Orange — это инструмент для визуализации и анализа данных с открытым исходным кодом. Orange разрабатывается в лаборатории биоинформатики на факультете компьютерных и информационных наук Университета Любляны, Словения, вместе с сообществом открытого исходного кода.
Orange — это библиотека Python. Интеллектуальный анализ данных (Data mining) осуществляется с помощью визуального программирования или сценариев Python. Сценарии Python могут выполняться в окне терминала, интегрированных средах, таких как PyCharm и PythonWin, или оболочках, таких как iPython.
Категория — Data Mining Software.
Лицензия — Open Source.
Стоимость — бесплатно.
• Для всех — начинающих и профессионалов.
• Выполнить простой и сложный анализ данных.
• Создавайте красивую и интересную графику.
• Использование в лекции анализа данных.
• Доступ к внешним функциям для расширенного анализа.
Лучшая и отличительная черта Orange — это замечательные визуальные эффекты.
Этот инструмент содержит компоненты для машинного обучения, дополнения для биоинформатики и интеллектуального анализа текста, а также множество функций для анализа данных. Orange состоит из интерфейса Canvas, на который пользователь помещает виджеты и создает рабочий процесс анализа данных.
Виджеты предлагают базовые функции, такие как чтение данных, отображение таблицы данных, выбор функций, предикторы обучения, сравнение алгоритмов обучения, визуализация элементов данных и т. д. Пользователь может интерактивно исследовать визуализации или передавать выбранное подмножество в другие виджеты.
В Orange процесс анализа данных (Data mining) может быть разработан с помощью визуального программирования.
Orange запоминает выбор, предлагает часто используемые комбинации. Orange имеет функции для различных визуализаций, таких как диаграммы рассеяния, гистограммы, деревья, дендрограммы, сети и тепловые карты.
Комбинируя виджеты, создайте структуру аналитики данных. Существует более 100 виджетов с охватом большинства стандартных и специализированных задач анализа данных для биоинформатики.
Orange читает файлы в собственном и других форматах данных.
Классификация использует два типа объектов: ученики и классификаторы. Учащиеся рассматривают данные, помеченные классом, и возвращают классификатор.
Методы регрессии в Orange очень похожи на классификацию. Они предназначены для интеллектуального анализа данных (Data mining), помеченных классом.
Обучение базовых наборов обучающих данных включает прогнозы отдельных моделей, чтобы достичь максимальной точности.
Модели могут быть получены из разных выборок обучающих данных или могут использовать разных учеников в одних и тех же наборах данных.
Учащиеся также могут быть разнообразны, изменяя свои наборы параметров.
Чем Orange поможет SEO-специалисту:
• Анализ и визуализация данных при аудите своего сайта или сайтов конкурентов;
• Анализ ссылочного, выявление связей в группе сайтов;
• Интеллектуальный анализ текстового контента (text-mining).
• Кластеризация данных.
Настройка системы Orange для анализа данных
Orange поставляется со встроенным инструментом Anaconda, если вы его предварительно установили. Если нет, выполните следующие действия для загрузки Orange.
Шаг 1: Перейдите на https://orange.biolab.si и нажмите «Скачать».
Шаг 2: Установите платформу и установите рабочий каталог, в котором Orange будет хранить свои файлы.
Прежде чем углубимся в работу Orange, давайте определим ключевые термины, которые помогут в дальнейшем понимании:
Виджет — основная точка обработки любых действий с данными. Виджет выполняет действия в зависимости от того, что вы выберете в селекторе виджетов в левой части экрана.
Рабочий процесс — это последовательность шагов или действий, которые вы выполняете на платформе для решения задачи.
Перейдите к разделу «Примеры рабочих процессов» на начальном экране, чтобы изучить варианты дополнительных рабочих процессов и используемых моделей.
Создание первого рабочего процесса
Нажмите «New» и создайте первый рабочий процесс.
Это первый шаг на пути к решению любой задачи. Обдумайте, какие шаги необходимо предпринять для достижения конечной цели — алгоритм построения процесса.

Импорт данных в Orange
Шаг 1: Нажмите на вкладку «Data» в меню выбора виджетов и перетащите виджет «File» в пустой рабочий процесс.
Шаг 2: Дважды щёлкните виджет «File» и выберите файл с данными, который вы хотите загрузить в рабочий процесс.
Шаг 3: Как только вы сможете увидеть структуру набора данных с помощью виджета, вернитесь, закрыв это меню.
Шаг 4: Поскольку нам нужна таблица данных, чтобы лучше визуализировать наши результаты, мы нажимаем на виджет «Data Table».
Шаг 5. Теперь дважды щёлкните виджет, чтобы визуализировать таблицу.

Визуализация данных при помощи Orange
Виджет Scatter Plot один из самых популярных в среде Orange. Нажмите на полукруг перед виджетом «File», перетащите его в пустое место в рабочем процессе и выберите виджет «Scatter Plot».
Как только создадите виджет Scatter Plot, дважды щёлкните по нему и изучите данные. Вы можете выбрать оси X и Y, цвета, формы, размеры и другие настройки.

Экспериментируйте, добавляя или меняя виджеты в вашем рабочем процессе.
Это только первая (вводная) статья об интеллектуальном анализе данных (Data mining) с использованием Orange. В следующей статье рассмотрим пример использования Orange для поисковой оптимизации сайтов.
This is documentation for Orange 2.7. For the latest documentation,
see Orange 3.
Orange Documentation v2.7.8
- Orange Documentation
- Visual programming
- Python Scripting
- Development documentation
- Indices and tables
Visual programming¶
- Widget catalog
- Loading your data
- Tutorial with examples from functional genomics
Python Scripting¶
- Tutorial
- Reference
Development documentation¶
- Widget development manual
- Writing Extensions in C++
- Testing
- Wiki pages for developers
Indices and tables¶
- Index
- Module Index
- Search Page
Перевод
Ссылка на автора
Инструменты машинного обучения и визуализации данных с открытым исходным кодом для ускорения анализа данных без написания единого кода!

Сегодняшняя тема о выполнении простой визуализации данных с использованием программного обеспечения с открытым исходным кодом под названием Orange. Если вы ищете альтернативу для визуализации набора данных без кода, Orange — это правильный выбор для вас! Официальный Github Страница утверждает, что
Orange — это программное обеспечение для интеллектуального анализа данных. Он включает в себя ряд методов визуализации, исследования, предварительной обработки и моделирования данных. Его можно использовать через приятный и интуитивно понятный пользовательский интерфейс или, для более опытных пользователей, в качестве модуля для языка программирования Python.
Другими словами, Orange подходит как для новичков, так и для экспертов при решении задач по науке о данных. В этом уроке есть 3 раздела:
- Настройка и установка
- Виджеты
- Вывод
[Раздел 1] Настройка и установка
Прежде всего, существует множество способов установки Orange. Наиболее распространенные способы — через автономный установщик, Anaconda или Pip. Давайте посмотрим на каждого из них.
Автономный установщик (Windows, MacOS)
Перейти к следующему ссылка и выберите нужную операционную систему.

Нажать на «Скачать Orange», Чтобы начать загрузку. Как только это будет завершено, дважды щелкните по программе установки, чтобы установить ее.
Linux / Источник
Для Linux / Source нет установщика. Вы должны клонировать официальный репозиторий из GitHub или скачать архив с исходным кодом, После этого вы можете просто следовать инструкциям в README.md, Когда вы закончите, вы можете запустить Orange Canvas с помощью следующей команды:
python -m Orange.canvas
анаконда
Если у вас уже есть Anaconda, вы можете начать добавлять conda-forge к своим каналам с помощью следующей команды:
conda config --add channels conda-forge
Затем выполните следующую команду для установки оранжевого:
conda install orange3
GUI требует некоторых зависимостей, которые не включены или не предоставлены conda-forge. Давайте добавим их, набрав в терминале следующую команду и запустив ее:
conda install -c defaults pyqt=5 qt
Есть также дополнительные дополнения, которые можно установить:
conda install orange3-<addon name>
Кроме того, вы можете найти менеджер дополнений вОпциименю.
зернышко
Если вы решили использовать индекс пакетов Python, вам могут потребоваться дополнительные системные пакеты, предоставляемые вашим дистрибутивом. Возможно, вы захотите создать свою собственную виртуальную среду перед установкой Orange. Как только вы все настроите, выполните следующую команду:
pip install orange3
Точно так же вам нужно включить дополнительные зависимости для графического интерфейса:
pip install PyQt5 PyQtWebEngine
Давайте перейдем к следующему разделу, чтобы узнать больше об Orange.
[Раздел 2] Виджеты
Откройте Orange, и вы должны увидеть следующий пользовательский интерфейс:

Вы можете заметить, что панель инструментов находится слева, а белая рабочая область — холст. Панель инструментов содержит все виджеты, которые можно переместить на холст.

Есть 3 способа добавить виджет на холст:
- Дважды щелкните на виджете.
- Перетащите виджет на холст.
- Щелкните правой кнопкой мыши на холсте для меню виджета.

Файл и таблица данных
Вы можете соединить два виджета вместе, если они совместимы. Давай попробуем:

- Перетащитефайлвиджет для холста.
- ПеретащитеТаблица данныхвиджет для холста.
- На правой сторонефайлВиджет, есть полукруглая форма. Наведите курсор на него и перетащитеТаблица данныхвиджет.
- Обратите внимание, что есть связь между обоими виджетами со словомДанныенаверху.
- Не беспокойтесь об ошибке на верхней частифайлвиджет, так как нам еще предстоит загрузить данные.
На холсте дважды щелкните виджет «Файл», чтобы открыть его. Затем вы можете загрузить свой собственный набор данных или просмотреть его из пользовательского набора данных документации. Давайте попробуем это с iris.tab через пользовательский набор данных документации. Orange принимает любой из следующих форматов:
- Значение, разделенное табуляцией
- Значение через запятую
- Файл корзины
- Электронная таблица Microsoft Excel
- Маринованный апельсин
Вы должны увидеть следующий экран.

Как только вы закончите, закройте всплывающее окно, используя метку X в правом верхнем углу. Не пугайтесь, если вы заметили, чтоПодать заявлениекнопка серого цвета. Он предназначен для применения изменений после того, как вы изменили или отредактировалиТипилиРольданных. Затем дважды щелкните виджет «Таблица данных». Вы должны быть в состоянии увидеть набор данных. Вы можете проверить переменные слева, чтобы визуализировать числа. Вы должны увидеть следующий экран, как только вы проверили все параметры.

распределение
Вы можете легко визуализировать данные с помощью некоторых виджетов Visualize. Распределение является одним из лучших виджетов для определения важных функций для набора данных. Вы можете легко визуализировать, хорошо ли разделены наборы данных или нет Давайте продолжим с предыдущего шага.

- Перетащитераспределениевиджет для холста.
- Виджет Подключить файл краспределениевиджет.
- Дважды щелкните нараспределениевиджет, чтобы увидеть визуализацию.
- Вверху слева выберите другую переменную и проверьте результаты распределения.

Scatter Plot
Диаграмма рассеяния — это еще один виджет визуализации, который отображает оба объекта вместе для определения проекции между ними. Давайте проверим это!

- ПеретащитеScatter Plotвиджет в холст.
- Подключитефайлвиджет дляScatter Plotвиджет. Шаг похож на то, как это было дляраспределениевиджет.
- Дважды щелкните наScatter Plotвиджет, чтобы увидеть визуализацию.
- Вы можете изменить оси X и Y в зависимости от доступных функций.

Если вы не уверены, какие функции выбрать, нажмите «Найти информативные проекции», и вы увидите следующий интерфейс.

Нажмите «Пуск» и выберите любой элемент из списка. График разброса будет изменен в зависимости от вашего выбора.

FreeViz
Виджет FreeViz использует парадигму, заимствованную из физики элементарных частиц. Хотя точки не могут быть перемещены, но якоря являются подвижными. Это позволяет нам визуализировать функции, которые привлекают друг друга, и функции, которые отталкиваются друг от друга. Он поставляется с кнопкой оптимизации, которая выполняет оптимизацию при подъеме на гору, позволяя ей достичь равновесия. Прежде чем продолжить, давайте очистим некоторые виджеты, чтобы они были аккуратными и аккуратными. Есть два способа удалить виджеты:
- Щелкните правой кнопкой мыши на нем, и появится меню. Выберитеудалятьвариант. Вы также можете переименовать виджет таким образом или через ярлык F2.
- Выберите его левой кнопкой мыши и нажмите «удалять»На клавиатуре. Можно выбрать несколько виджетов и удалить их все вместе.

Когда вы закончите, продолжайте, следуя инструкциям ниже:

- ОставьтеFreeVizвиджет для холста.
- Connectфайлвиджет дляFreeVizвиджет.
- ОставьтеТаблица данныхвиджет для холста.
- ConnectFreeVizвиджет дляТаблица данныхвиджет.
Если вам интересно, почему мы подключаемсяТаблица данныхвиджет сFreeVizвиджет вместофайлвиджет. Причина в том, что вы можете выбрать точки данных в любом изВизуализируйтеинтерфейс виджета и выбранные точки будут выведены наТаблица данныхвиджет. Давайте посмотрим на следующий рисунок, чтобы узнать больше о том, как перемещать опорную точку и выбирать точки данных для интерфейса FreeViz.

Кроме того, вы можете продолжать нажимать кнопку оптимизации, пока она не достигнет равновесия. Вы можете использовать этот виджет, чтобы узнать больше об отношениях между функциями. Давайте посмотрим на следующий пример из официальной документации.

Просто сформировав взгляд, мы можем определить, что это:
- Живые существа, которые откладывают яйца, чаще имеют перья.
- Водные живые существа, скорее всего, имеют плавники.
- Живые существа, которые производят молоко, чаще имеют волосы.
- Живые существа, которые откладывают яйца, не являются продуктом молока
FreeViz — чрезвычайно мощный виджет, который помогает вам извлекать недостоверную информацию из набора данных. Есть намного больше виджетов, которые можно использовать для визуализации набора данных. Не стесняйтесь попробовать их.
[Раздел 3] Заключение
Давайте вспомним то, что мы узнали сегодня. Мы начали с изучения трех способов установки и установки оранжевого на наш компьютер. Затем мы изучили пользовательский интерфейс и концепцию виджета в Orange. Кроме того, мы также протестировали три метода добавления виджета на холст. Виджеты могут быть связаны друг с другом, если они совместимы. Например, виджет «Файл» может быть связан с виджетом «Таблица данных». Наиболее важной частью является визуализация загруженного нами набора данных. Мы опробовали виджеты Distribution, Scatter Plot и FreeViz, используя пользовательский набор данных Iris. Спасибо за чтение первой частиData Science Made Easyруководство. В следующей части я расскажу об обработке данных с использованием Orange. ❤️
Data Science Made Easy
- Интерактивная визуализация данных
- Обработка данных
- Тест и оценка
- Моделирование данных и прогнозирование
- Аналитика изображений
Ссылка
- https://orange.biolab.si/
- https://github.com/biolab/orange3
- https://orange.biolab.si/docs/


Orange Data Mining
Orange is a data mining and visualization toolbox for novice and expert alike. To explore data with Orange, one requires no programming or in-depth mathematical knowledge. We believe that workflow-based data science tools democratize data science by hiding complex underlying mechanics and exposing intuitive concepts. Anyone who owns data, or is motivated to peek into data, should have the means to do so.
Installing
Easy installation
For easy installation, Download the latest released Orange version from our website. To install an add-on, head to Options -> Add-ons... in the menu bar.
Installing with Conda
First, install Miniconda for your OS.
Then, create a new conda environment, and install orange3:
# Add conda-forge to your channels for access to the latest release conda config --add channels conda-forge # Perhaps enforce strict conda-forge priority conda config --set channel_priority strict # Create and activate an environment for Orange conda create python=3 --yes --name orange3 conda activate orange3 # Install Orange conda install orange3
For installation of an add-on, use:
conda install orange3-<addon name>
See specific add-on repositories for details.
Installing with pip
We recommend using our standalone installer or conda, but Orange is also installable with pip. You will need a C/C++ compiler (on Windows we suggest using Microsoft Visual Studio Build Tools).
Orange needs PyQt to run. Install either:
- PyQt5 and PyQtWebEngine:
pip install -r requirements-pyqt.txt - PyQt6 and PyQt6-WebEngine:
pip install PyQt6 PyQt6-WebEngine
Installing with winget (Windows only)
To install Orange with winget, run:
winget install --id UniversityofLjubljana.Orange
Running
Ensure you’ve activated the correct virtual environment. If following the above conda instructions:
Run orange-canvas or python3 -m Orange.canvas. Add --help for a list of program options.
Starting up for the first time may take a while.
Developing
Want to write a widget? Use the Orange3 example add-on template.
Want to get involved? Join us on Discord, introduce yourself in #general!
Take a look at our contributing guide and style guidelines.
Check out our widget development docs for a comprehensive guide on writing Orange widgets.
The Orange ecosystem
The development of core Orange is primarily split into three repositories:
biolab/orange-canvas-core implements the canvas,
biolab/orange-widget-base is a handy widget GUI library,
biolab/orange3 brings it all together and implements the base data mining toolbox.
Additionally, add-ons implement additional widgets for more specific use cases. Anyone can write an add-on. Some of our first-party add-ons:
- biolab/orange3-text
- biolab/orange3-bioinformatics
- biolab/orange3-timeseries
- biolab/orange3-single-cell
- biolab/orange3-imageanalytics
- biolab/orange3-educational
- biolab/orange3-geo
- biolab/orange3-associate
- biolab/orange3-network
- biolab/orange3-explain
Setting up for core Orange development
First, fork the repository by pressing the fork button in the top-right corner of this page.
Set your GitHub username,
export MY_GITHUB_USERNAME=replaceme
create a conda environment, clone your fork, and install it:
conda create python=3 --yes --name orange3 conda activate orange3 git clone ssh://git@github.com/$MY_GITHUB_USERNAME/orange3 # Install PyQT and PyQtWebEngine. You can also use PyQt6 pip install -r requirements-pyqt.txt pip install -e orange3
Now you’re ready to work with git. See GitHub’s guides on pull requests, forks if you’re unfamiliar. If you’re having trouble, get in touch on Discord.
Running
Run Orange with python -m Orange.canvas (after activating the conda environment).
python -m Orange.canvas -l 2 --no-splash --no-welcome will skip the splash screen and welcome window, and output more debug info. Use -l 4 for more.
Add --clear-widget-settings to clear the widget settings before start.
To explore the dark side of the Orange, try --style=fusion:breeze-dark
Argument --help lists all available options.
To run tests, use unittest Orange.tests Orange.widgets.tests
Setting up for development of all components
Should you wish to contribute Orange’s base components (the widget base and the canvas), you must also clone these two repositories from Github instead of installing them as dependencies of Orange3.
First, fork all the repositories to which you want to contribute.
Set your GitHub username,
export MY_GITHUB_USERNAME=replaceme
create a conda environment, clone your forks, and install them:
conda create python=3 --yes --name orange3 conda activate orange3 # Install PyQT and PyQtWebEngine. You can also use PyQt6 pip install -r requirements-pyqt.txt git clone ssh://git@github.com/$MY_GITHUB_USERNAME/orange-widget-base pip install -e orange-widget-base git clone ssh://git@github.com/$MY_GITHUB_USERNAME/orange-canvas-core pip install -e orange-canvas-core git clone ssh://git@github.com/$MY_GITHUB_USERNAME/orange3 pip install -e orange3 # Repeat for any add-on repositories
It’s crucial to install orange-base-widget and orange-canvas-core before orange3 to ensure that orange3 will use your local versions.
Word «Orange» gives a first impression that it is a fruit. Which is a very obvious thing. Here in this article Orange is an open source tool which provides machine learning and data visualization capabilities for novice and expert users.

Introduction to Orange
Orange is an open source component-based visual programming software package used for data visualization, machine learning, data mining, and data analysis. Components of Orange are called widgets and they range from simple data visualization, subset selection, and pre-processing, to practical evaluation of learning algorithms and predictive modeling.
In Orange, visual programming is implemented through an interface in which workflows are created by linking predefined or user-designed widgets. While advanced users can use Orange as a Python library for data manipulation and widget alteration.
In short, Orange is an open source data visualization and data analysis tool for data mining through visual programming or Python scripting. The tool has components for almost all well-known machine learning algorithms, add-ons for bioinformatics and text mining as well as features for data analytics also. So, for researchers it is a one stop solution for pre-processing of dataset, visualization of dataset using graphs, all inbuilt machine learning algorithms, test and score feature for measuring accuracy of algorithm on different datasets along with many more fantastic features.
Eye-catching features of Orange
Following are some of the many amazing features of Orange,
1. Open source
The best part of Orange is that it is open source so that you can get its code and can even modify the tool as per your requirement. This tool is undoubtedly a boon for people doing Phd or masters in data science and machine learning. Also, you can get the source code of almost all machine learning algorithms too. So you can modify the algorithm as per your application and then you can add that modified algorithm in Orange and take the results. This is seriously amazing feature of the Orange tool.
2. Visual Programming
This tool is not just meant for computer science professionals but even novice users can use it as it provides visual programming. It is as simple installing a game and then playing it.
There is no need to learn any kind of programming languages like JAVA, C, C++ or Python etc, the only thing which you should know is data mining concepts and you should know that which algorithm should be used in a particular scenario.
It provides drag and drop facilities. It even provides lines for connection. To plot a graph was never such playful as Orange has made it. You will definitely fall in love with this tool when you will experience its flexible and visual environment. It provides dotted lines if connection is not proper. If you are not using proper machine learning algorithm or prediction algorithm then it will not allow you to connect with the data.
In short, visual programming provides interactive data exploration for rapid qualitative analysis with clear visualizations. GUI allows users to focus on exploratory data analysis instead of coding, while smart defaults make prototyping of any data analysis workflow fast and extremely easy.
Just place the widgets on the canvas, connect them, load your datasets and yield the insight.
3. Supports Google sheet
Oftenly in data science tools, one can browse any file from the local hard disk. But with Orange, it is possible to fetch the data from a given URL. It also provides support to fetch the data from Google spreadsheet which is its most eye catching feature. So if your data is not in your local hard drive, no need to worry as Orange provides the facility of fetching the data from Google spreadsheets also.
4. Add-ons are available to extend the functionality
It is possible to extend the functionality of Orange through add-ons which are available online. In fact, Orange never provides the toolbox for crunching bioinformatical data as an integral part of it; rather than it has always been an add-on. The exact process of distribution of add-ons has changed considerably in the last year to streamline the process for add-on authors and to make it more standards compliant. Among other things, this enables system administrators to install add-ons system-wide directly from PyPi using easy_install or pip.
Unfortunately there are some negative side effects of this process, notably the temporary breakage of the add-on management dialog within the Orange Canvas. It is reported that this is now being taken care of and you are encouraged to test the functionality. The process to add any add-ons is as below:
Firstly we open the Orange Tool.

The above picture shows the first screen that appears upon opening the Orange tool. Then we go to Options, and click on Add-ons… option.

You will see a new dialog for Add-ons as shown below.

From the list of available add-ons, tick the one you need and click on OK button to install the add-on.

5. Provides Online Support
Orange provides online as well as offline help for their users. Orange is having large online community support for solving the queries of its users. Orange also provides classroom training for its new users. It provides online tutorial supports. It also provides example as shown below:

Similarly more such example workflows are available on their official website for new users.
6. Create Dataset from any Graph you want
The most wonderful feature of Orange is that you can do reverse process. In general we have seen that we plot a graph from the data the we have, but here the reverse is also possible!
It seems strange but yes it is true that you can paint your graph by using paint data functionality and you will be able to generate the dataset for that graph which you have painted using paint data utility of Orange.
Here as shown in the figure below, you can see that using paint data, with help of brush we have painted the graph which we want. Now based on this graph, Orange tool can be used to provide us the dataset for it as shown in the next figure below. So this is just like a miracle for most of the researchers who are not getting dataset as per their requirement. They can now simply get the dataset as per their requirement with just one click.

Below we have the dataset generated from the graph shown above.

Installation Steps for Orange
To install it you can follow the following simple steps:
Step 1: Download and install Orange
You can download latest version of orange from following link: https://orange.biolab.si/download/
Step 2: Run the installer
Step 3: After installing you will get Orange icon on your desktop and click on it and open the Orange tool.
Step4: You will be prompted with a welcome screen of Orange. Now you are ready to start with your first project.
Working with Data
Orange provides you many options to do almost everything with your dataset. As shown in following figure there are almost 26 options to organize your dataset in any manner as you wish.

Visualizing Data
You can visualize the data in almost about 16 different types of graphs and plots. It is very easy and interesting feature of Orange where you just have to connect the dataset to the graph or plot you want and things are done.

Supervised Data Model
Orange provides almost 12 inbuilt machine learning models using which you can directly train your dataset. Inbuilt model includes most popular machine learning algorithms like KNN, SVM, Navies Bayes, Logistic regression and many more as shown in below figure.

Unsupervised Model
Orange provides inbuilt model for both supervised as well as unsupervised learning methods. It provides direct implementation of algorithms like PCA, K-Means etc. It also provides the access to other models as shown in given figure:

Evaluation of Performance of Models
Orange is not only powerful as an implementation tool but it is also excellent tool for evaluating the performance of different model.

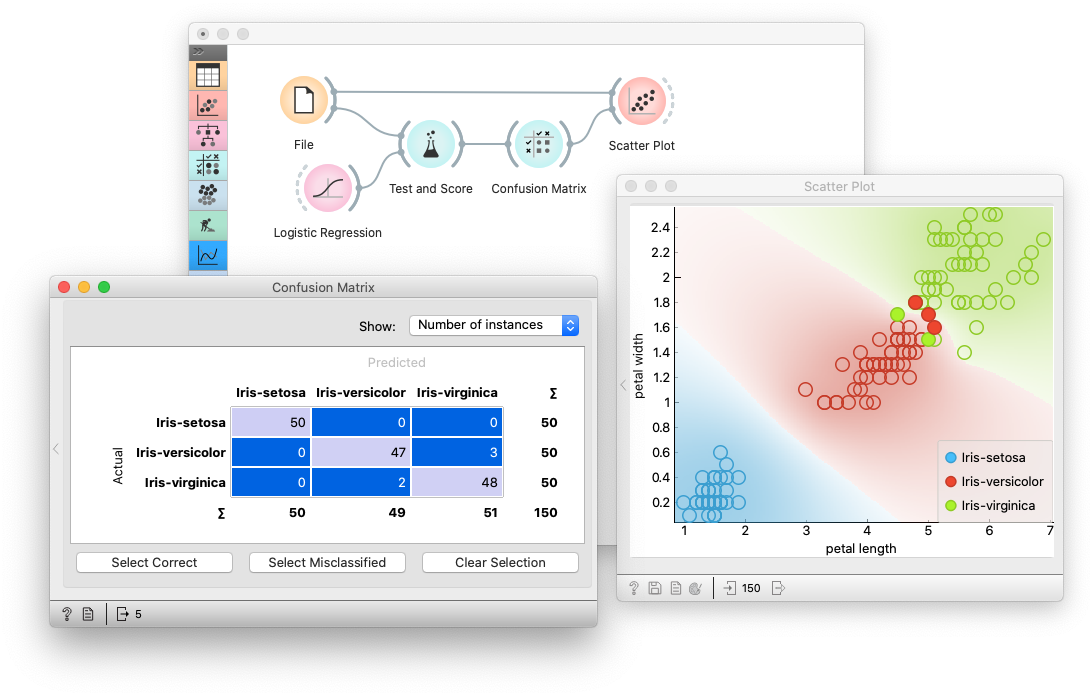
One of the most used widgets in Orange is Test & Score.
The widget mainly accepts 2 inputs — Data and Learner. Data is the dataset that we will be using for modeling for example titanic.tab that is already pre-loaded in the File widget.
Learner is any kind of learning algorithm, for example, it can be Logistic Regression, KNN or it can be SVM. You can only use those learners that support your type of task. If you wish to do classification, you can definitely not use Linear Regression and for regression you cannot use Logistic Regression.
Most other learners support both kind of tasks. You can connect more than single learner to Test & Score.

As you can see in the above diagram we have used to Test & Score from the Evaluate options, connected it to a dataset file and also connected multiple learners to it which are Logistic Regression, Naive bayes and Random Forest.
Test & Score will now use each connected Learner and the Data to develop a predictive model. There are different ways to build models. The most popular process is Cross Validation, which divides the data into n folds and uses n – 1 folds for training and the remaining fold for testing. This procedure is iterative, so that each fold has been used for testing exactly once. Test & Score will then generate report on the average accuracy of the model.
You can also use Random Sampling, which will divide the data into two sets with predefined proportions (e.g. 66% : 34%), build a model on the first set and test it against the second set. This is similar to Cross Validation, except that each data instance can be used more than once for testing.
Leave one out option is again very similar to the above mentioned two methods, but it only takes one data instance for testing each time. If you have a 1000 data instances, then 999 will be used for training and 1 for testing, and the procedure will be repeated a 1000 times until every data instance was used once for testing. As you can imagine, this is a very time-intensive procedure and it is recommended for smaller data sets only.
Test on train data option uses the whole data set for training and again the same data for testing. Because of over fitting, this will usually miscalculate the performance. Test on test data will not work with only existing dataset but it requires an additional data input (Test Data) and allows the user to control both data sets (training and testing) used for evaluation.
There is one more option which Orange provides is the use Cross Validation by feature. Sometimes, you would have pre-defined folds for a procedure that you wish to replicate. For such a requirement you can use Cross validation by feature to make sure that data instances are split into the same folds every time. Just make sure the feature you are using for defining folds is a categorical variable and located in meta attributes.
Additional scenarios are when you have several examples from the same object, for example several features of the same traveller in titanic or several images of the same plant. Then you absolutely want to make sure that all data instances for a particular object are in the same fold. Otherwise, your model may probably report ruthlessly over fitted scores.
In the screenshot below, you can see the various options availaible which we just discussed, you can choose anyone based on your requirements.

Based upon the selection, in the right pane you can see the results.
Thus it becomes very easy for the user to use test and score feature for evaluating more than one model simultaneously.
You may also like:
- It’s time you start taking ML/AI as serious Career Choices because Google is on it.
- What is Concept Learning in ML
- 6 Amazing Machine Learning Applications in The Real World
- ACUMOS : A New Innovative Path for Artificial intelligence Space