This article is about software to translate computer languages. For the manga, see Compiler (manga).
«Compile» and «Compiling» redirect here. For the software company, see Compile (company). For other uses, see Compilation.
In computing, a compiler is a computer program that translates computer code written in one programming language (the source language) into another language (the target language). The name «compiler» is primarily used for programs that translate source code from a high-level programming language to a low-level programming language (e.g. assembly language, object code, or machine code) to create an executable program.[1][2]: p1 [3]
There are many different types of compilers which produce output in different useful forms. A cross-compiler produces code for a different CPU or operating system than the one on which the cross-compiler itself runs. A bootstrap compiler is often a temporary compiler, used for compiling a more permanent or better optimised compiler for a language.
Related software include, a program that translates from a low-level language to a higher level one is a decompiler ; a program that translates between high-level languages, usually called a source-to-source compiler or transpiler. A language rewriter is usually a program that translates the form of expressions without a change of language. A compiler-compiler is a compiler that produces a compiler (or part of one), often in a generic and reusable way so as to be able to produce many differing compilers.
A compiler is likely to perform some or all of the following operations, often called phases: preprocessing, lexical analysis, parsing, semantic analysis (syntax-directed translation), conversion of input programs to an intermediate representation, code optimization and machine specific code generation. Compilers generally implement these phases as modular components, promoting efficient design and correctness of transformations of source input to target output. Program faults caused by incorrect compiler behavior can be very difficult to track down and work around; therefore, compiler implementers invest significant effort to ensure compiler correctness.[4]
Compilers are not the only language processor used to transform source programs. An interpreter is computer software that transforms and then executes the indicated operations.[2]: p2 The translation process influences the design of computer languages, which leads to a preference of compilation or interpretation. In theory, a programming language can have both a compiler and an interpreter. In practice, programming languages tend to be associated with just one (a compiler or an interpreter).
History[edit]
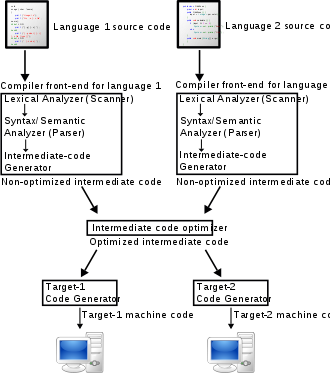
A diagram of the operation of a typical multi-language, multi-target compiler
Theoretical computing concepts developed by scientists, mathematicians, and engineers formed the basis of digital modern computing development during World War II. Primitive binary languages evolved because digital devices only understand ones and zeros and the circuit patterns in the underlying machine architecture. In the late 1940s, assembly languages were created to offer a more workable abstraction of the computer architectures. Limited memory capacity of early computers led to substantial technical challenges when the first compilers were designed. Therefore, the compilation process needed to be divided into several small programs. The front end programs produce the analysis products used by the back end programs to generate target code. As computer technology provided more resources, compiler designs could align better with the compilation process.
It is usually more productive for a programmer to use a high-level language, so the development of high-level languages followed naturally from the capabilities offered by digital computers. High-level languages are formal languages that are strictly defined by their syntax and semantics which form the high-level language architecture. Elements of these formal languages include:
- Alphabet, any finite set of symbols;
- String, a finite sequence of symbols;
- Language, any set of strings on an alphabet.
The sentences in a language may be defined by a set of rules called a grammar.[5]
Backus–Naur form (BNF) describes the syntax of «sentences» of a language and was used for the syntax of Algol 60 by John Backus.[6] The ideas derive from the context-free grammar concepts by Noam Chomsky, a linguist.[7] «BNF and its extensions have become standard tools for describing the syntax of programming notations, and in many cases parts of compilers are generated automatically from a BNF description.»[8]
In the 1940s, Konrad Zuse designed an algorithmic programming language called Plankalkül («Plan Calculus»). While no actual implementation occurred until the 1970s, it presented concepts later seen in APL designed by Ken Iverson in the late 1950s.[9] APL is a language for mathematical computations.
High-level language design during the formative years of digital computing provided useful programming tools for a variety of applications:
- FORTRAN (Formula Translation) for engineering and science applications is considered to be the first high-level language.[10]
- COBOL (Common Business-Oriented Language) evolved from A-0 and FLOW-MATIC to become the dominant high-level language for business applications.[11]
- LISP (List Processor) for symbolic computation.[12]
Compiler technology evolved from the need for a strictly defined transformation of the high-level source program into a low-level target program for the digital computer. The compiler could be viewed as a front end to deal with the analysis of the source code and a back end to synthesize the analysis into the target code. Optimization between the front end and back end could produce more efficient target code.[13]
Some early milestones in the development of compiler technology:
- 1952: An Autocode compiler developed by Alick Glennie for the Manchester Mark I computer at the University of Manchester is considered by some to be the first compiled programming language.
- 1952: Grace Hopper’s team at Remington Rand wrote the compiler for the A-0 programming language (and coined the term compiler to describe it),[14][15] although the A-0 compiler functioned more as a loader or linker than the modern notion of a full compiler.
- 1954–1957: A team led by John Backus at IBM developed FORTRAN which is usually considered the first high-level language. In 1957, they completed a FORTRAN compiler that is generally credited as having introduced the first unambiguously complete compiler.
- 1959: The Conference on Data Systems Language (CODASYL) initiated development of COBOL. The COBOL design drew on A-0 and FLOW-MATIC. By the early 1960s COBOL was compiled on multiple architectures.
- 1958-1960: Algol 58 was the precursor to ALGOL 60. Algol 58 introduced code blocks, a key advance in the rise of structured programming. ALGOL 60 was the first language to implement nested function definitions with lexical scope. It included recursion. Its syntax was defined using BNF. ALGOL 60 inspired many languages that followed it. Tony Hoare remarked: «… it was not only an improvement on its predecessors but also on nearly all its successors.»[16][17]
- 1958–1962: John McCarthy at MIT designed LISP.[18] The symbol processing capabilities provided useful features for artificial intelligence research. In 1962, LISP 1.5 release noted some tools: an interpreter written by Stephen Russell and Daniel J. Edwards, a compiler and assembler written by Tim Hart and Mike Levin.[19]
Early operating systems and software were written in assembly language. In the 1960s and early 1970s, the use of high-level languages for system programming was still controversial due to resource limitations. However, several research and industry efforts began the shift toward high-level systems programming languages, for example, BCPL, BLISS, B, and C.
BCPL (Basic Combined Programming Language) designed in 1966 by Martin Richards at the University of Cambridge was originally developed as a compiler writing tool.[20] Several compilers have been implemented, Richards’ book provides insights to the language and its compiler.[21] BCPL was not only an influential systems programming language that is still used in research[22] but also provided a basis for the design of B and C languages.
BLISS (Basic Language for Implementation of System Software) was developed for a Digital Equipment Corporation (DEC) PDP-10 computer by W.A. Wulf’s Carnegie Mellon University (CMU) research team. The CMU team went on to develop BLISS-11 compiler one year later in 1970.
Multics (Multiplexed Information and Computing Service), a time-sharing operating system project, involved MIT, Bell Labs, General Electric (later Honeywell) and was led by Fernando Corbató from MIT.[23] Multics was written in the PL/I language developed by IBM and IBM User Group.[24] IBM’s goal was to satisfy business, scientific, and systems programming requirements. There were other languages that could have been considered but PL/I offered the most complete solution even though it had not been implemented.[25] For the first few years of the Multics project, a subset of the language could be compiled to assembly language with the Early PL/I (EPL) compiler by Doug McIlory and Bob Morris from Bell Labs.[26] EPL supported the project until a boot-strapping compiler for the full PL/I could be developed.[27]
Bell Labs left the Multics project in 1969, and developed a system programming language B based on BCPL concepts, written by Dennis Ritchie and Ken Thompson. Ritchie created a boot-strapping compiler for B and wrote Unics (Uniplexed Information and Computing Service) operating system for a PDP-7 in B. Unics eventually became spelled Unix.
Bell Labs started the development and expansion of C based on B and BCPL. The BCPL compiler had been transported to Multics by Bell Labs and BCPL was a preferred language at Bell Labs.[28] Initially, a front-end program to Bell Labs’ B compiler was used while a C compiler was developed. In 1971, a new PDP-11 provided the resource to define extensions to B and rewrite the compiler. By 1973 the design of C language was essentially complete and the Unix kernel for a PDP-11 was rewritten in C. Steve Johnson started development of Portable C Compiler (PCC) to support retargeting of C compilers to new machines.[29][30]
Object-oriented programming (OOP) offered some interesting possibilities for application development and maintenance. OOP concepts go further back but were part of LISP and Simula language science.[31] At Bell Labs, the development of C++ became interested in OOP.[32] C++ was first used in 1980 for systems programming. The initial design leveraged C language systems programming capabilities with Simula concepts. Object-oriented facilities were added in 1983.[33] The Cfront program implemented a C++ front-end for C84 language compiler. In subsequent years several C++ compilers were developed as C++ popularity grew.
In many application domains, the idea of using a higher-level language quickly caught on. Because of the expanding functionality supported by newer programming languages and the increasing complexity of computer architectures, compilers became more complex.
DARPA (Defense Advanced Research Projects Agency) sponsored a compiler project with Wulf’s CMU research team in 1970. The Production Quality Compiler-Compiler PQCC design would produce a Production Quality Compiler (PQC) from formal definitions of source language and the target.[34] PQCC tried to extend the term compiler-compiler beyond the traditional meaning as a parser generator (e.g., Yacc) without much success. PQCC might more properly be referred to as a compiler generator.
PQCC research into code generation process sought to build a truly automatic compiler-writing system. The effort discovered and designed the phase structure of the PQC. The BLISS-11 compiler provided the initial structure.[35] The phases included analyses (front end), intermediate translation to virtual machine (middle end), and translation to the target (back end). TCOL was developed for the PQCC research to handle language specific constructs in the intermediate representation.[36] Variations of TCOL supported various languages. The PQCC project investigated techniques of automated compiler construction. The design concepts proved useful in optimizing compilers and compilers for the (since 1995, object-oriented) programming language Ada.
The Ada STONEMAN document[citation needed] formalized the program support environment (APSE) along with the kernel (KAPSE) and minimal (MAPSE). An Ada interpreter NYU/ED supported development and standardization efforts with the American National Standards Institute (ANSI) and the International Standards Organization (ISO). Initial Ada compiler development by the U.S. Military Services included the compilers in a complete integrated design environment along the lines of the STONEMAN document. Army and Navy worked on the Ada Language System (ALS) project targeted to DEC/VAX architecture while the Air Force started on the Ada Integrated Environment (AIE) targeted to IBM 370 series. While the projects did not provide the desired results, they did contribute to the overall effort on Ada development.[37]
Other Ada compiler efforts got underway in Britain at the University of York and in Germany at the University of Karlsruhe. In the U. S., Verdix (later acquired by Rational) delivered the Verdix Ada Development System (VADS) to the Army. VADS provided a set of development tools including a compiler. Unix/VADS could be hosted on a variety of Unix platforms such as DEC Ultrix and the Sun 3/60 Solaris targeted to Motorola 68020 in an Army CECOM evaluation.[38] There were soon many Ada compilers available that passed the Ada Validation tests. The Free Software Foundation GNU project developed the GNU Compiler Collection (GCC) which provides a core capability to support multiple languages and targets. The Ada version GNAT is one of the most widely used Ada compilers. GNAT is free but there is also commercial support, for example, AdaCore, was founded in 1994 to provide commercial software solutions for Ada. GNAT Pro includes the GNU GCC based GNAT with a tool suite to provide an integrated development environment.
High-level languages continued to drive compiler research and development. Focus areas included optimization and automatic code generation. Trends in programming languages and development environments influenced compiler technology. More compilers became included in language distributions (PERL, Java Development Kit) and as a component of an IDE (VADS, Eclipse, Ada Pro). The interrelationship and interdependence of technologies grew. The advent of web services promoted growth of web languages and scripting languages. Scripts trace back to the early days of Command Line Interfaces (CLI) where the user could enter commands to be executed by the system. User Shell concepts developed with languages to write shell programs. Early Windows designs offered a simple batch programming capability. The conventional transformation of these language used an interpreter. While not widely used, Bash and Batch compilers have been written. More recently sophisticated interpreted languages became part of the developers tool kit. Modern scripting languages include PHP, Python, Ruby and Lua. (Lua is widely used in game development.) All of these have interpreter and compiler support.[39]
«When the field of compiling began in the late 50s, its focus was limited to the translation of high-level language programs into machine code … The compiler field is increasingly intertwined with other disciplines including computer architecture, programming languages, formal methods, software engineering, and computer security.»[40] The «Compiler Research: The Next 50 Years» article noted the importance of object-oriented languages and Java. Security and parallel computing were cited among the future research targets.
Compiler construction[edit]
A compiler implements a formal transformation from a high-level source program to a low-level target program. Compiler design can define an end-to-end solution or tackle a defined subset that interfaces with other compilation tools e.g. preprocessors, assemblers, linkers. Design requirements include rigorously defined interfaces both internally between compiler components and externally between supporting toolsets.
In the early days, the approach taken to compiler design was directly affected by the complexity of the computer language to be processed, the experience of the person(s) designing it, and the resources available. Resource limitations led to the need to pass through the source code more than once.
A compiler for a relatively simple language written by one person might be a single, monolithic piece of software. However, as the source language grows in complexity the design may be split into a number of interdependent phases. Separate phases provide design improvements that focus development on the functions in the compilation process.
One-pass versus multi-pass compilers[edit]
Classifying compilers by number of passes has its background in the hardware resource limitations of computers. Compiling involves performing much work and early computers did not have enough memory to contain one program that did all of this work. So compilers were split up into smaller programs which each made a pass over the source (or some representation of it) performing some of the required analysis and translations.
The ability to compile in a single pass has classically been seen as a benefit because it simplifies the job of writing a compiler and one-pass compilers generally perform compilations faster than multi-pass compilers. Thus, partly driven by the resource limitations of early systems, many early languages were specifically designed so that they could be compiled in a single pass (e.g., Pascal).
In some cases, the design of a language feature may require a compiler to perform more than one pass over the source. For instance, consider a declaration appearing on line 20 of the source which affects the translation of a statement appearing on line 10. In this case, the first pass needs to gather information about declarations appearing after statements that they affect, with the actual translation happening during a subsequent pass.
The disadvantage of compiling in a single pass is that it is not possible to perform many of the sophisticated optimizations needed to generate high quality code. It can be difficult to count exactly how many passes an optimizing compiler makes. For instance, different phases of optimization may analyse one expression many times but only analyse another expression once.
Splitting a compiler up into small programs is a technique used by researchers interested in producing provably correct compilers. Proving the correctness of a set of small programs often requires less effort than proving the correctness of a larger, single, equivalent program.
Three-stage compiler structure[edit]

Regardless of the exact number of phases in the compiler design, the phases can be assigned to one of three stages. The stages include a front end, a middle end, and a back end.
- The front end scans the input and verifies syntax and semantics according to a specific source language. For statically typed languages it performs type checking by collecting type information. If the input program is syntactically incorrect or has a type error, it generates error and/or warning messages, usually identifying the location in the source code where the problem was detected; in some cases the actual error may be (much) earlier in the program. Aspects of the front end include lexical analysis, syntax analysis, and semantic analysis. The front end transforms the input program into an intermediate representation (IR) for further processing by the middle end. This IR is usually a lower-level representation of the program with respect to the source code.
- The middle end performs optimizations on the IR that are independent of the CPU architecture being targeted. This source code/machine code independence is intended to enable generic optimizations to be shared between versions of the compiler supporting different languages and target processors. Examples of middle end optimizations are removal of useless (dead-code elimination) or unreachable code (reachability analysis), discovery and propagation of constant values (constant propagation), relocation of computation to a less frequently executed place (e.g., out of a loop), or specialization of computation based on the context, eventually producing the «optimized» IR that is used by the back end.
- The back end takes the optimized IR from the middle end. It may perform more analysis, transformations and optimizations that are specific for the target CPU architecture. The back end generates the target-dependent assembly code, performing register allocation in the process. The back end performs instruction scheduling, which re-orders instructions to keep parallel execution units busy by filling delay slots. Although most optimization problems are NP-hard, heuristic techniques for solving them are well-developed and currently implemented in production-quality compilers. Typically the output of a back end is machine code specialized for a particular processor and operating system.
This front/middle/back-end approach makes it possible to combine front ends for different languages with back ends for different CPUs while sharing the optimizations of the middle end.[41] Practical examples of this approach are the GNU Compiler Collection, Clang (LLVM-based C/C++ compiler),[42] and the Amsterdam Compiler Kit, which have multiple front-ends, shared optimizations and multiple back-ends.
Front end[edit]
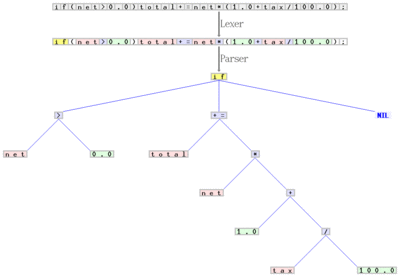
Lexer and parser example for C. Starting from the sequence of characters «if(net>0.0)total+=net*(1.0+tax/100.0);«, the scanner composes a sequence of tokens, and categorizes each of them, for example as identifier, reserved word, number literal, or operator. The latter sequence is transformed by the parser into a syntax tree, which is then treated by the remaining compiler phases. The scanner and parser handles the regular and properly context-free parts of the grammar for C, respectively.
The front end analyzes the source code to build an internal representation of the program, called the intermediate representation (IR). It also manages the symbol table, a data structure mapping each symbol in the source code to associated information such as location, type and scope.
While the frontend can be a single monolithic function or program, as in a scannerless parser, it was traditionally implemented and analyzed as several phases, which may execute sequentially or concurrently. This method is favored due to its modularity and separation of concerns. Most commonly today, the frontend is broken into three phases: lexical analysis (also known as lexing or scanning), syntax analysis (also known as scanning or parsing), and semantic analysis. Lexing and parsing comprise the syntactic analysis (word syntax and phrase syntax, respectively), and in simple cases, these modules (the lexer and parser) can be automatically generated from a grammar for the language, though in more complex cases these require manual modification. The lexical grammar and phrase grammar are usually context-free grammars, which simplifies analysis significantly, with context-sensitivity handled at the semantic analysis phase. The semantic analysis phase is generally more complex and written by hand, but can be partially or fully automated using attribute grammars. These phases themselves can be further broken down: lexing as scanning and evaluating, and parsing as building a concrete syntax tree (CST, parse tree) and then transforming it into an abstract syntax tree (AST, syntax tree). In some cases additional phases are used, notably line reconstruction and preprocessing, but these are rare.
The main phases of the front end include the following:
- Line reconstruction converts the input character sequence to a canonical form ready for the parser. Languages which strop their keywords or allow arbitrary spaces within identifiers require this phase. The top-down, recursive-descent, table-driven parsers used in the 1960s typically read the source one character at a time and did not require a separate tokenizing phase. Atlas Autocode and Imp (and some implementations of ALGOL and Coral 66) are examples of stropped languages whose compilers would have a Line Reconstruction phase.
- Preprocessing supports macro substitution and conditional compilation. Typically the preprocessing phase occurs before syntactic or semantic analysis; e.g. in the case of C, the preprocessor manipulates lexical tokens rather than syntactic forms. However, some languages such as Scheme support macro substitutions based on syntactic forms.
- Lexical analysis (also known as lexing or tokenization) breaks the source code text into a sequence of small pieces called lexical tokens.[43] This phase can be divided into two stages: the scanning, which segments the input text into syntactic units called lexemes and assigns them a category; and the evaluating, which converts lexemes into a processed value. A token is a pair consisting of a token name and an optional token value.[44] Common token categories may include identifiers, keywords, separators, operators, literals and comments, although the set of token categories varies in different programming languages. The lexeme syntax is typically a regular language, so a finite state automaton constructed from a regular expression can be used to recognize it. The software doing lexical analysis is called a lexical analyzer. This may not be a separate step—it can be combined with the parsing step in scannerless parsing, in which case parsing is done at the character level, not the token level.
- Syntax analysis (also known as parsing) involves parsing the token sequence to identify the syntactic structure of the program. This phase typically builds a parse tree, which replaces the linear sequence of tokens with a tree structure built according to the rules of a formal grammar which define the language’s syntax. The parse tree is often analyzed, augmented, and transformed by later phases in the compiler.[45]
- Semantic analysis adds semantic information to the parse tree and builds the symbol table. This phase performs semantic checks such as type checking (checking for type errors), or object binding (associating variable and function references with their definitions), or definite assignment (requiring all local variables to be initialized before use), rejecting incorrect programs or issuing warnings. Semantic analysis usually requires a complete parse tree, meaning that this phase logically follows the parsing phase, and logically precedes the code generation phase, though it is often possible to fold multiple phases into one pass over the code in a compiler implementation.
Middle end[edit]
The middle end, also known as optimizer, performs optimizations on the intermediate representation in order to improve the performance and the quality of the produced machine code.[46] The middle end contains those optimizations that are independent of the CPU architecture being targeted.
The main phases of the middle end include the following:
- Analysis: This is the gathering of program information from the intermediate representation derived from the input; data-flow analysis is used to build use-define chains, together with dependence analysis, alias analysis, pointer analysis, escape analysis, etc. Accurate analysis is the basis for any compiler optimization. The control-flow graph of every compiled function and the call graph of the program are usually also built during the analysis phase.
- Optimization: the intermediate language representation is transformed into functionally equivalent but faster (or smaller) forms. Popular optimizations are inline expansion, dead-code elimination, constant propagation, loop transformation and even automatic parallelization.
Compiler analysis is the prerequisite for any compiler optimization, and they tightly work together. For example, dependence analysis is crucial for loop transformation.
The scope of compiler analysis and optimizations vary greatly; their scope may range from operating within a basic block, to whole procedures, or even the whole program. There is a trade-off between the granularity of the optimizations and the cost of compilation. For example, peephole optimizations are fast to perform during compilation but only affect a small local fragment of the code, and can be performed independently of the context in which the code fragment appears. In contrast, interprocedural optimization requires more compilation time and memory space, but enable optimizations that are only possible by considering the behavior of multiple functions simultaneously.
Interprocedural analysis and optimizations are common in modern commercial compilers from HP, IBM, SGI, Intel, Microsoft, and Sun Microsystems. The free software GCC was criticized for a long time for lacking powerful interprocedural optimizations, but it is changing in this respect. Another open source compiler with full analysis and optimization infrastructure is Open64, which is used by many organizations for research and commercial purposes.
Due to the extra time and space needed for compiler analysis and optimizations, some compilers skip them by default. Users have to use compilation options to explicitly tell the compiler which optimizations should be enabled.
Back end[edit]
The back end is responsible for the CPU architecture specific optimizations and for code generation[46].
The main phases of the back end include the following:
- Machine dependent optimizations: optimizations that depend on the details of the CPU architecture that the compiler targets.[47] A prominent example is peephole optimizations, which rewrites short sequences of assembler instructions into more efficient instructions.
- Code generation: the transformed intermediate language is translated into the output language, usually the native machine language of the system. This involves resource and storage decisions, such as deciding which variables to fit into registers and memory and the selection and scheduling of appropriate machine instructions along with their associated addressing modes (see also Sethi–Ullman algorithm). Debug data may also need to be generated to facilitate debugging.
Compiler correctness[edit]
Compiler correctness is the branch of software engineering that deals with trying to show that a compiler behaves according to its language specification.[citation needed] Techniques include developing the compiler using formal methods and using rigorous testing (often called compiler validation) on an existing compiler.
Compiled versus interpreted languages[edit]
Higher-level programming languages usually appear with a type of translation in mind: either designed as compiled language or interpreted language. However, in practice there is rarely anything about a language that requires it to be exclusively compiled or exclusively interpreted, although it is possible to design languages that rely on re-interpretation at run time. The categorization usually reflects the most popular or widespread implementations of a language – for instance, BASIC is sometimes called an interpreted language, and C a compiled one, despite the existence of BASIC compilers and C interpreters.
Interpretation does not replace compilation completely. It only hides it from the user and makes it gradual. Even though an interpreter can itself be interpreted, a set of directly executed machine instructions is needed somewhere at the bottom of the execution stack (see machine language).
Furthermore, for optimization compilers can contain interpreter functionality, and interpreters may include ahead of time compilation techniques. For example, where an expression can be executed during compilation and the results inserted into the output program, then it prevents it having to be recalculated each time the program runs, which can greatly speed up the final program. Modern trends toward just-in-time compilation and bytecode interpretation at times blur the traditional categorizations of compilers and interpreters even further.
Some language specifications spell out that implementations must include a compilation facility; for example, Common Lisp. However, there is nothing inherent in the definition of Common Lisp that stops it from being interpreted. Other languages have features that are very easy to implement in an interpreter, but make writing a compiler much harder; for example, APL, SNOBOL4, and many scripting languages allow programs to construct arbitrary source code at runtime with regular string operations, and then execute that code by passing it to a special evaluation function. To implement these features in a compiled language, programs must usually be shipped with a runtime library that includes a version of the compiler itself.
Types[edit]
One classification of compilers is by the platform on which their generated code executes. This is known as the target platform.
A native or hosted compiler is one whose output is intended to directly run on the same type of computer and operating system that the compiler itself runs on. The output of a cross compiler is designed to run on a different platform. Cross compilers are often used when developing software for embedded systems that are not intended to support a software development environment.
The output of a compiler that produces code for a virtual machine (VM) may or may not be executed on the same platform as the compiler that produced it. For this reason, such compilers are not usually classified as native or cross compilers.
The lower level language that is the target of a compiler may itself be a high-level programming language. C, viewed by some as a sort of portable assembly language, is frequently the target language of such compilers. For example, Cfront, the original compiler for C++, used C as its target language. The C code generated by such a compiler is usually not intended to be readable and maintained by humans, so indent style and creating pretty C intermediate code are ignored. Some of the features of C that make it a good target language include the #line directive, which can be generated by the compiler to support debugging of the original source, and the wide platform support available with C compilers.
While a common compiler type outputs machine code, there are many other types:
- Source-to-source compilers are a type of compiler that takes a high-level language as its input and outputs a high-level language. For example, an automatic parallelizing compiler will frequently take in a high-level language program as an input and then transform the code and annotate it with parallel code annotations (e.g. OpenMP) or language constructs (e.g. Fortran’s
DOALLstatements). Other terms for a source-to-source compiler are transcompiler or transpiler.[48] - Bytecode compilers compile to assembly language of a theoretical machine, like some Prolog implementations
- This Prolog machine is also known as the Warren Abstract Machine (or WAM).
- Bytecode compilers for Java, Python are also examples of this category.
- Just-in-time compilers (JIT compiler) defer compilation until runtime. JIT compilers exist for many modern languages including Python, JavaScript, Smalltalk, Java, Microsoft .NET’s Common Intermediate Language (CIL) and others. A JIT compiler generally runs inside an interpreter. When the interpreter detects that a code path is «hot», meaning it is executed frequently, the JIT compiler will be invoked and compile the «hot» code for increased performance.
- For some languages, such as Java, applications are first compiled using a bytecode compiler and delivered in a machine-independent intermediate representation. A bytecode interpreter executes the bytecode, but the JIT compiler will translate the bytecode to machine code when increased performance is necessary.[49][non-primary source needed]
- Hardware compilers (also known as synthesis tools) are compilers whose input is a hardware description language and whose output is a description, in the form of a netlist or otherwise, of a hardware configuration.
- The output of these compilers target computer hardware at a very low level, for example a field-programmable gate array (FPGA) or structured application-specific integrated circuit (ASIC).[50][non-primary source needed] Such compilers are said to be hardware compilers, because the source code they compile effectively controls the final configuration of the hardware and how it operates. The output of the compilation is only an interconnection of transistors or lookup tables.
- An example of hardware compiler is XST, the Xilinx Synthesis Tool used for configuring FPGAs.[51][non-primary source needed] Similar tools are available from Altera,[52][non-primary source needed] Synplicity, Synopsys and other hardware vendors.[citation needed]
- An assembler is a program that compiles human readable assembly language to machine code, the actual instructions executed by hardware. The inverse program that translates machine code to assembly language is called a disassembler.
- A program that translates from a low-level language to a higher level one is a decompiler.[53]
- A program that translates into an object code format that is not supported on the compilation machine is called a cross compiler and is commonly used to prepare code for execution on embedded software applications.[54][better source needed]
- A program that rewrites object code back into the same type of object code while applying optimisations and transformations is a binary recompiler.
See also[edit]
- Abstract interpretation
- Bottom-up parsing
- Compile and go system
- Compile farm
- List of compilers
- List of important publications in computer science § Compilers
- Metacompilation
References[edit]
- ^ «Encyclopedia: Definition of Compiler». PCMag.com. Retrieved 2 July 2022.
{{cite web}}: CS1 maint: url-status (link) - ^ a b Compilers: Principles, Techniques, and Tools by Alfred V. Aho, Ravi Sethi, Jeffrey D. Ullman — Second Edition, 2007
- ^ SUDARSANAM, ASHOK; MALIK, SHARAD; FUJITA, MASAHIRO (2002). «A Retargetable Compilation Methodology for Embedded Digital Signal Processors Using a Machine-Dependent Code Optimization Library». Readings in Hardware/Software Co-Design. Elsevier. pp. 506–515. doi:10.1016/b978-155860702-6/50045-4. ISBN 9781558607026.
A compiler is a computer program that translates a program written in a high-level language (HLL), such as C, into an equivalent assembly language program [2].
- ^ Sun, Chengnian; Le, Vu; Zhang, Qirun; Su, Zhendong (2016). «Toward Understanding Compiler Bugs in GCC and LLVM». ACM. Issta 2016: 294–305. doi:10.1145/2931037.2931074. ISBN 9781450343909. S2CID 8339241.
- ^ lecture notes
Compilers: Principles, Techniques, and Tools
Jing-Shin Chang
Department of Computer Science & Information Engineering
National Chi-Nan University - ^ Naur, P. et al. «Report on ALGOL 60». Communications of the ACM 3 (May 1960), 299–314.
- ^ Chomsky, Noam; Lightfoot, David W. (2002). Syntactic Structures. Walter de Gruyter. ISBN 978-3-11-017279-9.
- ^ Gries, David (2012). «Appendix 1: Backus-Naur Form». The Science of Programming. Springer Science & Business Media. p. 304. ISBN 978-1461259831.
- ^ Iverson, Kenneth E. (1962). A Programming Language. John Wiley & Sons. ISBN 978-0-471430-14-8.
- ^ Backus, John. «The history of FORTRAN I, II and III» (PDF). History of Programming Languages. Softwarepreservation.org. Archived (PDF) from the original on 10 October 2022.
- ^ Porter Adams, Vicki (5 October 1981). «Captain Grace M. Hopper: the Mother of COBOL». InfoWorld. 3 (20): 33. ISSN 0199-6649.
- ^ McCarthy, J.; Brayton, R.; Edwards, D.; Fox, P.; Hodes, L.; Luckham, D.; Maling, K.; Park, D.; Russell, S. (March 1960). «LISP I Programmers Manual» (PDF). Boston, Massachusetts: Artificial Intelligence Group, M.I.T. Computation Center and Research Laboratory.
- ^ Compilers Principles, Techniques, & Tools 2nd edition by Aho, Lam, Sethi, Ullman ISBN 0-321-48681-1
- ^ Hopper, Grace Murray (1952). «The Education of a Computer». Proceedings of the 1952 ACM National Meeting (Pittsburgh): 243–249. doi:10.1145/609784.609818. S2CID 10081016.
- ^ Ridgway, Richard K. (1952). «Compiling routines». Proceedings of the 1952 ACM National Meeting (Toronto): 1–5. doi:10.1145/800259.808980. S2CID 14878552.
- ^ Hoare, C.A.R. (December 1973). «Hints on Programming Language Design» (PDF). p. 27. Archived (PDF) from the original on 10 October 2022. (This statement is sometimes erroneously attributed to Edsger W. Dijkstra, also involved in implementing the first ALGOL 60 compiler.)
- ^ Abelson, Hal; Dybvig, R. K.; et al. Rees, Jonathan; Clinger, William (eds.). «Revised(3) Report on the Algorithmic Language Scheme, (Dedicated to the Memory of ALGOL 60)». Retrieved 20 October 2009.
- ^ «Recursive Functions of Symbolic Expressions and Their Computation by Machine», Communications of the ACM, April 1960
- ^ McCarthy, John; Abrahams, Paul W.; Edwards, Daniel J.; Hart, Timothy P.; Levin, Michael I. (1965). Lisp 1.5 Programmers Manual. The MIT Press. ISBN 9780262130110.
- ^ «BCPL: A tool for compiler writing and system programming» M. Richards, University Mathematical Laboratory Cambridge, England 1969
- ^ BCPL: The Language and Its Compiler, M Richards, Cambridge University Press (first published 31 December 1981)
- ^ The BCPL Cintsys and Cintpos User Guide, M. Richards, 2017
- ^ Corbató, F. J.; Vyssotsky, V. A. «Introduction and Overview of the MULTICS System». 1965 Fall Joint Computer Conference. Multicians.org.
- ^ Report II of the SHARE Advanced Language Development Committee, 25 June 1964
- ^ Multicians.org «The Choice of PL/I» article, Editor /tom Van Vleck
- ^ «PL/I As a Tool for System Programming», F.J. Corbato, Datamation 6 May 1969 issue
- ^ «The Multics PL/1 Compiler», R. A. Freiburghouse, GE, Fall Joint Computer Conference 1969
- ^ Dennis M. Ritchie, «The Development of the C Language», ACM Second History of Programming Languages Conference, April 1993
- ^ S.C. Johnson, «a Portable C Compiler: Theory and Practice», 5th ACM POPL Symposium, January 1978
- ^ A. Snyder, A Portable Compiler for the Language C, MIT, 1974.
- ^ K. Nygaard, University of Oslo, Norway, «Basic Concepts in Object Oriented Programming», SIGPLAN Notices V21, 1986
- ^ B. Stroustrup: «What is Object-Oriented Programming?» Proceedings 14th ASU Conference, 1986.
- ^ Bjarne Stroustrup, «An Overview of the C++ Programming Language», Handbook of Object Technology (Editor: Saba Zamir, ISBN 0-8493-3135-8)
- ^ Leverett, Cattell, Hobbs, Newcomer, Reiner, Schatz, Wulf: «An Overview of the Production Quality Compiler-Compiler Project», CMU-CS-89-105, 1979
- ^ W. Wulf, K. Nori, «Delayed binding in PQCC generated compilers», CMU Research Showcase Report, CMU-CS-82-138, 1982
- ^ Joseph M. Newcomer, David Alex Lamb, Bruce W. Leverett, Michael Tighe, William A. Wulf — Carnegie-Mellon University and David Levine, Andrew H. Reinerit — Intermetrics: «TCOL Ada: Revised Report on An Intermediate Representation for the DOD Standard Programming Language», 1979
- ^ William A. Whitaker, «Ada — the project: the DoD High Order Working Group», ACM SIGPLAN Notices (Volume 28, No. 3, March 1991)
- ^ CECOM Center for Software Engineering Advanced Software Technology, «Final Report — Evaluation of the ACEC Benchmark Suite for Real-Time Applications», AD-A231 968, 1990
- ^ P.Biggar, E. de Vries, D. Gregg, «A Practical Solution for Scripting Language Compilers», submission to Science of Computer Programming, 2009
- ^ M.Hall, D. Padua, K. Pingali, «Compiler Research: The Next 50 Years», ACM Communications 2009 Vol 54 #2
- ^ Cooper and Torczon 2012, p. 8
- ^ Lattner, Chris (2017). «LLVM». In Brown, Amy; Wilson, Greg (eds.). The Architecture of Open Source Applications. Archived from the original on 2 December 2016. Retrieved 28 February 2017.
- ^ Aho, Lam, Sethi, Ullman 2007, p. 5-6, 109-189
- ^ Aho, Lam, Sethi, Ullman 2007, p. 111
- ^ Aho, Lam, Sethi, Ullman 2007, p. 8, 191-300
- ^ a b Blindell, Gabriel Hjort (3 June 2016). Instruction selection : principles, methods, and applications. Switzerland. ISBN 9783319340197. OCLC 951745657.
- ^ Cooper and Toczon (2012), p. 540
- ^ Ilyushin, Evgeniy; Namiot, Dmitry (2016). «On source-to-source compilers». International Journal of Open Information Technologies. 4 (5): 48–51. Archived from the original on 14 September 2022. Retrieved 14 September 2022.
- ^ Aycock, John (2003). «A Brief History of Just-in-Time». ACM Comput. Surv. 35 (2, June): 93–113. doi:10.1145/857076.857077. S2CID 15345671.
- ^ Swartz, Jordan S.; Betz, Vaugh; Rose, Jonathan (22–25 February 1998). «A Fast Routability-Driven Router for FPGAs» (PDF). FPGA ’98 Proceedings of the 1998 ACM/SIGDA Sixth International Symposium on Field Programmable Gate Arrays. Monterey, CA: ACM: 140–149. doi:10.1145/275107.275134. ISBN 978-0897919784. S2CID 7128364. Archived (PDF) from the original on 9 August 2017.
- ^ Xilinx Staff (2009). «XST Synthesis Overview». Xilinx, Inc. Archived from the original on 2 November 2016. Retrieved 28 February 2017.
- ^ Altera Staff (2017). «Spectra-Q™ Engine». Altera.com. Archived from the original on 10 October 2016. Retrieved 28 February 2017.
- ^ «Decompilers — an overview | ScienceDirect Topics». www.sciencedirect.com. Retrieved 12 June 2022.
- ^ Chandrasekaran, Siddharth (26 January 2018). «Cross Compilation Demystified». embedjournal.com. Retrieved 5 March 2023.
Further reading[edit]
- Aho, Alfred V.; Sethi, Ravi; Ullman, Jeffrey D. (1986). Compilers: Principles, Techniques, and Tools (1st ed.). Addison-Wesley. ISBN 9780201100884.
- Allen, Frances E. (September 1981). «A History of Language Processor Technology in IBM». IBM Journal of Research and Development. IBM. 25 (5): 535–548. doi:10.1147/rd.255.0535.
- Allen, Randy; Kennedy, Ken (2001). Optimizing Compilers for Modern Architectures. Morgan Kaufmann Publishers. ISBN 978-1-55860-286-1.
- Appel, Andrew Wilson (2002). Modern Compiler Implementation in Java (2nd ed.). Cambridge University Press. ISBN 978-0-521-82060-8.
- Appel, Andrew Wilson (1998). Modern Compiler Implementation in ML. Cambridge University Press. ISBN 978-0-521-58274-2.
- Bornat, Richard (1979). Understanding and Writing Compilers: A Do It Yourself Guide (PDF). Macmillan Publishing. ISBN 978-0-333-21732-0. Archived from the original (PDF) on 15 June 2007. Retrieved 11 April 2007.
- Calingaert, Peter (1979). Horowitz, Ellis (ed.). Assemblers, Compilers, and Program Translation. Computer software engineering series (1st printing, 1st ed.). Potomac, Maryland: Computer Science Press, Inc. ISBN 0-914894-23-4. ISSN 0888-2088. LCCN 78-21905. Retrieved 20 March 2020. (2+xiv+270+6 pages)
- Cooper, Keith Daniel; Torczon, Linda (2012). Engineering a compiler (2nd ed.). Amsterdam: Elsevier/Morgan Kaufmann. p. 8. ISBN 9780120884780. OCLC 714113472.
- Gries, David (1971). Compiler Construction for Digital Computers (in English, Spanish, Japanese, Chinese, Italian, and Russian). New York: John Wiley and Sons. ISBN 0-471-32776-X.
The first text on compiler construction.
- McKeeman, William Marshall; Horning, James J.; Wortman, David B. (1970). A Compiler Generator. Englewood Cliffs, NJ: Prentice-Hall. ISBN 978-0-13-155077-3.
- Muchnick, Steven (1997). Advanced Compiler Design and Implementation. Morgan Kaufmann Publishers. ISBN 978-1-55860-320-2.
- Scott, Michael Lee (2005). Programming Language Pragmatics (2nd ed.). Morgan Kaufmann. ISBN 978-0-12-633951-2.
- Srikant, Y. N.; Shankar, Priti (2003). The Compiler Design Handbook: Optimizations and Machine Code Generation. CRC Press. ISBN 978-0-8493-1240-3.
- Terry, Patrick D. (1997). Compilers and Compiler Generators: An Introduction with C++. International Thomson Computer Press. ISBN 978-1-85032-298-6.
- Wirth, Niklaus (1996). Compiler Construction (PDF). Addison-Wesley. ISBN 978-0-201-40353-4. Archived from the original (PDF) on 17 February 2017. Retrieved 24 April 2012.
- Compiler textbook references A collection of references to mainstream Compiler Construction Textbooks
External links[edit]
![]()
Look up compiler in Wiktionary, the free dictionary.
![]()
Wikimedia Commons has media related to Compilers.
- Compilers at Curlie
- Incremental Approach to Compiler Construction – a PDF tutorial
- Basics of Compiler Design at the Wayback Machine (archived 15 May 2018)
- Short animation on YouTube explaining the key conceptual difference between compilers and interpreters
- Syntax Analysis & LL1 Parsing on YouTube
- Let’s Build a Compiler, by Jack Crenshaw
- Forum about compiler development at the Wayback Machine (archived 10 October 2014)
Компилятор — это программа, которая переводит текст, написанный на языке программирования, в машинные коды. С помощью компиляторов компьютеры могут понимать разные языки программирования, в том числе высокоуровневые, то есть близкие к человеку и далекие от «железа».
Процесс работы компилятора с кодом называется компиляцией, или сборкой. По сути, компилятор — комплексный «переводчик», который собирает, или компилирует, программу в исполняемый файл. Исполняемый файл — это набор инструкций для компьютера, который тот понимает и может выполнить.
Языки программирования, для перевода которых используются компиляторы, называются компилируемыми.
Для чего нужен компилятор
Изначально компьютер не понимает смысл написанного на любом языке программирования. Язык компьютера — машинные коды, нули и единицы, в которых зашифрована информация и команды. Писать на машинных кодах программы практически невозможно: даже простейшее действие будет отнимать много часов работы программиста. Поэтому появились языки программирования, более понятные для людей, и специальные программы, которые переводят эти языки в машинные коды. Эти программы и есть компиляторы.
Без компилятора любой код на компилируемом языке программирования будет для компьютера просто текстом — он не распознает команды и не сможет их выполнить. Поэтому компилятор нужен, чтобы программы могли выполняться. Без него ничего не будет работать.
Еще одна задача компилятора — собрать все модули, например подключенные библиотеки, в единый файл. Нужно, чтобы исполняемый файл содержал в себе все необходимое для нормальной работы программы и полного выполнения инструкций.
Компилятор и интерпретатор: в чем разница
Компиляция — не единственный подход к «переводу» человекопонятного языка программирования на машинный. Еще есть интерпретаторы и байт-код, но там технологии совсем другие.
Интерпретатор — это тоже программа, которая «переводит» текст на высокоуровневом языке программирования, но делает это иначе. Она не собирает весь код в один исполняемый файл для последующего запуска, а исполняет код сразу, построчно. Это чуть медленнее, но иногда удобнее. Языки, использующие интерпретаторы, называются интерпретируемыми.
Байт-код — «промежуточное звено» между подходами компиляции и интерпретации. Программа преобразуется в особый код, который запускается под специальной виртуальной машиной. Языков, которые работают так, относительно немного, самый известный и яркий пример — Java.
В каких языках используются компиляторы
Среди популярных сегодня языков компилируемыми являются Swift и Go, а также C / C++ и Objective-C. Другие примеры — Visual Basic, Haskell, Pascal / Delphi, Rust, а также Lisp, Prolog и прочие менее известные языки. Разумеется, компилируемым является и язык ассемблера — очень низкоуровневый и написанный напрямую на машинных кодах.
Отдельно можно выделить языки, которые трансформируются в байт-код — это тоже своего рода компиляция. К ним относятся Java, Scala и Kotlin, а также C# и языки платформы .NET.
На каких языках пишут компиляторы
Другие языки. Писать компилятор на машинном коде тяжело и долго, порой практически невозможно. Поэтому их пишут на уже существующих языках: получается, что большинство языков написано на других.
Например, один из компиляторов языка Go частично написан на C++, самый первый компилятор C++ — на ассемблере, а уже ассемблер — на машинных кодах.
Тот же язык. Написать компилятор для языка программирования можно на других версиях того же языка — такой подход разрешен и активно используется в разработке. Это нужно, чтобы компиляторы были более гибкими и «умными» и могли поддерживать больше возможностей, — ассемблер довольно примитивен и не решает всех задач.
Выглядит это так:
- первый, более простой компилятор пишется на ассемблере;
- второй пишется уже на нужном языке и компилируется первым компилятором;
- переведенный в машинные коды второй компилятор компилирует свои же исходники — получается более новая и мощная версия его же.
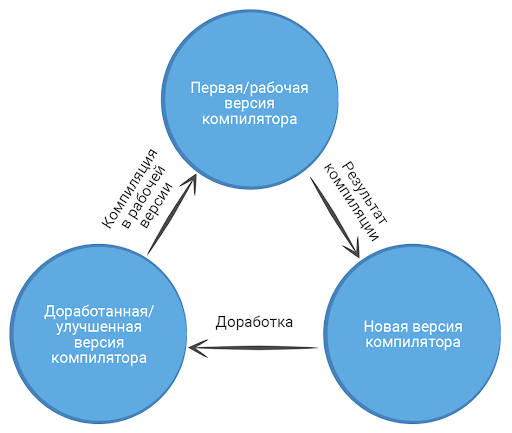
Например, большинство современных компиляторов для C / C++ написано на C / C++. Такие компиляторы называют самокомпилируемыми.
Почему у одного языка может быть несколько компиляторов
У большинства языков программирования несколько компиляторов. Их еще называют реализациями. Изначальную реализацию пишет создатель языка, потом со временем появляются альтернативные. Зачем это делается? Цели могут быть разными:
- написать более современный и функциональный компилятор, обновить язык;
- оптимизировать язык и сделать его эффективнее;
- создать свободную реализацию, которую сможет дополнять сообщество;
- исправить ошибки, которые есть в существующих реализациях;
- перенести язык на другую платформу, и так далее.
Подходы к оптимизации, портированию и выполнению других целей у всех групп разработчиков свои. Поэтому разные компиляторы одного и того же языка могут различаться скоростью, особенностями архитектуры, назначением и другими параметрами. Синтаксис языка при этом остается таким же, но есть особые ситуации, когда одна и та же строчка может выполняться по-разному в зависимости от компилятора.
Какими бывают компиляторы
Компиляторы очень многообразны. Есть такие, которые имеют узкую специализацию, например запускаются только под процессоры определенного семейства и оптимизированы под них. Есть и более широкие — так называемые кросс-компиляторы, которые могут поддерживать несколько операционных систем.
Один компилятор может «знать» несколько языков программирования. Яркий пример такого решения — GCC, или GNU Compiler Collection, кросс-компилятор для нескольких операционных систем и языков, полностью бесплатный и свободный. На нем написано программное обеспечение GNU.
Существуют и так называемые компиляторы компиляторов. Они генерируют компиляторы для языка на основе его формального описания.
Как устроены и работают компиляторы
Простыми словами, они «читают» пришедшую к ним на вход программу и переводят ее команды в соответствующие им наборы машинных кодов. Детали уже сложнее и различаются в зависимости от реализации. Например, есть модульные гибкие компиляторы, написанные на высокоуровневых языках, есть отладочные компиляторы, способные устранять часть синтаксических ошибок, и так далее.
Сама компиляция может быть:
- построчной — в машинный код по очереди переводится каждая строка, что похоже на интерпретацию, но отличается технически;
- пакетной — код разбивается на блоки, или пакеты, и компилируется поблочно;
- условной — особенности компиляции зависят от условий, которые прописаны в исходном коде компилируемой программы.
Сначала компилятор разбирает, что написано, потом анализирует команды, а потом генерирует машинные коды. Он не запускает программу, запуск — это отдельное действие.
Преимущества компилируемых языков
- Компилируемые языки обычно быстрее, чем интерпретируемые, и их легче оптимизировать.
- Итоговый размер кода у компилируемых языков, как правило, меньше, чем у интерпретируемых.
- В компилируемых языках намного шире возможность контролировать аппаратные ресурсы. Это не значит, что они все низкоуровневые, но обратное — верно: практически все низкоуровневые языки — компилируемые.
- Когда процессоры становятся мощнее, именно компилируемые языки могут в должной мере задействовать их преимущества.
- Код после компилятора лучше оптимизируется под конкретные устройства, архитектуру «железа», эффективно задействует память и не тратит лишних ресурсов.
- Компилируемые языки обычно мощные и высокопроизводительные, поэтому на них пишут игры и другие серьезно нагруженные приложения.
Недостатки компилируемых языков
- В отличие от интерпретируемых языков, компилируемые не выполняют код сразу — его сначала нужно собрать, а это лишний шаг и лишнее время.
- Код сложнее в отладке: приходится заново компилировать его при каждом, даже небольшом изменении. Сам процесс поиска и устранения ошибок бывает довольно неочевидным.
- Машинный код жестко связан с архитектурой платформы и различается в зависимости от системы. Поэтому компилируемые языки — по умолчанию не кроссплатформенные. Для переноса языка на другую операционную систему понадобится писать новый компилятор. Правда, есть исключения в виде универсальных кросс-компиляторов, работающих под разными платформами, но они подходят не для всего.
- Для новичков проблема еще и в том, что компилируемые языки часто сложнее, чем интерпретируемые. Изучать их с нуля может быть тяжело, хотя и тут есть исключения.
Как пользоваться компилятором
Начинающий разработчик редко взаимодействует с компилятором напрямую. Он скачивает язык программирования, в том числе его компилятор, а потом работает в редакторе кода или IDE. Среда разработки сама запускает компилятор каждый раз, когда пользователь кликает на кнопку сборки или выполнения программы. Для этого его не нужно вызывать вручную. Иногда среда может сама включать в себя несколько компиляторов и выбирать подходящий в каждом случае.
Поэтому трогать компилятор на ранних этапах не имеет смысла — просто стоит помнить, что он есть, чтобы лучше разбираться в происходящем. Но он может пригодиться, если вы захотите скомпилировать что-то без среды разработки, например прямо в командной строке. Тогда его придется вызвать с помощью специальной команды — она своя для каждого решения.
У любого ПО есть документация, так что, если вы хотите узнать больше о компиляторе, которым пользуетесь, можете прочитать ее.
Узнайте больше об устройстве и работе языков программирования на курсах — получите новую профессию и станьте востребованным IT-специалистом.
В этом гайде вы узнаете о том, что такое компилятор и как он работает. Мы разберем этапы компиляции и от чего зависит выбор подходящего компилятора. Этот материал поможет лучше понять, как компьютер выполняет программный код и почему иногда код не компилируется.
- Зачем нужен компилятор?
- Как работает компилятор?
- На чем написан компилятор?
- Какие бывают компиляторы?
- Какие ошибки может определить компилятор?
- Выводы и рекомендации
- Частые вопросы
- Дополнительные материалы
Зачем нужен компилятор?
Процессор — самая важная часть компьютера. Он обрабатывает информацию, выполняет команды пользователя и следит за работой всех подключенных устройств. Но процессор может разобрать только машинный код — набор 0 и 1, которые записаны в определённом порядке.
Почему именно 0 и 1? В процессор поступают электрические сигналы. Сильный сигнал обозначается цифрой 1, а слабый — 0. Набор таких цифр обозначает какую-то команду. Процессор ее распознает и выполняет.
Программы для первых компьютеров выглядели как огромные наборы 0 и 1. Чтобы записать такую программу, инженеры пользовались гибкими картонными карточками — перфокартами. Цифры на перфокарте записывались поочередно, в несколько строк. Чтобы записать 1, программист делал отверстие в карте. Места без отверстия обозначали 0.

Компьютер считывал перфокарту специальным устройством и выполнял записанную команду. Для одной программы составляли сотни перфокарт.
Писать их было долго и сложно, поэтому инженеры стали создавать языки программирования, обозначая команды словами и знаками. Для того, чтобы процессор понимал, какие команды записаны в программе, программисты создали компилятор — программу, которая преобразует программный код в машинный.
Как работает компилятор?
Преобразование программного кода в машинный называется компиляцией. Компиляция только преобразует код. Она не запускает его на исполнение. В этот момент он «статически» (то есть без запуска) транслируется в машинный код. Это сложный процесс, в котором сначала текст программы разбирается на части и анализируется, а затем генерируется код, понятный процессору.
Разберём этапы компиляции на примере вычисления периметра прямоугольника:
#include <iostream>
int main()
{
double a=2.5, b=5, P;
P = 2 * (a + b);
printf("Width of the rectangle - %4.1f", a);// => Width of the rectangle - 2.5
printf("nLength of the rectangle - %4.1f", b);// => Length of the rectangle - 5.0
printf("nPerimeter of the rectangle is %4.1f", P);// => Perimeter of the rectangle is 15.0
return 0;
}
После запуска программы компилятору нужно определить, какие команды в ней записаны. Сначала компилятор разделяет программу на слова и знаки — токены, и записывает их в список. Такой процесс называется лексическим анализом. Его главная задача — получить токены.
# include <iostream> int main ( ) { double a = 2.5 , b = 5 , P ; P = 2 * ( a + b ) ; printf ( " Width of the rectangle - % 4.1 f " , a ) ; printf ( " n Length of the rectangle - % 4.1 f " , b ) ; printf ( " n Perimeter of the rectangle is % 4.1 f " , P ) ; return 0 ; }
Затем компилятор читает список и ищет токен-операторы. Это могут быть оператор присваивания(=), арифметические операторы(+,-,*,/), оператор вывода(printf()) и другие операторы языка программирования. Такие операторы работают с числами, текстом и переменными.
Компилятор должен понять, какие токены в списке связаны с токен-оператором. Чтобы сделать это правильно, для каждого оператора строится специальная структура — логическое дерево или дерево разбора.
Так операция P = 2*(a + b) будет преобразована в логическое дерево:
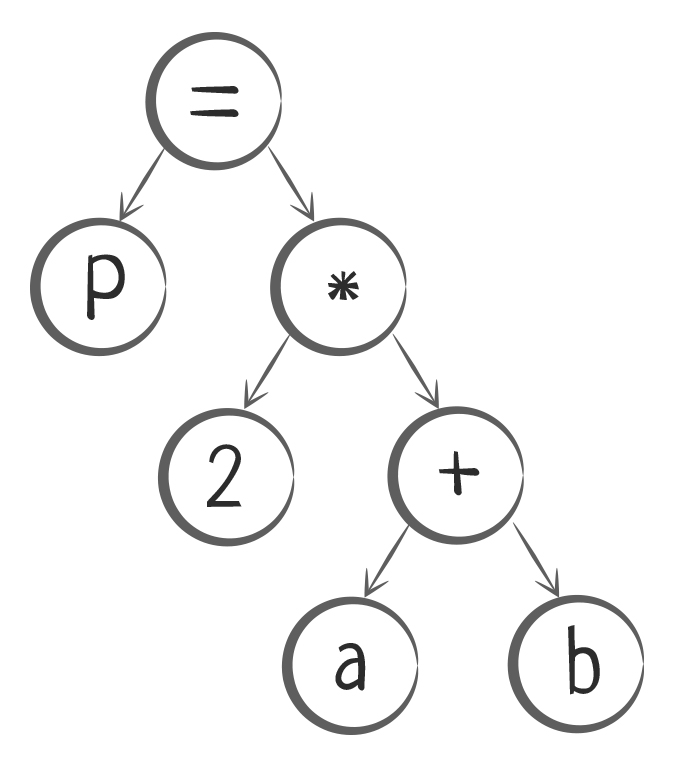
Теперь каждое дерево нужно разобрать на команды, и каждую команду преобразовать в машинный код.
Компилятор начинает читать дерево снизу вверх и составляет список команд:
- Взять переменную
a, взять переменнуюb, сложить их - Взять результат сложения, взять число
2и найти их произведение - Результат произведения присвоить (записать) в переменную
P
Компилятор еще раз проверяет команды, находит ошибки и старается улучшить код. При успешном завершении этого этапа, компилятор переводит каждую команду в набор 0 и 1. Наборы записываются в файл, который сможет прочитать и выполнить процессор.
10111011 00010001 00000001 10111001 00001101 00000000 10110100 00001110 10001010 00000111 01000011 11001101 00010000 11100010 11111001 11001101 00100000 01001000 01100101 01101100 01101100 01101111 00101100 00100000 01010111 01101111 01110010 01101100 01100100 00100001
На чем написан компилятор?
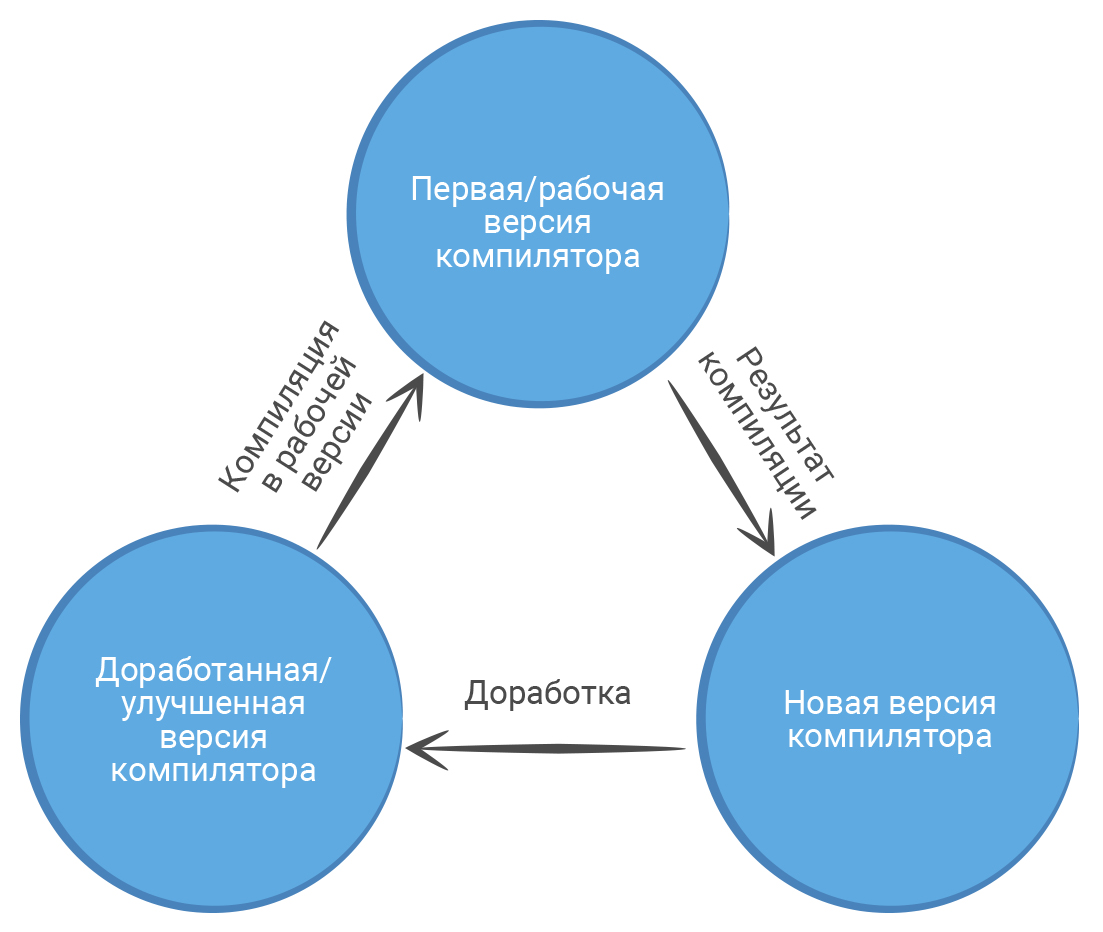
В 1950-е годы группа разработчиков IBM под руководством Джона Бэкуса разработала первый высокоуровневый язык программирования Fortran, который позволил писать программы на понятном человеку языке. Помимо языка, инженеры работали и над компилятором. Он представлял собой программу с набором исполняемых команд, которая могла компилировать другие программы на Fortran, в том числе и улучшенную версию себя.
В дальнейшем язык Fortran и его компилятор использовали, чтобы написать компиляторы для новых языков программирования. Такой подход используют программисты и в настоящее время.
Писать машинный код долго и неудобно. К тому же, для современных процессоров он может отличаться. Придется писать несколько версий одного и того же компилятора для разных компьютеров. Быстрее и проще написать компилятор на существующем языке программирования. Для этого разработчики выбирают удобный язык и пишут на нем первую версию своего компилятора. Он будет более универсальным для компьютеров и легко скомпилирует улучшенную версию себя.
Какие бывают компиляторы?
Ни один компилируемый язык программирования не обходится без компилятора. Некоторые компиляторы работают с несколькими языками программирования. Но программист должен учитывать еще и параметры компьютера, на котором программа будет запускаться.
Дело в том, что современные процессоры отличаются друг от друга устройством, поэтому машинный код для одного процессора будет понятен, а для другого нет. Это касается и операционных систем: одна и та же программа будет работать на Windows, но не запустится на Linux или MacOS. Поэтому нужно пользоваться тем компилятором, который работает с нужным процессором и операционной системой.
Если программа будет работать на нескольких операционных системах, то нужен кросс-компилятор — компилятор, который преобразует универсальный машинный код. Например, GNU Compiler Collection(сокращенно GCC) поддерживает C++, Objective-C, Java, Фортран, Ada, Go и поддерживает разную архитектуру процессоров.
Начинающие программисты даже не знают о наличии компилятора на компьютере. Они пишут программы в интегрированной среде разработки, в которую встроен компилятор, а иногда и не один. В этом случае, выбор компилятора делает среда, а не программист. Например, MS Visual Studio поддерживает компиляторы для операционных систем Windows, Linux, Android. Выбирая тип проекта, Visual Studio определяет процессор и операционную систему компьютера, и после этого выбирает подходящий компилятор.
Какие ошибки может определить компилятор?
Когда компилятор анализирует текст программы, он проверяет, соответствует ли запись оператора стандартам языка. Если найдено несоответствие, то компилятор выводит об этом информацию пользователю в виде ошибки. Когда вся программа разобрана, пользователь видит список ошибок, которые есть в коде, и может их исправить.
Пока программист не исправит ошибки, компилятор не перейдет к следующему этапу — генерации машинного кода для процессора.
Чаще всего компилятор показывает пользователю:
- ошибки объявления переменных или отсутствие их начальных значений
- ошибки несоответствия типов
- ошибки неправильной записи операторов и функций
Иногда компилятор определяет код, который при выполнении дает неправильный результат. Но преобразовать такую программу в машинный код все-таки можно. В этом случае компилятор показывает пользователю предупреждение. Такая реакция компилятора больше похожа на рекомендации, но на них стоит обратить внимание. Программист сам решает оставить код с предупреждением или изменить программу.
Анализируя текст программы, компилятор не только ищет ошибки, но еще и упрощает ее код. Такой процесс называется оптимизацией.
Во время оптимизации компилятор изменяет программный код, но функции, которые выполняла программа, остаются прежними.
Выводы и рекомендации
Компилятор — переводчик между программистом и процессором. Он преобразует текст программы в машинный код, определяет ряд ошибок в программе и оптимизирует ее работу.
Выбирая, где компилировать программу, важно помнить о том, что машинный код для процессоров и операционных систем будет разным, и подобрать правильный компилятор.
Чем точнее компилятор определит команды, тем корректнее и быстрее будет работать программа. Для этого следуйте простым рекомендациям:
- использовать простые, понятные команды;
- помнить о соответствии типов данных;
- внимательно набирать код, избегая синтаксических ошибок;
- избегать повторяющихся действий и бесполезных переменных.
Частые вопросы
Чем компилятор отличается от интерпретатора?
Компилятор это программа, которая выполняет преобразование текста программы в другое представление, обычно машинный код, без его запуска, статически. Затем эта программа уже может быть запущена на выполнение. Интерпретатор сразу запускает код и выполняет его в процессе чтения. Промежуточного этапа как в компиляции нет.
Дополнительные материалы
- Компилятор
- ARM против x86: В чем разница между двумя архитектурами процессоров?

Если вы программист, то наверняка слышали слово “компилятор”. Но знаете ли вы, что это такое на самом деле? Вы когда-нибудь задумывались, что происходит под капотом, когда вы запускаете команду javac(если у вас код на Java)? Вы когда-нибудь хотели создать свой собственный язык программирования? — и просто заводили бесполезный репозиторий GitHub, где все равно есть только один readme.md, потому что вы даже не знаете, с чего начать. Я думаю, что начинать стоит с этого: узнать больше о компиляторе.

Итак, в этой статье мы разберёмся, что представляет собой компилятор. Если вы опытный программист, который знает про компилятор каждую мелочь, то извините, эта статья не для вас. Но если вы — тот самый парень из абзаца выше, то вперёд за мной, в кроличью нору. На протяжении статьи я буду обсуждать следующие подтемы:
- введение в компилятор;
- типы компиляторов;
- архитектура компилятора.
Мне хочется, чтобы к концу статьи вы могли понимать, что происходит под капотом, когда вы запускаете команду javac, а также получили некоторое представление о том, как написать свой собственный язык программирования.
Вступление
Компилятор — это не что иное, как переводчик исходного кода.
Задача компилятора — перевести исходный код с одного языка на другой. Это означает, что если вы скормите компилятору исходный код Java, то сможете получить исходный код Python (не самый лучший пример, просто для понимания сути. На самом деле вы получите байт-код Java, который можно запустить на JVM). Для выполнения этого процесса у компилятора есть несколько взаимосвязанных компонентов.
Типы компиляторов
Мы можем классифицировать компиляторы по-разному. В этой статье я расскажу о двух способах классификации компиляторов, однако особенно углубляться в это не буду.
Классификация компиляторов в соответствии с этапами компиляции
Здесь мы рассмотрим количество этапов, которые проходит компилятор. Некоторые компиляторы непосредственно преобразуют высокоуровневый исходный код в машинный код, а некоторые — сначала преобразуют высокоуровневый исходный код в промежуточное представление перед преобразованием в машинный код.
Таким образом, в соответствии с этой классификацией можно выделить три типа компиляторов:
- Однопроходной компилятор.
- Двухпроходной компилятор.
- Многопроходной компилятор.
Если вы хотите узнать больше об этой классификации компиляторов, посмотрите сюда.
Классификация компиляторов в соответствии с исходным кодом и целевым кодом
Для преобразования исходного кода в целевой применяются разные подходы. Некоторые компиляторы преобразуют код на высокоуровневом языке в машинный. Некоторые компиляторы преобразуют с одного языка высокого уровня на другой язык высокого уровня. Таким образом, здесь выделяются следующие типы:
- Кросс-компиляторы — такие компиляторы работают на одной платформе и производят код для запуска на другой платформе. Например, компилятор работает на платформе X и создает код для запуска на платформе Y. Такими компиляторами пользуются разработчики встроенных систем.
- Традиционные компиляторы — нам лучше всего знаком именно этот тип компиляторов. Такие компиляторы преобразуют исходный код языка высокого уровня в исходный код машинного языка. Набор компиляторов GCC преобразует эти языки в низкоуровневые, которые выполняются на этих платформах.
- Транспилеры — они преобразуют исходный код языка высокого уровня в исходный код другого языка высокого уровня. Например, Babel transpiler преобразует ECMAScript 2015+ в JavaScript.
- Декомпиляторы — они принимают низкоуровневый исходный код в качестве входных данных и пытаются создать высокоуровневый исходный код, который может быть успешно перекомпилирован.
Архитектура компилятора
Когда компилятор компилирует (переводит) исходный код, он проходит несколько этапов:
- Исходный код.
- Лексический анализ.
- Синтаксический анализ.
- Семантический анализ.
- Промежуточная генерация кода.
- Оптимизация кода.
- Генерация кода.
- Целевой код.
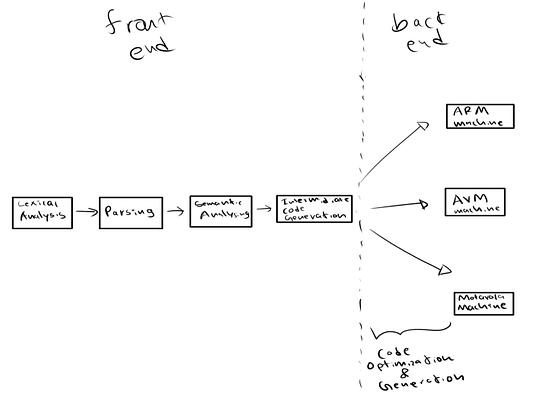
Мы можем разделить все эти этапы на две фазы, примерно как фронтенд и бэкенд. Эти фазы включают в себя следующие этапы:
Фронтенд
- Лексический анализ.
- Синтаксический анализ.
- Семантический анализ.
- Генерация промежуточного кода.
Бэкенд
- Оптимизация кода.
- Генерация кода.
В следующем разделе я кратко опишу, что происходит на каждой фазе. Если вы не программируете компиляторы, то нормально иметь о них лишь поверхностное представление, но если вы хотите разработать компилятор сами, то вам стоит подробно изучить их работу.
Лексический анализ
Теперь вы знаете, что компилятор — это программа, которая преобразует исходный код в другой исходный код. Компилятор получает исходный код в виде файла. Этот файл содержит код в текстовом формате, но компилятор не может работать с этим текстом. Необходимо преобразовать этот текст в некоторый другой формат, понятный компилятору. Для этого компилятор разбивает текст по маркерам. Помните, что эти маркеры заранее определены в грамматике языка. Маркеры пригодятся на следующих этапах процесса компиляции:
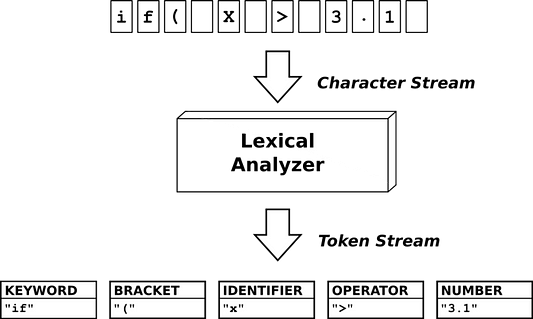
KEYWORD, BRACKET, IDENTIFIER, OPERATOR, NUMBER на приведенной выше диаграмме — это и есть маркеры. Компилятор использует лексический анализ для идентификации маркеров, и если он получает маркер, который не определен заранее в грамматике языка, то это будет считаться ошибкой.
Синтаксический анализ (парсинг)
На этом этапе компилятор проверяет, расположены ли идентифицированные ранее маркеры в правильном порядке. Для этого в каждом языке есть набор правил, называемый грамматикой. Во-первых, компилятор пытается построить структуру данных — дерево синтаксического анализа. Если компилятор смог успешно построить дерево синтаксического анализа в соответствии с заранее определенными правилами грамматики, то в исходном коде нет синтаксических ошибок. В противном случае возникают ошибки и компилятор их покажет.
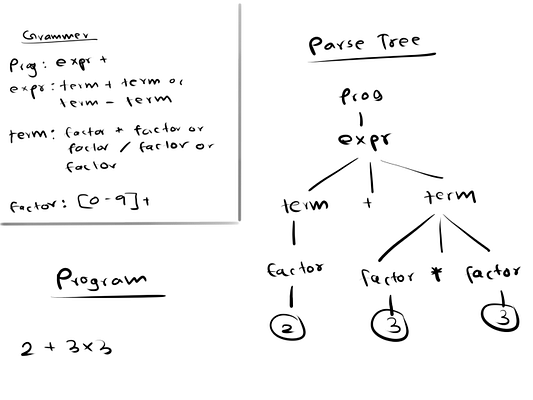
Здесь мы сначала определили грамматику. Затем компилятор пытается построить дерево синтаксического анализа для исходного кода 2 + 3 * 3. В этом случае компилятору удается построить дерево синтаксического анализа (с правой стороны) в соответствии с грамматикой, следовательно в этой программе нет синтаксических ошибок.
Семантический анализ
Просто потому, что программа не содержит синтаксических ошибок, код еще не может считаться правильным. Рассмотрим предложение ниже.
I love compilers
Теперь предположим, что все слова в этом предложении — правильные лексемы, идентифицированные на этапе лексического анализа. Как люди, мы знаем, что в предложении на английском языке есть порядок подлежащее -> сказуемое -> дополнение.

Компилятор при анализе синтаксиса может решить, что в этом предложении нет синтаксических ошибок, потому что маркеры (слова) расположены в правильном порядке.
Теперь рассмотрим предложение ниже.
I eat compilers
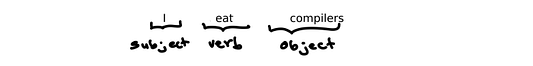
Предположим, что eat — правильный маркер в соответствии с грамматикой. Таким образом, предложение признается правильным на этапе лексического и синтаксического анализа, поскольку слова расположены в правильном порядке. Но в этом предложении нет никакого смысла — никто не может есть компиляторы.
Итак, согласно этапу семантического анализа, эта программа содержит ошибку. Мы называем эту разновидность ошибок семантическими ошибками. Взгляните на этот простой Java-код:
class SemanticAnalysis{
public static void main(String[] args){
int a = 5;
int b = 10;
int total = c + d;
}
}Здесь нет синтаксических ошибок. Все маркеры упорядочены правильно. Но на пятой строке int total = c + d — не имеет никакого значения, так как идентификаторы c и d не определены. Это и есть семантическая ошибка.
Генерация промежуточного кода
Любой компилятор может непосредственно генерировать машинный код из исходного. Так зачем же тогда нужна фаза генерации промежуточного кода?
Существуют различные типы машин. Таким образом, машинный код зависит от системы, а высокоуровневый исходный код — нет. Если компилятор непосредственно генерирует машинный код из исходного кода, то каждая машина нуждается в полной компиляции от фронта к бэку. Но когда компилятор генерирует промежуточный код (промежуточное представление), он уже может генерировать машинный код для каждой машины с его помощью, без повторения лексического анализа и парсинга для каждой машины.
Существует два основных типа промежуточных представлений:
- Высокоуровневый — более близкий к высокоуровневому языку.
- Низкоуровневый — более близкий к машинному коду.
Существует также несколько способов представления промежуточного представления.
- AST — абстрактное синтаксическое дерево (графическое).
- Постфиксная нотация.
- Трехадресный код.
- Двухадресный код.
Оптимизация кода
Этап оптимизации кода выполняет две основные задачи: минимизация времени или минимизация ресурсов. Что все это значит? Когда пользователь пишет код, нет ничего, кроме инструкций. Когда процессор выполняет эти инструкции, требуют время и ресурсы памяти. Таким образом, целью этапа оптимизации кода становится сокращение времени выполнения и ресурсов, потребляемых программой. Оптимизатор кода всегда следует трем правилам:
- Выходной код никоим образом не должен изменять значение исходного кода.
- Минимизируйте либо время, либо ресурсы, либо и то и другое вместе.
- Фаза оптимизации кода сама по себе не должна занимать много времени и замедлять весь процесс компиляции.
Существует два способа оптимизации кода:
- Машинно-независимая оптимизация.
- Машинно-зависимая оптимизация.
Машинно-независимая оптимизация принимает промежуточное представление относительно входных данных и не заботится ни о каких регистрах процессора и ячейках памяти. Она происходит после генерации промежуточного кода.
При машинно-зависимой оптимизации кода компилятор заботится о регистрах процессора, расположениях памяти и архитектуре машины. Она происходит после генерации машинного кода.
Генерация кода
Генерация кода — это последний этап процесса компиляции. Да, после может следовать машинно-зависимая оптимизация кода. Но мы можем рассматривать и то, и другое вместе как генерацию кода. На этом этапе компилятор генерирует машинно-зависимый код. Генератор кода должен иметь представление о среде выполнения целевой машины и ее наборе команд.
На этом этапе компилятор выполняет несколько основных задач:
- Выбор инструкций — какую инструкцию использовать.
- Создание расписания инструкций — в каком порядке должны быть упорядочены инструкции.
- Распределение регистров — выделение переменных в регистры процессора.
- Отладка данных — отладка кода с помощью отладочных данных.
Итоговый машинный код, сгенерированный генератором кода, может быть выполнен на целевой машине. Именно так высокоуровневый исходный код, который мы пишем в нашем любимом редакторе кода, преобразуется в формат, который можно запустить на любой целевой машине.
В этой статье я предоставляю только краткое описание. Если вам хочется углубиться в эти концепции, к вашим услугам миллионы ресурсов в интернете.
Читайте также:
- Пять отличных Python-библиотек для data science
- Значение Data Science в современном мире
- Шесть рекомендаций для начинающих специалистов по Data Science
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Buddhika Chathuranga: “What is the Compiler”
Компиля́тор — транслятор, который осуществляет перевод всей исходной программы в эквивалентную ей результирующую программу на языке машинных команд или на языке ассемблера.
Основы
Большинство компиляторов переводят программу с некоторого высокоуровневого языка программирования в машинный код, который может быть непосредственно выполнен компьютером, то есть в набор инструкций для центрального процессора. Компьютер, для которого производится компиляция, называется целевой машиной.
Некоторые компиляторы (например, Java) переводят программу не в машинный код, а в программу на некотором специально созданном низкоуровневом языке. Например, для языка Java это язык Java Virtual Machine, JVM — язык виртуальной машины Java, или так называемый байт-код Java (вслед за ним все промежуточные низкоуровневые языки стали называть байт-кодами). Для языков программирования на платформе .NET Framework (C#, Managed C++, Visual Basic .NET и другие) это так называемый MSIL (Microsoft Intermediate Language), или «Промежуточный язык фирмы Майкрософт». Далее программа на промежуточном языке подлежит интерпретации,
либо ещё одной компиляции в код целевой машины непосредственно перед исполнением (для Java это делает «Just-In-Time compiler» (JIT); MSIL-код компилируется в код целевой машины также JIT-компилятором, а библиотеки .NET Framework компилируются заранее).
Для каждой целевой машины (IBM, Apple и т. д.) и каждой операционной системы или семейства операционных систем, работающих на целевой машине, требуется написание своего компилятора. Существуют также так называемые «кросс-компиляторы», позволяющие на одной машине и в среде одной ОС получать код, предназначенный для выполнения на другой целевой машине или в среде другой ОС. Кроме того, компиляторы для одной и той же целевой машины могут быть оптимизированы под разные процессоры (путем использования специфических для этих процессоров инструкций). Например, компилятор, оптимизированный под процессоры фирмы Intel, создаёт машинный код, который быстрее всего выполняется на компьютерах с этими процессорами.
Существуют программы, которые решают обратную задачу — перевод программы с низкоуровневого языка на высокоуровневый. Этот процесс называют декомпиляцией, а программы — декомпиляторами. Но, поскольку компиляция — это процесс с потерями, точно восстановить исходный код, скажем, на C++ в общем случае невозможно. Более эффективно декомпилируются программы в байт-кодах — например, существует довольно надежный декомпилятор для Flash.
Структура компилятора
Процесс компиляции состоит из следующих этапов:
- Лексический анализ. На этом этапе последовательность символов исходного файла преобразуется в последовательность лексем.
- Грамматический анализ. Последовательность лексем преобразуется в дерево разбора.
- Семантический анализ. Дерево разбора обрабатывается с целью установления его семантики (смысла) — напр. привязка идентификаторов к их декларациям, типам, проверка совместимости, определение типов выражений и т.д. Результат обычно называется «промежуточным представлением/кодом», и может быть дополненным деревом разбора, новым деревом, абстрактным набором команд или чем-то еще, удобным для дальнейшей обработки.
- Оптимизация. Выполняется удаление излишних конструкций и упрощение кода с сохранением его смысла. Оптимизация может быть на разных уровнях и этапах, напр. над промежуточным кодом или над конечным машинным кодом.
- Генерация кода. Из промежуточного представления выдается код на целевом языке.
В конкретных реализациях компиляторов, эти этапы могут быть раздельны или совмещены в том или ином виде.
Компиляция и компоновка
Важной исторической особенностью компилятора, отраженной в его названии (Шаблон:Lang-en — собирать вместе, составлять), являлось то, что он мог производить и компоновку (т.е. содержал две части — транслятор и компоновщик). Это связано с тем, что раздельная компиляция и компоновка как отдельная стадия сборки выделились значительно позже появления компиляторов, и многие популярные компиляторы (например, GCC) до сих пор физически объединены со своими компоновщиками. В связи с этим, вместо термина «компилятор» иногда используют термин «транслятор» как его синоним: либо в старой литературе, либо когда хотят подчеркнуть его способность переводить программу в машинный код (и наоборот, используют термин «компилятор» для подчеркивания способности собирать из многих файлов один).
Примеры компиляторов
GCC, Free Pascal Compiler, Преобразователь Глагола.
См. также
- Интерпретатор
- Транслятор
- CORC
- «Книга дракона» — классический учебник о построении компиляторов
- Синтаксический анализ
Ссылки
- Компиляторы: принципы, методы и средства разработки
- Ахо, Альфред В., Сети, Рави, Ульман, Джеффри Д. Компиляторы: принципы, технологии и инструменты : Пер. с англ.— М. Издательский дом «Вильямс», 2001 .— 768 с.: ил.— Парал. тит. Шаблон:Lang-en5-8459-0189-8 (рус.)
- Хантер Р. Проектирование и конструирование компиляторов : Пер. с англ. С. М. Круговой — М. Финансы и статистика, 1984 — 232 с. ил. 24 см
Эта статья включает описание термина «Компиляция»; см. также другие значения.
Компиля́тор — программа или техническое средство, выполняющее компиляцию.[1][2][3]
Компиляция — трансляция программы, составленной на исходном языке высокого уровня, в эквивалентную программу на низкоуровневом языке, близком машинному коду (абсолютный код, объектный модуль, иногда на язык ассемблера).[2][3][4] Входной информацией для компилятора (исходный код) является описание алгоритма или программа на проблемно-ориентированном языке, а на выходе компилятора — эквивалентное описание алгоритма на машинно-ориентированном языке (объектный код).[5]
Компилировать — проводить трансляцию машинной программы с проблемно-ориентированного языка на машинно-ориентированный язык.[3]
Содержание
- 1 Виды компиляторов[2]
- 2 Виды компиляции[2]
- 3 Структура компилятора
- 4 Генерация кода
- 4.1 Генерация машинного кода
- 4.2 Генерация байт-кода
- 4.3 Динамическая компиляция
- 4.4 Декомпиляция
- 5 Раздельная компиляция
- 6 Интересные факты
- 7 См. также
- 8 Примечания
- 9 Литература
Виды компиляторов[2]
- Векторизующий. Транслирует исходный код в машинный код компьютеров, оснащённых векторным процессором.
- Гибкий. Сконструирован по модульному принципу, управляется таблицами и запрограммирован на языке высокого уровня или реализован с помощью компилятора компиляторов.
- Диалоговый. См.: диалоговый транслятор.
- Инкрементальный. Повторно транслирует фрагменты программы и дополнения к ней без перекомпиляции всей программы.
- Интерпретирующий (пошаговый). Последовательно выполняет независимую компиляцию каждого отдельного оператора (команды) исходной программы.
- Компилятор компиляторов. Транслятор, воспринимающий формальное описание языка программирования и генерирующий компилятор для этого языка.
- Отладочный. Устраняет отдельные виды синтаксических ошибок.
- Резидентный. Постоянно находится в оперативной памяти и доступен для повторного использования многими задачами.
- Самокомпилируемый. Написан на том же языке, с которого осуществляется трансляция.
- Универсальный. Основан на формальном описании синтаксиса и семантики входного языка. Составными частями такого компилятора являются: ядро, синтаксический и семантический загрузчики.
Виды компиляции[2]
- Пакетная. Компиляция нескольких исходных модулей в одном пункте задания.
- Построчная. То же, что и интерпретация.
- Условная. Компиляция, при которой транслируемый текст зависит от условий, заданных в исходной программе директивами компилятора. Так, в зависимости от значения некоторой константы, можно включать или выключать трансляцию части текста программы.
Структура компилятора
Процесс компиляции состоит из следующих этапов:
- Лексический анализ. На этом этапе последовательность символов исходного файла преобразуется в последовательность лексем.
- Синтаксический (грамматический) анализ. Последовательность лексем преобразуется в дерево разбора.
- Семантический анализ. Дерево разбора обрабатывается с целью установления его семантики (смысла) — например, привязка идентификаторов к их декларациям, типам, проверка совместимости, определение типов выражений и т. д. Результат обычно называется «промежуточным представлением/кодом», и может быть дополненным деревом разбора, новым деревом, абстрактным набором команд или чем-то ещё, удобным для дальнейшей обработки.
- Оптимизация. Выполняется удаление излишних конструкций и упрощение кода с сохранением его смысла. Оптимизация может быть на разных уровнях и этапах — например, над промежуточным кодом или над конечным машинным кодом.
- Генерация кода. Из промежуточного представления порождается код на целевом языке.
В конкретных реализациях компиляторов эти этапы могут быть разделены или, наоборот, совмещены в том или ином виде.
Генерация кода
Генерация машинного кода
Большинство компиляторов переводит программу с некоторого высокоуровневого языка программирования в машинный код, который может быть непосредственно выполнен процессором. Как правило, этот код также ориентирован на исполнение в среде конкретной операционной системы, поскольку использует предоставляемые ею возможности (системные вызовы, библиотеки функций). Архитектура (набор программно-аппаратных средств), для которой производится компиляция, называется целевой машиной.
Результат компиляции — исполнимый модуль — обладает максимальной возможной производительностью, однако привязан к определённой операционной системе и процессору (и не будет работать на других).
Для каждой целевой машины (IBM, Apple, Sun и т. д.) и каждой операционной системы или семейства операционных систем, работающих на целевой машине, требуется написание своего компилятора. Существуют также так называемые кросс-компиляторы, позволяющие на одной машине и в среде одной ОС генерировать код, предназначенный для выполнения на другой целевой машине и/или в среде другой ОС. Кроме того, компиляторы могут оптимизировать код под разные модели из одного семейства процессоров (путём поддержки специфичных для этих моделей особенностей или расширений наборов инструкций). Например, код, скомпилированный под процессоры семейства Pentium, может учитывать особенности распараллеливания инструкций и использовать их специфичные расширения — MMX, SSE и т. п.
Некоторые компиляторы переводят программу с языка высокого уровня не прямо в машинный код, а на язык ассемблера. Это делается для упрощения части компилятора, отвечающей за кодогенерацию, и повышения его переносимости (задача окончательной генерации кода и привязки его к требуемой целевой платформе перекладывается на ассемблер), либо для возможности контроля и исправления результата компиляции программистом.
Генерация байт-кода
Результатом работы компилятора может быть программа на специально созданном низкоуровневом языке, подлежащем интерпретации виртуальной машиной. Такой язык называется псевдокодом или байт-кодом. Как правило, он не является машинным кодом какого-либо компьютера и программы на нём могут исполняться на различных архитектурах, где имеется соответствующая виртуальная машина, но в некоторых случаях создаются аппаратные платформы, напрямую поддерживающие псевдокод какого-либо языка. Например, псевдокод языка Java называется байт-кодом Java и выполняется в Java Virtual Machine, для его прямого исполнения была создана спецификация процессора picoJava. Для платформы .NET Framework псевдокод называется Common Intermediate Language (CIL), а среда исполнения — Common Language Runtime (CLR).
Некоторые реализации интерпретируемых языков высокого уровня (например, Perl) используют байт-код для оптимизации исполнения: затратные этапы синтаксического анализа и преобразование текста программы в байт-код выполняются один раз при загрузке, затем соответствующий код может многократно использоваться без промежуточных этапов.
Динамическая компиляция
Из-за необходимости интерпретации байт-код выполняется значительно медленнее машинного кода сравнимой функциональности, однако он более переносим (не зависит от операционной системы и модели процессора). Чтобы ускорить выполнение байт-кода, используется динамическая компиляция, когда виртуальная машина транслирует псевдокод в машинный код непосредственно перед его первым исполнением (и в при повторных обращениях к коду исполняется уже скомпилированный вариант).
CIL-код также компилируется в код целевой машины JIT-компилятором, а библиотеки .NET Framework компилируются заранее.
Декомпиляция
Существуют программы, которые решают обратную задачу — перевод программы с низкоуровневого языка на высокоуровневый. Этот процесс называют декомпиляцией, а такие программы — декомпиляторами. Но поскольку компиляция — это процесс с потерями, точно восстановить исходный код, скажем, на C++, в общем случае невозможно. Более эффективно декомпилируются программы в байт-кодах — например, существует довольно надёжный декомпилятор для Flash. Разновидностью декомпилирования является дизассемблирование машинного кода в код на языке ассемблера, который почти всегда выполняется успешно (при этом сложность может представлять самомодифицирующийся код или код, в котором собственно код и данные не разделены). Связано это с тем, что между кодами машинных команд и командами ассемблера имеется практически взаимно-однозначное соответствие.
Раздельная компиляция
Раздельная компиляция (англ. separate compilation) — трансляция частей программы по отдельности с последующим объединением их компоновщиком в единый загрузочный модуль.[2]
Исторически особенностью компилятора, отражённой в его названии (англ. compile — собирать вместе, составлять), являлось то, что он производил как трансляцию, так и компоновку, при этом компилятор мог порождать сразу абсолютный код. Однако позже, с ростом сложности и размера программ (и увеличением времени, затрачиваемого на перекомпиляцию), возникла необходимость разделять программы на части и выделять библиотеки, которые можно компилировать независимо друг от друга. При трансляции каждой части программы компилятор порождает объектный модуль, содержащий дополнительную информацию, которая потом, при компоновке частей в исполнимый модуль, используется для связывания и разрешения ссылок между частями.
Появление раздельной компиляции и выделение компоновки как отдельной стадии произошло значительно позже создания компиляторов. В связи с этим вместо термина «компилятор» иногда используют термин «транслятор» как его синоним: либо в старой литературе, либо когда хотят подчеркнуть его способность переводить программу в машинный код (и наоборот, используют термин «компилятор» для подчёркивания способности собирать из многих файлов один).
Интересные факты
На заре развития компьютеров первые компиляторы (трансляторы) называли «программирующими программами»[6] (так как в тот момент программой считался только машинный код, а «программирующая программа» была способна из человеческого текста сделать машинный код, то есть запрограммировать ЭВМ).
См. также
- CORC
- Компиляторы: принципы, технологии и инструменты
- SSA
Примечания
- ↑ ГОСТ 19781-83 // Вычислительная техника. Терминология: Справочное пособие. Выпуск 1 / Рецензент канд. техн. наук Ю. П. Селиванов. — М.: Издательство стандартов, 1989. — 168 с. — 55 000 экз. — ISBN 5-7050-0155-X
- ↑ 1 2 3 4 5 Першиков В. И., Савинков В. М. Толковый словарь по информатике / Рецензенты: канд. физ.-мат. наук А. С. Марков и д-р физ.-мат. наук И. В. Поттосин. — М.: Финансы и статистика, 1991. — 543 с. — 50 000 экз. — ISBN 5-279-00367-0
- ↑ 1 2 3 СТ ИСО 2382/7-77 // Вычислительная техника. Терминология. Указ. соч.
- ↑ Борковский А. Б. Англо-русский словарь по программированию и информатике (с толкованиями). — М.: Русский язык, 1990. — 335 с. — 50 050 (доп,) экз. — ISBN 5-200-01169-3
- ↑ Толковый словарь по вычислительным системам = Dictionary of Computing / Под ред. В. Иллингуорта и др.: Пер. с англ. А. К. Белоцкого и др.; Под ред. Е. К. Масловского. — М.: Машиностроение, 1990. — 560 с. — 70 000 (доп,) экз. — ISBN 5-217-00617-X (СССР), ISBN 0-19-853913-4 (Великобритания)
- ↑ Н. А. Криницкий, Г. А. Миронов, Г. Д. Фролов. Программирование / Под ред. М. Р. Шура-Бура. — М.: Государственное издательство физико-математической литературы, 1963.
Литература
- Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман. Компиляторы: принципы, технологии и инструментарий = Compilers: Principles, Techniques, and Tools. — 2-е изд. — М.: Вильямс, 2010. — 1184 с. — ISBN 978-5-8459-1349-4
- Робин Хантер. Основные концепции компиляторов = The Essence of Compilers. — М.: Вильямс, 2002. — 256 с. — ISBN 0-13-727835-7
- Хантер Р. Проектирование и конструирование компиляторов / Пер. с англ. С. М. Круговой. — М.: Финансы и статистика, 1984. — 232 с.
- Д. Креншоу. Давайте создадим компилятор!
- Серебряков В. А., Галочкин М. П. Основы конструирования компиляторов.
В настоящее время, с активным развитием языков программирования высокого уровня, все большую роль начинают играть так называемые компиляторы.
Компилятор − это специальная программа, которая переводит текст программы, написанный на языке программирования, в набор машинных кодов, понятных для компьютера.
Компиляторы составляют существенную часть программного обеспечения ЭВМ. Это связано с тем, что языки высокого уровня стали основным средством разработки программ. Только очень незначительная часть программного обеспечения, требующая особой эффективности, обходится без компиляторов и программируется при помощи ассемблеров
Компьютер, для которого производится компиляция, называется целевой машиной.
Входной информацией для компилятора является описание алгоритма или программа на языке программирования.

На выходе компилятора – эквивалентное описание алгоритма на машинно-ориентированном языке (объектный код).
Классификация компиляторов в соответствии с этапами компиляции
Одни компиляторы непосредственно преобразуют высокоуровневый исходный код в машинный код, а некоторые − сначала преобразуют высокоуровневый исходный код в промежуточное представление перед окончательным преобразованием в машинный код.
В соответствии с данным критерием классификации можно выделить два основных типа компиляторов:
- Однопроходной компилятор − это компилятор, который проходит через части каждого блока компиляции только один раз, немедленно переводя каждую часть в конечный машинный код.
- Двухпроходной/многопроходной компилятор − это тип компилятора, который два и более раз обрабатывает исходный код или абстрактное синтаксическое дерево программы.
Классификация компиляторов в соответствии с исходным кодом и целевым кодом
Для преобразования исходного кода в целевой применяются разные подходы.
Одни компиляторы преобразуют код на высокоуровневом языке в машинный. Другие же компиляторы преобразуют с одного языка высокого уровня на другой язык высокого уровня. Таким образом, опираясь на данный критерий классификации, можно выделить следующие типы компиляторов:
- Кросс-компиляторы − такие компиляторы работают на одной платформе и производят код для запуска на другой платформе. Например, компилятор работает на платформе X и создает код для запуска на платформе Y. Такими компиляторами пользуются разработчики встроенных систем.
- Традиционные компиляторы − наиболее распространённый тип компиляторов. Такие компиляторы преобразуют исходный код языка высокого уровня в исходный код машинного языка.
- Транспилеры − они преобразуют исходный код языка высокого уровня в исходный код другого языка высокого уровня.
- Декомпиляторы − они принимают низкоуровневый исходный код в качестве входных данных и пытаются на его основе создать высокоуровневый исходный код, который может быть в дальнейшем успешно перекомпилирован.
Основные этапы работы компилятора
Исходная программа, которая написана на некотором условном языке программирования, представляет собой цепочку знаков. Компилятор по сути своей постепенно превращает эту цепочку знаков в цепочку битов – объектный код.
Компиляторы используют следующие принципы и технологии в своей работе:
- Проведение лексического анализа кода;
- Проведение синтаксического анализа кода;
- Генерирование промежуточного кода;
- Оптимизация промежуточного кода;
- Распределение памяти между переменными компилируемого скрипта;
- Генерирование объектного кода и компонация программных сегментов.
Принцип работы компилятора состоит в следующем:
а) проверяется весь текст программы на наличие синтаксических ошибок;
б) если программа не содержит ошибок, то происходит ее выполнение.
Генерация выполняемой программы происходит только в том случае, если в тексте программы нет синтаксических ошибок.
Отличительной особенностью компилятора является то, что на его вход подается программа на языке высокого уровня, а на выходе получается та же программа на языке низкого уровня.
Тест по теме «Принцип работы компилятора»
Транслятор (англ. translator —
переводчик) — это программа-переводчик. Она преобразует программу, написанную
на одном из языков высокого уровня, в программу, состоящую из машинных команд[15].
Компилятор (англ. compiler —
составитель, собиратель) читает всю программу целиком, делает ее перевод и
создает законченный вариант программы на машинном языке, который затем и
выполняется.
Примеры
компиляторов:
1) GCC
2) Free Pascal Compiler
3) Компиляторы C, C++ и Fortran от Sun Microsystems Inc.
4) Watcom Fortran/C++ Compiler
5) Intel C++/Fortran compiler
6) ICC AVR.
Компилятор
обеспечивает преобразование программы с одного языка на другой. Команды
исходного языка сильно отличаются по организации и мощности, нежели команды
машинного языка. Бывают такие, в которых одна команда исходного языка
транслируется в 7-10 машинных команд. Существуют даже такие, в которых в каждой
команде может соответствовать более 100
машинных команд (например язык программирования Пролог). В исходных языках
довольно часто используется строгая типизация данных, которая осуществляется
через их предварительное описание. Программирование на таких языках может
опираться не только на кодирование алгоритма, но и на тщательное обдумывание
структур данных или классов. Весь процесс трансляции с таких языков
программирования обычно называется компиляцией, а исходные языки обычно
относятся к языкам высокого уровня.
Интерпретатор (англ. interpreter —
истолкователь, устный переводчик) переводит и выполняет программу строка
за строкой.В отличие от компилятора, интерпретатор не порождает на выходе
программу на машинном языке. Распознав команду исходного языка, он тут же выполняет
ее. Как в компиляторах, так и в интерпретаторах используются одинаковые методы
анализа исходного текста программы. Но интерпретатор позволяет начать обработку
данных после написания даже одной команды. Это делает процесс разработки и
отладки программ более гибким. Кроме того, отсутствие выходного машинного кода
позволяет не «захламлять» внешние устройства дополнительными файлами, а сам
интерпретатор можно достаточно легко адаптировать к любым машинным
архитектурам, разработав его только один раз на широко распространенном языке
программирования. Поэтому, интерпретируемые языки, типа Java Script, VB Script,
получили широкое распространение. Недостатком интерпретаторов является низкая
скорость выполнения программ. Обычно интерпретируемые программы выполняются в
50-100 раз медленнее программ, написанных в машинных кодах.