||
|---|---|---|---|
| В | С | D | |
| 100 | База данных | 100 | Alex |
| 102 | электроника | 102 | майя |
| — | — | 104 | Мир |
Полное внешнее соединение: (R  S)
S)
Все кортежи из обоих участвующих отношений включены в результирующее отношение. Если для обоих отношений нет соответствующих кортежей, их соответствующие несопоставленные атрибуты становятся равными NULL.
| Курсы |
|||
|---|---|---|---|
| В | С | D | |
| 100 | База данных | 100 | Alex |
| 101 | механика | — | — |
| 102 | электроника | 102 | майя |
| — | — | 104 | Мир |
СУБД – Система хранения
Базы данных хранятся в файловых форматах, которые содержат записи. На физическом уровне фактические данные хранятся в электромагнитном формате на каком-либо устройстве. Эти запоминающие устройства можно разделить на три типа:

-
Основное хранилище – хранилище памяти, которое напрямую доступно ЦПУ, относится к этой категории. Внутренняя память ЦП (регистры), быстрая память (кэш) и основная память (ОЗУ) напрямую доступны для ЦП, поскольку все они размещены на материнской плате или чипсете ЦП. Это хранилище обычно очень маленькое, сверхбыстрое и нестабильное. Первичное хранилище требует постоянного источника питания, чтобы поддерживать его состояние. В случае сбоя питания все его данные теряются.
-
Вторичное хранилище – Вторичные устройства хранения используются для хранения данных для будущего использования или в качестве резервной копии. Вторичное хранилище включает в себя устройства памяти, которые не являются частью набора микросхем ЦП или материнской платы, например магнитные диски, оптические диски (DVD, CD и т. Д.), Жесткие диски, флэш-накопители и магнитные ленты.
-
Третичное хранилище – Третичное хранилище используется для хранения огромных объемов данных. Поскольку такие запоминающие устройства являются внешними по отношению к компьютерной системе, они являются самыми медленными по скорости. Эти устройства хранения в основном используются для резервного копирования всей системы. Оптические диски и магнитные ленты широко используются в качестве третичного хранилища.
Основное хранилище – хранилище памяти, которое напрямую доступно ЦПУ, относится к этой категории. Внутренняя память ЦП (регистры), быстрая память (кэш) и основная память (ОЗУ) напрямую доступны для ЦП, поскольку все они размещены на материнской плате или чипсете ЦП. Это хранилище обычно очень маленькое, сверхбыстрое и нестабильное. Первичное хранилище требует постоянного источника питания, чтобы поддерживать его состояние. В случае сбоя питания все его данные теряются.
Вторичное хранилище – Вторичные устройства хранения используются для хранения данных для будущего использования или в качестве резервной копии. Вторичное хранилище включает в себя устройства памяти, которые не являются частью набора микросхем ЦП или материнской платы, например магнитные диски, оптические диски (DVD, CD и т. Д.), Жесткие диски, флэш-накопители и магнитные ленты.
Третичное хранилище – Третичное хранилище используется для хранения огромных объемов данных. Поскольку такие запоминающие устройства являются внешними по отношению к компьютерной системе, они являются самыми медленными по скорости. Эти устройства хранения в основном используются для резервного копирования всей системы. Оптические диски и магнитные ленты широко используются в качестве третичного хранилища.
Иерархия памяти
Компьютерная система имеет четко определенную иерархию памяти. Процессор имеет прямой доступ к основной памяти, а также к встроенным регистрам. Время доступа к основной памяти явно меньше скорости процессора. Чтобы минимизировать это несоответствие скорости, введена кэш-память. Кэш-память обеспечивает самое быстрое время доступа и содержит данные, к которым центральный процессор чаще всего обращается.
Память с самым быстрым доступом является самой дорогой. Большие устройства хранения данных предлагают низкую скорость и дешевле, однако они могут хранить огромные объемы данных по сравнению с регистрами ЦП или кэш-памятью.
Магнитные Диски
Жесткие диски являются наиболее распространенными вторичными устройствами хранения данных в современных компьютерных системах. Они называются магнитными дисками, потому что они используют концепцию намагничивания для хранения информации. Жесткие диски состоят из металлических дисков, покрытых намагничиваемым материалом. Эти диски расположены вертикально на шпинделе. Головка чтения / записи перемещается между дисками и используется для намагничивания или размагничивания пятна под ней. Намагниченное пятно может быть распознано как 0 (ноль) или 1 (один).
Жесткие диски отформатированы в четко определенном порядке для эффективного хранения данных. На пластине жесткого диска много концентрических кругов, называемых дорожками . Каждый трек далее делится на сектора . Сектор на жестком диске обычно хранит 512 байт данных.
RAID
RAID означает « R edundant» – « Множество независимых дисков», представляющих собой технологию подключения нескольких вторичных устройств хранения и использования их в качестве единого носителя.
RAID состоит из массива дисков, в которых несколько дисков соединены вместе для достижения разных целей. Уровни RAID определяют использование дисковых массивов.
-
RAID 0 – на этом уровне реализован чередующийся массив дисков. Данные разбиваются на блоки и блоки распределяются по дискам. Каждый диск получает блок данных для записи / чтения параллельно. Это увеличивает скорость и производительность устройства хранения. На уровне 0 нет четности и резервного копирования.
RAID 0 – на этом уровне реализован чередующийся массив дисков. Данные разбиваются на блоки и блоки распределяются по дискам. Каждый диск получает блок данных для записи / чтения параллельно. Это увеличивает скорость и производительность устройства хранения. На уровне 0 нет четности и резервного копирования.
-
RAID 1 – RAID 1 использует методы зеркалирования. Когда данные отправляются на контроллер RAID, он отправляет копию данных на все диски в массиве. Уровень RAID 1 также называется зеркалированием и обеспечивает 100% резервирование в случае сбоя.
RAID 1 – RAID 1 использует методы зеркалирования. Когда данные отправляются на контроллер RAID, он отправляет копию данных на все диски в массиве. Уровень RAID 1 также называется зеркалированием и обеспечивает 100% резервирование в случае сбоя.
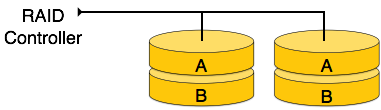
-
RAID 2 – RAID 2 записывает код исправления ошибок, используя расстояние Хемминга для своих данных, размеченных на разных дисках. Как и уровень 0, каждый бит данных в слове записывается на отдельный диск, а коды ECC слов данных хранятся на разных дисках. Из-за его сложной структуры и высокой стоимости, RAID 2 не доступен в продаже.
RAID 2 – RAID 2 записывает код исправления ошибок, используя расстояние Хемминга для своих данных, размеченных на разных дисках. Как и уровень 0, каждый бит данных в слове записывается на отдельный диск, а коды ECC слов данных хранятся на разных дисках. Из-за его сложной структуры и высокой стоимости, RAID 2 не доступен в продаже.
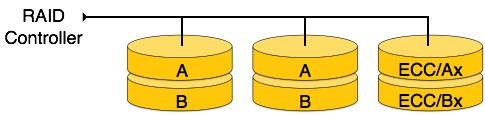
-
RAID 3 – RAID 3 чередует данные на нескольких дисках. Бит четности, сгенерированный для слова данных, хранится на другом диске. Этот метод позволяет преодолеть сбои в работе одного диска.
RAID 3 – RAID 3 чередует данные на нескольких дисках. Бит четности, сгенерированный для слова данных, хранится на другом диске. Этот метод позволяет преодолеть сбои в работе одного диска.
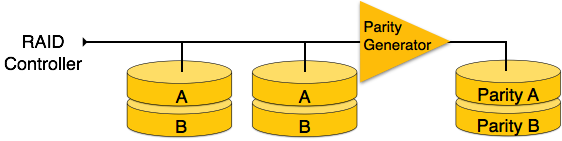
-
RAID 4 – на этом уровне весь блок данных записывается на диски данных, а затем генерируется четность и сохраняется на другом диске. Обратите внимание, что уровень 3 использует чередование на уровне байтов, тогда как уровень 4 использует чередование на уровне блоков. Как для уровня 3, так и для уровня 4 требуется как минимум три диска для реализации RAID.
RAID 4 – на этом уровне весь блок данных записывается на диски данных, а затем генерируется четность и сохраняется на другом диске. Обратите внимание, что уровень 3 использует чередование на уровне байтов, тогда как уровень 4 использует чередование на уровне блоков. Как для уровня 3, так и для уровня 4 требуется как минимум три диска для реализации RAID.
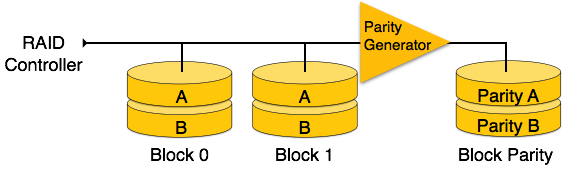
-
RAID 5 – RAID 5 записывает целые блоки данных на разные диски, но биты четности, генерируемые для полосы блоков данных, распределяются между всеми дисками данных, а не хранятся на другом выделенном диске.
RAID 5 – RAID 5 записывает целые блоки данных на разные диски, но биты четности, генерируемые для полосы блоков данных, распределяются между всеми дисками данных, а не хранятся на другом выделенном диске.
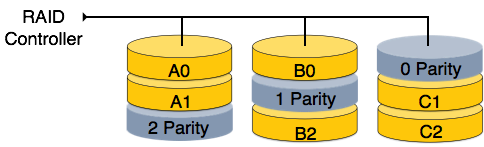
-
RAID 6 – RAID 6 является расширением уровня 5. На этом уровне два независимых контроля четности генерируются и хранятся распределенным образом среди нескольких дисков. Два соотношения обеспечивают дополнительную отказоустойчивость. Для этого уровня требуется как минимум четыре диска для реализации RAID.
RAID 6 – RAID 6 является расширением уровня 5. На этом уровне два независимых контроля четности генерируются и хранятся распределенным образом среди нескольких дисков. Два соотношения обеспечивают дополнительную отказоустойчивость. Для этого уровня требуется как минимум четыре диска для реализации RAID.
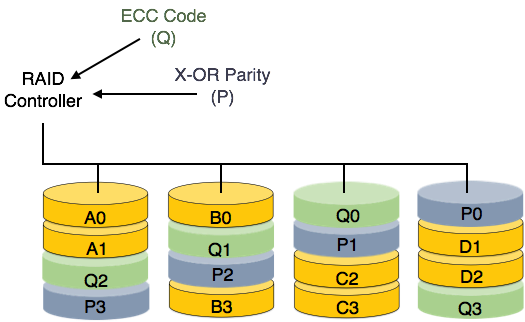
СУБД – Файловая структура
Относительные данные и информация хранятся вместе в форматах файлов. Файл представляет собой последовательность записей, хранящихся в двоичном формате. Диск отформатирован в несколько блоков, которые могут хранить записи. Файловые записи отображаются на эти блоки диска.
Организация файлов
Организация файлов определяет, как файловые записи отображаются на дисковые блоки. У нас есть четыре типа организации файлов для организации записей файлов –
Организация файлов кучи
Когда файл создается с помощью организации файлов кучи, операционная система выделяет область памяти для этого файла без каких-либо дополнительных учетных данных. Файловые записи могут быть размещены в любом месте этой области памяти. Ответственность за управление записями лежит на программном обеспечении. Heap File не поддерживает само упорядочение, последовательность или индексацию.
Последовательная организация файлов
Каждая запись файла содержит поле данных (атрибут), чтобы однозначно идентифицировать эту запись. При последовательной организации файлов записи помещаются в файл в некотором последовательном порядке на основе поля уникального ключа или ключа поиска. Практически невозможно хранить все записи последовательно в физической форме.
Организация хэш-файлов
Организация хеш-файлов использует вычисления хеш-функции в некоторых полях записей. Выходные данные хеш-функции определяют местоположение дискового блока, в который должны быть помещены записи.
Организация кластерных файлов
Организация кластерных файлов не считается хорошей для больших баз данных. В этом механизме связанные записи из одного или нескольких отношений хранятся в одном и том же блоке диска, то есть порядок записей не основан на первичном ключе или ключе поиска.
Файловые операции
Операции над файлами базы данных можно в целом разделить на две категории:
-
Операции обновления
-
Операции поиска
Операции обновления
Операции поиска
Операции обновления изменяют значения данных путем вставки, удаления или обновления. Операции извлечения, с другой стороны, не изменяют данные, а извлекают их после необязательной условной фильтрации. В обоих типах операций выбор играет значительную роль. Помимо создания и удаления файла, может быть несколько операций над файлами.
-
Открыть – файл можно открыть в одном из двух режимов : режиме чтения или записи . В режиме чтения операционная система не позволяет никому изменять данные. Другими словами, данные только для чтения. Файлы, открытые в режиме чтения, могут быть разделены между несколькими объектами. Режим записи позволяет изменять данные. Файлы, открытые в режиме записи, могут быть прочитаны, но не могут использоваться совместно.
-
Locate – каждый файл имеет указатель файла, который сообщает текущую позицию, где данные должны быть прочитаны или записаны. Этот указатель можно настроить соответствующим образом. Используя операцию поиска (поиска), ее можно перемещать вперед или назад.
-
Чтение – по умолчанию, когда файлы открываются в режиме чтения, указатель файла указывает на начало файла. Существуют варианты, в которых пользователь может указать операционной системе, где находится указатель файла во время открытия файла. Самые следующие данные к указателю файла читаются.
-
Запись – Пользователь может выбрать, чтобы открыть файл в режиме записи, что позволяет им редактировать его содержимое. Это может быть удаление, вставка или изменение. Указатель файла может находиться во время открытия или может быть динамически изменен, если операционная система позволяет это сделать.
-
Закрыть – это самая важная операция с точки зрения операционной системы. Когда генерируется запрос на закрытие файла, операционная система
- удаляет все блокировки (если в режиме совместного использования),
- сохраняет данные (если они были изменены) на вторичном носителе и
- освобождает все буферы и обработчики файлов, связанные с файлом.
Открыть – файл можно открыть в одном из двух режимов : режиме чтения или записи . В режиме чтения операционная система не позволяет никому изменять данные. Другими словами, данные только для чтения. Файлы, открытые в режиме чтения, могут быть разделены между несколькими объектами. Режим записи позволяет изменять данные. Файлы, открытые в режиме записи, могут быть прочитаны, но не могут использоваться совместно.
Locate – каждый файл имеет указатель файла, который сообщает текущую позицию, где данные должны быть прочитаны или записаны. Этот указатель можно настроить соответствующим образом. Используя операцию поиска (поиска), ее можно перемещать вперед или назад.
Чтение – по умолчанию, когда файлы открываются в режиме чтения, указатель файла указывает на начало файла. Существуют варианты, в которых пользователь может указать операционной системе, где находится указатель файла во время открытия файла. Самые следующие данные к указателю файла читаются.
Запись – Пользователь может выбрать, чтобы открыть файл в режиме записи, что позволяет им редактировать его содержимое. Это может быть удаление, вставка или изменение. Указатель файла может находиться во время открытия или может быть динамически изменен, если операционная система позволяет это сделать.
Закрыть – это самая важная операция с точки зрения операционной системы. Когда генерируется запрос на закрытие файла, операционная система
Организация данных внутри файла играет здесь важную роль. Процесс поиска указателя файла на нужную запись внутри файла зависит от того, расположены ли записи последовательно или кластеризовано.
СУБД – Индексирование
Мы знаем, что данные хранятся в виде записей. Каждая запись имеет ключевое поле, которое помогает ее узнавать однозначно.
Индексирование – это метод структуры данных, позволяющий эффективно извлекать записи из файлов базы данных на основе некоторых атрибутов, по которым была выполнена индексация. Индексирование в системах баз данных похоже на то, что мы видим в книгах.
Индексирование определяется на основе его атрибутов индексации. Индексирование может быть следующих типов –
-
Первичный индекс – первичный индекс определяется в упорядоченном файле данных. Файл данных упорядочен по ключевому полю . Поле ключа, как правило, является первичным ключом отношения.
-
Вторичный индекс – Вторичный индекс может быть создан из поля, которое является ключом-кандидатом и имеет уникальное значение в каждой записи, или неключевой ключ с дублирующимися значениями.
-
Индекс кластеризации. Индекс кластеризации определяется в упорядоченном файле данных. Файл данных упорядочен в неключевом поле.
Первичный индекс – первичный индекс определяется в упорядоченном файле данных. Файл данных упорядочен по ключевому полю . Поле ключа, как правило, является первичным ключом отношения.
Вторичный индекс – Вторичный индекс может быть создан из поля, которое является ключом-кандидатом и имеет уникальное значение в каждой записи, или неключевой ключ с дублирующимися значениями.
Индекс кластеризации. Индекс кластеризации определяется в упорядоченном файле данных. Файл данных упорядочен в неключевом поле.
Упорядоченное индексирование бывает двух типов:
- Плотный индекс
- Разреженный индекс
Плотный индекс
В плотном индексе есть индексная запись для каждого значения ключа поиска в базе данных. Это ускоряет поиск, но требует больше места для хранения записей индекса. Индексные записи содержат значение ключа поиска и указатель на фактическую запись на диске.
Разреженный индекс
В разреженном индексе записи индекса создаются не для каждого ключа поиска. Индексная запись здесь содержит ключ поиска и фактический указатель на данные на диске. Для поиска записи мы сначала переходим к индексной записи и достигаем фактическое местоположение данных. Если данные, которые мы ищем, находятся не там, где мы непосредственно достигаем, следуя индексу, то система начинает последовательный поиск, пока не будут найдены нужные данные.
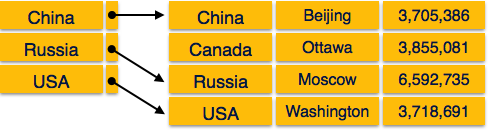
Многоуровневый индекс
Индексные записи содержат значения ключей поиска и указатели данных. Многоуровневый индекс хранится на диске вместе с актуальными файлами базы данных. По мере увеличения размера базы данных увеличивается и размер индексов. Существует огромная необходимость хранить записи индекса в основной памяти, чтобы ускорить операции поиска. Если используется одноуровневый индекс, индекс большого размера не может быть сохранен в памяти, что приводит к нескольким обращениям к диску.
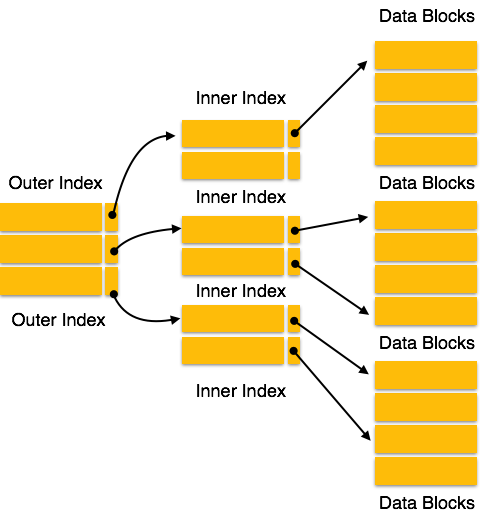
Многоуровневый индекс помогает разбить индекс на несколько меньших индексов, чтобы сделать внешний уровень настолько маленьким, чтобы его можно было сохранить в одном блоке диска, который можно легко разместить в любом месте основной памяти.
B + Дерево
AB + дерево – это сбалансированное двоичное дерево поиска, которое соответствует многоуровневому формату индекса. Листовые узлы дерева B + обозначают фактические указатели данных. B + дерево гарантирует, что все листовые узлы остаются на одной высоте, таким образом, сбалансированы. Кроме того, конечные узлы связаны с использованием списка ссылок; следовательно, дерево B + может поддерживать произвольный доступ, а также последовательный доступ.
Структура дерева B +
Каждый листовой узел находится на одинаковом расстоянии от корневого узла. Дерево AB + имеет порядок n, где n фиксировано для каждого дерева B + .
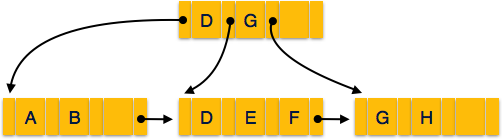
Внутренние узлы –
- Внутренние (неконечные) узлы содержат как минимум ⌈n / 2⌉ указателей, кроме корневого узла.
- Максимум, внутренний узел может содержать n указателей.
Листовые узлы –
- Конечные узлы содержат как минимум ⌈n / 2⌉ указатели записи и ⌈n / 2⌉ ключевые значения.
- Самое большее, листовой узел может содержать n указателей записи и n значений ключа.
- Каждый листовой узел содержит один блок-указатель P для указания на следующий листовой узел и формирует связанный список.
B + Tree Вставка
-
B + деревья заполняются снизу, и каждая запись выполняется на листовом узле.
- Если листовой узел переполняется –
-
Разделите узел на две части.
-
Разбиение при i = ⌊ (m + 1) / 2 ⌋.
-
Сначала i записи хранятся в одном узле.
-
Остальные записи (i + 1 и далее) перемещаются в новый узел.
-
i- й ключ продублирован у родителя листа.
-
-
Если неконечный узел переполняется –
-
Разделите узел на две части.
-
Разбейте узел на i = ⌈ (m + 1) / 2 ⌉ .
-
Записи до i хранятся в одном узле.
-
Остальные записи перемещаются на новый узел.
-
B + деревья заполняются снизу, и каждая запись выполняется на листовом узле.
Разделите узел на две части.
Разбиение при i = ⌊ (m + 1) / 2 ⌋.
Сначала i записи хранятся в одном узле.
Остальные записи (i + 1 и далее) перемещаются в новый узел.
i- й ключ продублирован у родителя листа.
Если неконечный узел переполняется –
Разделите узел на две части.
Разбейте узел на i = ⌈ (m + 1) / 2 ⌉ .
Записи до i хранятся в одном узле.
Остальные записи перемещаются на новый узел.
Удаление дерева B +
-
Записи дерева B + удаляются в конечных узлах.
-
Целевая запись ищется и удаляется.
-
Если это внутренний узел, удалите и замените запись с левой позиции.
-
-
После удаления проверяется недостаточное количество
-
Если происходит переполнение, распределите записи от оставленных ему узлов.
-
-
Если распределение слева невозможно, то
-
Распределите от узлов прямо к нему.
-
-
Если распределение не возможно слева или справа, то
-
Объедините узел с левой и правой стороны.
-
Записи дерева B + удаляются в конечных узлах.
Целевая запись ищется и удаляется.
Если это внутренний узел, удалите и замените запись с левой позиции.
После удаления проверяется недостаточное количество
Если происходит переполнение, распределите записи от оставленных ему узлов.
Если распределение слева невозможно, то
Распределите от узлов прямо к нему.
Если распределение не возможно слева или справа, то
Объедините узел с левой и правой стороны.
СУБД – Хеширование
Для огромной структуры базы данных может быть практически невозможно выполнить поиск по всем значениям индекса по всему его уровню, а затем достичь целевого блока данных, чтобы получить нужные данные. Хеширование – это эффективный метод расчета прямого расположения записи данных на диске без использования структуры индекса.
Хеширование использует хеш-функции с ключами поиска в качестве параметров для генерации адреса записи данных.
Хэш-организация
-
Bucket – Хэш-файл хранит данные в формате Bucket . Ведро считается единицей хранения. В корзине обычно хранится один полный блок диска, который, в свою очередь, может хранить одну или несколько записей.
-
Хеш-функция – хеш-функция h является функцией отображения, которая отображает весь набор ключей K поиска на адрес, на котором размещены фактические записи. Это функция от ключей поиска до адресов корзины.
Bucket – Хэш-файл хранит данные в формате Bucket . Ведро считается единицей хранения. В корзине обычно хранится один полный блок диска, который, в свою очередь, может хранить одну или несколько записей.
Хеш-функция – хеш-функция h является функцией отображения, которая отображает весь набор ключей K поиска на адрес, на котором размещены фактические записи. Это функция от ключей поиска до адресов корзины.
Статическое хеширование
В статическом хешировании, когда предоставляется значение ключа поиска, хеш-функция всегда вычисляет один и тот же адрес. Например, если используется хеш-функция mod-4, то она должна генерировать только 5 значений. Выходной адрес всегда должен быть одинаковым для этой функции. Количество предоставляемых ковшей остается неизменным во все времена.
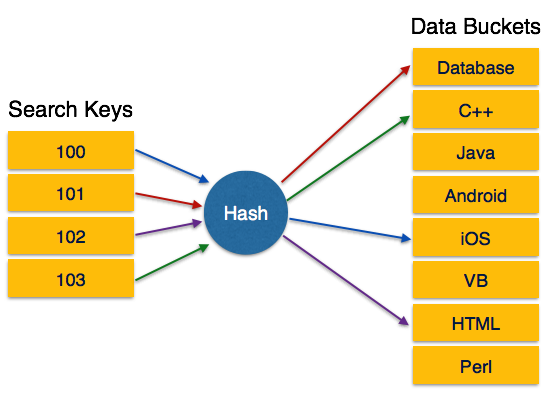
операция
-
Вставка – Когда запись должна быть введена с использованием статического хэша, хэш-функция h вычисляет адрес сегмента для ключа поиска K , где запись будет сохранена.
Адрес корзины = h (K)
-
Поиск – когда требуется извлечь запись, та же хеш-функция может использоваться для получения адреса группы, в которой хранятся данные.
-
Удалить – это просто поиск с последующей операцией удаления.
Вставка – Когда запись должна быть введена с использованием статического хэша, хэш-функция h вычисляет адрес сегмента для ключа поиска K , где запись будет сохранена.
Адрес корзины = h (K)
Поиск – когда требуется извлечь запись, та же хеш-функция может использоваться для получения адреса группы, в которой хранятся данные.
Удалить – это просто поиск с последующей операцией удаления.
Переполнение ковша
Условие переполнения ковша известно как столкновение . Это смертельное состояние для любой статической хэш-функции. В этом случае можно использовать цепочку переполнения.
-
Переполнение цепочки – когда сегменты заполнены, новый сегмент выделяется для того же результата хеширования и связывается после предыдущего. Этот механизм называется закрытым хешированием .
Переполнение цепочки – когда сегменты заполнены, новый сегмент выделяется для того же результата хеширования и связывается после предыдущего. Этот механизм называется закрытым хешированием .
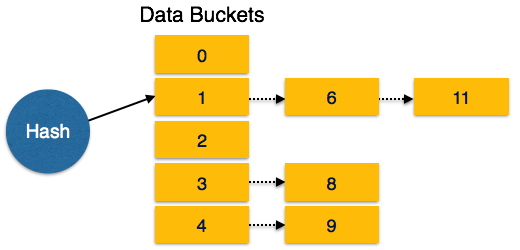
-
Линейное зондирование – когда хеш-функция генерирует адрес, по которому данные уже сохранены, ему выделяется следующий свободный сегмент. Этот механизм называется Open Hashing .
Линейное зондирование – когда хеш-функция генерирует адрес, по которому данные уже сохранены, ему выделяется следующий свободный сегмент. Этот механизм называется Open Hashing .
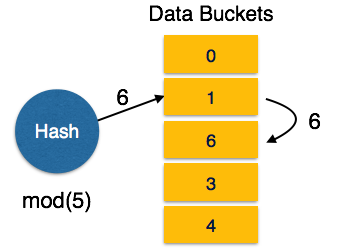
Динамическое хеширование
Проблема статического хэширования заключается в том, что он не расширяется и не сжимается динамически при увеличении или уменьшении размера базы данных. Динамическое хеширование обеспечивает механизм, в котором корзины данных добавляются и удаляются динамически и по требованию. Динамическое хеширование также известно как расширенное хеширование .
Функция хеширования в динамическом хешировании предназначена для получения большого числа значений, и только несколько из них используются изначально.
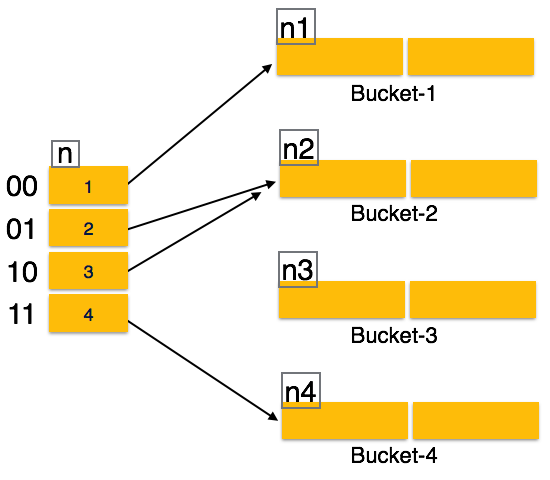
организация
Префикс всего хэш-значения принимается как хеш-индекс. Только часть значения хэша используется для вычисления адресов сегмента. Каждый хеш-индекс имеет значение глубины, чтобы указать, сколько битов используется для вычисления хеш-функции. Эти биты могут адресовать 2n сегментов. Когда все эти биты используются – то есть, когда все сегменты заполнены, – значение глубины увеличивается линейно и выделяется в два раза больше сегментов.
операция
-
Запросы – посмотрите на значение глубины хеш-индекса и используйте эти биты для вычисления адреса сегмента.
-
Обновить – выполнить запрос, как указано выше, и обновить данные.
-
Удаление – выполните запрос, чтобы найти нужные данные и удалить их.
-
Вставка – Вычислить адрес корзины
- Если ведро уже заполнено.
- Добавьте больше ведер.
- Добавьте дополнительные биты к значению хеша.
- Пересчитать хеш-функцию.
- еще
- Добавить данные в корзину,
- Если все ведра заполнены, выполните действия статического хеширования.
- Если ведро уже заполнено.
Запросы – посмотрите на значение глубины хеш-индекса и используйте эти биты для вычисления адреса сегмента.
Обновить – выполнить запрос, как указано выше, и обновить данные.
Удаление – выполните запрос, чтобы найти нужные данные и удалить их.
Вставка – Вычислить адрес корзины
Хеширование не выгодно, когда данные организованы в некотором порядке, а запросы требуют диапазона данных. Когда данные дискретны и случайны, хеш работает лучше всего.
Алгоритмы хеширования имеют большую сложность, чем индексация. Все хеш-операции выполняются в постоянное время.
СУБД – Транзакция
Транзакция может быть определена как группа задач. Единственная задача – это минимальная единица обработки, которую нельзя разделить дальше.
Давайте рассмотрим пример простой транзакции. Предположим, сотрудник банка переводит 500 рупий со счета А на счет Б. Эта очень простая и небольшая транзакция включает в себя несколько задач низкого уровня.
Счет А
Open_Account(A) Old_Balance = A.balance New_Balance = Old_Balance - 500 A.balance = New_Balance Close_Account(A)
B счет
Open_Account(B) Old_Balance = B.balance New_Balance = Old_Balance + 500 B.balance = New_Balance Close_Account(B)
ACID Свойства
Транзакция – это очень маленькая единица программы, и она может содержать несколько низкоуровневых задач. Для обеспечения точности, полноты и целостности данных транзакция в системе базы данных должна поддерживать единообразие, согласованность, согласованность и устойчивость, обычно известные как свойства ACID.
-
Атомарность. Это свойство указывает, что транзакция должна рассматриваться как атомарная единица, то есть либо все ее операции выполняются, либо их нет. В базе данных не должно быть состояния, в котором транзакция оставлена частично завершенной. Состояния должны быть определены либо до выполнения транзакции, либо после выполнения / прерывания / сбоя транзакции.
-
Согласованность – база данных должна оставаться в согласованном состоянии после любой транзакции. Ни одна транзакция не должна оказывать неблагоприятного воздействия на данные, находящиеся в базе данных. Если база данных находилась в согласованном состоянии до выполнения транзакции, она должна оставаться согласованной и после выполнения транзакции.
-
Долговечность. База данных должна быть достаточно надежной, чтобы в ней можно было хранить все последние обновления, даже если система выходит из строя или перезагружается. Если транзакция обновляет порцию данных в базе данных и фиксирует, то база данных будет содержать измененные данные. Если транзакция завершается, но система завершается неудачей, прежде чем данные могут быть записаны на диск, эти данные будут обновлены, как только система вернется в действие.
-
Изоляция. В системе баз данных, в которой одновременно и параллельно выполняется более одной транзакции, свойство изоляции указывает, что все транзакции будут выполняться и выполняться так, как если бы это была единственная транзакция в системе. Никакая транзакция не повлияет на существование любой другой транзакции.
Атомарность. Это свойство указывает, что транзакция должна рассматриваться как атомарная единица, то есть либо все ее операции выполняются, либо их нет. В базе данных не должно быть состояния, в котором транзакция оставлена частично завершенной. Состояния должны быть определены либо до выполнения транзакции, либо после выполнения / прерывания / сбоя транзакции.
Согласованность – база данных должна оставаться в согласованном состоянии после любой транзакции. Ни одна транзакция не должна оказывать неблагоприятного воздействия на данные, находящиеся в базе данных. Если база данных находилась в согласованном состоянии до выполнения транзакции, она должна оставаться согласованной и после выполнения транзакции.
Долговечность. База данных должна быть достаточно надежной, чтобы в ней можно было хранить все последние обновления, даже если система выходит из строя или перезагружается. Если транзакция обновляет порцию данных в базе данных и фиксирует, то база данных будет содержать измененные данные. Если транзакция завершается, но система завершается неудачей, прежде чем данные могут быть записаны на диск, эти данные будут обновлены, как только система вернется в действие.
Изоляция. В системе баз данных, в которой одновременно и параллельно выполняется более одной транзакции, свойство изоляции указывает, что все транзакции будут выполняться и выполняться так, как если бы это была единственная транзакция в системе. Никакая транзакция не повлияет на существование любой другой транзакции.
Сериализуемость
Когда операционная система выполняет несколько транзакций в многопрограммной среде, есть вероятность, что инструкции одной транзакции чередуются с какой-либо другой транзакцией.
-
Расписание – хронологическая последовательность выполнения транзакции называется расписанием. В расписании может быть много транзакций, каждая из которых состоит из ряда инструкций / задач.
-
Последовательное расписание – это расписание, в котором транзакции выровнены таким образом, что одна транзакция выполняется первой. Когда первая транзакция завершает свой цикл, выполняется следующая транзакция. Транзакции заказываются одна за другой. Этот тип расписания называется последовательным расписанием, поскольку транзакции выполняются последовательным образом.
Расписание – хронологическая последовательность выполнения транзакции называется расписанием. В расписании может быть много транзакций, каждая из которых состоит из ряда инструкций / задач.
Последовательное расписание – это расписание, в котором транзакции выровнены таким образом, что одна транзакция выполняется первой. Когда первая транзакция завершает свой цикл, выполняется следующая транзакция. Транзакции заказываются одна за другой. Этот тип расписания называется последовательным расписанием, поскольку транзакции выполняются последовательным образом.
В среде с несколькими транзакциями последовательные расписания считаются эталоном. Последовательность выполнения инструкции в транзакции не может быть изменена, но две транзакции могут иметь свои инструкции, выполненные случайным образом. Это выполнение не вредит, если две транзакции независимы друг от друга и работают с разными сегментами данных; но если эти две транзакции работают с одними и теми же данными, результаты могут отличаться. Этот постоянно меняющийся результат может привести базу данных в несогласованное состояние.
Чтобы решить эту проблему, мы разрешаем параллельное выполнение расписания транзакций, если его транзакции либо сериализуемы, либо имеют некоторое отношение эквивалентности между ними.
Графики эквивалентности
График эквивалентности может быть следующих типов:
Результат Эквивалентность
Если два графика дают один и тот же результат после выполнения, они называются эквивалентными. Они могут давать один и тот же результат для некоторого значения и разные результаты для другого набора значений. Вот почему эта эквивалентность обычно не считается значимой.
Посмотреть эквивалентность
Два расписания были бы эквивалентны представлению, если транзакции в обоих расписаниях выполняют аналогичные действия одинаковым образом.
Например –
-
Если T читает начальные данные в S1, то он также читает начальные данные в S2.
-
Если T читает значение, записанное J в S1, то оно также читает значение, записанное J в S2.
-
Если T выполняет окончательную запись значения данных в S1, то он также выполняет окончательную запись значения данных в S2.
Если T читает начальные данные в S1, то он также читает начальные данные в S2.
Если T читает значение, записанное J в S1, то оно также читает значение, записанное J в S2.
Если T выполняет окончательную запись значения данных в S1, то он также выполняет окончательную запись значения данных в S2.
Эквивалентность конфликта
Два расписания будут конфликтовать, если они имеют следующие свойства –
- Оба относятся к отдельным транзакциям.
- Оба получают доступ к одному и тому же элементу данных.
- По крайней мере, один из них – операция записи.
Два расписания с несколькими транзакциями с конфликтующими операциями называются конфликтно-эквивалентными, если и только если –
- Оба графика содержат одинаковый набор транзакций.
- Порядок конфликтующих пар операций поддерживается в обоих расписаниях.
Примечание. Просмотр эквивалентных расписаний можно просматривать сериализуемо, а конфликтно-эквивалентные расписания можно сериализировать конфликтом. Все конфликтные сериализуемые графики также доступны для просмотра.
Состояния транзакций
Транзакция в базе данных может находиться в одном из следующих состояний:
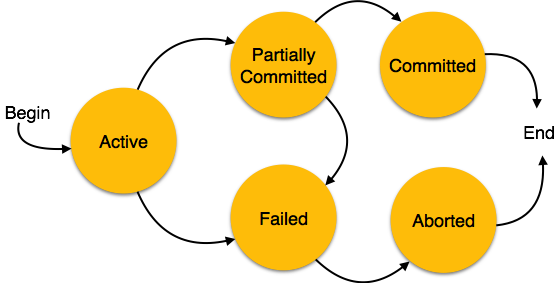
-
Активно – в этом состоянии транзакция выполняется. Это начальное состояние каждой транзакции.
-
Частично зафиксировано – когда транзакция выполняет свою последнюю операцию, говорят, что она находится в частично зафиксированном состоянии.
-
Failed (Сбой) – считается, что транзакция находится в состоянии сбоя, если какая-либо из проверок, выполненных системой восстановления базы данных, дает сбой. Неудачная транзакция больше не может продолжаться дальше.
-
Прервано – если какая-либо из проверок завершилась неудачно и транзакция достигла состояния отказа, менеджер восстановления откатывает все свои операции записи в базе данных, чтобы вернуть базу данных в исходное состояние, в котором она находилась до выполнения транзакции. Транзакции в этом состоянии называются прерванными. Модуль восстановления базы данных может выбрать одну из двух операций после завершения транзакции –
- Перезапустить транзакцию
- Убить сделку
-
Подтверждено – если транзакция успешно выполняет все свои операции, она считается подтвержденной. Все его эффекты теперь постоянно установлены в системе баз данных.
Активно – в этом состоянии транзакция выполняется. Это начальное состояние каждой транзакции.
Частично зафиксировано – когда транзакция выполняет свою последнюю операцию, говорят, что она находится в частично зафиксированном состоянии.
Failed (Сбой) – считается, что транзакция находится в состоянии сбоя, если какая-либо из проверок, выполненных системой восстановления базы данных, дает сбой. Неудачная транзакция больше не может продолжаться дальше.
Прервано – если какая-либо из проверок завершилась неудачно и транзакция достигла состояния отказа, менеджер восстановления откатывает все свои операции записи в базе данных, чтобы вернуть базу данных в исходное состояние, в котором она находилась до выполнения транзакции. Транзакции в этом состоянии называются прерванными. Модуль восстановления базы данных может выбрать одну из двух операций после завершения транзакции –
Подтверждено – если транзакция успешно выполняет все свои операции, она считается подтвержденной. Все его эффекты теперь постоянно установлены в системе баз данных.
СУБД – контроль параллелизма
В многопрограммной среде, где несколько транзакций могут выполняться одновременно, очень важно контролировать параллельность транзакций. У нас есть протоколы контроля параллелизма для обеспечения атомарности, изоляции и сериализуемости параллельных транзакций. Протоколы управления параллелизмом можно разделить на две категории:
- Протоколы на основе блокировки
- Протоколы на основе меток времени
Протоколы на основе блокировки
Системы баз данных, оснащенные протоколами на основе блокировок, используют механизм, с помощью которого любая транзакция не может читать или записывать данные, пока не получит соответствующую блокировку. Замки бывают двух видов –
-
Двоичные блокировки – блокировка элемента данных может находиться в двух состояниях; он либо заблокирован, либо разблокирован.
-
Разделяемый / эксклюзивный – этот тип механизма блокировки различает замки в зависимости от их использования. Если для элемента данных установлена блокировка для выполнения операции записи, это исключительная блокировка. Разрешение на запись более чем одной транзакции в один и тот же элемент данных приведет базу данных в несогласованное состояние. Блокировки чтения являются общими, поскольку значение данных не изменяется.
Двоичные блокировки – блокировка элемента данных может находиться в двух состояниях; он либо заблокирован, либо разблокирован.
Разделяемый / эксклюзивный – этот тип механизма блокировки различает замки в зависимости от их использования. Если для элемента данных установлена блокировка для выполнения операции записи, это исключительная блокировка. Разрешение на запись более чем одной транзакции в один и тот же элемент данных приведет базу данных в несогласованное состояние. Блокировки чтения являются общими, поскольку значение данных не изменяется.
Доступны четыре типа протоколов блокировки –
Упрощенный протокол блокировки
Упрощенные протоколы на основе блокировок позволяют транзакциям получать блокировку для каждого объекта перед выполнением операции записи. Транзакции могут разблокировать элемент данных после завершения операции записи.
Предварительный запрос протокола блокировки
Протоколы предварительной заявки оценивают их операции и создают список элементов данных, для которых они нуждаются в блокировках. Перед началом выполнения транзакция запрашивает у системы все блокировки, в которых она нуждается заранее. Если все блокировки предоставлены, транзакция выполняется и освобождает все блокировки, когда все ее операции завершены. Если все блокировки не предоставлены, транзакция откатывается и ждет, пока все блокировки не будут предоставлены.
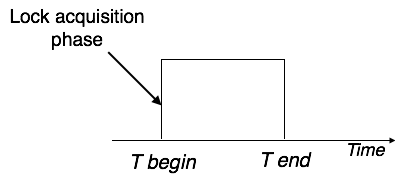
Двухфазная блокировка 2PL
Этот протокол блокировки разделяет этап выполнения транзакции на три части. В первой части, когда транзакция начинает выполняться, она ищет разрешения для требуемых блокировок. Вторая часть, где транзакция получает все блокировки. Как только транзакция освобождает свою первую блокировку, начинается третья фаза. На этом этапе транзакция не может требовать каких-либо новых блокировок; это только освобождает приобретенные замки.
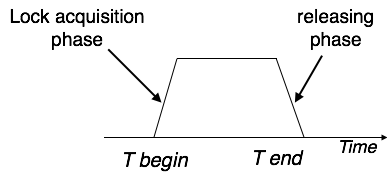
Двухфазная блокировка имеет две фазы, одна растет , где все блокировки приобретаются транзакцией; и вторая фаза сокращается, когда освобождаются блокировки, удерживаемые транзакцией.
Чтобы запросить исключительную блокировку (запись), транзакция должна сначала получить общую (чтение) блокировку, а затем обновить ее до эксклюзивной блокировки.
Строгая двухфазная блокировка
Первая фаза Strict-2PL такая же, как 2PL. После получения всех блокировок на первом этапе транзакция продолжает выполняться в обычном режиме. Но в отличие от 2PL, Strict-2PL не снимает блокировку после его использования. Strict-2PL удерживает все блокировки до момента фиксации и снимает все блокировки одновременно.
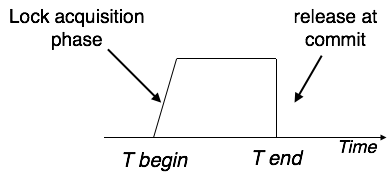
Strict-2PL не имеет каскадного прерывания, как 2PL.
Протоколы на основе меток времени
Наиболее часто используемый протокол параллелизма – это протокол, основанный на метках времени. Этот протокол использует системное время или логический счетчик в качестве метки времени.
Протоколы на основе блокировок управляют порядком между конфликтующими парами между транзакциями во время выполнения, тогда как протоколы на основе временных меток начинают работать, как только создается транзакция.
С каждой транзакцией связана временная метка, а порядок определяется возрастом транзакции. Транзакция, созданная в 0002 тактового времени, будет старше всех других транзакций, следующих за ней. Например, любая транзакция ‘y’, входящая в систему на 0004, на две секунды моложе, и приоритет будет отдан более старой.
Кроме того, каждому элементу данных присваивается последняя отметка времени чтения и записи. Это позволяет системе узнать, когда была выполнена последняя операция чтения и записи для элемента данных.
Протокол заказа метки времени
Протокол упорядочения меток времени обеспечивает сериализуемость между транзакциями в их конфликтующих операциях чтения и записи. Система протокола отвечает за то, что конфликтующая пара задач должна выполняться в соответствии со значениями временных меток транзакций.
- Временная метка транзакции T i обозначается как TS (T i ).
- Отметка времени чтения элемента данных X обозначается как R-отметка времени (X).
- Отметка времени записи элемента данных X обозначается W-отметкой времени (X).
Протокол заказа метки времени работает следующим образом:
-
Если транзакция Ti выполняет операцию чтения (X) –
- Если TS (Ti) <W-метка времени (X)
- Операция отклонена.
- Если TS (Ti)> = W-метка времени (X)
- Операция выполнена.
- Все метки времени элемента данных обновлены.
-
Если транзакция Ti выполняет операцию записи (X) –
- Если TS (Ti) <R-отметка времени (X)
- Операция отклонена.
- Если TS (Ti) <W-метка времени (X)
- Операция отклонена и Ti откатился назад.
- В противном случае операция выполнена.
Если транзакция Ti выполняет операцию чтения (X) –
Если транзакция Ti выполняет операцию записи (X) –
Писать правило Томаса
Это правило гласит, что если TS (Ti) <W-timestamp (X), то операция отклоняется и T i откатывается.
Правила упорядочения меток времени можно изменить, чтобы сделать сериализованным представление расписания.
Вместо того, чтобы откатить T i , сама операция записи игнорируется.
СУБД – тупик
В многопроцессорной системе тупиковая ситуация – это нежелательная ситуация, которая возникает в среде общих ресурсов, где процесс бесконечно ожидает ресурс, который удерживается другим процессом.
Например, предположим набор транзакций {T 0 , T 1 , T 2 , …, T n }. T 0 нужен ресурс X, чтобы завершить свою задачу. Ресурс X удерживается T 1 , а T 1 ожидает ресурс Y, который удерживается T 2 . T 2 ожидает ресурс Z, который удерживается T 0 . Таким образом, все процессы ждут друг друга, чтобы освободить ресурсы. В этой ситуации ни один из процессов не может завершить свою задачу. Эта ситуация известна как тупик.
Тупики не полезны для системы. В случае, если система застревает в тупике, транзакции, вовлеченные в тупик, либо откатываются, либо перезапускаются.
Предотвращение тупиковой ситуации
Чтобы предотвратить любую тупиковую ситуацию в системе, СУБД настойчиво проверяет все операции, в которых собираются выполнить транзакции. СУБД проверяет операции и анализирует, могут ли они создать тупиковую ситуацию. Если он обнаруживает, что может возникнуть ситуация взаимоблокировки, эта транзакция никогда не будет разрешена для выполнения.
Существуют схемы предотвращения взаимоблокировок, в которых используется механизм упорядочения временных меток транзакций для предопределения ситуации взаимоблокировки.
Схема ожидания
В этой схеме, если транзакция запрашивает блокировку ресурса (элемента данных), который уже удерживается с конфликтующей блокировкой другой транзакцией, то может возникнуть одна из двух возможностей:
-
Если TS (T i ) <TS (T j ) – то есть T i , который запрашивает конфликтующую блокировку, старше, чем T j – тогда T i разрешается ждать, пока элемент данных станет доступным.
-
Если TS (T i )> TS (t j ) – то есть T i моложе, чем T j – тогда T i умирает. T i перезапускается позже со случайной задержкой, но с той же отметкой времени.
Если TS (T i ) <TS (T j ) – то есть T i , который запрашивает конфликтующую блокировку, старше, чем T j – тогда T i разрешается ждать, пока элемент данных станет доступным.
Если TS (T i )> TS (t j ) – то есть T i моложе, чем T j – тогда T i умирает. T i перезапускается позже со случайной задержкой, но с той же отметкой времени.
Эта схема позволяет старшей транзакции ждать, но убивает младшую.
Схема ожидания
В этой схеме, если транзакция запрашивает блокировку ресурса (элемента данных), который уже удерживается с конфликтующей блокировкой какой-либо другой транзакцией, может возникнуть одна из двух возможностей:
-
Если TS (T i ) <TS (T j ), то T i заставляет T j откатываться – то есть T i ранит T j . T j перезапускается позже со случайной задержкой, но с той же временной меткой.
-
Если TS (T i )> TS (T j ), то T i вынужден ждать, пока ресурс не станет доступен.
Если TS (T i ) <TS (T j ), то T i заставляет T j откатываться – то есть T i ранит T j . T j перезапускается позже со случайной задержкой, но с той же временной меткой.
Если TS (T i )> TS (T j ), то T i вынужден ждать, пока ресурс не станет доступен.
Эта схема позволяет младшей транзакции ждать; но когда более старая транзакция запрашивает элемент, принадлежащий более молодой, более старая транзакция вынуждает более молодую транзакцию прервать и отпустить элемент.
В обоих случаях транзакция, поступающая в систему на более позднем этапе, прерывается.
Предотвращение тупиков
Отмена транзакции не всегда практический подход. Вместо этого можно заранее использовать механизмы предотвращения тупиковой ситуации для обнаружения любой тупиковой ситуации. Такие методы, как «график ожидания», доступны, но они подходят только для тех систем, где транзакции имеют малый вес и имеют меньшее количество экземпляров ресурса. В громоздкой системе методы предотвращения тупиковых ситуаций могут хорошо работать.
График ожидания
Это простой метод, доступный для отслеживания возможных ситуаций тупика. Для каждой транзакции, входящей в систему, создается узел. Когда транзакция T i запрашивает блокировку элемента, скажем, X, которая удерживается какой-либо другой транзакцией T j , создается направленный край от T i до T j . Если T j освобождает элемент X, грань между ними отбрасывается, и T i блокирует элемент данных.
Система поддерживает этот график ожидания для каждой транзакции, ожидающей некоторые элементы данных, удерживаемые другими. Система постоянно проверяет, есть ли цикл на графике.
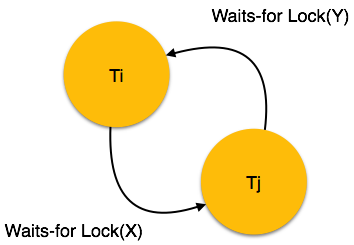
Здесь мы можем использовать любой из следующих двух подходов:
-
Во-первых, не допускайте никаких запросов на элемент, который уже заблокирован другой транзакцией. Это не всегда выполнимо и может вызвать голод, когда транзакция бесконечно ожидает элемент данных и никогда не сможет его получить.
-
Второй вариант – откатить одну из транзакций. Не всегда выполнимо откатить младшую транзакцию, поскольку она может быть важнее старой. С помощью некоторого относительного алгоритма выбирается транзакция, которая должна быть прервана. Эта транзакция называется жертвой, а процесс – выбором жертвы .
Во-первых, не допускайте никаких запросов на элемент, который уже заблокирован другой транзакцией. Это не всегда выполнимо и может вызвать голод, когда транзакция бесконечно ожидает элемент данных и никогда не сможет его получить.
Второй вариант – откатить одну из транзакций. Не всегда выполнимо откатить младшую транзакцию, поскольку она может быть важнее старой. С помощью некоторого относительного алгоритма выбирается транзакция, которая должна быть прервана. Эта транзакция называется жертвой, а процесс – выбором жертвы .
СУБД – Резервное копирование данных
Потеря Летучего Хранения
В энергозависимом хранилище, таком как ОЗУ, хранятся все активные журналы, дисковые буферы и связанные данные. Кроме того, он хранит все транзакции, которые выполняются в данный момент. Что произойдет, если такое энергозависимое хранилище внезапно выйдет из строя? Очевидно, он забрал бы все журналы и активные копии базы данных. Это делает восстановление практически невозможным, так как все, что требуется для восстановления данных, потеряно.
Следующие методы могут быть приняты в случае потери энергозависимого хранения –
-
Мы можем иметь контрольные точки на нескольких этапах, чтобы периодически сохранять содержимое базы данных.
-
Состояние активной базы данных в энергозависимой памяти может периодически выгружаться в стабильное хранилище, которое также может содержать журналы и активные транзакции и буферные блоки.
-
<dump> может быть отмечен в файле журнала всякий раз, когда содержимое базы данных выгружается из энергонезависимой памяти в стабильную.
Мы можем иметь контрольные точки на нескольких этапах, чтобы периодически сохранять содержимое базы данных.
Состояние активной базы данных в энергозависимой памяти может периодически выгружаться в стабильное хранилище, которое также может содержать журналы и активные транзакции и буферные блоки.
<dump> может быть отмечен в файле журнала всякий раз, когда содержимое базы данных выгружается из энергонезависимой памяти в стабильную.
восстановление
-
Когда система восстанавливается после сбоя, она может восстановить последний дамп.
-
Он может поддерживать повторный список и список отмен как контрольные точки.
-
Он может восстановить систему, просмотрев списки отмен и повторов, чтобы восстановить состояние всех транзакций до последней контрольной точки.
Когда система восстанавливается после сбоя, она может восстановить последний дамп.
Он может поддерживать повторный список и список отмен как контрольные точки.
Он может восстановить систему, просмотрев списки отмен и повторов, чтобы восстановить состояние всех транзакций до последней контрольной точки.
Резервное копирование и восстановление базы данных после катастрофического сбоя
Катастрофический сбой – это тот случай, когда стабильное вторичное запоминающее устройство повреждено. При использовании устройства хранения все ценные данные, которые хранятся внутри, теряются. У нас есть две разные стратегии для восстановления данных после такого катастрофического сбоя –
-
Удаленное резервное копирование & minu; Здесь резервная копия базы данных хранится в удаленном месте, откуда она может быть восстановлена в случае катастрофы.
-
Кроме того, резервные копии базы данных могут быть сделаны на магнитных лентах и храниться в более безопасном месте. Впоследствии эта резервная копия может быть перенесена в недавно установленную базу данных, чтобы привести ее к точке резервного копирования.
Удаленное резервное копирование & minu; Здесь резервная копия базы данных хранится в удаленном месте, откуда она может быть восстановлена в случае катастрофы.
Кроме того, резервные копии базы данных могут быть сделаны на магнитных лентах и храниться в более безопасном месте. Впоследствии эта резервная копия может быть перенесена в недавно установленную базу данных, чтобы привести ее к точке резервного копирования.
Взрослые базы данных слишком громоздки, чтобы их можно было часто копировать. В таких случаях у нас есть методы, при которых мы можем восстановить базу данных, просто взглянув на ее логи. Итак, все, что нам нужно сделать здесь, это сделать резервную копию всех журналов с частыми интервалами времени. Резервное копирование базы данных может производиться один раз в неделю, а журналы очень малого размера могут создаваться ежедневно или как можно чаще.
Удаленное резервное копирование
Удаленное резервное копирование обеспечивает чувство безопасности на случай, если основное местоположение, где расположена база данных, разрушено. Удаленное резервное копирование может быть в автономном режиме или в режиме реального времени или онлайн. В случае, если он не в сети, он поддерживается вручную.
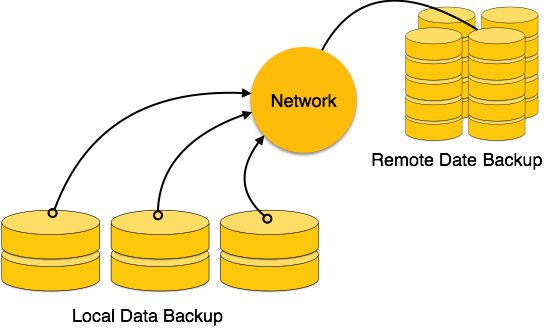
Системы резервного копирования в режиме онлайн являются в реальном времени и спасают для администраторов баз данных и инвесторов. Система оперативного резервного копирования – это механизм, в котором каждый бит данных в реальном времени резервируется одновременно в двух удаленных местах. Один из них напрямую подключен к системе, а другой хранится в удаленном месте в качестве резервной копии.
Как только происходит сбой основного хранилища базы данных, система резервного копирования обнаруживает сбой и переключает пользовательскую систему на удаленное хранилище. Иногда это происходит настолько мгновенно, что пользователи даже не осознают неудачу.
СУБД – Восстановление данных
Восстановление после сбоя
СУБД – очень сложная система с сотнями транзакций, выполняемых каждую секунду. Долговечность и надежность СУБД зависят от ее сложной архитектуры и лежащего в ее основе аппаратного и системного программного обеспечения. Если в результате транзакции происходит сбой или происходит сбой, ожидается, что система будет использовать какой-то алгоритм или методы для восстановления потерянных данных.
Классификация отказов
Чтобы увидеть, где возникла проблема, мы обобщаем отказ на различные категории, а именно:
Сбой транзакции
Транзакция должна быть прервана, если она не выполняется или когда она достигает точки, из которой она не может идти дальше. Это называется сбой транзакции, когда повреждены только несколько транзакций или процессов.
Причины сбоя транзакции могут быть:
-
Логические ошибки – когда транзакция не может быть завершена из-за ошибки в коде или из-за внутренней ошибки.
-
Системные ошибки – когда система базы данных сама завершает активную транзакцию, потому что СУБД не может выполнить ее, или она должна остановиться из-за какого-либо состояния системы. Например, в случае тупика или недоступности ресурса система прерывает активную транзакцию.
Логические ошибки – когда транзакция не может быть завершена из-за ошибки в коде или из-за внутренней ошибки.
Системные ошибки – когда система базы данных сама завершает активную транзакцию, потому что СУБД не может выполнить ее, или она должна остановиться из-за какого-либо состояния системы. Например, в случае тупика или недоступности ресурса система прерывает активную транзакцию.
Системный сбой
Существуют проблемы, внешние по отношению к системе, которые могут привести к внезапной остановке системы и ее аварийному завершению. Например, перебои в электроснабжении могут вызвать сбой основного аппаратного или программного сбоя.
Примеры могут включать ошибки операционной системы.
Ошибка диска
На заре развития технологии это была распространенная проблема, когда жесткие диски или накопители часто выходили из строя.
Отказы диска включают в себя образование поврежденных секторов, недоступность диска, поломку головки диска или любой другой сбой, который разрушает все или часть дискового хранилища.
Структура хранения
Мы уже описали систему хранения. Вкратце, структуру хранения можно разделить на две категории –
-
Энергозависимое хранилище. Как следует из названия, энергозависимое хранилище не может выдержать сбои системы. Энергозависимые запоминающие устройства расположены очень близко к процессору; обычно они встроены в сам чипсет. Например, основная память и кэш-память являются примерами энергозависимой памяти. Они быстрые, но могут хранить только небольшое количество информации.
-
Энергонезависимое хранилище – эти воспоминания созданы для того, чтобы выдерживать сбои системы. Они огромны по объему хранения данных, но медленнее по доступу. Примерами могут быть жесткие диски, магнитные ленты, флэш-память и энергонезависимое ОЗУ (с резервным питанием от батареи).
Энергозависимое хранилище. Как следует из названия, энергозависимое хранилище не может выдержать сбои системы. Энергозависимые запоминающие устройства расположены очень близко к процессору; обычно они встроены в сам чипсет. Например, основная память и кэш-память являются примерами энергозависимой памяти. Они быстрые, но могут хранить только небольшое количество информации.
Энергонезависимое хранилище – эти воспоминания созданы для того, чтобы выдерживать сбои системы. Они огромны по объему хранения данных, но медленнее по доступу. Примерами могут быть жесткие диски, магнитные ленты, флэш-память и энергонезависимое ОЗУ (с резервным питанием от батареи).
Восстановление и атомарность
В случае сбоя системы может быть выполнено несколько транзакций и открыты различные файлы для изменения элементов данных. Сделки состоят из различных операций, которые по своей природе являются атомарными. Но согласно ACID-свойствам СУБД, атомарность транзакций в целом должна поддерживаться, то есть либо все операции выполняются, либо их нет.
Когда СУБД восстанавливается после сбоя, она должна поддерживать следующее:
-
Он должен проверять состояния всех транзакций, которые выполнялись.
-
Транзакция может быть в середине некоторой операции; СУБД должна обеспечивать атомарность транзакции в этом случае.
-
Он должен проверить, может ли транзакция быть завершена сейчас или ее необходимо откатить.
-
Никакие транзакции не позволят оставить СУБД в несогласованном состоянии.
Он должен проверять состояния всех транзакций, которые выполнялись.
Транзакция может быть в середине некоторой операции; СУБД должна обеспечивать атомарность транзакции в этом случае.
Он должен проверить, может ли транзакция быть завершена сейчас или ее необходимо откатить.
Никакие транзакции не позволят оставить СУБД в несогласованном состоянии.
Существует два типа методов, которые могут помочь СУБД в восстановлении, а также в поддержании атомарности транзакции.
-
Ведение журналов каждой транзакции и запись их в некоторое стабильное хранилище перед тем, как вносить изменения в базу данных.
-
Ведение теневой подкачки, когда изменения выполняются в энергозависимой памяти, а затем актуальная база данных обновляется.
Ведение журналов каждой транзакции и запись их в некоторое стабильное хранилище перед тем, как вносить изменения в базу данных.
Ведение теневой подкачки, когда изменения выполняются в энергозависимой памяти, а затем актуальная база данных обновляется.
Восстановление на основе журнала
Журнал – это последовательность записей, которая ведет записи действий, выполненных транзакцией. Важно, чтобы журналы записывались до фактического изменения и сохранялись на стабильном носителе, который является отказоустойчивым.
Восстановление на основе журнала работает следующим образом:
-
Файл журнала хранится на стабильном носителе.
-
Когда транзакция входит в систему и начинает выполнение, она записывает в нее журнал.
Файл журнала хранится на стабильном носителе.
Когда транзакция входит в систему и начинает выполнение, она записывает в нее журнал.
<T n , Start>
-
Когда транзакция изменяет элемент X, она записывает журналы следующим образом:
Когда транзакция изменяет элемент X, она записывает журналы следующим образом:
<T n , X, V 1 , V 2 >
В нем говорится, что T n изменило значение X с V 1 до V 2 .
- Когда транзакция заканчивается, она регистрирует –
<T n , commit>
База данных может быть изменена с использованием двух подходов –
-
Отложенная модификация базы данных – все журналы записываются в стабильное хранилище, а база данных обновляется при фиксации транзакции.
-
Немедленное изменение базы данных – каждый журнал следует за фактическим изменением базы данных. То есть база данных модифицируется сразу после каждой операции.
Отложенная модификация базы данных – все журналы записываются в стабильное хранилище, а база данных обновляется при фиксации транзакции.
Немедленное изменение базы данных – каждый журнал следует за фактическим изменением базы данных. То есть база данных модифицируется сразу после каждой операции.
Восстановление с параллельными транзакциями
Когда несколько транзакций выполняются параллельно, журналы чередуются. Во время восстановления системе восстановления будет трудно отследить все журналы, а затем начать восстановление. Чтобы облегчить эту ситуацию, большинство современных СУБД используют концепцию «контрольных точек».
Контрольно-пропускной пункт
Хранение и ведение журналов в реальном времени и в реальной среде может заполнить все пространство памяти, доступное в системе. Со временем файл журнала может стать слишком большим, чтобы его можно было обрабатывать вообще. Контрольная точка – это механизм, при котором все предыдущие журналы удаляются из системы и постоянно хранятся на диске. Контрольная точка объявляет точку, до которой СУБД находилась в согласованном состоянии, и все транзакции были зафиксированы.
восстановление
Когда происходит сбой и восстановление системы с одновременными транзакциями, она ведет себя следующим образом:

-
Система восстановления считывает журналы в обратном направлении от конца до последней контрольной точки.
-
Он поддерживает два списка: список отмены и список повторов.
-
Если система восстановления видит журнал с <T n , Start> и <T n , Commit> или просто <T n , Commit>, она помещает транзакцию в повторный список.
-
Если система восстановления видит журнал с <T n , Start>, но журнал фиксации или отмены не найден, она помещает транзакцию в список отмены.
Система восстановления считывает журналы в обратном направлении от конца до последней контрольной точки.
Он поддерживает два списка: список отмены и список повторов.
Если система восстановления видит журнал с <T n , Start> и <T n , Commit> или просто <T n , Commit>, она помещает транзакцию в повторный список.
Если система восстановления видит журнал с <T n , Start>, но журнал фиксации или отмены не найден, она помещает транзакцию в список отмены.
Все транзакции в списке отмены затем отменяются и их журналы удаляются. Все транзакции в повторном списке и их предыдущие журналы удаляются и затем переделываются перед сохранением их журналов.
Эта статья содержит краткие сведения о базах данных: что это, чем они могут быть полезны, каковы функции их отдельных элементов. Здесь используется терминология, свойственная Microsoft Access, однако описываемые понятия применимы по отношению к любым базам данных.
В этой статье:
-
Что такое база данных?
-
Элементы базы данных Access
Что представляет собой база данных?
База данных — это инструмент для сбора и у организатора сведений. В базах данных могут храниться сведения о товарах, товарах, заказах и других данных. Многие базы данных начинаются с списка в word-processing program или spreadsheet. По мере роста списка в данных появляются избыточные и несоответствия. Данные становится трудно понять в форме списка, и существует ограниченный способ поиска или вывода подмног данных для проверки. Когда эти проблемы начнут появляться, лучше перенести данные в базу данных, созданную системой управления базами данных (СУБД), такой как Access.
Компьютерная база данных — это хранилище объектов. В одной базе данных может быть больше одной таблицы. Например, система отслеживания складских запасов, в которой используются три таблицы, — это не три базы данных, а одна. В базе данных Access (если ее специально не настраивали для работы с данными или кодом, принадлежащими другому источнику) все таблицы хранятся в одном файле вместе с другими объектами, такими как формы, отчеты, макросы и модули. Для файлов баз данных, созданных в формате Access 2007 (который также используется в Access 2016, Access 2013 и Access 2010), используется расширение ACCDB, а для баз данных, созданных в более ранних версиях Access, — MDB. С помощью Access 2016, Access 2013, Access 2010 и Access 2007 можно создавать файлы в форматах более ранних версий приложения (например, Access 2000 и Access 2002–2003).
Использование Access позволяет:
-
добавлять новую информацию в базу данных, например новый артикул складских запасов;
-
изменять информацию, уже находящуюся в базе, например перемещать артикул;
-
удалять информацию, например если артикул был продан или утилизирован;
-
упорядочивать и просматривать данные различными способами;
-
обмениваться данными с другими людьми с помощью отчетов, сообщений электронной почты, внутренней сети или Интернета.
Элементы базы данных Access
Ниже приведены краткие описания элементов стандартной базы данных Access.
-
Таблицы
-
Формы
-
Отчеты
-
Запросы
-
Макросы
-
Модули
Таблицы
 Таблица базы данных похожа на электронную таблицу — и там, и там информация расположена в строках и столбцах. Поэтому импортировать электронную таблицу в таблицу базы данных обычно довольно легко. Основное различие заключается в том, как данные структурированы.
Таблица базы данных похожа на электронную таблицу — и там, и там информация расположена в строках и столбцах. Поэтому импортировать электронную таблицу в таблицу базы данных обычно довольно легко. Основное различие заключается в том, как данные структурированы.
Чтобы база данных была как можно более гибкой и чтобы в ней не появлялось излишней информации, данные должны быть структурированы в виде таблиц. Например, если речь идет о таблице с информацией о сотрудниках компании, больше одного раза вводить данные об одном и том же сотруднике не нужно. Данные о товарах должны храниться в отдельной таблице, как и данные о филиалах компании. Этот процесс называется нормализацией.
Строки в таблице называются записями. В записи содержатся блоки информации. Каждая запись состоит по крайней мере из одного поля. Поля соответствуют столбцам в таблице. Например, в таблице под названием «Сотрудники» в каждой записи находится информация об одном сотруднике, а в каждом поле — отдельная категория информации, например имя, фамилия, адрес и т. д. Поля выделяются под определенные типы данных, например текстовые, цифровые или иные данные.
Еще один способ описания записей и полей — визуализация старого стиля каталога карток библиотеки. Каждая карточка в карточке соответствует записи в базе данных. Каждый фрагмент сведений на отдельной карточке (автор, заголовок и так далее) соответствует полю в базе данных.
Дополнительные сведения о таблицах см. в статье Общие сведения о таблицах.
Формы
 С помощью форм создается пользовательский интерфейс для ввода и редактирования данных. Формы часто содержат кнопки команд и другие элементы управления, предназначенные для выполнения различных функций. Можно создать базу данных, не используя формы, если просто отредактировать уже имеющуюся информацию в таблицах Access. Тем не менее, большинство пользователей предпочитает использовать формы для просмотра, ввода и редактирования информации в таблицах.
С помощью форм создается пользовательский интерфейс для ввода и редактирования данных. Формы часто содержат кнопки команд и другие элементы управления, предназначенные для выполнения различных функций. Можно создать базу данных, не используя формы, если просто отредактировать уже имеющуюся информацию в таблицах Access. Тем не менее, большинство пользователей предпочитает использовать формы для просмотра, ввода и редактирования информации в таблицах.
С помощью кнопок команд задаются данные, которые должны появляться в форме, открываются прочие формы и отчеты и выполняется ряд других задач. Например, есть «Форма клиента», в которой вы работаете с данными о клиентах. И в ней может быть кнопка, нажатием которой открывается форма заказа, с помощью которой вы вносите информацию о заказе, сделанном определенным клиентом.
Формы также дают возможность контролировать взаимодействие пользователей с информацией базы данных. Например, можно создать форму, в которой отображаются только определенные поля и с помощью которой можно выполнять только ограниченное число операций. Таким образом обеспечивается защита и корректный ввод данных.
Дополнительные сведения о формах см. в статье Формы.
Отчеты
 Отчеты используются для форматирования, сведения и показа данных. Обычно отчет позволяет найти ответ на определенный вопрос, например «Какую прибыль в этом году принесли нам наши клиенты?» или «В каких городах живут наши клиенты?» Отчеты можно форматировать таким образом, чтобы информация отображалась в наиболее читабельном виде.
Отчеты используются для форматирования, сведения и показа данных. Обычно отчет позволяет найти ответ на определенный вопрос, например «Какую прибыль в этом году принесли нам наши клиенты?» или «В каких городах живут наши клиенты?» Отчеты можно форматировать таким образом, чтобы информация отображалась в наиболее читабельном виде.
Отчет можно сформировать в любое время, и в нем всегда будет отображена текущая информация базы данных. Отчеты обычно форматируются таким образом, чтобы их можно было распечатать, но их также можно просматривать на экране, экспортировать в другие программы или вкладывать в сообщения электронной почты.
Дополнительные сведения об отчетах см. в статье «Обзор отчетов в Access».
Запросы
 Запросы могут выполнять множество функций в базе данных. Одна из их основных функций — находить информацию в таблицах. Нужная информация обычно содержится в нескольких таблицах, но, если использовать запросы, ее можно просматривать в одной. Кроме того, запросы дают возможность фильтровать данные (для этого задаются критерии поиска), чтобы отображались только нужные записи.
Запросы могут выполнять множество функций в базе данных. Одна из их основных функций — находить информацию в таблицах. Нужная информация обычно содержится в нескольких таблицах, но, если использовать запросы, ее можно просматривать в одной. Кроме того, запросы дают возможность фильтровать данные (для этого задаются критерии поиска), чтобы отображались только нужные записи.
Используются и так называемые «обновляемые» запросы, которые дают возможность редактировать данные, найденные в основных таблицах. При работе с обновляемым запросом помните, что правки вносятся в основные таблицы, а не только в таблицу запроса.
У запросов два основных вида: запросы на выборки и запросы на выполнение действий. Запрос на выборки просто извлекает данные и делает их доступными для использования. Вы можете просмотреть результаты запроса на экране, распечатать его или скопировать в буфер обмена. Вы также можете использовать выходные данные запроса в качестве источника записей для формы или отчета.
Запрос на изменение, как следует из названия, выполняет задачу с данными. С помощью запросов на изменения можно создавать новые таблицы, добавлять данные в существующие таблицы, обновлять или удалять данные.
Дополнительные сведения о запросах см. в статье Знакомство с запросами.
Макросы
 Макросы в Access — это нечто вроде упрощенного языка программирования, с помощью которого можно сделать базу данных более функциональной. Например, если к кнопке команды в форме добавить макрос, то он будет запускаться всякий раз при нажатии этой кнопки. Макросы состоят из команд, с помощью которых выполняются определенные задачи: открываются отчеты, выполняются запросы, закрывается база данных и т. д. Используя макросы, можно автоматизировать большинство операций, которые в базе данных вы делаете вручную, и, таким образом, значительно сэкономить время.
Макросы в Access — это нечто вроде упрощенного языка программирования, с помощью которого можно сделать базу данных более функциональной. Например, если к кнопке команды в форме добавить макрос, то он будет запускаться всякий раз при нажатии этой кнопки. Макросы состоят из команд, с помощью которых выполняются определенные задачи: открываются отчеты, выполняются запросы, закрывается база данных и т. д. Используя макросы, можно автоматизировать большинство операций, которые в базе данных вы делаете вручную, и, таким образом, значительно сэкономить время.
Дополнительные сведения о макросах см. в статье Общие сведения о программировании в Access.
Модули
 Подобно макросам, модули — это объекты, с помощью которых базу данных можно сделать более функциональной. Но если макросы в Access составляются путем выбора из списка макрокоманд, модули создаются на языке Visual Basic для приложений (VBA). Модули представляют собой наборы описаний, инструкций и процедур. Существуют модули класса и стандартные модули. Модули класса связаны с конкретными формами или отчетами и обычно включают в себя процедуры, которые работают только с этими формами или отчетами. В стандартных модулях содержатся общие процедуры, не связанные ни с каким объектом. Стандартные модули, в отличие от модулей класса, перечисляются в списке Модули в области навигации.
Подобно макросам, модули — это объекты, с помощью которых базу данных можно сделать более функциональной. Но если макросы в Access составляются путем выбора из списка макрокоманд, модули создаются на языке Visual Basic для приложений (VBA). Модули представляют собой наборы описаний, инструкций и процедур. Существуют модули класса и стандартные модули. Модули класса связаны с конкретными формами или отчетами и обычно включают в себя процедуры, которые работают только с этими формами или отчетами. В стандартных модулях содержатся общие процедуры, не связанные ни с каким объектом. Стандартные модули, в отличие от модулей класса, перечисляются в списке Модули в области навигации.
Дополнительные сведения о модулях см. в статье Общие сведения о программировании в Access.
К началу страницы
#статьи
- 16 янв 2023
-

0
База данных: что это такое и зачем она нужна
Рассказываем, как работают базы данных, почему их используют, какие они бывают и чем отличаются от СУБД.
Иллюстрация: Shutterstock / imgix / jms / Arina Bondar / Unsplash / Polina Vari для Skillbox Media

Любитель научной фантастики и технологического прогресса. Хорошо сочетает в себе заумного технаря и утончённого гуманитария. Пишет про IT и радуется этому.
Если вы захотите написать приложение, которое будет использовать данные пользователей, — например, интернет-магазин или игру, вам точно понадобится база данных. Как раз чтобы работать с этими данными.
В информатике базой данных называют совокупность данных, организованных по определённым правилам. Но мы дадим более простое определение.
База данных (БД) — это набор данных, который как-то структурирован. Например, можно взять сто картинок с котами и отсортировать их по цвету или по позе.

Иллюстрация: Polina Vari для Skillbox Media
Обычно данные в БД записывают в виде таблицы — строк и столбцов. В такой архитектуре каждая строка — это новый элемент, у которого есть некоторые свойства — столбцы. Тех же котов можно отсортировать по множеству параметров — например, цвету, позе и весу.
Иллюстрация: Polina Vari для Skillbox Media
Базу данных нельзя назвать программой в полном смысле этого слова. Это скорее просто файлик, в котором записаны данные. А чтобы достать из этого файла данные, сначала нужно написать программу, которая будет всё это делать, то есть управлять базой данных.
Например, вы хотите найти элемент по индексу и решили написать программу, которая умеет это делать. А затем вам вдруг понадобилось отсортировать записи в БД по каким-то параметрам. И вы пишете ещё один скрипт, который уже умеет сортировать таблицы. Так вы продолжаете создавать всё новые и новые мини-программы для разных мини-задач.
Иллюстрация: Polina Vari для Skillbox Media
В итоге у вас копится куча полезных скриптов на все случаи жизни и вы понимаете: «А зачем каждый раз писать что-то новое, объединю-ка я эти скрипты в одну программу и назову её системой управления базами данных, или СУБД». Так что СУБД позволяют просто манипулировать данными в БД — например, доставать элементы, добавлять новые и удалять ненужные, не отвлекаясь на код.
Получается, что база данных — это просто файл на диске компьютера, а СУБД — это инструменты, которые помогают управлять базами данных. Кстати, нередко базами данных называют именно СУБД, такая вот терминологическая путаница и ад для душнилы-перфекциониста.
Давайте на примере рассмотрим, зачем люди используют базы данных.
Допустим, мы открыли магазин музыкальных инструментов. Теперь нам нужно создать сайт, чтобы продавать товары в онлайне. На сайте должен находиться весь ассортимент магазина, при этом информация о наличии инструментов всегда должна поддерживаться в актуальном состоянии.
Для этого мы создадим базу данных и добавим в неё наши музыкальные инструменты. В итоге получится большая таблица, каждая строка которой — отдельный инструмент, а каждый столбец — его свойство. Среди свойств мы пока остановимся на трёх: цена, количество товара на складе и тип инструмента.
Иллюстрация: Polina Vari для Skillbox Media
Теперь, когда у нас есть база данных со всеми товарами, мы должны понять, что именно мы будем с этими данными делать. Вот основные операции, которые пригодятся интернет-магазину:
- Записать новые данные. Чтобы мы могли добавить новый инструмент, когда он приедет на склад.
- Изменить старые данные. Чтобы изменить цену товара или его количество на складе.
- Найти данные. Чтобы найти, например, все синтезаторы и показать клиенту.
- Позволить читать данные только работникам, а всем остальным закрыть доступ. Чтобы клиенты сами не меняли цены товаров и не получали их бесплатно.
- Поддерживать данные в порядке. Чтобы быть уверенным: в категории «Гитары» будут лежать именно гитары, а не барабаны.
- Масштабировать базу данных. Чтобы добавлять новые данные и не переживать об ограничениях по объёму.
- Ничего не потерять. Чтобы, даже если магазин сгорит, мы всегда могли восстановить базу данных.
Эти принципы применимы к любой базе данных, а не только к нашему примеру.
Если бегло посмотреть на базу данных и электронную таблицу, можно не увидеть разницы. Но она есть — и сейчас мы о ней расскажем.
Представим, что у нас есть Excel-таблица, в которой мы ведём учёт всех клиентов нашей компании — отмечаем, как их зовут, где они работают, зачем к нам обращались и когда в последний раз мы с ними общались. Этот Excel-файл единый для всей компании, и каждый день им пользуются десятки человек.
Вот вы садитесь за работу, открываете эту таблицу и вносите в неё какие-то изменения. Параллельно с этим ваш коллега тоже открыл её и начал вносить изменения — причём в те же колонки или строки, в которых работаете вы. Вы доделали работу, сохранили файл и закрыли его. Данные перезаписались в таблицу. Но ваш коллега не увидит эти изменения, потому что он открыл файл раньше. Поэтому когда он сохранит свой файл, то перезапишет ваши данные своими, а ваши изменения пропадут.
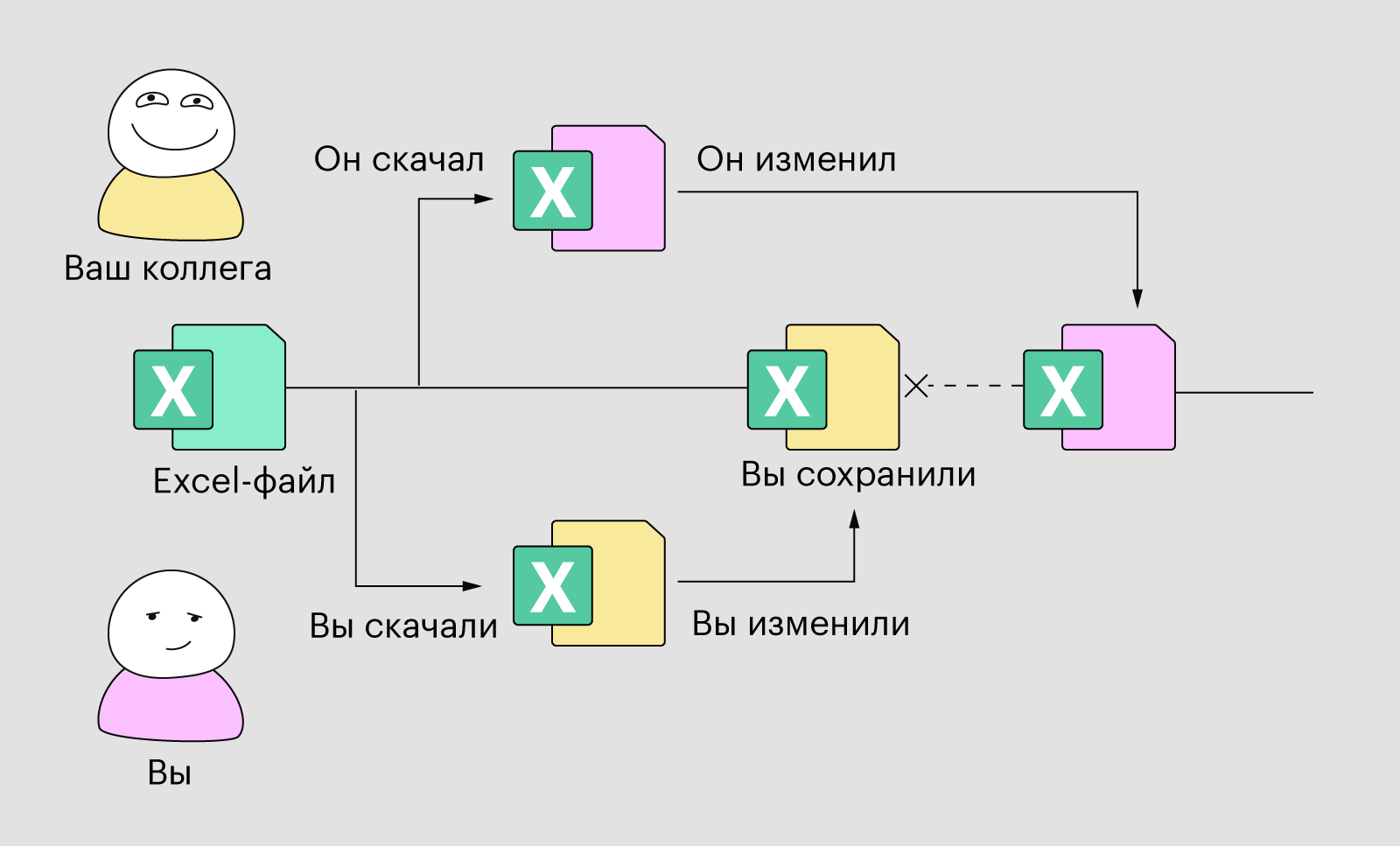
Иллюстрация: Polina Vari для Skillbox Media
С базой данных такой ситуации не произойдёт. Пусть у нас та же ситуация, но таблица — это база данных, которая управляется с помощью какой-то СУБД. Теперь каждый раз, когда вы вносите изменения, они отправляются в виде запросов в СУБД. И даже если ваш коллега будет работать с вами одновременно и тоже отправит запрос, то он встанет в очередь и будет ждать, пока не обработается предыдущий.
Иллюстрация: Polina Vari для Skillbox Media
Базы данных и СУБД обеспечивают надёжность и помогают избежать ситуаций, когда ваши изменения могут быть утрачены. Это называется разрешением коллизий.
Базы данных разделяют на два основных типа: реляционные и нереляционные. Последние делятся ещё на два: сетевые и иерархические. Получается, существует три главных типа баз данных — реляционные, сетевые и иерархические.
Ещё их называют табличными — из-за того, что все данные они хранят в виде таблиц. Эти таблицы внутри связаны друг с другом, поэтому получается такая связная структура:
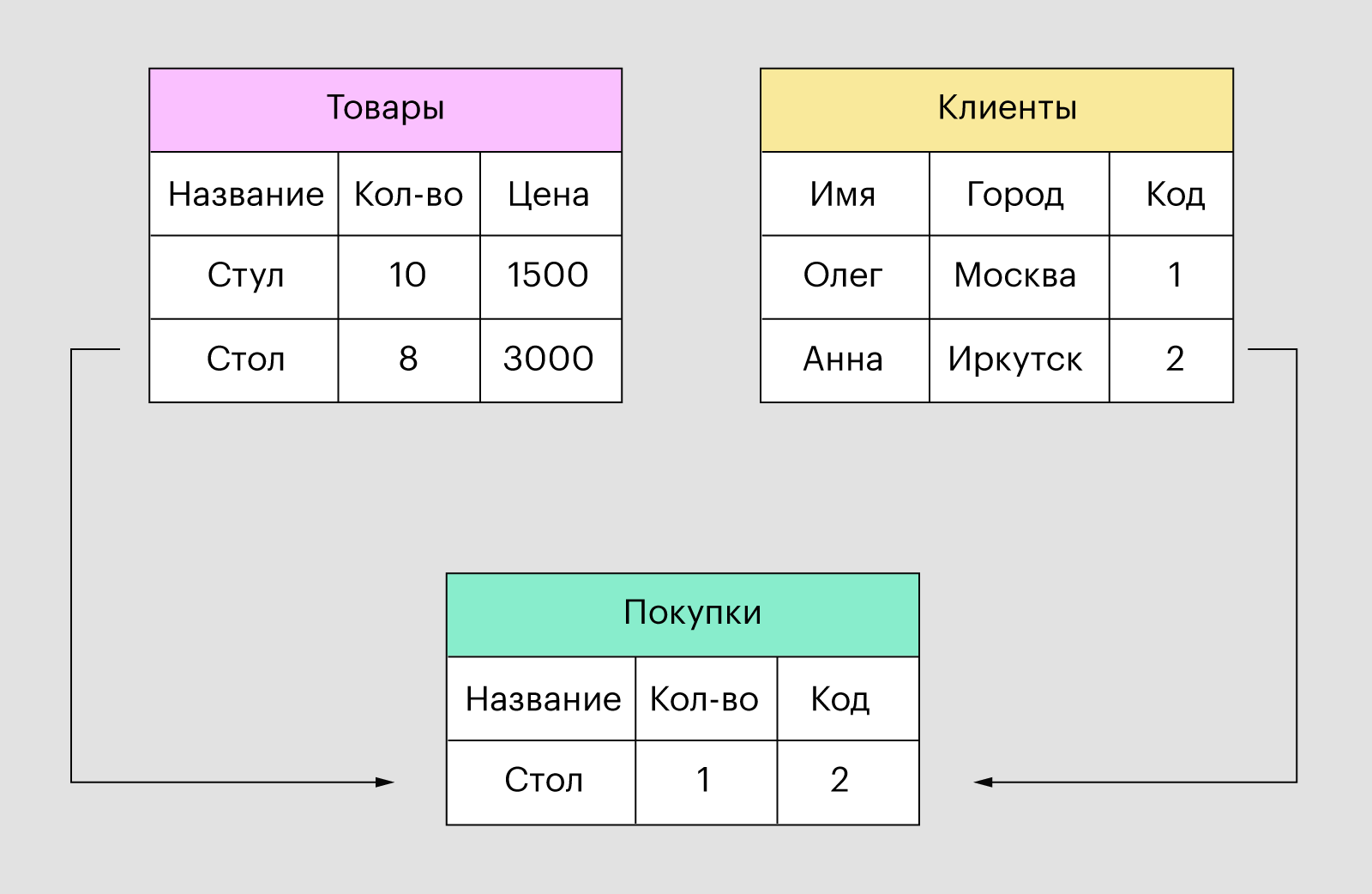
Иллюстрация: Polina Vari для Skillbox Media
У нас есть две таблицы — с покупателями и товарами. Когда покупатель что-то покупает, данные добавляются в третью таблицу. Там находится информация о купленных товарах и ссылки на них.
Такая структура хороша тем, что если поменяются какие-то данные — например, адрес покупателя, то нам нужно будет всего лишь изменить значения в одной таблице, а остальные таблицы трогать не придётся.
Их отличие от реляционных в том, что между таблицами и их записями может быть несколько разных связей. Каждая такая связь отвечает за что-то своё.
Сетевые базы данных применяют, например, в соцсетях:
Иллюстрация: Polina Vari для Skillbox Media
Вся информация в сетевой базе данных хранится в отдельных файлах. Она содержит в них сами данные и связи между ними. Базе не приходится тратить время на поиск данных, ведь вся информация уже есть в специальных файлах. В них находятся все связи, позволяющие быстро выдать результат.
Такая структура похожа на файловую систему в Windows. У каждого элемента есть вышестоящий элемент, а есть и подчинённый элемент — тот, что ниже. Поэтому по этой структуре легко перемещаться снизу вверх и сверху вниз.
Изображение: Microsoft Corporation
Иерархическая база данных знает, кто кому подчиняется, а значит, быстро находит информацию. Однако такие базы можно организовать только в том случае, если у вас есть чёткое разделение в данных и вы точно понимаете, какой элемент главный, а какой ему подчиняется.
Базы данных особо не отличаются друг от друга. Они просто хранят информацию в файле. А вот то, что отличается, — это СУБД. И обычно, когда говорят про базы данных, имеют в виду СУБД. Давайте посмотрим, какие из них популярны. Если хотите подробнее прочитать о них — смотрите нашу статью о СУБД.
СУБД имеет большую функциональность и высокую производительность — например, она без проблем может работать с большими данными под высокой нагрузкой.
Язык запросов — SQL, но его можно поменять через расширения на PL/Python, PL/Java и PL/Perl. И ещё одно преимущество PostgreSQL — в ней нет лимита по размеру баз данных и числу записей в таблицах.
Посмотреть можно на официальном сайте.
Скриншот: PostgreSQL
Интерфейс программы позволяет работать с таблицами разных форматов. MySQL работает онлайн и вмещает до 50 миллионов элементов. По функциональности она уступает PostgreSQL. При этом её можно интегрировать с другими СУБД.
MySQL использовали для сайтов и интернет-магазинов такие компании, как Twitter, Alibaba, Meta, Wikipedia.
После того как MySQL купила компания Oracle, пользователи стали немного переживать, что в скором времени база данных может стать платной. Но пока она остаётся бесплатной.
Скачать эту СУБД можно на официальном сайте.
Изображение: MySQL
Эта СУБД добавляет автоматизацию задач — например, можно задать скрипт, который будет управлять памятью. Ещё Microsoft SQL Server позволяет удобно хранить сложные структуры данных и быстро искать их.
СУБД совместима с другими программами Microsoft — например, Excel и Access. С ними можно сделать интеграцию и выгружать данные оттуда, а также изменять их онлайн.
В качестве языка запросов Microsoft SQL Server использует язык SQL.
Посмотреть можно на официальном сайте.
Изображение: Microsoft
SQLite очень компактная СУБД, которая не использует серверы и другие утилиты. Все данные хранятся на одном устройстве.
На SQLite можно написать простой сайт или приложение, у которого будет ограничен трафик и объём данных. СУБД работает на любых устройствах — смартфонах, компьютерах, ТВ и других, куда можно загрузить библиотеку. Она не нуждается в администрировании, а её язык запросов — C.
Посмотреть можно на официальном сайте.
Скриншот: sqliteexpert.com
Главная особенность этой СУБД — данные представлены в виде текстовых документов, которые записаны в формате JSON. MongoDB — NoSQL-СУБД.
Вместо таблиц здесь данные в виде коллекций — групп документов. СУБД оптимизирована для распределённой работы, но также поддерживает локальное хранение данных.
MongoDB используют такие компании, как Meta, Google, Twitter, Forbes, IBM, а также многие интернет-магазины.
Посмотреть можно на официальном сайте.
Скриншот: studio3t.com
Redis можно использовать в облаке — полностью готовую к работе и оптимально настроенную. Она легко масштабируется и управляется.
В Redis можно перенести данные из другой базы данных с помощью автоматизированного сервиса.
Посмотреть можно на официальном сайте.
Скриншот: Hector Hernandez / stackoverflow.com

Oracle DB работает как клиент-сервер. Это значит, что она располагается на сервере вместе с базой данных. Поэтому, чтобы работать с ней, нужен специальный интерфейс приложения-клиента. Пользователь управляет пересылкой и получением данных от сервиса.
Oracle DB обеспечивает высокую безопасность и лёгкий доступ для пользователей. Ещё она позволяет снизить нагрузку на клиентские компьютеры. При этом сервер для СУБД должен быть помощнее.
Посмотреть можно на официальном сайте.
Скриншот: sqlmanager.net
- База данных — это набор элементов, которые сгруппированы по определённым правилам. Они бывают реляционными, графовыми и иерархическими.
- СУБД — это инструменты, которые помогают управлять базами данных. Например, с их помощью можно удалять, изменять и находить элементы.
- Популярные СУБД — PostgreSQL, MySQL, Microsoft SQL Server, SQLite, MongoDB, Redis, Oracle Database.
- Базы данных отличаются от СУБД тем, что сами по себе представляют лишь файл на компьютере. Базы данных не умеют ничего делать с этими данными — только хранить. А вот СУБД уже предоставляют возможности по манипуляции ими.
- Электронные таблицы очень похожи на базы данных, но имеют большой недостаток: если несколько пользователей будут использовать одну таблицу одновременно, есть риск перезаписать данные друг поверх друга и потерять их. С базами данных такого не случится, потому что они обрабатывают запросы по очереди.
* Решением суда запрещена «деятельность компании Meta Platforms Inc. по реализации продуктов — социальных сетей Facebook и Instagram на территории Российской Федерации по основаниям осуществления экстремистской деятельности».

Научитесь: Профессия Веб-разработчик
Узнать больше
База данных – это хранилище, в которое можно сохранять данные, а позже делать по ним поиск и загружать их. Ну например, на форуме в базе данных может храниться информация о пользователях сайта и написанных ими сообщениях. При просмотре страницы скрипт на сервере ищет в БД сообщения на определенную тему и выводит их на странице. Почти любой интерактивный сайт использует БД.
Конечно, можно попробовать сделать свое хранилище (к примеру, на файлах), но вряд ли оно будет работать так же быстро и надежно, как профессиональная база данных. Хорошая база данных гарантирует отсутствие потерь сохраненных данных, даже если неожиданно отключится питание, отсутствие проблем при одновременной работе нескольких пользователей, позволяет искать информацию по произвольным критериям.
@sqlhub – разборы задач sql с нуля до профи.
Есть разные виды баз данных, но этот урок посвящен базам данных, поддерживающим язык SQL. В них любые операции над данными – добавление, удаление, поиск – делаются с помощью отправки SQL-запросов. Сам язык достаточно простой и запросы на нем напоминают обычные предложения на английском языке. Ну к примеру, запрос на удаление из БД пользователя с email ivan@example.com выглядит так: DELETE FROM users WHERE email = 'ivan@example.com'. Если знать английский (“удалить из пользователей где email равен ‘ivan@example.com‘”), то смысл запроса легко понять, даже не зная SQL. Запросы может отправлять как сам разработчик вручную, так и написанная им программа.
SQL – это что-то вроде стандарта в мире баз данных. Зная этот язык, можно работать с разными БД от разных производителей.
Программы, управляющие базой данных
Есть разные программы, которые позволяют создавать и управлять базой данных. Они называются СУБД (системы управления БД). Из бесплатных самые известные – это MySQL и PostgreSQL. MySQL (в 2016 году) более распространена, а в PostgreSQL больше интересных нестандартных возможностей (а также, считается что она более полно поддерживает стандарт).
Есть и коммерческие СУБД – например, MSSQL, Oracle DB.
Наконец, есть еще встраиваемые СУБД, которые используются не отдельно, а встраиваются в другую программу и используются только ей. Ну например, (в 2016 году) встроенную бесплатную СУБД SQLite использовали браузер Chrome, который хранил с ее помощью историю и закладки, Skype для хранения сообщений и множество мобильных приложений под Android и iOS.
Со всеми этими БД можно работать, зная язык SQL.
Устройство базы данных
База данных хранит данные в таблицах. Таблицы создает разработчик, и обычно каждая из них предназначается для своей сущности – например, таблица со списком пользователей, таблица тем на форуме, таблица сообщений на форуме. Таблица состоит из колонок, каждая из которых имеет определенных тип (число, строка). Ну к примеру, таблица для хранения информации о пользователях форума может выглядеть так:
| id | name | password_hash | salt | registered | |
|---|---|---|---|---|---|
| 1 | Администратор | admin@example.com | abbs09s7s6s6 | gt9xbxvx4x30 | 2014-08-02 |
| 2 | Иван | ivan@example.com | hd6bc00c8c7c665ce | gs65s4s4sb0x | 2015-01-01 |
При регистрации скрипт добавляет в нее информацию о новом пользователе, а при логине – проверяет введенные email и пароль. Мы, конечно, в целях безопасности не храним в базе сами пароли в открытом виде, а получаем из них хеш с солью и сохраняем их в колонках password_hash и salt (по которым можно проверить правильность введенного при логине пароля, но нельзя восстановить его). Также, мы присваиваем каждому пользователю уникальный числовой идентификатор (id), который еще называют первичный ключ – это позволяет потом в других таблицах ссылаться на него (например, в таблице сообщений мы можем хранить id автора сообщения, по которому можно достать информацию о нем).
А вот, как может выглядеть таблица сообщений, которые оставили пользователи на форуме. Для простоты представим, что у нас нет отдельных тем, а есть один большой общий поток сообщений:
| id | author_id | posted | text |
|---|---|---|---|
| 1 | 1 | 2014-08-03 | Добро пожаловать на наш форум! Жду ваших сообщений. |
| 2 | 1 | 2014-08-04 | Что-то никого нету… |
| 3 | 1 | 2014-08-05 | Ни души… |
| 4 | 2 | 2015-01-01 | Всем привет. Я новый тут. |
Здесь колонка id хранит идентификатор сообщения, author_id – идентификатор автора сообщения (по которому можно найти его имя, email в первой таблице), posted – дату отправки и text – тело сообщения. Первые 3 сообщения оставил Администратор, а четвертое – Иван.
Все операции с таблицами, включая их создание и заполнение делаются с помощью запросов на языке SQL. Подробнее о том, как это делать, написано ниже по ссылкам.
Работа с базой данных
Как правило сам сервер базы данных (программа, которая обеспечивает ее работу) не имеет своего интерфейса и каких-то окошек, кнопочек, чтобы с ним взаимодействовать. Управление базой данных делается с помощью запуска программы-клиента, который подсоединяется к серверу, пересылает ему SQL запросы и выводит полученные ответы. Одновременно к БД может подсоединиться несколько клиентов.
Как правило, у каждой базы данных есть клиент для командной строки. Это программа с минималистичным интерфейсом, в которой можно писать SQL запросы и видеть полученные ответы. Это то, что стоит использовать начинающему.
Те, кто освоил основы, могут использовать и более сложные программы-клиенты с графическим интерфейсом. Они могут отображать информацию из базы данных в виде таблиц, перемещаться по ним, менять значения в них. При этом можно запускать и вручную написанные SQL запросы. Я не буду тут писать названия конкретных программ, но их легко найти по словам вроде “MySQL GUI”, “MySQL admin”, “PostgreSQL GUI” и так далее. Я бы советовал сначала научиться работать исключительно в клиенте командной строки, а только потом переходить к этим программам.
Наконец, подсоединяться и отправлять запросы к БД можно из программы. Например, скрипт на языке PHP может таким образом выбирать данные из базы и отображать на веб-странице. Для этого нужна библиотека или расширение-клиент для базы данных. В PHP есть даже 2 расширения для этого (PDO и MySQLi), я рекомендую использовать расширение PDO, так как оно поддерживает исключения, за счет чего при какой-то ошибке проще получить информацию о ней.
Изучаем базы данных – ссылки
Теория и туториалы для начинающих:
- основы и туториал по MySQL (немного старый, но еще актуальный): http://phpclub.ru/mysql/doc/tutorial.html
- руководство на русском по PostgreSQL: https://postgrespro.ru/docs/postgresql
- большой учебник по SQL: http://www.pyramidin.narod.ru/rusql/index.htm
Если ты хранишь данные в нескольких таблицах, то необходимо уметь создавать связи между ними. Всего есть 3 вида связей – “один-к-одному”, “один-ко-многим”, “многие-ко-многим”. Вот уроки по этой теме:
- отношения между таблицами в БД: http://jtest.ru/bazyi-dannyix/sql-dlya-nachinayushhix-chast-3.html
- внешние ключи: http://denis.in.ua/foreign-keys-in-mysql.htm
После этого надо научиться правильно проектировать таблицы и связи между ними. Для этого надо изучить нормализацию БД. По этой теме есть разные статьи – некоторые написаны простым языком, а некоторые нет. Это важная тема, если не соблюдать принципы нормализации, то потом с такой базой будет неудобно работать.
- https://habrahabr.ru/post/129195/
- https://habrahabr.ru/post/254773/
- http://club.shelek.ru/viewart.php?id=177
- http://alexvolkov.ru/database-normalizatio.html
Поскольку это очень важная тема, я написал отдельный урок про нормализацию.
Советую изучить style guide – рекомендации по выбору названий для таблиц и колонок: http://www.sqlstyle.guide/ru/
А пока еще несколько полезных ссылок:
- сборник запросов на все случаи жизни (англ): http://www.artfulsoftware.com/infotree/queries.php
- таблицы отличий в диалектах SQL в разных СУБД (англ): http://en.wikibooks.org/wiki/SQL_dialects_reference
- манга-учебник про SQL в картинках: http://www.nostarch.com/mg_databases.htm
Под Windows в командной строке не работают русские буквы
Надо выполнить команду SET NAMES cp866; после соединения: http://gahcep.github.io/blog/2013/01/05/mysql-utf8/
Еще ссылки на тему кодировок при соединении с MySQL из PHP:
- http://fstrange.ru/coder/mysql/kodirovka-krakozyably.html
- http://phpfaq.ru/charset
Что должен знать разработчик?
Вот список понятий, которые стоит знать, если ты хочешь очень хорошо разбираться в MySQL:
- управление базами данных: CREATE DATABASE, DROP DATABASE, SHOW DATABASES
- управление таблицами: CREATE TABLE, ALTER TABLE, DROP TABLE, SHOW TABLES, SHOW CREATE TABLE, DESC table, TRUNCATE table
- управление правами доступа: GRANT, SHOW GRANTS
- типы колонок: ENUM, SET, CHAR, VARCHAR, TEXT, DATE, TIME, DATETIME, TIMESTAMP, INT, FLOAT, TINYINT, DECIMAL, MEDIUMTEXT, LONGTEXT. В чем разница между TIMESTAMP и DATETIME? Между FLOAT и DECIMAL? CHAR и VARCHAR?
- DECIMAL — тип с фиксированной точностью. В отличие от FLOAT/DOUBLE, которые приближенные и могут терять знаки после запятой, DECIMAL хранит заданное число знаков. Используется например, для хранения суммы денег.
- NULL и троичная логика (в БД NULL значит «неизвестно». Например, возраст пользователя неизвестен. Соответственно, все операции с NULL это учитывают: NULL + 5 тоже дает в итоге NULL (5 + неизвестное число дает неизвестное число), сравнение (NULL = NULL) возвращает ложь, чтобы проверить равно ли поле NULL надо использовать IS NULL/IS NOT NULL. http://ru.wikipedia.org/wiki/NULL_(SQL))
- можно ли искать пустые поля условием WHERE x = NULL?
- при создании таблицы можно сделать поля обязательными для заполнения, указав NOT NULL
- SELECT/INSERT/DELETE/UPDATE
- порядок выполнения запроса выборки: FROM+JOIN, WHERE, GROUP, HAVING, ORDER, LIMIT, SELECT (его надо знать наизусть)
- REPLACE, INSERT IGNORE, INSERT .. ON DUPLICATE KEY UPDATE
- выборка данных: DISTINCT, JOIN, ORDER BY, GROUP BY, HAVING, LIMIT
- группировка и агрегатные функции: GROUP BY, COUNT, MAX, MIN, AVG, SUM
- транзакции: BEGIN, ROLLBACK, COMMIT
- внешние ключи: FOREIGN KEY. Внешний ключ — это поле, которое хранит id записи в другой таблице
- первичный ключ: естественный и искусственный
- обычные и уникальные индексы (ключи)
- оптимизация запросов, команда EXPLAIN
- отличие InnoDB от MyISAM
Теория по проектированию БД
Чтобы уметь проектировать базы данных и новые таблицы, нужно знать следующее:
- виды отношений между таблицами: один-к-одному, один-ко-многим, многие-ко-многим
- принципы нормализации БД. В интернете можно найти статьи где “нормальные формы” объясняют простыми словами, например http://club.shelek.ru/viewart.php?id=311 или https://habrahabr.ru/post/193756/ а также, можно почитать мой урок про нормализацию
- способы хранения древовидных (иерархических) данных в БД. Ну например, это нужно для реализации дерева комментариев к статье или дерева категорий товаров в интернет-магазине. Есть такие паттерны: Adjacency List, Closure Path, Nested Sets, Materialized Path. Вот мой урок про них: https://github.com/codedokode/pasta/blob/master/db/trees.md
- способы реализации наследования таблиц (когда есть похожие, но не одинаковые сущности с общим набором свойств: например Пользователи и Администраторы, или несколько видов приложений к сообщению: Видеозапись, Аудиозапись, Файл, Ссылка на сайт). Для таких случаев есть паттерны Single Table Inheritance, Concrete table Inheritance, Class Table Inheritance
- паттерн EAV (Entity-Attribute-Value), описание на англ., на русском. Этот паттерн можно использовать в тех случаях, когда есть сущности с разным набором свойств, и свойства могут добавляться (например объявление: объявления о сдаче квартиры и продаже машины имеют разный набор свойств). Также, в интернете можно найти много обсуждений по поводу того, зло это или нет. Есть также альтернативные подходы, например в PostgreSQL можно использовать индексируемые hstore (англ.) или json (англ.) колонки
Вот цикл статей на Хабре, который подойдет в качестве вступления: 1-3, 4-6, 7-9, 10-13, 14-15, бонус
Самое главное, что надо изучить – это нормализация. Если не знать ее или не следовать ее правилам, то с базой будет неудобно работать.
Чем отличаются движки для таблиц MyISAM и InnoDB?
- http://rtfm.co.ua/mysql-otlichiya-mezhdu-myisam-i-innodb/
- http://itif.ru/otlichiya-myisam-innodb/
Если кратко: MyISAM более простой и не поддерживает внешние ключи и транзакции. А они нужны почти всегда. Потому в 99% случаев тебе нужен InnoDB.
Индексы
Индексы позволяют ускорить поиск по условиям вроде x = ?, x < ?, x BETWEEN ? AND ?, x LIKE 'xxx%', x IN (?, ?, ?), а также сортировку (поля по которым идет сортировка должны идти в конце индекса). Разница на большой таблице может быть огромная — порядка 1 тысячной секунды против нескольких секунд. Ну например, если у нас есть таблица размером в миллион записей и мы делаем запрос
SELECT a, b FROM table ORDER BY y LIMIT 10
то без индекса MySQL вынуждена будет прочитать с диска в память миллион значений, отсортировать их только ради того, чтобы взять первые 10. Если же есть индекс по полю y (который хранит отсортированные по возрастанию значения этого поля) то MySQL просто возьмет из него первые 10 записей. Разница в скорости работы будет огромная.
Вот статьи для начинающих про индексы:
- http://ruhighload.com/post/%D0%A0%D0%B0%D0%B1%D0%BE%D1%82%D0%B0+%D1%81+%D0%B8%D0%BD%D0%B4%D0%B5%D0%BA%D1%81%D0%B0%D0%BC%D0%B8+%D0%B2+MySQL
- http://www.mysql.ru/docs/man/MySQL_indexes.html
- http://habrahabr.ru/post/211022/
Если ты все прочел внимательно, ответь на вопрос, может ли индекс (если да, то какой) ускорить такие запросы:
SELECT * FROM table WHERE x <> 1SELECT * FROM table WHERE x + y < 100SELECT MAX(a) FROM table WHERE b = 2SELECT * FROM table WHERE name LIKE '%Иван%'SELECT * FROM table WHERE b = 1 AND a < 10
Задачка про лайки
С полученными знаниями ты легко сможешь решить эту задачу: есть пользователи (id, имя) и они могут ставить друг другу лайки. Сделай таблицы для хранения всей этой информации и напиши запрос, который выведет такую таблицу:
- id пользователя
- имя
- лайков получено
- лайков поставлено
- взаимных лайков
Сложно? Ну хорошо, давай начнем с более простой задачи: просто выведи 5 самых популярных пользователей.
Далее, выведи список всех пользователей, которые лайкнули пользователей A и B, но при этом не лайкнули пользователя C. Тут есть несколько вариантов решения.
- Если ты используешь несколько связанных друг с другом таблиц, связи необходимо пометить с помощью внешних ключей
- Желательно на уровне БД запретить возможность ставить пользователю лайк другому пользователю дважды (подсказка: можно использовать уникальный или первичный составной ключ)
- Подсказка: эта задача решается без подзапросов
- Подсказка: достаточно использовать всего 2 джойна и группировку
- Подсказка: изучи агрегатные функции, которые можно применять к сгруппированным данным: http://www.mysql.ru/docs/man/Group_by_functions.html
- Подсказка: для подсчета числа взаимных лайков внутри группы можно написать выражение, которое для каждой строчки вернет 0/1 в зависимости от того, обозначает она взаимный лайк или нет, а потом остается только просуммировать эти значения
- Подсказка: задача про пользователей, “которые лайкнули пользователей A и B, но при этом не лайкнули пользователя C”, решается без подзапросов и джойнов, в один проход по таблице с группировкой. Достаточно сгруппировать строки, после чего посчитать число лайков к A, B, С в каждой группе и отобрать те группы, которые соответствуют условию (HAVING).
- Подсказка: изучи функции из этого списка: http://www.mysql.ru/docs/man/Control_flow_functions.html – они тут пригодятся. С их помощью можно найти число записей, соответствующих определенному условию
Усложненная (но более жизненная) задача про лайки
В воображаемой социальной сети есть Пользователи (id, имя), Фото (id, название, автор) и Комментарии К Фото (id, текст, автор, к какому Фото относится). Необходимо добавить возможность для Пользователей ставить лайки другим Пользователям, Фото или Комментариям К Фото. Нужно реализовать такие возможности:
- пользователь не может поставить 2 лайка одной и той же сущности (например одному и тому же Фото)
- пользователь может отозвать лайк
- необходимо иметь возможность посчитать число полученных сущностью лайков и вывести список Пользователей, поставивших лайки
- в будущем могут появиться новые виды сущностей которые можно лайкать
Для начала, нужно решить задачу без оглядки на производительность. Очень желательно следовать принципам нормализации и помечать связи внешними ключами (а также на уровне БД предотвратить возможность повторной отправки лайка). Далее, можно дополнить решение комментариями по поводу оптимизаций производительности.
Тут есть несколько вариантов решения.
Задачка про кинотеатр
Вот дополнительная, более сложная задачка. Есть кинотеатр, в нем идут фильмы. У фильма есть название, длительность (пусть для простоты будет 60, 90 или 120 минут), цена билета (в разное время и дни может быть разная), время начала сеанса (один фильм может быть показан несколько раз в разное время за разную цену). Также, есть информация о купленных билетах (номер билета, на какой сеанс).
Задания:
- составь грамотную нормализованную схему хранения этих данных в БД. Внеси в нее 4-5 фильмов, расписание на один день и несколько проданных билетов.
Сделай запросы, считающие и выводящие в понятном виде:
- ошибки в расписании (фильмы накладываются друг на друга), отсортированные по возрастанию времени. Выводить надо колонки «фильм 1», «время начала», «длительность», «фильм 2», «время начала», «длительность».
- перерывы больше или равные 30 минут между фильмами, выводятся по уменьшению длительности перерыва. Выводить надо колонки «фильм 1», «время начала», «длительность», «время начала второго фильма», «длительность перерыва».
- список фильмов, для каждого указано общее число посетителей за все время, среднее число зрителей за сеанс и общая сумма сбора по каждому, отсортированные по убыванию прибыли. Внизу таблицы должна быть строчка «итого», содержащая данные по всем фильмам сразу.
- число посетителей и кассовые сборы, сгруппированные по времени начала фильма: с 9 до 15, с 15 до 18, с 18 до 21, с 21 до 00:00. (то есть сколько посетителей пришло с 9 до 15 часов, сколько с 15 до 18 и т.д.).
Сложная задача про календарь
Решил предыдущие задачи и они слишком простые? Ок, давай возьмемся за действительно сложную задачу. Напиши SQL-код, выводящий календарь на текущий месяц в виде:
| Пн | Вт | Ср | Чт | Пт | Сб | Вс |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- Подсказка: ты можешь делать запросы без таблиц, например
SELECT 2 + 3, 'Hello' - Подсказка: здесь не надо использовать циклы или процедуры
- Подсказка: функции работы с датой и временем ты можешь найти тут http://dev.mysql.com/doc/refman/5.0/en/date-and-time-functions.html (англ.)
- Подсказка: для сокращения объема кода ты можешь использовать переменные (создаются командой
SET)
select
distinct first_name, last_name
from
actor as a ;
select
last_name, count(last_name) as lnc
from
actor as a
group by
last_name
having count(last_name) > 1;
-- приоритеты логических операторов
SELECT * FROM payment p ;
SELECT
p.amount, p.payment_date
FROM
payment AS p
WHERE
p.amount > 7 AND p.payment_date > '2007-05-01'
OR
p.amount < 3 AND p.payment_date > '2007-05-05'
ORDER BY
p.amount, p.payment_date;
-- приоритеты логических операторов
SELECT DISTINCT
amount
FROM
payment AS p
WHERE
(amount = 1.99 OR amount = 4.99)
OR
(amount = 8.99 OR amount = 10.99)
ORDER BY
amount;
SELECT NOW();
SELECT EXTRACT(YEAR FROM NOW());
SELECT EXTRACT(MONTH FROM NOW());
SELECT EXTRACT(DAY FROM NOW());
SELECT EXTRACT (DOW FROM NOW());
SELECT AGE(NOW(), '2000-12-12');
SELECT EXTRACT(YEAR FROM AGE(NOW(), '2000-12-12'));
SELECT EXTRACT(EPOCH FROM '2020-12-12' - '2000-12-12');
select age('2020-08-01', '2012-03-05');
select '2015-01-11'::date - '2015-01-01'::date;
SELECT
(EXTRACT(epoch from age('2017-6-15', now())) / 86400)::int
SELECT
*
FROM
film AS f
WHERE
--title LIKE('D% C%e');
title ilike('d_i%');
-- LIKE - чувствителен к регистру
-- ilike - не чувствителен к регистру
-- % сколько угодно символов
-- _ один любой символ
SELECT
*
FROM
film f
WHERE
f.title NOT LIKE 'D%'
AND f.description LIKE '%Shark%'
AND f.rental_duration IN(3, 5);
-- функция IN(3, 5) проверяет на наличие одного из указ-х элементов
-- Работа с датами
SELECT
c.create_date
,c.last_update
FROM
customer AS c
;
SELECT
'2022-01-15 15:15:15'::DATE AS " Дата из строки"
,'2022-01-15 15:15:15' AS "Строка"
,timestamp'2022-01-15 15:15:15' AS "Дата+Время 1"
,'2022-01-15 15:15:15'::TIMESTAMP AS "Дата+Время 2"
;
SELECT
-- Использование ::DATE
'2022-01-15 15:15:15'::DATE - '2006-02-13 10:10:10' AS "::DATE 1"
,'2022-01-15'::DATE - '2022-02-13'::DATE AS "::DATE 2"
-- Использование date
,date'2022-01-15' - date'2022-02-13' AS "date 1"
,date'2022-01-15' - '2022-02-13' AS "date 2"
-- timestamp дата
,timestamp'2022-04-13' - '2022-02-13' AS "ts 1"
,timestamp'2022-04-13' - timestamp'2022-02-13' AS "ts 2"
-- timestamp дата+время
,timestamp'2022-04-13 ' - '2022-02-13' AS "ts time 1"
,timestamp'2022-04-13 15:15:15' - timestamp'2022-02-13 10:10:10' AS "ts time 2"
,'2022-04-13 15:15:15'::TIMESTAMP - '2022-02-13 10:10:10'::TIMESTAMP AS "ts time 3"
;
SELECT
'2022-04-13'::TIMESTAMP AS tm
, timestamp'2006-04-13 10:10:10' - date'2006-05-13'
;
SELECT date('2022-04-13 10:10:10') AS "date 1";
SELECT
last_update
,text(last_update )
,last_update ::TEXT
FROM
customer c;
SELECT
create_date AS "Создание"
,last_update AS "Обнова"
,concat(create_date - last_update) AS "Вычет"
,create_date - '2006-02-13' AS "Нов.вычет"
FROM
customer;
Домашнее задание №1
SELECT * FROM film f;
SELECT TEXT(f.last_update) FROM film f;
SELECT f.rental_rate FROM film f;
SELECT
f.title AS "Имя"
,f.release_year AS "Релиз"
,f.rental_rate AS "Ставка"
,round(f.rental_rate / f.rental_duration, 2) AS "Ставка в час"
FROM
film AS f
WHERE
f.rental_rate > 3
AND
f.release_year = 2006
ORDER BY
f.title;
--TEXT(f.release_year) LIKE '2006%'
--EXTRACT(YEAR FROM f.last_update) = '2006'
Домашнее задание №2
SELECT * FROM payment p;
SELECT
*
FROM
payment AS p
WHERE
p.payment_date > '2007-05-01' AND p.amount > 3
OR
p.amount > 10
ORDER BY
p.payment_date;
Домашнее задание №3
SELECT
--a.first_name || ' ' || a.last_name
CONCAT(a.first_name, ' ', a.last_name)
FROM
actor AS a
WHERE
a.first_name LIKE 'F%'
AND
a.last_name NOT LIKE '%s'
ORDER BY
a.last_update;Просмотры: 558
-
Главная
-
Инструкции
-
SQLite
-
Краткое руководство по работе с SQLite
SQLite — это внутрипроцессная библиотека, которая реализует автономный, бессерверный, не требующий настройки транзакционный механизм базы данных SQL. Исходный код для SQLite имеется в открытом доступе, позволяет модифицирование и является бесплатным. SQLite выбирают за скорость, минимализм, надёжность. В сервисах timeweb.cloud вы можете установить её на VDS-сервер.
Кстати, в официальном канале Timeweb Cloud мы собрали комьюнити из специалистов, которые говорят про IT-тренды, делятся полезными инструкциями и даже приглашают к себе работать.
Библиотека SQLite уже скомпилирована и доступна к скачиванию и установке с официального сайта. Желающие могут компилировать исходники и самостоятельно.
Для написания и исполнения запросов к базам SQLite можно использовать простую программу-оболочку командной строки — sqlite3. Но также существуют множество бесплатных (например, SQLiteStudio) и коммерческих инструментов с графическим интерфейсом для управления базами SQLite.
Установка и запуск SQLite на Windows
1. Переходим на страницу загрузки SQLite и загружаем файлы, обеспечивающие работу SQLite в Windows, в том числе sqlite3:
2. На своем компьютере создаём новую папку, например, C:sqlite.
3. Извлекаем содержимое скачанного файла в папку C:sqlite. Там должны появиться три программы:
- Sqlite3.exe
- Sqlite3_analizer.exe
- sqldiff.exe
4. В командной строке переходим в папку с sqlite3.exe и запускаем этот файл. При этом можно указать имя базы данных:
C:>cd C:sqlite
sqlite3 <имя базы данных SQLite>Если файл с таким именем не существует, то он будет создан автоматически. Если в командной строке не указано имя файла с базой данных, создается временная база данных, которая автоматически удаляется при выходе из sqlite3.
5. Пользователи Windows могут дважды кликнуть значок sqlite3.exe, чтобы открылось всплывающее окно терминала с запущенным sqlite. Однако, так как двойной клик запускает sqlite3 без аргументов, файл базы данных не будет указан, а будет использоваться временная база данных, которая удалится при завершении сеанса.
Установка и запуск SQLite на Linux
Посмотрим как установить на Linux SQLite на примере Ubuntu.
1. Чтобы установить sqlite3 в Ubuntu, сначала обновите список пакетов:
$ sudo apt update2. Затем установите sqlite3:
$ sudo apt install sqlite33. Понять, прошла ли установка, можно, проверив версию:
$ sqlite3 --versionВ случае успеха, вы получите нечто подобное:
3.38.3 2022-04-27 12:03:15 3bfa9cc97da10589251b342961df8f5f68c7399fa117345eeb516bee837balt1Как создать базу данных в SQLite
Существует несколько способов, чтобы сделать создать базу в SQLite:
1. Как отмечалось выше, при запуске sqlite3 можно указать имя базы данных:
$ sqlite3 my_first_db.dbЕсли база my_first_db.db существует, то она откроется, если нет — она будет создана и автоматически удалится при выходе из sqlite3, если к базе не было совершено ни одного запроса. Поэтому, чтобы убедиться, что база записана на диск, можно запустить пустой запрос, введя ; и нажав Enter:
sqlite> ;После работы изменения в базе можно сохранить с помощью специальной команды SQLite «.save» с указанием имени базы:
sqlite> .save my_first_db.dbили полного пути до базы:
sqlite> .save C:/sqlite/my_first_db.dbПри использовании команды «.save» стоит проявлять осторожность, так как эта команда перезапишет все ранее существовавшие файлы с таким же именем не запрашивая подтверждения.
2. В SQLite создать базу данных можно с помощью команды «.open»:
sqlite> .open my_first_db.dbКак и в первом случае, если база с указанным именем существует, то она откроется, если же не существует — то будет создана. При таком способе создания новая база данных SQLite не исчезнет при закрытии sqlite3, но все изменения перед выходом из программы нужно сохранить с помощью команды «.save», как показано выше.
3. Как уже упоминалось, при запуске sqlite3 без аргументов, будет использоваться временная база данных, которая будет удалена при завершении сеанса. Однако эту базу можно сохранить на диск с помощью команды «.save»
$ sqlite3
SQLite version 3.38.3 2022-04-27 12:03:15
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> ... many SQL commands omitted ...
sqlite> .save db1.db
sqlite>SQLite. Создание таблицы
Информация в базах SQLite хранится в виде таблиц. Для создания таблиц в SQLite используется запрос CREATE TABLE. Этот запрос должен содержать имя таблицы и имена полей (столбцов), а также может содержать типы данных, описания полей (ключевое поле) и значения по умолчанию. Например, создадим таблицу с описаниями параметров разных пород собак, применяя CREATE TABLE в SQLite:
sqlite> CREATE TABLE dog_params (id integer PRIMARY KEY,
dog_breed text,
speed_km_per_h integer,
weight_kg integer);В нашей таблице колонка id помечена как PRIMARY KEY. Это значит, что id будет ключевым столбцом (индексом) и целое число для него будет генерироваться автоматически.
Внесение записей в таблицу
Для внесения новой записи в таблицу используется SQL-запрос INSERT INTO, в котором указывается в какую таблицу и в какие поля заносить новые значения. Структура запроса:
sqlite> INSERT INTO таблица (столбец1, столбец2)
VALUES (значение1, значение2);Если количество значений соответствует количеству колонок в таблице, то названия полей можно исключить из запроса. Столбцы таблицы, которые не отображаются в списке столбцов, заполняются значением столбца по умолчанию (указывается как часть инструкции CREATE TABLE) или значением NULL, если значение по умолчанию не было указано.
Например:
sqlite> INSERT INTO dog_params (dog_breed, speed_km_per_h, weight_kg)
VALUES ("Greyhound", 72, 29);
sqlite> INSERT INTO dog_params VALUES (2, "Jack Russell Terrier", 61, 5);
sqlite> INSERT INTO dog_params VALUES (3, "Dalmation", 59, 24);В первом случае id сгенерировался сам, так как это поле назначено индексом, а для внесения строчек без указания названий колонок нужно прописывать номера id вручную.
С помощью следующего SQL-запроса можно вставить несколько записей одновременно, id опять сгенерируются автоматически:
sqlite> INSERT INTO dog_params (dog_breed, speed_km_per_h, weight_kg)
VALUES ("Borzoi", 58, 39), ("Standard Poodle", 48, 27);SQLite. Просмотр таблиц
Чтобы просмотреть всё содержимое таблицы, используется запрос SELECT:
sqlite> SELECT * FROM dog_params;Результат будет выглядеть таким образом:
1|Greyhound|72|29
2|Jack Russell Terrier|61|5
3|Dalmation|59|24
4|Borzoi|58|39
5|Standard Poodle|48|27С помощью команды WHERE можно просмотреть только те строки, которые удовлетворяют некоторому условию. Например, выведем породы, у которых скорость меньше 60 км/ч:
sqlite> SELECT * FROM dog_params WHERE speed_km_per_h < 60;
3|Dalmation|59|24
4|Borzoi|58|39
5|Standard Poodle|48|27Изменение записей в таблице
С помощью запроса ALTER TABLE и дополнительных команд можно изменять таблицу следующим образом:
- переименовать таблицу — RENAME TABLE,
- добавить колонку — ADD COLUMN,
- переименовать колонку — RENAME COLUMN,
- удалить колонку — DROP COLUMN.
К примеру, добавим в нашу таблицу колонку с высотой собаки в холке:
sqlite> ALTER TABLE dog_params ADD COLUMN height_cm integer;Чтобы изменить значения в существующих записях таблицы понадобится запрос в SQLite – Update. В этом случае возможно как изменение значений ячейки в группе строк, так и изменение значения ячейки отдельной строки.
В качестве примера, внесем значения высоты собак в холке в нашу таблицу:
sqlite> UPDATE dog_params SET height_cm=71 WHERE id=1;
sqlite> UPDATE dog_params SET height_cm=28 WHERE id=2;
sqlite> UPDATE dog_params SET height_cm=53 WHERE id=3;
sqlite> UPDATE dog_params SET height_cm=69 WHERE id=4;
sqlite> UPDATE dog_params SET height_cm=61 WHERE id=5;Наша итоговая таблица будет выглядеть так:
sqlite> SELECT * FROM dog_params:
1|Greyhound|72|29|71
2|Jack Russell Terrier|61|5|28
3|Dalmation|59|24|53
4|Borzoi|58|39|69
5|Standard Poodle|48|27|61Как пользоваться SQLiteStudio
Работать с базами данных SQLite можно не только из командной строки, но и с помощью инструментов с графическим интерфейсом, одним из которых является SQLiteStudio.
Инструмент SQLiteStudio бесплатный, портативный, интуитивно понятный и кроссплатформенный. Он предоставляет много наиболее важных функций для работы с базами данных SQLite, такие как импорт и экспорт данных в различных форматах, включая CSV, XML и JSON.
Вы можете скачать установщик SQLiteStudio или его портативную версию с официального сайта https://sqlitestudio.pl. Затем необходимо извлечь (или установить) загруженный файл в папку, например, C:sqlitegui и запустить его. Подробные инструкции по установке и работе с SQLiteStudio можно найти на сайте.