#статьи
- 30 сен 2022
-

0
Рассказываем об одном из самых популярных интернет-протоколов, на котором работает весь современный веб — HTTP.
Иллюстрация: Оля Ежак для Skillbox Media

Любитель научной фантастики и технологического прогресса. Хорошо сочетает в себе заумного технаря и утончённого гуманитария. Пишет про IT и радуется этому.
Каждый раз, когда вы включаете компьютер и заходите почитать статьи о программировании, браузер посылает куда-то какие-то запросы. Он делает это беспрерывно, пока вы сидите в интернете. Что это за запросы и зачем они нужны? Давайте разбираться.
HTTP означает «протокол передачи гипертекста» (или HyperText Transfer Protocol). Он представляет собой список правил, по которым компьютеры обмениваются данными в интернете. HTTP умеет передавать все возможные форматы файлов — например, видео, аудио, текст. Но при этом состоит только из текста.
Например, когда вы вписываете в строке браузера www.skillbox.ru, он составляет запрос и отправляет его на сервер, чтобы получить HTML-страницу сайта. Когда сервер обрабатывает запрос, то он отправляет ответ, в котором написано, что всё «ок» и вот вам сайт.
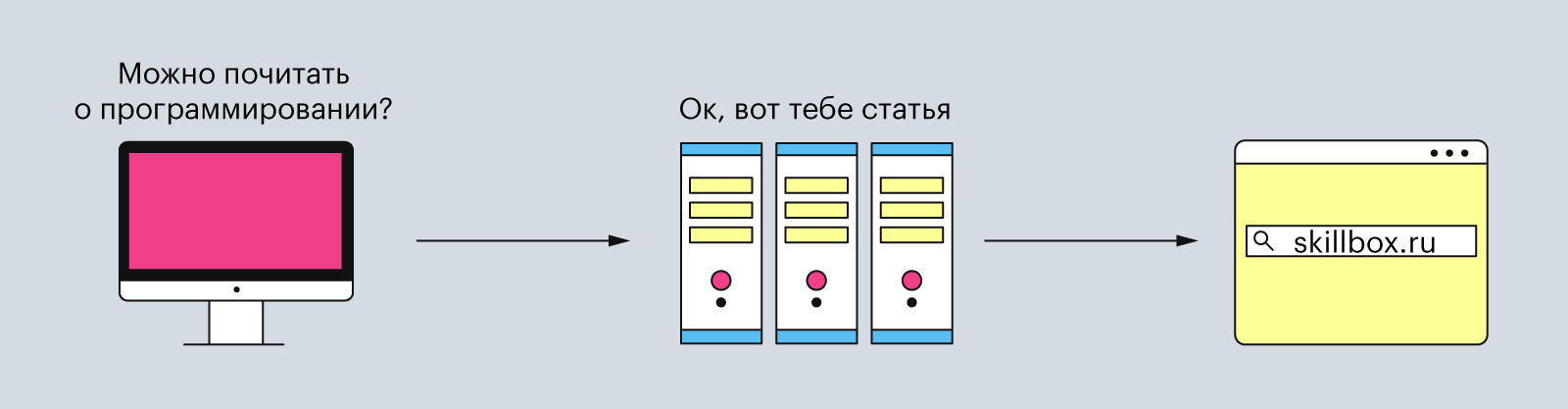
Иллюстрация: Polina Vari для Skillbox Media
Протокол HTTP используют ещё с 1992 года. Он очень простой, но при этом довольно функциональный. А ещё HTTP находится на самой вершине модели OSI (на прикладном уровне), где приложения обмениваются друг с другом данными. А работает HTTP с помощью протоколов TCP/IP и использует их, чтобы передавать данные.
Кроме HTTP в интернете работает ещё протокол HTTPS. Аббревиатура расшифровывается как «защищённый протокол передачи гипертекста» (или HyperText Transfer Protocol Secure). Он нужен для безопасной передачи данных по Сети. Всё происходит по тем же принципам, как и у HTTP, правда, перед отправкой данные дополнительно шифруются, а затем расшифровываются на сервере.
Например, HTTPS используют во время ввода данных банковской карты или паролей на сайтах — да и в целом большинство современных сайтов используют именно его.
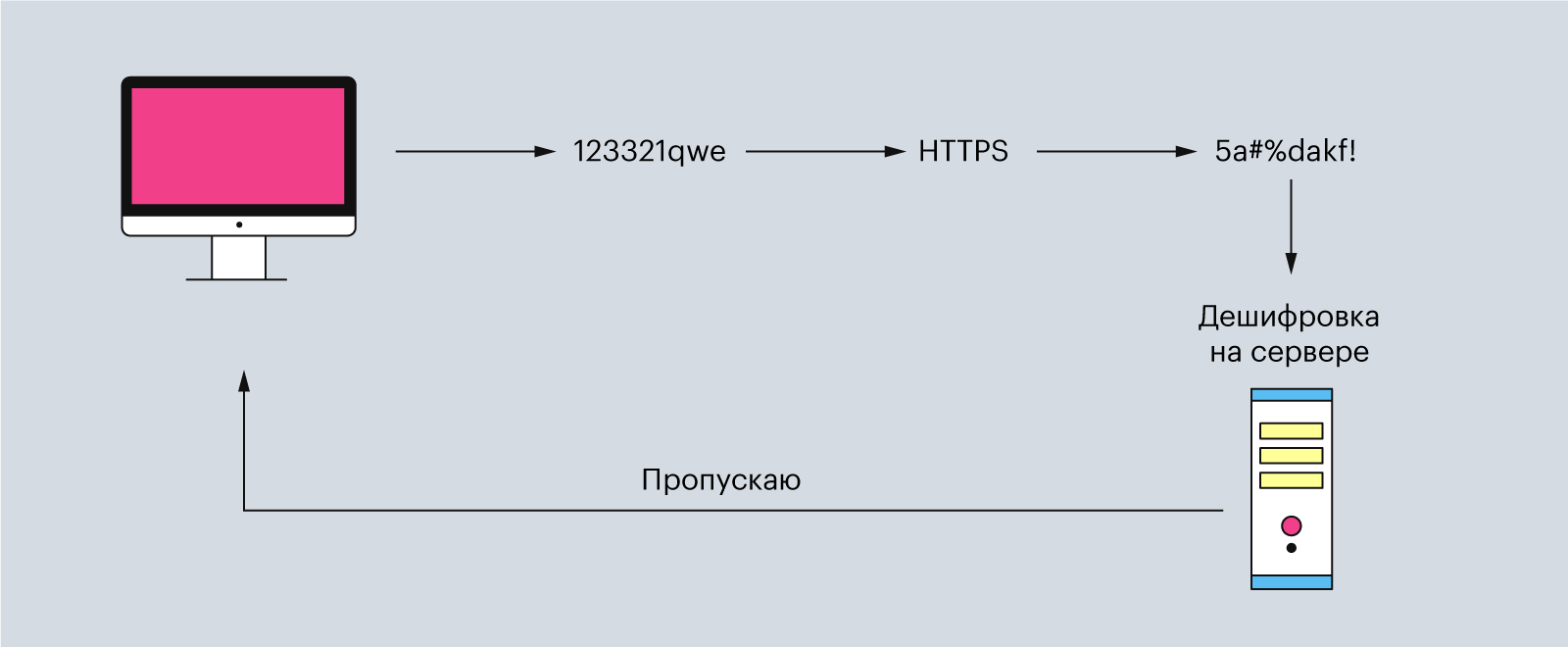
Иллюстрация: Polina Vari для Skillbox Media
HTTP состоит из двух элементов: клиента и сервера. Клиент отправляет запросы и ждёт данные от сервера. А сервер ждёт, пока ему придёт очередной запрос, обрабатывает его и возвращает ответ клиенту.
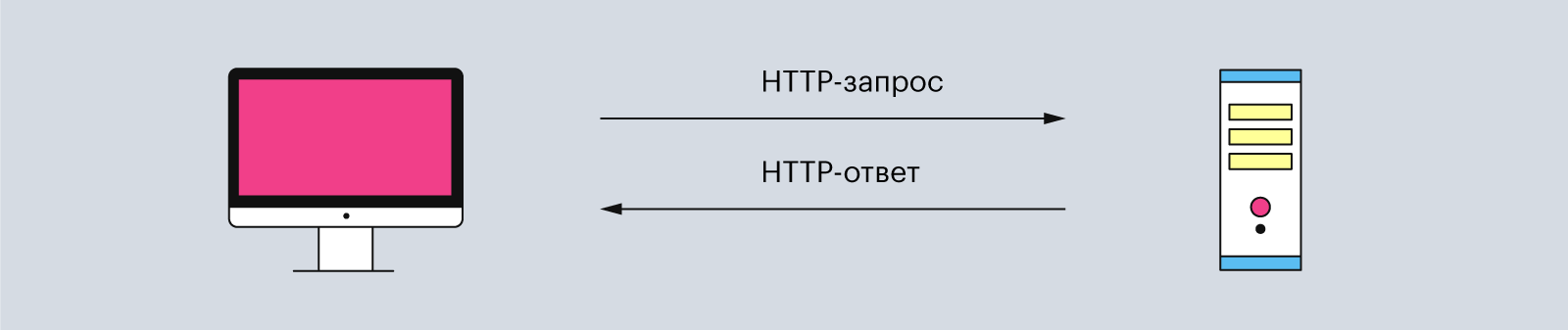
Иллюстрация: Polina Vari для Skillbox Media
Обычно эта связь между клиентом и сервером имеет посредников в виде прокси-серверов. Они нужны для разных операций — например, для безопасности и конфиденциальности, кэширования или распределения нагрузки на серверы.
Поэтому типичная процедура отправки HTTP-запроса от клиента выглядит так:
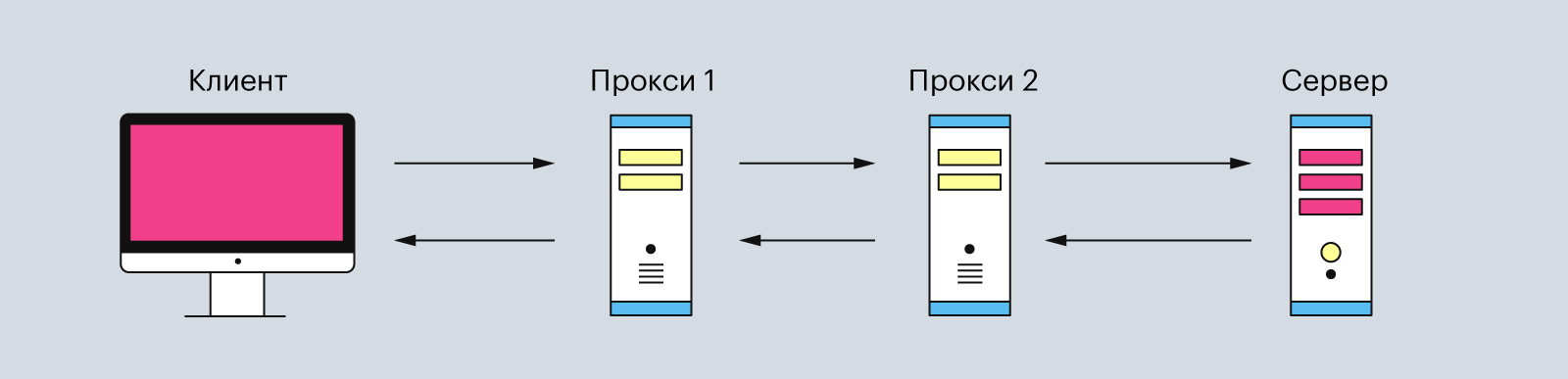
Иллюстрация: Polina Vari для Skillbox Media
Клиентом может быть любое устройство, через которое пользователь запрашивает данные. Часто в роли клиента выступает веб-браузер, программы для отладки приложений или даже командная строка. Главная особенность клиента — он всегда инициирует запрос.
Сервер — это устройство, которое обрабатывает запросы клиента. Он может состоять как из одного компьютера, так и из кластера. А ещё несколько виртуальных серверов могут находиться на одной физической машине.
Прокси-серверы — это второстепенные серверы, которые располагаются между клиентом и главным сервером. Они обрабатывают HTTP-запросы, а также ответы на них. Чаще всего прокси-серверы используют для кэширования и сжатия данных, обхода ограничений и анонимных запросов. И ещё — обычно между клиентом и основным сервером находится один или несколько таких прокси-серверов.
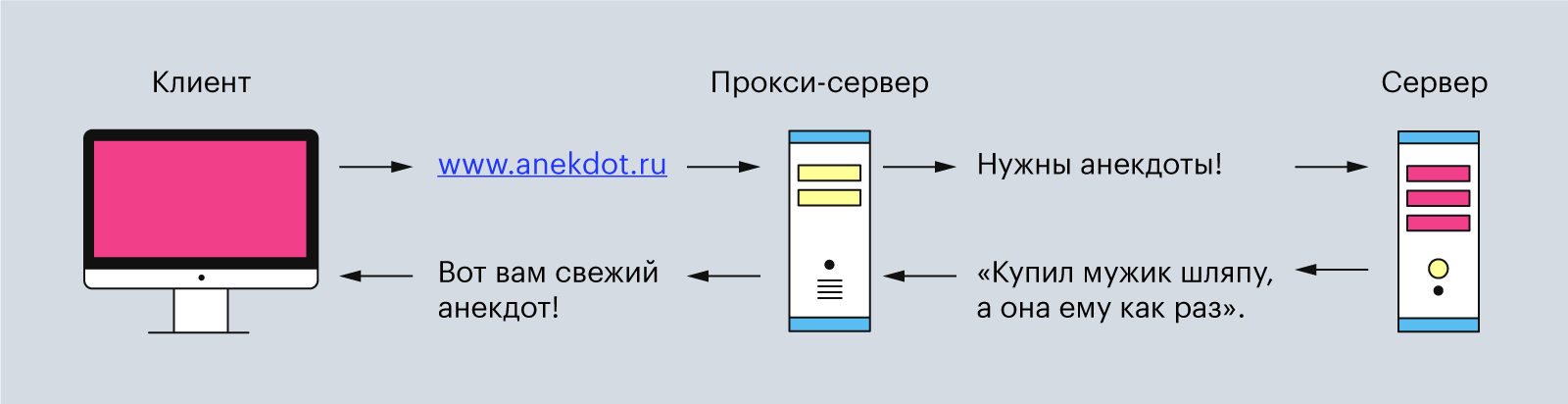
Иллюстрация: Polina Vari для Skillbox Media
Весь процесс передачи HTTP-запроса можно разбить на пять шагов. Давайте разберём их подробнее.
Чтобы отправить HTTP-запрос, нужно использовать URL-адрес — это «унифицированный указатель ресурса» (или Uniform Resource Locator). Он указывает браузеру, что нужно использовать HTTP-протокол, а затем получить файл с этого адреса обратно. Обычно URL-адреса начинаются с http:// или https:// (зависит от версии протокола).
Например, http://www.skillbox.ru — это URL-адрес. Он представляет собой главную страницу Skillbox. Но также в URL-адресе могут быть и поддомены — http://www.skillbox.ru/media. Теперь мы запросили главную страницу Skillbox Media.
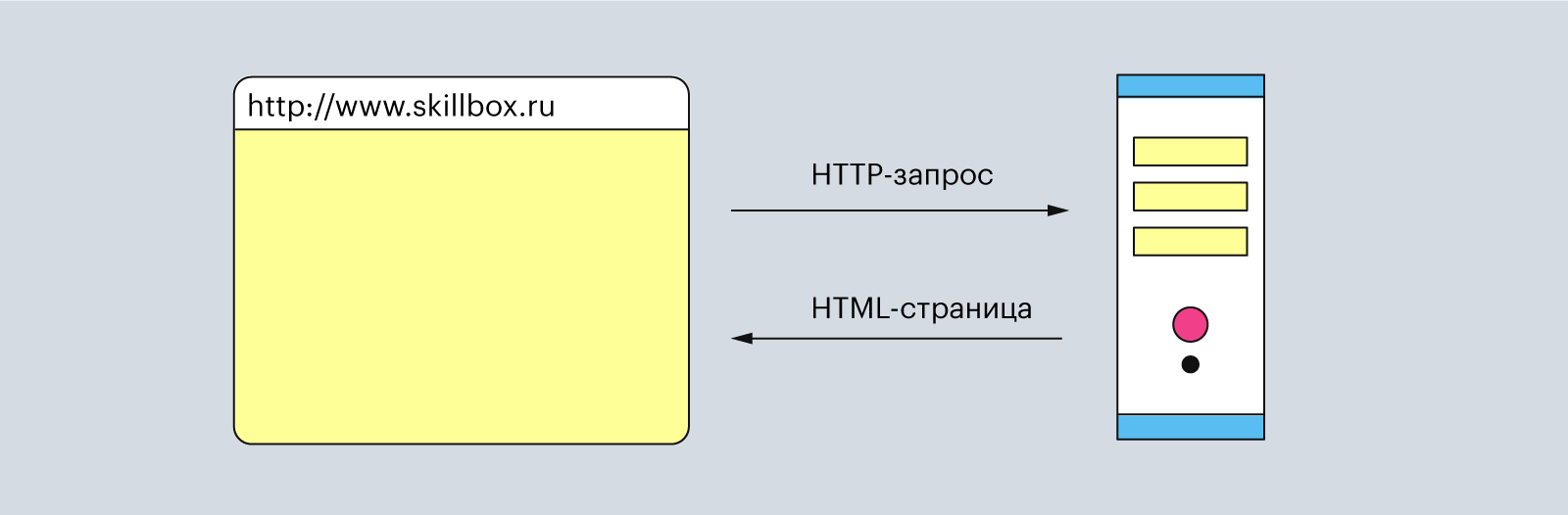
Иллюстрация: Polina Vari для Skillbox Media
Для пользователей URL-адрес — это набор понятных слов: Skillbox, Yandex, Google. Но для компьютера эти понятные нам слова — набор непонятных символов.
Поэтому браузер отправляет введённые вами слова в DNS, преобразователь URL-адресов в IP-адреса. DNS расшифровывается как «доменная система имён» (Domain Name System), и его можно представить как огромную таблицу со всеми зарегистрированными именами для сайтов и их IP-адресами.
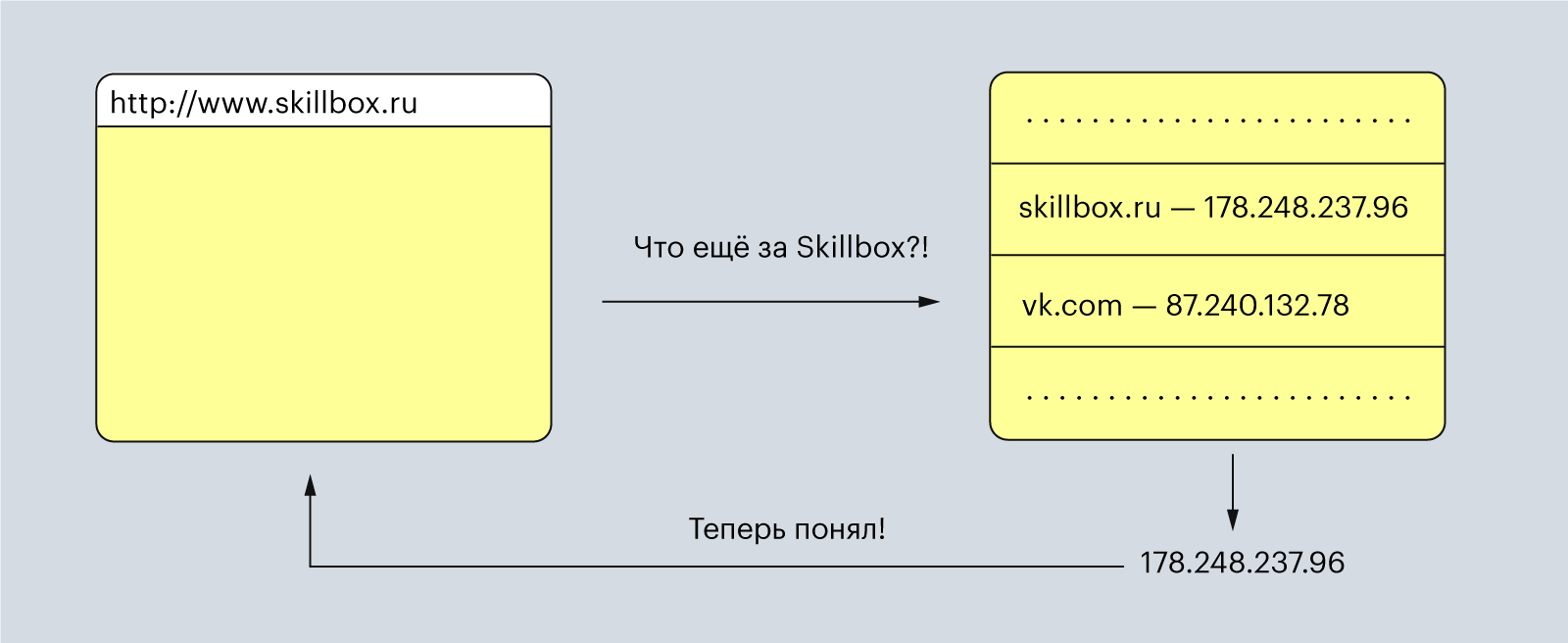
Иллюстрация: Polina Vari для Skillbox Media
DNS возвращает браузеру IP-адрес, с которым тот уже умеет работать. Теперь браузер начинает составлять HTTP-запрос с вложенным в него IP-адресом.
Сам HTTP-запрос может выглядеть так:

Здесь четыре элемента: метод — «GET», URI — «/», версия HTTP — «1.1» и адрес хоста — «www.skillbox.ru». Давайте разберём каждый из них подробнее.
Метод — это действие, которое клиент ждёт от сервера. Например, отправить ему HTML-страницу сайта или скачать документ. Протокол HTTP не ограничивает количество разных методов, но программисты договорились между собой использовать только три основных:
- GET — чтобы получить данные с сервера. Например, видео с YouTube или мем с Reddit.
- POST — чтобы отправить данные на сервер. Например, сообщение в Telegram или новый трек в SoundCloud.
- HEAD — чтобы получить только метаданные об HTML-странице сайта. Это те данные, которые находятся в <head>-теге HTML-файла.
URI расшифровывается как «унифицированный идентификатор ресурса» (или Uniform Resource Identifier) — это полный адрес сайта в Сети. Он состоит из двух частей: URL и URN. Первое — это адрес хоста. Например, www.skillbox.ru или www.vk.com. Второе — это то, что ставится после URL и символа / — например, для URI www.skillbox.ru/media URN-адресом будет /media. URN ещё можно назвать адресом до конкретного файла на сайте.
Версия HTTP указывает, какую версию HTTP браузер использует при отправке запроса. Если её не указывать, по умолчанию будет стоять версия 1.1. Она нужна, чтобы сервер вернул HTTP-ответ с той же версией HTTP-протокола и не создал ошибок с чтением у клиента.
Адрес хоста нужен, чтобы указать, с какого сайта клиент пытается получить данные. Адрес указывают в виде домена, но он сразу же меняется на IP-адрес перед отправкой запроса с помощью DNS.

Иллюстрация: Polina Vari для Skillbox Media
После получения и обработки HTTP-запроса сервер создаёт ответ и отправляет его обратно клиенту. В нём содержатся дополнительная информация (метаданные) и запрашиваемые данные.
Простой HTTP-ответ выглядит так:

Здесь три главные части: статус ответа — HTTP/1.1 200 OK, заголовки Content-Type и Content-Length и тело ответа — HTML-код. Рассмотрим их подробнее.
Статус ответа содержит версию HTTP-протокола, который клиент указал в HTTP-запросе. А после неё идёт код статуса ответа — 200, что означает успешное получение данных. Затем — словесное описание статуса ответа: «ок».
Всего статусов в спецификации HTTP 1.1 — 40. Вот самые популярные из них:
- 200 OK — данные успешно получены;
- 201 Created — значит, что запрос успешный, а данные созданы. Его используют, чтобы подтверждать успех запросов PUT или POST;
- 300 Moved Permanently — указывает, что URL-адрес изменили навсегда;
- 400 Bad Request — означает неверно сформированный запрос. Обычно это случается в связке с запросами POST и PUT, когда данные не прошли проверку или представлены в неправильном формате;
- 401 Unauthorized — нужно выполнить аутентификацию перед тем, как запрашивать доступ к ресурсу;
- 404 Not Found — значит, что не удалось найти запрашиваемый ресурс;
- 405 Forbidden — говорит, что указанный метод HTTP не поддерживается для запрашиваемого ресурса;
- 409 Conflict — произошёл конфликт. Например, когда клиент хочет создать дважды данные с помощью запроса PUT;
- 500 Internal Server Error — означает ошибку со стороны сервера.
Заголовки помогают браузеру разобраться с полученными данными и представить их в правильном виде. Например, заголовок Content-Type сообщает, какой формат файла пришёл и какие у него дополнительные параметры, а Content-Length — сколько места в байтах занимает этот файл.
Тело ответа содержит в себе сам файл. Например, сервер может вернуть код HTML-документа или отправить JPEG-картинку.

Иллюстрация: Polina Vari для Skillbox Media
Как только браузер получил ответ с веб-страницей, он отображает её с помощью внутреннего движка. И на этом весь процесс отправки и получение HTTP-запросов заканчивается, а клиент получает нужные ему данные.
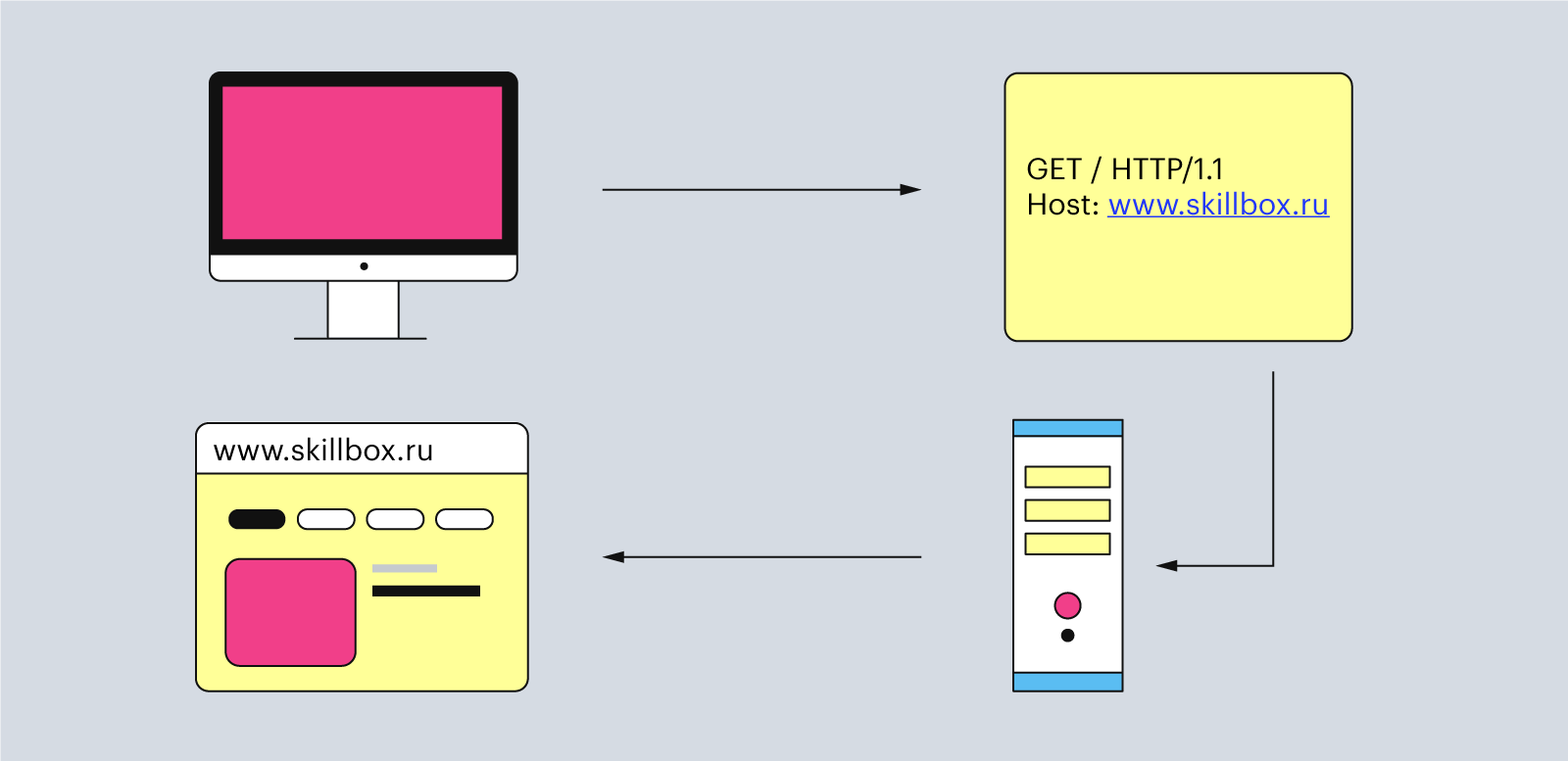
Иллюстрация: Polina Vari для Skillbox Media
- HTTP-протокол — это набор правил, по которым компьютеры обмениваются данными друг с другом. Его инициирует клиент (в данном случае — человек, заходящий в интернет с любого устройства), а обрабатывает сервер и возвращает обратно клиенту. Между ними могут находиться прокси-серверы, которые занимаются дополнительными задачами — шифрованием данных, перераспределением нагрузки или кэшированием.
- HTTP-запрос содержит четыре элемента: метод, URI, версию HTTP и адрес хоста. Метод указывает, какое действие нужно совершить. URI — это путь до конкретного файла на сайте. Версию HTTP нужно указывать, чтобы избежать ошибок, а адрес хоста помогает браузеру определить, куда отправлять HTTP-запрос.
- HTTP-ответ имеет три части: статус ответа, заголовки и тело ответа. В статусе ответа сообщается, всё ли прошло успешно и возникли ли ошибки. В заголовках указывается дополнительная информация, которая помогает браузеру корректно отобразить файл. А в тело ответа сервер кладёт запрашиваемый файл.

Научитесь: Профессия Веб-разработчик
Узнать больше
HTTP (HyperText Transfer Protocol — протокол передачи гипертекста) — символьно-ориентированный клиент-серверный протокол прикладного уровня без сохранения состояния, используемый сервисом World Wide Web.
Основным объектом манипуляции в HTTP является ресурс, на который указывает URI (Uniform Resource Identifier – уникальный идентификатор ресурса) в запросе клиента. Основными ресурсами являются хранящиеся на сервере файлы, но ими могут быть и другие логические (напр. каталог на сервере) или абстрактные объекты (напр. ISBN). Протокол HTTP позволяет указать способ представления (кодирования) одного и того же ресурса по различным параметрам: mime-типу, языку и т. д. Благодаря этой возможности клиент и веб-сервер могут обмениваться двоичными данными, хотя данный протокол является текстовым.
Структура протокола¶
Структура протокола определяет, что каждое HTTP-сообщение состоит из трёх частей (рис. 1), которые передаются в следующем порядке:
- Стартовая строка (англ. Starting line) — определяет тип сообщения;
- Заголовки (англ. Headers) — характеризуют тело сообщения, параметры передачи и прочие сведения;
- Тело сообщения (англ. Message Body) — непосредственно данные сообщения. Обязательно должно отделяться от заголовков пустой строкой.
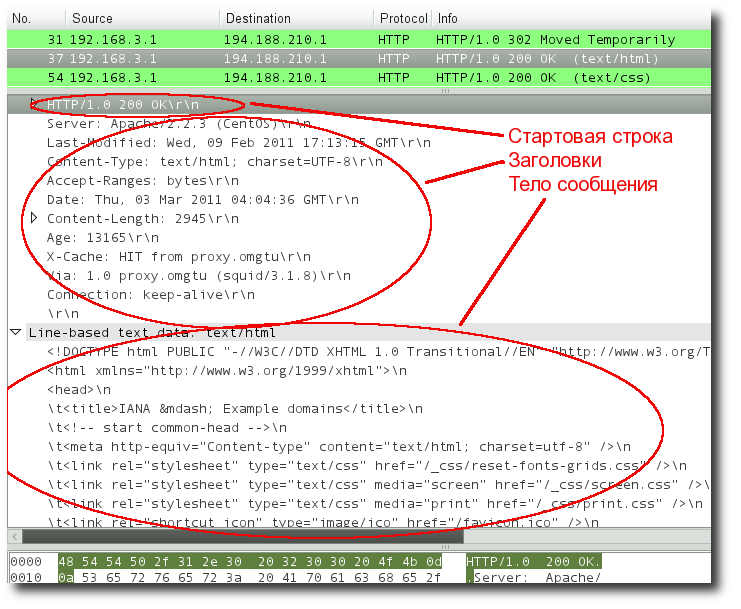
Рис. 1. Структура протокола HTTP (дамп пакета, полученный сниффером Wireshark)
Стартовая строка HTTP¶
Cтартовая строка является обязательным элементом, так как указывает на тип запроса/ответа, заголовки и тело сообщения могут отсутствовать.
Стартовые строки различаются для запроса и ответа. Строка запроса выглядит так:
Метод URI HTTP/Версия протокола
Пример запроса:
GET /web-programming/index.html HTTP/1.1
Стартовая строка ответа сервера имеет следующий формат:
HTTP/Версия КодСостояния [Пояснение]
Например, на предыдущий наш запрос клиентом данной страницы сервер ответил строкой:
HTTP/1.1 200 Ok
Методы протокола¶
Метод HTTP (англ. HTTP Method) — последовательность из любых символов, кроме управляющих и разделителей, указывающая на основную операцию над ресурсом. Обычно метод представляет собой короткое английское слово, записанное заглавными буквами (Табл. 1). Названия метода чувствительны к регистру.
Таблица 1. Методы протокола HTTP
| Метод | Краткое описание |
|---|---|
| OPTIONS |
Используется для определения возможностей веб-сервера или параметров соединения для конкретного ресурса. Для того чтобы узнать возможности всего сервера, клиент должен указать в URI звёздочку — «*». Запросы «OPTIONS * HTTP/1.1» могут также применяться для проверки работоспособности сервера (аналогично «пингованию») и тестирования на предмет поддержки сервером протокола HTTP версии 1.1. Результат выполнения этого метода не кэшируется. |
| GET |
Используется для запроса содержимого указанного ресурса. С помощью метода GET можно также начать какой-либо процесс. В этом случае в тело ответного сообщения следует включить информацию о ходе выполнения процесса. Согласно стандарту HTTP, запросы типа GET считаются идемпотентными[4] — многократное повторение одного и того же запроса GET должно приводить к одинаковым результатам (при условии, что сам ресурс не изменился за время между запросами). Это позволяет кэшировать ответы на запросы GET. Кроме обычного метода GET, различают ещё условный GET и частичный GET. Условные запросы GET содержат заголовки If-Modified-Since, If-Match, If-Range и подобные. Частичные GET содержат в запросе Range. Порядок выполнения подобных запросов определён стандартами отдельно. |
| HEAD |
Аналогичен методу GET, за исключением того, что в ответе сервера отсутствует тело. Запрос HEAD обычно применяется для извлечения метаданных, проверки наличия ресурса (валидация URL) и чтобы узнать, не изменился ли он с момента последнего обращения. Заголовки ответа могут кэшироваться. При несовпадении метаданных ресурса с соответствующей информацией в кэше копия ресурса помечается как устаревшая. |
| POST |
Применяется для передачи пользовательских данных заданному ресурсу. Например, в блогах посетители обычно могут вводить свои комментарии к записям в HTML-форму, после чего они передаются серверу методом POST и он помещает их на страницу. При этом передаваемые данные (в примере с блогами — текст комментария) включаются в тело запроса. Аналогично с помощью метода POST обычно загружаются файлы. В отличие от метода GET, метод POST не считается идемпотентным[4], то есть многократное повторение одних и тех же запросов POST может возвращать разные результаты (например, после каждой отправки комментария будет появляться одна копия этого комментария). При результатах выполнения 200 (Ok) и 204 (No Content) в тело ответа следует включить сообщение об итоге выполнения запроса. Если был создан ресурс, то серверу следует вернуть ответ 201 (Created) с указанием URI нового ресурса в заголовке Location. Сообщение ответа сервера на выполнение метода POST не кэшируется. |
| PUT |
Применяется для загрузки содержимого запроса на указанный в запросе URI. Если по заданному URI не существовало ресурса, то сервер создаёт его и возвращает статус 201 (Created). Если же был изменён ресурс, то сервер возвращает 200 (Ok) или 204 (No Content). Сервер не должен игнорировать некорректные заголовки Content-* передаваемые клиентом вместе с сообщением. Если какой-то из этих заголовков не может быть распознан или не допустим при текущих условиях, то необходимо вернуть код ошибки 501 (Not Implemented). Фундаментальное различие методов POST и PUT заключается в понимании предназначений URI ресурсов. Метод POST предполагает, что по указанному URI будет производиться обработка передаваемого клиентом содержимого. Используя PUT, клиент предполагает, что загружаемое содержимое соответствуют находящемуся по данному URI ресурсу. Сообщения ответов сервера на метод PUT не кэшируются. |
| PATCH |
Аналогично PUT, но применяется только к фрагменту ресурса. |
| DELETE |
Удаляет указанный ресурс. |
| TRACE |
Возвращает полученный запрос так, что клиент может увидеть, что промежуточные сервера добавляют или изменяют в запросе. |
| LINK |
Устанавливает связь указанного ресурса с другими. |
| UNLINK |
Убирает связь указанного ресурса с другими. |
Каждый сервер обязан поддерживать как минимум методы GET и HEAD. Если сервер не распознал указанный клиентом метод, то он должен вернуть статус 501 (Not Implemented). Если серверу метод известен, но он не применим к конкретному ресурсу, то возвращается сообщение с кодом 405 (Method Not Allowed). В обоих случаях серверу следует включить в сообщение ответа заголовок Allow со списком поддерживаемых методов.
Наиболее востребованными являются методы GET и POST — на человеко-ориентированных ресурсах, POST — роботами поисковых машин и оффлайн-браузерами.
Примечание
Прокси-сервер
Прокси — это транзитный сервер, перенаправляющий HTTP-трафик. Прокси-серверы используются для ускорения выполнения запросов путем кэширования веб-страниц. В локальной сети применяется как межсетевой экран и средство управления HTTP-трафиком (например, для блокирования доступа к некоторым ресурсам). В Интернете прокси часто используют для анонимизации запросов — в этом случае веб-сервер получает ip-адрес прокси-сервера, а не реального клиента. В современных браузерах можно задать целый список прокси и переключаться между серверами из этого списка по мере необходимости (обычно такая возможность доступна через расширения или плагины браузера).
Коды состояния¶
Код состояния информирует клиента о результатах выполнения запроса и определяет его дальнейшее поведение. Набор кодов состояния является стандартом, и все они описаны в соответствующих документах RFC.
Каждый код представляется целым трехзначным числом. Первая цифра указывает на класс состояния, последующие — порядковый номер состояния (рис 1.). За кодом ответа обычно следует краткое описание на английском языке.
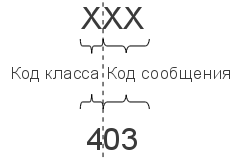
Рис. 1. Структура кода состояния HTTP
Введение новых кодов должно производиться только после согласования с IETF. Клиент может не знать все коды состояния, но он обязан отреагировать в соответствии с классом кода.
Применяемые в настоящее время классы кодов состояния и некоторые примеры ответов сервера приведены в табл. 2.
Таблица 2. Коды состояния протокола HTTP
| Класс кодов | Краткое описание |
|---|---|
| 1xx Informational (Информационный) |
В этот класс выделены коды, информирующие о процессе передачи. В HTTP/1.0 сообщения с такими кодами должны игнорироваться. В HTTP/1.1 клиент должен быть готов принять этот класс сообщений как обычный ответ, но ничего отправлять серверу не нужно. Сами сообщения от сервера содержат только стартовую строку ответа и, если требуется, несколько специфичных для ответа полей заголовка. Прокси-сервера подобные сообщения должны отправлять дальше от сервера к клиенту. Примеры ответов сервера: 100 Continue (Продолжать) 101 Switching Protocols (Переключение протоколов) 102 Processing (Идёт обработка) |
| 2xx Success (Успешно) |
Сообщения данного класса информируют о случаях успешного принятия и обработки запроса клиента. В зависимости от статуса сервер может ещё передать заголовки и тело сообщения. Примеры ответов сервера: 200 OK (Успешно). 201 Created (Создано) 202 Accepted (Принято) 204 No Content (Нет содержимого) 206 Partial Content (Частичное содержимое) |
| 3xx Redirection (Перенаправление) |
Коды статуса класса 3xx сообщают клиенту, что для успешного выполнения операции нужно произвести следующий запрос к другому URI. В большинстве случаев новый адрес указывается в поле Location заголовка. Клиент в этом случае должен, как правило, произвести автоматический переход (жарг. «редирект»). Обратите внимание, что при обращении к следующему ресурсу можно получить ответ из этого же класса кодов. Может получиться даже длинная цепочка из перенаправлений, которые, если будут производиться автоматически, создадут чрезмерную нагрузку на оборудование. Поэтому разработчики протокола HTTP настоятельно рекомендуют после второго подряд подобного ответа обязательно запрашивать подтверждение на перенаправление у пользователя (раньше рекомендовалось после 5-го). За этим следить обязан клиент, так как текущий сервер может перенаправить клиента на ресурс другого сервера. Клиент также должен предотвратить попадание в круговые перенаправления. Примеры ответов сервера: 300 Multiple Choices (Множественный выбор) 301 Moved Permanently (Перемещено навсегда) 304 Not Modified (Не изменялось) |
| 4xx Client Error (Ошибка клиента) |
Класс кодов 4xx предназначен для указания ошибок со стороны клиента. При использовании всех методов, кроме HEAD, сервер должен вернуть в теле сообщения гипертекстовое пояснение для пользователя. Примеры ответов сервера: 401 Unauthorized (Неавторизован) 402 Payment Required (Требуется оплата) 403 Forbidden (Запрещено) 404 Not Found (Не найдено) 405 Method Not Allowed (Метод не поддерживается) 406 Not Acceptable (Не приемлемо) 407 Proxy Authentication Required (Требуется аутентификация прокси) |
| 5xx Server Error (Ошибка сервера) |
Коды 5xx выделены под случаи неудачного выполнения операции по вине сервера. Для всех ситуаций, кроме использования метода HEAD, сервер должен включать в тело сообщения объяснение, которое клиент отобразит пользователю. Примеры ответов сервера: 500 Internal Server Error (Внутренняя ошибка сервера) 502 Bad Gateway (Плохой шлюз) 503 Service Unavailable (Сервис недоступен) 504 Gateway Timeout (Шлюз не отвечает) |
Заголовки HTTP¶
Заголовок HTTP (HTTP Header) — это строка в HTTP-сообщении, содержащая разделённую двоеточием пару вида «параметр-значение». Формат заголовка соответствует общему формату заголовков текстовых сетевых сообщений ARPA (RFC 822). Как правило, браузер и веб-сервер включают в сообщения более чем по одному заголовку. Заголовки должны отправляться раньше тела сообщения и отделяться от него хотя бы одной пустой строкой (CRLF).
Название параметра должно состоять минимум из одного печатного символа (ASCII-коды от 33 до 126). После названия сразу должен следовать символ двоеточия. Значение может содержать любые символы ASCII, кроме перевода строки (CR, код 10) и возврата каретки (LF, код 13).
Пробельные символы в начале и конце значения обрезаются. Последовательность нескольких пробельных символов внутри значения может восприниматься как один пробел. Регистр символов в названии и значении не имеет значения (если иное не предусмотрено форматом поля).
Пример заголовков ответа сервера:
Server: Apache/2.2.3 (CentOS) Last-Modified: Wed, 09 Feb 2011 17:13:15 GMT Content-Type: text/html; charset=UTF-8 Accept-Ranges: bytes Date: Thu, 03 Mar 2011 04:04:36 GMT Content-Length: 2945 Age: 51 X-Cache: HIT from proxy.omgtu Via: 1.0 proxy.omgtu (squid/3.1.8) Connection: keep-alive 200 OK
Все HTTP-заголовки разделяются на четыре основных группы:
- General Headers (Основные заголовки) — должны включаться в любое сообщение клиента и сервера.
- Request Headers (Заголовки запроса) — используются только в запросах клиента.
- Response Headers (Заголовки ответа) — присутствуют только в ответах сервера.
- Entity Headers (Заголовки сущности) — сопровождают каждую сущность сообщения.
Сущности (entity, в переводах также встречается название “объект”) — это полезная информация, передаваемая в запросе или ответе. Сущность состоит из метаинформации (заголовки) и непосредственно содержания (тело сообщения).
В отдельный класс заголовки сущности выделены, чтобы не путать их с заголовками запроса или заголовками ответа при передаче множественного содержимого (multipart/*). Заголовки запроса и ответа, как и основные заголовки, описывают всё сообщение в целом и размещаются только в начальном блоке заголовков, в то время как заголовки сущности характеризуют содержимое каждой части в отдельности, располагаясь непосредственно перед её телом.
В таблице 3 приведено краткое описание некоторых HTTP-заголовков.
Таблица 3. Заголовки HTTP
| Заголовок | Группа | Краткое описание |
|---|---|---|
| Allow | Entity | Список методов, применимых к запрашиваемому ресурсу. |
| Content-Encoding | Entity | Применяется при необходимости перекодировки содержимого (например, gzip/deflated). |
| Content-Language | Entity | Локализация содержимого (язык(и)) |
| Content-Length | Entity | Размер тела сообщения (в октетах) |
| Content-Range | Entity | Диапазон (используется для поддержания многопоточной загрузки или дозагрузки) |
| Content-Type | Entity | Указывает тип содержимого (mime-type, например text/html).Часто включает указание на таблицу символов локали (charset) |
| Expires | Entity | Дата/время, после которой ресурс считается устаревшим. Используется прокси-серверами |
| Last-Modified | Entity | Дата/время последней модификации сущности |
| Cache-Control | General | Определяет директивы управления механизмами кэширования. Для прокси-серверов. |
| Connection | General | Задает параметры, требуемые для конкретного соединения. |
| Date | General | Дата и время формирования сообщения |
| Pragma | General | Используется для специальных указаний, которые могут (опционально) применяется к любому получателю по всей цепочке запросов/ответов (например, pragma: no-cache). |
| Transfer-Encoding | General | Задает тип преобразования, применимого к телу сообщения. В отличие от Content-Encoding этот заголовок распространяется на все сообщение, а не только на сущность. |
| Via | General | Используется шлюзами и прокси для отображения промежуточных протоколов и узлов между клиентом и веб-сервером. |
| Warning | General | Дополнительная информация о текущем статусе, которая не может быть представлена в сообщении. |
| Accept | Request | Определяет применимые типы данных, ожидаемых в ответе. |
| Accept-Charset | Request | Определяет кодировку символов (charset) для данных, ожидаемых в ответе. |
| Accept-Encoding | Request | Определяет применимые форматы кодирования/декодирования содержимого (напр, gzip) |
| Accept-Language | Request | Применимые языки. Используется для согласования передачи. |
| Authorization | Request | Учетные данные клиента, запрашивающего ресурс. |
| From | Request | Электронный адрес отправителя |
| Host | Request | Имя/сетевой адрес [и порт] сервера. Если порт не указан, используется 80. |
| If-Modified-Since | Request | Используется для выполнения условных методов (Если-Изменился…). Если запрашиваемый ресурс изменился, то он передается с сервера, иначе — из кэша. |
| Max-Forwards | Request | Представляет механиз ограничения количества шлюзов и прокси при использовании методов TRACE и OPTIONS. |
| Proxy-Authorization | Request | Используется при запросах, проходящих через прокси, требующие авторизации |
| Referer | Request | Адрес, с которого выполняется запрос. Этот заголовок отсутствует, если переход выполняется из адресной строки или, например, по ссылке из js-скрипта. |
| User-Agent | Request | Информация о пользовательском агенте (клиенте) |
| Location | Response | Адрес перенаправления |
| Proxy-Authenticate | Response | Сообщение о статусе с кодом 407. |
| Server | Response | Информация о программном обеспечении сервера, отвечающего на запрос (это может быть как веб- так и прокси-сервер). |
В листинге 1 приведен фрагмент дампа заголовков при подключении к серверу http://example.org
Листинг 1. Заголовки HTTP
http://www.example.org/ GET http://www.example.org/ HTTP/1.1 Host: www.example.org User-Agent: Mozilla/5.0 (X11; U; Linux i686; ru; rv:1.9.2.13) Gecko/20101203 SUSE/3.6.13-0.2.1 Firefox/3.6.13 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: ru-ru,ru;q=0.8,en-us;q=0.5,en;q=0.3 Accept-Encoding: gzip,deflate Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7 Keep-Alive: 115 Proxy-Connection: keep-alive HTTP/1.0 302 Moved Temporarily Date: Thu, 03 Mar 2011 06:48:28 GMT Location: http://www.iana.org/domains/example/ Server: BigIP Content-Length: 0 X-Cache: MISS from proxy.omgtu Via: 1.0 proxy.omgtu (squid/3.1.8) Connection: keep-alive ---------------------------------------------------------- http://www.iana.org/domains/example/ GET http://www.iana.org/domains/example/ HTTP/1.1 Host: www.iana.org User-Agent: Mozilla/5.0 (X11; U; Linux i686; ru; rv:1.9.2.13) Gecko/20101203 SUSE/3.6.13-0.2.1 Firefox/3.6.13 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: ru-ru,ru;q=0.8,en-us;q=0.5,en;q=0.3 Accept-Encoding: gzip,deflate Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7 Keep-Alive: 115 Proxy-Connection: keep-alive HTTP/1.0 200 OK Server: Apache/2.2.3 (CentOS) Last-Modified: Wed, 09 Feb 2011 17:13:15 GMT Content-Type: text/html; charset=UTF-8 Accept-Ranges: bytes Date: Thu, 03 Mar 2011 04:04:36 GMT Content-Length: 2945 Age: 9858 X-Cache: HIT from proxy.omgtu Via: 1.0 proxy.omgtu (squid/3.1.8) Connection: keep-alive ....
Несколько полезных примеров php-скриптов, обрабатывающих HTTP-заголовки, приведены в статье «Использование файла .htaccess» (редирект, отправка кода ошибки, установка last-modified и т.п.).
Тело сообщения¶
Тело HTTP сообщения (message-body), если оно присутствует, используется для передачи сущности, связанной с запросом или ответом. Тело сообщения (message-body) отличается от тела сущности (entity-body) только в том случае, когда при передаче применяется кодирование, указанное в заголовке Transfer-Encoding. В остальных случаях тело сообщения идентично телу сущности.
Заголовок Transfer-Encoding должен отправляться для указания любого кодирования передачи, примененного приложением в целях гарантирования безопасной и правильной передачи сообщения. Transfer-Encoding — это свойство сообщения, а не сущности, и оно может быть добавлено или удалено любым приложением в цепочке запросов/ответов.
Присутствие тела сообщения в запросе отмечается добавлением к заголовкам запроса поля заголовка Content-Length или Transfer-Encoding. Тело сообщения (message-body) может быть добавлено в запрос только когда метод запроса допускает тело объекта (entity-body).
Все ответы содержат тело сообщения, возможно нулевой длины, кроме ответов на запрос методом HEAD и ответов с кодами статуса 1xx (Информационные), 204 (Нет содержимого, No Content), и 304 (Не модифицирован, Not Modified).
Контрольные вопросы¶
- В каком случае клиент получит от сервера ответ с кодом 418?
Время на прочтение
9 мин
Количество просмотров 1.3M
Вашему вниманию предлагается описание основных аспектов протокола HTTP — сетевого протокола, с начала 90-х и по сей день позволяющего вашему браузеру загружать веб-страницы. Данная статья написана для тех, кто только начинает работать с компьютерными сетями и заниматься разработкой сетевых приложений, и кому пока что сложно самостоятельно читать официальные спецификации.
HTTP — широко распространённый протокол передачи данных, изначально предназначенный для передачи гипертекстовых документов (то есть документов, которые могут содержать ссылки, позволяющие организовать переход к другим документам).
Аббревиатура HTTP расшифровывается как HyperText Transfer Protocol, «протокол передачи гипертекста». В соответствии со спецификацией OSI, HTTP является протоколом прикладного (верхнего, 7-го) уровня. Актуальная на данный момент версия протокола, HTTP 1.1, описана в спецификации RFC 2616.
Протокол HTTP предполагает использование клиент-серверной структуры передачи данных. Клиентское приложение формирует запрос и отправляет его на сервер, после чего серверное программное обеспечение обрабатывает данный запрос, формирует ответ и передаёт его обратно клиенту. После этого клиентское приложение может продолжить отправлять другие запросы, которые будут обработаны аналогичным образом.
Задача, которая традиционно решается с помощью протокола HTTP — обмен данными между пользовательским приложением, осуществляющим доступ к веб-ресурсам (обычно это веб-браузер) и веб-сервером. На данный момент именно благодаря протоколу HTTP обеспечивается работа Всемирной паутины.
Также HTTP часто используется как протокол передачи информации для других протоколов прикладного уровня, таких как SOAP, XML-RPC и WebDAV. В таком случае говорят, что протокол HTTP используется как «транспорт».
API многих программных продуктов также подразумевает использование HTTP для передачи данных — сами данные при этом могут иметь любой формат, например, XML или JSON.
Как правило, передача данных по протоколу HTTP осуществляется через TCP/IP-соединения. Серверное программное обеспечение при этом обычно использует TCP-порт 80 (и, если порт не указан явно, то обычно клиентское программное обеспечение по умолчанию использует именно 80-й порт для открываемых HTTP-соединений), хотя может использовать и любой другой.
Как отправить HTTP-запрос?
Самый простой способ разобраться с протоколом HTTP — это попробовать обратиться к какому-нибудь веб-ресурсу вручную. Представьте, что вы браузер, и у вас есть пользователь, который очень хочет прочитать статьи Анатолия Ализара.
Предположим, что он ввёл в адресной строке следующее:
http://alizar.habrahabr.ru/
Соответственно вам, как веб-браузеру, теперь необходимо подключиться к веб-серверу по адресу alizar.habrahabr.ru.
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
telnet alizar.habrahabr.ru 80
Сразу уточню, что если вы вдруг передумаете, то нажмите Ctrl + «]», и затем ввод — это позволит вам закрыть HTTP-соединение. Помимо telnet можете попробовать nc (или ncat) — по вкусу.
После того, как вы подключитесь к серверу, нужно отправить HTTP-запрос. Это, кстати, очень легко — HTTP-запросы могут состоять всего из двух строчек.
Для того, чтобы сформировать HTTP-запрос, необходимо составить стартовую строку, а также задать по крайней мере один заголовок — это заголовок Host, который является обязательным, и должен присутствовать в каждом запросе. Дело в том, что преобразование доменного имени в IP-адрес осуществляется на стороне клиента, и, соответственно, когда вы открываете TCP-соединение, то удалённый сервер не обладает никакой информацией о том, какой именно адрес использовался для соединения: это мог быть, например, адрес alizar.habrahabr.ru, habrahabr.ru или m.habrahabr.ru — и во всех этих случаях ответ может отличаться. Однако фактически сетевое соединение во всех случаях открывается с узлом 212.24.43.44, и даже если первоначально при открытии соединения был задан не этот IP-адрес, а какое-либо доменное имя, то сервер об этом никак не информируется — и именно поэтому этот адрес необходимо передать в заголовке Host.
Стартовая (начальная) строка запроса для HTTP 1.1 составляется по следующей схеме:
Метод URI HTTP/Версия
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
GET / HTTP/1.1
Метод (в англоязычной тематической литературе используется слово method, а также иногда слово verb — «глагол») представляет собой последовательность из любых символов, кроме управляющих и разделителей, и определяет операцию, которую нужно осуществить с указанным ресурсом. Спецификация HTTP 1.1 не ограничивает количество разных методов, которые могут быть использованы, однако в целях соответствия общим стандартам и сохранения совместимости с максимально широким спектром программного обеспечения как правило используются лишь некоторые, наиболее стандартные методы, смысл которых однозначно раскрыт в спецификации протокола.
URI (Uniform Resource Identifier, унифицированный идентификатор ресурса) — путь до конкретного ресурса (например, документа), над которым необходимо осуществить операцию (например, в случае использования метода GET подразумевается получение ресурса). Некоторые запросы могут не относиться к какому-либо ресурсу, в этом случае вместо URI в стартовую строку может быть добавлена звёздочка (астериск, символ «*»). Например, это может быть запрос, который относится к самому веб-серверу, а не какому-либо конкретному ресурсу. В этом случае стартовая строка может выглядеть так:
OPTIONS * HTTP/1.1
Версия определяет, в соответствии с какой версией стандарта HTTP составлен запрос. Указывается как два числа, разделённых точкой (например 1.1).
Для того, чтобы обратиться к веб-странице по определённому адресу (в данном случае путь к ресурсу — это «/»), нам следует отправить следующий запрос:
GET / HTTP/1.1
Host: alizar.habrahabr.ru
При этом учитывайте, что для переноса строки следует использовать символ возврата каретки (Carriage Return), за которым следует символ перевода строки (Line Feed). После объявления последнего заголовка последовательность символов для переноса строки добавляется дважды.
Впрочем, в спецификации HTTP рекомендуется программировать HTTP-сервер таким образом, чтобы при обработке запросов в качестве межстрочного разделителя воспринимался символ LF, а предшествующий символ CR, при наличии такового, игнорировался. Соответственно, на практике бо́льшая часть серверов корректно обработает и такой запрос, где заголовки отделены символом LF, и он же дважды добавлен после объявления последнего заголовка.
Если вы хотите отправить запрос в точном соответствии со спецификацией, можете воспользоваться управляющими последовательностями r и n:
echo -en "GET / HTTP/1.1rnHost: alizar.habrahabr.rurnrn" | ncat alizar.habrahabr.ru 80
Как прочитать ответ?
Стартовая строка ответа имеет следующую структуру:
HTTP/Версия Код состояния Пояснение
Версия протокола здесь задаётся так же, как в запросе.
Код состояния (Status Code) — три цифры (первая из которых указывает на класс состояния), которые определяют результат совершения запроса. Например, в случае, если был использован метод GET, и сервер предоставляет ресурс с указанным идентификатором, то такое состояние задаётся с помощью кода 200. Если сервер сообщает о том, что такого ресурса не существует — 404. Если сервер сообщает о том, что не может предоставить доступ к данному ресурсу по причине отсутствия необходимых привилегий у клиента, то используется код 403. Спецификация HTTP 1.1 определяет 40 различных кодов HTTP, а также допускается расширение протокола и использование дополнительных кодов состояний.
Пояснение к коду состояния (Reason Phrase) — текстовое (но не включающее символы CR и LF) пояснение к коду ответа, предназначено для упрощения чтения ответа человеком. Пояснение может не учитываться клиентским программным обеспечением, а также может отличаться от стандартного в некоторых реализациях серверного ПО.
После стартовой строки следуют заголовки, а также тело ответа. Например:
HTTP/1.1 200 OK
Server: nginx/1.2.1
Date: Sat, 08 Mar 2014 22:53:46 GMT
Content-Type: application/octet-stream
Content-Length: 7
Last-Modified: Sat, 08 Mar 2014 22:53:30 GMT
Connection: keep-alive
Accept-Ranges: bytes
Wisdom
Тело ответа следует через два переноса строки после последнего заголовка. Для определения окончания тела ответа используется значение заголовка Content-Length (в данном случае ответ содержит 7 восьмеричных байтов: слово «Wisdom» и символ переноса строки).
Но вот по тому запросу, который мы составили ранее, веб-сервер вернёт ответ не с кодом 200, а с кодом 302. Таким образом он сообщает клиенту о том, что обращаться к данному ресурсу на данный момент нужно по другому адресу.
Смотрите сами:
HTTP/1.1 302 Moved Temporarily
Server: nginx
Date: Sat, 08 Mar 2014 22:29:53 GMT
Content-Type: text/html
Content-Length: 154
Connection: keep-alive
Keep-Alive: timeout=25
Location: http://habrahabr.ru/users/alizar/
<html>
<head><title>302 Found</title></head>
<body bgcolor="white">
<center><h1>302 Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
В заголовке Location передан новый адрес. Теперь URI (идентификатор ресурса) изменился на /users/alizar/, а обращаться нужно на этот раз к серверу по адресу habrahabr.ru (впрочем, в данном случае это тот же самый сервер), и его же указывать в заголовке Host.
То есть:
GET /users/alizar/ HTTP/1.1
Host: habrahabr.ru
В ответ на этот запрос веб-сервер Хабрахабра уже выдаст ответ с кодом 200 и достаточно большой документ в формате HTML.
Если вы уже успели вжиться в роль, то можете теперь прочитать полученный от сервера HTML-код, взять карандаш и блокнот, и нарисовать профайл Ализара — в принципе, именно этим бы на вашем месте браузер сейчас и занялся.
А что с безопасностью?
Сам по себе протокол HTTP не предполагает использование шифрования для передачи информации. Тем не менее, для HTTP есть распространённое расширение, которое реализует упаковку передаваемых данных в криптографический протокол SSL или TLS.
Название этого расширения — HTTPS (HyperText Transfer Protocol Secure). Для HTTPS-соединений обычно используется TCP-порт 443. HTTPS широко используется для защиты информации от перехвата, а также, как правило, обеспечивает защиту от атак вида man-in-the-middle — в том случае, если сертификат проверяется на клиенте, и при этом приватный ключ сертификата не был скомпрометирован, пользователь не подтверждал использование неподписанного сертификата, и на компьютере пользователя не были внедрены сертификаты центра сертификации злоумышленника.
На данный момент HTTPS поддерживается всеми популярными веб-браузерами.
А есть дополнительные возможности?
Протокол HTTP предполагает достаточно большое количество возможностей для расширения. В частности, спецификация HTTP 1.1 предполагает возможность использования заголовка Upgrade для переключения на обмен данными по другому протоколу. Запрос с таким заголовком отправляется клиентом. Если серверу требуется произвести переход на обмен данными по другому протоколу, то он может вернуть клиенту ответ со статусом «426 Upgrade Required», и в этом случае клиент может отправить новый запрос, уже с заголовком Upgrade.
Такая возможность используется, в частности, для организации обмена данными по протоколу WebSocket (протокол, описанный в спецификации RFC 6455, позволяющий обеим сторонам передавать данные в нужный момент, без отправки дополнительных HTTP-запросов): стандартное «рукопожатие» (handshake) сводится к отправке HTTP-запроса с заголовком Upgrade, имеющим значение «websocket», на который сервер возвращает ответ с состоянием «101 Switching Protocols», и далее любая сторона может начать передавать данные уже по протоколу WebSocket.
Что-то ещё, кстати, используют?
На данный момент существуют и другие протоколы, предназначенные для передачи веб-содержимого. В частности, протокол SPDY (произносится как английское слово speedy, не является аббревиатурой) является модификацией протокола HTTP, цель которой — уменьшить задержки при загрузке веб-страниц, а также обеспечить дополнительную безопасность.
Увеличение скорости обеспечивается посредством сжатия, приоритизации и мультиплексирования дополнительных ресурсов, необходимых для веб-страницы, чтобы все данные можно было передать в рамках одного соединения.
Опубликованный в ноябре 2012 года черновик спецификации протокола HTTP 2.0 (следующая версия протокола HTTP после версии 1.1, окончательная спецификация для которой была опубликована в 1999) базируется на спецификации протокола SPDY.
Многие архитектурные решения, используемые в протоколе SPDY, а также в других предложенных реализациях, которые рабочая группа httpbis рассматривала в ходе подготовки черновика спецификации HTTP 2.0, уже ранее были получены в ходе разработки протокола HTTP-NG, однако работы над протоколом HTTP-NG были прекращены в 1998.
На данный момент поддержка протокола SPDY есть в браузерах Firefox, Chromium/Chrome, Opera, Internet Exporer и Amazon Silk.
И что, всё?
В общем-то, да. Можно было бы описать конкретные методы и заголовки, но фактически эти знания нужны скорее в том случае, если вы пишете что-то конкретное (например, веб-сервер или какое-то клиентское программное обеспечение, которое связывается с серверами через HTTP), и для базового понимания принципа работы протокола не требуются. К тому же, всё это вы можете очень легко найти через Google — эта информация есть и в спецификациях, и в Википедии, и много где ещё.
Впрочем, если вы знаете английский и хотите углубиться в изучение не только самого HTTP, но и используемых для передачи пакетов TCP/IP, то рекомендую прочитать вот эту статью.
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.
Удачи и плодотворного обучения!
Learning the fundamentals of the World Wide Web is crucial, especially if you are planning to build web apps. And HTTP is at the heart of any web application you could build.
HTTP stands for Hypertext Transfer Protocol. It’s a stateless, application-layer protocol for communicating between distributed systems, and it’s the foundation of the modern web.
In this article, I’ll start with the basics. I’ll explain the aspects of HTTP that any potential web developer should know. Then we’ll dive into the deeper and more advanced theories of HTTP.
HTTP Is a Hypertext Transfer Protocol
When you open a website in a browser, you see text, images, and embedded content. All this content is loaded from servers elsewhere on the web. It is the role of the browser—also called a client—to raise a request for this content. The request is sent to a server, which in return sends a response back to the browser. Both the request and the response are sent as human-readable text.


Every request raised by the browser is independent. The HTTP protocol is stateless. That means that each individual request needs to carry all the information needed to fulfill it. In an HTTP request, this information is passed through headers.
The HTTP protocol supports a mix of network configurations. The browser is one of the many possible clients which can raise a request. The requests are sent, and responses are received over the TCP/IP layer. The default port for HTTP communication is port 80, but this can be configured differently for different applications.
HTTP Versions
- Currently, clients use version HTTP/2.0. Recent releases of Chrome, Firefox, Safari, and Edge all support HTTP/2.0. This version of HTTP allows the client to send multiple requests simultaneously. This technique is known as multiplexing. It cuts down on the time required to load a page.
- HTTP/1.1 was revised in the year 2014. This version allows only a single outstanding request with every TCP/IP connection. This mechanism is also known as baseline.
- HTTP/0.9 was the original version of the protocol. Currently, this version is completely deprecated.
The flow diagram, below, explains why HTTP/2.0 is better than HTTP/1.1.
As seen, HTTP/2.0 allows the client to request for both the style and script simultaneously. Likewise, the style and script get loaded at the same time. The entire process gets completed in a single TCP connection.



Also, HTTP/2.0 comes with smart packet management strategies and header compression mechanisms to cut down on latency.
HTTP URLs
Requests are sent to servers specified with Uniform Resource Locators (URLs). I’m sure you are already familiar with URLs, but for the sake of completeness, I’ll include it here. URLs have a simple structure that consists of the following components:
https://www.domain.com:1234/path/to/resource?a=b&x=y
- https specifies the protocol. It can be http or https, which makes the communication secure.
- www.domain.com is the host.
- 1234 is the port. In many cases, the browser hides the port. The default is 80.
- path/to/resource is the resource path. It helps the server identify a specific resource and generate the right response.
- ?a=b&x=y are query string parameters. Query string parameters are used by the server to spot the right resource.
The URL identifies the specific host with which the client wants to communicate. It does not perform any action. This is where the request comes. HTTP has a formalized way of framing requests that capture all the required pieces of information, which can be applied by any kind of application.
HTTP Requests
At the heart of web communications is the request message. A request is made up of the following parts:
- request line: this says what is being requested. It consists of a verb, a path, and the HTTP version. The HTTP verb says what action is requested of the host, e.g. to GET a resource or POST form data.
- headers: additional information about the message, the requester, and the communication format.
- body (optional): the content of the request. For a simple request for a static resource like a web page, this will be empty. For a form submission, this will contain the information from the form. The body is separated from the headers by a blank line.
Here’s a typical HTTP request:
1 |
GET /articles/http-basics HTTP/1.1 |
2 |
Host: www.articles.com |
3 |
Connection: keep-alive |
4 |
Cache-Control: no-cache |
5 |
Pragma: no-cache |
6 |
Accept: text/html, application/xhtml+xml, application/xml;q=0.9, */*;q=0.8 |
The first line has the verb, resource path, and HTTP version. In this case, we are trying to GET the resource at /articles/http-basics. The rest of the request lines are headers—this request has no body.
HTTP Request Verbs
There are four universally applicable HTTP verbs in a request:
- GET: fetch a resource from the server. For a GET request, the URL should carry all the required pieces of information for the server to spot the right resource. It does not have a message body.
- POST: create a new resource. The request has an optional payload which helps the server create a new resource.
- PUT: update an existing resource. The request should have an optional payload to help the server update an existing resource.
- DELETE: delete an existing resource.
The above four verbs are the most popular ones. Interestingly, PUT and DELETE are sometimes considered as specialised versions of the POST verb. In certain cases, PUT may be packaged as a POST request with the payload containing the exact action: create, update, or delete.
There are some less-used verbs too. A few to consider are:
- HEAD is similar to GET, but without the message body. It’s used to retrieve the server headers for a particular resource, generally to check if the resource has changed, via timestamps.
-
TRACE is used to retrieve the hops that a request takes during a round trip from the server. Each intermediate proxy or gateway would inject its IP or DNS name into the
Viaheader field. This can be used for diagnostic purposes. - OPTIONS is used to retrieve server capabilities. On the client side, it can be used to modify the request based on what the server supports.
HTTP Headers
HTTP headers give the server information about the sender, the way the client wants to interact, and the message. Each header is a name-value pair. The HTTP protocol specifies all the valid HTTP headers the client and server can use.
A bunch of general headers are shared by both the request and response messages:
-
Cache-Control: a directive that controls how caching happens in CDNs, proxies, or browsers. It became effective from HTTP/1.1. -
Connection: used to decide if the network connection needs to be closed or open once a request is completed. Possible values arekeep-aliveorclosed. -
Pragmais an interesting and heavily implementation-specific header. It is provided only for backwards compatibility with HTTP/1.0, which does not supportCache-Control. -
Trailer: tells the server it can append metadata to the message body, for example an integrity check or digital signature. -
Transfer-encoding: defines the encoding of the payload transferred from the server. Often, this is known as the hop-by-hop header because the encoding is applied between nodes, and not between the server and client. -
Viais used in the header to track messages and the capabilities of the client or server. -
Upgradeis available only in HTTP/1.1 and above. If the client or server is allowed to shift from one protocol to another, this header has to be set. For example:Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11.
Here are some of the headers that are specific to the request:
-
Accept-prefixed headers indicate the acceptable media-types, encoding, languages, and character sets on the client. -
From,Host,Referer, andUser-Agenthave details about the client that initiated the request. -
Authorization: used by the client to provide credentials which can be further used by the server to authenticate the request. This is useful for accessing password-protected resources. -
If-prefixed headers are used to make a request conditional—the server returns the resource only if the condition matches. Otherwise, it returns a304 Not Modified. -
Referrer: contains either the partial or absolute address of the requesting page.
There are many other HTTP headers in use. Read more about headers if you want to understand some of the intricacies of the HTTP protocol.
HTTP Responses
The response is similar in structure to a request message, except for the status line and headers.
- status line: includes a status code that indicates whether the request succeeded (status code 200) or why the request failed. It also includes the HTTP version and a very brief description of the status.
- headers: additional information about the response—for example, the content type or information about the server.
- body (optional): the content of the response. For example, this might be the HTML content of a requested web page or the binary data of an image.
A successful response from the server will have a status line similar to HTTP/1.1 200 OK.
Response Headers
Just like in a request, the response message can have a number of headers. Here are some commonly used response headers:
-
Age: the time in seconds since the message was generated on the server. -
ETag: the MD5 hash of the entity, used to check for modifications. -
Location: used when sending a redirection and contains the new URL. -
Server: identifies the server generating the message.
The HTTP response can also have a collection of entity headers. The role of the entity header is to offer meta-information about the message body. Here are some typical entity headers:
-
Allow: defines the set of methods a resource may support. If the resource is not supported, you will receive a status code405 Method Not Allowed. -
Content-prefixed headers indicate the response media-types, encoding, languages, and character sets on the message payload. For instance,Content-Encodingis used to compress the transmitted data. -
Expires: indicates the date and time when the response will become invalid, so the resource should not be cached past that point. -
Last-Modified: carries details of when the server believes that the response resource was last modified.
Status Codes
With so many theoretical concepts, you might be feeling a bit drowsy. But please hold on. We are going to end our theories with the HTTP response status codes. Every response from the server will have a status code. The status code is important and tells the client how to interpret the server response
1xx: Informational Messages
This class of codes was introduced in HTTP/1.1 and is purely provisional. The server can send an Expect: 100-continue message, telling the client to continue sending the remainder of the request, or ignore if it has already sent it. HTTP/1.0 clients are supposed to ignore this header.
2xx: Successful
This tells the client that the request was successfully processed. The most common code is 200 OK. For a response to a GET request, the server sends the resource in the message body.
-
200 OK: the request was processed successfully, and the response body will contain any requested content. -
202 Accepted: the request was accepted but may not include the resource in the response. This is useful for async processing on the server side. The server may choose to send information for monitoring. -
204 No Content: there is no message body in the response. -
205 Reset Content: indicates to the client to reset its document view. -
206 Partial Content: indicates that the response only contains partial content. Additional headers indicate the exact range and content expiration information.
3xx: Redirection
This requires the client to take additional action. The most common use-case is to jump to a different URL in order to fetch the resource.
-
301 Moved Permanently: the resource is now located at a new URL. -
303 See Other: the resource is temporarily located at a new URL. TheLocationresponse header contains the temporary URL. -
304 Not Modified: the server has determined that the resource has not changed and the client should use its cached copy. This relies on the fact that the client is sendingETag(entity tag) information that is a hash of the content. The server compares this with its own computedETagto check for modifications.
4xx: Client Error
These codes are used when the server thinks that the client is at fault, either by requesting an invalid resource or making a bad request. The most common code in this class is 404 Not Found, which I think everyone recognizes.
-
400 Bad Request: the request was malformed. -
401 Unauthorized: request requires authentication. The client can repeat the request with theAuthorizationheader. If the client already included theAuthorizationheader, then the credentials were wrong. -
403 Forbidden: server has denied access to the resource. -
404 Not Found: indicates that the resource is invalid and does not exist on the server. The other codes in this class include: -
405 Method Not Allowed: invalid HTTP verb used in the request line, or the server does not support that verb. -
409 Conflict: the server could not complete the request because the client is trying to modify a resource that is newer than the client’s timestamp. Conflicts arise mostly for PUT requests during collaborative edits on a resource.
5xx: Server Error
This class of codes are used to indicate a server failure while processing the request. The most commonly used error codes are:
-
500 Internal Server Error: the server had some sort of crash or internal error that stopped it from fulfilling the request. -
501 Not Implemented: the server does not yet support the requested functionality. -
503 Service Unavailable: this could happen if an internal system on the server has failed or the server is overloaded. Typically, the server won’t even respond and the request will time out.
Tools to View HTTP Traffic
There are a number of tools available to monitor HTTP communication. Here, we list some of the more popular tools.
Undoubtedly, the Chrome or Webkit inspector is every web developers’ favourite. The Network tab, in the Chrome Developers Tools menu, has become much more useful in recent years. A lot of information can be gathered from here about HTTP requests and responses.



There are also web debugging proxies, like Fiddler and Charles Proxy or OSX.





For the command line, we have utilities like curl, tcpdump and tshark. These help in monitoring HTTP traffic.
Using HTTP in Web Frameworks and Libraries
Finally, let’s see how the request-response pair is used by frameworks. As an example, let’s begin with Express for Node.js.
Receiving an HTTP Request With Express
If you are building web servers in Node.js, chances are high that you’ve considered Express.
Express provides a simple API for writing web servers. I won’t cover the details of the API. Instead, I’ll show you an example of how Express uses HTTP requests and responses.
Express Hello World
1 |
const app = express() |
2 |
|
3 |
app.get('/', (req, res) => { |
4 |
res.send('Hello World!') |
5 |
})
|
6 |
|
7 |
app.get('*', (req, res) => { |
8 |
res.sendStatus(401); |
9 |
})
|
10 |
|
11 |
app.listen(3000, () => { |
12 |
console.log(`Example app listening on port ${port}`) |
13 |
})
|
In this example, we set up a handler for a GET request with the path /. When the server receives this request, it will respond with 200 OK, and the message body will be Hello World. The server will listen on port 3000. For GET requests to any other path, the server will return a 401 Not Found error.
You can learn more about using Express in the official documentation or in our in-depth tutorial on creating a REST API.
Sending an HTTP Request With the Fetch API
Finally, let’s see how to make an HTTP request from the client side. This used to be done with jQuery, but modern browsers have the Fetch API built-in. And the syntax does not get any simpler.
GET Requests With Fetch
To request data from the server, use fetch("https://example.com/something.html"). This returns a promise, which you can await to get the response.
1 |
let response = await fetch('https://example.com/movies.json') |
2 |
let data = await response.json(); |
3 |
console.log(data); |
In the example above, we sent a GET request to https://example.com for the movies.json resource. We await the response, and then extract the response body as JSON.
POST Requests With Fetch
To post data to the server, with an optional payload, the client makes use of fetch('https://example.com/profile', { method: 'POST'}). Again, this returns a promise which you can await to get the results of the request.
1 |
let response = await fetch('https://example.com/profile', { |
2 |
method: 'POST', |
3 |
headers: { |
4 |
'Content-Type': 'application/json', |
5 |
},
|
6 |
body: JSON.stringify(data), |
7 |
})
|
8 |
|
9 |
if (! response.ok) { |
10 |
console.log(`POST failed with status ${response.status}`) |
11 |
}
|
In this example, we’re submitting a post request to the profile endpoint of https://example.com. We want to send JSON data to the server, so we set the Content-Type header to application/json. Then we stringify our data to JSON and send it in the request body.
Conclusion
Congratulations, you have now mastered the basics of HTTP request and response! Now, you will be able to use the protocol in your application. Also, you should be able to choose the right HTTP verbs and headers for your use-case.
Divya Dev is a front-end developer with more than half a decade of experience. She is a grad and gold medalist from Anna University.
Did you find this post useful?

Web Developer, New York
I am a financial technologist specializing in front-end development, mostly for trading and analytics applications. I have worked on a wide variety of UI technologies in the past, ranging from Java Swing, Eclipse SWT, and Nokia Qt to Cocoa on OSX/iOS, .Net WPF, and HTML5.
I am the author of WPF Control Development Unleashed with Addison/Wesley-SAMS. I am also the creator of QuickLens, a Mac App targeted at UI Designers and Developers.
- Назначение протокола
- Общая Структура
- Общие понятия
- Строка Статус
- Метод
- GET
- HEAD
- POST
- PUT
- DELETE
- LINK
- UNLINK
- Поля Заголовок-Запроса
- From
- If-Modified-Since
- User-Agent
- Структура ответа
- Строка Статус
- Статус-Код и пояснение к нему
- Поля Заголовок-Ответа
- Общие Понятия
- Поля Заголовок-Содержания
- Allow
- Content-Length
- Content-Type
- Last-Modified
- Тело сообщения
HyperText Transfer Protocol (HTTP) — это протокол высокого уровня (а именно, уровня приложений), обеспечивающий необходимую скорость передачи данных, требующуюся для распределенных информационных систем гипермедиа. HTTP используется проектом World Wide Web с 1990 года.
Практические информационные системы требуют большего, чем примитивный поиск, модификация и аннотация данных. HTTP/1.0 предоставляет открытое множество методов, которые могут быть использованы для указания целей запроса. Они построены на дисциплине ссылок, где для указания ресурса, к которому должен быть применен данный метод, используется Универсальный Идентификатор Ресурсов (Universal Resource Identifier — URI), в виде местонахождения (URL) или имени (URN). Формат сообщений сходен с форматом Internet Mail или Multipurpose Internet Mail Extensions (MIME-Многоцелевое Расширение Почты Internet).
HTTP/1.0 используется также для коммуникаций между различными пользовательскими просмотрщиками и шлюзами, дающими гипермедиа доступ к существующим Internet протоколам, таким как SMTP, NNTP, FTP, Gopher и WAIS. HTTP/1.0 разработан, чтобы позволять таким шлюзам через proxy серверы, без какой-либо потери передавать данные с помощью упомянутых протоколов более ранних версий.
HTTP основывается на парадигме запросов/ответов. Запрашивающая программа (обычно она называется клиент) устанавливает связь с обслуживающей программой-получателем (обычно называется сервер) и посылает запрос серверу в следующей форме: метод запроса, URI, версия протокола, за которой следует MIME-подобное сообщение, содержащее управляющую информацию запроса, информацию о клиенте и, может быть, тело сообщения. Сервер отвечает сообщением, содержащим строку статуса (включая версию протокола и код статуса — успех или ошибка), за которой следует MIME-подобное сообщение, включающее в себя информацию о сервере, метаинформацию о содержании ответа, и, вероятно, само тело ответа. Следует отметить, что одна программа может быть одновременно и клиентом и сервером. Использование этих терминов в данном тексте относится только к роли, выполняемой программой в течение данного конкретного сеанса связи, а не к общим функциям программы.
В Internet коммуникации обычно основываются на TCP/IP протоколах. Для WWW номер порта по умолчанию — TCP 80, но также могут быть использованы и другие номера портов — это не исключает возможности использовать HTTP в качестве протокола верхнего уровня.
Для большинства приложений сеанс связи открывается клиентом для каждого запроса и закрывается сервером после окончания ответа на запрос. Тем не менее, это не является особенностью протокола. И клиент, и сервер должны иметь возможность закрывать сеанс связи, например, в результате какого-нибудь действия пользователя. В любом случае, разрыв связи, инициированный любой стороной, прерывает текущий запрос, независимо от его статуса.
Запрос — это сообщение, посылаемое клиентом серверу.
Первая строка этого сообщения включает в себя метод, который должен быть применен к запрашиваемому ресурсу, идентификатор ресурса и используемую версию протокола. Для совместимости с протоколом HTTP/0.9, существует два формата HTTP запроса:
Запрос = Простой-Запрос | Полный-Запрос
Простой-Запрос = "GET" SP Запрашиваемый-URI CRLF
Полный-Запрос = Строка-Статус
*(Общий-Заголовок | Заголовок-Запроса | Заголовок-Содержания ) CRLF
[ Содержание-Запроса ]
Если HTTP/1.0 сервер получает Простой-Запрос, он должен отвечать Простым-Ответом HTTP/0.9. HTTP/1.0 клиент, способный обрабатывать Полный-Ответ, никогда не должен посылать Простой-Запрос.
Строка Статус начинается со строки с названием метода, за которым следует URI-Запроса и использующаяся версия протокола. Строка Статус заканчивается символами CRLF. Элементы строки разделяются пробелами (SP). В Строке Статус не допускаются символы LF и CR, за исключением заключающей последовательности CRLF.
Строка-Статус = Метод SP URI-Запроса SP Версия-HTTP CRLF
Следует отметить, что отличие Строки Статус Полного-Запроса от Строки Статус Простого- Запроса заключается в присутствии поля Версия-HTTP.
В поле Метод указывается метод, который должен быть применен к ресурсу, идентифицируемому URI-Запроса. Названия методов чувствительны к регистру. Существующий список методов может быть расширен.
Метод = "GET" | "HEAD" | "PUT" | "POST" | "DELETE" | "LINK" | "UNLINK" | дополнительный-метод
Список методов, допускаемых отдельным ресурсом, может быть указан в поле Заголовок-Содержание «Баллов». Тем не менее, клиент всегда оповещается сервером через код статуса ответа, допускается ли применение данного метода для указанного ресурса, так как допустимость применения различных методов может динамически изменяться. Если данный метод известен серверу, но не допускается для указанного ресурса, сервер должен вернуть код статуса «405 Method Not Allowed», и код статуса «501 Not Implemented», если метод не известен или не поддерживается данным сервером. Общие методы HTTP/1.0 описываются ниже.
Метод GET служит для получения любой информации, идентифицированной URI-Запроса. Если URI- Запроса ссылается на процесс, выдающий данные, в качестве ответа будут выступать данные, сгенерированные данным процессом, а не код самого процесса (если только это не является выходными данными процесса).
Метод GET изменяется на «условный GET», если сообщение запроса включает в себя поле заголовка «If-Modified-Since». В ответ на условный GET, тело запрашиваемого ресурса передается только, если он изменялся после даты, указанной в заголовке «If-Modified-Since». Алгоритм определения этого включает в себя следующие случаи:
- Если код статуса ответа на запрос будет отличаться от «200 OK», или дата, указанная в поле заголовка «If-Modified-Since» некорректна, ответ будет идентичен ответу на обычный запрос GET.
- Если после указанной даты ресурс изменялся, ответ будет также идентичен ответу на обычный запрос GET.
- Если ресурс не изменялся после указанной даты, сервер вернет код статуса «304 Not Modified».
Использование метода условный GET направлено на разгрузку сети, так как он позволяет не передавать по сети избыточную информацию.
Метод HEAD аналогичен методу GET, за исключением того, что в ответе сервер не возвращает Тело- Ответа. Метаинформация, содержащаяся в HTTP заголовках ответа на запрос HEAD, должна быть идентична информации HTTP заголовков ответа на запрос GET. Данный метод может использоваться для получения метаинформации о ресурсе без передачи по сети самого ресурса. Метод «Условный HEAD», аналогичный условному GET, не определен.
Метод POST используется для запроса сервера, чтобы тот принял информацию, включенную в запрос, как субординантную для ресурса, указанного в Строке Статус в поле URI-Запроса. Метод POST был разработан, чтобы была возможность использовать один общий метод для следующих функций:
- Аннотация существующих ресурсов
- Добавление сообщений в группы новостей, почтовые списки или подобные группы статей
- Доставка блоков данных процессам, обрабатывающим данные
- Расширение баз данных через операцию добавления
Реальная функция, выполняемая методом POST, определяется сервером и обычно зависит от URI- Запроса. Добавляемая информация рассматривается как субординатная указанному URI в том же смысле, как файл субординатен каталогу, в котором он находится, новая статья субординатна группе новостей, в которую она добавляется, запись субординатна базе данных.
Клиент может предложить URI для идентификации нового ресурса, включив в запрос заголовок «URI». Тем не менее, сервер должен рассматривать этот URI только как совет и может сохранить тело запроса под другим URI или вообще без него.
Если в результате обработки запроса POST был создан новый ресурс, ответ должен иметь код статуса, равный «201 Created», и содержать URI нового ресурса.
Метод PUT запрашивает сервер о сохранении Тело-Запроса под URI, равным URI-Запроса. Если URI-Запроса ссылается на уже существующий ресурс, Тело-Запроса должно рассматриваться как модифицированная версия данного ресурса. Если ресурс, на который ссылается URI-Запроса не существует, и данный URI может рассматриваться как описание для нового ресурса, сервер может создать ресурс с данным URI. Если был создан новый ресурс, сервер должен информировать направившего запрос клиента через ответ с кодом статуса «201 Created». Если существующий ресурс был модифицирован, должен быть послан ответ «200 OK», для информирования клиента об успешном завершении операции. Если ресурс с указанным URI не может быть создан или модифицирован, должно быть послано соответствующее сообщение об ошибке.
Фундаментальное различие между методами POST и PUT заключается в различном значении поля URI-Запроса. Для метода POST данный URI указывает ресурс, который будет управлять информацией, содержащейся в теле запроса, как неким придатком. Ресурс может быть обрабатывающим данные процессом, шлюзом в какой нибудь другой протокол, или отдельным ресурсом, допускающим аннотации. В противоположность этому, URI для запроса PUT идентифицирует информацию, содержащуюся в Содержание-Запроса. Использующий запрос PUT точно знает какой URI он собирается использовать, и получатель запроса не должен пытаться применить этот запрос к какому-нибудь другому ресурсу.
Метод DELETE используется для удаления ресурсов, идентифицированных с помощью URI-Запроса. Результаты работы данного метода на сервере могут быть изменены с помощью человеческого вмешательства (или каким-нибудь другим способом). В принципе, клиент никогда не может быть уверен, что операция удаления была выполнена, даже если код статуса, переданный сервером, информирует об успешном выполнении действия. Тем не менее, сервер не должен информировать об успехе до тех пор, пока на момент ответа он не будет собираться стереть данный ресурс или переместить его в некоторую недостижимую область.
Метод LINK устанавливает взаимосвязи между существующим ресурсом, указанным в URI-Запроса, и другими существующими ресурсами. Отличие метода LINK от остальных методов, допускающих установление ссылок между документами, заключается в том, что метод LINK не позволяет передавать в запросе Тело-Запроса, и в том, что в результате работы данного метода не создаются новые ресурсы.
Метод UNLINK удаляет одну или более ссылочных взаимосвязей для ресурса, указанного в URI- Запроса. Эти взаимосвязи могут быть установлены с помощью метода LINK или какого-нибудь другого метода, поддерживающего заголовок «Link». Удаление ссылки на ресурс не означает, что ресурс прекращает существование или становится недоступным для будущих ссылок.
Поля Заголовок-Запроса позволяют клиенту передавать серверу дополнительную информацию о запросе и о самом клиенте.
Заголовок-Запроса = Accept | Accept-Charset | Accept-Encoding |
Accept-Language | Authorization | From |
If-Modified-Since |
Pragma | Referer | User-Agent | extension-header
Кроме того через механизм расширения могут быть определены дополнительные заголовки; приложения, которые их не распознают, должны трактовать эти заголовки, как Заголовок-Содержание.
Ниже будут рассмотрены некоторые поля заголовка запроса.
В случае присутствия поля From, оно должно содержать полный E-mail адрес пользователя, который управляет программой-агентом, осуществляющей запросы. Этот адрес должен быть задан в формате, определенном в RFC 822. Формат данного поля следующий: From = «From» «:» спецификация адреса. Например:
Данное поле может быть использовано для функций захода в систему, а также для идентификации источника некорректных или нежелательных запросов. Оно не должно использоваться, как несекретная форма разграничения прав доступа. Интерпретация этого поля состоит в том, что обрабатываемый запрос производится от имени данного пользователя, который принимает ответственность за применяемый метод. В частности, агенты-роботы должны использовать этот заголовок для того, чтобы можно было связаться с тем человеком, который отвечает за работу робота, в случае возникновения проблем. Почтовый Internet адрес, указывающийся в этом поле, не обязан соответствовать адресу того хоста, с которого был послан данный запрос. По возможности, адрес должен быть доступным Internet адресом вне зависимости от того, является ли он в действительности Internet E-mail адресом или Internet E-mail представлением адреса других почтовых систем.
Замечание: Клиент не должен использовать поле заголовка From без позволения пользователя, так как это может войти в конфликт с его частными интересами или с местной, используемой им, системой безопасности. Настоятельно рекомендуется предоставление пользователю возможности запретить, разрешить или модифицировать это поле в любой момент перед запросом.
Поле заголовка If-Modified-Since используется с методом GET для того, чтобы сделать его условным: если запрашиваемый ресурс не изменялся во времени, указанного в этом поле, копия этого ресурса не будет возвращена сервером; вместо этого, будет возвращен ответ «304 Not Modified» без Тела- Ответа.
If-Modified-Since = "If-Modified-Since" ":" HTTP-дата
Пример использования заголовка:
If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT
Целью этой особенности является предоставление возможности эффективного обновления информации локальных кэшей с минимумом передаваемой информации. Тот же результат может быть достигнут применением метода HEAD с последующим использованием GET, если сервер указал, что содержимое документа изменилось.
Поле заголовка User-Agent содержит информацию о пользовательском агенте, пославшем запрос. Данное поле используется для статистики, прослеживания ошибок протокола, и автоматического распознавания пользовательских агентов. Хотя это не обязательно, пользовательские агенты должны всегда включать это поле в свои запросы. Поле может содержать несколько строк, представляющих собой название программного продукта, необязательную косую черту с указанием версии продукта, а также другие программные продукты, составляющие важную часть пользовательского агента. По соглашению, продукты указываются в списке в порядке убывания их значимости для идентификации приложения.
User-Agent = "User-Agent" ":" 1*( продукт ) продукт = строка ["/" версия-продукта] версия-продукта = строка
Пример:
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
Строка, описывающая название продукта, должна быть короткой и давать информацию по существу — использование данного заголовка для рекламирования какой-либо другой, не относящейся к делу, информации не допускается и рассматривается, как не соответствующее протоколу. Хотя в поле версии продукта может присутствовать любая строка, данная строка должна использоваться только для указания версии продукта. Поле User-Agent может включать в себя дополнительную информацию в комментариях, которые не являются частью его значения.
После получения и интерпретации запроса, сервер посылает ответ в соответствии со следующей формой:
Ответ = Простой-Ответ | Полный-Ответ
Простой-Ответ = [ Содержание-Ответа ]
Полный-Ответ = Строка-Статус
*( Общий-Заголовок | Заголовок-Ответа | Заголовок-Содержания) CRLF
[ Содержание-Ответа ]
Простой-Ответ должен посылаться только в ответ на HTTP/0.9 Простой-Запрос, или в том случае, если сервер поддерживает только ограниченный HTTP/0.9 протокол. Если клиент посылает HTTP/1.0 Полный-Запрос и получает ответ, который не начинается со Строки-Статус, он должен предполагать, что ответ сервера представляет собой Простой-Ответ, и обрабатывать его в соответствии с этим. Следует заметить, что Простой-Ответ состоит только из запрашиваемой информации (без заголовков) и поток данных прекращается в тот момент, когда сервер закрывает сеанс связи.
Первая строка Полного-Запроса является Строкой-Статус, состоящей из версии протокола, за которой следует цифровой код статуса и ассоциированное с ним текстовое предложение. Все элементы Строки-Статус разделены пробелами. Не разрешены символы CR и LF, за исключением завершающей последовательности CRLF.
Строка-Статус=Версия-HTTP SP Статус-Код SP Фраза-Об'яснение.
Так как Строка-Статус всегда начинается с версии протокола «HTTP/» 1*ЦИФРА «.» 1*ЦИФРА (например HTTP/1.0), существование этого выражения рассматривается как основное для определения того, является ли ответ Простым-Ответом, или Полным-Ответом. Хотя формат Простого-Ответа не исключает появления подобной строки (что привело бы к неправильной интерпретации сообщения ответа и принятию его за Полный-Ответ), вероятность такого появления близка к нулю.
Элемент Статус-Код представляет собой 3-х цифровой целый код, идентифицирующий результат попытки интерпретации и удовлетворения запроса. Фраза-Об’яснение, следующая за ним, предназначена для краткого текстового описания Статус-Кода. Статус-Код нацелен на то, чтобы его использовала машина, а Фраза-Об’яснение предназначена для человека. Клиент не обязан исследовать и выводить на экран Фразу-Об’яснение.
Первая цифра Статус-Кода предназначена для определения класса ответа. Последние две цифры не выполняют никакой категоризирующей роли. Существует 5 значений для первой цифры:
- 1xx: Информационный — Не используется, но зарезервирован для использования в будущем
- 2xх: Успех — Запрос был полностью получен, понят, и принят к обработке.
- 3xx: Перенаправление — Клиенту следует предпринять дальнейшие действия для успешного выполнения запроса. Необходимое дополнительное действие иногда может быть выполнено клиентом без взаимодействия с пользователем, но настоятельно рекомендуется, чтобы это имело место только в тех случаях, когда метод, использующийся в запросе безразличен (GET или HEAD).
- 4xx: Ошибка клиента — Запрос, содержащий неправильные синтаксические конструкции, не может быть успешно выполнен. Класс 4xx предназначен для описания тех случаев, когда ошибка была допущена со стороны клиента. Если клиент еще не завершил запрос, когда он получил ответ с Статус-Кодом- 4xx, он должен немедленно прекратить передачу данных серверу. Данный тип Статус-Кодов применим для любых методов, употребляющихся в запросе.
- 5xx: Ошибка Сервера — Сервер не смог дать ответ на корректно поставленный запрос. В этих случаях
сервер либо знает, что он допустил ошибку, либо не способен обработать запрос. За исключением ответов на запросы HEAD, сервер посылает описание ошибочной ситуации и то, является ли это состояние временным или постоянным, в Содержание-Ответа. Данный тип Статус-Кодов применим для любых методов, употребляющихся в запросе.
Отдельные значения Статус-Кодов и соответствующие им Фразы-Об’яснения приведены ниже. Данные Фразы-Об’яснения только рекомендуются — они могут быть замещены любыми другими фразами, сохраняющими смысл и допускающимися протоколом.
Статус-Код = "200" ; OK | "201" ; Created | "202" ; Accepted | "203" ; Provisional Information | "204" ; No Content | "300" ; Multiple Choices | "301" ; Moved Permanently | "302" ; Moved Temporarily | "303" ; Method | "304" ; Not Modified | "400" ; Bad Request | "401" ; Unauthorized | "402" ; Payment Required | "403" ; Forbidden | "404" ; Not Found | "405" ; Method Not Allowed | "406" ; None Acceptable | "407" ; Proxy Authentication Required | "408" ; Request Timeout | "409" ; Conflict | "410" ; Gone | "500" ; Internal Server Error | "501" ; Not Implemented | "502" ; Bad Gateway | "503" ; Service Unavailable | "504" ; Gateway Timeout | Код-Рассширения Код-Расширения = 3ЦИФРА Фраза-Об'яснение = строка *( SP строка )
От HTTP приложений не требуется понимание всех Статус-Кодов, хотя такое понимание, очевидно, желательно. Тем не менее, от приложений требуется способность распознавания классов Статус-Кодов (идентифицирующихся первой цифрой) и отношение ко всем Статус-Кодам статуса ответа, как если бы они были эквивалентны Статус-Коду x00.
Поля заголовка ответа позволяют серверу передать дополнительную информацию об ответе, которая не может быть внесена в Строку-Статус. Эти поля заголовков не предназначены для передачи информации о содержании ответа, передаваемого в ответ на запрос, но там может быть информация собственно о сервере.
Заголовок-Ответа= Public | Retry-After | Server | WWW-Authenticate | extension-header
Хотя дополнительные поля заголовка ответа могут быть реализованы через механизм расширения, приложения, которые не распознают эти поля, должны обрабатывать их как поля Заголовок-Содержание. Полное описание этих полей можно получить в спецификации протокола HTTP в CERN.
Полный-Запрос и Полный-Ответ может использоваться для передачи некоторой информации в отдельных запросах и ответах. Этой информацией является Содержание-Запроса или Содержание-Ответа соответственно, а также Заголовок-Содержания.
Поля Заголовок-Содержания содержат необязательную метаинформацию о Содержании-Запроса или Содержании-Ответа соответственно. Если тело соответствующего сообщения (запроса или ответа) не присутствует, то Заголовок-Содержания содержит информацию о запрашиваемом ресурсе.
Заголовок-Содержания = Allow |
Content-Encoding | Content-Language | Content-Length |
Content-Transfer-Encoding | Content-Type |Derived-From |
Expires | Last-Modified |Link |
Location | Title | URI-header | Version | Заголовок-Расширения
Заголовок-Расширения = HTTP-заголовок
Некоторые из полей заголовка содержания описаны ниже.
Поле заголовка Allow представляет собой список методов, которые поддерживает ресурс, идентифицированный URI-Запроса. Назначение этого поля — точное информирование получателя о допустимых методах, ассоциированных с ресурсом; это поле должно присутствовать в ответе со статус кодом «405 Method Not Allowed».
Allow = "Allow" ":" 1#метод
Пример использования:
Конечно, клиент может попробовать использовать другие методы. Однако, рекомендуется следовать тем методам, которые указаны в данном поле. У этого поля нет значения по умолчанию; если оно оставлено неопределенным, множество разрешенных методов определяется сервером в момент каждого запроса.
Поле Content-Length указывает размер тела сообщения, посланного сервером в ответ на запрос или, в случае запроса HEAD, размер тела сообщения, которое было бы послано в ответ на запрос GET.
Content-Length = "Content-Length" ":" 1*ЦИФРА
Например:
Хотя это не обязательно, но все же приложениям настоятельно рекомендуется использовать это поле для анализа размеров передаваемого сообщения, независимо от типа содержащейся в нем информации. Для поля Content-Length допустимым является любое целочисленное значение больше нуля.
Поле заголовка Content-Type идентифицирует тип информации в теле сообщения, которая посылается получающей стороне или, в случае метода HEAD, тип информации (среды), который был бы послан, если использовался метод GET.
Content-Type = "Content-Type" ":" тип-среды
Типы сред определены отдельно.
Пример:
Content-Type: text/html; charset=ISO-8859-4
Поле Content-Type не имеет значения по умолчанию.
Поле заголовка содержит дату и время, в которое, по мнению отправляющей стороны, ресурс был последний раз модифицирован. Семантика данного поля определена в терминах, описывающих, как получатель должен его интерпретировать: если получатель имеет копию ресурса, которая старше, чем передаваемая в поле Last-Modified дата, то копия должна считаться устаревшей.
Last-Modified = "Last-Modified" ":" HTTP-дата
Пример использования:
Last-Modified: Tue, 15 Nov 1994 12:45:26 GMT
Точное значение этого поля заголовка зависит от реализации отправляющей стороны и сути самого ресурса. Для файлов, это может быть просто его время последней модификации. Для шлюзов к базам данных, это может быть время последнего обновления данных в базе. В любом случае, получатель должен беспокоиться лишь о результате — о том, что находится в данном поле, — и не беспокоиться о том, как результат был получен.
Под телом сообщения понимается Содержание-Запроса или Содержание-Ответа соответственно. Тело сообщения, если оно присутствует, посылается в HTTP/1.0 запросе или ответе в формате и кодировке, определяемыми полями Заголовок-Содержания.
Тело-Сообщения = *OCTET (где OCTET это любой 8-битный символ)
Тело сообщения включается в запрос, только если метод запроса подразумевает его наличие. Для спецификации HTTP/1.0 такими методами являются POST и PUT. В общем, на присутствие тела сообщения указывает присутствие таких полей заголовка содержания, как Content-Length и/или Content- Transfer-Encoding, в передаваемом запросе.
Что касается сообщений-ответов, наличие тела сообщения в ответе зависит от метода, который был использован в запросе, и Статус-Кода. Все ответы на запросы HEAD не должны содержать тело сообщения, хотя наличие некоторых полей заголовка сообщения может указывать на возможное присутствие такового. Соответственно, ответы «204 No Content», «304 Not Modified», и «406 None Acceptable» также не должны включать в себя тело сообщения.