Привет. Я занимался сбором семантического ядра для своего сайта с разными перерывами на протяжении последних 3 лет. До этого лет 10 меня тошнило от самой идеи. Я приступал к этому процессу, бросал, потом пробовал снова и снова бросал. SEO казалось чем-то таким заоблачным. Типа, пришёл какой-то волшебник и что-то там насеошил.
К моему большому сожалению, обилие тренингов, статей, лекций и видосов на YouTube не сильно облегчают понимание процесса сбора и обработки семантики. Перелопачивать все эти тонны воды могут лишь не все😊 А сеошники любят налить воды, мы все про это прекрасно знаем. Смотришь вот так разные тренинги, а у преподов в голове сплошная каша. Когда человек не может сформулировать свои мысли в краткой статье, ему явно не стоит преподавать. Я решил попробовать. Кратко не получилось 😊
На данный момент я занимаюсь внедрением собранной семантики на сайт и решил написать эту статью. Возможно, она поможет тем, кто только начинает в этом разбираться. Мне бы точно очень помогла. Это, по сути, пошаговое руководство. Что, за чем, как и в каком порядке стоит делать. «Делать» никуда не денется, работать придётся много, но зато теперь с пониманием, куда и как двигаться и где вообще конец этого бесконечного тоннеля.
Но, хватит предисловий, приступим к алогоритму.
Важная ремарка. Здесь не будет конкретных рекомендаций по работе с Excel. Будем считать по умолчанию, что интернет маркетолог хорошо знаком с этим инструментом. Key Collector тоже не должен быть для вас чем-то новым.
Также должен сказать, что читать этот мануал по диагонали бесполезно, т.к. он представляет из себя конкретный набор шагов, которые нужно выполнять. Без выполнения, всё это чтение «по буллетам» вам ничего не даст. Делюсь, потому что понимаю, что этот каторжный труд осилят единицы.
Итак, для сбора и обработки семантического ядра вам понадобится:
Доступы:
· Google search console
· Yandex метрика
· Yandex webmaster
Программы:
· Key Collector
· SEO Screaming Frog
· MS Excel
· Надстройка для парсинга yandex webmaster в google chrome
Платные сервисы и услуги:
· 10 прокси для Key Collector
· Pixeltools
· Just Magic
Cбор семантического ядра представляет из себя систему воронок, через которые просеиваются запросы. На каждом из этапов фильтрации вы постепенно избавляетесь от мусора.
Вам предстоит много ручной работы, много часов труда. Чем выше ваша вовлеченность в бизнес и понимание тематики, тем проще вам будет отделить мусор от полезных запросов.
Вводные данные: у вас уже есть сайт, который вы создали по своему усмотрению и пониманию того, каким должен быть идеальный поисковый спрос. Пора столкнуться с суровой реальностью. Сайт приносит какие-то деньги, но хочется больше.
Источники семантики / запросов:
· Keyso — сервис видимости конкурентов
· Счётчики на вашем сайте (метрика, вебмастер, сёрч консоль)
· Yandex wordstat
· Метатеги сайтов конкурентов
· Подсказки в Yandex и Google
ШАГ 1. Сервисы видимости
1. Находите на kwork или подобной бирже человека, который делает выгрузки из keyso за деньги. Покупаете у него выгрузку по 15 основным конкурентам. 15 будет достаточно. Если вы занимаетесь своей темой давно, 15 основных конкурентов у вас уже будут на слуху. Это будет большущая таблица с запросами.
2. Делаем выгрузку из метрики и сёрч консоли
3. Собираем с помощью плагина для google chrome информацию из вебмастера
Где смотреть:
· Метрика: стандартные отчеты — источники — поисковые запросы
· Вебмастер: поисковые запросы — управление группами — все запросы
· Сёрч консоль: эффективность — запросы
Делаете выгрузку за 1 год из этих источников.
ШАГ 2. Парсинг конкурентов
Находите сайты конкурентов. Чем больше найдёте, тем лучше.
Осматриваете сайты на предмет оптимизации. Обычно сразу видно, ведется над сайтом работа или он сделан лишь бы как и не стоит внимания.
Парсите все отобранные сайты с помощью программы SEO Screaming Frog. Вам нужны данные из полей title и h1.
Как правило, у большинства сайтов эти теги сделаны по шаблонам и не составит большого труда удалить из тегов лишнюю информацию и оставить только ключевые слова.
Обрабатываете title и h1 конкурентов в Excel. Собираете всё это в одну большую таблицу.
ШАГ 3. Фильтрация по частотности
Загружаете результаты ваших сборов в Key Collector.
Настройки в KC — вашего региона, если бизнес сильно к нему привязан. Если он универсальный, выставляйте Москву. Там будет больше статистики.
Можно предварительно перед загрузкой в Key Collector заменить в вашей базе слов точки, запятые, тире, дефисы и слэши на знак пробела и почистить фразы от двойных пробелов.
Можно предварительно почистить вашу базу от мусора. На ваше усмотрение. Но я на этом этапе не советую этим заниматься, т.к. база очень большая и проще сначала убрать из неё всё, что можно, автоматически.
К этому моменту вам понадобятся платные прокси. Покупаете их и прописываете в настройках программы Key Collector. Настройки для парсинга не привожу. Нагуглите сами. Вы уже большие.
Итак, вы загружаете в KC вашу базу ключевых слов и парсите базовую частотность с помощью прокси. С вашего основного IP парсить бесполезно. Это пустая трата времени и потенциальный бан от поисковой системы.
Если частотность собирается слишком долго, можно воспользоваться платными сервисами типа https://moab.tools/Parse/CheckWordstat
Ваша задача на этом этапе избавиться от нулевых запросов.
После парсинга базовой частотности переносите нулевые запросы в отдельную мусорную папку в Key Collector. Вы НЕ удаляете запросы. Это нужно для того, чтобы в дальнейшем мусор не попадал в вашу базу по второму кругу.
В вашем проекте в KC теперь будет три папки для мусора:
1. базовая частотность = 0
2. «точная частотность» = 0
3. «!точная !частотность» = 0
Как вы уже поняли, после того, как вы уберете запросы по первому параметру, нужно будет спарсить частотности по двум остальным
После каждого из этапов чистки, запросов в вашей семантике будет оставаться всё меньше, а мусора будет становиться всё больше.
При сборе базовой частотности может оказаться, что для каких-то запросов она не собирается. Это нормально. Запускайте сбор частотности повторно. То, что не собралось, соберется. Останутся:
· запросы слишком длинные (больше 7 слов).
· запросы со спец символами
Кто-то заморачивается и пытается оставить длинные запросы в ядре. У меня не настолько конкурентная тематика, поэтому я их просто переношу в мусор. Поверьте, вам хватит работы и без них. И при желании в дальнейшем к ним можно будет вернуться.
ШАГ 4. ГЕО
После того, как в вашей базе остались запросы с «!точной !частотностью» > 0, мы чистим их по ГЕО. Удаляем гео запросы.
Для этого вы лично формируете свою первую базу минус слов для KC – ГЕО.
Там будут города, населенные пункты, регионы, области, страны в различных вариантах склонений и описаний. Для склонения можно использовать сервис https://morpher.ru/Opt/
ШАГ 5. Мусор, часть 1
После чистки по ГЕО вы составляете собственный словарь мусорных «минус слов». Вы собираете ваш персональный список минус слов, таких как: порно, скачать, форум и прочее.
Список будет постепенно расширяться, упрощая вам первичную фильтрацию в дальнейшем. Не ленитесь добавлять в него частотные мусорные слова. Для каждой тематики такой список минус слов свой собственный. Поэтому не стоит искать какие-то универсальные списки. Создавайте свой собственный.
Слова, которые наиболее часто встречаются в вашем списке запросов можно посмотреть с помощью инструмента «анализ групп» в KC. Да, там можно искать не только что-то полезное, но и мусор. Вообще именно с поиска мусора в этом инструменте и стоит начать. Сканировать список запросов глазами – так вы далеко не уедете.
Удаляем из нашего списка самый очевидный мусор.
ШАГ 6. Бренды
Отделяем брендовые и товарные запросы от чистых категорийных. Для этого вы составляете собственный список брендовых «минус слов». Сюда входят различные варианты написания брендов, транслит, опечатки.
Отсеиваете список запросов по брендам, вынося все такие запросы в отдельную папку «Брендовые запросы».
ШАГ 7. Инфо
Отделение инфо запросов. Составляете ваш собственный словарь минус слов, которые позволят отделить информационные запросы от коммерческих. Сюда входя такие слова как отзывы, топ, рейтинг, лучший, обзор, и т.д.
Убирайте информационку в отдельную папку «информационные запросы»
ШАГ 8. Товарка
Отделяете бренды от товаров. Часто в названиях товаров используются цифры — это один из простейших способов отделить бренды от товаров.
Если брендовый трафик для вас имеет большое значение, работайте с этой папкой в KC.
Используйте возможности KC для поиска: «анализ групп» — это очень мощный инструмент
Также вам пригодятся инструменты фильтрации, такие как «фраза содержит / не содержит»:
· цифры
· латинские буквы
· буквы кириллицы
· повторы слов
ШАГ 9. Первичная структура
Составление первичной структуры сайта в Key Collector. Это необходимо для упрощения дальнейшей фильтрации.
Создавая структуру сайта в KC, вы также упрощаете себе в дальнейшем парсинг и обработку запросов, т.к. они будут собираться примерно из одной и той же темы / группы запросов и отсеять мусор из одной такой пачки намного проще, чем пытаться убрать его из одной большой общей кучи.
Чем детальнее вы создадите структуру проекта в KC, тем проще вам будет работать
Данная структура нужна только для парсинга и фильтрации. То, что вы будете внедрять на сайт, от этой предварительной структуры будет очень сильно отличаться
ШАГ 10. Сортировка
Работаете со «структурой», сортируя запросы по папкам, параллельно избавляясь от мусора. Это самый длительный и занудный процесс, но его нужно пройти.
Параллельно вы будете находить гео, мусор, информационку, брендовые и товарные запросы, а ваши словари минус слов будут пополняться. Структура будет становиться более детальной и понятной. У проекта начнут вырисовываться черты, вы наконец-то поймете, сколько всего вы упустили.
Вы научитесь работать с «анализом групп» и фильтрами в KC, помимо структуры создадите необходимые лично вам подпапки в KC.
В целом уже начнёт складываться понимание как это всё работает, что удобно, а что — нет.
Заодно, поковырявшись в меню КС, вы найдете способы простого перемещения списков запросов по папкам. и в целом поднатореете в тематике.
Заодно увидите сколько новых вариантов написания уже известных вам запросов существует, а вы о них и не догадывались.
ШАГ 11. Отдохните
Итак вы разгребли вот это всё: метрика, вебмастер, сёрч консоль, keyso, метатеги конкурентов.
Это уже большое достижение. У вас уже также создана структура сайта в KC для парсинга запросов, которая позволит эффективно собирать вам нужные группы запросов.
К этому моменту вы должны уже ненавидеть KC и его мелкие буковки, правая рука — стонать от приближающегося тоннельного синдрома, а глаза — просить пощады.
Ну что, же, приступим к парсингу.
ШАГ 12. Парсинг запросов
Благодаря сформированной структуре, вы можете зайти в любую из папок с запросами, включить анализ групп и найти там все существительные.
Существительные — это основа маркеров для парсинга.
«Анализ групп» позволяет легко найти самые частотные слова и легко составить небольшой список маркерных фраз для последующего парсинга Wordstat.
Итак вы составили список маркеров для конкретной папки. Берете их и все запросы, которые уже есть в этой папке и собираете вордстат по всем этим фразам.
Далее повторяете перечисленные выше этапы с чисткой. Теперь чистка будет проходить уже намного проще, ведь вы работаете с небольшими участками сем ядра. И мусор в таких условиях чистить гораздо проще. Ведь то, что является мусором в одной категории, в другой – совсем не мусор. В общем, вы меня поймете, когда поработаете в KC хоть немного.
Чистку опять начинаете с частотности, потом гео, мусор, бренды, информационка. В итоге останется не так много рабочих запросов.
При парсинге сюда будут прилетать запросы из других групп, сортируем всё это дело по своим местам.
ШАГ 13. Глубокий парсинг
Если вы хотите максимально глубоко погрузиться в тему, вы берете высокочастотные слова и парсите их в таких вариантах
· «слово слово слово слово слово слово»
· «слово слово слово слово слово»
· «слово слово слово слово»
· «слово слово слово»
· «слово слово»
· «слово»
Таким образом вы максимально обходите ограничения Wordstat по выводу слов, ведь глубина просмотра статистики у него всего лишь 41 страница и в больших тематиках этого часто не хватает.
Для этого вы и парсите 6-5-4-3-2-1-словники по-отдельности.
ШАГ 14. Сбор подсказок
После того как пройдены все 13 предыдущих этапов, вы берете все запросы из любой папки и парсите по ним подсказки.
Далее чистите, фильтруете и сортируете.
Работа довольно муторная как и всё что связано с сем ядром, но зато вы можете быть уверены, что мало кто из конкурентов способен пройти через весь этот ад. Ну и фильтровать подсказки по конкретным группам – это детский сад по сравнению с тем, что вы уже проделали ранее.
ШАГ 15. Just Magic
Ура. вы собрали сем ядро. Радоваться, однако, рано. Собранная и внедрённая семантика — это две больших разницы. Приступим к следующему этапу.
На данном этапе основная работа с KC закончена и мы переносим собранное сем ядро / а точнее ту часть, с которой вы решаете работать, в Excel.
Работайте с отдельными группами, относительно большими кластерами, которые вы бы вынесли на первый / максимум на второй уровень в меню вашего сайта.
Не стоит сильно углубляться в подпапки но и не стоит сразу хвататься за весь сайт.
Берём группу запросов, с которой мы решили работать.
Регистрируемся в Just Magic и парсим там частотность [«!слово !слово»] — это самая точная словоформа и порядок слов, именно её стоит использовать в работе.
JM любит сортировать запросы по алфавиту. Учитывайте это и используйте формулы Vlookup / ВПР в Excel.
Убираем из нашего списка в Excel все запросы, у которых [«!слово !слово»] = 0.
Создаём новый пустой (!) проект в KС.
Загружаем в него оставшиеся запросы и супер точную частотность, полученную в Just Magic.
Используя инструмент KC «анализ неявных дублей», отмечаем в списке «неявные дубли».
Выгружаем полученный список в Excel, вставляем эти данные в нашу таблицу
Убираем из списка запросов в Excel неявные дубли.
Вы только что сократили вашу табличку примерно на 30-40%.
Для оставшихся запросов используем сервис «тематический классификатор» Just Magic.
Он позволяет еще более точно просеять оставшийся список и найти потенциально проблемные запросы, которые стоит убрать из ядра.
Проходимся по списку глазами/руками еще раз, отмечая лишнее.
ШАГ 16. PixelTools
Итак у нас остались запросы без дублей, с максимальной точной частотностью, просеянные через тематический классификатор.
Регистрируемся в Pixeltools и собираем там параметры «Гео/коммерциализация», а также делаем кластеризацию запросов в Just magic.
Это всё платные инструменты. Но если вы когда-нибудь сливали деньги в контексте, суммы за эти услуги не должны вас шокировать. Экономить тут не стоит. И стоит это совсем не космических денег, ведь вы делаете семантику для себя любимого.
Почему кластеризация в JM? Потому что там очень удобно за один проход делается кластеризация на нескольких уровнях. Это очень наглядно и выглядит в Excel позволяет быстро перегруппировать запросы в случае необходимости, не прибегая к повторной кластеризации.
Не нужно возиться с кучей настроек в Key Assort, не нужно по нескольку раз перекластеризовывать ядро, ища подходящий вариант, в Pixeltools тоже кластеризация не наглядная. JM на данный момент в табличном виде мне кажется самым удобным.
Почему идёт работа с 2 сервисами? Это упрощает аналитику и помогает сделать выбор, основываясь на показаниях в 2 разных источниках. В таблицах с такими данными работать намного проще.
В итоге у вас будут собраны вот эти параметры:
Pixel tools:
· геозависимость
· локализация
· комерциализация
· витальный ответ
Just Magic:
· «[!проверяемая !фраза]»
· тематика
· группировка по 4 уровням
· наличие главных страниц в выдаче
· комерциализация
· геозависимость
К сожалению, в JM нет возможности собрать гео и коммерцию отдельно, это работает только при кластеризации. Ну, работаем с тем, что есть.
ШАГ 17. Excel
Обработка таблиц с полученными данными в Excel. Сортируете всё это чудо, используете условное форматирование столбцов с необходимыми вам данными, чтобы проще их читать.
На этом этапе из списков ваших запросы отсеются потенциальные инфо запросы, которые вы посчитали коммерцией.
А также вы быстро пройдётесь по названиям групп, которые уже были выгружены из KC и сравните их с данными, полученными в JM.
Это первичная кластеризация с первой ручной корректировкой данных
ШАГ 18. Чистовая кластеризация
После отсева мусора в результате первичной кластеризации, берете оставшийся у вас список запросов из разных подгрупп одного большого раздела, сваливаете их в кучу и на этот раз делаете кластеризацию уже всего списка запросов в JM.
Она пройдёт более качественно, т.к. мусор вы уже убирали руками. Он всё равно будет, но уже в единичных случаях. В целом это и есть ваш финальный список запросов.
Далее вы проходитесь по нему вручную и решаете, нужно ли дробить какие-то кластеры на отдельные, переносить ли какие-то запросы из одной группы в другую.
Сортировка по группам в JM + ваша личная сортировка запросов по группам, которую вы сначала сделали в KC, а потом перепроверили в Excel, сделает обработку финального списка запросов простой и наглядной.
В итоге у вас получится таблица, которая называется «карта релевантности». В ней будут сгруппированы запросы для каждого из кластеров. Вам останется только проставить для них продвигаемые URL.
У многих групп запросов таких URL / страниц не будет, их придётся создавать на сайте.
Проанализировав получившиеся группы / кластеры, вы поймете для каких из них нужны отдельные страницы, а для каких хватит настроек в фильтрах категорий на сайте.
Далее, работая уже с конкретным ассортиментом на сайте, вы поймете, что некоторые из полученных в результате кластеризации групп просто нельзя использовать, потому что в каталоге нет таких товаров, соответственно, список рабочих кластеров станет еще меньше.
Всё. Создаете страницы и следите за апдейтами.
В итоге у вас есть:
1. Проект в KC который вы можете пополнять новыми запросами, ведь конкуренты не спят и стоит периодические заглядывать к ним, смотреть, что у них новенького. Парсить их и ваши маркеры.
2. Карта релевантности — вещь, которая есть далеко не у каждого.
3. Благодаря карте релевантности у вас есть чёткое понимание, какие страницы нужно создать, какого ассортимента не хватает на сайте, как его стоит там разместить, как изменить структуру каталога для удобства навигации, какие страницы наиболее популярны и значит должны быть наиболее заметны в меню и навигации. Всё это было бы невозможно без описанных выше шагов.
4. Если вы захотите написать инфо статью, у вас уже будут собраны инфо запросы в вашем проекте. Останется только немного их доработать.
Если сайт и ассортимент большой, эти все описанные шаги нужно будет проделать для каждого из больших разделов. Невозможно осилить всё сразу, но у вас уже есть очень мощная база, к работе над которой вы можете вернуться в любой момент, как только у вас появится вдохновение.
Пример предварительной группировки одной большой группы товаров в KC для мотивации. По цифрам в мусоре вы можете понять сколько всего пришлось отсеять.

Советы
Как составить семантическое ядро сайта
Руководство с комментариями опытного сеошника
Семантическое ядро — список поисковых запросов, по которым пользователь может найти сайт. Его собирают для того чтобы понять интересы целевой аудитории, продумать структуру сайта и добавить ключи в текст.
В этом материале подробно разберемся с семантикой. В начале статьи будет теоретическая часть — что это такое, для чего нужно и когда сбор семантики лучше доверить специалисту. Во второй части будет пошаговая инструкция по сбору семантики. Если вам интересна именно эта часть — кликайте: пошаговая инструкция как составить семантическое ядро.
Статья написана под надзором Lead SEO в Unisender — Сергея Лукашевича. Если после статьи у вас останутся вопросы— задайте их в комментариях Сергею 🙂
Что такое семантическое ядро
Семантическое ядро — набор слов, фраз и запросов, которые характеризуют сайт, услугу или страницу в интернете. Использование таких слов на сайте позволит нам попасть в выдачу поисковика, хотя у самой семантики функции шире — о них чуть ниже.
Например, для интернет-магазина, который продает головные уборы, в семантическое ядро будут входить слова «купить шапку», «купить кепку», «шляпы дешево», «все ли шапки одного размера» и так далее.
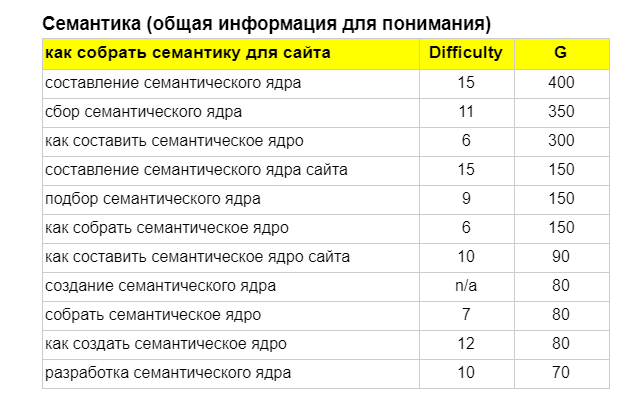
Вот так выглядит семантика для статьи, которую вы читаете. Скорее всего, если вы нашли эту статью в поиске, вы писали что-то подобное. Difficulty означает сложность запроса — чем выше, тем труднее попасть в топ выдачи. G означает частность — сколько таких запросов ищут в месяц
Для чего собирать семантическое ядро
Вот основные причины:
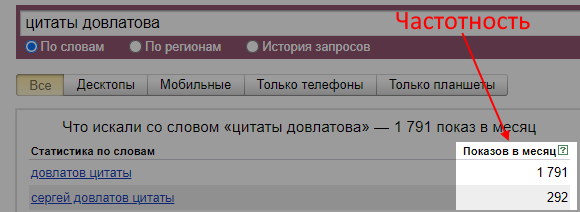
1. Исследовать интересы целевой аудитории. Анализ поисковых фраз — простой и достоверный способ узнать, как и что ищет человек: в поиске он не стесняется своих желаний. Более того, можно количественно отследить интерес людей к теме — в этом помогает частотность запросов в месяц:
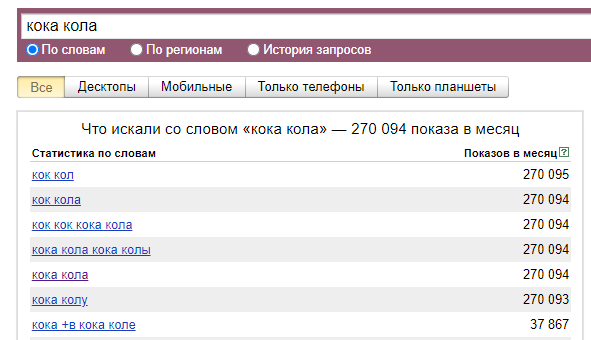
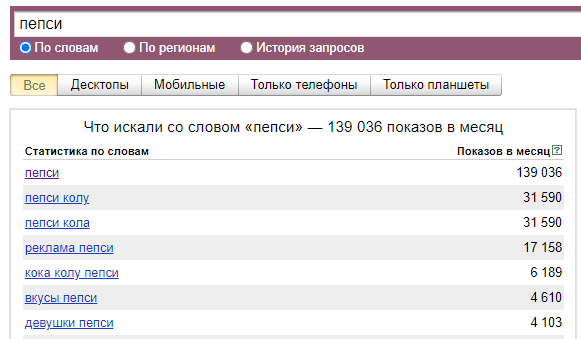
Кока кола популярнее Пепси. По данным Wordstat, запросов, связанных с ней, больше чем в два раза
Анализ семантического ядра дает подсказки в развитии бизнеса: закрыть непопулярные направления (их люди не ищут), открыть популярные — их часто ищут, а это потенциальный источник трафика и оплат.
Глобальная цель сбора семантики — понять, что хочет целевая аудитория, что ищут люди и как часто. Возможно, продукт который мы планируем выпустить или который уже есть — никому не нужен. В этом случае стоит сместить вектор развития в сторону популярных запросов.
2. Создать или доработать структуру сайта. Собранное семантическое ядро разбивается на кластеры. Кластер — группа запросов, которые поисковик считает одной темой и показывает по ней похожие результаты.
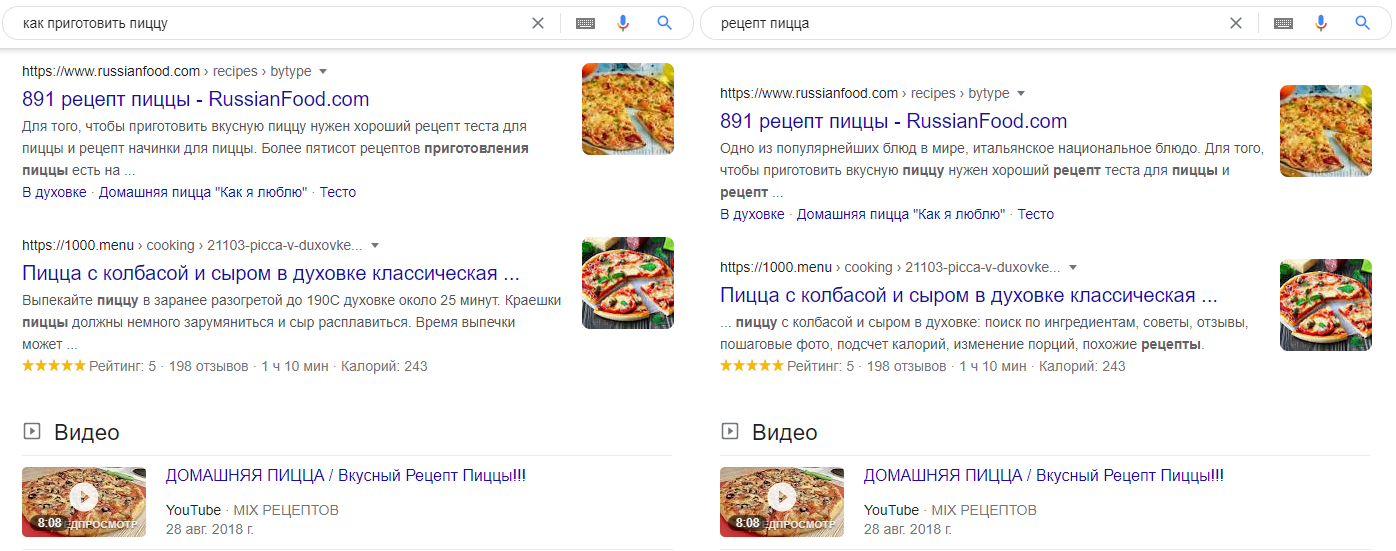
«Как приготовить пиццу» и «Рецепт пицца» — один кластер. Google выдает по этим запросам пересекающие результаты. Первые позиции совпадают полностью
Кластер — готовая идея для страницы в интернете или статьи. Разбив семантическое ядро на кластеры, мы получим грубую структуру сайта, основанную на интересах аудитории. Следуя этой структуре, мы становимся клиентоориентированными.
Семантика — практически неисчерпаемый источник идей для статей. Причем не просто статей, а статей по темам, на которые есть спрос. В блоге Unisender больше половины всех статей seo-оптимизированные. Эта статья тоже оптимизирована.
3. Оптимизировать текст под поиск. На основе семантического ядра к страницам прописывают заголовок, метатеги, описание статьи, структуру с H2 и H3 подзаголовками. А сама семантика — промежуточный этап в формировании ключевых слов (ключей). А глобально все это нужно для пассивного продвижения сайта в поиске.
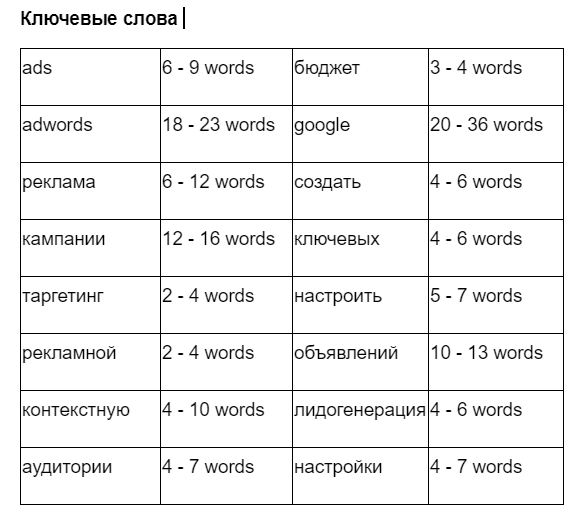
Ключи для статьи про контекстную рекламу. Справа от слова написано его рекомендуемое вхождение — сколько раз за статью оно должно быть использовано
Подбор ключей — совсем другой процесс, в котором сеошник анализирует текст конкурентов в выдаче по определенному кластеру. Через SEO-сервисы можно оценить, какие ключи и в каком количестве используются в их статьях. Если целиться на ключи конкурентов из первых мест выдачи, есть шанс, что и наш материал тоже попадет в топ.
Этап подбора ключей возможен только после составления семантического ядра и кластеризации — благодаря им, мы ищем конкурентов.
4. Отслеживать динамику страниц в поисковике. После того как собрано семантическое ядро мы можем следить за движением сайта в выдаче по определенным запросам. Например, в семантику попал запрос «как поставить мат двумя конями в шахматах». Мы написали статью на эту тему и теперь следим, как поисковик ранжирует ее.
Сначала статья будет выше сотой страницы в интернете, потом постепенно будет подниматься до тех пор, пока не достигнет первой страницы и высших строчек — это показатель того, что SEO-стратегия работает. Если же сайт застрял дальше второй-третьей страницы выдачи, мы что-то делаем неправильно. Возможно, неправильно подобраны ключи или есть другие фундаментальные проблемы. Кстати говоря, на пустой доске мат двумя конями поставить невозможно 🙂
А еще может выясниться, что по другим запросам из кластера сайт продвигается медленнее. Это повод докрутить текст, добавить ключей, оптимизировать некоторые предложения под отстающий запрос.
Семантика — это еще не все
Сбор семантики относится к SEO — оптимизации сайта под поисковую выдачу. Чем сайт оптимизированнее, тем выше вероятность, что он окажется на первой странице по ключевому запросу. Соответственно, тем больше переходов на сайт и целевых действий.
Кроме того, органика (люди, которые перешли на сайт по запросу из поисковика) бесплатна и пассивно приносит людей годами. Например, нашу статью про сокращаторы ссылок за полтора года прочитали 120 000 человек. При этом, мы не вкладывали денег в продвижение — просто правильно оптимизировали текст под поиск.
Сбор семантики — это только маленькая часть работы по SEO. На позицию сайта влияют его быстродействие, гигиена страниц, внешняя оптимизация, текстовая оптимизация и активность пользователей. Про все это подробнее можно почитать в нашем гиде по SEO. Если вы плохо ориентируетесь в поисковой оптимизации, рекомендую сначала изучать гид.
Когда семантическое ядро собирать самому, а когда лучше звать сеошника
Составление семантики — не самый сложный в мире процесс, однако в нем легко запутаться (особенно без опыта):
- Собрать много повторяющихся запросов.
- Упустить перспективные низкочастотные запросы.
- Неправильно отсеять нерелевантные запросы.
- Еще выше вероятность ошибиться на следующих этапах — кластеризации, анализе, формировании страниц в интернете.
Чем больше проект, тем выше вероятность ошибок.
Чем больше проект, тем больше нужд в специальном инструментарии
Я пользуюсь Ahrefs, SEMrush и другими. Они достаточно сложные и новичку в них будет сложно разобраться. В большом проекте может потребоваться сбор семантического ядра из 10 тысяч запросов (например, для крупного интернет-магазина) и развитая структура сайта с тысячами страниц.
Если ваш проект до 50 страниц, смело можете собирать семантику самостоятельно. Как минимум, это поможет определиться со структурой сайта и понять, на каких продуктах или услугах стоит сосредоточиться. А более тонкую работу можно оставить сеошнику, которого наймете позже.
Составление семантики — работа и она требует времени. Если вы плохо с этим знакомы, вам придется тратить время на изучение. Иногда целесообразнее сразу взять сеошника — пусть даже в рамках разового проекта.
На что обратить внимание при подборе ядра
Прежде чем собирать семантическое ядро, нужно синхронизироваться по некоторым терминам. Это теоретическая часть, чтобы лучше понимать инструкцию.
Частотность
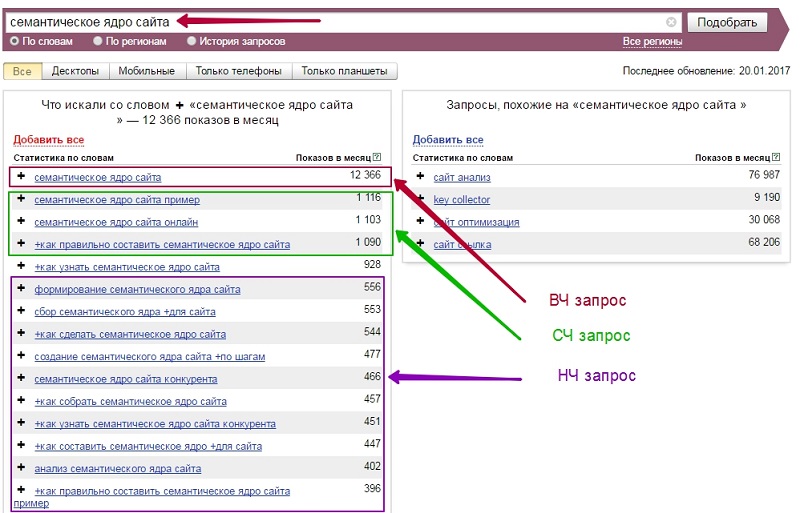
Частотность показывает количество запросов в месяц. Запросы в семантическом ядре разделяются на высокочастотные, среднечастотные и низкочастотные. Высокочастотные ищут чаще, чем низкочастотные, а среднечастотные — что-то промежуточное между ними. Деление запросов на эти группы относительное и зависит от сферы. В каких-то сферах, 100 относится к низкочастотным, а в других — к высокочастотным.
Ранжирование
Ранжирование — сортировка сайтов в выдаче в зависимости от их рейтинга, который подсчитывают алгоритмы поисковика. Чем выше рейтинг сайта, тем лучше он ранжируется — занимает верхние строчки выдачи.
На рейтинг влияют текстовая оптимизация, адаптивность, скорость загрузки, внешние ссылки и другие параметры. Запущенный сайт с идеальными семантическим ядром не попадет в топ — поэтому не фокусируйтесь лишь на одном сборе семантики.
Конкурентность
Конкурентность запроса — величина, которая показывает сложность попасть в топ выдачи. Она зависит от конкурентов — чем их больше и чем качественные их сайты, тем сложнее будет идти продвижение.
Подробнее про конкуретность можете почитать здесь.
Опытные сеошники при сборе семантики указывают сложность (Difficulty). Если вы новичок — не парьтесь. Но если ваша ниша сильно конкурентная, опять же, нужен опытный сеошник.

Чем выше значение Difficulty, тем сложнее попасть в топ выдачи по этому запросу
Интент
Интент — это потребность пользователя, которую он хочет решить, когда вводит запрос. Некоторые запросы размыты, например, запрос «что такое осень» — пользователь хочет узнать, что такое осень или он ищет песню группы ДДТ?
Поисковики научились угадывать интент пользователя и даже по обобщенным запросам выдают нужное. И по запросу «что такое осень» все имеют в виду песню — это и показывает поисковик.
Учитывайте интент, иначе в ваше семантическое ядро попадут запросы, к которым вы не имеете отношения. Для этого просто внимательно просматривайте семантику на этапе чистки.
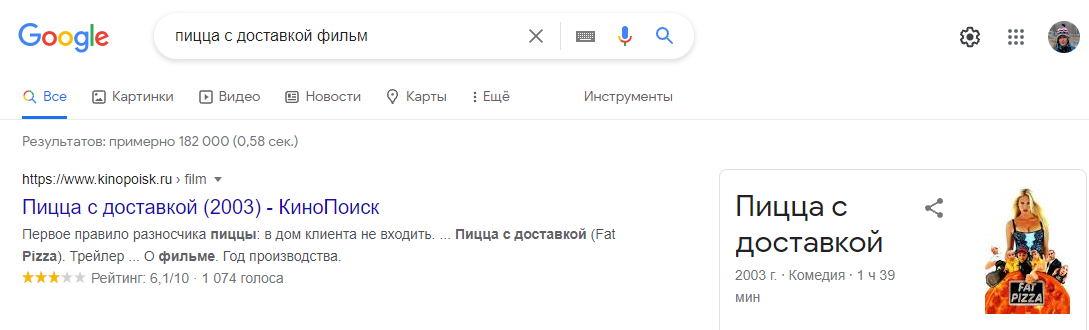
В мою семантику попал запрос «пицца с доставкой фильм». Не знал, что такой есть и поэтому было ощущение что запрос можно оставить. Но потом загуглил и вот — под пиццерию это не подходит
Геозависимость
Геозависимость — фича поисковиков, чтобы адаптировать выдачу под место проживания пользователя. Если вести «макдональдс адрес» — мне не покажут адреса фастфудов в Сыктывкаре, а покажут в моем городе.
Если у вас локальный бизнес, семантику нужно составлять с учетом геозависимости. Для этого в Яндекс Вордстат есть настройка по региону — информация будет выводиться только по нему. А если у вас онлайн бизнес, то на геозависимость можно не обращать внимания — в Вордстат по умолчанию выбраны все регионы. Но при желании можно добавить еще и страны СНГ.
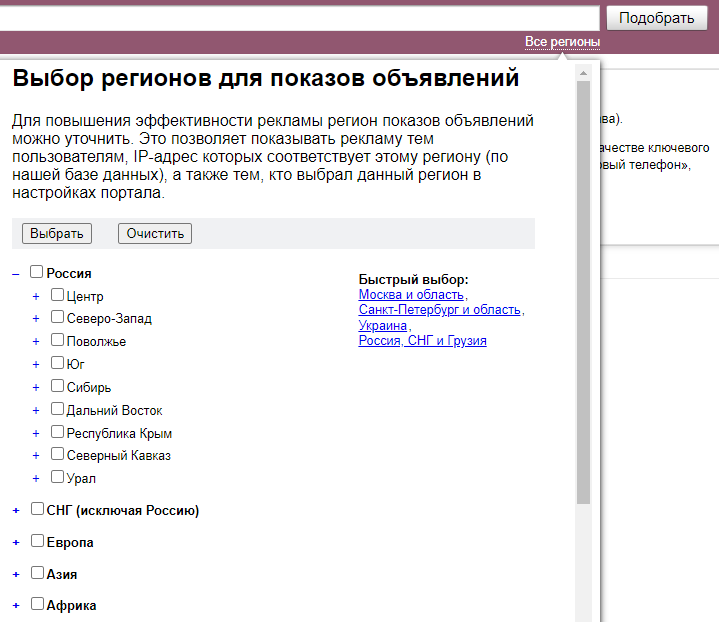
Можно выбрать как всю Россию, так и конкретный город или регион
Пошаговая инструкция как составить семантическое ядро
Подумайте, какие запросы характеризуют ваш сайт
Составление семантического ядра начинается с мозгового штурма. Ответьте на вопрос: если бы вы искали свой сайт в поисковике, то по каким запросам? Все идеи, которые придут в голову, записывайте в таблицу или текстовый документ.
Несколько советов, как охватить все интересные запросы:
- Созвонитесь с командой, особенно с теми, кто участвует в разработке продукта и делает сайт. Попросите их ответить на вопрос выше. Записывайте все идеи и фразы, которые придут в голову.
- Нужны запросы не только в рамках сайта в общем, но и в разрезе конкретных продуктов и частных вопросов клиентов. Например, сайт продает и устанавливает пластиковые окна. В семантику можно записать запросы «сколько стоит установка пластиковых окон» и «чем отличаются пластиковые окна». Такие запросы напрямую не связаны с нашими услугами, но все равно могут принести трафик, который позже конвертируется в клиентов.
- Забавный источник идей — отдел продаж и служба поддержки. Им всегда задают кучу вопросов и практически всегда эти вопросы популярны в поисковике.
Блог покроет информационные запросы и увеличит трафик на сайт
Даже если ваш сайт предполагается чисто коммерческим, я все равно рекомендую обратить внимание на информационные запросы, сделать под них специальные страницы или даже вынести в блог. Это в несколько раз ускорит продвижение и существенно увеличит трафик на сайт.
Блог ощутимо ест бюджет, особенно если организовывать собственную редакцию и налаживать регулярный выпуск материалов. Но это и не нужно — достаточно нескольких статей, которые бы отвечали на популярные запросы в поиске.
Производство статей можно отдать на аутсорс, а технически реализовать блог внутри домена несложно и недорого. В таком случае это будет лишь единовременным вложением, а не ежемесячной статьей расходов.
Теперь покажу на примере, что у вас должно получиться на этом этапе. В моем примере я собираю семантику для интернет-магазина пиццы в Оренбурге. Я сгенерировал такие запросы:
Сбор базовых ключевых слов
Все запросы, которые мы получили на прошлом этапе, поочередно вбиваем в Яндекс Wordstat или Букварикс. Все сервисы интуитивно понятны.
У Букварикс база Google и Яндекса, но я в нем не нашел функции фильтра по местности. У Яндекса это и есть, однако он раздражает вводом капчи после каждого запроса.
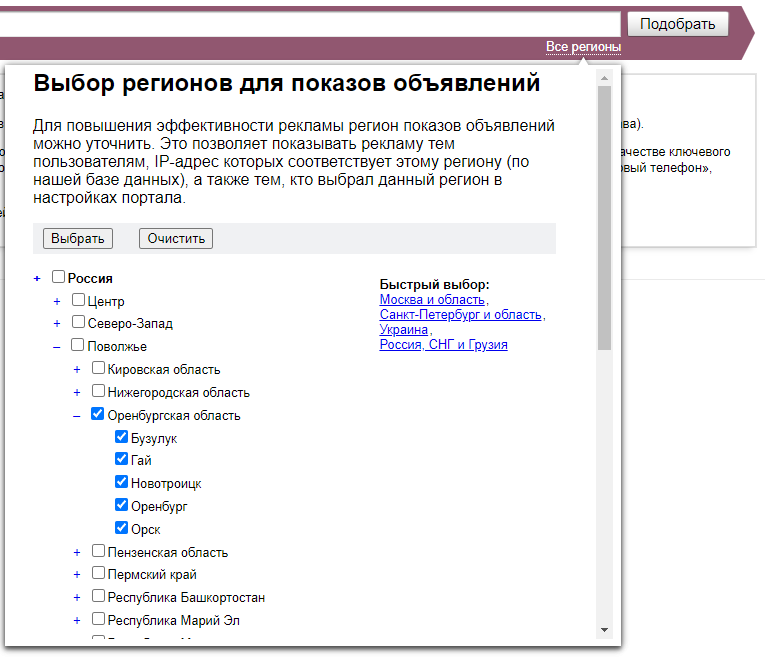
Выбор региона в Яндекс Вордстат
Поглядите, какая мне смешная капча попалась 🙂
Показываю на примере, как работаю с Яндекс Вордстат. Беру первый запрос из своего документа и ввожу его. Всю статистику из обоих столбцов копирую в Google Таблицы.
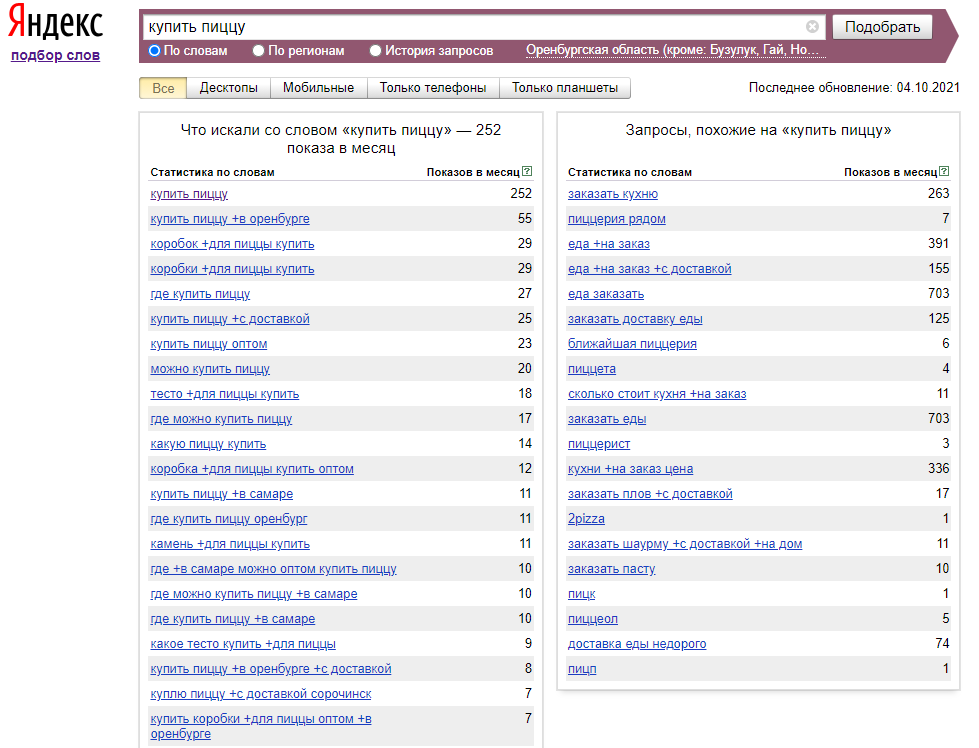
Статистика Яндекс Вордстат по запросу «купить пиццу» для Оренбурга
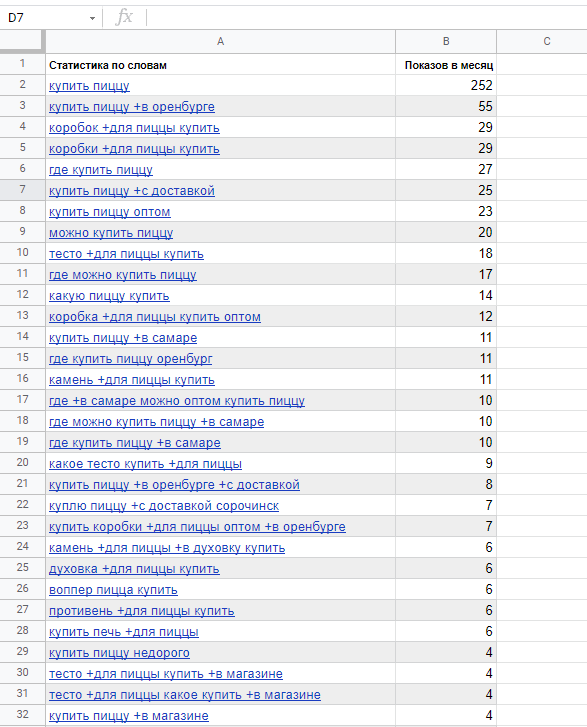
А вот так это выглядит в Google Таблицах
Располагайте запросы в один столбец. Пройдитесь по всем запросам из своего документа. Самые общие высокочастотные запросы пробейте дополнительно через Букварикс — в нем можно подсмотреть запросы, которые стоит поискать. Например:
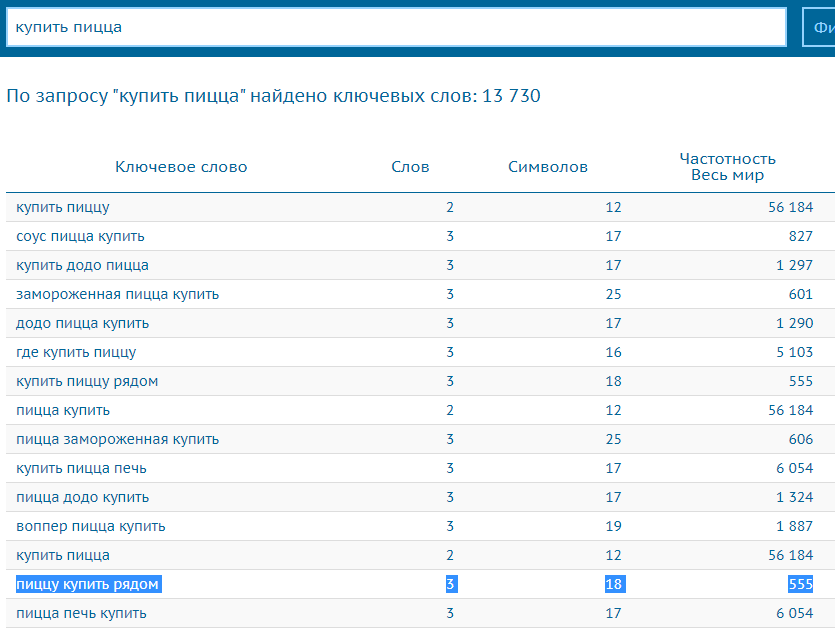
Я вбил общий запрос «купить пицца» и мне приглянулись фразы «пиццу купить рядом» и «воппер пицца купить» — последнюю часто ищут, видимо, какой-то тренд. В этот раз меня интуиция подвела: в Оренбурге «воппер пиццу» ищут 6 раз в месяц, что очень мало, а «купить пиццу рядом» не ищут вообще. Но тем не менее используйте Букварикс — это поможет вам отыскать другие перспективные запросы
Важно в процессе подбора запросов не переусердствовать. В какой-то момент это утратит смысл — в таблицу будут попадать фразы-синонимы, странная низкочастотка и другой мусор. Соблюдайте баланс — если расслабитесь слишком рано, не дойдете до перспективных среднечастотных запросов.
Как понять, что пора заканчивать собирать семантическое ядро — вопрос опыта. Тут нет идеального правила. По идее, вы сами почувствуете, что уже перебираете одно и то же — это сигнал, что вы финишировали.
Когда я только начал заниматься SEO, то любил собрать тонну запросов и копаться в них. Потом понимаешь, что это бессмыслица. Пускай лучше запросов будет меньше для каждой страницы, но они будут качественные и понятные.
Если сомневаетесь, можете собирать много запросов — мы все равно их удалим при чистке: просто это лишняя работа.
Анализ конкурентов
В интернете полно конкурентов — мы можем просканировать их через специальные сервисы и получить почти готовую семантику: важно отбирать только качественные страницы, которые высоко ранжируются в выдаче. Такие сервисы платные и разбирать в статье их функционал мы не будем. Если вам интересно, присмотритесь к следующим сервисам и изучите их самостоятельно:
- SEMRush
- Ahrefs
- Serpstat.
Почерпнуть идеи у конкурентов можно и без специализированных сервисов. Заходите на их сайт и внимательно изучайте — пощелкайте страницы в интернете и посмотрите, что пишут. Вы, скорее всего, отыщете запрос, который стоило бы включить в семантическое ядро, но который сами упустили из виду — обращайте внимание на заголовки страниц.
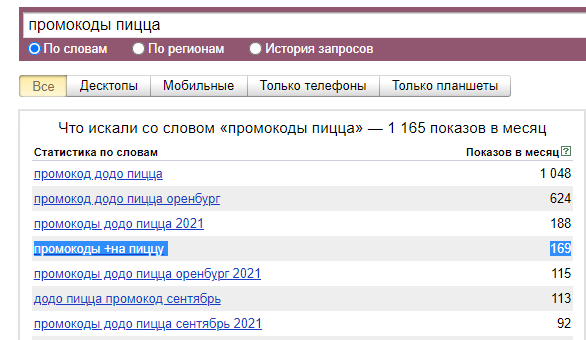
На одном сайте пиццерии я увидел раздел с акциями и стал копать в этом направлении. Попробовал запросы «пицца скидки» и «промокоды пицца». По последнему запросу неплохой результат — 169 запросов для Оренбурга, точно нужно взять. А по скидкам частотность меньше, но тоже можно использовать
Шлифуем семантику — сортируем, удаляем дубликаты и лишние символы
Удаление дубликатов. Некоторые запросы будут пересекаться. Нам они не нужны, поэтому удалим дубликаты через все тот же раздел «Данные»:
Выделяем таблицу и нажимаем вкладку «Данные», а в ней «Удалить повторы». Оставляем только столбец A — в котором содержатся сами запросы
Удалить плюсы. Они будут мешать на этапе кластеризации.
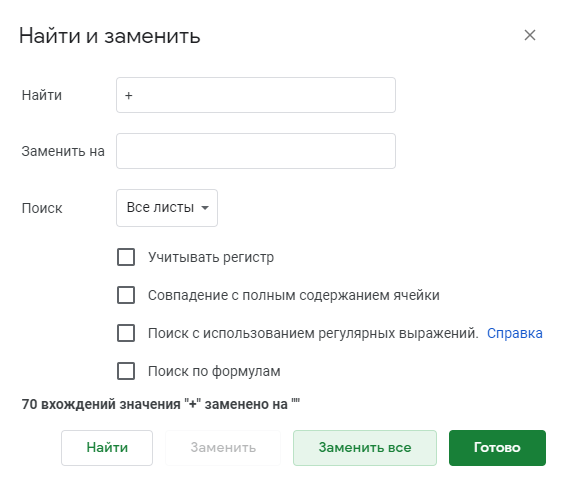
Нажмите Ctrl + F или Command + F на MacBook. В выпадающем меню выберите три точки. Либо в разделе «Правки» кликните «Найти и заменить». В поле «Найти» напишите «+», остальное оставьте без изменений. Нажмите на кнопку «Заменить все». Google удалит все плюсы из таблицы
Сортировка. Теперь всю таблицу отсортируем по убыванию частности. Отсортировать можно функционалом Google Таблиц. Этот шаг нужно повторить после следующего пункта «чистка нерелевантных запросов». При удалении запросов у нас появятся в случайных местах таблицы, а сортировка снова сведет всю семантику воедино.
Сортировка запросов по убыванию частотности. Выделяем таблицу, нажимаем «Данные» и кликаем по «Сортировать диапазон по столбцу B, Я → А». Если у вас частность не в столбце B, то сортируйте по другому столбцу
Чистка нерелевантных запросов
В семантическое ядро так или иначе попадут нерелевантные запросы — такие запросы не характеризуют наш сайт, а люди, когда их вводят, ищут совсем другое. От таких запросов нужно избавляться — трафика они не принесут.
Удаляем такие запросы:
- С упоминаниями конкурентов.
- С товарами или услугами, которые не оказываем.
- С упоминанием города, районов и улиц в которых не работаем.
- Запросы с ошибками. Даже если человек сделает ошибку в запросе, поисковик все равно переведет его на верный запрос.
- Фразы, которые вы не понимаете. С большой вероятностью это не имеет отношения к вашей компании.
- Запросы-синонимы, например, «купить смартфон» и «смартфон купить»
- Микрозапросы — их ищут ничтожно мало, такая сеошная погрешность. Зависит от сферы: например, если наша среднечастотка 200 запросов, то все запросы меньше 10 можно удалять. Тем более, если они похожи на уточнение основного запроса.
Давайте почистим ненужные ключи для нашего примера с пиццерией. Их получилось много:
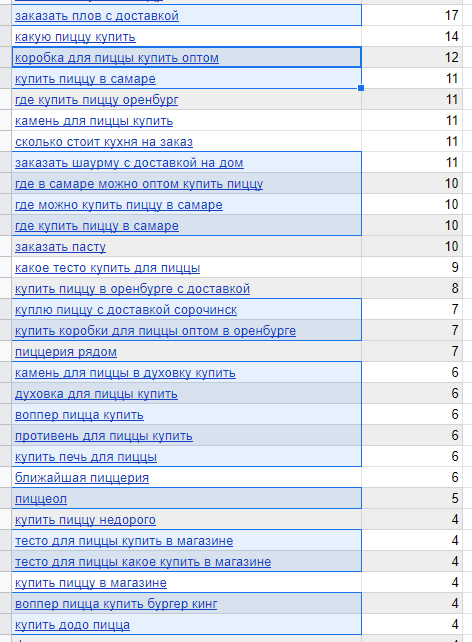
Плов и шаурму я не продаю. Печку, камень, противень, тесто и коробки для пиццы тоже. Воппер-пиццы нет в моем ассортименте. Удаляем.
Несмотря на то, что я смотрел запросы только по Оренбургу, в результаты Яндекс Вордстата подмешались левые запросы — пицца Сорочинск и Самара. Удаляем.
«Пиццеол» — непонятный запрос, который не прояснился даже после того, как я проверил в Google — удаляем. Еще на этот скриншот попала «Додо пицца» — конкурент. Конкурентов, гораздо больше, все они выше. Конкурентов удаляем, либо переносим их в другой документ: если планируете запускать контекстную рекламу — там пригодится такая семантика.
Еще встретился запрос «чудо пицца». Я сначала не понял, потом оказалось что это местная пиццерия. Поэтому важно удалять запросы, которые вы не понимаете. Для верности можете загуглить их.
Несколько примеров с запросами под удаление. Они выделены синим:



Если запрос перспективный, но у вас нет таких услуг — переносите его в скоринг-документ
При сборе семантики часто всплывают запросы, которые близки нашему бизнесу, но таких услуг у нас еще нет. Если эти запросы перспективны и их часто ищут люди — не удаляйте их, а перенесите в скоринг-документ. Это документ с идеями развития и масштабирования бизнеса с точки зрения SEO.
В нашем примере про пиццу такие запросы — суши и роллы. Люди часто ищут их вместе с пиццей, но если мы занимаемся одной только пиццей — нам они не подходят.
Чистка — рутинный процесс, который может занять много времени. Проверять семантическое ядро нужно вручную, а иногда запросов много — больше тысячи. Ну тут ничего не поделать.
Не игнорируйте информационные запросы
При чистке важно сохранять осознанность и не делать это действие на автомате — можете пропустить интересные запросы, которые стоило бы внедрить.
В примере про пиццерию я выяснил, что люди часто ищут рецепты для пиццы — это информационный запрос. Пиццерия вполне может запустить небольшой блог, в котором будет раскрывать похожие темы. Так мы привлечем больше трафика и познакомим аудиторию со своим брендом. Бизнесу ведь нужно повышать узнаваемость — это один из инструментов.
Конечно, если человек ищет рецепт пиццы, он хочет сам ее приготовить, но в конце статьи мы можем предложить человеку купить нашу пиццу, по рецепту который он искал. У человека уже появится лояльность к нашему бренду, а когда его пицца не получится, он закажет ее у нас 😁.
Другой интересный запрос, который я увидел — «рейтинг пиццерий». Мы можем на поддомене написать статью с рейтингом популярных оренбургских пиццерий. Похожую механику мы используем в Unisender: объективно сравниваем себя с конкурентами в статьях из базы знаний.
Если вы видите, что низкочастотные запросы повторяют основные запросы, только в них содержится странный хвост — их тоже можно удалять. В нашем примере про пиццу выяснилось что все запросы с частотой 10 и меньше можно убрать — они так или иначе копируют запросы, которые уже есть.
Также удаляйте запросы-синонимы, в которых слова из запроса одни и те же, но в другой последовательности. Например, «пицца доставка» и «доставка пицца. Их можно искать вручную, но удобнее делать через программу Key Collector (платная) — там есть функция «анализ неявных дублей».
Ссылка на Google-таблицу с семантикой сайта пиццы
На этом сбор семантики закончен. Теперь ее нужно разбить на кластеры.
Кластеризация
Напомню, кластеризация — деление семантического ядра на кластеры. Кластер — группа запросов, которую поисковик считает одной темой и выдает по ней пересекающиеся результаты.
Проверить кластеры можно вручную. В режиме инкогнито вбейте запросы и проверьте выдачу. Например, «заказать пиццу» и «купить пиццу» один кластер, выдача похожа.
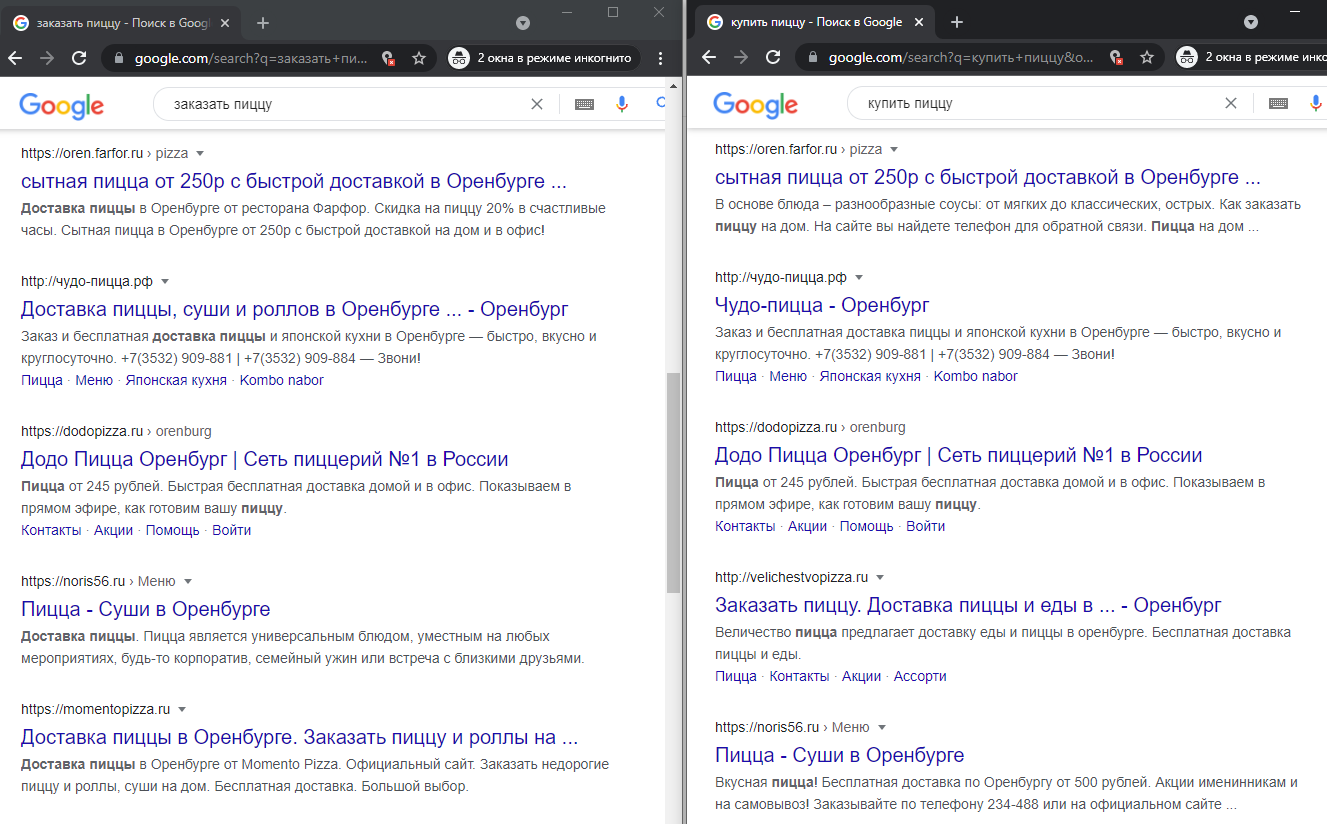
Проще всего кластеризовать семантику через специальные сервисы. Советуем KeyAssort — он платный, но с мощным функционалом. Еще можете присмотреться к KeyClusterer, этот уже бесплатный.
Далее будем кластеризовать семантическое ядро на примере KeyAssort. Принцип работы следующий: вы отдаете сервису свою семантику, он в зависимости от заданных параметров, проверяет пересечения, объединяет похожие запросы в кластеры и отдает вам. Вы можете посмотреть видео-инструкцию по работе с программой на официальном сайте, а я здесь кратко перескажу основные действия.
Приведенный ниже пример кластеризации — упрощенная схема. Более сложный и точный подход — когда мы берем частотность и сложность ключевого слова из платных сервисов.
Импорт. Чтобы программа все загрузила верно, лучше работать через шаблон. Скачать шаблон.
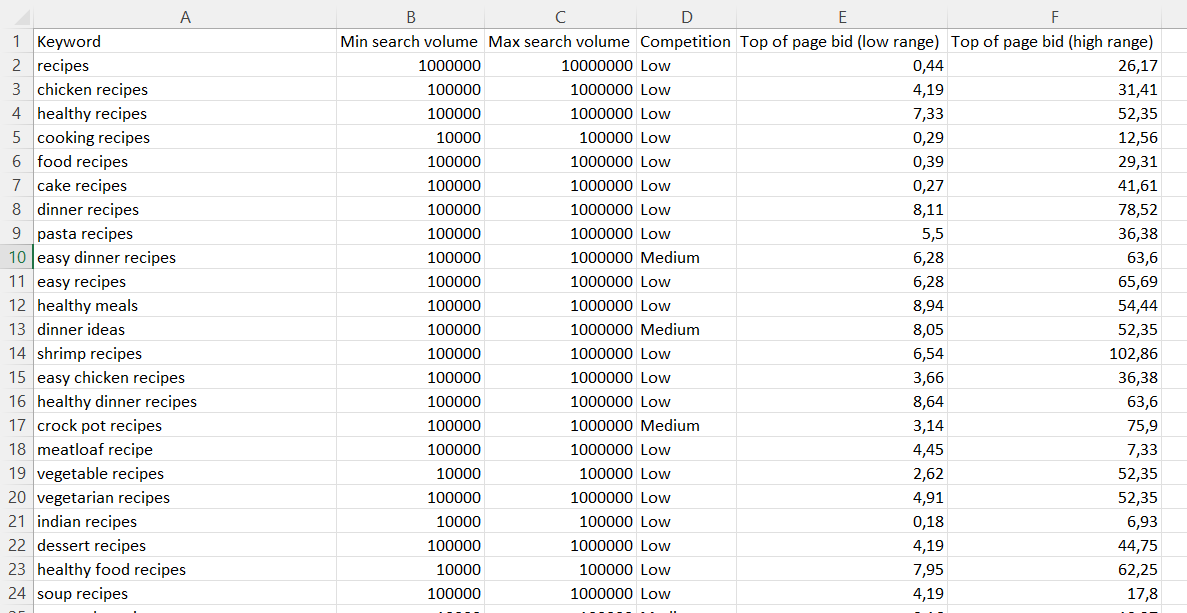
В первый столбец копируем запросы, а частотность копируем во второй и третий столбец (Mix search volume и Max search volume) — то есть их нужно продублировать. Поставьте значение «0» во всех остальных ячейках и «low» в Сompetition. Теперь импортируем:
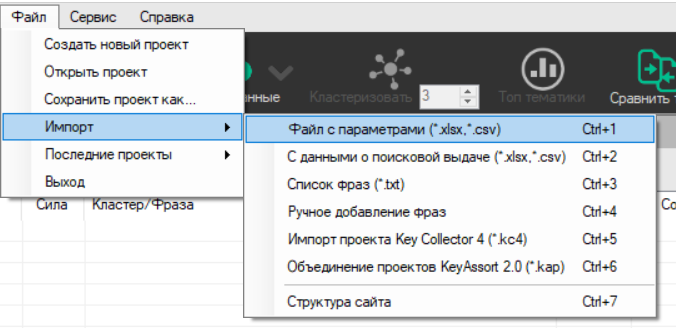
В меню нажимаем «Файл» — «Импорт» — «Файл с параметрами»
Следующие окна оставляем без изменений:
Сбор данных. Теперь нужно, чтобы программа проанализировала запросы и выявила среди них кластеры. Нажимаем «Собрать данные» в верхнем меню:
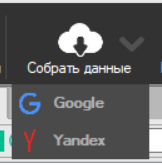
Так как мы работали с Яндекс Вордстат, то собираем по Яндексу
У нас около 200 запросов и сбор данных займет несколько минут. Чем больше семантика — тем больше времени.
Кластеризация. Нажимаем в верхнем меню «Кластеризация» и начинаем эксперименты с настройками. Цель — получить адекватную сборку кластеров . Мы можем менять вид кластеризации, силу группировки и другие параметры — подробнее об этом читайте в справке KeyAssort.
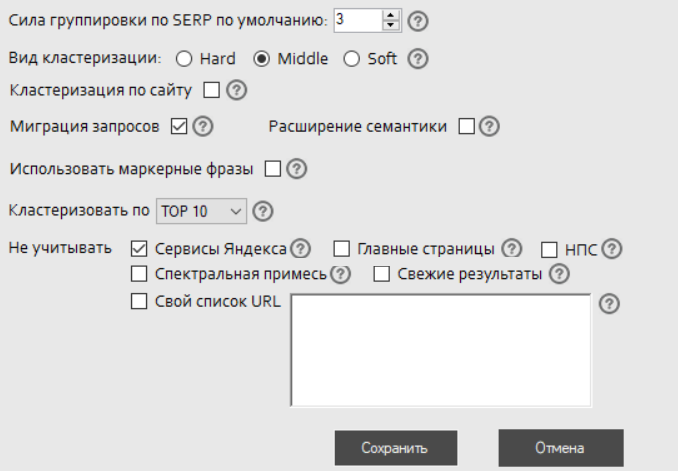
Настройка кластеризации
Меняйте настройки пока не увидите адекватную сборку кластеров. Иногда приходится вручную перебрасывать запросы из одного кластера в другой чтобы получить лучший результат.
В нашем примере получился такой результат:

В последнем кластере ошибка — это не статья в блоге, а страницы пиццы
Структура будущего сайта получилась точной, но большая часть запросов попала на главную страницу — это особенность региональных проектов.
Что дальше
Теперь у вас есть собранная и кластеризованная семантика. Можно:
- Продумать структуру сайта. Под каждый кластер — своя страница.
- Отслеживать движение сайта в выдаче по ключевым запросам.
- Подумать над созданием продуктов, которые близки нашему бизнесу.
- Писать технические задания с ключевыми словами и вставлять их в страницу — но это уже совсем другая тема, в этой статье мы ее касаться не будем.
Заключение
Статья получилась большой, пробежимся по основным выводам.
Что касается базовой теории:
- Семантика — набор запросов и фраз, которые характеризуют наш сайт или конкретную страницу.
- Семантика помогает продумать структура сайта, отслеживать продвижение сайта по ключевым запросам в поиске, а также это необходимый этап перед формированием сео-ключей. Собранное ядро — отличный советник по бизнес-идеям: на разработке каких продуктов и страниц, нужно сосредоточить внимание, а от каких наоборот отказаться.
- Если у вас не очень крупный проект, есть желание и время погрузиться в SEO — собрать семантику можно самостоятельно. В остальных случаях нужен сеошник хотя бы на разовый проект.
- Собранное семантическое ядро открывает путь к текстовой оптимизации страниц — добавлению SEO-ключей и метатегов, проработке структуры статьи, ее объема и другое. Это сложнее сбора семантики и тут нужные более глубокие знания. Скорее всего, придется звать сеошника и не факт, что его устроит собранная вами семантика.
Как собрать семантику за 6 шагов:
- Обсудите с коллегами и сотрудниками, какие запросы характеризуют ваш сайт. Ответьте на вопрос: «если бы вы искали свой сайт в поисковике, то по каким запросам?»
- Вбейте все фразы из предыдущего этапа в Яндекс Вордстат и скопируйте все предложенные запросы в Google Таблицы. Дополнительно используйте Букварикс.
- Посмотрите конкурентов — изучите их разделы, вам наверняка придет идея, как расширить свою семантику.
- Шлифовка и сортировка. Удаляем дубли, микрозапросы, символы «+» из Яндекс Вордстат.
- Чистка. Удаляем непонятные фразы и все, что наш сайт дать пользователю не может. Перспективные запросы, но которые сейчас не описывают наши услуги, переносим в скоринг-документ.
- Кластеризируем семантику через KeyClusterer.
SEO-продвижение не ограничивается одной лишь семантикой и текстовой оптимизацией — это более многогранный процесс, который охватывает работу с технической и контентной частью сайта. А еще желательно публиковаться на внешних ресурсах — блогах и каталогах. Подробности про всё SEO читайте в нашем гиде.
ЭКСКЛЮЗИВЫ ⚡️
Читайте только в блоге
Unisender
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
![]()
![]()
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Один из этапов создания рекламной кампании — сбор семантического ядра. Оно включает в себя ключевые фразы пользователей, по которым будут показываться рекламные объявления. Релевантные ключевые слова и правильно написанный оффер — отличная возможность показать объявления целевой аудитории, привлечь клиентов и сэкономить бюджет. Как это сделать, читайте в инструкции по составлению семантического ядра от eLama.
Семантическое ядро для поисковых кампаний
1 этап. Сбор базовых ключевых слов
Прежде всего подумайте, какие слова характеризуют вашу нишу. Например, для интернет-магазина по продаже iPhone будут очевидны следующие слова: iPhone, айфон, купить, заказать и т. д. Для удобства записывайте слова в таблицу Excel.

Если у вас закончились идеи, то зайдите в yandex.wordstat.ru и посмотрите, что ищут при вводе, например, iPhone.

К собранному в Excel списку добавим слово «Цена».
Далее, найденные слова нужно скомпоновать. Это можно сделать через инструмент eLama «Комбинатор ключевых фраз»:

Полученные фразы мы будем использовать на следующем этапе.
Бесплатные кампании в Директе для старта
Для тех, кто раньше не запускал рекламу в Директе через eLama
Получить кампании
Этап 2. Подбор семантического ядра
Снова обратимся к сервису Wordstat и узнаем количество запросов пользователей по тому или иному слову. Это поможет в создании семантического ядра.
Установите расширение Yandex Wordstat Assistant для браузера, чтобы собрать запросы и их частотность быстрее:

Итак, получился список и одна свободная колонка, которая нужна для списка минус-слов.

Этап 3. Чистка семантического ядра
Теперь весь список ключевых слов нужно очистить от нерелевантных запросов, чтобы показывать рекламу только тем пользователям, которые ищут наши товары. Например, я не продаю iphone 7 в рассрочку в Минске, поэтому исключаю 7, минск, рассрочка. Содержащие эти слова и ключи стоит удалять сразу же, чтобы они случайно не попали в ключевые фразы.
Проще и удобнее это сделать в минусаторе eLama. Скопируйте собранную список семантики и вручную выделите все ненужные слова. В итоге у вас получится два списка: ключей и минус-слов. А еще в минусаторе можно применить готовый список минус-слов к списку ключевых фраз — инструмент найдет нерелевантные фразы и удалит их. Как работать с инструментом, читайте в другом нашем материале.
Можно продолжить работу в таблице, но так будет посложнее.

Если требуется удаление нескольких фраз, то сократите время поисков, используя фильтр Excel.

Для кампаний в Google Ads можно выбрать «Планировщик ключевых слов».

По сравнению с Wordstat он имеет больше функций, благодаря которым можно:
- узнать конкурентность ниши и процент показа объявлений;
- минимальные/максимальные ставки для показа объявлений внизу/вверху страницы.
В списке могут появиться фразы с минимальным различием, например, «iphone 8 в москве» и «iphone 8 купить спб». Для того, чтобы система показывала объявления, релевантные запросу, нужно провести кросс-минусацию, например, через eLama.
Для получения более точного результата попробуйте комбинировать все инструменты.
Этап 4. Заключительный
Теперь у вас есть отдельно список с ключевыми фразами и минус-словами. Вам нужно составить объявления таким образом, чтобы ключевая фраза была в первом или втором заголовке. Так вы сможете увеличить CTR объявления, а следовательно, уменьшить его стоимость.

Операторы и типы соответствия ключевых слов в Яндекс Директе и Google Ads
Операторы и типы соответствия необходимы для уточнения запросов пользователей. Например, вы создали акционное рекламное объявление, в котором говорите о продаже билетов из Москвы в Санкт-Петербург, то используйте оператор []. Таким образом, люди, которые хотят поехать из Санкт-Петербурга в Москву, не увидят ваше объявление.
Для экономии времени используйте «Комбинатор ключевых фраз», который автоматически добавит операторы +, ! в ваши списки. Под столбцами с собранным списком нажмите на «Дополнительно» и выберите оператор:

Если нужны типы соответствия/операторы, которых нет в «Комбинаторе ключевых фраз», то используйте Excel. Например, вы можете вставить оператор перед повторяющимся словом. Полный список операторов Яндекс.Директа есть на странице помощи, а для типов соответствия Google Ads — здесь.
Подбор ключевых слов для КМС и РСЯ
Ключевые фразы для РСЯ и КМС не нужно уточнять. Достаточно создать семантическое ядро с широкими ключевыми фразами, которые взаимосвязаны между собой. Если вы не уверены в собранных ключевых словах или боитесь мусорного трафика, то воспользуйтесь помощью Google Ads. Войдите в Аккаунт — Ключевые слова — Ключевые слова КМС или видео — введите свой сайт или услугу — система покажет релевантные ключи. Подобранные ключи можете использовать не только для КМС, но и для РСЯ.
Заключение
Сбор семантики — интересный, но в то же время сложный процесс. На каждом из этапов надо быть внимательным, чтобы не допустить нецелевых ключевых фраз. Однако следование подробной инструкции от eLama поможет сэкономить время на каждом этапе.
Семантическое ядро, или СЯ, это сердце сайта интернет-магазина — те запросы, по которым люди будут находить ваши товары в поисковых системах. СЯ является важной частью SEO-продвижения, и без него не обойтись.
Идеально, если СЯ составляется перед запуском сайта. Но на практике далеко не все хотят заморачиваться этим, и в результате интернет-магазин теряет позиции в поиске. Люди просто не видят его, ведь сайт “не заточен” на нужные слова. Но никогда не поздно исправить ситуацию и переделать сайт с учетом правильно составленного ядра.
В этой статье расскажем, зачем нужно составлять семантическое ядро, как это сделать и какие инструменты нужно использовать.
Что такое семантическое ядро?
А теперь подробнее. Вот у вас интернет-магазин с каталогом товаров, категориями меню, карточками товаров. Еще наверняка есть текст на главной странице, условия доставки и возврата, а может, еще и блог. И везде есть слова, которые могут быть просто словами, а могут — поисковыми запросами.
Например, вы продаете женскую одежду. Она разбита по категориям: юбки, брюки, платья, нижнее белье. Это еще не запросы, это просто слова-маркеры. Идем дальше. Наверняка категории товаров разбиты на бренды. Платья “Зара”, юбки “Диор” — это уже ближе к запросам. А вот “купить юбку диор”, “платье зара недорого” — это уже поисковые запросы. Именно их человек будет вбивать в поиск, и именно по ним попадет (если все правильно сделать) на ваш сайт.
Так вот, семантическое ядро — это пул часто встречающихся запросов, по которым пользователь придет к вам. Логично, что все эти запросы должны быть органично включены в продающие и информационные тексты на сайте.
Зачем нужно составлять семантическое ядро?
Тому, как в песне, есть пять причин:
- Чтобы грамотно оптимизировать сайт как внешне, так и внутренне.
- Чтобы создать удобную и понятную клиентам структуру сайта.
- Чтобы улучшить позиции сайта в поисковой выдаче.
- Чтобы привлечь на сайт бесплатный органический трафик.
- Чтобы получить новых клиентов и увеличить прибыль.

Что такое семантическое ядро: обобщение
Как создать семантическое ядро для интернет-магазина
Шаг 1. Собираем маркеры
Как уже было сказано, маркеры — это заготовки поисковых запросов, их смысловая основа. Маркеры по сути — это наименования категорий, подкатегорий, названий товаров. Чем дальше углубляться в структуру сайта, тем более развернутыми будут маркеры.
Если продолжать рассматривать пример магазина женской одежды, маркерами на уровне категорий будут “юбки”, “платья”, брюки” и так далее. На уровне подкатегории “платья” — “платья летние”, “платья утепленные”, “платья бандажные”, “платья Zara” и прочих брендов. На уровне карточек товаров — “платье летнее из шелка”, “платье из коллекции “Шик”, “платье Zara белое льняное”.
Для категорий/подкатегорий/карточек товара собирать маркеры нужно отдельно. Можно просто выписать их в отдельные таблички.
Мы рассмотрели случай, когда структура интернет-магазина уже создана ранее. Кстати, будьте готовы к тому, что с учетом СЯ ее придется переделать: убрать ненужные и не пользующиеся спросом категории, например. Так ваш сайт будет более оптимизирован.
Вернемся к случаю, когда СЯ составляется параллельно со структурой и каталогом сайта. В этом случае сначала создайте каталог (можно воспользоваться готовым шаблоном или составить таблицу каталога вручную, ориентируясь на ассортимент магазина, структуру конкурентов). Вот пример такой таблицы:

Шаг 2. Подбираем запросы
Теперь на основе этих маркеров подбираем поисковые запросы, по которым пользователи попадут на сайт. Сделать это можно несколькими способами.
Первый и самый популярный — через сервис “Яндекс.Вордстат”.
Забиваем в строку поиска маркеры и смотрим выпавшие подсказки. Это и будут запросы и частота, с которой люди их делают. Если ваш бизнес привязан к конкретному региону или зависит от сезона, можно посмотреть статистику и по этим параметрам.
Второй способ — с помощью бесплатной программы “Словоёб”или “Словодёр” (простите, это название такое, но программа классная!). Прописываете в настройках логин и пароль от Яндекс-аккаунта, указываете регион и забиваете в поисковое поле маркер.
Третий способ — платная программа Key Collector. В этой программе можно дополнительно прописать список стоп-слов для вашей ниши (найти можно в интернете).
И наконец, с помощью сервиса Serpstat можно посмотреть, какое СЯ собрали конкуренты. Нужно указать домен сайта, выбрать регион и поисковик — “Яндекс” или “Гугл”. Во вкладке “Конкуренты” выбрать основных конкурентов примерно одного уровня с вами и анализировать.
Шаг 3. Смотрим частотность
Итак, запросы собраны. Теперь смотрим самые популярные (высокочастотные), средне- и низкочастотные. Высокочастотные запросы — не панацея. Совсем не факт, что по запросу “платья летние купить” вам удастся вывести сайт в ТОП. Все потому, что таких запросов слишком много, а конкуренция — еще больше. В ТОПе скорее всего окажутся крупные магазины и товарные маркетплейсы.
Поэтому продвигаться лучше по низко- и среднечастотным словам. Их набирают меньше, а значит, можно побороться за топ поиска!
Частотность запроса в “Яндекс.Вордстат”
Шаг 4. Чистим мусор
Теперь внимательно смотрим оставшиеся ключевые слова и избавляемся от тех, которые люди набирали меньше 5 раз за месяц — зачем они нам, если по ним никто не придет! Вот и первый звоночек скорректировать ассортимент, кстати.
Затем удаляем нерелевантные запросы. Мало ли, что случайно может затесаться в стройную систему — программа ведь не человек и может ошибиться. Возможно также наложение смыслов: например, при запросе “платья женские” мне встретился сомнительный “ключ, что под женским платьем”. Можно, конечно, включить его в структуру сайта, но только представьте, кто по этому запросу к вам придет! И дело даже не в этической стороне: придет такой пользователь и быстро покинет сайт, поняв, что здесь всего лишь магазин. И испортит вам тем самым статистику поведенческих факторов.
От мусора можно избавиться вручную, просмотрев собранное ядро и удалить нерелевантные запросы. А можно облегчить себе задачу, воспользовавшись текстовым анализатором. Например, сервисом text.ru. Достаточно загрузить собранные ключи в поле и нажать на кнопку “SEO-анализ текста”. Вы увидите список слов, ранжированный по частоте. Наиболее часто встречающиеся слова — это и есть семантическое ядро. Те, что висят в самом хвосте — это мусор.
Шаг 5. Внедряем СЯ в структуру сайта
Ядро собрано, начинается самое интересное. Теперь нужно вставить полученные запросы в тексты на сайте.
Если вы когда-то встречали SEOшников, которые с пеной у рта доказывали, что ключей на странице должно быть как можно больше, а то и дотошный план составляли вроде 23 ключа таких, 33 ключа сяких, такой-то ключ во втором предложении и непременно в первом слове абзаца — забудьте как страшный сон. Такое SEO уже давным-давно не работает.
Все намного проще. Для одной страницы достаточно нескольких релевантных ключей. Важно понять логику: основные ключи вставляются в мета-теги title, description, заголовки H1, h2-h3, а остальные равномерно распределяются по тексту страницы.
Итак, начинаем с самого главного — страниц категорий и подкатегорий. Во-первых, вставляем ключи в теги Title и Description. Для этих тегов нужно выбирать ключи из самых популярных по частотности запросов. Чем частотнее — тем лучше.
Далее — тексты для страниц категорий. Огород городить не надо — достаточно написать 500-1000 символов с основной информацией. Вставляем высокочастотные ключи в название категории или товара (он же заголовок, он же тег H1). В шаблонах InSales в этот тег по умолчанию обрамляются названия страниц и товаров.
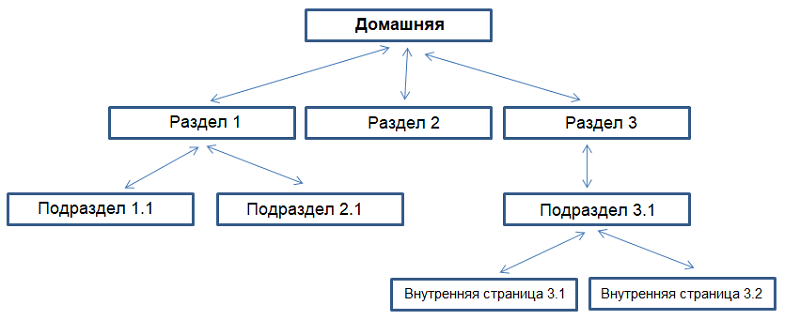
Простая структура сайта
В сам текст вставляем 2-3 ключа. И снова развенчаем миф: совсем не обязательно делать вхождения ключей “прямыми”, то есть прямо такими, как указано в ядре. В 2020 году можно изменять окончания, порядок слов, подстраиваться под человеческий язык. Можно и нужно.
То же самое проделываем с текстами страниц подкатегорий и карточек товаров. По тому же принципу: основные ключи — в мета-теги и заголовки, еще несколько — в тело текста. В карточках товара не забудьте добавить ключ в описание фотографии — тег Alt.
Шаг 6. Не забываем о логике
Запрос запросу рознь. Есть универсальные — например, “платье льняное белое” — его можно включить и в мета-тег, и в заголовок, и в текст карточки товара. Есть такие, которые надо вписывать в определенные страницы. Как правило, для них характерны дополнительные слова (купить, заказать, какой, как и так далее). Рассмотрим каждые.
Какие бывают виды запросов:
- коммерческие запросы — те, в которых встречаются слова “купить”, “заказать” и подобные. Такие запросы вставляйте в текст карточек товаров, на главную страницу, в мета-теги и подзаголовки описания категорий и подкатегорий;
- брендовые запросы — те, в которых встречается название бренда-производителя товаров. Поскольку люди часто вводят такие запросы в поиск, позаботьтесь, чтобы они тоже присутствовали в ваших текстах. Вот и еще один повод проанализировать ассортимент и дополнить его новыми брендами, найти новых поставщиков. Брендовые запросы включайте в соответствующие страницы — карточки товаров, подкатегории определенного бренда (“платье Зара”, “юбки Диор”);
- информационные запросы — те, в которых включены слова “как”, “где”, “какой” и другие. Тут сложнее: в мета-теги и названия категорий такие ключи не впишешь. Значит, надо подумать о создании блога, в котором вы будете давать пользователю полезную информацию и отвечать на поставленные запросы (“как правильно стирать вещи из шерсти”, “где купить аксессуары для одежды” и так далее). Подойдет также страничка FAQ (популярные вопросы и ответы). Если такого в вашем блоге не предусмотрено, включите эти запросы в тексты карточек товаров. Но постарайтесь давать на них исчерпывающую информацию, чтобы пользователь, ищущий ответ на вопрос, не ушел с вашего сайта ни с чем. В небольшом описании сделать это проблематично, поэтому мы советуем все же заняться контент-маркетингом и вести блог интернет-магазина;
- навигационные запросы — ключи с упоминанием конкретной модели товара или фирмы-производителя. Подойдут для текста карточек товара.
Если в СЯ есть запросы, которые вы затрудняетесь характеризовать и не знаете, куда вписать, поступайте просто. Создайте отдельную информационную страницу под этот запрос и смело отвечайте на поставленный вопрос.
Шаг 7. Меняем структуру (если нужно)
Этот шаг подойдет для тех, кто составлял СЯ уже после того, как создал структуру сайта. Мы уже писали про звоночки, которые помогут понять, нужно ли менять структуру. Итак, если в СЯ много запросов, под которые у вас нет категорий/подкатегорий/карточек — создавайте их. Дополняйте ассортимент, наполняйте каталог новыми товарами, пишите информационные статьи. Подгоняйте структуру под семантическое ядро, а не наоборот!
Теперь вы знаете, как составить семантическое ядро сайта и какими инструментами пользоваться. Удачи в продвижении!
Возможно вам также будет интересно:
Семантическое ядро – это фундамент любого сайта. Если вы хотите получить хороший, а главное целевой трафик на сайт, уделите разработке семантического ядра особое внимание.
В данной статье разберемся в тонкостях составления семантического ядра и рассмотрим особенности распределения ключей на сайте.
Что такое семантическое ядро?
Семантическое ядро (СЯ) – это упорядоченный набор слов, их морфологических форм и словосочетаний, которые наиболее точно характеризуют вид деятельности, товары или услуги, предлагаемые сайтом. Именно по этому набору слов вы и будете продвигать свой сайт.
На основе разработанного сем. ядра будет формироваться окончательная структура сайта: в зависимости от подобранных ключевых фраз станет понятно, какие новые страницы нужно добавить на сайт, а какие можно удалить.
Этапы разработки семантического ядра:
Шаг 1. Составление первичного списка запросов
На этапе необходимо собрать основные запросы по тематике сайта. Это можно сделать несколькими способами:
«Мозговой штурм» – самостоятельно или совместно с друзьями/коллегами выделяете 10-15 минут, чтобы сесть и записать все слова и фразы, по которым хотите, чтобы сайт находили.
Эти фразы должны включать:
- все варианты названия товара или услуги, синонимы, написание марки/брендов как на латинице, так и на кириллице;
- сокращенные названия;
- сленговые названия;
- названия составных частей товара или услуг. Например, строительные материалы – кирпич, цемент, гипсокартон, сухие смеси, герметики и т.д.;
- надежность товара или услуг (недорогой ремонт квартир, профессиональная юридическая консультация).
Анализ сайтов конкурентов – проанализируйте сайты конкурентов в поисковой выдаче по основным ключам (не забудьте отключить персональный поиск, смотрите в браузере в режиме инкогнито по своему региону). Выпишите из текстов конкурентов все слова, которые могут быть ключевыми. Собрать семантику конкурентов помогут специальные сервисы serpstat.com, bukvarix.com.
Анализ контекстной рекламы – определите, какие слова используют в рекламных объявлениях ваши конкуренты. Можно проанализировать как вручную, так и с помощью сервисов, таких как, spywords.ru, advodka.com.
Благодаря такому тщательному исследованию, вы получите довольно приличный список ключевых слов, необходимых для построения семантического ядра. Но чтобы не упустить и другие качественные запросы, необходимо расширить этот список. Переходим ко второму этапу работ по составлению сем.ядра.
Шаг 2. Расширение списка
Для этого можно использовать сервисы поисковых систем Яндекс.Вордстат, Google AdWords.
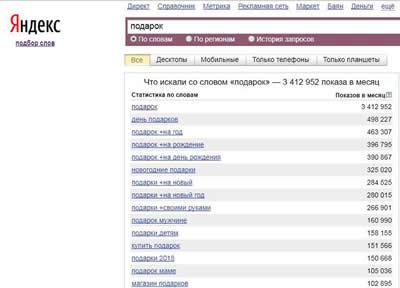
Поочередно вводя каждое слово первичного списка в строку поиска любого из этих сервисов, вы получите расширенный список уточнённых и ассоциативных запросов.
Уточнённые запросы – те, которые включают слово из вашего первичного запроса. Например, введя слово «подарок», вы обнаружите 200 запросов с этим словом, которые на самом деле вводили пользователи за прошедший месяц: «купить подарок», «подарок на день рождения», «подарок мужчине» и т.д.
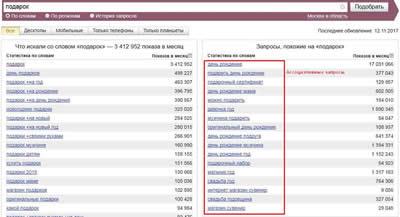
Ассоциативные запросы – те, которые пользователи вводили вместе с интересующим вас запросом. Например, пользователи, которые искали «подарок» вводили еще запросы: «подарить день рождение», «подарочный сертификат», «можно подарить», «подарочный набор» и т.д. Они тоже могут быть вам полезны.
Также при составлении семантических ядер будут полезны специальные программы KeyCollector, SlovoEB и онлайн-сервисы – Топвизор, serpstat.com и другие. Они помогут вам подобрать ключевые слова, а также провести анализ и группировку запросов.
Для расширения списка рекомендуем обратить внимание на Поисковые подсказки – самые популярные запросы, которые начинаются на те же буквы или слова, что и ваш запрос. Подробнее о данном методе сбора ключевых слов читайте в нашей статье.
Эти методы помогут вам получить полный список запросов, который теперь необходимо «почистить».
Шаг 3. Зачистка
Несколько слов о классификации поисковых запросов.
Ключевые запросы принято классифицировать по нескольким признакам. Предлагаем рассмотреть типы запросов по частоте и по цели.
По частоте запросов можно выделить 3 основных категории:
- высокочастотные (свыше 1500 запросов в месяц);
- среднечастотные (от 600 до 1500 запросов в месяц);
- низкочастотные (100-200 запросов в месяц).
Сразу отмечу, что в зависимости от тематики сайта, эти показатели могут меняться.
Существует тенденция, с каждым годом показатель низкочастотных запросов пользователей увеличивается, сегодня средняя длина запроса составляет – около 5 слов.
Это говорит о том, что для продвижения сайта следует делать упор на среднечастотные и низкочастотные ключи. Они менее конкуренты, а значит, попасть в топ будет гораздо легче, чем продвигаться по ВЧ запросам. Кроме того, поисковики все чаще отдают предпочтение сайтам, которые продвигаются по НЧ ключам.
Кроме частоты, поисковые запросы классифицируют по цели поиска:
- Информационные – запросы, которые ищут пользователи для нахождения какой-либо информации. Вот несколько примеров: «как построить дом самостоятельно», «какие материалы нужны для укладки пола».
- Транзакционные – запросы, которые пользователи ищут, когда хотят совершить какое-либо действие (в большинстве своем это коммерческие запросы: купить, заказать, скачать и пр.). Примеры: «купить доску», «заказать пиломатериалы».
- Витальные запросы – поисковые фразы, которые вводятся пользователями для поиска определенного сайта (например, 1PS, М.Видео, Сбербанк и др.). Примеры: «продвижение сайта в 1PS», «онлайн Сбербанк», «купить телефон в М.Видео».
- Прочие (общие) запросы. Это ключевые слова, по которым сложно определить, что именно хочет найти пользователь. Например, запрос «книга» пользователь может ввести, если желает скачать книгу, прочитать онлайн или купить на сайте.
С классификацией разобрались, теперь самое время приступить к отсеиванию лишних запросов, по которым не имеет смысла продвигаться. Рекомендуем удалить ключевые слова:
- которые не соответствуют тематике сайта;
- с упоминанием конкурирующих брендов;
- с упоминанием других регионов (например, купить строительные материалы в СПб, если вы продвигаетесь только по Москве);
- с ошибками или опечатками (поисковики понимают, когда вы пишите мантаж, а не монтаж и учитывают это).
Определение конкурентности запросов
Для правильного распределения запросов на сайте нужно отранжировать их по значимости. В этом вам поможет индекс KEI (индекс эффективности ключевых слов).
Рассчитать KEI можно по следующей формуле: KEI = P2/C, где P – это частота показов за последний месяц, а С – количество сайтов, которое оптимизировано под эту ключевую фразу.
Таким образом, чем больше популярность, тем больше KEI, тем больше трафика по ключевой фразе вы получите, тем интересней она вам. Чем больше конкуренции, тем меньше KEI, тем сложнее будет продвинуться в топ, тем менее интересна для вас данная ключевая фраза. Т.е. с ростом популярности KEI тоже растет, с ростом конкуренции KEI падает.
Существует и более простой вариант этой формулы: KEI = P2/U, где вместо С используют показатель U – количество страниц, которое оптимизировано под данный запрос.
Чтобы наглядно представить, как работает эта формула, приведу пример:
Для определения частоты запросов в месяц обратимся к сервису Яндекс Wordstat:
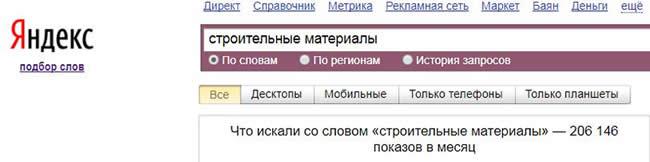
Далее проверим число страниц в поисковой выдаче по запросу «строительные материалы».
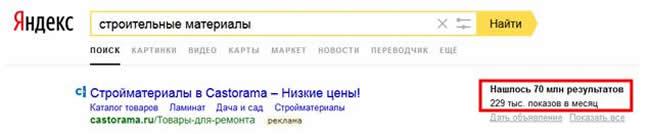
Рассчитаем индекс эффективности ключевых слов:
P = 206 146
U = 70 000 000
KEI = (206 146*206 146)/70 000 000 = 607 (результат округлили до целого числа)
Шкала оценки KEI:
KEI до 10 – плохие ключевые фразы.
KEI от 10 до 100 – хорошие ключевые фразы, с наличием трафика.
KEI от 100 до 400 – отличные ключевые фразы, которые позволяют получать значительную долю трафика.
KEI больше 400 – ключевые фразы высшей категории с мега-порциями трафика и большим количеством аудитории.
Таким методом следует определить индекс эффективности для всех ключевых слов из вашего списка. Основываясь на полученных результатах индекса, вы можете приступать к распределению запросов постранично.
Обратите внимание, показатель KEI в большей мере зависит от тематики сайта, поэтому для некоторых тематик KEI>400 слишком мал. А для узкотематических сайтов применять данную шкалу не имеет смысла.
Группировка ключевых слов на сайте
Кластеризация ключевых слов или разбивка ключей на группы с точки зрения логики и на основе выдачи поисковых систем – очень трудоемкий процесс, особенно, если семантика подобрана для большого сайта. Для группировки поисковых запросов необходимо хорошо знать специфику бизнеса. Для облегчения работы есть сервисы, которые производят автоматическую кластеризацию ключевых слов на основе анализа ТОП-10 поисковой выдачи – Топвизор, Seranking.ru и др. Но после автоматической группировки фраз, советуем просмотреть получившиеся группы и вручную, при необходимости, внести правки, так как логика может не всегда учитываться машинами. После распределения запросов на группы вы получите, по сути, готовую структуру сайта – станет понятно, какие новые страницы можно создать на сайте, а какие удалить.
И еще 4 FAQ по семантическому ядру
- Сколько ключей должно входить в СЯ (100? 1000? 100000?).
Сказать, какое количество ключевых запросов должно быть задействовано для продвижения, сложно, так как каждый сайт индивидуален. Объем семантического ядра зависит от тематики сайта, его структуры, а также конкурентов.
- Можно ли пользоваться готовыми базами ключей?
В Сети представлено множество готовых источников семантики, например База Пастухова, UP Base, Мутаген, KeyBooster и др.
Подобные базы содержат огромный архив ключевых запросов и будут полезны для продвижения крупных проектов. Пользоваться такими базами можно, но необходимо проверять их на актуальность и конкурентность. Нужно понимать, что этими базами пользуются и другие владельцы сайтов, а значит, конкурентов у вас будет больше. Кроме того, в готовом семантическом ядре могут быть упущены важные для вас запросы.
- Как использовать семантическое ядро.
На основе отобранных ключей семантического ядра разрабатывают карту релевантности, которая включает теги title, description и заголовки h1-h6, необходимые для продвижения сайта. О том, как правильно составить карту релевантности, можно прочитать в нашей статье.
Ключевые запросы из семантического ядра также необходимы для написания оптимизированных текстов.
- Можно ли в семантическом ядре использовать запросы с нулевой частотой?
Да, можно в тех случаях, когда:
- для получения страниц с ключевыми словами с нулевой частотой будет затрачено минимум усилий (автоматическая генерация страниц), к примеру, страницы SEO фильтров у интернет-магазинов;
- ключевые слова с неабсолютным нулем: на момент проверки 0, но при этом в истории запросов присутствуют запросы по данной ключевой фразе;
- ключевые слова с 0 по вашему региону, но при этом в других регионах присутствуют более частотные запросы.
В заключение
Если вы решили оптимизировать ваш сайт или создать новый ресурс с нуля, то материал данной статьи как раз кстати. А если разработка семантического ядра слишком сложная задача для вас, обращайтесь! Соберем правильное семантическое ядро, которое будет эффективно работать. Просто напишите про свой проект, сориентируем по стоимости.