The Pentaho Data Integration is intended to Extract, Transform, Load (ETL) mainly. It consists of the following elements:
DI Server (Server Application)
Data integration server executes jobs and transformations using PDI engine. It has default user and role-based security and can also be integrated with existing LDAP/ Active Directory security providers. Here, we can store the transformations and jobs stored at one commonplace.
Design Tool (standalone) – It is for designing jobs and transformations
Spoon – GUI Tool to develop all jobs & transformations
Kitchen – Tool to run any job & transformations
Pan – Tool to run just the transformations
Carte – Remote ETL Server
In a data warehouse, historical data is loaded at one go and historical data is available with the organization. On a daily basis, since we won’t be able to run the entire data repeatedly into the data warehouse, we go forward with the incremental load.
The incremental load involves loading any changed data from the source site. It’s important to know that we won’t be able to sit or run the job & transformation manually every day so we must schedule the job. We schedule it on a weekly basis using windows scheduler and it runs the particular job at a specific time in order to run the incremental data into the data warehouse. This is known as the command prompt feature of PDI (Pentaho Data Integration).
Data Connections – Which is used for making connections from the source to the target database.
Transformation – It works on extracting and loading data into the data warehouse.
What is Spoon?
It’s a GUI tool for developing jobs and transformations. It is easy to learn and is user-friendly. There is a transformation already opened under the name ‘DIM_Product’. On the left side there are two tabs called View and Design. Here, we build a Database Connection to get data or load data from data warehouse. In the design tab we have different nodes such as:
Input – Where we need to extract the data.
Output – In order to load data.
Transform – This involves connectors and logic.
If you’re looking to improve your abilities and learn more about Business Intelligence tools to become certified as a Business Intelligence Professional. Explore the Tableau training or Pentaho BI Training as well as the certification program. Expertly designed by experts and taught by experts This program might be the one you’re hoping to learn.
Recommended videos for you

QlikView – What’s Your Business Question?
Watch Now

Data Visualization-How to Make Sense of Data
Watch Now
Recommended blogs for you

What are Excel Pivot Tables and how to create them?
Read Article

Difference between SQL and MySQL : SQL vs MySQL
Read Article

How to Build an Impressive Tableau Developer Resume?
Read Article

Everything You Need To Know About Power BI Charts
Read Article

Quick guide for Tableau Certification: Tableau Desktop 9 Qualified Associate Exam
Read Article

Power BI vs Tableau : Which One Would You Choose?
Read Article

Excel Charts: Advanced Data Visualization using MS Excel
Read Article

What is Business Intelligence: A Comprehensive Guide
Read Article

Tableau vs QlikView – Which Data Visualization Tool To Choose?
Read Article
В этом уроке я продемонстрирую, как ведется проектирование ETL процесса с нуля и до полного завершения в PDI (Pentaho Data Integration). Этот процесс не очень быстрый: все уместилось в два часа. Это очень долго для одного урока, но я решил оставить видео таким, как я его записал. На это есть ряд причин:
- На первый взгляд 2 часа — это много, однако ETL процессы разрабатываются в компаниях в течение нескольких месяцев.
- Все будет разрабатываться, тестироваться на ваших глазах.
- Так как видео смогут осилить немногие, поэтому разделение на несколько уроков не принесет пользы. Куда лучше взять готовую схему и обратиться к той части видео, где возникли вопросы. Видео будет как пример разработки ETL процесса.
Главное вам добиться того, чтобы проект заработал. Вот и сам проект, который разработали в видео. (Загрузка/Download)
Рекомендую просматривать видео на Youtube (ссылка http://youtu.be/XMb8dtlHKME)
План видео /Video plan (ссылка на youtub http://youtu.be/XMb8dtlHKME)
00:05 Цели и задачи / Goals and Objectives
01:29 Как запустить ETL проект (если вы его скачали с сайта) / How to run the ETL project (if you downloaded it from the website).
06:22 Обзор ETL / Overview ETL (ru).
24:04 Разработка/Designing
25:05 Проектирование главного элемента «Job». / Designing the main element «Job».
28:48 Проектирование элемента «Job» для обновления таблицы измерений. / Designing element «Job» to update the table of dimensions.
28:13 Создание элементов «transformation» для обновления таблиц измерений. / Creating elements «transformation“ to update the dimension tables.
29:50 “Insert / Update”.
39:53 “Dimension lookup/update”
47:35 Разработка элемента «Job» загрузки таблицы фактов / Designing the «Job» load the fact table.
48:37 Установка данных в переменные. / Set data into variable.
51:37 Параметризация загрузки данных из таблицы фактов. / Preparing data for load in the fact table (use variable).
01:01:36 Выбор ключа для фильтрации таблицы фактов из OLTP таблицы. / Selection key to filter the fact table from OLTP table.
01:08:12 Фильтрация входной таблицы фактов. / Filtering of the input fact table.
01:10:02 Загрузка кандидата таблицы фактов в WH. / Loading of the candidate fact table in WH.
01:14:19 Вставка данных в контрольное измерение. / Inserting data into control dimension.
01:16:54 Вставка данных в таблицу фактов через SQL запрос. / Insert data into the fact table through a SQL query.
01:31:15 Финальное тестирование и доработка процесса. / Final testing and refinement process.
В уроке использовались следующие приемы:
- Работа со скриптами “Execute SQL script” в PDI. Здесь рассмотрим, как задается параметризация SQL запроса.
- Работа с обновлением таблиц измерений (“Insert / Update”, “Dimension lookup/update”).
- Установка и использование переменных в работе (“Set Variables”).
- Использование трансформаций и заданий.
- Фильтрация таблицы фактов при помощи “Database lookup”.
- Работа с таблицами в Mysql (MySQLWorkbench) и составление запросов.
- Исправление ошибок при обновлении таблиц: устранение ошибок несоответствия типов.
- Вставка таблицы фактов средствами “SQL”
- и другие.
Ссылки по теме:
- Часть 3. Установка Pentaho и PDI (видео)
- Часть 5. Разработка WH (видео)
- Часть 5. Организация хранилища данных (WareHouse)
- Часть 6. Развертывание системы WH через PDI (видео)
- Create DI Solutions http://www.pentaho.com
- Michel Jansen. Building data warehouses using open source technologies
- Matt Casters, Roland Bouman, Jos van Dongen: Pentaho® Kettle Solutions: Building Open Source ETL Solutions with Pentaho Data Integration. Wiley Publishing, Inc.
- Getting Started with Pentaho Data Integration http://www.pentaho.com
- Latest Pentaho Data Integration (aka Kettle) Documentation http://wiki.pentaho.com/display/EAI/Latest+Pentaho+Data+Integration+%28aka+Kettle%29+Documentation
- Data Integration — Kettle http://community.pentaho.com/projects/data-integration/
- A Basic Mondrian Cube: Using Multi-Level Dimensions http://type-exit.org/adventures-with-open-source-bi/2010/07/a-basic-mondrian-cube-using-multi-level-dimensions/
- A Basic Mondrian Cube: Introducing the Star Schema http://type-exit.org/adventures-with-open-source-bi/2010/07/a-basic-mondrian-cube-introducing-the-star-schema/
- ADVENTURES WITH OPEN SOURCE BI http://type-exit.org/adventures-with-open-source-bi/2010/06/run-kettle-job-for-each-row/
- Using Variables in Kettle http://wiki.pentaho.com/display/COM/Using+Variables+in+Kettle
- Pentaho Data Integration (a.k.a. Kettle) and Database Sharding http://www.bluefiredatasolutions.com/blog/2011/01/pentaho-data-integration-and-database-sharding/
- Мини руководство по ETL Kettle на русском языке. (Хотя очень кривое) http://wiki.pentaho.com/display/EAIru/Pentaho+Data+Integration+%28Kettle%29+Tutorial+%28ru%29
- Execute SQL script http://wiki.pentaho.com/display/EAI/Execute+SQL+script
- Insert — Update http://wiki.pentaho.com/display/EAI/Insert+-+Update
- Dimension Lookup-Update http://wiki.pentaho.com/display/EAI/Dimension+Lookup-Update
- Set Variable http://wiki.pentaho.com/display/EAI/Set+Variable
- Database lookup http://wiki.pentaho.com/display/EAI/Database+lookup
- Порядок разработки ETL-процессов http://www.olap.ru/basic/etl.asp
- Подробности
-
Опубликовано: 09 Март 2014 - Просмотров: 8168
Что такое Pentaho BI?
Pentaho – это инструмент бизнес-аналитики, который предоставляет клиентам широкий спектр решений для бизнес-аналитики. Он способен создавать отчеты, анализировать данные, интегрировать данные, извлекать данные и т. Д. Pentaho также предлагает полный набор функций BI, которые позволяют повысить производительность и эффективность бизнеса.
Из этого урока в Пентахо вы узнаете:
- Особенности Пентахо
- Pentaho BI suite
- Кто использует Pentaho BI?
- Установите Pentaho в AWS
- Установка Пентахо
- Консоль администрирования Pentaho
- Pentaho Tool против BI-стека
- Преимущества использования Pentaho
- Недостатки использования Pentaho
Особенности Пентахо
Ниже приведены важные особенности Pentaho:
- Возможности ETL для нужд бизнес-аналитики
- Понимание дизайнера отчетов Pentaho
- Экспертиза продукта
- Предложения параллельных подотчетов
- Разблокировка новых возможностей
- Профессиональная поддержка
- Запрос и отчетность
- Предлагает расширенную функциональность
- Полная поддержка метаданных во время выполнения из источников данных
Pentaho BI suite

Pentaho BI Suite включает в себя следующие компоненты:
Составление отчетов
Отчетность Pentaho зависит от проекта JFreeReport. Это поможет вам удовлетворить ваши потребности в деловой отчетности. Этот компонент также предлагает публикацию отчетов по расписанию и по запросу в популярных форматах, таких как XLS, PDF, TXT и HTML.
Анализ
Он предлагает широкий спектр анализа, широкий спектр функций, включая представление сводной таблицы. Инструмент предоставляет расширенные возможности графического интерфейса пользователя (с использованием Flash или SVG), интегрированные виджеты панели мониторинга, портал и интеграцию с рабочим процессом.
Кроме того, Pentaho Spreadsheet Services позволяет пользователю просматривать, поворачивать и использовать диаграммы из MS Excel.
Сводки
Панель инструментов предлагает отчеты и анализ, которые предоставляют контент для панелей Pentaho. Дизайнер панели самообслуживания включает в себя обширные встроенные шаблоны и макет панели мониторинга. Это позволяет бизнес-пользователям создавать персонализированные информационные панели с минимальным обучением.
Сбор данных
Инструмент интеллектуального анализа данных обнаруживает скрытые закономерности и показатели будущей производительности. Он предлагает наиболее полный набор алгоритмов машинного обучения из проекта Weka, который включает кластеризацию, деревья решений, случайные леса, анализ главных компонентов, нейронные сети.
Он позволяет просматривать данные графически, программно взаимодействовать с ними или использовать несколько источников данных для отчетов, дальнейшего анализа и других процессов.
Pentaho Data Integration
Этот компонент используется для интеграции данных везде, где они существуют.
Богатая библиотека преобразований с более чем 150 готовыми объектами отображения.
Он поддерживает широкий спектр источников данных, который включает в себя более 30 платформ с открытым исходным кодом и проприетарных баз данных, плоских файлов. Это также помогает аналитике больших данных в интеграции и управлении данными Hadoop.
Кто использует Pentaho BI?
Pentaho BI – это широко используемый инструмент, который могут использовать такие профессионалы в области программного обеспечения, как:
- Программы с открытым исходным кодом
- Бизнес-аналитик и исследователь
- Студенты колледжа
- Советник по бизнес-разведке
Установите Pentaho в AWS
Шаг 1) Перейдите по ссылке и нажмите «Продолжить, чтобы подписаться».
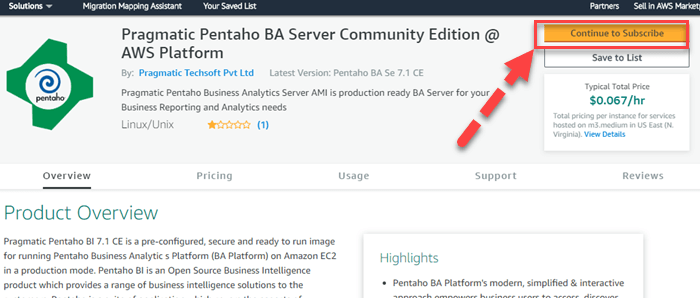
Шаг 2) Примите условия
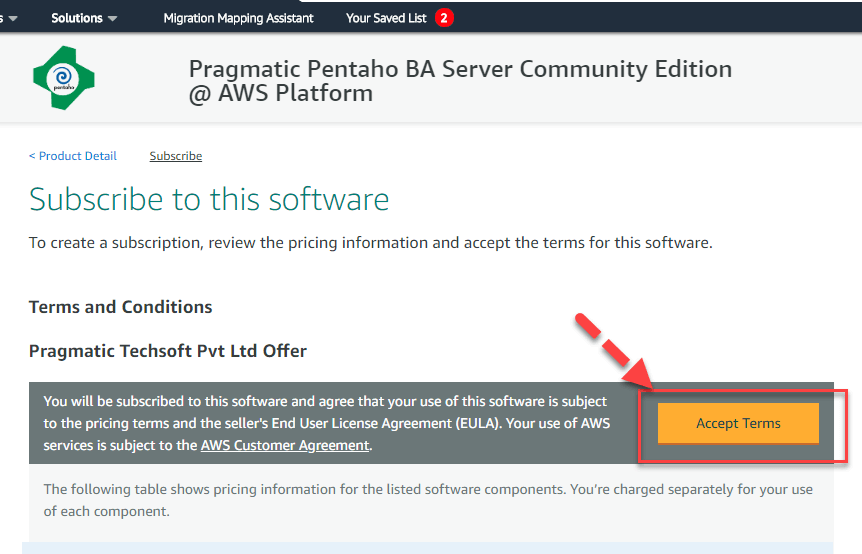
Шаг 3) Нажмите «Продолжить настройку»
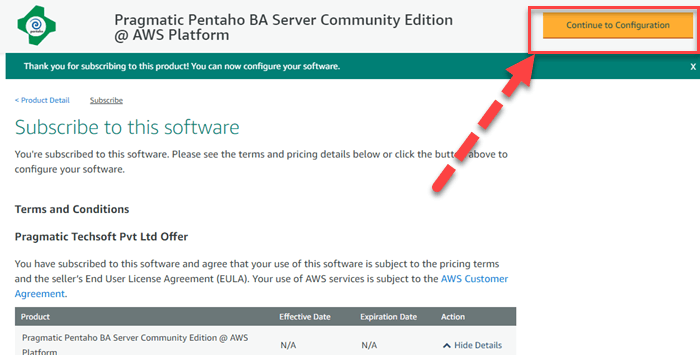
Шаг 4) Оставьте настройки по умолчанию и нажмите «Продолжить настройку».
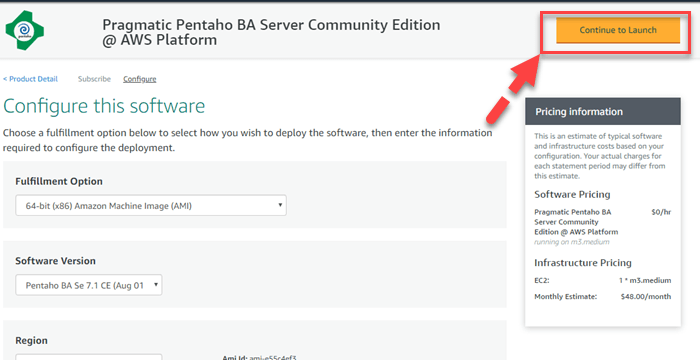
Шаг 5) Проверьте инструкции по использованию и подождите 5 минут, чтобы запустить экземпляр.
Шаг 6) Получить публичный IP-адрес экземпляра.

Шаг 7) Используйте публичный IP-адрес экземпляра для доступа к нему.
Установка Пентахо
- Требования к оборудованию
- Требования к программному обеспечению
- Загрузка и установка Bl Suite
- Начиная Bl Bl
- Администрация Bl Suite
Требования к оборудованию:
Программное обеспечение Pentaho Bl Suite не имеет каких-либо ограничений на компьютер или сетевое оборудование, если вы соответствуете минимальным требованиям к программному обеспечению. Этот инструмент бизнес-аналитики легко установить. Однако рекомендуется набор системных спецификаций:
| баран | Минимум 2 ГБ |
| Место на жестком диске | Минимум 1 ГБ |
| процессор | Двухъядерный EM64T или AMD64 |
Требования к программному обеспечению
- Установка Sun JRE 5.0
- Среда может быть 32-битной или 64-битной
- Поддерживаемые операционные системы: Linux, Solaris, Windows, Mac
- Рабочая станция с современным интерфейсом веб-браузера, таким как Chrome, Internet Explorer, Firefox
Запустить Bl-сервер
- На Windows с самого начала, нажмите кнопку на иконке запуска Bl сервера.
- В ОС Linux запустите скрипт start-pentaho в каталоге / biserver-ce /
Чтобы запустить сервер администратора:
- В Windows с помощью кнопки «Пуск» нажмите кнопку «Запустить Bl Enterprise Server».
- Для Linux: перейдите в командное окно и запустите сценарий запуска в каталоге / biserver-ce / Administration-console /.
Чтобы остановить сервер администратора:
- Чтобы остановить сервер в Windows, нажмите на значок остановки двухсерверного сервера.
- В линуксе Вам нужно зайти в терминал и перейти в установленный каталог и запустить stop.bat
Консоль администрирования Pentaho
Дизайнер отчетов:
Это расширенный инструмент для создания отчетов. Это идеальный инструмент для вас, если вы хотите создать полный отчет о накопителе данных. Этот инструмент обладает большей гибкостью и функциональностью, чем специальные отчеты в пользовательской консоли Pentaho.
Студия дизайна:
Это инструмент на основе Eclipse. Это позволяет вручную редактировать отчет или анализ. Он широко используется для добавления изменений в существующий отчет, которые нельзя добавить с помощью конструктора отчетов.
Конструктор агрегации:
Этот графический инструмент позволяет повысить эффективность куба Мондриана.
Редактор метаданных:
Он используется для добавления пользовательского слоя метаданных в любой существующий источник данных.
Интеграция данных Pentaho:
Инструмент извлечения, преобразования и загрузки Kettle (ETL), который позволяет
Pentaho Tool против BI-стека
| Pentaho Tool | BI Stack |
| Интеграция данных (PDI) | ETL |
| Предлагает редактор метаданных | Обеспечивает управление метаданными |
| Pentaho BA | аналитика |
| Дизайнер отчетов | Оперативная отчетность |
| Saiku | Специальная отчетность |
| CDE | Сводки |
| Консоль пользователя Pentaho (PUC) | Управление / контроль |
Преимущества использования Pentaho
- Pentaho BI – очень интуитивно понятный инструмент. С некоторыми основными понятиями вы можете работать с ним.
- Простой и легкий в использовании инструмент бизнес-аналитики
- Предлагает широкий спектр возможностей бизнес-аналитики, включая отчеты, панель мониторинга, интерактивный анализ, интеграцию данных, анализ данных и т. Д.
- Поставляется с удобным интерфейсом и предоставляет различные инструменты для извлечения данных из нескольких источников данных
- Предлагает один пакет для работы с данными
- Имеет выпуск сообщества с большим количеством участников наряду с выпуском Enterprise.
- Возможность работы на кластере Hadoop
- Код JavaScript, написанный в компонентах шага, можно повторно использовать в других компонентах.
Недостатки использования Pentaho
Вот минусы / недостатки использования инструмента Pentaho BI:
- Дизайн интерфейса может быть слабым, и нет унифицированного интерфейса для всех компонентов.
- Гораздо медленнее эволюция инструмента по сравнению с другими инструментами BI.
- Бизнес аналитика Pentaho предлагает ограниченное количество компонентов.
- Плохая поддержка сообщества. Поэтому, если вы не получили работающий компонент, вам нужно подождать, пока не выйдет следующая версия.
Резюме:
- Pentaho – это инструмент бизнес-аналитики, который предоставляет клиентам широкий спектр решений для бизнес-аналитики.
- Он предлагает возможности ETL для нужд бизнес-аналитики.
- Наборы Pentaho предлагают такие компоненты, как отчет, анализ, панель инструментов и интеллектуальный анализ данных
- Pentaho широко используется 1) бизнес-аналитиками 2) программистами с открытым исходным кодом 3) исследователями и 4) студентами колледжей.
- Процесс установки Pentaho включает в себя: 1) Требования к оборудованию 2) Требования к программному обеспечению, 3) Загрузка пакета Bl, 4) Запуск пакета Bl и 5) Администрирование пакета Bl
- Важными компонентами консоли администрирования Pentaho являются: 1) Дизайнер отчетов, 2) Design Studio, 3) Дизайнер агрегации 4) Редактор метаданных 5) Интеграция данных Pentaho
- Pentaho – это инструмент интеграции данных (PDI), а стек BI – инструмент ETL.
- Самым большим преимуществом Pentaho является то, что это простой и удобный инструмент бизнес-аналитики.
- Основным недостатком Pentaho является то, что он значительно медленнее развивается, чем другие инструменты BI.
Время на прочтение
8 мин
Количество просмотров 13K
Привет, Хабр.
Меня зовут Илья Гребцов, я работаю Java/JS Developer в DataArt. Хочу поделиться кое-чем полезным с теми, кто работает с Salesforce.
В Salesforce часто возникает задача массово создать/изменить/удалить группу связанных записей в нескольких объектах, аналогах таблиц в реляционной базе данных. Например, часто используемые стандартные объекты Account (информация о компании клиента), Contact (информация о самом клиенте). Проблема в том, что при сохранении записи Contact необходимо указать Id связанной записи Account, т. е. аккаунт должен существовать на момент добавления записи контакта.
В реальности связи могут быть еще сложнее, например, объект Opportunity ссылается и на Account, и на Contact. Плюс возможны ссылки на какие-либо нестандартные (custom) объекты. В любом случае, запись по ссылке должна быть создана раньше записи, на нее ссылающуюся.
Рассмотрим варианты решения этой проблемы:
Anonymous APEX
Необходимо подготовить APEX-скрипт, затем выполнить его в Salesforce Developer Console. В скрипте связанные объекты заполняются последовательно. В примере ниже вставляется тестовая запись Account, затем Contact. При вставке Contact используется Id записи Account, полученный после вставки Account.
Account[] accounts;
accounts.add(new Account(
Name = ‘test’
));
insert accounts;
Contact[] contacts;
contacts.add(new Contact(
AccountId = accounts[0].Id,
FirstName = ‘test’,
LastName = ‘test’
));
insert contacts;
Плюсы:
- Developer Console всегда под рукой, ничего дополнительно устанавливать и настраивать не требуется.
- Скрипт пишется на языке APEX, близком Salesforce-разработчикам.
- Несложно реализовать простую логику.
Минусы:
- Salesforce Limits допускают изменение не более 200 записей таким способом.
- Тяжело реализовать сложную логику.
- Метод не подходит для миграции данных извне Salesforce, все данные должны быть уже загружены.
Таким образом, способ подходит лишь для небольших простых изменений, производимых вручную.
Batch APEX
Когда необходимо произвести изменения множества записей, которые уже внутри Salesforce, можно воспользоваться Batch APEX. В отличии от предыдущего, этот способ позволяет обработать до 10 000 записей, согласно Salesforce Limits. Batch — кастомный класс, наследуемый от Database.Batchable, написанный на языке APEX.
Вручную класс можно запустить из Developer Console:
Database.Batchable<sObject> batch = new myBatchClass();
Database.executeBatch(batch);
Либо создать Job, с помощью которого процесс запустится в определенное время.
Таким образом, способ подходит для масштабных изменений данных внутри Salesforce, но весьма трудоемок. При внедрении с sandbox на продуктив класс, как и любой другой APEX-код, должен быть покрыт юнит-тестом.
Data Loader
Data Loader — стандартная Salesforce-утилита, устанавливающаяся локально. Позволяет обработать до 5 млн записей. Миграция с помощью Data Loader — best practise и наиболее популярный метод обработки большого количества записей. Выгрузка/загрузка записей осуществляется с помощью Salesforce API.
Утилита позволяет выбрать объект в Salesforce и экспортировать данные в CSV файл. А также наоборот, загрузить из CSV в Salesforce объект.
Обработка уже существующих данных в Salesforce выглядит следующим образом:
- Выгрузка необходимых данных из Salesforce в CSV-файлы.
- Изменение данных в CSV-файлах.
- Загрузка данных в Salesforce из CSV-файлов.
Пункт 2 тут — узкое место, не реализуемое самим Data Loader. Необходимо создание сторонних процедур обработки CSV файлов.
В качестве примера, чтобы вставить несколько записей контактов, данные должны пойти в связанные Account и Contact. Алгоритм действий должен быть таким:
- Подготовить CSV файл со списком новых записей Account. Загрузить в Salesforce с помощью Data Loader. В результате будет получен список Account IDs.
- Подготовить CSV файл со списком новых записей Contact. В нем в поле AccountId необходимо указать ID из списка, полученного на 1-м шаге. Это можно сделать вручную, либо использовать любой язык программирования.
- Загрузить в Salesforce полученную CSV со списком Contacts.
Таким образом, способ подходит для масштабных изменений данных и внутри Salesforce, и с использованием внешних данных. Но весьма трудоемок, особенно если необходима модификация записей.
Pentaho Data Integration
Pentaho Data Integration также известная как Kettle — универсальная ETL утилита. Не является специализированной утилитой Salesforce. В наборе — Salesforce Input- и Output-методы подключения, что позволяет прозрачно обрабатывать Salesforce данные как данные из других источников: реляционных баз данных, SAP, файлов XML, CSV и других.
С Salesforce утилита работает через Salesforce API, таким образом, возможно обработать до 5 млн записей, как и с Data Loader. Только более удобным способом.
Главная отличительная особенность — графический интерфейс. Вся трансформация разбивается на отдельные простые шаги: прочитать данные, отсортировать, соединить (join), записать данные. Шаги отображаются в виде пиктограмм, между которыми проведены стрелки. Таким образом, наглядно видно, что откуда берется и куда приходит.
Есть как минимум две версии утилиты: платная с гарантированной поддержкой и бесплатная. Бесплатную Community Edition (Apache License v2.0) можно скачать по адресу http://community.pentaho.com/.
Разработка трансформации в простейшем случае не требует навыков программирования. Но при желании можно использовать шаги, включающие подпрограммы, написанные на Java или JavaScript.
Особенности миграции данных с помощью Pentaho Data Integration стоит осветить подробнее. Здесь же опишу свой опыт и трудности, с которыми столкнулся.
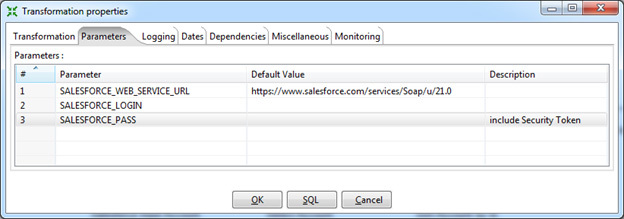
Параметры подключения к Salesforce стоит указать в параметрах Transformation Properties. Единожды сделанные настройки будут доступны во всех шагах, где это необходимо, в виде переменных.
Я рекомендую указывать:
- URL для подключения к Salesforce.
Для продуктива, включая Salesforce Developer Edition: https://www.salesforce.com/services/Soap/u/21.0
Для тестовых сред (sandbox): https://test.salesforce.com/services/Soap/u/21.0
Версию API (в данном случае 21.0) изменять по необходимости. - Логин. Пользователь должен иметь достаточные права для подключения через API. В идеале, это должен быть System Administrator.
- Пароль. Важно, помимо самого пароля необходимо указать Security Token.
По соображениям безопасности можно оставить поля логина и пароля пустыми, в этом случае Data Integration запросит их при запуске трансформации.
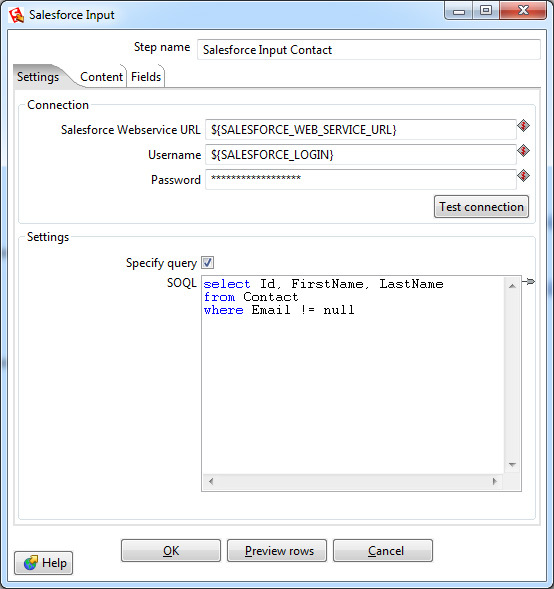
Выборка данных осуществляется шагом Salesforce Input. В настройках этого шага нужно указать параметры подключения, в данном случае используются переменные, созданные ранее. Также выбрать объект и список полей для выборки либо указать специфичный запрос, используя язык запросов SOQL (похож на язык запросов SQL, используемый в реляционных базах данных).
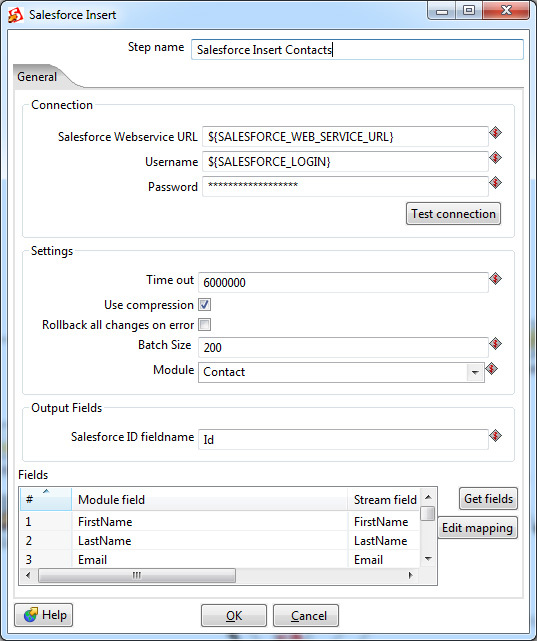
Вставка данных осуществляется с помощью одного из нескольких Output шагов:
- Salesforce Insert
- Salesforce Update
- Salesforce Upsert (объединяет insert и update: если запись есть — она будет обновлена, иначе вставлена новая)
Также возможно удаление записей с помощью
- Salesforce Delete.
Как и в Input-шаге, необходимо указать параметры подключения, в данном случае используются переменные трансформации. Тут имеется и более тонкая настройка — параметры time out-подключения, по истечении которого трансформация завершится неуспешно. И специфичный для Salesforce параметр Batch Size — количество записей, передаваемых в одной транзакции. Увеличение Batch Size незначительно повышает скорость работы трансформации, но не может быть больше 200 (согласно ограничениям Salesforce). Кроме того, если имеются триггеры, осуществляющие дополнительную обработку данных после вставки, возможна нестабильная работа с большим значением Batch Size. Значение по умолчанию — 10.
Приведенные два шага полностью покрывают возможности утилиты Data Loader. Всё, что между ними, — логика обработки данных. И ее можно реализовать непосредственно в Pentaho Data Integration.
Например, один из самых востребованных шагов — объединение (join) двух потоков данных. Тот самый join из SQL, которого так не хватает в SOQL. Тут он есть.
В настройках возможно выбрать тип: Inner, Left Outer, Right Outer, Full Outer — и указать ключи соединения.
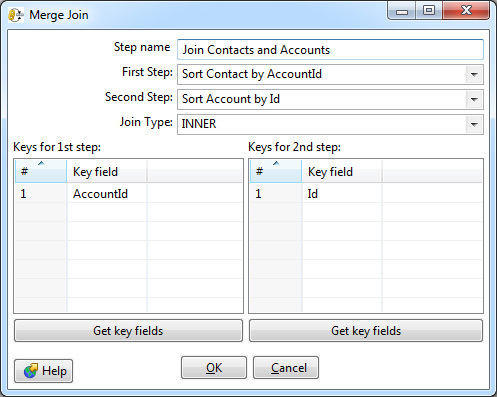
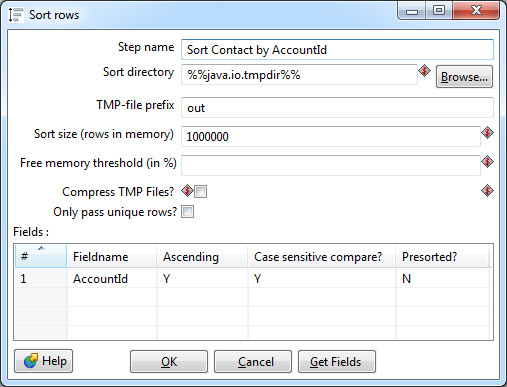
Обязательное требование — входные данные для этого шага должны быть отсортированы по ключевым полям. В Data Integration для этого применяется отдельный шаг Sorter.
Сортировка производится в оперативной памяти, тем не менее, возможна ситуация, что ее не хватит и данные будут сохраняться в промежуточный файл на диск. Большинство настроек сортера связано именно с этим кейсом. В идеале нужно избегать свопа на диск: это в десятки раз медленнее сортировки в памяти. Для этого необходимо скорректировать параметр Sort size — указать верхнюю границу количества строк, которые теоретически могут проходить через сортер.
Также в настройках можно выбрать одно или несколько ключевых полей, по которым будет производиться сортировка в порядке возрастания или убывания значений. Если тип поля строковый, имеет смысл указать чувствительность к регистру. Параметр Presorted показывает, что строки уже отсортированы по данному полю.
Join и Sorter образуют связку, встречающуюся практически в каждой трансформации.
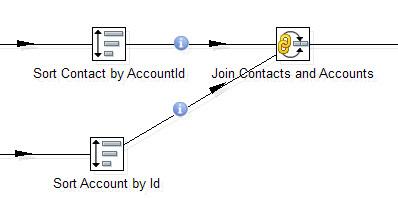
Сортировки и соединения больше всего влияют на производительность трансформации. Стоит избегать лишних сортировок, если данные уже отсортированы несколькими шагами ранее и их порядок после не менялся. Но нужно быть аккуратным: если в Join данные придут несортированными, Data Integration не прервет работу и не покажет ошибку, просто полученный результат будет некорректным.
В качестве ключевых полей всегда нужно выбирать короткое поле. Data Integration позволяет выбрать несколько ключевых полей для сортировки и соединения, но скорость обработки при этом значительно снижается. В качестве обходного пути лучше сгенерировать суррогатный ключ, в результате останется только одно поле для соединения. В простейшем случае суррогатный ключ можно получить конкатенацией строк. Например, для соединения по полям FirstName, LastName лучше соединять по FirstName + ‘ ‘+ LastName. Если идти дальше, из полученной строки можно вычислить хеш (md5, sha2). К сожалению, в Data Integration нет встроенного шага для расчета хеша строки, его можно написать самостоятельно, используя User Defined Java Class.
Кроме приведенных выше шагов, Data Integration включает множество других. Это фильтры, switch, union, шаги для обработки строк, лукапы к реляционным таблицам и веб-сервисам. И множество других. А также два универсальных шага, позволяющие выполнить код на Java или JavaScript. Не буду останавливаться на них подробно.
Неприятная особенность работы Data Integration именно с Salesforce — медленная скорость вставки записей через Salesforce API. Около 50 записей в секунду (как и у стандартного Data Loader, само по себе обращение к веб-сервису — медленная операция), что делает затруднительным обработку тысяч строк. К счастью, в Data Integration можно организовать вставку в несколько потоков. Стандартного решения нет, вот то, что я смог придумать:
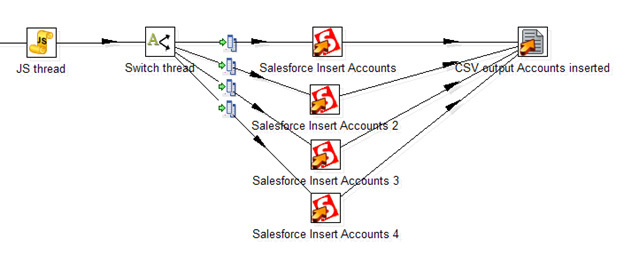
Тут JavaScript-процедура генерирует случайный номер потока. Далее шаг Switch распределяет потоки согласно его номеру. Четыре отдельных шага Salesforce Insert производят вставку записей, таким образом увеличивая общую скорость потока до 200 записей в секунду. В конечном счете, все вставленные записи с заполненным полем ID сохраняются в CSV файл.
Используя параллельную вставку, можно несколько ускорить обработку данных. Но плодить потоки бесконечно не получится: согласно ограничениям Salesforce, возможно не более 25 открытых соединений от одного пользователя.
Полученную трансформацию можно сразу же запустить на локальной машине. Прогресс пробега отображается в Step Metrics. Тут видно, какие шаги работают, сколько записей было прочитано на этом шаге и передано далее. А также скорость обработки записей на конкретном шаге, что делает простым нахождение «бутылочного горлышка» трансформации.

Для регулярных преобразований Data Integration позволяет создать Job, запускаемый по условию или расписанию на локальной машине или выделенном сервере.
Спасибо за внимание. Надеюсь, Salesforce-разработчики возьмут столь полезное средство на вооружение.
Ссылка: http://www.pentaho.com/product/data-integration
Краткое описание Kettle (дизайнер трансформаций и заданий): http://wiki.pentaho.com/display/EAI/Pentaho+Data+Integration+(Kettle)+Tutorial
Что это такое
Потратил 2 дня на знакомство с этой замечательной системой обработки данных, точнее с той ее частью, которая отвечает за ETL. ETL — это сокращение от Extract Transform Load, то есть загрузка данных, их преобразование и сохранение в новом формате.
Для человека, имеющего опыт работы и разработки под MS Access, Pentaho Data Integration выглядит именно как Access на стероидах. или на анаболиках — система немного монструозна. Объяснение простое — она написана на Java. Что сразу очерчивает некоторые рамки аппетита к ресурсам. В частности, в виртуалке под vSphere с Windows 2008 с квотой в 2 Гб памяти графический дизайнер грузится неторопливо
и работает достаточно размеренно, хотя явного дискомфорта не вызывает. Разве что отдельные нюансы самого гуя напоминают лишний раз, что это GUI на джаве — явно не нативное поведение окон и контролов. Фильтрация шагов по введенному названию вызывает неспешные перерисовки списка после ввода каждого символа, и для «REST client» можно наблюдать полуминутную мультипликацию с морганием палитры инструментов. Впрочем, мелочи.
Решаемая PDI задача, если отбросить технические нюансы, проста и понятна. Есть разные источники данных, в том числе реляционные СУБД, веб-сервисы, простые текстовые файлы в формате CSV и так далее. Там есть ценные данные, которые нужны бизнесу для планирования тактики и стратегии. Чем больше бизнес, тем больше разнородных данных. Аналитика по этим разнородным источникам сводится к повторению одних и тех же шагов: прочитать (точнее, периодически перечитывать) данные из (1C, csv файла, пришедшего из филиала, из Excel документа из департамента стратегического планирования и т.д.), выделить из них подмножество (берем столбцы дата и стоимость акций MSFT, игнорируем остальное), соединяем с выдачей веб-сервиса, который анализирует сентимент IT-новостей в спектре центральных СМИ, джойним, сохраняем в другом месте — пусть это будет какой-нибудь JSON документ в MongoDB. Потом мы эти данные прогоним через регрессионную machine learning модель (см. Weka http://wiki.pentaho.com/display/EAI/Weka+Forecasting), наконец нарисуем красивый репорт (опять там же https://www.profdata.com/reporting/) с рекомендациями — вставать в длинную и как много. Ну или типа того.
Плюсы
(*) Написано на Java, поэтому кроссплатформенно, если повезет с JRE, конечно. У меня со второго захода получилось установить нужную оракловую JRE и стартовать Kettle.
(*) Для софтверной компании, разрабатывающей коробочный продукт для enterprise сегмента, Pentaho DI однозначно суперская вещь с точки зрения маркетинга. На некоторых частях документации концентрация баззводов и наименований модных решений соперничает
с английскими артиклями. К примеру, раздел по Master DataManegement (http://wiki.pentaho.com/display/EAI/Master+Data+Management-Concepts)
перечисляет все основные приемы — Data Quality, Data Cleansing, Validation, Harmonization, Standardization, Data Consolidation (Deduplication, Enrichment).
Загрузить данные из веб-сервиса? Почти без проблем. Правда, я не смог подцепить свой SOAP веб-сервис, пентаха ругнулась на некое несоответствие формата в xml-оформлении конверта. С REST-сервисом все пошло веслее.
(*) Широчайшая поддержка различных РСУБД в качестве источников данных и вариантов сохранения результатов. По-моему, больше чем в MS Access или SSIS. Интеграция с всевозможными NoSQL базами, есть SAP HANA и вся классика типа Oracle и MS SQL. Даже крошка SQLite присутствует. Я сходу сделал сохранение данных в SQLite и оно заработало без каких либо шероховатостей. Потом небольшая пляска со скачиваем Oracle JDBC драйвера и установкой его в нужном каталоге — удалось прочитать данные из оракловой таблицы. Хотя тут был первый неприятный опыт, так как кириллица в varchar2 полях пришла поломанная. То есть настройка локалей где-то на пути требует заботливых рук ветеринара.
(*) Возможность цеплять SOAP и REST-сервисы.
(*) Графический дизайнер для редактирования трансформаций и заданий — это, конечно, плюс для использования PDI не-разработчиками.
(*) Графические программы (трансформации и заданий) сохраняются в XML формате и могут быть, таким образом, созданы и загружены через rest-api сторонними компонентами.
(*) Интеграция с другими компонентами Pentaho, хотя я их не успел попробовать. Отчеты и анализ данных — это хорошо и всегда полезно в реальных бизнес-задачах.
Минусы
(*) Все написано на Java. Поэтому прожорливо и неповоротливо. Когда стартует Carte (сервис, предоставляющий rest-api для создания/запуска/мониторинга трансформаций и заданий), в логе видно, как он инициализирует кучку всяких приблуд — кэши, вспомогательные библиотеки. Выглядит монструозно.
(*) Немного ненативный GUI. Хотя надо сказать, что эта ненативность гораздо нативнее, чем, к примеру, в PyCharm, который меня своими файловыми диалогами иногда ставит в тупик.
(*) Конфигурирование java-style, через xml-конфиги. Лично мне это всегда доставляет боль, так как неимоверное время тратится, чтобы нагуглить и подобрать, какие параметры в каких конфигах надо выставить в волшебные значения, чтобы все завелось. Например, правильный конфиг
для Carte, чтобы сервис увидел репозиторий с готовыми трансформациями, у меня получилось сделать не сразу, а через пару часов гугления и экспериментов.
(*) Это графический язык программирования со всеми вытекающими. Чтобы понять, какой визуальный кирпичик надо подпихнуть и как его настроить для выполнения элементарного действия, приходится гуглить, зырить видюшки на ютубе, в общем чуствовать себя полным буратиной. Возможно, по мере набора компетенции этот фактор станет меньше, но по началу просто часы уходят на то, что в питоне делается за 10 минут. Спустя день мне удалось выстроить трансформацию, в которой данные загружаются из моего rest-сервиса в json-формате, немного модифицируются, затем запихиваются в другой rest-сервис.
(*) Документация (вики) крайне скудна. Местами это просто скриншоты диалоговых окошек с перечислением подписей к контролам, то есть абсолютно бесполезная штука.
(*) В документации говорится, что можно использовать Python для написания специальных трансформаций. У меня не получилось даже понять, как это сделать. Никаких следов переключения с JavaScript на другие ЯП в кирпичике SCRIPT найти не удалось. Нашел некий плагин, который должен добавить поддержку Jython. Скачал его с гитхаба, запустил сборку в java-системе сборки, после 10 минут скачивания зависимостей и сборки эта редиска ругнулась «Fatal error in java compiler» и все. Представив, как этот процесс делать у клиентов удаленно с ограниченным доступом в инет, я решил что это плохой путь.
(*) Редактор js-скриптов в трансформациях мягко говоря убог. Нет, конечно я могу писать без поддержки IDE, и иногда редактирую программы на питоне просто в Notepad++. Но в графическом дизайнере хотелось бы большей поддержки для js.
За рамками исследованного
Остались некотрые вещи, которые я просто увидел в документации, но не смог потрогать вживую.
Во-первых, интеграция с различными системами доставки сообщений. Вроде бы есть встроенная интеграция с Java Message Service, но только в платной enterprise-версии. Есть некие плагины для интеграции с Apache Kafka, но как это все использовать — надо разбираться.
Во-вторых, как обеспечивается гарантированная обработка данных в случае технической аварии на исполняющем хосте. Попросту, можно ли возобновить трансформацию, если произошел фатальный сбой на промежуточном шаге (oom к примеру).