Указатель команд (инструкций)
(IP
– Instruction
Pointer)
Хранит
относительный адрес, по которому в RAM
находится инструкция, следующая за
исполняемой. Фактически этот регистр
«следит» за ходом выполнения программы.
Наращивание адреса выполняет CPU,
в зависимости от длины текущей команды.
Значение, хранящееся в IP,
может изменяться в зависимости от
структуры программы. Команды условных
и безусловных переходов, циклов, вызова
подпрограмм и т.д. изменяют содержимое
IP,
осуществляя переходы к требуемой точке
команды. Разрядность регистра IP
— 16 бит.
Регистры указатели
К
ним относятся индексные
регистры:
SI
– Source (Источник)
DI
– Destination (Приемник)
Используются
в основном при перемещении цепочек
данных (многобайтных последовательностей
произвольной длины), но могут использоваться
и произвольным образом. Основное
их назначение – хранить индексы
(смещения) относительно некоторой базы,
(т.е., начала массива) при выборке операндов
из памяти.
Регистр
SI
– регистр индекса источника (source
index
register).
Он содержит относительный адрес начала
цепочки, которую следует переместить.
Регистр
DI
– регистр индекса приемника (destination
index
register).
Содержит относительный адрес, по которому
нужно переместить цепочку. Число
перемещаемых байт обычно хранится в
регистре CX
(счетчике). Кроме
операций по перемещению цепочек данных,
индексные регистры используют и для
адресации внутри массивов числовых
данных. Адрес базы при этом может
находиться в базовых регистрах BX
или BP
(base
pointer).
Т.о., в этих регистрах хранится сегментная
часть адреса.
Указатель стека
(SP
– Stack
Pointer)
Используется
только как указатель вершины стека. В
любом случае регистры BP
и SP
используются для указания на начало
области памяти отведенной под стек,
т.к. BP
выступает как указатель базы при работе
с данными в стековой структуре.
Сегментные регистры
Эти
регистры используются только!
при работе с адресами. Это важнейшие
элементы в архитектуре CPU,
т.к. обеспечивают 20-ти разрядную адресацию
адресного пространства с помощью 16-ти
разрядных операндов.
CS
(Code
Segment
Register)
Регистр
сегмента кодов. В нем хранится начальный
адрес сегмента содержащего команды
(инструкции). В сочетании с регистром
IP
(счетчиком команд) образует полный адрес
текущей выполняемой инструкции.
DS
(Data
Segment
Register)
Регистр
сегмента данных. Обычно указывает начало
область памяти, отведенной под данные.
В сочетании с регистрами DI,
SI
или
BX
может использоваться для доступа к
определенным байтам или словам внутри
области данных.
SS
(Stack Segment Register)
Регистр
сегмента
стека.
В сочетании с
регистром SP
указывает на текущее хранимое в стеке
число. Может также использоваться и в
паре с регистром BP
при выполнении некоторых инструкций.
ES
(Extra
Segment
Register)
Регистр
дополнительного сегмента, отведенный
для нужд программиста. Обычно используется
в инструкциях по обработке цепочек.
Регистры
данных регистры-указатели
сегментные регистры
|
AH |
AL |
аккумулятор |
SI |
источник |
CS |
команд |
|
BH |
BL |
базовый |
DI |
приемник |
DS |
данных |
|
CH |
CL |
счетчик |
BP |
указ.базы |
ES |
дополн.дан. |
|
DH |
DL |
данных |
SP |
указ.стека |
SS |
стека |
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Указатель инструкции
Указатель инструкции содержит смещение в сегменте кода текущей исполняемой инструкции процессора. 16-разрядный регистр-указатель инструкции носит название IP, 32-разрядный — EIP, 64-разрядный — RIP.
В 64-разрядном режиме регистр RIP может также использоваться в качестве базового в инструкциях, чьи операнды расположены в памяти, и в командах перехода. В таком же качестве, но только для команд перехода, он может использоваться и в режиме совместимости.
Материалы сообщества доступны в соответствии с условиями лицензии CC-BY-SA, если не указано иное.
Разбираемся в С, изучая ассемблер
Время на прочтение
11 мин
Количество просмотров 84K
Перевод статьи Дэвида Альберта — Understanding C by learning assembly.
В прошлый раз Аллан О’Доннелл рассказывал о том, как изучать С используя GDB. Сегодня же я хочу показать, как использование GDB может помочь в понимании ассемблера.
Уровни абстракции — отличные инструменты для создания вещей, но иногда они могут стать преградой на пути обучения. Цель этого поста — убедить вас, что для твердого понимания C нужно также хорошо понимать ассемблерный код, который генерирует компилятор. Я сделаю это на примере дизассемблирования и разбора простой программы на С с помощью GDB, а затем мы используем GDB и приобретенные знания ассемблера для изучения того, как устроены статические локальные переменные в С.
Примечание автора: Весь код из этой статьи был скомпилирован на процессоре x86_64 под Mac OS X 10.8.1 с использованием Clang 4.0 с отключенной оптимизацией (-O0).
Изучаем ассемблер с помощью GDB
Давайте начнем с дизассемблирования программы с помощью GDB и научимся читать выходные данные. Наберите следующий текст программы и сохраните его в файле simple.c:
int main(void)
{
int a = 5;
int b = a + 6;
return 0;
}
Теперь скомпилируйте его в отладочном режиме и с отключенной оптимизацией и запустите GDB.
$ CFLAGS="-g -O0" make simple
cc -g -O0 simple.c -o simple
$ gdb simple
Поставьте точку останова на функции main и продолжайте выполнение до тех пор, пока не дойдете до оператора return. Введите число 2 после оператора next, чтобы указать, что мы хотим выполнить его дважды:
(gdb) break main
(gdb) run
(gdb) next 2
Теперь используйте команду disassemble, чтобы вывести ассемблерные инструкции текущей функции. Также можно передавать команде disassemble имя функции, чтобы указать другую функцию для исследования.
(gdb) disassemble
Dump of assembler code for function main:
0x0000000100000f50 <main+0>: push %rbp
0x0000000100000f51 <main+1>: mov %rsp,%rbp
0x0000000100000f54 <main+4>: mov $0x0,%eax
0x0000000100000f59 <main+9>: movl $0x0,-0x4(%rbp)
0x0000000100000f60 <main+16>: movl $0x5,-0x8(%rbp)
0x0000000100000f67 <main+23>: mov -0x8(%rbp),%ecx
0x0000000100000f6a <main+26>: add $0x6,%ecx
0x0000000100000f70 <main+32>: mov %ecx,-0xc(%rbp)
0x0000000100000f73 <main+35>: pop %rbp
0x0000000100000f74 <main+36>: retq
End of assembler dump.
По умолчанию команда disassemble выводит инструкции в синтаксисе AT&T, который совпадает с синтаксисом, используемым ассемблером GNU. Синтаксис AT&T имеет формат: mnemonic source, destination. Где mnemonic — это понятные человеку имена инструкций. А source и destination являются операндами, которые могут быть непосредственными значениями, регистрами, адресами памяти или метками. В свою очередь, непосредственные значения — это константы, они имеют префикс $. Например, $0x5 соответствует числу 5 в шестнадцатеричном представлении. Имена регистров записываются с префиксом %.
Регистры
На изучение регистров стоит потратить некоторое время. Регистры — это места хранения данных, которые находятся непосредственно на центральном процессоре. С некоторыми исключениями, размер или ширина регистров процессора определяет его архитектуру. Поэтому, если у вас есть 64-битный CPU, то его регистры будут иметь ширину в 64 бита. То же самое касается и 32-битных и 16-битных процессоров и т. д. Скорость доступа к регистрам очень высокая и именно из-за этого в них часто хранятся операнды арифметических и логических операций.
Семейство процессоров с архитектурой x86 имеет ряд специальных регистров и регистров общего назначения. Регистры общего назначения могут быть использованы для любых операций, и данные, хранящиеся в них, не имеют особого значения для процессора. С другой стороны, процессор в своей работе опирается на специальные регистры, и данные, которые хранятся в них, имеют определенное значение в зависимости от конкретного регистра. В нашем примере %eax и %ecx — регистры общего назначения, в то время как %rbp и %rsp — специальные регистры. Регистр %rbp — это указатель базы, который указывает на базу текущего стекового фрейма, а %rsp — указатель стека, который указывает на вершину текущего стекового фрейма. Регистр %rbp всегда имеет большее значение нежели %rsp, потому что стек всегда начинается со старшего адреса памяти и растет в сторону младших адресов. Если Вы не знакомы с понятием “стек вызовов”, то можете найти хорошее объяснение на Википедии.
Особенность процессоров семейства x86 в том, что они сохраняют полную совместимость с 16-битными процессорами 8086. В процессе перехода x86 архитектуры от 16-битной к 32-битной и в конце-концов к 64-битной, регистры были расширены и получили новые имена, чтобы сохранить совместимость с кодом, который был написан для более ранних процессоров.
Возьмем регистр общего назначения AX, который имеет ширину в 16 бит. Доступ к его старшему байту осуществляется по имени AH, а к младшему — по имени AL. Когда появился 32-битный 80386, расширенный (Extended) AX или EAX стал 32-битным регистром, в то время как AX остался 16-битным и стал младшей половиной регистра EAX. Аналогичным образом, когда появилась x86_64, то был использован префикс “R” и EAX стал младшей половиной 64-битного регистра RAX. Ниже приведена диаграмма, основанная на статье из Википедии, чтобы проиллюстрировать вышеописанные связи:
|__64__|__56__|__48__|__40__|__32__|__24__|__16__|__8___|
|__________________________RAX__________________________|
|xxxxxxxxxxxxxxxxxxxxxxxxxxx|____________EAX____________|
|xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx|_____AX______|
|xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx|__AH__|__AL__|
Назад к коду
Этого уже должно быть достаточно, чтобы перейти к разбору нашей дизассемблированой программы:
0x0000000100000f50 <main+0>: push %rbp
0x0000000100000f51 <main+1>: mov %rsp,%rbp
Первые две инструкции называются прологом функции или преамбулой. Первым делом записываем старый указатель базы в стек, чтобы сохранить его на будущее. Потом копируем значение указателя стека в указатель базы. После этого %rbp указывает на базовый сегмент стекового фрейма функции main.
0x0000000100000f54 <main+4>: mov $0x0,%eax
Эта инструкция копирует 0 в %eax. Соглашение о вызовах архитектуры x86 гласит, что возвращаемые функцией значения хранятся в регистре %eax, поэтому вышеуказанная инструкция предписывает нам вернуть 0 в конце нашей функции.
0x0000000100000f59 <main+9>: movl $0x0,-0x4(%rbp)
Здесь у нас то, с чем мы раньше не встречались: -0x4(%rbp). Круглые скобки дают нам понять, что это адрес памяти. В этом фрагменте %rbp, так называемый регистр базы, и -0x4, являющееся смещением. Это эквивалентно записи %rbp + -0x4. Поскольку стек растет вниз, то вычитание 4 из базового стекового фрейма перемещает нас к собственно текущему фрейму, где хранится локальная переменная. Это значит, что эта инструкция сохраняет 0 по адресу %rbp — 4. Мне потребовалось некоторое время, чтобы выяснить, для чего служит эта строчка, и как мне кажется Clang выделяет скрытую локальную переменную для неявно возвращаемого значения из функции main.
Вы также можете заметить, что mnemonic имеет суффикс l. Это означает, что операнд будет иметь тип long (32 бита для целых чисел). Другие возможные суффиксы — byte, short, word, quad, и ten. Если Вам попадется инструкция, не имеющая суффикса, то размер такой инструкции будет подразумеваться из размера регистра источника или регистра назначения. Например, в предыдущей строчке %eax имеет ширину 32 бита, поэтому инструкция mov на самом деле является movl.
0x0000000100000f60 <main+16>: movl $0x5,-0x8(%rbp)
Теперь мы переходим в самую сердцевину нашей тестовой программы. Приведенная строка ассемблера — это первая строка на С в функции main, и она помещает число 5 в следующий доступный слот локальной переменной (%rbp — 0x8), на 4 байта ниже от нашей предыдущей локальной переменной. Это местоположение переменной a. Мы можем использовать GDB, чтобы проверить это:
(gdb) x &a
0x7fff5fbff768: 0x00000005
(gdb) x $rbp - 8
0x7fff5fbff768: 0x00000005
Заметьте, что адрес памяти один и тот же. Также Вы можете обратить внимание, что GDB устанавливает переменные для наших регистров, поэтому, как и перед всеми переменными в GDB, перед их именем стоит префикс $, в то время как префикс % используется в ассемблере от AT&T.
0x0000000100000f67 <main+23>: mov -0x8(%rbp),%ecx
0x0000000100000f6a <main+26>: add $0x6,%ecx
0x0000000100000f70 <main+32>: mov %ecx,-0xc(%rbp)
Далее мы помещаем переменную a в %ecx, один из наших регистров общего назначения, добавляем к ней число 6 и сохраняем результат в %rbp — 0xc. Это вторая строчка функции main. Вы могли уже догадаться, что адрес %rbp — 0xc соответствует переменной b, что мы тоже можем проверить с помощью GDB:
(gdb) x &b
0x7fff5fbff764: 0x0000000b
(gdb) x $rbp - 0xc
0x7fff5fbff764: 0x0000000b
Остальное в функции main — это просто процесс уборки, который еще называют эпилогом.
0x0000000100000f73 <main+35>: pop %rbp
0x0000000100000f74 <main+36>: retq
Мы достаем старый указатель базы и помещаем его обратно в %rbp, а затем инструкция retq перебрасывает нас к адресу возвращения, который тоже хранится в стековом фрейме.
До этого момента мы использовали GDB для дизассемблирования небольшой программы на С, прошли через чтение синтаксиса ассемблера от AT&T и раскрыли тему регистров и операндов адресов памяти. Также мы использовали GDB для проверки места хранения локальных переменных по отношению к %rbp. Теперь используем приобретенные знания для объяснения принципов работы статических локальных переменных.
Разбираемся в статических локальных переменных
Статические локальные переменные — это очень классная особенность С. В двух словах, это локальные переменные, которые инициализируются один раз и сохраняют свое значение между вызовами функции, в которой были объявлены. Простой пример использования статических локальных переменных — это генератор в стиле Python. Вот один такой, который генерирует все натуральные числа вплоть до INT_MAX.
/* static.c */
#include <stdio.h>
int natural_generator()
{
int a = 1;
static int b = -1;
b += 1;
return a + b;
}
int main()
{
printf("%dn", natural_generator());
printf("%dn", natural_generator());
printf("%dn", natural_generator());
return 0;
}
Когда вы скомпилируете и запустите эту программу, то она выведет три первых натуральных числа:
$ CFLAGS="-g -O0" make static
cc -g -O0 static.c -o static
$ ./static
1
2
3
Но как это работает? Чтобы это выяснить, перейдем в GDB и посмотрим на ассемблерный код. Я удалил адресную информацию, которую GDB добавляет в дизассемблерный вывод и теперь все помещается на экране:
$ gdb static
(gdb) break natural_generator
(gdb) run
(gdb) disassemble
Dump of assembler code for function natural_generator:
push %rbp
mov %rsp,%rbp
movl $0x1,-0x4(%rbp)
mov 0x177(%rip),%eax # 0x100001018 <natural_generator.b>
add $0x1,%eax
mov %eax,0x16c(%rip) # 0x100001018 <natural_generator.b>
mov -0x4(%rbp),%eax
add 0x163(%rip),%eax # 0x100001018 <natural_generator.b>
pop %rbp
retq
End of assembler dump.
Первое, что нам нужно сделать, это выяснить, на какой инструкции мы сейчас находимся. Сделать это мы можем путем изучения указателя инструкции или счетчика команды. Указатель инструкции — это регистр, который хранит адрес следующей инструкции. В архитектуре x86_64 этот регистр называется %rip. Мы можем получить доступ к указателю инструкции с помощью переменной $rip, или, как альтернативу, можем использовать архитектурно независимую переменную $pc:
(gdb) x/i $pc
0x100000e94 <natural_generator+4>: movl $0x1,-0x4(%rbp)
Указатель инструкции содержит указатель именно на следующую инструкцию для выполнения, что значит, что третья инструкция еще не была выполнена, но вот-вот будет.
Поскольку знать следующую инструкцию — это очень полезно, то мы заставим GDB показывать нам следующую инструкцию каждый раз, когда программа останавливается. В GDB 7.0 и выше, вы можете просто выполнить команду set disassemble-next-line on, которая показывает все инструкции, которые будут исполнены в следующей строке программного кода. Но я использую Mac OS X, который поставляется с версией GDB 6.3, так что мне придется пользоваться командой display. Эта команда аналогична x, за исключением того, что она показывает значение выражения после каждой остановки программы:
(gdb) display/i $pc
1: x/i $pc 0x100000e94 <natural_generator+4>: movl $0x1,-0x4(%rbp)
Теперь GDB настроен так, чтобы всегда показывать следующую инструкцию перед своим выводом.
Мы уже прошли пролог функции, который рассматривали ранее, поэтому начнем сразу с третьей инструкции. Она соответствует первой строке кода, которая присваивает 1 переменной a. Вместо команды next, которая переходит к следующей строчке кода, мы будем использовать nexti, которая переходит к следующей ассемблерной инструкции. Теперь исследуем адрес %rbp — 0x4, чтобы проверить гипотезу о том, что переменная a хранится именно здесь:
(gdb) nexti
7 b += 1;
1: x/i $pc mov 0x177(%rip),%eax # 0x100001018 <natural_generator.b>
(gdb) x $rbp - 0x4
0x7fff5fbff78c: 0x00000001
(gdb) x &a
0x7fff5fbff78c: 0x00000001
И мы видим, что адреса одинаковые, как мы и ожидали. Следующая инструкция более интересная:
mov 0x177(%rip),%eax # 0x100001018 <natural_generator.b>
Здесь мы ожидали увидеть выполнение инструкций строки static int b = -1;, но это выглядит существенно иначе, нежели то, с чем мы встречались раньше. С одной стороны, нет никаких ссылок на стековый фрейм, где мы ожидали увидеть локальные переменные. Нет даже -0x1! В место этого, у нас есть инструкция, которая загружает что-то из адреса 0x100001018, находящегося где-то после указателя инструкции, в регистр %eax. GDB дает нам полезный комментарий с результатом вычисления операнда памяти, чем подсказывает, что по этому адресу размещается natural_generator.b. Давайте выполним инструкцию и разберемся, что происходит:
(gdb) nexti
(gdb) p $rax
$3 = 4294967295
(gdb) p/x $rax
$5 = 0xffffffff
Несмотря на то, что дизассемблер показывает как получателя регистр %eax, мы выводим $rax, поскольку GDB задает переменные для полной ширины регистра.
В этой ситуации, мы должны помнить, что в то время как переменные имеют типы, которые определяют знаковые они или беззнаковые, регистры таких типов не имеют, поэтому GDB выводит значение регистра %rax как беззнаковое. Давайте попробуем еще раз, приведя значение %rax к знаковому целому:
(gdb) p (int)$rax
$11 = -1
Похоже на то, что мы нашли b. Можем повторно убедиться в этом, используя команду x:
(gdb) x/d 0x100001018
0x100001018 <natural_generator.b>: -1
(gdb) x/d &b
0x100001018 <natural_generator.b>: -1
Так что переменная b не только хранится в другом участке памяти, вне стека, но и к тому же инициализируется значением -1 еще до того, как вызывается функция natural_generator. На самом деле, даже если вы дизассемблируете всю программу, то не найдете никакого кода, устанавливающего b в -1. Все это потому, что значение переменной b зашито в другой секции исполняемого файла нашей программы, и оно загружается в память вместе со всем машинным кодом загрузчиком операционной системы, когда процесс запущен.
С таким подходом, вещи начинают обретать смысл. После сохранения b в %eax, мы переходим к следующей строке кода, где мы увеличиваем b. Это соответствует следующим инструкциям:
add $0x1,%eax
mov %eax,0x16c(%rip) # 0x100001018 <natural_generator.b>
Здесь мы добавляем 1 к %eax и записываем результат обратно в память. Давайте выполним эти инструкции и посмотрим на результат:
(gdb) nexti 2
(gdb) x/d &b
0x100001018 <natural_generator.b>: 0
(gdb) p (int)$rax
$15 = 0
Следующие две инструкции отвечают за возвращение результата a + b:
mov -0x4(%rbp),%eax
add 0x163(%rip),%eax # 0x100001018 <natural_generator.b>
Здесь мы загружаем переменную a в %eax, а затем добавляем b. На данном этапе мы ожидаем, что в %eax хранится значение 1. Давайте проверим:
(gdb) nexti 2
(gdb) p $rax
$16 = 1
Регистр %eax используется для хранения значения, возвращаемого функцией natural_generator, и мы ожидаем на эпилог, который очистит стек и приведет к возвращению:
pop %rbp
retq
Мы разобрались, как переменная b инициализируется. Теперь давайте посмотрим, что происходит, когда функция natural_generator вызывается повторно:
(gdb) continue
Continuing.
1
Breakpoint 1, natural_generator () at static.c:5
5 int a = 1;
1: x/i $pc 0x100000e94 <natural_generator+4>: movl $0x1,-0x4(%rbp)
(gdb) x &b
0x100001018 <natural_generator.b>: 0
Поскольку переменная b не хранится на стеке с остальными переменными, она все еще 0 при повторном вызове natural_generator. Не важно сколько раз будет вызываться наш генератор, переменная b всегда будет сохранять свое предыдущее значение. Все это потому, что она хранится вне стека и инициализируется, когда загрузчик помещает программу в память, а не по какому-то из наших машинных кодов.
Заключение
Мы начали с разбора ассемблерных команд и научились дизассемблировать программу с помощью GDB. В последствии, мы разобрали, как работают статические локальные переменные, чего мы не смогли бы сделать без дизассемблирования исполняемого файла.
Мы провели много времени, чередуя чтение ассемблерных инструкций и проверки наших гипотез с помощью GBD. Это может показаться скучным, но есть веская причина для следующего подхода: лучший способ изучить что-то абстрактное, это сделать его более конкретным, а один из лучших способов сделать что-то более конкретным — это использовать инструменты, которые помогут заглянуть за слои абстракции. Лучший способ изучить эти инструменты — это заставлять себя использовать их, пока это не станет для вас обыденностью.
От переводчика: Низкоуровневое программирование — не мой профиль, поэтому если допустил какие-то неточности, буду рад узнать о них в ЛС.
Processor operations mostly involve processing data. This data can be stored in memory and accessed from thereon. However, reading data from and storing data into memory slows down the processor, as it involves complicated processes of sending the data request across the control bus and into the memory storage unit and getting the data through the same channel.
To speed up the processor operations, the processor includes some internal memory storage locations, called registers.
The registers store data elements for processing without having to access the memory. A limited number of registers are built into the processor chip.
Processor Registers
There are ten 32-bit and six 16-bit processor registers in IA-32 architecture. The registers are grouped into three categories −
- General registers,
- Control registers, and
- Segment registers.
The general registers are further divided into the following groups −
- Data registers,
- Pointer registers, and
- Index registers.
Data Registers
Four 32-bit data registers are used for arithmetic, logical, and other operations. These 32-bit registers can be used in three ways −
-
As complete 32-bit data registers: EAX, EBX, ECX, EDX.
-
Lower halves of the 32-bit registers can be used as four 16-bit data registers: AX, BX, CX and DX.
-
Lower and higher halves of the above-mentioned four 16-bit registers can be used as eight 8-bit data registers: AH, AL, BH, BL, CH, CL, DH, and DL.
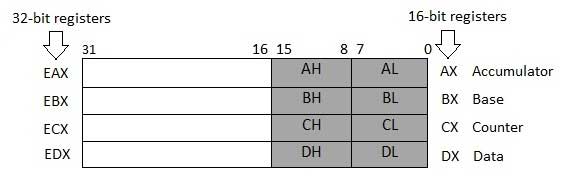
Some of these data registers have specific use in arithmetical operations.
AX is the primary accumulator; it is used in input/output and most arithmetic instructions. For example, in multiplication operation, one operand is stored in EAX or AX or AL register according to the size of the operand.
BX is known as the base register, as it could be used in indexed addressing.
CX is known as the count register, as the ECX, CX registers store the loop count in iterative operations.
DX is known as the data register. It is also used in input/output operations. It is also used with AX register along with DX for multiply and divide operations involving large values.
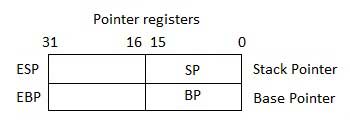
Pointer Registers
The pointer registers are 32-bit EIP, ESP, and EBP registers and corresponding 16-bit right portions IP, SP, and BP. There are three categories of pointer registers −
-
Instruction Pointer (IP) − The 16-bit IP register stores the offset address of the next instruction to be executed. IP in association with the CS register (as CS:IP) gives the complete address of the current instruction in the code segment.
-
Stack Pointer (SP) − The 16-bit SP register provides the offset value within the program stack. SP in association with the SS register (SS:SP) refers to be current position of data or address within the program stack.
-
Base Pointer (BP) − The 16-bit BP register mainly helps in referencing the parameter variables passed to a subroutine. The address in SS register is combined with the offset in BP to get the location of the parameter. BP can also be combined with DI and SI as base register for special addressing.
Index Registers
The 32-bit index registers, ESI and EDI, and their 16-bit rightmost portions. SI and DI, are used for indexed addressing and sometimes used in addition and subtraction. There are two sets of index pointers −
-
Source Index (SI) − It is used as source index for string operations.
-
Destination Index (DI) − It is used as destination index for string operations.

Control Registers
The 32-bit instruction pointer register and the 32-bit flags register combined are considered as the control registers.
Many instructions involve comparisons and mathematical calculations and change the status of the flags and some other conditional instructions test the value of these status flags to take the control flow to other location.
The common flag bits are:
-
Overflow Flag (OF) − It indicates the overflow of a high-order bit (leftmost bit) of data after a signed arithmetic operation.
-
Direction Flag (DF) − It determines left or right direction for moving or comparing string data. When the DF value is 0, the string operation takes left-to-right direction and when the value is set to 1, the string operation takes right-to-left direction.
-
Interrupt Flag (IF) − It determines whether the external interrupts like keyboard entry, etc., are to be ignored or processed. It disables the external interrupt when the value is 0 and enables interrupts when set to 1.
-
Trap Flag (TF) − It allows setting the operation of the processor in single-step mode. The DEBUG program we used sets the trap flag, so we could step through the execution one instruction at a time.
-
Sign Flag (SF) − It shows the sign of the result of an arithmetic operation. This flag is set according to the sign of a data item following the arithmetic operation. The sign is indicated by the high-order of leftmost bit. A positive result clears the value of SF to 0 and negative result sets it to 1.
-
Zero Flag (ZF) − It indicates the result of an arithmetic or comparison operation. A nonzero result clears the zero flag to 0, and a zero result sets it to 1.
-
Auxiliary Carry Flag (AF) − It contains the carry from bit 3 to bit 4 following an arithmetic operation; used for specialized arithmetic. The AF is set when a 1-byte arithmetic operation causes a carry from bit 3 into bit 4.
-
Parity Flag (PF) − It indicates the total number of 1-bits in the result obtained from an arithmetic operation. An even number of 1-bits clears the parity flag to 0 and an odd number of 1-bits sets the parity flag to 1.
-
Carry Flag (CF) − It contains the carry of 0 or 1 from a high-order bit (leftmost) after an arithmetic operation. It also stores the contents of last bit of a shift or rotate operation.
The following table indicates the position of flag bits in the 16-bit Flags register:
| Flag: | O | D | I | T | S | Z | A | P | C | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bit no: | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Segment Registers
Segments are specific areas defined in a program for containing data, code and stack. There are three main segments −
-
Code Segment − It contains all the instructions to be executed. A 16-bit Code Segment register or CS register stores the starting address of the code segment.
-
Data Segment − It contains data, constants and work areas. A 16-bit Data Segment register or DS register stores the starting address of the data segment.
-
Stack Segment − It contains data and return addresses of procedures or subroutines. It is implemented as a ‘stack’ data structure. The Stack Segment register or SS register stores the starting address of the stack.
Apart from the DS, CS and SS registers, there are other extra segment registers — ES (extra segment), FS and GS, which provide additional segments for storing data.
In assembly programming, a program needs to access the memory locations. All memory locations within a segment are relative to the starting address of the segment. A segment begins in an address evenly divisible by 16 or hexadecimal 10. So, the rightmost hex digit in all such memory addresses is 0, which is not generally stored in the segment registers.
The segment registers stores the starting addresses of a segment. To get the exact location of data or instruction within a segment, an offset value (or displacement) is required. To reference any memory location in a segment, the processor combines the segment address in the segment register with the offset value of the location.
Example
Look at the following simple program to understand the use of registers in assembly programming. This program displays 9 stars on the screen along with a simple message −
section .text global _start ;must be declared for linker (gcc) _start: ;tell linker entry point mov edx,len ;message length mov ecx,msg ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov edx,9 ;message length mov ecx,s2 ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data msg db 'Displaying 9 stars',0xa ;a message len equ $ - msg ;length of message s2 times 9 db '*'
When the above code is compiled and executed, it produces the following result −
Displaying 9 stars *********
Операции процессора в основном связаны с обработкой данных. Эти данные могут быть сохранены в памяти и доступны оттуда. Однако чтение данных из памяти и ее сохранение в памяти замедляет процессор, поскольку включает сложные процессы отправки запроса данных через шину управления и в блок хранения памяти и получения данных по одному и тому же каналу.
Чтобы ускорить работу процессора, процессор включает в себя несколько мест хранения внутренней памяти, называемых регистрами .
Регистры хранят элементы данных для обработки без необходимости доступа к памяти. Ограниченное количество регистров встроено в чип процессора.
Регистры процессора
В архитектуре IA-32 имеется десять 32-разрядных и шесть 16-разрядных процессорных регистров. Регистры сгруппированы в три категории –
- Общие регистры,
- Регистры управления и
- Сегментные регистры.
Общие регистры далее делятся на следующие группы –
- Регистры данных,
- Регистры указателя и
- Индексные регистры.
Регистры данных
Четыре 32-битных регистра данных используются для арифметических, логических и других операций. Эти 32-битные регистры можно использовать тремя способами:
-
Как полные 32-битные регистры данных: EAX, EBX, ECX, EDX.
-
Нижние половины 32-битных регистров могут использоваться как четыре 16-битных регистра данных: AX, BX, CX и DX.
-
Нижняя и верхняя половины вышеупомянутых четырех 16-битных регистров могут использоваться как восемь 8-битных регистров данных: AH, AL, BH, BL, CH, CL, DH и DL.
Как полные 32-битные регистры данных: EAX, EBX, ECX, EDX.
Нижние половины 32-битных регистров могут использоваться как четыре 16-битных регистра данных: AX, BX, CX и DX.
Нижняя и верхняя половины вышеупомянутых четырех 16-битных регистров могут использоваться как восемь 8-битных регистров данных: AH, AL, BH, BL, CH, CL, DH и DL.
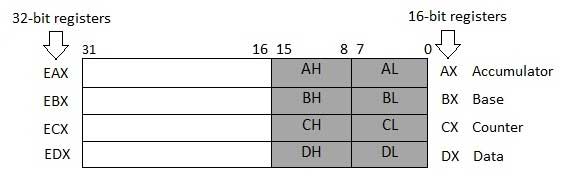
Некоторые из этих регистров данных имеют конкретное применение в арифметических операциях.
AX – основной аккумулятор ; он используется во вводе / выводе и большинстве арифметических инструкций. Например, в операции умножения один операнд сохраняется в регистре EAX или AX или AL в соответствии с размером операнда.
BX известен как базовый регистр , поскольку его можно использовать при индексированной адресации.
CX известен как регистр подсчета , так как регистры ECX, CX хранят счетчик циклов в итерационных операциях.
DX известен как регистр данных . Он также используется в операциях ввода / вывода. Он также используется с регистром AX вместе с DX для операций умножения и деления, связанных с большими значениями.
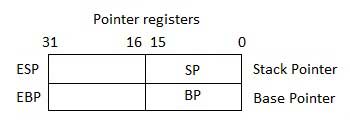
Регистры указателя
Регистры указателя являются 32-разрядными регистрами EIP, ESP и EBP и соответствующими 16-разрядными правыми частями IP, SP и BP. Есть три категории регистров указателей –
-
Указатель инструкций (IP) – 16-битный регистр IP хранит адрес смещения следующей команды, которая должна быть выполнена. IP вместе с регистром CS (как CS: IP) дает полный адрес текущей инструкции в сегменте кода.
-
Указатель стека (SP) – 16-разрядный регистр SP обеспечивает значение смещения в программном стеке. SP в сочетании с регистром SS (SS: SP) относится к текущей позиции данных или адреса в программном стеке.
-
Базовый указатель (BP) – 16-битный регистр BP в основном помогает ссылаться на переменные параметра, передаваемые подпрограмме. Адрес в регистре SS объединяется со смещением в BP, чтобы получить местоположение параметра. BP также можно комбинировать с DI и SI в качестве базового регистра для специальной адресации.
Указатель инструкций (IP) – 16-битный регистр IP хранит адрес смещения следующей команды, которая должна быть выполнена. IP вместе с регистром CS (как CS: IP) дает полный адрес текущей инструкции в сегменте кода.
Указатель стека (SP) – 16-разрядный регистр SP обеспечивает значение смещения в программном стеке. SP в сочетании с регистром SS (SS: SP) относится к текущей позиции данных или адреса в программном стеке.
Базовый указатель (BP) – 16-битный регистр BP в основном помогает ссылаться на переменные параметра, передаваемые подпрограмме. Адрес в регистре SS объединяется со смещением в BP, чтобы получить местоположение параметра. BP также можно комбинировать с DI и SI в качестве базового регистра для специальной адресации.
Индексные регистры
32-разрядные индексные регистры ESI и EDI и их 16-разрядные крайние правые части. SI и DI, используются для индексированной адресации и иногда используются для сложения и вычитания. Есть два набора указателей индекса –
-
Исходный индекс (SI) – используется в качестве исходного индекса для строковых операций.
-
Указатель назначения (DI) – используется как указатель назначения для строковых операций.
Исходный индекс (SI) – используется в качестве исходного индекса для строковых операций.
Указатель назначения (DI) – используется как указатель назначения для строковых операций.

Регистры управления
Регистр указателя 32-битной инструкции и регистр 32-битных флагов рассматриваются как регистры управления.
Многие инструкции включают сравнения и математические вычисления и изменяют состояние флагов, а некоторые другие условные инструкции проверяют значение этих флагов состояния, чтобы перенести поток управления в другое место.
Общие биты флага:
-
Флаг переполнения (OF) – указывает на переполнение старшего бита (крайнего левого бита) данных после арифметической операции со знаком.
-
Флаг направления (DF) – определяет направление влево или вправо для перемещения или сравнения строковых данных. Когда значение DF равно 0, строковая операция принимает направление слева направо, а когда значение равно 1, строковая операция принимает направление справа налево.
-
Флаг прерывания (IF) – определяет, будут ли игнорироваться или обрабатываться внешние прерывания, такие как ввод с клавиатуры и т. Д. Он отключает внешнее прерывание, когда значение равно 0, и разрешает прерывания, когда установлено значение 1.
-
Trap Flag (TF) – позволяет настроить работу процессора в одношаговом режиме. Программа DEBUG, которую мы использовали, устанавливает флаг прерывания, чтобы мы могли выполнять выполнение одной инструкции за раз.
-
Флаг знака (SF) – показывает знак результата арифметической операции. Этот флаг устанавливается в соответствии со знаком элемента данных после арифметической операции. Знак указывается старшим левым битом. Положительный результат очищает значение SF до 0, а отрицательный результат устанавливает его в 1.
-
Нулевой флаг (ZF) – указывает результат арифметической операции или операции сравнения. Ненулевой результат очищает нулевой флаг до 0, а нулевой результат устанавливает его в 1.
-
Вспомогательный флаг переноса (AF) – содержит перенос с бита 3 на бит 4 после арифметической операции; используется для специализированной арифметики. AF устанавливается, когда 1-байтовая арифметическая операция вызывает перенос из бита 3 в бит 4.
-
Флаг четности (PF) – указывает общее количество 1-битов в результате, полученном в результате арифметической операции. Чётное число 1-бит очищает флаг четности до 0, а нечетное число 1-бит устанавливает флаг четности в 1.
-
Флаг переноса (CF) – содержит перенос 0 или 1 из старшего бита (крайнего слева) после арифметической операции. Он также хранит содержимое последнего бита операции сдвига или поворота .
Флаг переполнения (OF) – указывает на переполнение старшего бита (крайнего левого бита) данных после арифметической операции со знаком.
Флаг направления (DF) – определяет направление влево или вправо для перемещения или сравнения строковых данных. Когда значение DF равно 0, строковая операция принимает направление слева направо, а когда значение равно 1, строковая операция принимает направление справа налево.
Флаг прерывания (IF) – определяет, будут ли игнорироваться или обрабатываться внешние прерывания, такие как ввод с клавиатуры и т. Д. Он отключает внешнее прерывание, когда значение равно 0, и разрешает прерывания, когда установлено значение 1.
Trap Flag (TF) – позволяет настроить работу процессора в одношаговом режиме. Программа DEBUG, которую мы использовали, устанавливает флаг прерывания, чтобы мы могли выполнять выполнение одной инструкции за раз.
Флаг знака (SF) – показывает знак результата арифметической операции. Этот флаг устанавливается в соответствии со знаком элемента данных после арифметической операции. Знак указывается старшим левым битом. Положительный результат очищает значение SF до 0, а отрицательный результат устанавливает его в 1.
Нулевой флаг (ZF) – указывает результат арифметической операции или операции сравнения. Ненулевой результат очищает нулевой флаг до 0, а нулевой результат устанавливает его в 1.
Вспомогательный флаг переноса (AF) – содержит перенос с бита 3 на бит 4 после арифметической операции; используется для специализированной арифметики. AF устанавливается, когда 1-байтовая арифметическая операция вызывает перенос из бита 3 в бит 4.
Флаг четности (PF) – указывает общее количество 1-битов в результате, полученном в результате арифметической операции. Чётное число 1-бит очищает флаг четности до 0, а нечетное число 1-бит устанавливает флаг четности в 1.
Флаг переноса (CF) – содержит перенос 0 или 1 из старшего бита (крайнего слева) после арифметической операции. Он также хранит содержимое последнего бита операции сдвига или поворота .
В следующей таблице указано положение битов флага в 16-битном регистре флагов:
| Флаг: | О | D | я | T | S | Z | п | С | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Бит нет: | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Сегментные регистры
Сегменты – это определенные области, определенные в программе для хранения данных, кода и стека. Есть три основных сегмента –
-
Сегмент кода – содержит все инструкции, которые должны быть выполнены. 16-битный регистр сегмента кода или регистр CS хранит начальный адрес сегмента кода.
-
Сегмент данных – содержит данные, константы и рабочие области. 16-битный регистр сегмента данных или регистр DS хранит начальный адрес сегмента данных.
-
Сегмент стека – содержит данные и адреса возврата процедур или подпрограмм. Он реализован в виде структуры данных стека. Регистр сегмента стека или регистр SS хранит начальный адрес стека.
Сегмент кода – содержит все инструкции, которые должны быть выполнены. 16-битный регистр сегмента кода или регистр CS хранит начальный адрес сегмента кода.
Сегмент данных – содержит данные, константы и рабочие области. 16-битный регистр сегмента данных или регистр DS хранит начальный адрес сегмента данных.
Сегмент стека – содержит данные и адреса возврата процедур или подпрограмм. Он реализован в виде структуры данных стека. Регистр сегмента стека или регистр SS хранит начальный адрес стека.
Помимо регистров DS, CS и SS существуют и другие регистры дополнительных сегментов – ES (дополнительный сегмент), FS и GS, которые предоставляют дополнительные сегменты для хранения данных.
При программировании на ассемблере программе необходим доступ к ячейкам памяти. Все области памяти в сегменте относятся к начальному адресу сегмента. Сегмент начинается с адреса, равномерно делимого на 16 или шестнадцатеричного числа 10. Таким образом, крайняя правая шестнадцатеричная цифра во всех таких адресах памяти равна 0, что обычно не сохраняется в регистрах сегментов.
Сегментные регистры хранят начальные адреса сегмента. Чтобы получить точное местоположение данных или инструкции в сегменте, требуется значение смещения (или смещение). Чтобы сослаться на любую ячейку памяти в сегменте, процессор объединяет адрес сегмента в регистре сегмента со значением смещения местоположения.
пример
Посмотрите на следующую простую программу, чтобы понять использование регистров в программировании сборки. Эта программа отображает 9 звезд на экране вместе с простым сообщением –
Live Demo
section .text global _start ;must be declared for linker (gcc) _start: ;tell linker entry point mov edx,len ;message length mov ecx,msg ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov edx,9 ;message length mov ecx,s2 ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data msg db 'Displaying 9 stars',0xa ;a message len equ $ - msg ;length of message s2 times 9 db '*'
Когда приведенный выше код компилируется и выполняется, он дает следующий результат –
Ассемблер — язык программирования низкого уровня. Ниже него только машинный код (нули и единицы).
Зачем учить ассемблер?
- понимание функционирование компьютера. Любой программист должен знать Си. Любой программист, знающий Си — должен знать ассемблер.
- умение реверсить ПО (мы живем в копирастическом мире). Для меня это в первую очередь старинные игры 90-х годов, исходников к которым не сохранилось.
- ок. коммерческая разработка. Если у вашего устройства мало памяти. — вы пишете на асме. Микроконтроллеры, загрузчики, встраиваемое ПО. Если вам надо чтобы все работало быстрее молнии под конкретную систему — вы тоже пишете напрямую под процессор, это эффективнее.
- WebAssembly (wasm) 🙂 Это не язык программирования, а технология, которая сейчас захватывает веб. На ассемблере там писать не нужно, но для оптимизации кода понимание ассемблера может пригодится.
- Ну и анализ всякой вирусной дряни. Компьютерная безопасность и антивирусные лаборатории — вот где ассемблер идет только в путь.
Ассемблер — это семейство языков. Под разных архитектуры он отличается. Не пудрите себе мозг и сосредоточьтесь на х86 для начала — по нему больше всего инфы.
Что нужно знать, чтобы войти в асм? Умение прогать на Си и понимание двоичной и шестнадцатеричной системы исчисления. Хотя можно Си и не знать, а узнать в процессе.
Итак. Как устроен ПК? Есть:
CPU. RAM. Устройства ввода-вывода.
CPU (центральное обрабатывающее устройство — central processing unit), он же процессор, внутри имеет:
Управляющее устройство. Работает с RAM. Берет из памяти адреса на инструкции, которые сохраняет потом в регистрах.
Регистры. «Встроенная» память процессора, используемая для выполнения инструкций. Фактически, это маленькие ячейки памяти, которые располагаются на процессоре; с точки зрения программиста, можно сказать, что регистр — это временная переменная без типа данных, но определенного размера.
Не стоит путайте «регистры» с «кэшем процессора»,
который по сути является филиалом RAM,
находящимся поближе к «центру принятия решений»
и где хранятся данные, часто используемые процессором,
с целью все время не дергать основную оперативку.
АЛУ (арифметико-логическое устройство). Обрабатывает данные, хранящиеся в регистрах в соответствии с инструкциями. Потом сохраняет полученную информацию в регистры или RAM.
Суть кодинга на асме — взаимодействие с регистрами процессора, который в свою очередь взаимодействую со стеком. Есть разные архитектуры: x86 (десктоп), ARM (мобилки), AVR (микроконтроллеры), но мы пока будем изучать только х86.
Тут же стоит отметить, что есть много разных ассемблеров и для x86. Самый популярный для реверсинга игрушек — MASM (Microsoft Macro Assembler), хотя есть еще, например, NASM (Netwide Assembler). Мы будем изучать кондовый MASM.
Итак, мы знаем, что регистры — специальные ячейки памяти, расположенные непосредственно в процессоре.
Процессор читает команду (aka опкод aka инструкцию) из памяти себе в регистр и начинает ее выполнение. Пример команды:
MOV EAX, 15
Здесь MOV — опкод; EAX — регистр; 15 — значение, которое кладется в регистр
1) регистры общего назначения
2) регистры специального назначения
— указатель команд
— регистр флагов
— сегментные регистры
Даже в х86 регистров дофига, но учить наизусть их все не надо, достаточно разобраться лишь в нескольких (я отметил их красным на картинке).
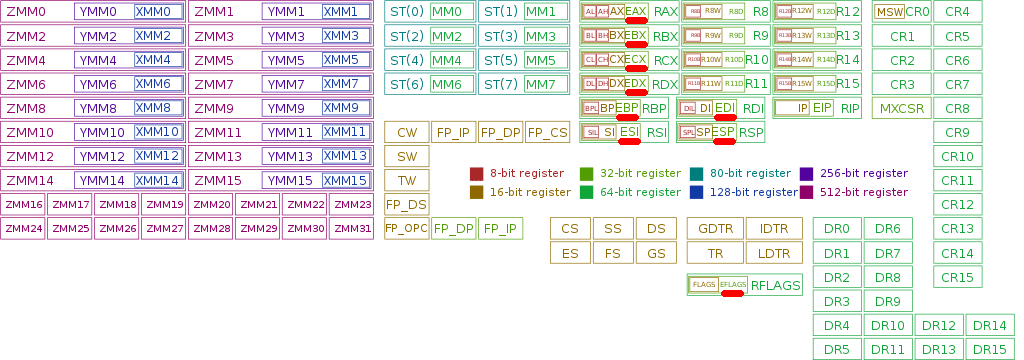
Указатель инструкции (Instruction pointer) — регистр где хранится указатель на инструкцию в стеке, которую нужно выполнить следующей; указывает её смещение (адрес) в сегменте кода. После выполнения, меняется на адрес следующей инструкции.
Далее… Регистры общего назначения aka Регистры данных. Их 8 штук; справа указано как их обычно кличут:
AX (accumulator register) — аккумулятор
BX (base register) — база (регистр базы)
CX (counter register) — счётчик
DX (data register) — регистр данных
SI (source index register) — индекс источника
DI (destination index register) — индекс приёмника (получателя)
SP (stack pointer register) — регистр указателя вершины стека (адрес самого последнего добавленного в стек элемента)
BP (base pointer register) — регистр указателя базы (адрес начала фрейма, начиная с которого в стек добавляются или извлекаются значения; его адрес всегда статичен)
Некоторые команды работают только с определёнными регистрами. Например, команды умножения и деления используют регистры EAX и EDX для хранения исходных данных и результата операции. Команды управления циклом используют регистр ECX в качестве счётчика цикла.
Регистры выше — 32битные, о чем говорит буква E начале. 64битные будет начинаться с R. Если в названии две буквы — регистр 16битный.
Регистр флагов:
EFLAGS — состояние процессора (флаг нуля, переноса и проч)
Флаги состояния (биты 0, 2, 4, 6, 7 и 11) — результат выполнения арифметических инструкций (ADD, SUB, MUL, DIV).
Флаг переноса CF (0) отмечает перенос/заём из старшего значащего бита и отмечает переполнение беззнаковых чисел. См. арифметику бинарных чисел. // Эт единственный флаг, который мы можем изменять напрямую (инструкции STC, CLC и CMC).
Флаг чётности PF ставится, когда младший значащий байт является чётным // младший — тот, что справа.
Вспомогательный флаг переноса AF ставится при переносе/заёме из бита 3-го результата.
Флаг нуля ZF становится 1, когда результат операции равен нулю.
Флаг знака SF равен значению старшего знакового бита.
Флаг переполнения OF (11) ставится, когда результат слишком длинный для размещения в регистре или ячейке памяти.
Управляющий флаг
Флаг направления DF (10) для уменьшения/увеличения адресов управляя строковыми инструкциями (MOVS, CMPS, SCAS, LODS, STOS). Чтобы установить/сбросить этот флаг — STD и CLD.
Комментарий на полях:
Так как я в первую очередь учу асм для «разбора» кода старинных игр, тут мне для дизасма требуется в том числе знание Windows API. В отличие от языка Си, где у нас есть int, short, long, singed/unsigned и проч. — Винда использует свои собственные типы, например, WORD — беззнаковое 16-битное значение, DWORD — 32-битное (линуксоиды негодуэ). В названии переменных обязательна «венгерская нотация»: имя переменной DWORD всегда будет начинаться с dw. Взаимодействие с ОС идет через «дескрипторы» — ссылки на участок памяти или объект (файл, процесс, окно, меню и проч); например, когда вы создаете окошко, вам выдается дескриптор HWND, на который вы будете в дальнейшем ссылатся, чтобы взаимодействовать с этим окошком. Дескрипторы отличаются от указателей тем, что не всегда дают адрес объекта и не используются в арифметике.
Про реестры понятно. Теперь поговорим о памяти, то бишь о стеке. Память компьютера (RAM) делится на 4 основных сегмента (в произвольном порядке):
- Статические данные — инициализируются при запуске программы и не изменяются в процессе выполнения. Также называются глобальными, т.к. доступны из любой части кода.
- Программный код. Инструкции, который выполняет процессор.
- Куча (heap) — динамическая память, где во время работы программы постоянно создаются и удаляются объекты (именно из кучи в Си мы выделяем память при помощи команды malloc() и освобождаем при помощи free().
- Стек временное хранилище для значений регистров процедур, локальных переменных и аргументов.
Проще говоря, Стек — область памяти программы для временного хранения каких-нибудь данных, чтобы их можно было быстро использовать и управлять потоком выполнения программы.
При вызове подпрограммы или возникновении прерывания, в стек заносится
адрес возврата — адрес в памяти следующей инструкции приостановленной программы и управление передается подпрограмме или подпрограмме-обработчику. Соответственно, стек отслеживает место, куда каждая из вызванных процедур должна вернуть управление после своего завершения.
Вики
Со стеком работает регистр ESP (и порой EBP). Есть три операции работы со стеком:
push — добавление элемента (процессор декрементирует значение в регистре ESP и записывает помещаемое значение на вершину стека).
pop — удаление элемента (процессор сначала копирует удаляемое значение с вершины стека, а затем уже инкрементирует значение в регистре ESP)
peek — чтение головного элемента.
Про них будет еще рассказано ниже.
Stack Pointer (SP) — указатель стека; регистр процессора, который указывает на адрес головы стека.
Важно! Не путайте Stack pointer
с Instruction pointer (см. выше).
Всего есть 3 типа указателей:
Instruction pointer, Stack pointer, Base Pointer.
Они разные 🙂
Предположим для примера, что голова стека расположена по меньшему адресу, следующие элементы располагаются по нарастающим адресам. При каждом вталкивании слова в стек SP сначала увеличивается на 1 и затем по адресу из SP производится запись в память. При каждом извлечении слова из стека (выталкивании) сначала производится чтение по текущему адресу из SP и последующее уменьшение содержимого SP на 1. Короче… Есть правило работы со стеком: процедура, которая вошла последней, должна первой из него выйти.
Еще раз вспоминаем базовый алгоритм: процессор читает команду (aka опкод aka инструкцию) из памяти себе в регистр и начинает ее выполнение.
Пройдемся по популярным инструкциям:
Инструкции работы со стеком
MOV — поместить значение в регистр. Пример команды:
MOV EAX, 15, где
MOV — опкод; EAX — регистр; 15 — значение, которое кладется в регистр.
PUSH поместить какие-либо данные на вершину стека. один “аргумент” — источник.
PUSH 21 значение в регистре SP уменьшится на машинное слово; по адресу будет записано 21
POP — берёт верхний элемент с вершина стека стека; при этом элемент из стека удаляется и возвращается нам. “аргументом” не может быть число. После POP надо написать в регистр/переменную (туда будет помещено значение из стека).
POP EAX забираем данные с вершины стека и кладем в регистр EAX
Инструкции перехода
JMP (jump) — прыгает из одного участка кода в другой по указанному адресу.
CALL — записывает в стек адрес возврата, а потом уже делает переход по указанному адресу (соотв. адрес возврата — адрес инструкции в стеке, следующей за командой CALL).
RET (return) — выполняет выход из программы или процедуры по адресу возврата, записанному ранее инструкцией CALL.
Математические инструкции
ADD сложение
ADD EAX, 15 (результат сложения кладется в EAX)
SUB вычитание. SUB по сути является инвертированной командой ADD (с отрицательным источником).
SUB EDX, ECX (результат кладется в EDX)
NEG меняет знак числа на противоположный и меняет флаги CF, ZF, SF, OF, AF, PF.
Умножение и деление в асме довольно долго разъяснять; поэтому просто приведу список, а вы уже сами погуглите мануалы:
MUL умножение беззнаковых чисел.
IMUL умножение чисел со знаком
DIV деление чисел без знака
IDIV деление чисел со знаком
Логические инструкции
AND побитовое логическое умножение
OR побитовое логическое сложение
XOR побитовое сложение по модулю два
CMP сравнение двух чисел
TEST сравнение через логическое умножение
NOT инвертирует каждый бит
Кстати, есть прикольный лайфхак, который зовется XOR-обмен (XOR swap algorithm). Он используется, чтобы поменять местами значения в регистрах и работает быстрее, чем xchg:
XOR AX, BX
XOR BX, AX
XOR AX, BX
Пример:
a = 0101; b = 1010.
a = a ^ b // 1111
b = a ^ b // 1111 ^ 1010 = 0101
a = a ^ b // 1111 ^ 0101 = 1010
Также XOR позволяет обнулить регистры, например, XOR EAX, EAX. По сути это аналог команды MOV EAX, 0 , но работает быстрее.
Типы данных в ассемблере
Типов данных как таковых нет. По сути есть только данные, записанные в двоичной системе. Т.е. там нет десятичных чисел, символов или строк. Но есть 5 директив определения данных:
Byte (DB — define byte) — определяет переменную размером в 8 бит (1 байт). Byte всегда занимает 8 бит; если там хранится число меньшего размера, остальные биты заменяются нулями. Максимальное значение: 255.
Word (DW — define word) — слово. Состоит из 16 бит (2 байта). Максимальное значение: 65 535
Double Word (DD — define double word) — двойное слово; 4 байта; 32 бита.
Quad Word (DQ — define quad word) — учетверённое слово; 8 байт; 64 бита.
Ten Byte (DT — define ten bytes) — 10 байт.
Синтаксис:
<имя> <тип> <операнд>, ... <операнд>, например
foo DB 1010011
Определить переменную foo размером 1 байт со значением 1010011, заданным в двоичной системе счисления.
Тоже самое в шестнадцатеричной системе: foo DB 53h
Десятичной: foo DB 83d
Тоже самое в виде строки (83 в ASCII соответствует символы S):
foo db 'S' ; заметим, что можно указывать тип как в верхнем (DB), так и нижнем (db) регистре.
Для строк используется тип данных Byte (DB). По сути, строки — это просто набор последовательных байтов, то бишь массив, например:
foo db 115d, 107d, 111d, 98d, 107d, 105d
это тоже самое, что и:
foo db 'skobki'
? дает задать неинициализированную переменную
foo dd ? — определить переменную в 4 байта
DUP дает заполнить элементы последовательности одинаковыми значениями
foo dd 9 dup (5) — определить массив из 10 двойных слов и инициализировать все элементы значением 5. Таким образом:
foo dd 9 dup (5) == foo dd 5,5,5,5,5,5,5,5,5
Можем сделать такой фокус:
foo dd 9 dup (?) — определить массив с 9 неинициализированными двойными словами.
Указатель исполняемой инструкции (регистр RIP)
Регистр указателя инструкции (RIP) содержит смещение в текущем сегменте кода для следующей инструкции, которая будет
выполняться. Его назначение в перемещении от одной инструкции к другой в прямолинейном коде или в перемещении вперёд или
назад на несколько инструкций при выполнении инструкций JMP, Jcc, CALL, RET и IRET.
Регистр RIP не может быть изменён программой. Он управляется исключительно инструкциями перемещения (такими как JMP,
Jcc, CALL и RET), прерываниями и исключениями. Единственным способом прочитать значение регистра является выполнение
инструкции CALL с последующим чтением значения указателя возврата из стека процедуры. Регистр RIP может быть изменён
косвенно, путём изменения значения указателя возврата в стеке процедуры и выполнения инструкции возврата (RET или IRET).
Поддержите проект, если он помог вам
Проект продвигается за счёт личных средств и времени авторского коллектива. Если вы нашли здесь то, что искали,
то вы можете выразить свою благодарность финансово. Даже небольшой платёж помогает авторам в их труде,
сохраняя их вовлечённость и высокую мотивацию чтобы строить открытый мир равных возможностей для всех
неравнодушных людей вокруг.