PostgreSQL – Обзор
PostgreSQL – это мощная система объектно-реляционных баз данных с открытым исходным кодом. Он имеет более 15 лет активной фазы разработки и проверенную архитектуру, которая заслужила хорошую репутацию за надежность, целостность данных и правильность.
Этот учебник даст вам быстрый старт с PostgreSQL и позволит вам освоиться с программированием на PostgreSQL.
Что такое PostgreSQL?
PostgreSQL (произносится как post-gress-QL ) – это система управления реляционными базами данных (СУБД) с открытым исходным кодом, разработанная всемирной командой добровольцев. PostgreSQL не контролируется какой-либо корпорацией или другим частным лицом, и исходный код доступен бесплатно.
Краткая история PostgreSQL
PostgreSQL, первоначально называемый Postgres, был создан в UCB профессором информатики Майклом Стоунбрейкером. Stonebraker начал Postgres в 1986 году в качестве последующего проекта своего предшественника Ingres, в настоящее время принадлежащего Computer Associates.
-
1977-1985 гг. – разработан проект INGRES.
-
Подтверждение концепции реляционных баз данных
-
Основанная компания Ingres в 1980 году
-
Куплен Computer Associates в 1994 году
-
-
1986-1994 – ПОСТГРЕСС
-
Разработка концепций в INGRES с акцентом на объектную ориентацию и язык запросов – Quel
-
Кодовая база INGRES не использовалась в качестве основы для POSTGRES.
-
Коммерциализируется как Illustra (куплено Informix, куплено IBM)
-
-
1994-1995 – Postgres95
-
Поддержка SQL была добавлена в 1994 году
-
Выпущен как Postgres95 в 1995 году
-
Переиздан как PostgreSQL 6.0 в 1996 году
-
Создание глобальной команды разработчиков PostgreSQL
-
1977-1985 гг. – разработан проект INGRES.
Подтверждение концепции реляционных баз данных
Основанная компания Ingres в 1980 году
Куплен Computer Associates в 1994 году
1986-1994 – ПОСТГРЕСС
Разработка концепций в INGRES с акцентом на объектную ориентацию и язык запросов – Quel
Кодовая база INGRES не использовалась в качестве основы для POSTGRES.
Коммерциализируется как Illustra (куплено Informix, куплено IBM)
1994-1995 – Postgres95
Поддержка SQL была добавлена в 1994 году
Выпущен как Postgres95 в 1995 году
Переиздан как PostgreSQL 6.0 в 1996 году
Создание глобальной команды разработчиков PostgreSQL
Ключевые особенности PostgreSQL
PostgreSQL работает во всех основных операционных системах, включая Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64) и Windows. Он поддерживает текст, изображения, звуки и видео, а также включает программные интерфейсы для C / C ++, Java, Perl, Python, Ruby, Tcl и Open Database Connectivity (ODBC).
PostgreSQL поддерживает большую часть стандарта SQL и предлагает множество современных функций, включая следующие:
- Сложные SQL-запросы
- Подвыборки SQL
- Внешние ключи
- Спусковой крючок
- Просмотры
- операции
- Мультиверсионный параллельный контроль (MVCC)
- Потоковая репликация (по состоянию на 9.0)
- Горячий резерв (по состоянию на 9.0)
Вы можете проверить официальную документацию PostgreSQL, чтобы понять вышеупомянутые функции. PostgreSQL может быть расширен пользователем многими способами. Например, добавив новый –
- Типы данных
- функции
- операторы
- Агрегатные функции
- Индексные методы
Поддержка процедурных языков
PostgreSQL поддерживает четыре стандартных процедурных языка, которые позволяют пользователям писать свой собственный код на любом из языков, и он может выполняться сервером базы данных PostgreSQL. Эти процедурные языки – PL / pgSQL, PL / Tcl, PL / Perl и PL / Python. Кроме того, поддерживаются и другие нестандартные процедурные языки, такие как PL / PHP, PL / V8, PL / Ruby, PL / Java и т. Д.
PostgreSQL – настройка среды
Чтобы начать понимать основы PostgreSQL, сначала давайте установим PostgreSQL. В этой главе рассказывается об установке PostgreSQL на платформах Linux, Windows и Mac OS.
Установка PostgreSQL в Linux / Unix
Следуйте приведенным инструкциям, чтобы установить PostgreSQL на ваш Linux-компьютер. Прежде чем продолжить установку, убедитесь, что вы вошли в систему как пользователь root .
-
Выберите номер версии PostgreSQL, которую вы хотите, и, насколько это возможно, платформу, которую вы хотите от EnterpriseDB
-
Я скачал postgresql-9.2.4-1-linux-x64.run для своей 64-битной машины CentOS-6. Теперь давайте выполним это следующим образом –
Выберите номер версии PostgreSQL, которую вы хотите, и, насколько это возможно, платформу, которую вы хотите от EnterpriseDB
Я скачал postgresql-9.2.4-1-linux-x64.run для своей 64-битной машины CentOS-6. Теперь давайте выполним это следующим образом –
[root@host]# chmod +x postgresql-9.2.4-1-linux-x64.run [root@host]# ./postgresql-9.2.4-1-linux-x64.run ------------------------------------------------------------------------ Welcome to the PostgreSQL Setup Wizard. ------------------------------------------------------------------------ Please specify the directory where PostgreSQL will be installed. Installation Directory [/opt/PostgreSQL/9.2]:
-
Когда вы запускаете установщик, он задает вам несколько основных вопросов, таких как место установки, пароль пользователя, который будет использовать базу данных, номер порта и т. Д. Поэтому оставьте для всех их значения по умолчанию, кроме пароля, который вы можете указать в качестве пароля. согласно вашему выбору. Он установит PostgreSQL на ваш Linux-компьютер и отобразит следующее сообщение:
Когда вы запускаете установщик, он задает вам несколько основных вопросов, таких как место установки, пароль пользователя, который будет использовать базу данных, номер порта и т. Д. Поэтому оставьте для всех их значения по умолчанию, кроме пароля, который вы можете указать в качестве пароля. согласно вашему выбору. Он установит PostgreSQL на ваш Linux-компьютер и отобразит следующее сообщение:
Please wait while Setup installs PostgreSQL on your computer. Installing 0% ______________ 50% ______________ 100% ######################################### ----------------------------------------------------------------------- Setup has finished installing PostgreSQL on your computer.
-
Выполните следующие шаги после установки, чтобы создать базу данных –
Выполните следующие шаги после установки, чтобы создать базу данных –
[root@host]# su - postgres Password: bash-4.1$ createdb testdb bash-4.1$ psql testdb psql (8.4.13, server 9.2.4) test=#
-
Вы можете запустить / перезапустить сервер postgres, если он не работает, с помощью следующей команды –
Вы можете запустить / перезапустить сервер postgres, если он не работает, с помощью следующей команды –
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
-
Если ваша установка была правильной, у вас будет приглашение PotsgreSQL test = #, как показано выше.
Если ваша установка была правильной, у вас будет приглашение PotsgreSQL test = #, как показано выше.
Установка PostgreSQL в Windows
Следуйте приведенным инструкциям для установки PostgreSQL на вашем компьютере с Windows. Убедитесь, что вы отключили сторонний антивирус при установке.
-
Выберите номер версии PostgreSQL, которую вы хотите, и, насколько это возможно, платформу, которую вы хотите от EnterpriseDB
-
Я загрузил postgresql-9.2.4-1-windows.exe для своего ПК с Windows, работающего в 32 -битном режиме, поэтому давайте запустим postgresql-9.2.4-1-windows.exe в качестве администратора для установки PostgreSQL. Выберите место, где вы хотите установить его. По умолчанию он устанавливается в папке Program Files.
Выберите номер версии PostgreSQL, которую вы хотите, и, насколько это возможно, платформу, которую вы хотите от EnterpriseDB
Я загрузил postgresql-9.2.4-1-windows.exe для своего ПК с Windows, работающего в 32 -битном режиме, поэтому давайте запустим postgresql-9.2.4-1-windows.exe в качестве администратора для установки PostgreSQL. Выберите место, где вы хотите установить его. По умолчанию он устанавливается в папке Program Files.
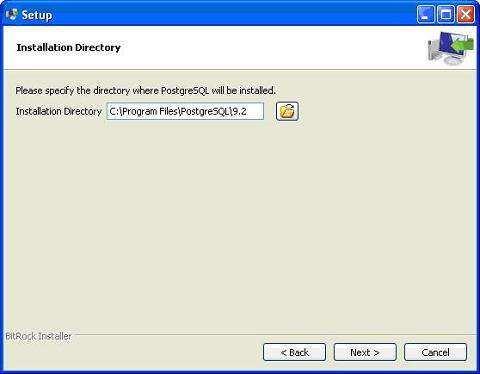
-
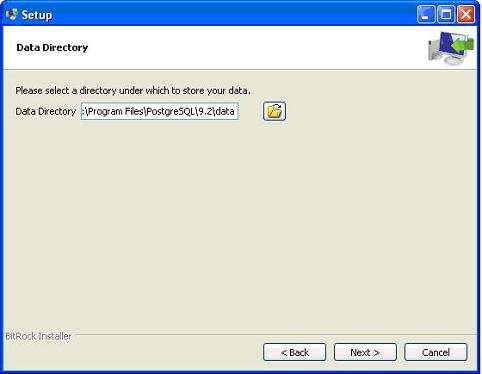
Следующим шагом процесса установки будет выбор каталога, в котором будут храниться ваши данные. По умолчанию он хранится в каталоге «data».
Следующим шагом процесса установки будет выбор каталога, в котором будут храниться ваши данные. По умолчанию он хранится в каталоге «data».
-
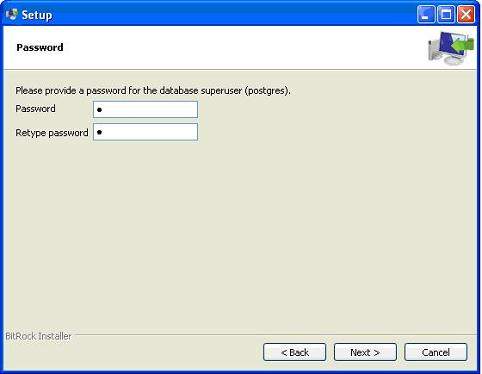
Затем программа установки запрашивает пароль, чтобы вы могли использовать свой любимый пароль.
Затем программа установки запрашивает пароль, чтобы вы могли использовать свой любимый пароль.
-
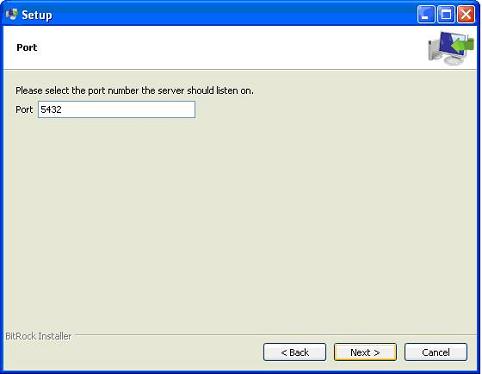
Следующий шаг; оставьте порт по умолчанию.
Следующий шаг; оставьте порт по умолчанию.
-
На следующем шаге, когда меня спросили «Locale», я выбрал «English, United States».
-
Установка PostgreSQL в вашей системе занимает некоторое время. По завершении процесса установки вы получите следующий экран. Снимите флажок и нажмите кнопку Готово.
На следующем шаге, когда меня спросили «Locale», я выбрал «English, United States».
Установка PostgreSQL в вашей системе занимает некоторое время. По завершении процесса установки вы получите следующий экран. Снимите флажок и нажмите кнопку Готово.
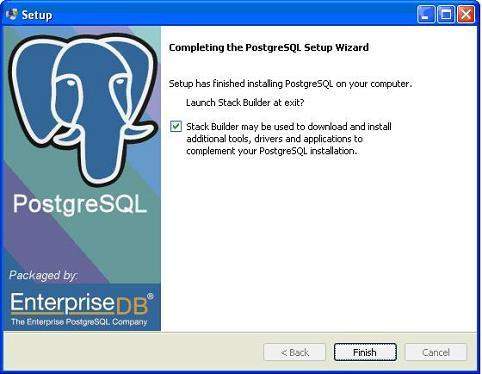
После завершения процесса установки вы можете получить доступ к оболочкам pgAdmin III, StackBuilder и PostgreSQL из меню программ в PostgreSQL 9.2.
Установка PostgreSQL на Mac
Выполните указанные шаги, чтобы установить PostgreSQL на свой компьютер Mac. Прежде чем приступить к установке, убедитесь, что вы вошли в систему как администратор .
-
Выберите номер последней версии PostgreSQL для Mac OS, доступный на EnterpriseDB
-
Я загрузил postgresql-9.2.4-1-osx.dmg для моей Mac OS, работающей с OS X версии 10.8.3. Теперь давайте откроем образ dmg в поисковике и просто дважды щелкните по нему, что даст вам установщик PostgreSQL в следующем окне –
Выберите номер последней версии PostgreSQL для Mac OS, доступный на EnterpriseDB
Я загрузил postgresql-9.2.4-1-osx.dmg для моей Mac OS, работающей с OS X версии 10.8.3. Теперь давайте откроем образ dmg в поисковике и просто дважды щелкните по нему, что даст вам установщик PostgreSQL в следующем окне –
-
Затем щелкните значок postgres-9.2.4-1-osx , который выдаст предупреждающее сообщение. Примите предупреждение и приступайте к дальнейшей установке. Он запросит пароль администратора, как показано в следующем окне –
Затем щелкните значок postgres-9.2.4-1-osx , который выдаст предупреждающее сообщение. Примите предупреждение и приступайте к дальнейшей установке. Он запросит пароль администратора, как показано в следующем окне –
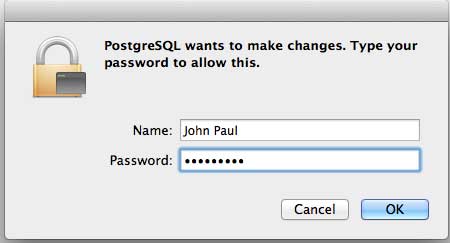
Введите пароль, продолжите установку и после этого перезапустите компьютер Mac. Если вы не видите следующее окно, запустите установку еще раз.

-
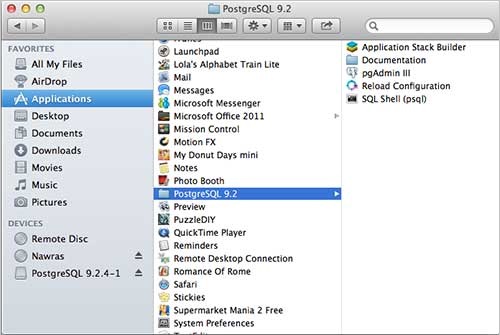
Когда вы запускаете установщик, он задает вам несколько основных вопросов, таких как место установки, пароль пользователя, который будет использовать базу данных, номер порта и т. Д. Поэтому оставьте для всех их значения по умолчанию, кроме пароля, который вы можете предоставить. согласно вашему выбору. Он установит PostgreSQL на ваш компьютер Mac в папке приложения, которую вы можете проверить –
Когда вы запускаете установщик, он задает вам несколько основных вопросов, таких как место установки, пароль пользователя, который будет использовать базу данных, номер порта и т. Д. Поэтому оставьте для всех их значения по умолчанию, кроме пароля, который вы можете предоставить. согласно вашему выбору. Он установит PostgreSQL на ваш компьютер Mac в папке приложения, которую вы можете проверить –
-
Теперь вы можете запустить любую программу для начала. Давайте начнем с SQL Shell. Когда вы запускаете SQL Shell, просто используйте все отображаемые по умолчанию значения, кроме того, введите ваш пароль, который вы выбрали во время установки. Если все пойдет хорошо, вы окажетесь в базе данных postgres, и будет отображено приглашение postgress # , как показано ниже –
Теперь вы можете запустить любую программу для начала. Давайте начнем с SQL Shell. Когда вы запускаете SQL Shell, просто используйте все отображаемые по умолчанию значения, кроме того, введите ваш пароль, который вы выбрали во время установки. Если все пойдет хорошо, вы окажетесь в базе данных postgres, и будет отображено приглашение postgress # , как показано ниже –
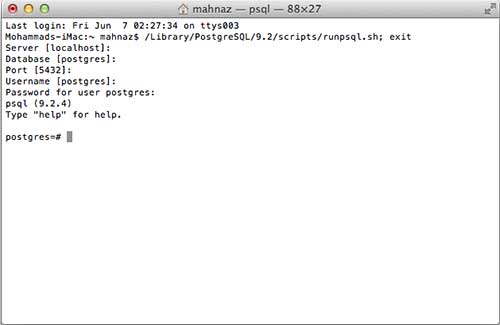
Поздравляем !!! Теперь у вас есть готовая среда для программирования баз данных PostgreSQL.
PostgreSQL – синтаксис
В этой главе приведен список команд PostgreSQL SQL, а также точные правила синтаксиса для каждой из этих команд. Этот набор команд взят из инструмента командной строки psql. Теперь, когда у вас установлен Postgres, откройте psql как –
Программные файлы → PostgreSQL 9.2 → Оболочка SQL (psql).
Используя psql, вы можете создать полный список команд с помощью команды help. Для синтаксиса конкретной команды используйте следующую команду –
postgres-# help <command_name>
Оператор SQL
Оператор SQL состоит из токенов, где каждый токен может представлять собой ключевое слово, идентификатор, заключенный в кавычки идентификатор, константу или символ специального символа. В приведенной ниже таблице используется простая инструкция SELECT, чтобы проиллюстрировать базовую, но полную инструкцию SQL и ее компоненты.
| ВЫБРАТЬ | идентификатор, имя | ОТ | состояния | |
|---|---|---|---|---|
| Тип токена | Ключевое слово | Идентификаторы | Ключевое слово | Идентификатор |
| Описание | команда | Столбцы идентификатора и имени | пункт | Имя таблицы |
SQL-команды PostgreSQL
ABORT
Прервать текущую транзакцию.
ABORT [ WORK | TRANSACTION ]
ALTER AGGREGATE
Измените определение агрегатной функции.
ALTER AGGREGATE name ( type ) RENAME TO new_name ALTER AGGREGATE name ( type ) OWNER TO new_owner
АЛЬТЕР КОНВЕРСИЯ
Изменить определение конверсии.
ALTER CONVERSION name RENAME TO new_name
ALTER CONVERSION name OWNER TO new_owner
ALTER DATABASE
Изменить параметр базы данных.
ALTER DATABASE name SET parameter { TO | = } { value | DEFAULT } ALTER DATABASE name RESET parameter ALTER DATABASE name RENAME TO new_name ALTER DATABASE name OWNER TO new_owner
ALTER DOMAIN
Измените определение определенного для домена параметра.
ALTER DOMAIN name { SET DEFAULT expression | DROP DEFAULT } ALTER DOMAIN name { SET | DROP } NOT NULL ALTER DOMAIN name ADD domain_constraint ALTER DOMAIN name DROP CONSTRAINT constraint_name [ RESTRICT | CASCADE ] ALTER DOMAIN name OWNER TO new_owner
ALTER FUNCTION
Изменить определение функции.
ALTER FUNCTION name ( [ type [, ...] ] ) RENAME TO new_name ALTER FUNCTION name ( [ type [, ...] ] ) OWNER TO new_owner
ALTER GROUP
Изменить группу пользователей.
ALTER GROUP groupname ADD USER username [, ... ] ALTER GROUP groupname DROP USER username [, ... ] ALTER GROUP groupname RENAME TO new_name
ALTER INDEX
Изменить определение индекса.
ALTER INDEX name OWNER TO new_owner
ALTER INDEX name SET TABLESPACE indexspace_name
ALTER INDEX name RENAME TO new_name
АЛЬТЕРСКИЙ ЯЗЫК
Изменить определение процедурного языка.
ALTER LANGUAGE name RENAME TO new_name
ALTER OPERATOR
Изменить определение оператора.
ALTER OPERATOR name ( { lefttype | NONE }, { righttype | NONE } ) OWNER TO new_owner
ALTER ОПЕРАТОР КЛАСС
Изменить определение класса оператора.
ALTER OPERATOR CLASS name USING index_method RENAME TO new_name
ALTER OPERATOR CLASS name USING index_method OWNER TO new_owner
ALTER SCHEMA
Измените определение схемы.
ALTER SCHEMA name RENAME TO new_name
ALTER SCHEMA name OWNER TO new_owner
ALTER SEQUENCE
Измените определение генератора последовательности.
ALTER SEQUENCE name [ INCREMENT [ BY ] increment ] [ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ] [ RESTART [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
ALTER TABLE
Изменить определение таблицы.
ALTER TABLE [ ONLY ] name [ * ] action [, ... ] ALTER TABLE [ ONLY ] name [ * ] RENAME [ COLUMN ] column TO new_column ALTER TABLE name RENAME TO new_name
Где действие – одна из следующих строк –
ADD [ COLUMN ] column_type [ column_constraint [ ... ] ] DROP [ COLUMN ] column [ RESTRICT | CASCADE ] ALTER [ COLUMN ] column TYPE type [ USING expression ] ALTER [ COLUMN ] column SET DEFAULT expression ALTER [ COLUMN ] column DROP DEFAULT ALTER [ COLUMN ] column { SET | DROP } NOT NULL ALTER [ COLUMN ] column SET STATISTICS integer ALTER [ COLUMN ] column SET STORAGE { PLAIN | EXTERNAL | EXTENDED | MAIN } ADD table_constraint DROP CONSTRAINT constraint_name [ RESTRICT | CASCADE ] CLUSTER ON index_name SET WITHOUT CLUSTER SET WITHOUT OIDS OWNER TO new_owner SET TABLESPACE tablespace_name
ALTER TABLESPACE
Изменить определение табличного пространства.
ALTER TABLESPACE name RENAME TO new_name
ALTER TABLESPACE name OWNER TO new_owner
ALTER TRIGGER
Изменить определение триггера.
ALTER TRIGGER name ON table RENAME TO new_name
ALTER TYPE
Изменить определение типа.
ALTER TYPE name OWNER TO new_owner
ALTER USER
Изменить учетную запись пользователя базы данных.
ALTER USER name [ [ WITH ] option [ ... ] ] ALTER USER name RENAME TO new_name ALTER USER name SET parameter { TO | = } { value | DEFAULT } ALTER USER name RESET parameter
Где вариант может быть –
[ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password' | CREATEDB | NOCREATEDB | CREATEUSER | NOCREATEUSER | VALID UNTIL 'abstime'
ПРОАНАЛИЗИРУЙТЕ
Сбор статистики о базе данных.
ANALYZE [ VERBOSE ] [ table [ (column [, ...] ) ] ]
НАЧАТЬ
Начать блок транзакции.
BEGIN [ WORK | TRANSACTION ] [ transaction_mode [, ...] ]
Где транзакция_мод является одним из –
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED } READ WRITE | READ ONLY
КОНТРОЛЬНО-ПРОПУСКНОЙ ПУНКТ
Принудительно установить контрольную точку журнала транзакций.
CHECKPOINT
БЛИЗКО
Закройте курсор.
CLOSE name
Кластер
Сгруппируйте таблицу в соответствии с индексом.
CLUSTER index_name ON table_name
CLUSTER table_name
CLUSTER
КОММЕНТАРИЙ
Определите или измените комментарий объекта.
COMMENT ON { TABLE object_name | COLUMN table_name.column_name | AGGREGATE agg_name (agg_type) | CAST (source_type AS target_type) | CONSTRAINT constraint_name ON table_name | CONVERSION object_name | DATABASE object_name | DOMAIN object_name | FUNCTION func_name (arg1_type, arg2_type, ...) | INDEX object_name | LARGE OBJECT large_object_oid | OPERATOR op (left_operand_type, right_operand_type) | OPERATOR CLASS object_name USING index_method | [ PROCEDURAL ] LANGUAGE object_name | RULE rule_name ON table_name | SCHEMA object_name | SEQUENCE object_name | TRIGGER trigger_name ON table_name | TYPE object_name | VIEW object_name } IS 'text'
COMMIT
Зафиксируйте текущую транзакцию.
COMMIT [ WORK | TRANSACTION ]
COPY
Скопируйте данные между файлом и таблицей.
COPY table_name [ ( column [, ...] ) ] FROM { 'filename' | STDIN } [ WITH ] [ BINARY ] [ OIDS ] [ DELIMITER [ AS ] 'delimiter' ] [ NULL [ AS ] 'null string' ] [ CSV [ QUOTE [ AS ] 'quote' ] [ ESCAPE [ AS ] 'escape' ] [ FORCE NOT NULL column [, ...] ] COPY table_name [ ( column [, ...] ) ] TO { 'filename' | STDOUT } [ [ WITH ] [ BINARY ] [ OIDS ] [ DELIMITER [ AS ] 'delimiter' ] [ NULL [ AS ] 'null string' ] [ CSV [ QUOTE [ AS ] 'quote' ] [ ESCAPE [ AS ] 'escape' ] [ FORCE QUOTE column [, ...] ]
СОЗДАТЬ АГРЕГАТ
Определите новую агрегатную функцию.
CREATE AGGREGATE name ( BASETYPE = input_data_type, SFUNC = sfunc, STYPE = state_data_type [, FINALFUNC = ffunc ] [, INITCOND = initial_condition ] )
СОЗДАТЬ АКТЕРЫ
Определите новый состав.
CREATE CAST (source_type AS target_type) WITH FUNCTION func_name (arg_types) [ AS ASSIGNMENT | AS IMPLICIT ] CREATE CAST (source_type AS target_type) WITHOUT FUNCTION [ AS ASSIGNMENT | AS IMPLICIT ]
СОЗДАТЬ ОГРАНИЧЕННЫЙ ТРИГГЕР
Определите новый триггер ограничения.
CREATE CONSTRAINT TRIGGER name AFTER events ON table_name constraint attributes FOR EACH ROW EXECUTE PROCEDURE func_name ( args )
СОЗДАТЬ КОНВЕРСИЯ
Определите новую конверсию.
CREATE [DEFAULT] CONVERSION name FOR source_encoding TO dest_encoding FROM func_name
СОЗДАТЬ БАЗУ ДАННЫХ
Создать новую базу данных.
CREATE DATABASE name [ [ WITH ] [ OWNER [=] db_owner ] [ TEMPLATE [=] template ] [ ENCODING [=] encoding ] [ TABLESPACE [=] tablespace ] ]
СОЗДАТЬ ДОМЕН
Определите новый домен.
CREATE DOMAIN name [AS] data_type [ DEFAULT expression ] [ constraint [ ... ] ]
Где ограничение –
[ CONSTRAINT constraint_name ] { NOT NULL | NULL | CHECK (expression) }
СОЗДАТЬ ФУНКЦИЮ
Определите новую функцию.
CREATE [ OR REPLACE ] FUNCTION name ( [ [ arg_name ] arg_type [, ...] ] ) RETURNS ret_type { LANGUAGE lang_name | IMMUTABLE | STABLE | VOLATILE | CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT | [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER | AS 'definition' | AS 'obj_file', 'link_symbol' } ... [ WITH ( attribute [, ...] ) ]
СОЗДАТЬ ГРУППУ
Определите новую группу пользователей.
CREATE GROUP name [ [ WITH ] option [ ... ] ] Where option can be: SYSID gid | USER username [, ...]
СОЗДАТЬ ИНДЕКС
Определите новый индекс.
CREATE [ UNIQUE ] INDEX name ON table [ USING method ] ( { column | ( expression ) } [ opclass ] [, ...] ) [ TABLESPACE tablespace ] [ WHERE predicate ]
СОЗДАТЬ ЯЗЫК
Определите новый процедурный язык.
CREATE [ TRUSTED ] [ PROCEDURAL ] LANGUAGE name HANDLER call_handler [ VALIDATOR val_function ]
СОЗДАТЬ ОПЕРАТОР
Определите нового оператора.
CREATE OPERATOR name ( PROCEDURE = func_name [, LEFTARG = left_type ] [, RIGHTARG = right_type ] [, COMMUTATOR = com_op ] [, NEGATOR = neg_op ] [, RESTRICT = res_proc ] [, JOIN = join_proc ] [, HASHES ] [, MERGES ] [, SORT1 = left_sort_op ] [, SORT2 = right_sort_op ] [, LTCMP = less_than_op ] [, GTCMP = greater_than_op ] )
СОЗДАТЬ КЛАСС ОПЕРАТОРА
Определите новый класс операторов.
CREATE OPERATOR CLASS name [ DEFAULT ] FOR TYPE data_type USING index_method AS { OPERATOR strategy_number operator_name [ ( op_type, op_type ) ] [ RECHECK ] | FUNCTION support_number func_name ( argument_type [, ...] ) | STORAGE storage_type } [, ... ]
СОЗДАТЬ ПРАВИЛО
Определите новое правило перезаписи.
CREATE [ OR REPLACE ] RULE name AS ON event TO table [ WHERE condition ] DO [ ALSO | INSTEAD ] { NOTHING | command | ( command ; command ... ) }
СОЗДАТЬ СХЕМУ
Определите новую схему.
CREATE SCHEMA schema_name [ AUTHORIZATION username ] [ schema_element [ ... ] ] CREATE SCHEMA AUTHORIZATION username [ schema_element [ ... ] ]
СОЗДАТЬ ПОСЛЕДОВАТЕЛЬНОСТЬ
Определите новый генератор последовательности.
CREATE [ TEMPORARY | TEMP ] SEQUENCE name [ INCREMENT [ BY ] increment ] [ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ] [ START [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
СОЗДАТЬ СТОЛ
Определите новую таблицу.
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } ] TABLE table_name ( { column_name data_type [ DEFAULT default_expr ] [ column_constraint [ ... ] ] | table_constraint | LIKE parent_table [ { INCLUDING | EXCLUDING } DEFAULTS ] } [, ... ] ) [ INHERITS ( parent_table [, ... ] ) ] [ WITH OIDS | WITHOUT OIDS ] [ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ] [ TABLESPACE tablespace ]
Где находится column_constraint –
[ CONSTRAINT constraint_name ] { NOT NULL | NULL | UNIQUE [ USING INDEX TABLESPACE tablespace ] | PRIMARY KEY [ USING INDEX TABLESPACE tablespace ] | CHECK (expression) | REFERENCES ref_table [ ( ref_column ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELETE action ] [ ON UPDATE action ] } [ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
И ограничение таблицы –
[ CONSTRAINT constraint_name ] { UNIQUE ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] | PRIMARY KEY ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] | CHECK ( expression ) | FOREIGN KEY ( column_name [, ... ] ) REFERENCES ref_table [ ( ref_column [, ... ] ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELETE action ] [ ON UPDATE action ] } [ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
СОЗДАТЬ ТАБЛИЦУ КАК
Определите новую таблицу из результатов запроса.
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } ] TABLE table_name [ (column_name [, ...] ) ] [ [ WITH | WITHOUT ] OIDS ] AS query
СОЗДАТЬ СТОЛ
Определите новое табличное пространство.
CREATE TABLESPACE tablespace_name [ OWNER username ] LOCATION 'directory'
СОЗДАТЬ ТРИГГЕР
Определите новый триггер.
CREATE TRIGGER name { BEFORE | AFTER } { event [ OR ... ] } ON table [ FOR [ EACH ] { ROW | STATEMENT } ] EXECUTE PROCEDURE func_name ( arguments )
СОЗДАТЬ ТИП
Определите новый тип данных.
CREATE TYPE name AS ( attribute_name data_type [, ... ] ) CREATE TYPE name ( INPUT = input_function, OUTPUT = output_function [, RECEIVE = receive_function ] [, SEND = send_function ] [, ANALYZE = analyze_function ] [, INTERNALLENGTH = { internal_length | VARIABLE } ] [, PASSEDBYVALUE ] [, ALIGNMENT = alignment ] [, STORAGE = storage ] [, DEFAULT = default ] [, ELEMENT = element ] [, DELIMITER = delimiter ] )
СОЗДАТЬ ПОЛЬЗОВАТЕЛЯ
Определите новую учетную запись пользователя базы данных.
CREATE USER name [ [ WITH ] option [ ... ] ]
Где вариант может быть –
SYSID uid | [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password' | CREATEDB | NOCREATEDB | CREATEUSER | NOCREATEUSER | IN GROUP group_name [, ...] | VALID UNTIL 'abs_time'
СОЗДАТЬ ВИД
Определить новый вид.
CREATE [ OR REPLACE ] VIEW name [ ( column_name [, ...] ) ] AS query
DEALLOCATE
Распределите подготовленное заявление.
DEALLOCATE [ PREPARE ] plan_name
DECLARE
Определить курсор.
DECLARE name [ BINARY ] [ INSENSITIVE ] [ [ NO ] SCROLL ] CURSOR [ { WITH | WITHOUT } HOLD ] FOR query [ FOR { READ ONLY | UPDATE [ OF column [, ...] ] } ]
УДАЛЯТЬ
Удалить строки таблицы.
DELETE FROM [ ONLY ] table [ WHERE condition ]
DROP AGGREGATE
Удалить агрегатную функцию.
DROP AGGREGATE name ( type ) [ CASCADE | RESTRICT ]
КАПЛИ КАПИТАЛА
Удалить актерский состав.
DROP CAST (source_type AS target_type) [ CASCADE | RESTRICT ]
КАПЛИВНАЯ КОНВЕРСИЯ
Удалить конверсию
DROP CONVERSION name [ CASCADE | RESTRICT ]
DROP DATABASE
Удалить базу данных.
DROP DATABASE name
DROP DOMAIN
Удалить домен.
DROP DOMAIN name [, ...] [ CASCADE | RESTRICT ]
ФУНКЦИЯ КАПЛИ
Удалить функцию.
DROP FUNCTION name ( [ type [, ...] ] ) [ CASCADE | RESTRICT ]
DROP GROUP
Удалить группу пользователей.
DROP GROUP name
Индекс капли
Удалить индекс.
DROP INDEX name [, ...] [ CASCADE | RESTRICT ]
УСТАРЕТЬ ЯЗЫК
Удалить процедурный язык.
DROP [ PROCEDURAL ] LANGUAGE name [ CASCADE | RESTRICT ]
КАПЕЛЬНЫЙ ОПЕРАТОР
Удалить оператора.
DROP OPERATOR name ( { left_type | NONE }, { right_type | NONE } ) [ CASCADE | RESTRICT ]
КАПЛЯЖ ОПЕРАТОРА
Удалить класс оператора.
DROP OPERATOR CLASS name USING index_method [ CASCADE | RESTRICT ]
DROP RULE
Удалить правило перезаписи.
DROP RULE name ON relation [ CASCADE | RESTRICT ]
DROP SCHEMA
Удалить схему.
DROP SCHEMA name [, ...] [ CASCADE | RESTRICT ]
DROP SEQUENCE
Удалить последовательность.
DROP SEQUENCE name [, ...] [ CASCADE | RESTRICT ]
DROP TABLE
Удалить стол.
DROP TABLE name [, ...] [ CASCADE | RESTRICT ]
DROP TABLESPACE
Удалить табличное пространство.
DROP TABLESPACE tablespace_name
DROP TRIGGER
Удалить триггер.
DROP TRIGGER name ON table [ CASCADE | RESTRICT ]
DROP TYPE
Удалить тип данных.
DROP TYPE name [, ...] [ CASCADE | RESTRICT ]
DROP USER
Удалить учетную запись пользователя базы данных.
DROP USER name
DROP VIEW
Удалить вид.
DROP VIEW name [, ...] [ CASCADE | RESTRICT ]
КОНЕЦ
Зафиксируйте текущую транзакцию.
END [ WORK | TRANSACTION ]
ВЫПОЛНИТЬ
Выполните подготовленное заявление.
EXECUTE plan_name [ (parameter [, ...] ) ]
EXPLAIN
Показать план выполнения выписки.
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
FETCH
Получить строки из запроса с помощью курсора.
FETCH [ direction { FROM | IN } ] cursor_name
Где направление может быть пустым или одно из –
NEXT
PRIOR
FIRST
LAST
ABSOLUTE count
RELATIVE count
count
ALL
FORWARD
FORWARD count
FORWARD ALL
BACKWARD
BACKWARD count
BACKWARD ALL
ГРАНТ
Определите права доступа.
GRANT { { SELECT | INSERT | UPDATE | DELETE | RULE | REFERENCES | TRIGGER } [,...] | ALL [ PRIVILEGES ] } ON [ TABLE ] table_name [, ...] TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ] GRANT { { CREATE | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] } ON DATABASE db_name [, ...] TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ] GRANT { CREATE | ALL [ PRIVILEGES ] } ON TABLESPACE tablespace_name [, ...] TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ] GRANT { EXECUTE | ALL [ PRIVILEGES ] } ON FUNCTION func_name ([type, ...]) [, ...] TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ] GRANT { USAGE | ALL [ PRIVILEGES ] } ON LANGUAGE lang_name [, ...] TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ] GRANT { { CREATE | USAGE } [,...] | ALL [ PRIVILEGES ] } ON SCHEMA schema_name [, ...] TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
ВСТАВИТЬ
Создать новые строки в таблице.
INSERT INTO table [ ( column [, ...] ) ] { DEFAULT VALUES | VALUES ( { expression | DEFAULT } [, ...] ) | query }
СЛУШАТЬ
Слушайте уведомления.
LISTEN name
НАГРУЗКИ
Загрузите или перезагрузите файл общей библиотеки.
LOAD 'filename'
ЗАМОК
Заблокировать стол
LOCK [ TABLE ] name [, ...] [ IN lock_mode MODE ] [ NOWAIT ]
Где lock_mode является одним из –
ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE | SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE
ПЕРЕЕХАТЬ
Поместите курсор.
MOVE [ direction { FROM | IN } ] cursor_name
ПОСТАВИТЬ В ИЗВЕСТНОСТЬ
Создать уведомление.
NOTIFY name
ПОДГОТОВИТЬ
Подготовьте заявление к исполнению.
PREPARE plan_name [ (data_type [, ...] ) ] AS statement
REINDEX
Перестройте индексы.
REINDEX { DATABASE | TABLE | INDEX } name [ FORCE ]
RELEASE SAVEPOINT
Уничтожить ранее определенную точку сохранения.
RELEASE [ SAVEPOINT ] savepoint_name
СБРОС
Восстановите значение параметра времени выполнения до значения по умолчанию.
RESET name
RESET ALL
КЕУОКЕ
Удалить права доступа.
REVOKE [ GRANT OPTION FOR ] { { SELECT | INSERT | UPDATE | DELETE | RULE | REFERENCES | TRIGGER } [,...] | ALL [ PRIVILEGES ] } ON [ TABLE ] table_name [, ...] FROM { username | GROUP group_name | PUBLIC } [, ...] [ CASCADE | RESTRICT ] REVOKE [ GRANT OPTION FOR ] { { CREATE | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] } ON DATABASE db_name [, ...] FROM { username | GROUP group_name | PUBLIC } [, ...] [ CASCADE | RESTRICT ] REVOKE [ GRANT OPTION FOR ] { CREATE | ALL [ PRIVILEGES ] } ON TABLESPACE tablespace_name [, ...] FROM { username | GROUP group_name | PUBLIC } [, ...] [ CASCADE | RESTRICT ] REVOKE [ GRANT OPTION FOR ] { EXECUTE | ALL [ PRIVILEGES ] } ON FUNCTION func_name ([type, ...]) [, ...] FROM { username | GROUP group_name | PUBLIC } [, ...] [ CASCADE | RESTRICT ] REVOKE [ GRANT OPTION FOR ] { USAGE | ALL [ PRIVILEGES ] } ON LANGUAGE lang_name [, ...] FROM { username | GROUP group_name | PUBLIC } [, ...] [ CASCADE | RESTRICT ] REVOKE [ GRANT OPTION FOR ] { { CREATE | USAGE } [,...] | ALL [ PRIVILEGES ] } ON SCHEMA schema_name [, ...] FROM { username | GROUP group_name | PUBLIC } [, ...] [ CASCADE | RESTRICT ]
ROLLBACK
Прервать текущую транзакцию.
ROLLBACK [ WORK | TRANSACTION ]
Откат к SAVEPOINT
Откат к точке сохранения.
ROLLBACK [ WORK | TRANSACTION ] TO [ SAVEPOINT ] savepoint_name
SAVEPOINT
Определите новую точку сохранения в текущей транзакции.
SAVEPOINT savepoint_name
ВЫБРАТЬ
Получить строки из таблицы или представления.
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ] * | expression [ AS output_name ] [, ...] [ FROM from_item [, ...] ] [ WHERE condition ] [ GROUP BY expression [, ...] ] [ HAVING condition [, ...] ] [ { UNION | INTERSECT | EXCEPT } [ ALL ] select ] [ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ] [ LIMIT { count | ALL } ] [ OFFSET start ] [ FOR UPDATE [ OF table_name [, ...] ] ]
Где from_item может быть одним из:
[ ONLY ] table_name [ * ] [ [ AS ] alias [ ( column_alias [, ...] ) ] ] ( select ) [ AS ] alias [ ( column_alias [, ...] ) ] function_name ( [ argument [, ...] ] ) [ AS ] alias [ ( column_alias [, ...] | column_definition [, ...] ) ] function_name ( [ argument [, ...] ] ) AS ( column_definition [, ...] ) from_item [ NATURAL ] join_type from_item [ ON join_condition | USING ( join_column [, ...] ) ]
ВЫБРАТЬ В
Определите новую таблицу из результатов запроса.
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ] * | expression [ AS output_name ] [, ...] INTO [ TEMPORARY | TEMP ] [ TABLE ] new_table [ FROM from_item [, ...] ] [ WHERE condition ] [ GROUP BY expression [, ...] ] [ HAVING condition [, ...] ] [ { UNION | INTERSECT | EXCEPT } [ ALL ] select ] [ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ] [ LIMIT { count | ALL } ] [ OFFSET start ] [ FOR UPDATE [ OF table_name [, ...] ] ]
ЗАДАВАТЬ
Измените параметр времени выполнения.
SET [ SESSION | LOCAL ] name { TO | = } { value | 'value' | DEFAULT } SET [ SESSION | LOCAL ] TIME ZONE { time_zone | LOCAL | DEFAULT }
УСТАНОВИТЬ ОГРАНИЧЕНИЯ
Установите режимы проверки ограничений для текущей транзакции.
SET CONSTRAINTS { ALL | name [, ...] } { DEFERRED | IMMEDIATE }
УСТАНОВКА АВТОРИЗАЦИИ СЕССИИ
Установите идентификатор пользователя сеанса и текущий идентификатор пользователя текущего сеанса.
SET [ SESSION | LOCAL ] SESSION AUTHORIZATION username SET [ SESSION | LOCAL ] SESSION AUTHORIZATION DEFAULT RESET SESSION AUTHORIZATION
УСТАНОВИТЬ СДЕЛКУ
Установите характеристики текущей транзакции.
SET TRANSACTION transaction_mode [, ...] SET SESSION CHARACTERISTICS AS TRANSACTION transaction_mode [, ...]
Где транзакция_мод является одним из –
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED } READ WRITE | READ ONLY
ШОУ
Показать значение параметра времени выполнения.
SHOW name
SHOW ALL
НАЧАТЬ СДЕЛКУ
Начать блок транзакции.
START TRANSACTION [ transaction_mode [, ...] ]
Где транзакция_мод является одним из –
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED } READ WRITE | READ ONLY
TRUNCATE
Пустой стол.
TRUNCATE [ TABLE ] name
UNLISTEN
Хватит слушать уведомления.
UNLISTEN { name | * }
ОБНОВИТЬ
Обновите строки таблицы.
UPDATE [ ONLY ] table SET column = { expression | DEFAULT } [, ...] [ FROM from_list ] [ WHERE condition ]
ВАКУУМНАЯ
Сборка мусора и при необходимости анализ базы данных.
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ table ] VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] ANALYZE [ table [ (column [, ...] ) ] ]
PostgreSQL – тип данных
В этой главе мы обсудим типы данных, используемые в PostgreSQL. При создании таблицы для каждого столбца вы указываете тип данных, т. Е. Какой тип данных вы хотите хранить в полях таблицы.
Это дает несколько преимуществ –
-
Согласованность. Операции со столбцами одного типа данных дают согласованные результаты и обычно являются самыми быстрыми.
-
Валидация – правильное использование типов данных подразумевает проверку формата данных и отклонение данных вне области действия типа данных.
-
Компактность – поскольку столбец может хранить значения одного типа, он хранится в компактном виде.
-
Производительность – правильное использование типов данных обеспечивает наиболее эффективное хранение данных. Сохраненные значения можно быстро обработать, что повышает производительность.
Согласованность. Операции со столбцами одного типа данных дают согласованные результаты и обычно являются самыми быстрыми.
Валидация – правильное использование типов данных подразумевает проверку формата данных и отклонение данных вне области действия типа данных.
Компактность – поскольку столбец может хранить значения одного типа, он хранится в компактном виде.
Производительность – правильное использование типов данных обеспечивает наиболее эффективное хранение данных. Сохраненные значения можно быстро обработать, что повышает производительность.
PostgreSQL поддерживает широкий набор типов данных. Кроме того, пользователи могут создавать свои собственные типы данных с помощью команды CREATE TYPE SQL. В PostgreSQL существуют разные категории типов данных. Они обсуждаются ниже.
Числовые Типы
Числовые типы состоят из двухбайтовых, четырехбайтовых и восьмибайтовых целых чисел, четырехбайтовых и восьмибайтовых чисел с плавающей запятой и десятичных дробей с выбираемой точностью. В следующей таблице перечислены доступные типы.
| название | Размер хранилища | Описание | Спектр |
|---|---|---|---|
| SMALLINT | 2 байта | целое число малого диапазона | От -32768 до +32767 |
| целое число | 4 байта | типичный выбор для целого числа | От -2147483648 до +2147483647 |
| BIGINT | 8 байт | большое целое число | От -9223372036854775808 до 9223372036854775807 |
| десятичный | переменная | указанная пользователем точность, точная | до 131072 цифр перед десятичной точкой; до 16383 знаков после запятой |
| числовой | переменная | указанная пользователем точность, точная | до 131072 цифр перед десятичной точкой; до 16383 знаков после запятой |
| реальный | 4 байта | переменная точность, неточная | Точность 6 десятичных цифр |
| двойная точность | 8 байт | переменная точность, неточная | Точность 15 десятичных цифр |
| smallserial | 2 байта | небольшое автоинкрементное целое число | От 1 до 32767 |
| последовательный | 4 байта | автоинкрементное целое число | 1 до 2147483647 |
| bigserial | 8 байт | большое автоинкрементное целое число | 1 до 9223372036854775807 |
Денежные Типы
Тип money хранит сумму в валюте с фиксированной дробной точностью. Значения типов данных numeric, int и bigint могут быть приведены к деньгам . Использование чисел с плавающей точкой не рекомендуется для обработки денег из-за возможной ошибки округления.
| название | Размер хранилища | Описание | Спектр |
|---|---|---|---|
| Деньги | 8 байт | сумма в валюте | От -92233720368547758.08 до +92233720368547758.07 |
Типы персонажей
В приведенной ниже таблице перечислены типы символов общего назначения, доступные в PostgreSQL.
| С. Нет. | Имя и описание |
|---|---|
| 1 |
различные символы (n), varchar (n) переменная длина с ограничением |
| 2 |
символ (n), символ (n) фиксированная длина, с подкладкой |
| 3 |
текст переменная неограниченная длина |
различные символы (n), varchar (n)
переменная длина с ограничением
символ (n), символ (n)
фиксированная длина, с подкладкой
текст
переменная неограниченная длина
Двоичные типы данных
Тип данных bytea позволяет хранить двоичные строки, как показано в таблице ниже.
| название | Размер хранилища | Описание |
|---|---|---|
| BYTEA | 1 или 4 байта плюс фактическая двоичная строка | двоичная строка переменной длины |
Типы даты / времени
PostgreSQL поддерживает полный набор типов даты и времени SQL, как показано в таблице ниже. Даты считаются по григорианскому календарю. Здесь все типы имеют разрешение 1 микросекунда / 14 цифр, кроме типа даты , разрешение которого – день .
| название | Размер хранилища | Описание | Низкое значение | Высокое значение |
|---|---|---|---|---|
| отметка времени [(p)] [без часового пояса] | 8 байт | дата и время (без часового пояса) | 4713 г. до н.э. | 294276 н.э. |
| TIMESTAMPTZ | 8 байт | дата и время с часовым поясом | 4713 г. до н.э. | 294276 н.э. |
| Дата | 4 байта | дата (без времени суток) | 4713 г. до н.э. | 5874897 н.э. |
| время [(p)] [без часового пояса] | 8 байт | время суток (без даты) | 00:00:00 | 24:00:00 |
| время [(p)] с часовым поясом | 12 байт | только время суток, с часовым поясом | 00: 00: 00 + 1459 | 24: 00: 00-1459 |
| интервал [поля] [(p)] | 12 байт | интервал времени | -178000000 лет | 178000000 лет |
Логический тип
PostgreSQL предоставляет стандартный тип SQL Boolean. Тип данных Boolean может иметь состояния true , false и третье состояние неизвестно , которое представлено нулевым значением SQL.
| название | Размер хранилища | Описание |
|---|---|---|
| логический | 1 байт | состояние истинного или ложного |
Перечислимый тип
Перечислимые (enum) типы – это типы данных, которые содержат статический упорядоченный набор значений. Они эквивалентны типам enum, поддерживаемым во многих языках программирования.
В отличие от других типов, перечисляемые типы необходимо создавать с помощью команды CREATE TYPE. Этот тип используется для хранения статического упорядоченного набора значений. Например, направления по компасу, например, СЕВЕР, ЮГ, ВОСТОК и ЗАПАД или дни недели, как показано ниже –
CREATE TYPE week AS ENUM ('Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun');
Перечисленные, однажды созданные, могут использоваться как любые другие типы.
Геометрический тип
Геометрические типы данных представляют собой двумерные пространственные объекты. Самый фундаментальный тип, точка, формирует основу для всех других типов.
| название | Размер хранилища | Представление | Описание |
|---|---|---|---|
| точка | 16 байт | Точка на плоскости | (Х, у) |
| линия | 32 байта | Бесконечная линия (не полностью реализована) | ((X1, y1), (х2, у2)) |
| LSEG | 32 байта | Конечный отрезок | ((X1, y1), (х2, у2)) |
| коробка | 32 байта | Прямоугольная коробка | ((X1, y1), (х2, у2)) |
| дорожка | 16 + 16n байт | Закрытый путь (похож на полигон) | ((X1, y1), …) |
| дорожка | 16 + 16n байт | Открытый путь | [(X1, y1), …] |
| многоугольник | 40 + 16n | Полигон (похож на замкнутый путь) | ((X1, y1), …) |
| круг | 24 байта | Круг | <(x, y), r> (центральная точка и радиус) |
Тип сетевого адреса
PostgreSQL предлагает типы данных для хранения IPv4, IPv6 и MAC-адресов. Лучше использовать эти типы вместо обычных текстовых типов для хранения сетевых адресов, потому что эти типы предлагают проверку ошибок ввода и специализированные операторы и функции.
| название | Размер хранилища | Описание |
|---|---|---|
| CIDR | 7 или 19 байт | Сети IPv4 и IPv6 |
| инет | 7 или 19 байт | IPv4 и IPv6 хосты и сети |
| MacAddr | 6 байт | MAC-адреса |
Тип битовой строки
Типы битовых строк используются для хранения битовых масок. Это либо 0, либо 1. Существует два типа битов SQL: bit (n) и bitinging (n) , где n – положительное целое число.
Тип текстового поиска
Этот тип поддерживает полнотекстовый поиск, который представляет собой поиск в наборе документов на естественном языке для поиска документов, которые лучше всего соответствуют запросу. Для этого есть два типа данных:
| С. Нет. | Имя и описание |
|---|---|
| 1 |
поисковый вектор Это отсортированный список отдельных слов, которые были нормализованы для объединения различных вариантов одного и того же слова, называемые «лексемы». |
| 2 |
tsquery Это хранит лексемы, которые нужно искать, и объединяет их, соблюдая логические операторы & (AND), | (Или) и! (НЕ). Круглые скобки могут быть использованы для принудительной группировки операторов. |
поисковый вектор
Это отсортированный список отдельных слов, которые были нормализованы для объединения различных вариантов одного и того же слова, называемые «лексемы».
tsquery
Это хранит лексемы, которые нужно искать, и объединяет их, соблюдая логические операторы & (AND), | (Или) и! (НЕ). Круглые скобки могут быть использованы для принудительной группировки операторов.
Тип UUID
UUID (универсальные уникальные идентификаторы) записывается в виде последовательности шестнадцатеричных цифр в нижнем регистре, в нескольких группах, разделенных дефисами, в частности, в группе из восьми цифр, за которой следуют три группы из четырех цифр, за которыми следует группа из 12 цифр, для всего 32 цифры, представляющие 128 бит.
Пример UUID – 550e8400-e29b-41d4-a716-446655440000
Тип XML
Тип данных XML может использоваться для хранения данных XML. Для хранения данных XML сначала необходимо создать значения XML с помощью функции xmlparse следующим образом:
XMLPARSE (DOCUMENT '<?xml version="1.0"?> <tutorial> <title>PostgreSQL Tutorial </title> <topics>...</topics> </tutorial>') XMLPARSE (CONTENT 'xyz<foo>bar</foo><bar>foo</bar>')
Тип JSON
Тип данных json может использоваться для хранения данных JSON (JavaScript Object Notation). Такие данные также могут быть сохранены в виде текста , но у типа данных json есть преимущество проверки того, что каждое сохраненное значение является допустимым значением JSON. Также доступны связанные вспомогательные функции, которые можно использовать непосредственно для обработки типа данных JSON следующим образом.
| пример | Пример результата |
|---|---|
| array_to_json ( ‘{{1,5}, {99100}}’ :: Int []) | [[1,5], [99100]] |
| row_to_json (строка (1, ‘Foo’)) | { “F1”: 1, “F2”: “Foo”} |
Тип массива
PostgreSQL дает возможность определять столбец таблицы как многомерный массив переменной длины. Могут быть созданы массивы любого встроенного или определенного пользователем базового типа, типа enum или составного типа.
Декларация массивов
Тип массива может быть объявлен как
CREATE TABLE monthly_savings ( name text, saving_per_quarter integer[], scheme text[][] );
или используя ключевое слово “ARRAY” как
CREATE TABLE monthly_savings ( name text, saving_per_quarter integer ARRAY[4], scheme text[][] );
Вставка значений
Значения массива могут быть вставлены в виде литеральной константы, заключая значения элементов в фигурные скобки и разделяя их запятыми. Пример показан ниже –
INSERT INTO monthly_savings VALUES (‘Manisha’, ‘{20000, 14600, 23500, 13250}’, ‘{{“FD”, “MF”}, {“FD”, “Property”}}’);
Доступ к массивам
Пример доступа к массивам приведен ниже. Приведенная ниже команда выберет людей, чьи сбережения больше во втором квартале, чем в четвертом квартале.
SELECT name FROM monhly_savings WHERE saving_per_quarter[2] > saving_per_quarter[4];
Модификация массивов
Пример изменения массивов приведен ниже.
UPDATE monthly_savings SET saving_per_quarter = '{25000,25000,27000,27000}' WHERE name = 'Manisha';
или используя синтаксис выражения ARRAY –
UPDATE monthly_savings SET saving_per_quarter = ARRAY[25000,25000,27000,27000] WHERE name = 'Manisha';
Поиск массивов
Пример поиска в массивах приведен ниже.
SELECT * FROM monthly_savings WHERE saving_per_quarter[1] = 10000 OR saving_per_quarter[2] = 10000 OR saving_per_quarter[3] = 10000 OR saving_per_quarter[4] = 10000;
Если размер массива известен, можно использовать метод поиска, указанный выше. Иначе, следующий пример показывает, как искать, когда размер неизвестен.
SELECT * FROM monthly_savings WHERE 10000 = ANY (saving_per_quarter);
Композитные типы
Этот тип представляет список имен полей и их типов данных, т. Е. Структуру строки или записи таблицы.
Декларация составных типов
В следующем примере показано, как объявить составной тип
CREATE TYPE inventory_item AS ( name text, supplier_id integer, price numeric );
Этот тип данных может использоваться в таблицах создания, как показано ниже:
CREATE TABLE on_hand ( item inventory_item, count integer );
Ввод композитного значения
Составные значения могут быть вставлены в виде литеральной константы, заключая значения полей в круглые скобки и разделяя их запятыми. Пример показан ниже –
INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
Это действительно для описанного выше инвентаризационного элемента. Ключевое слово ROW на самом деле является необязательным, если у вас есть более одного поля в выражении.
Доступ к составным типам
Чтобы получить доступ к полю составного столбца, используйте точку, за которой следует имя поля, подобно выбору поля из имени таблицы. Например, чтобы выбрать некоторые подполя из нашей таблицы примеров on_hand, запрос будет выглядеть так, как показано ниже –
SELECT (item).name FROM on_hand WHERE (item).price > 9.99;
Вы даже можете использовать имя таблицы (например, в многопользовательском запросе), например так:
SELECT (on_hand.item).name FROM on_hand WHERE (on_hand.item).price > 9.99;
Типы диапазонов
Типы диапазона представляют собой типы данных, которые используют диапазон данных. Типом диапазона могут быть дискретные диапазоны (например, все целочисленные значения от 1 до 10) или непрерывные диапазоны (например, любой момент времени между 10:00 и 11:00).
Доступные встроенные типы диапазонов включают следующие диапазоны –
-
int4range – диапазон целого числа
-
int8range – диапазон от bigint
-
numrange – диапазон числовых значений
-
tsrange – диапазон меток времени без часового пояса
-
tstzrange – диапазон меток времени с часовым поясом
-
диапазон дат – диапазон дат
int4range – диапазон целого числа
int8range – диапазон от bigint
numrange – диапазон числовых значений
tsrange – диапазон меток времени без часового пояса
tstzrange – диапазон меток времени с часовым поясом
диапазон дат – диапазон дат
Пользовательские типы диапазонов могут быть созданы, чтобы сделать доступными новые типы диапазонов, такие как диапазоны IP-адресов, использующие тип inet в качестве базы, или диапазоны с плавающей точкой, использующие тип данных float в качестве базы.
Типы диапазонов поддерживают включающие и исключающие границы диапазона, используя символы [] и () соответственно. Например, «[4,9)» представляет все целые числа, начиная с 4 и включая до 9, но не включая 9.
Типы идентификаторов объектов
Идентификаторы объектов (OID) используются внутри PostgreSQL в качестве первичных ключей для различных системных таблиц. Если указано WITH OIDS или включена переменная конфигурации default_with_oids , только тогда в таких случаях OID добавляются в созданные пользователем таблицы. В следующей таблице перечислены несколько типов псевдонимов. Типы псевдонимов OID не имеют собственных операций, за исключением специализированных подпрограмм ввода и вывода.
| название | Рекомендации | Описание | Пример значения |
|---|---|---|---|
| подъязычная | любой | числовой идентификатор объекта | 564182 |
| regproc | pg_proc | имя функции | сумма |
| regprocedure | pg_proc | функция с типами аргументов | сумма (int4) |
| regoper | pg_operator | имя оператора | + |
| regoperator | pg_operator | оператор с типами аргументов | * (целое число, целое число) или – (НЕТ, целое число) |
| regclass | pg_class | имя отношения | pg_type |
| regtype | pg_type | имя типа данных | целое число |
| regconfig | pg_ts_config | конфигурация текстового поиска | английский |
| regdictionary | pg_ts_dict | словарь текстового поиска | просто |
Псевдо-типы
Система типов PostgreSQL содержит ряд записей специального назначения, которые в совокупности называются псевдотипами. Псевдотип нельзя использовать в качестве типа данных столбца, но его можно использовать для объявления аргумента функции или типа результата.
В приведенной ниже таблице перечислены существующие псевдотипы.
| С. Нет. | Имя и описание |
|---|---|
| 1 |
любой Указывает, что функция принимает любой тип входных данных. |
| 2 |
anyelement Указывает, что функция принимает любой тип данных. |
| 3 |
anyarray Указывает, что функция принимает любой тип данных массива. |
| 4 |
anynonarray Указывает, что функция принимает любой тип данных, отличный от массива. |
| 5 |
anyenum Указывает, что функция принимает любой тип данных enum. |
| 6 |
anyrange Указывает, что функция принимает любой тип данных диапазона. |
| 7 |
CString Указывает, что функция принимает или возвращает строку C с нулевым символом в конце. |
| 8 |
внутренний Указывает, что функция принимает или возвращает внутренний тип данных сервера. |
| 9 |
language_handler Обработчик вызова процедурного языка объявляется как возвращающий language_handler. |
| 10 |
fdw_handler Обработчик обёртки сторонних данных объявляется как возвращающий fdw_handler. |
| 11 |
запись Определяет функцию, возвращающую неопределенный тип строки. |
| 12 |
спусковой крючок Объявлена триггерная функция для возврата триггера. |
| 13 |
недействительным Указывает, что функция не возвращает значения. |
любой
Указывает, что функция принимает любой тип входных данных.
anyelement
Указывает, что функция принимает любой тип данных.
anyarray
Указывает, что функция принимает любой тип данных массива.
anynonarray
Указывает, что функция принимает любой тип данных, отличный от массива.
anyenum
Указывает, что функция принимает любой тип данных enum.
anyrange
Указывает, что функция принимает любой тип данных диапазона.
CString
Указывает, что функция принимает или возвращает строку C с нулевым символом в конце.
внутренний
Указывает, что функция принимает или возвращает внутренний тип данных сервера.
language_handler
Обработчик вызова процедурного языка объявляется как возвращающий language_handler.
fdw_handler
Обработчик обёртки сторонних данных объявляется как возвращающий fdw_handler.
запись
Определяет функцию, возвращающую неопределенный тип строки.
спусковой крючок
Объявлена триггерная функция для возврата триггера.
недействительным
Указывает, что функция не возвращает значения.
PostgreSQL – СОЗДАТЬ базу данных
В этой главе рассказывается о том, как создать новую базу данных в вашем PostgreSQL. PostgreSQL предоставляет два способа создания новой базы данных –
- Используя CREATE DATABASE, команду SQL.
- Используя созданный исполняемый файл командной строки.
Использование CREATE DATABASE
Эта команда создаст базу данных из командной строки PostgreSQL, но у вас должна быть соответствующая привилегия для создания базы данных. По умолчанию новая база данных будет создана путем клонирования стандартной системной базы данных template1 .
Синтаксис
Основной синтаксис оператора CREATE DATABASE следующий:
CREATE DATABASE dbname;
где dbname – это имя базы данных, которую нужно создать.
пример
Ниже приведен простой пример, который создаст testdb в вашей схеме PostgreSQL
postgres=# CREATE DATABASE testdb; postgres-#
Использование команды creatb
Исполняемый файл командной строки PostgreSQL создалb – оболочка для команды SQL CREATE DATABASE . Единственная разница между этой командой и командой SQL CREATE DATABASE заключается в том, что первую можно запустить непосредственно из командной строки, и она позволяет добавлять комментарии в базу данных, все в одной команде.
Синтаксис
Синтаксис для созданного B , как показано ниже –
createdb [option...] [dbname [description]]
параметры
В приведенной ниже таблице перечислены параметры с их описаниями.
| С. Нет. | Параметр и описание |
|---|---|
| 1 |
имя_бд Имя базы данных для создания. |
| 2 |
описание Определяет комментарий, который будет связан с вновь созданной базой данных. |
| 3 |
опции аргументы командной строки, которые созданныйb принимает. |
имя_бд
Имя базы данных для создания.
описание
Определяет комментарий, который будет связан с вновь созданной базой данных.
опции
аргументы командной строки, которые созданныйb принимает.
Опции
В следующей таблице перечислены аргументы командной строки, которые принимает createb –
| С. Нет. | Вариант и описание |
|---|---|
| 1 |
-D табличное пространство Задает табличное пространство по умолчанию для базы данных. |
| 2 |
-e Выводим команды, которые создалb генерирует и отправляет на сервер. |
| 3 |
-Е кодировка Определяет схему кодировки символов, которая будет использоваться в этой базе данных. |
| 4 |
-l локаль Определяет язык, который будет использоваться в этой базе данных. |
| 5 |
-Т шаблон Определяет базу данных шаблонов, из которой можно построить эту базу данных. |
| 6 |
–Помогите Показать справку об аргументах командной строки созданной командыb и выйти. |
| 7 |
-х хозяин Указывает имя хоста компьютера, на котором работает сервер. |
| 8 |
порт Указывает порт TCP или расширение файла локального сокета домена Unix, на котором сервер прослушивает соединения. |
| 9 |
-U имя пользователя Имя пользователя для подключения как. |
| 10 |
-w Никогда не выдавайте запрос пароля. |
| 11 |
-W Принудительно создайтеb для запроса пароля перед подключением к базе данных. |
-D табличное пространство
Задает табличное пространство по умолчанию для базы данных.
-e
Выводим команды, которые создалb генерирует и отправляет на сервер.
-Е кодировка
Определяет схему кодировки символов, которая будет использоваться в этой базе данных.
-l локаль
Определяет язык, который будет использоваться в этой базе данных.
-Т шаблон
Определяет базу данных шаблонов, из которой можно построить эту базу данных.
–Помогите
Показать справку об аргументах командной строки созданной командыb и выйти.
-х хозяин
Указывает имя хоста компьютера, на котором работает сервер.
порт
Указывает порт TCP или расширение файла локального сокета домена Unix, на котором сервер прослушивает соединения.
-U имя пользователя
Имя пользователя для подключения как.
-w
Никогда не выдавайте запрос пароля.
-W
Принудительно создайтеb для запроса пароля перед подключением к базе данных.
Откройте командную строку и перейдите в каталог, где установлен PostgreSQL. Перейдите в каталог bin и выполните следующую команду, чтобы создать базу данных.
createdb -h localhost -p 5432 -U postgres testdb password ******
Приведенная выше команда запросит у вас пароль администратора PostgreSQL, который по умолчанию является postgres . Следовательно, введите пароль и приступайте к созданию новой базы данных.
После того, как база данных создана с использованием любого из вышеупомянутых методов, вы можете проверить ее в списке баз данных, используя команду l , т.е. команду backslash el следующим образом:
postgres-# l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+---------+-------+----------------------- postgres | postgres | UTF8 | C | C | template0 | postgres | UTF8 | C | C | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | C | C | =c/postgres + | | | | | postgres=CTc/postgres testdb | postgres | UTF8 | C | C | (4 rows) postgres-#
PostgreSQL – ВЫБРАТЬ базу данных
В этой главе описываются различные способы доступа к базе данных. Предположим, что мы уже создали базу данных в нашей предыдущей главе. Вы можете выбрать базу данных одним из следующих способов:
- База данных SQL Prompt
- Командная строка ОС
База данных SQL Prompt
Предположим, что вы уже запустили свой клиент PostgreSQL и попали в следующую подсказку SQL –
postgres=#
Вы можете проверить список доступных баз данных, используя команду l , т.е. команду backslash el следующим образом:
postgres-# l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+---------+-------+----------------------- postgres | postgres | UTF8 | C | C | template0 | postgres | UTF8 | C | C | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | C | C | =c/postgres + | | | | | postgres=CTc/postgres testdb | postgres | UTF8 | C | C | (4 rows) postgres-#
Теперь введите следующую команду для подключения / выбора нужной базы данных; здесь мы подключимся к базе данных testdb .
postgres=# c testdb; psql (9.2.4) Type "help" for help. You are now connected to database "testdb" as user "postgres". testdb=#
Командная строка ОС
Вы можете выбрать свою базу данных из самой командной строки во время входа в свою базу данных. Ниже приведен простой пример –
psql -h localhost -p 5432 -U postgress testdb Password for user postgress: **** psql (9.2.4) Type "help" for help. You are now connected to database "testdb" as user "postgres". testdb=#
Теперь вы вошли в PostgreSQL testdb и готовы выполнять свои команды внутри testdb. Для выхода из базы данных вы можете использовать команду q.
PostgreSQL – DROP база данных
В этой главе мы обсудим, как удалить базу данных в PostgreSQL. Есть два варианта удаления базы данных –
- Используя DROP DATABASE, команду SQL.
- Используя dropdb исполняемый файл командной строки.
Будьте осторожны, прежде чем использовать эту операцию, потому что удаление существующей базы данных приведет к потере полной информации, хранящейся в базе данных.
Использование DROP DATABASE
Эта команда удаляет базу данных. Он удаляет записи каталога для базы данных и удаляет каталог, содержащий данные. Он может быть выполнен только владельцем базы данных. Эта команда не может быть выполнена, пока вы или кто-либо еще подключен к целевой базе данных (подключитесь к postgres или любой другой базе данных, чтобы выполнить эту команду).
Синтаксис
Синтаксис для DROP DATABASE приведен ниже –
DROP DATABASE [ IF EXISTS ] name
параметры
В таблице приведены параметры с их описаниями.
| С. Нет. | Параметр и описание |
|---|---|
| 1 |
ЕСЛИ СУЩЕСТВУЕТ Не выдавайте ошибку, если база данных не существует. В этом случае выдается уведомление. |
| 2 |
название Имя базы данных для удаления. |
ЕСЛИ СУЩЕСТВУЕТ
Не выдавайте ошибку, если база данных не существует. В этом случае выдается уведомление.
название
Имя базы данных для удаления.
Мы не можем удалить базу данных, которая имеет какие-либо открытые соединения, включая наше собственное соединение с psql или pgAdmin III . Мы должны переключиться на другую базу данных или шаблон1, если мы хотим удалить базу данных, к которой мы сейчас подключены. Таким образом, может быть удобнее использовать программу dropdb , которая является оберткой для этой команды.
пример
Ниже приведен простой пример, который удалит testdb из вашей схемы PostgreSQL:
postgres=# DROP DATABASE testdb; postgres-#
Использование команды dropdb
Исполняемый файл командной строки PostgresSQL dropdb – это оболочка командной строки для команды SQL DROP DATABASE . Нет эффективной разницы между удалением баз данных с помощью этой утилиты и других методов доступа к серверу. dropdb уничтожает существующую базу данных PostgreSQL. Пользователь, который выполняет эту команду, должен быть суперпользователем базы данных или владельцем базы данных.
Синтаксис
Синтаксис для dropdb , как показано ниже –
dropdb [option...] dbname
параметры
В следующей таблице перечислены параметры с их описаниями
| С. Нет. | Параметр и описание |
|---|---|
| 1 |
имя_бд Имя базы данных, которая будет удалена. |
| 2 |
вариант аргументы командной строки, которые принимает dropdb. |
имя_бд
Имя базы данных, которая будет удалена.
вариант
аргументы командной строки, которые принимает dropdb.
Опции
В следующей таблице перечислены аргументы командной строки, которые принимает dropdb –
| С. Нет. | Вариант и описание |
|---|---|
| 1 |
-e Показывает команды, отправляемые на сервер. |
| 2 |
-я Выдает запрос подтверждения, прежде чем делать что-либо разрушительное. |
| 3 |
-V Распечатайте версию dropdb и выйдите. |
| 4 |
–Если-существует Не выдавайте ошибку, если база данных не существует. В этом случае выдается уведомление. |
| 5 |
–Помогите Показать справку об аргументах командной строки dropdb и завершиться. |
| 6 |
-х хозяин Указывает имя хоста компьютера, на котором работает сервер. |
| 7 |
порт Указывает порт TCP или расширение файла локального сокета домена UNIX, на котором сервер прослушивает соединения. |
| 8 |
-U имя пользователя Имя пользователя для подключения как. |
| 9 |
-w Никогда не выдавайте запрос пароля. |
| 10 |
-W Заставьте dropdb запрашивать пароль перед подключением к базе данных. |
| 11 |
–maintenance-DB = имя_бд Задает имя базы данных, к которой нужно подключиться, чтобы удалить целевую базу данных. |
-e
Показывает команды, отправляемые на сервер.
-я
Выдает запрос подтверждения, прежде чем делать что-либо разрушительное.
-V
Распечатайте версию dropdb и выйдите.
–Если-существует
Не выдавайте ошибку, если база данных не существует. В этом случае выдается уведомление.
–Помогите
Показать справку об аргументах командной строки dropdb и завершиться.
-х хозяин
Указывает имя хоста компьютера, на котором работает сервер.
порт
Указывает порт TCP или расширение файла локального сокета домена UNIX, на котором сервер прослушивает соединения.
-U имя пользователя
Имя пользователя для подключения как.
-w
Никогда не выдавайте запрос пароля.
-W
Заставьте dropdb запрашивать пароль перед подключением к базе данных.
–maintenance-DB = имя_бд
Задает имя базы данных, к которой нужно подключиться, чтобы удалить целевую базу данных.
пример
В следующем примере демонстрируется удаление базы данных из командной строки ОС –
dropdb -h localhost -p 5432 -U postgress testdb Password for user postgress: ****
Приведенная выше команда удаляет базу данных testdb . Здесь я использовал имя пользователя postgres (находится в pg_roles шаблона template1) для удаления базы данных.
PostgreSQL – CREATE Table
Оператор PostgreSQL CREATE TABLE используется для создания новой таблицы в любой из заданных баз данных.
Синтаксис
Основной синтаксис оператора CREATE TABLE следующий:
CREATE TABLE table_name( column1 datatype, column2 datatype, column3 datatype, ..... columnN datatype, PRIMARY KEY( one or more columns ) );
CREATE TABLE – это ключевое слово, указывающее системе баз данных на создание новой таблицы. Уникальное имя или идентификатор таблицы следует за оператором CREATE TABLE. Первоначально пустая таблица в текущей базе данных принадлежит пользователю, выполняющему команду.
Затем в скобках приводится список, определяющий каждый столбец таблицы и тип данных. Синтаксис станет понятен с примером, приведенным ниже.
Примеры
Ниже приведен пример, который создает таблицу COMPANY с ID в качестве первичного ключа, а NOT NULL – это ограничения, показывающие, что эти поля не могут иметь значение NULL при создании записей в этой таблице:
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
Давайте создадим еще одну таблицу, которую мы будем использовать в наших упражнениях в последующих главах –
CREATE TABLE DEPARTMENT( ID INT PRIMARY KEY NOT NULL, DEPT CHAR(50) NOT NULL, EMP_ID INT NOT NULL );
Вы можете проверить, была ли ваша таблица создана успешно, с помощью команды d , которая будет использоваться для вывода списка всех таблиц в присоединенной базе данных.
testdb-# d
Приведенный выше оператор PostgreSQL даст следующий результат:
List of relations Schema | Name | Type | Owner --------+------------+-------+---------- public | company | table | postgres public | department | table | postgres (2 rows)
Используйте d tablename для описания каждой таблицы, как показано ниже –
testdb-# d company
Приведенный выше оператор PostgreSQL даст следующий результат:
Table "public.company"
Column | Type | Modifiers
-----------+---------------+-----------
id | integer | not null
name | text | not null
age | integer | not null
address | character(50) |
salary | real |
join_date | date |
Indexes:
"company_pkey" PRIMARY KEY, btree (id)
PostgreSQL – DROP Table
Оператор PostgreSQL DROP TABLE используется для удаления определения таблицы и всех связанных с ней данных, индексов, правил, триггеров и ограничений для этой таблицы.
Вы должны быть осторожны при использовании этой команды, потому что после удаления таблицы вся доступная в ней информация также будет потеряна навсегда.
Синтаксис
Основной синтаксис оператора DROP TABLE следующий:
DROP TABLE table_name;
пример
Мы создали таблицы DEPARTMENT и COMPANY в предыдущей главе. Сначала проверьте эти таблицы (используйте d для просмотра таблиц) –
testdb-# d
Это даст следующий результат –
List of relations Schema | Name | Type | Owner --------+------------+-------+---------- public | company | table | postgres public | department | table | postgres (2 rows)
Это означает, что таблицы DEPARTMENT и COMPANY присутствуют. Итак, давайте бросим их следующим образом –
testdb=# drop table department, company;
Это даст следующий результат –
DROP TABLE testdb=# d relations found. testdb=#
Возвращенное сообщение DROP TABLE указывает, что команда удаления выполнена успешно.
PostgreSQL – схема
Схема – это именованная коллекция таблиц. Схема также может содержать представления, индексы, последовательности, типы данных, операторы и функции. Схемы аналогичны каталогам на уровне операционной системы, за исключением того, что схемы не могут быть вложенными. Оператор PostgreSQL CREATE SCHEMA создает схему.
Синтаксис
Основной синтаксис CREATE SCHEMA следующий:
CREATE SCHEMA name;
Где имя – это имя схемы.
Синтаксис для создания таблицы в схеме
Основной синтаксис для создания таблицы в схеме следующий:
CREATE TABLE myschema.mytable ( ... );
пример
Давайте посмотрим пример для создания схемы. Подключитесь к базе данных testdb и создайте схему myschema следующим образом –
testdb=# create schema myschema; CREATE SCHEMA
Сообщение «CREATE SCHEMA» означает, что схема создана успешно.
Теперь давайте создадим таблицу в приведенной выше схеме следующим образом:
testdb=# create table myschema.company( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
Это создаст пустую таблицу. Вы можете проверить таблицу, созданную с помощью команды, приведенной ниже –
testdb=# select * from myschema.company;
Это даст следующий результат –
id | name | age | address | salary ----+------+-----+---------+-------- (0 rows)
Синтаксис для удаления схемы
Чтобы удалить схему, если она пуста (все объекты в ней удалены), используйте команду –
DROP SCHEMA myschema;
Чтобы удалить схему, включающую все содержащиеся в ней объекты, используйте команду –
DROP SCHEMA myschema CASCADE;
Преимущества использования схемы
-
Это позволяет многим пользователям использовать одну базу данных, не мешая друг другу.
-
Он организует объекты базы данных в логические группы, чтобы сделать их более управляемыми.
-
Сторонние приложения могут быть помещены в отдельные схемы, чтобы они не конфликтовали с именами других объектов.
Это позволяет многим пользователям использовать одну базу данных, не мешая друг другу.
Он организует объекты базы данных в логические группы, чтобы сделать их более управляемыми.
Сторонние приложения могут быть помещены в отдельные схемы, чтобы они не конфликтовали с именами других объектов.
PostgreSQL – INSERT Query
Инструкция PostgreSQL INSERT INTO позволяет вставлять новые строки в таблицу. Можно вставить одну строку за раз или несколько строк в результате запроса.
Синтаксис
Основной синтаксис оператора INSERT INTO следующий:
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN) VALUES (value1, value2, value3,...valueN);
-
Здесь column1, column2, … columnN – это имена столбцов в таблице, в которую вы хотите вставить данные.
-
Имена целевых столбцов могут быть перечислены в любом порядке. Значения, предоставляемые предложением или запросом VALUES, связаны с явным или неявным списком столбцов слева направо.
Здесь column1, column2, … columnN – это имена столбцов в таблице, в которую вы хотите вставить данные.
Имена целевых столбцов могут быть перечислены в любом порядке. Значения, предоставляемые предложением или запросом VALUES, связаны с явным или неявным списком столбцов слева направо.
Вам может не потребоваться указывать имя столбца (-ов) в запросе SQL, если вы добавляете значения для всех столбцов таблицы. Однако убедитесь, что порядок значений соответствует порядку столбцов в таблице. Синтаксис SQL INSERT INTO будет выглядеть следующим образом:
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);
Выход
В следующей таблице приведены выходные сообщения и их значение.
| С. Нет. | Выходное сообщение и описание |
|---|---|
| 1 |
ВСТАВИТЬ oid 1 Сообщение возвращается, если была вставлена только одна строка. oid – это числовой OID вставленной строки. |
| 2 |
ВСТАВИТЬ 0 # Сообщение возвращается, если было вставлено более одной строки. # – количество вставленных строк. |
ВСТАВИТЬ oid 1
Сообщение возвращается, если была вставлена только одна строка. oid – это числовой OID вставленной строки.
ВСТАВИТЬ 0 #
Сообщение возвращается, если было вставлено более одной строки. # – количество вставленных строк.
Примеры
Давайте создадим таблицу COMPANY в testdb следующим образом:
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL, JOIN_DATE DATE );
Следующий пример вставляет строку в таблицу COMPANY –
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (1, 'Paul', 32, 'California', 20000.00,'2001-07-13');
Следующий пример – вставить строку; здесь столбец зарплаты опущен, и поэтому он будет иметь значение по умолчанию –
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,JOIN_DATE) VALUES (2, 'Allen', 25, 'Texas', '2007-12-13');
В следующем примере используется предложение DEFAULT для столбца JOIN_DATE вместо указания значения –
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (3, 'Teddy', 23, 'Norway', 20000.00, DEFAULT );
В следующем примере вставляется несколько строк с использованием многострочного синтаксиса VALUES –
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00, '2007-12-13' ), (5, 'David', 27, 'Texas', 85000.00, '2007-12-13');
Все вышеперечисленные утверждения создадут следующие записи в таблице COMPANY. Следующая глава научит вас, как отображать все эти записи из таблицы.
ID NAME AGE ADDRESS SALARY JOIN_DATE ---- ---------- ----- ---------- ------- -------- 1 Paul 32 California 20000.0 2001-07-13 2 Allen 25 Texas 2007-12-13 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 2007-12-13 5 David 27 Texas 85000.0 2007-12-13
PostgreSQL – SELECT Query
Оператор PostgreSQL SELECT используется для извлечения данных из таблицы базы данных, которая возвращает данные в форме таблицы результатов. Эти таблицы результатов называются наборами результатов.
Синтаксис
Основной синтаксис оператора SELECT следующий:
SELECT column1, column2, columnN FROM table_name;
Здесь column1, column2 … это поля таблицы, значения которых вы хотите получить. Если вы хотите получить все поля, доступные в этом поле, вы можете использовать следующий синтаксис:
SELECT * FROM table_name;
пример
Рассмотрим таблицу COMPANY, имеющую записи следующим образом:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Ниже приведен пример, в котором можно получить поля ID, Имя и Зарплата клиентов, доступных в таблице CUSTOMERS.
testdb=# SELECT ID, NAME, SALARY FROM COMPANY ;
Это даст следующий результат –
id | name | salary ----+-------+-------- 1 | Paul | 20000 2 | Allen | 15000 3 | Teddy | 20000 4 | Mark | 65000 5 | David | 85000 6 | Kim | 45000 7 | James | 10000 (7 rows)
Если вы хотите получить все поля таблицы CUSTOMERS, используйте следующий запрос:
testdb=# SELECT * FROM COMPANY;
Это даст следующий результат –
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
PostgreSQL – операторы
Что такое оператор в PostgreSQL?
Оператор – это зарезервированное слово или символ, используемый в основном в предложении WHERE оператора PostgreSQL для выполнения операций, таких как сравнения и арифметические операции.
Операторы используются для указания условий в операторе PostgreSQL и в качестве союзов для нескольких условий в операторе.
- Арифметические операторы
- Операторы сравнения
- Логические операторы
- Битовые операторы
PostgreSQL Арифметические Операторы
Предположим, что переменная a содержит 2, а переменная b содержит 3, тогда –
пример
| оператор | Описание | пример |
|---|---|---|
| + | Добавление – добавляет значения по обе стороны от оператора | а + б даст 5 |
| – | Вычитание – вычитает правый операнд из левого операнда | а – б даст -1 |
| * | Умножение – умножает значения по обе стороны от оператора | а * б даст 6 |
| / | Деление – делит левый операнд на правый операнд | б / у даст 1 |
| % | Модуль – Делит левый операнд на правый операнд и возвращает остаток | б% а даст 1 |
| ^ | Экспонирование – это дает значение экспоненты правого операнда | а ^ б даст 8 |
| | / | квадратный корень | | / 25.0 даст 5 |
| || / | кубический корень | || / 27,0 даст 3 |
| ! | факториал | 5! даст 120 |
| !! | факториал (префиксный оператор) | !! 5 даст 120 |
Операторы сравнения PostgreSQL
Предположим, что переменная a содержит 10, а переменная b содержит 20, тогда –
Показать примеры
| оператор | Описание | пример |
|---|---|---|
| знак равно | Проверяет, равны ли значения двух операндов или нет, если да, тогда условие становится истинным. | (а = б) не соответствует действительности. |
| знак равно | Проверяет, равны ли значения двух операндов или нет, если значения не равны, тогда условие становится истинным. | (a! = b) верно. |
| <> | Проверяет, равны ли значения двух операндов или нет, если значения не равны, тогда условие становится истинным. | (а <> б) верно. |
| > | Проверяет, больше ли значение левого операнда, чем значение правого операнда, если да, тогда условие становится истинным. | (а> б) не соответствует действительности. |
| < | Проверяет, меньше ли значение левого операнда, чем значение правого операнда, если да, тогда условие становится истинным. | (а <б) верно. |
| > = | Проверяет, больше ли значение левого операнда или равно значению правого операнда, если да, тогда условие становится истинным. | (a> = b) не соответствует действительности. |
| <= | Проверяет, меньше ли значение левого операнда или равно значению правого операнда, если да, тогда условие становится истинным. | (a <= b) верно. |
Логические операторы PostgreSQL
Вот список всех логических операторов, доступных в PostgresSQL.
Показать примеры
| С. Нет. | Оператор и описание |
|---|---|
| 1 |
А ТАКЖЕ Оператор AND допускает существование нескольких условий в предложении WHERE оператора PostgresSQL. |
| 2 |
НЕ Оператор NOT меняет значение логического оператора, с которым он используется. Например. НЕ СУЩЕСТВУЕТ, НЕ МЕЖДУ, НЕ В И т. Д. Это оператор отрицания . |
| 3 |
ИЛИ ЖЕ Оператор OR используется для объединения нескольких условий в предложении WHERE оператора PostgresSQL. |
А ТАКЖЕ
Оператор AND допускает существование нескольких условий в предложении WHERE оператора PostgresSQL.
НЕ
Оператор NOT меняет значение логического оператора, с которым он используется. Например. НЕ СУЩЕСТВУЕТ, НЕ МЕЖДУ, НЕ В И т. Д. Это оператор отрицания .
ИЛИ ЖЕ
Оператор OR используется для объединения нескольких условий в предложении WHERE оператора PostgresSQL.
Операторы битовых строк PostgreSQL
Побитовый оператор работает с битами и выполняет побитовую операцию. Таблица истинности для & и | выглядит следующим образом –
| п | Q | P & Q | р | Q |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 |
Предположим, если А = 60; и B = 13; теперь в двоичном формате они будут выглядеть следующим образом –
A = 0011 1100
B = 0000 1101
—————–
A & B = 0000 1100
A | B = 0011 1101
~ A = 1100 0011
Показать примеры
Побитовые операторы, поддерживаемые PostgreSQL, перечислены в следующей таблице:
| оператор | Описание | пример |
|---|---|---|
| & | Двоичный оператор AND немного копирует результат, если он существует в обоих операндах. | (A & B) даст 12, что 0000 1100 |
| | | Оператор двоичного ИЛИ копирует немного, если он существует в любом из операндов. | (A | B) даст 61, что составляет 0011 1101 |
| ~ | Оператор дополнения двоичных единиц является унарным и имеет эффект «переворачивания» битов. | (~ A) даст -61, что составляет 1100 0011 в форме дополнения 2 из-за двоичного числа со знаком. |
| << | Двоичный оператор левого сдвига. Значение левого операнда перемещается влево на количество битов, указанное правым операндом. | << 2 даст 240, что составляет 1111 0000 |
| >> | Оператор двоичного правого сдвига. Значение левого операнда перемещается вправо на количество битов, указанное правым операндом. | A >> 2 даст 15, что 0000 1111 |
| # | побитовый XOR. | A # B даст 49, что составляет 0100 1001 |
PostgreSQL – выражения
Выражение представляет собой комбинацию одного или нескольких значений, операторов и функций PostgresSQL, которые оценивают значение.
PostgreSQL EXPRESSIONS подобны формулам и написаны на языке запросов. Вы также можете использовать для запроса базы данных для конкретного набора данных.
Синтаксис
Рассмотрим основной синтаксис оператора SELECT следующим образом:
SELECT column1, column2, columnN FROM table_name WHERE [CONDITION | EXPRESSION];
Существуют различные типы выражений PostgreSQL, которые упомянуты ниже:
PostgreSQL – логические выражения
Логические выражения PostgreSQL извлекают данные на основе совпадения с одним значением. Ниже приводится синтаксис –
SELECT column1, column2, columnN FROM table_name WHERE SINGLE VALUE MATCHTING EXPRESSION;
Рассмотрим таблицу COMPANY, имеющую записи следующим образом:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Вот простой пример, демонстрирующий использование логических выражений PostgreSQL:
testdb=# SELECT * FROM COMPANY WHERE SALARY = 10000;
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+-------+-----+----------+-------- 7 | James | 24 | Houston | 10000 (1 row)
PostgreSQL – числовое выражение
Эти выражения используются для выполнения любой математической операции в любом запросе. Ниже приводится синтаксис –
SELECT numerical_expression as OPERATION_NAME [FROM table_name WHERE CONDITION] ;
Здесь числовое выражение используется для математического выражения или любой формулы. Ниже приведен простой пример использования числовых выражений SQL:
testdb=# SELECT (15 + 6) AS ADDITION ;
Приведенный выше оператор PostgreSQL даст следующий результат:
addition
----------
21
(1 row)
Существует несколько встроенных функций, таких как avg (), sum (), count (), которые выполняют так называемые вычисления совокупных данных для таблицы или определенного столбца таблицы.
testdb=# SELECT COUNT(*) AS "RECORDS" FROM COMPANY;
Приведенный выше оператор PostgreSQL даст следующий результат:
RECORDS
---------
7
(1 row)
PostgreSQL – выражения даты
Выражения даты возвращают текущие системные значения даты и времени, и эти выражения используются в различных манипуляциях с данными.
testdb=# SELECT CURRENT_TIMESTAMP;
Приведенный выше оператор PostgreSQL даст следующий результат:
now ------------------------------- 2013-05-06 14:38:28.078+05:30 (1 row)
PostgreSQL – предложение WHERE
Предложение PostgreSQL WHERE используется для указания условия при извлечении данных из одной таблицы или объединении с несколькими таблицами.
Если данное условие выполняется, только тогда оно возвращает конкретное значение из таблицы. Вы можете отфильтровать строки, которые вы не хотите включать в набор результатов, используя предложение WHERE.
Предложение WHERE не только используется в операторе SELECT, но также используется в операторе UPDATE, DELETE и т. Д., Что мы рассмотрим в последующих главах.
Синтаксис
Основной синтаксис оператора SELECT с предложением WHERE следующий:
SELECT column1, column2, columnN FROM table_name WHERE [search_condition]
Вы можете указать условие поиска, используя сравнение или логические операторы. like>, <, =, LIKE, NOT и т. д. Следующие примеры прояснят эту концепцию.
пример
Рассмотрим таблицу COMPANY, имеющую записи следующим образом:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Вот простые примеры, показывающие использование логических операторов PostgreSQL. После оператора SELECT будут перечислены все записи, где AGE больше или равно 25 И зарплата больше или равна 65000.00 –
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+-------+-----+------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (2 rows)
Следующий оператор SELECT перечисляет все записи, где AGE больше или равно 25 ИЛИ оклад больше или равен 65000.00 –
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (4 rows)
Следующая инструкция SELECT перечисляет все записи, где AGE не NULL, что означает все записи, потому что ни одна из записей не имеет AGE, равный NULL –
testdb=# SELECT * FROM COMPANY WHERE AGE IS NOT NULL;
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (7 rows)
Следующая инструкция SELECT перечисляет все записи, где NAME начинается с «Pa», независимо от того, что идет после «Pa».
testdb=# SELECT * FROM COMPANY WHERE NAME LIKE 'Pa%';
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age |address | salary ----+------+-----+-----------+-------- 1 | Paul | 32 | California| 20000
Следующая инструкция SELECT перечисляет все записи, где значение AGE равно 25 или 27 –
testdb=# SELECT * FROM COMPANY WHERE AGE IN ( 25, 27 );
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+-------+-----+------------+-------- 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (3 rows)
Следующая инструкция SELECT перечисляет все записи, где значение AGE не равно ни 25, ни 27 –
testdb=# SELECT * FROM COMPANY WHERE AGE NOT IN ( 25, 27 );
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 3 | Teddy | 23 | Norway | 20000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (4 rows)
Следующая инструкция SELECT перечисляет все записи, где значение AGE находится между 25 и 27 –
testdb=# SELECT * FROM COMPANY WHERE AGE BETWEEN 25 AND 27;
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+-------+-----+------------+-------- 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (3 rows)
В следующем операторе SELECT используется подзапрос SQL, в котором подзапрос находит все записи с полем AGE, имеющим SALARY> 65000 и более поздних, с помощью оператора WHERE вместе с оператором EXISTS для вывода списка всех записей, в которых AGE из внешнего запроса присутствует в возвращенном результате. по подзапросу –
testdb=# SELECT AGE FROM COMPANY WHERE EXISTS (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
Приведенный выше оператор PostgreSQL даст следующий результат:
age ----- 32 25 23 25 27 22 24 (7 rows)
В следующем операторе SELECT используется подзапрос SQL, в котором подзапрос находит все записи с полем AGE, имеющим SALARY> 65000 и более поздних, с помощью оператора WHERE вместе с оператором> для вывода списка всех записей, где возраст AGE из внешнего запроса превышает возраст в результат, возвращаемый подзапросом –
testdb=# SELECT * FROM COMPANY WHERE AGE > (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+------+-----+------------+-------- 1 | Paul | 32 | California | 20000
И и ИЛИ Соединительные Операторы
Операторы PostgreSQL И и ИЛИ используются для объединения нескольких условий для сужения выбранных данных в операторе PostgreSQL. Эти два оператора называются конъюнктивными операторами.
Эти операторы предоставляют возможность проводить множественные сравнения с разными операторами в одной и той же инструкции PostgreSQL.
Оператор AND
Оператор AND допускает существование нескольких условий в предложении WHERE оператора PostgreSQL. При использовании оператора AND полное условие будет считаться истинным, если все условия выполняются. Например, [условие1] И [условие2] будет истинным, только когда оба условия1 и условие2 будут истинными.
Синтаксис
Основной синтаксис оператора AND с предложением WHERE следующий:
SELECT column1, column2, columnN FROM table_name WHERE [condition1] AND [condition2]...AND [conditionN];
Вы можете объединить N условий с помощью оператора AND. Для действия, выполняемого оператором PostgreSQL, будь то транзакция или запрос, все условия, разделенные AND, должны быть ИСТИНА.
пример
Рассмотрим таблицу COMPANY, имеющую записи следующим образом:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Следующий оператор SELECT перечисляет все записи, где AGE больше или равно 25 И зарплата больше или равна 65000.00 –
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+-------+-----+------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (2 rows)
Оператор ИЛИ
Оператор OR также используется для объединения нескольких условий в предложении WHERE оператора PostgreSQL. При использовании оператора ИЛИ полное условие будет считаться истинным, если хотя бы одно из условий является истинным. Например, [условие1] ИЛИ [условие2] будет истинным, если условие 1 или условие 2 истинно.
Синтаксис
Основной синтаксис оператора OR с предложением WHERE следующий:
SELECT column1, column2, columnN FROM table_name WHERE [condition1] OR [condition2]...OR [conditionN]
Вы можете комбинировать N условий с помощью оператора ИЛИ. Для действия, выполняемого оператором PostgreSQL, будь то транзакция или запрос, только ОДИН из условий, разделенных ИЛИ, должно быть ИСТИНА.
пример
Рассмотрим таблицу COMPANY , имеющую следующие записи:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Следующий оператор SELECT перечисляет все записи, где AGE больше или равно 25 ИЛИ оклад больше или равен 65000.00 –
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (4 rows)
PostgreSQL – ОБНОВЛЕНИЕ запроса
Запрос UPDATE PostgreSQL используется для изменения существующих записей в таблице. Вы можете использовать предложение WHERE с запросом UPDATE для обновления выбранных строк. В противном случае все строки будут обновлены.
Синтаксис
Основной синтаксис запроса UPDATE с предложением WHERE следующий:
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
Вы можете объединить N условий с помощью операторов И или ИЛИ.
пример
Рассмотрим таблицу COMPANY , имеющую записи следующим образом –
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Ниже приведен пример, который будет обновлять адрес для клиента, чей идентификатор 6 –
testdb=# UPDATE COMPANY SET SALARY = 15000 WHERE ID = 3;
Теперь таблица COMPANY будет иметь следующие записи –
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 3 | Teddy | 23 | Norway | 15000 (7 rows)
Если вы хотите изменить все значения столбцов ADDRESS и SALARY в таблице COMPANY, вам не нужно использовать предложение WHERE, а запрос UPDATE будет выглядеть следующим образом:
testdb=# UPDATE COMPANY SET ADDRESS = 'Texas', SALARY=20000;
Теперь таблица COMPANY будет иметь следующие записи –
id | name | age | address | salary ----+-------+-----+---------+-------- 1 | Paul | 32 | Texas | 20000 2 | Allen | 25 | Texas | 20000 4 | Mark | 25 | Texas | 20000 5 | David | 27 | Texas | 20000 6 | Kim | 22 | Texas | 20000 7 | James | 24 | Texas | 20000 3 | Teddy | 23 | Texas | 20000 (7 rows)
PostgreSQL – УДАЛИТЬ Запрос
PostgreSQL DELETE Query используется для удаления существующих записей из таблицы. Вы можете использовать предложение WHERE с запросом DELETE, чтобы удалить выбранные строки. В противном случае все записи будут удалены.
Синтаксис
Основной синтаксис запроса DELETE с предложением WHERE следующий:
DELETE FROM table_name WHERE [condition];
Вы можете объединить N условий с помощью операторов И или ИЛИ.
пример
Рассмотрим таблицу COMPANY , имеющую записи следующим образом –
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Ниже приведен пример, который удаляет клиента с идентификатором 7 –
testdb=# DELETE FROM COMPANY WHERE ID = 2;
Теперь таблица COMPANY будет иметь следующие записи –
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (6 rows)
Если вы хотите УДАЛИТЬ все записи из таблицы COMPANY, вам не нужно использовать предложение WHERE с запросами DELETE, которое будет выглядеть следующим образом:
testdb=# DELETE FROM COMPANY;
Теперь в таблице COMPANY нет записей, поскольку все записи были удалены оператором DELETE.
PostgreSQL – как статья
Оператор PostgreSQL LIKE используется для сопоставления текстовых значений с шаблоном с использованием подстановочных знаков. Если поисковое выражение может быть сопоставлено с выражением шаблона, оператор LIKE вернет true, равное 1 .
В сочетании с оператором LIKE используются два подстановочных знака:
- Знак процента (%)
- Подчеркивание (_)
Знак процента представляет собой ноль, один или несколько чисел или символов. Подчеркивание представляет собой одно число или символ. Эти символы могут использоваться в комбинациях.
Если ни один из этих двух признаков не используется вместе с предложением LIKE, то LIKE действует как оператор равенства.
Синтаксис
Основной синтаксис% и _ следующий:
SELECT FROM table_name WHERE column LIKE 'XXXX%' or SELECT FROM table_name WHERE column LIKE '%XXXX%' or SELECT FROM table_name WHERE column LIKE 'XXXX_' or SELECT FROM table_name WHERE column LIKE '_XXXX' or SELECT FROM table_name WHERE column LIKE '_XXXX_'
Вы можете объединить N условий с помощью операторов И или ИЛИ. Здесь XXXX может быть любым числовым или строковым значением.
пример
Вот несколько примеров, показывающих, где часть WHERE имеет другое предложение LIKE с операторами «%» и «_» –
| С. Нет. | Заявление и описание |
|---|---|
| 1 |
Где заработная плата :: текст, как “200%” Находит любые значения, которые начинаются с 200 |
| 2 |
Где заработная плата :: текст, как “% 200%” Находит любые значения, которые имеют 200 в любой позиции |
| 3 |
Где заработная плата :: текст, как “_00%” Находит любые значения, которые имеют 00 во второй и третьей позиции |
| 4 |
ГДЕ НАЛОГОВЫЙ :: текст НРАВИТСЯ ‘2 _% _%’ Находит любые значения, которые начинаются с 2 и имеют длину не менее 3 символов |
| 5 |
Где заработная плата :: текст, как “% 2” Находит любые значения, которые заканчиваются на 2 |
| 6 |
Где заработная плата :: текст как ‘_2% 3’ Находит любые значения, которые имеют 2 во второй позиции и заканчиваются на 3 |
| 7 |
Где заработная плата :: текст, как «2___3» Находит любые значения в пятизначном числе, которые начинаются с 2 и заканчиваются на 3 |
Где заработная плата :: текст, как “200%”
Находит любые значения, которые начинаются с 200
Где заработная плата :: текст, как “% 200%”
Находит любые значения, которые имеют 200 в любой позиции
Где заработная плата :: текст, как “_00%”
Находит любые значения, которые имеют 00 во второй и третьей позиции
ГДЕ НАЛОГОВЫЙ :: текст НРАВИТСЯ ‘2 _% _%’
Находит любые значения, которые начинаются с 2 и имеют длину не менее 3 символов
Где заработная плата :: текст, как “% 2”
Находит любые значения, которые заканчиваются на 2
Где заработная плата :: текст как ‘_2% 3’
Находит любые значения, которые имеют 2 во второй позиции и заканчиваются на 3
Где заработная плата :: текст, как «2___3»
Находит любые значения в пятизначном числе, которые начинаются с 2 и заканчиваются на 3
Postgres LIKE – это только сравнение строк. Следовательно, нам нужно явно преобразовать столбец целых чисел в строку, как в примерах выше.
Давайте возьмем реальный пример, рассмотрим таблицу COMPANY , имеющую записи следующим образом:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Ниже приведен пример, который будет отображать все записи из таблицы COMPANY, где AGE начинается с 2 –
testdb=# SELECT * FROM COMPANY WHERE AGE::text LIKE '2%';
Это даст следующий результат –
id | name | age | address | salary ----+-------+-----+-------------+-------- 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 (7 rows)
Ниже приведен пример, в котором будут отображаться все записи из таблицы COMPANY, в которых ADDRESS будет содержать дефис (-) внутри текста –
testdb=# SELECT * FROM COMPANY WHERE ADDRESS LIKE '%-%';
Это даст следующий результат –
id | name | age | address | salary ----+------+-----+-------------------------------------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 (2 rows)
PostgreSQL – предложение LIMIT
Предложение LIMIT PostgreSQL используется для ограничения объема данных, возвращаемых оператором SELECT.
Синтаксис
Основной синтаксис оператора SELECT с предложением LIMIT следующий:
SELECT column1, column2, columnN FROM table_name LIMIT [no of rows]
Ниже приведен синтаксис предложения LIMIT, когда он используется вместе с предложением OFFSET:
SELECT column1, column2, columnN FROM table_name LIMIT [no of rows] OFFSET [row num]
LIMIT и OFFSET позволяют вам получить только часть строк, которые генерируются остальной частью запроса.
пример
Рассмотрим таблицу COMPANY, имеющую записи следующим образом:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Ниже приведен пример, который ограничивает строку в таблице в соответствии с количеством строк, которые вы хотите извлечь из таблицы:
testdb=# SELECT * FROM COMPANY LIMIT 4;
Это даст следующий результат –
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 (4 rows)
Однако в определенных ситуациях вам может потребоваться подобрать набор записей из определенного смещения. Вот пример, который поднимает три записи, начиная с третьей позиции:
testdb=# SELECT * FROM COMPANY LIMIT 3 OFFSET 2;
Это даст следующий результат –
id | name | age | address | salary ----+-------+-----+-----------+-------- 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (3 rows)
PostgreSQL – предложение ORDER BY
Предложение PostgreSQL ORDER BY используется для сортировки данных в порядке возрастания или убывания на основе одного или нескольких столбцов.
Синтаксис
Основной синтаксис предложения ORDER BY следующий:
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC];
Вы можете использовать более одного столбца в предложении ORDER BY. Убедитесь, что любой столбец, который вы используете для сортировки, должен быть доступен в столбце списка.
пример
Рассмотрим таблицу COMPANY, имеющую записи следующим образом:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Ниже приведен пример, который сортирует результат в порядке возрастания по SALARY –
testdb=# SELECT * FROM COMPANY ORDER BY AGE ASC;
Это даст следующий результат –
id | name | age | address | salary ----+-------+-----+------------+-------- 6 | Kim | 22 | South-Hall | 45000 3 | Teddy | 23 | Norway | 20000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 4 | Mark | 25 | Rich-Mond | 65000 2 | Allen | 25 | Texas | 15000 5 | David | 27 | Texas | 85000 1 | Paul | 32 | California | 20000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 (10 rows)
Ниже приведен пример, который сортирует результат в порядке возрастания по NAME и SALARY.
testdb=# SELECT * FROM COMPANY ORDER BY NAME, SALARY ASC;
Это даст следующий результат –
id | name | age | address | salary ----+-------+-----+--------------+-------- 2 | Allen | 25 | Texas | 15000 5 | David | 27 | Texas | 85000 10 | James | 45 | Texas | 5000 9 | James | 44 | Norway | 5000 7 | James | 24 | Houston | 10000 6 | Kim | 22 | South-Hall | 45000 4 | Mark | 25 | Rich-Mond | 65000 1 | Paul | 32 | California | 20000 8 | Paul | 24 | Houston | 20000 3 | Teddy | 23 | Norway | 20000 (10 rows)
Ниже приведен пример, который сортирует результат в порядке убывания по ИМЯ –
testdb=# SELECT * FROM COMPANY ORDER BY NAME DESC;
Это даст следующий результат –
id | name | age | address | salary ----+-------+-----+------------+-------- 3 | Teddy | 23 | Norway | 20000 1 | Paul | 32 | California | 20000 8 | Paul | 24 | Houston | 20000 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 5 | David | 27 | Texas | 85000 2 | Allen | 25 | Texas | 15000 (10 rows)
PostgreSQL – GROUP BY
Предложение PostgreSQL GROUP BY используется в сотрудничестве с оператором SELECT для группировки этих строк в таблице с одинаковыми данными. Это делается для устранения избыточности в выходных и / или вычислительных агрегатах, которые применяются к этим группам.
Предложение GROUP BY следует за предложением WHERE в инструкции SELECT и предшествует предложению ORDER BY.
Синтаксис
Основной синтаксис предложения GROUP BY приведен ниже. Предложение GROUP BY должно соответствовать условиям в предложении WHERE и должно предшествовать предложению ORDER BY, если оно используется.
SELECT column-list FROM table_name WHERE [ conditions ] GROUP BY column1, column2....columnN ORDER BY column1, column2....columnN
Вы можете использовать более одного столбца в предложении GROUP BY. Убедитесь, что какой столбец вы используете для группировки, этот столбец должен быть доступен в списке столбцов.
пример
Рассмотрим таблицу COMPANY, имеющую записи следующим образом:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Если вы хотите узнать общую сумму зарплаты каждого клиента, запрос GROUP BY будет выглядеть следующим образом:
testdb=# SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME;
Это даст следующий результат –
name | sum -------+------- Teddy | 20000 Paul | 20000 Mark | 65000 David | 85000 Allen | 15000 Kim | 45000 James | 10000 (7 rows)
Теперь давайте создадим еще три записи в таблице COMPANY, используя следующие операторы INSERT:
INSERT INTO COMPANY VALUES (8, 'Paul', 24, 'Houston', 20000.00); INSERT INTO COMPANY VALUES (9, 'James', 44, 'Norway', 5000.00); INSERT INTO COMPANY VALUES (10, 'James', 45, 'Texas', 5000.00);
Теперь наша таблица имеет следующие записи с повторяющимися именами –
id | name | age | address | salary ----+-------+-----+--------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 (10 rows)
Опять же, давайте используем один и тот же оператор для группировки всех записей с использованием столбца NAME следующим образом:
testdb=# SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME ORDER BY NAME;
Это даст следующий результат –
name | sum -------+------- Allen | 15000 David | 85000 James | 20000 Kim | 45000 Mark | 65000 Paul | 40000 Teddy | 20000 (7 rows)
Давайте использовать предложение ORDER BY вместе с предложением GROUP BY следующим образом:
testdb=# SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME ORDER BY NAME DESC;
Это даст следующий результат –
name | sum -------+------- Teddy | 20000 Paul | 40000 Mark | 65000 Kim | 45000 James | 20000 David | 85000 Allen | 15000 (7 rows)
PostgreSQL – предложение WITH
В PostgreSQL запрос WITH предоставляет возможность написать вспомогательные операторы для использования в запросе большего размера. Это помогает разбить сложные и большие запросы на более простые формы, которые легко читаются. Эти операторы, часто называемые выражениями общих таблиц или CTE, могут рассматриваться как определяющие временные таблицы, которые существуют только для одного запроса.
Запрос WITH, являющийся запросом CTE, особенно полезен, когда подзапрос выполняется несколько раз. Это одинаково полезно вместо временных таблиц. Он вычисляет агрегацию один раз и позволяет нам ссылаться на нее по ее имени (может быть несколько раз) в запросах.
Предложение WITH должно быть определено до того, как оно будет использовано в запросе.
Синтаксис
Основной синтаксис запроса WITH следующий:
WITH
name_for_summary_data AS (
SELECT Statement)
SELECT columns
FROM name_for_summary_data
WHERE conditions <=> (
SELECT column
FROM name_for_summary_data)
[ORDER BY columns]
Где name_for_summary_data – это имя, данное предложению WITH. Name_for_summary_data может совпадать с именем существующей таблицы и иметь приоритет.
Вы можете использовать операторы изменения данных (INSERT, UPDATE или DELETE) в WITH. Это позволяет вам выполнять несколько разных операций в одном запросе.
Рекурсивный СО
Рекурсивные запросы WITH или Иерархические запросы – это форма CTE, в которой CTE может ссылаться на себя, т. Е. Запрос WITH может ссылаться на свой собственный вывод, следовательно, имя рекурсивно.
пример
Рассмотрим таблицу COMPANY, имеющую записи следующим образом:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Теперь давайте напишем запрос, используя предложение WITH, чтобы выбрать записи из приведенной выше таблицы следующим образом:
With CTE AS (Select ID , NAME , AGE , ADDRESS , SALARY FROM COMPANY ) Select * From CTE;
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Теперь давайте напишем запрос, используя ключевое слово RECURSIVE вместе с предложением WITH, чтобы найти сумму зарплат менее 20000, как показано ниже:
WITH RECURSIVE t(n) AS ( VALUES (0) UNION ALL SELECT SALARY FROM COMPANY WHERE SALARY < 20000 ) SELECT sum(n) FROM t;
Приведенный выше оператор PostgreSQL даст следующий результат:
sum ------- 25000 (1 row)
Давайте напишем запрос, используя операторы изменения данных вместе с предложением WITH, как показано ниже.
Сначала создайте таблицу COMPANY1, аналогичную таблице COMPANY. Запрос в примере эффективно перемещает строки из КОМПАНИИ в КОМПАНИ1. DELETE в WITH удаляет указанные строки из COMPANY, возвращая их содержимое с помощью предложения RETURNING; а затем первичный запрос читает этот вывод и вставляет его в КОМПАНИЮ TABLE –
CREATE TABLE COMPANY1( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL ); WITH moved_rows AS ( DELETE FROM COMPANY WHERE SALARY >= 30000 RETURNING * ) INSERT INTO COMPANY1 (SELECT * FROM moved_rows);
Приведенный выше оператор PostgreSQL даст следующий результат:
INSERT 0 3
Теперь записи в таблицах COMPANY и COMPANY1 выглядят следующим образом:
testdb=# SELECT * FROM COMPANY; id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 7 | James | 24 | Houston | 10000 (4 rows) testdb=# SELECT * FROM COMPANY1; id | name | age | address | salary ----+-------+-----+-------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 (3 rows)
PostgreSQL – предложение HAVING
Предложение HAVING позволяет нам выбирать конкретные строки, в которых результат функции удовлетворяет некоторому условию.
Предложение WHERE помещает условия в выбранные столбцы, тогда как предложение HAVING помещает условия в группы, созданные предложением GROUP BY.
Синтаксис
Ниже приведена позиция предложения HAVING в запросе SELECT.
SELECT FROM WHERE GROUP BY HAVING ORDER BY
Предложение HAVING должно следовать за предложением GROUP BY в запросе и также должно предшествовать предложению ORDER BY, если оно используется. Ниже приведен синтаксис оператора SELECT, включая предложение HAVING.
SELECT column1, column2 FROM table1, table2 WHERE [ conditions ] GROUP BY column1, column2 HAVING [ conditions ] ORDER BY column1, column2
пример
Рассмотрим таблицу COMPANY, имеющую записи следующим образом:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Ниже приведен пример, в котором будет отображаться запись, для которой количество имен меньше 2 –
testdb-# SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) < 2;
Это даст следующий результат –
name ------- Teddy Paul Mark David Allen Kim James (7 rows)
Теперь давайте создадим еще три записи в таблице COMPANY, используя следующие операторы INSERT:
INSERT INTO COMPANY VALUES (8, 'Paul', 24, 'Houston', 20000.00); INSERT INTO COMPANY VALUES (9, 'James', 44, 'Norway', 5000.00); INSERT INTO COMPANY VALUES (10, 'James', 45, 'Texas', 5000.00);
Теперь наша таблица имеет следующие записи с повторяющимися именами –
id | name | age | address | salary ----+-------+-----+--------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 (10 rows)
Ниже приведен пример, в котором будет отображаться запись, для которой количество имен больше 1 –
testdb-# SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) > 1;
Это даст следующий результат –
name ------- Paul James (2 rows)
PostgreSQL – ключевое слово DISTINCT
Ключевое слово PostgreSQL DISTINCT используется вместе с оператором SELECT, чтобы исключить все дублирующиеся записи и извлечь только уникальные записи.
Может возникнуть ситуация, когда в таблице несколько повторяющихся записей. При получении таких записей имеет смысл выбирать только уникальные записи, а не дублировать записи.
Синтаксис
Основной синтаксис ключевого слова DISTINCT для устранения повторяющихся записей заключается в следующем:
SELECT DISTINCT column1, column2,.....columnN FROM table_name WHERE [condition]
пример
Рассмотрим таблицу COMPANY, имеющую записи следующим образом:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Давайте добавим еще две записи в эту таблицу следующим образом:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (8, 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (9, 'Allen', 25, 'Texas', 15000.00 );
Теперь записи в таблице COMPANY будут:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 32 | California | 20000 9 | Allen | 25 | Texas | 15000 (9 rows)
Во-первых, давайте посмотрим, как следующий запрос SELECT возвращает дубликаты записей заработной платы –
testdb=# SELECT name FROM COMPANY;
Это даст следующий результат –
name ------- Paul Allen Teddy Mark David Kim James Paul Allen (9 rows)
Теперь давайте используем ключевое слово DISTINCT с вышеупомянутым запросом SELECT и посмотрим на результат –
testdb=# SELECT DISTINCT name FROM COMPANY;
Это приведет к следующему результату, где у нас нет дублирующихся записей –
name ------- Teddy Paul Mark David Allen Kim James (7 rows)
PostgreSQL – ОГРАНИЧЕНИЯ
Ограничения – это правила, применяемые к столбцам данных в таблице. Они используются для предотвращения ввода неверных данных в базу данных. Это обеспечивает точность и достоверность данных в базе данных.
Ограничения могут быть на уровне столбца или таблицы. Ограничения уровня столбца применяются только к одному столбцу, тогда как ограничения уровня таблицы применяются ко всей таблице. Определение типа данных для столбца само по себе является ограничением. Например, столбец типа DATE ограничивает столбец допустимыми датами.
Ниже приведены часто используемые ограничения, доступные в PostgreSQL.
-
NOT NULL Ограничение – Гарантирует, что столбец не может иметь значение NULL.
-
UNIQUE Constraint – гарантирует, что все значения в столбце разные.
-
PRIMARY Key – уникально идентифицирует каждую строку / запись в таблице базы данных.
-
Ключ FOREIGN – Ограничивает данные на основе столбцов в других таблицах.
-
Ограничение CHECK – ограничение CHECK гарантирует, что все значения в столбце удовлетворяют определенным условиям.
-
Ограничение EXCLUSION – ограничение EXCLUDE гарантирует, что, если любые две строки сравниваются в указанных столбцах или выражениях с использованием указанных операторов, не все эти сравнения возвращают TRUE.
NOT NULL Ограничение – Гарантирует, что столбец не может иметь значение NULL.
UNIQUE Constraint – гарантирует, что все значения в столбце разные.
PRIMARY Key – уникально идентифицирует каждую строку / запись в таблице базы данных.
Ключ FOREIGN – Ограничивает данные на основе столбцов в других таблицах.
Ограничение CHECK – ограничение CHECK гарантирует, что все значения в столбце удовлетворяют определенным условиям.
Ограничение EXCLUSION – ограничение EXCLUDE гарантирует, что, если любые две строки сравниваются в указанных столбцах или выражениях с использованием указанных операторов, не все эти сравнения возвращают TRUE.
NOT NULL Ограничение
По умолчанию столбец может содержать значения NULL. Если вы не хотите, чтобы столбец имел значение NULL, вам необходимо определить такое ограничение для этого столбца, указав, что NULL теперь не разрешен для этого столбца. Ограничение NOT NULL всегда записывается как ограничение столбца.
NULL – это не то же самое, что отсутствие данных; скорее это представляет неизвестные данные.
пример
Например, следующий оператор PostgreSQL создает новую таблицу с именем COMPANY1 и добавляет пять столбцов, три из которых, ID и NAME и AGE, указывают, что они не должны принимать значения NULL.
CREATE TABLE COMPANY1( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
Уникальное ограничение
Уникальное ограничение не позволяет двум записям иметь одинаковые значения в определенном столбце. Например, в таблице COMPANY вы можете запретить двум или более людям одинаковый возраст.
пример
Например, следующий оператор PostgreSQL создает новую таблицу с именем COMPANY3 и добавляет пять столбцов. Здесь столбец AGE имеет значение UNIQUE, поэтому вы не можете иметь две записи одного возраста –
CREATE TABLE COMPANY3( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL UNIQUE, ADDRESS CHAR(50), SALARY REAL DEFAULT 50000.00 );
ПЕРВИЧНЫЙ КЛЮЧ Ограничение
Ограничение PRIMARY KEY однозначно идентифицирует каждую запись в таблице базы данных. Может быть больше УНИКАЛЬНЫХ столбцов, но только один первичный ключ в таблице. Первичные ключи важны при разработке таблиц базы данных. Первичные ключи – это уникальные идентификаторы.
Мы используем их для ссылки на строки таблицы. Первичные ключи становятся внешними ключами в других таблицах при создании связей между таблицами. Из-за «давнего надзора за кодированием» первичные ключи могут иметь значение NULL в SQLite. Это не относится к другим базам данных
Первичный ключ – это поле в таблице, которое однозначно идентифицирует каждую строку / запись в таблице базы данных. Первичные ключи должны содержать уникальные значения. Столбец первичного ключа не может иметь значения NULL.
Таблица может иметь только один первичный ключ, который может состоять из одного или нескольких полей. Когда несколько полей используются в качестве первичного ключа, они называются составным ключом .
Если у таблицы есть первичный ключ, определенный для любого поля (полей), то у вас не может быть двух записей, имеющих одинаковое значение этого поля (полей).
пример
Вы уже видели различные примеры выше, где мы создали таблицу COMAPNY4 с ID в качестве первичного ключа –
CREATE TABLE COMPANY4( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
ЗАРУБЕЖНЫЙ КЛЮЧ
Ограничение внешнего ключа указывает, что значения в столбце (или группе столбцов) должны соответствовать значениям, появляющимся в некоторой строке другой таблицы. Мы говорим, что это поддерживает ссылочную целостность между двумя связанными таблицами. Они называются внешними ключами, потому что ограничения являются внешними; то есть вне стола. Внешние ключи иногда называют ссылочными ключами.
пример
Например, следующий оператор PostgreSQL создает новую таблицу с именем COMPANY5 и добавляет пять столбцов.
CREATE TABLE COMPANY6( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
Например, следующий оператор PostgreSQL создает новую таблицу с именем DEPARTMENT1, которая добавляет три столбца. Столбец EMP_ID является внешним ключом и ссылается на поле идентификатора таблицы COMPANY6.
CREATE TABLE DEPARTMENT1( ID INT PRIMARY KEY NOT NULL, DEPT CHAR(50) NOT NULL, EMP_ID INT references COMPANY6(ID) );
ПРОВЕРЬТЕ Ограничение
Ограничение CHECK позволяет условию проверять значение, вводимое в запись. Если условие оценивается как ложное, запись нарушает ограничение и не заносится в таблицу.
пример
Например, следующий оператор PostgreSQL создает новую таблицу с именем COMPANY5 и добавляет пять столбцов. Здесь мы добавляем столбец CHECK with SALARY, чтобы у вас не было SALARY в качестве нуля.
CREATE TABLE COMPANY5( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL CHECK(SALARY > 0) );
ИСКЛЮЧЕНИЕ Ограничение
Ограничения исключения гарантируют, что, если любые две строки сравниваются в указанных столбцах или выражениях с использованием указанных операторов, по крайней мере одно из этих сравнений операторов вернет false или null.
пример
Например, следующий оператор PostgreSQL создает новую таблицу с именем COMPANY7 и добавляет пять столбцов. Здесь мы добавляем ограничение EXCLUDE –
CREATE TABLE COMPANY7( ID INT PRIMARY KEY NOT NULL, NAME TEXT, AGE INT , ADDRESS CHAR(50), SALARY REAL, EXCLUDE USING gist (NAME WITH =, AGE WITH <>) );
Здесь USING gist – это тип индекса, который нужно создать и использовать для принудительного применения.
Вам необходимо выполнить команду CREATE EXTENSION btree_gist , один раз для каждой базы данных. Это установит расширение btree_gist, которое определяет ограничения исключения для простых скалярных типов данных.
Поскольку мы установили, что возраст должен быть одинаковым, давайте посмотрим на это, вставив записи в таблицу:
INSERT INTO COMPANY7 VALUES(1, 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY7 VALUES(2, 'Paul', 32, 'Texas', 20000.00 ); INSERT INTO COMPANY7 VALUES(3, 'Allen', 42, 'California', 20000.00 );
Для первых двух операторов INSERT записи добавляются в таблицу COMPANY7. Для третьего оператора INSERT отображается следующая ошибка:
ERROR: duplicate key value violates unique constraint "company7_pkey" DETAIL: Key (id)=(3) already exists.
Отбрасывание ограничений
Чтобы удалить ограничение, вам нужно знать его имя. Если имя известно, его легко отбросить. Иначе, вам нужно узнать имя, сгенерированное системой. Здесь может помочь команда psql d имя таблицы. Общий синтаксис –
ALTER TABLE table_name DROP CONSTRAINT some_name;
PostgreSQL – СОЕДИНЕНИЯ
Предложение PostgreSQL Joins используется для объединения записей из двух или более таблиц в базе данных. JOIN – это средство для объединения полей из двух таблиц с использованием значений, общих для каждой.
Типы соединения в PostgreSQL:
- CROSS JOIN
- ВНУТРЕННЕЕ СОЕДИНЕНИЕ
- ЛЕВОЕ НАРУЖНОЕ СОЕДИНЕНИЕ
- ПРАВИЛЬНОЕ НАРУЖНОЕ СОЕДИНЕНИЕ
- ПОЛНОЕ НАРУЖНОЕ СОЕДИНЕНИЕ
Прежде чем мы продолжим, давайте рассмотрим две таблицы, КОМПАНИЯ и ОТДЕЛ. Мы уже видели операторы INSERT для заполнения таблицы COMPANY. Итак, давайте предположим список записей, доступных в таблице COMPANY –
id | name | age | address | salary | join_date ----+-------+-----+-----------+--------+----------- 1 | Paul | 32 | California| 20000 | 2001-07-13 3 | Teddy | 23 | Norway | 20000 | 4 | Mark | 25 | Rich-Mond | 65000 | 2007-12-13 5 | David | 27 | Texas | 85000 | 2007-12-13 2 | Allen | 25 | Texas | | 2007-12-13 8 | Paul | 24 | Houston | 20000 | 2005-07-13 9 | James | 44 | Norway | 5000 | 2005-07-13 10 | James | 45 | Texas | 5000 | 2005-07-13
Другая таблица – ОТДЕЛ, имеет следующее определение –
CREATE TABLE DEPARTMENT( ID INT PRIMARY KEY NOT NULL, DEPT CHAR(50) NOT NULL, EMP_ID INT NOT NULL );
Вот список операторов INSERT для заполнения таблицы DEPARTMENT –
INSERT INTO DEPARTMENT (ID, DEPT, EMP_ID) VALUES (1, 'IT Billing', 1 ); INSERT INTO DEPARTMENT (ID, DEPT, EMP_ID) VALUES (2, 'Engineering', 2 ); INSERT INTO DEPARTMENT (ID, DEPT, EMP_ID) VALUES (3, 'Finance', 7 );
Наконец, у нас есть следующий список записей, доступных в таблице ОТДЕЛ –
id | dept | emp_id ----+-------------+-------- 1 | IT Billing | 1 2 | Engineering | 2 3 | Finance | 7
CROSS JOIN
CROSS JOIN сопоставляет каждую строку первой таблицы с каждой строкой второй таблицы. Если во входных таблицах есть столбцы x и y соответственно, то в результирующей таблице будут столбцы x + y. Поскольку CROSS JOINs могут генерировать очень большие таблицы, необходимо соблюдать осторожность, чтобы использовать их только при необходимости.
Ниже приводится синтаксис CROSS JOIN –
SELECT ... FROM table1 CROSS JOIN table2 ...
На основании приведенных выше таблиц мы можем написать CROSS JOIN следующим образом:
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY CROSS JOIN DEPARTMENT;
Приведенный выше запрос даст следующий результат –
emp_id| name | dept
------|-------|--------------
1 | Paul | IT Billing
1 | Teddy | IT Billing
1 | Mark | IT Billing
1 | David | IT Billing
1 | Allen | IT Billing
1 | Paul | IT Billing
1 | James | IT Billing
1 | James | IT Billing
2 | Paul | Engineering
2 | Teddy | Engineering
2 | Mark | Engineering
2 | David | Engineering
2 | Allen | Engineering
2 | Paul | Engineering
2 | James | Engineering
2 | James | Engineering
7 | Paul | Finance
7 | Teddy | Finance
7 | Mark | Finance
7 | David | Finance
7 | Allen | Finance
7 | Paul | Finance
7 | James | Finance
7 | James | Finance
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
INNER JOIN создает новую таблицу результатов, комбинируя значения столбцов двух таблиц (table1 и table2) на основе предиката соединения. Запрос сравнивает каждую строку таблицы table1 с каждой строкой таблицы table2, чтобы найти все пары строк, которые удовлетворяют предикату соединения. Когда предикат соединения удовлетворяется, значения столбцов для каждой соответствующей пары строк таблиц table1 и table2 объединяются в строку результатов.
ВНУТРЕННЕЕ СОЕДИНЕНИЕ является наиболее распространенным типом объединения и является типом соединения по умолчанию. При желании вы можете использовать ключевое слово INNER.
Ниже приведен синтаксис INNER JOIN –
SELECT table1.column1, table2.column2... FROM table1 INNER JOIN table2 ON table1.common_filed = table2.common_field;
Основываясь на приведенных выше таблицах, мы можем написать INNER JOIN следующим образом:
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
Приведенный выше запрос даст следующий результат –
emp_id | name | dept
--------+-------+------------
1 | Paul | IT Billing
2 | Allen | Engineering
ЛЕВОЕ НАРУЖНОЕ СОЕДИНЕНИЕ
НАРУЖНОЕ СОЕДИНЕНИЕ является продолжением ВНУТРЕННЕГО СОЕДИНЕНИЯ. Стандарт SQL определяет три типа OUTER JOIN: LEFT, RIGHT и FULL, а PostgreSQL поддерживает все это.
В случае LEFT OUTER JOIN сначала выполняется внутреннее соединение. Затем для каждой строки в таблице T1, которая не удовлетворяет условию соединения с какой-либо строкой в таблице T2, добавляется объединенная строка с нулевыми значениями в столбцах T2. Таким образом, объединенная таблица всегда имеет хотя бы одну строку для каждой строки в T1.
Ниже приведен синтаксис LEFT OUTER JOIN –
SELECT ... FROM table1 LEFT OUTER JOIN table2 ON conditional_expression ...
На основании приведенных выше таблиц мы можем написать внутреннее соединение следующим образом:
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
Приведенный выше запрос даст следующий результат –
emp_id | name | dept
--------+-------+------------
1 | Paul | IT Billing
2 | Allen | Engineering
| James |
| David |
| Paul |
| Mark |
| Teddy |
| James |
ПРАВИЛЬНОЕ НАРУЖНОЕ СОЕДИНЕНИЕ
Сначала выполняется внутреннее соединение. Затем для каждой строки в таблице T2, которая не удовлетворяет условию соединения с какой-либо строкой в таблице T1, присоединенная строка добавляется с нулевыми значениями в столбцах T1. Это противоположность левого соединения; В таблице результатов всегда будет строка для каждой строки в T2.
Ниже приведен синтаксис RIGHT OUTER JOIN –
SELECT ... FROM table1 RIGHT OUTER JOIN table2 ON conditional_expression ...
На основании приведенных выше таблиц мы можем написать внутреннее соединение следующим образом:
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY RIGHT OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
Приведенный выше запрос даст следующий результат –
emp_id | name | dept
--------+-------+--------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | | Finance
ПОЛНОЕ НАРУЖНОЕ СОЕДИНЕНИЕ
Сначала выполняется внутреннее соединение. Затем для каждой строки в таблице T1, которая не удовлетворяет условию соединения с какой-либо строкой в таблице T2, добавляется объединенная строка с нулевыми значениями в столбцах T2. Кроме того, для каждой строки T2, которая не удовлетворяет условию соединения с какой-либо строкой в T1, добавляется объединенная строка с нулевыми значениями в столбцах T1.
Ниже приведен синтаксис FULL OUTER JOIN –
SELECT ... FROM table1 FULL OUTER JOIN table2 ON conditional_expression ...
На основании приведенных выше таблиц мы можем написать внутреннее соединение следующим образом:
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY FULL OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
Приведенный выше запрос даст следующий результат –
emp_id | name | dept
--------+-------+---------------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | | Finance
| James |
| David |
| Paul |
| Mark |
| Teddy |
| James |
PostgreSQL – предложение UNIONS
Оператор / оператор PostgreSQL UNION используется для объединения результатов двух или более операторов SELECT без возврата повторяющихся строк.
Чтобы использовать UNION, каждый SELECT должен иметь одинаковое количество выбранных столбцов, одинаковое количество выражений столбцов, один и тот же тип данных и иметь их в одном порядке, но они не обязательно должны быть одинаковой длины.
Синтаксис
Основной синтаксис UNION выглядит следующим образом –
SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition] UNION SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition]
Здесь, данное условие может быть любым выражением, основанным на вашем требовании.
пример
Рассмотрим следующие две таблицы: (а) Таблица КОМПАНИИ выглядит следующим образом –
testdb=# SELECT * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
(б) Другая таблица – это ОТДЕЛ следующего содержания:
testdb=# SELECT * from DEPARTMENT; id | dept | emp_id ----+-------------+-------- 1 | IT Billing | 1 2 | Engineering | 2 3 | Finance | 7 4 | Engineering | 3 5 | Finance | 4 6 | Engineering | 5 7 | Finance | 6 (7 rows)
Теперь давайте объединим эти две таблицы, используя инструкцию SELECT вместе с предложением UNION следующим образом:
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID UNION SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
Это даст следующий результат –
emp_id | name | dept
--------+-------+--------------
5 | David | Engineering
6 | Kim | Finance
2 | Allen | Engineering
3 | Teddy | Engineering
4 | Mark | Finance
1 | Paul | IT Billing
7 | James | Finance
(7 rows)
СОЮЗ ВСЕ Статья
Оператор UNION ALL используется для объединения результатов двух операторов SELECT, включая повторяющиеся строки. Те же правила, которые применяются к UNION, применяются и к оператору UNION ALL.
Синтаксис
Основной синтаксис UNION ALL следующий:
SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition] UNION ALL SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition]
Здесь, данное условие может быть любым выражением, основанным на вашем требовании.
пример
Теперь давайте объединим две вышеупомянутые таблицы в нашем операторе SELECT следующим образом:
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID UNION ALL SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
Это даст следующий результат –
emp_id | name | dept
--------+-------+--------------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | James | Finance
3 | Teddy | Engineering
4 | Mark | Finance
5 | David | Engineering
6 | Kim | Finance
1 | Paul | IT Billing
2 | Allen | Engineering
7 | James | Finance
3 | Teddy | Engineering
4 | Mark | Finance
5 | David | Engineering
6 | Kim | Finance
(14 rows)
PostgreSQL – значения NULL
PostgreSQL NULL – это термин, используемый для обозначения пропущенного значения. Значение NULL в таблице – это значение в поле, которое кажется пустым.
Поле со значением NULL является полем без значения. Очень важно понимать, что значение NULL отличается от нулевого значения или поля, которое содержит пробелы.
Синтаксис
Основной синтаксис использования NULL при создании таблицы следующий:
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
Здесь NOT NULL означает, что столбец всегда должен принимать явное значение данного типа данных. Есть два столбца, в которых мы не использовали NOT NULL. Следовательно, это означает, что эти столбцы могут быть NULL.
Поле со значением NULL – это поле, которое было оставлено пустым при создании записи.
пример
Значение NULL может вызвать проблемы при выборе данных, поскольку при сравнении неизвестного значения с любым другим значением результат всегда неизвестен и не включается в окончательные результаты. Рассмотрим следующую таблицу, КОМПАНИЯ, имеющая следующие записи –
ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 1 Paul 32 California 20000.0 2 Allen 25 Texas 15000.0 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0 6 Kim 22 South-Hall 45000.0 7 James 24 Houston 10000.0
Давайте используем оператор UPDATE, чтобы установить несколько значений NULL в NULL следующим образом:
testdb=# UPDATE COMPANY SET ADDRESS = NULL, SALARY = NULL where ID IN(6,7);
Теперь в таблице COMPANY должны быть следующие записи:
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | | 7 | James | 24 | | (7 rows)
Далее, давайте посмотрим на использование оператора IS NOT NULL для вывода списка всех записей, где SALARY не равен NULL –
testdb=# SELECT ID, NAME, AGE, ADDRESS, SALARY FROM COMPANY WHERE SALARY IS NOT NULL;
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (5 rows)
Ниже приводится использование оператора IS NULL, который перечислит все записи, где SALARY равен NULL.
testdb=# SELECT ID, NAME, AGE, ADDRESS, SALARY FROM COMPANY WHERE SALARY IS NULL;
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | address | salary ----+-------+-----+---------+-------- 6 | Kim | 22 | | 7 | James | 24 | | (2 rows)
PostgreSQL – Синтаксис ALIAS
Вы можете временно переименовать таблицу или столбец, указав другое имя, известное как ALIAS . Использование псевдонимов таблиц означает переименование таблицы в конкретном операторе PostgreSQL. Переименование является временным изменением, и фактическое имя таблицы не изменяется в базе данных.
Псевдонимы столбцов используются для переименования столбцов таблицы с целью конкретного запроса PostgreSQL.
Синтаксис
Основной синтаксис псевдонима таблицы следующий:
SELECT column1, column2.... FROM table_name AS alias_name WHERE [condition];
Основной синтаксис псевдонима столбца следующий:
SELECT column_name AS alias_name FROM table_name WHERE [condition];
пример
Рассмотрим следующие две таблицы: (а) Таблица КОМПАНИИ выглядит следующим образом –
testdb=# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
(б) Другая таблица – это ОТДЕЛ следующего содержания:
id | dept | emp_id ----+--------------+-------- 1 | IT Billing | 1 2 | Engineering | 2 3 | Finance | 7 4 | Engineering | 3 5 | Finance | 4 6 | Engineering | 5 7 | Finance | 6 (7 rows)
Далее следует использование TABLE ALIAS, где мы используем C и D в качестве псевдонимов для таблиц COMPANY и DEPARTMENT соответственно –
testdb=# SELECT C.ID, C.NAME, C.AGE, D.DEPT FROM COMPANY AS C, DEPARTMENT AS D WHERE C.ID = D.EMP_ID;
Приведенный выше оператор PostgreSQL даст следующий результат:
id | name | age | dept ----+-------+-----+------------ 1 | Paul | 32 | IT Billing 2 | Allen | 25 | Engineering 7 | James | 24 | Finance 3 | Teddy | 23 | Engineering 4 | Mark | 25 | Finance 5 | David | 27 | Engineering 6 | Kim | 22 | Finance (7 rows)
Давайте рассмотрим пример использования COLUMN ALIAS, где COMPANY_ID – это столбец псевдонимов идентификатора, а COMPANY_NAME – столбец псевдонимов имен.
testdb=# SELECT C.ID AS COMPANY_ID, C.NAME AS COMPANY_NAME, C.AGE, D.DEPT FROM COMPANY AS C, DEPARTMENT AS D WHERE C.ID = D.EMP_ID;
Приведенный выше оператор PostgreSQL даст следующий результат:
company_id | company_name | age | dept
------------+--------------+-----+------------
1 | Paul | 32 | IT Billing
2 | Allen | 25 | Engineering
7 | James | 24 | Finance
3 | Teddy | 23 | Engineering
4 | Mark | 25 | Finance
5 | David | 27 | Engineering
6 | Kim | 22 | Finance
(7 rows)
PostgreSQL – ТРИГГЕРС
Триггеры PostgreSQL – это функции обратного вызова базы данных, которые автоматически выполняются / запускаются, когда происходит указанное событие базы данных.
Ниже приведены важные моменты, касающиеся триггеров PostgreSQL:
-
Триггер PostgreSQL может быть указан для запуска
-
Перед попыткой операции над строкой (перед проверкой ограничений и попыткой INSERT, UPDATE или DELETE)
-
После завершения операции (после проверки ограничений и завершения INSERT, UPDATE или DELETE)
-
Вместо операции (в случае вставки, обновления или удаления в представлении)
-
-
Триггер, помеченный FOR EACH ROW, вызывается один раз для каждой строки, которую изменяет операция. Напротив, триггер, помеченный FOR EACH STATEMENT, выполняется только один раз для любой данной операции, независимо от того, сколько строк он изменяет.
-
И предложение WHEN, и действия триггера могут обращаться к элементам вставляемой, удаляемой или обновляемой строки, используя ссылки в форме NEW.column-name и OLD.column-name , где column-name – это имя столбца из таблица, с которой связан триггер.
-
Если указано предложение WHEN, указанные операторы PostgreSQL выполняются только для тех строк, для которых предложение WHEN является истинным. Если предложение WHEN не указано, операторы PostgreSQL выполняются для всех строк.
-
Если для одного и того же события определены несколько триггеров одного и того же типа, они будут срабатывать в алфавитном порядке по имени.
-
Ключевое слово BEFORE, AFTER или INSTEAD OF определяет, когда действия триггера будут выполнены относительно вставки, изменения или удаления связанной строки.
-
Триггеры автоматически удаляются при удалении таблицы, с которой они связаны.
-
Изменяемая таблица должна существовать в той же базе данных, что и таблица или представление, к которому присоединен триггер, и необходимо использовать только имя таблицы , а не database.tablename .
-
Опция CONSTRAINT, когда она указана, создает триггер ограничения . Это то же самое, что и обычный триггер, за исключением того, что время срабатывания триггера можно настроить с помощью SET CONSTRAINTS. Ожидается, что триггеры ограничения вызовут исключение, когда реализуемые ими ограничения нарушены.
Триггер PostgreSQL может быть указан для запуска
Перед попыткой операции над строкой (перед проверкой ограничений и попыткой INSERT, UPDATE или DELETE)
После завершения операции (после проверки ограничений и завершения INSERT, UPDATE или DELETE)
Вместо операции (в случае вставки, обновления или удаления в представлении)
Триггер, помеченный FOR EACH ROW, вызывается один раз для каждой строки, которую изменяет операция. Напротив, триггер, помеченный FOR EACH STATEMENT, выполняется только один раз для любой данной операции, независимо от того, сколько строк он изменяет.
И предложение WHEN, и действия триггера могут обращаться к элементам вставляемой, удаляемой или обновляемой строки, используя ссылки в форме NEW.column-name и OLD.column-name , где column-name – это имя столбца из таблица, с которой связан триггер.
Если указано предложение WHEN, указанные операторы PostgreSQL выполняются только для тех строк, для которых предложение WHEN является истинным. Если предложение WHEN не указано, операторы PostgreSQL выполняются для всех строк.
Если для одного и того же события определены несколько триггеров одного и того же типа, они будут срабатывать в алфавитном порядке по имени.
Ключевое слово BEFORE, AFTER или INSTEAD OF определяет, когда действия триггера будут выполнены относительно вставки, изменения или удаления связанной строки.
Триггеры автоматически удаляются при удалении таблицы, с которой они связаны.
Изменяемая таблица должна существовать в той же базе данных, что и таблица или представление, к которому присоединен триггер, и необходимо использовать только имя таблицы , а не database.tablename .
Опция CONSTRAINT, когда она указана, создает триггер ограничения . Это то же самое, что и обычный триггер, за исключением того, что время срабатывания триггера можно настроить с помощью SET CONSTRAINTS. Ожидается, что триггеры ограничения вызовут исключение, когда реализуемые ими ограничения нарушены.
Синтаксис
Основной синтаксис создания триггера следующий:
CREATE TRIGGER trigger_name [BEFORE|AFTER|INSTEAD OF] event_name ON table_name [ -- Trigger logic goes here.... ];
Здесь, event_name может быть операцией базы данных INSERT, DELETE, UPDATE и TRUNCATE над упомянутой таблицей table_name . При желании вы можете указать FOR EACH ROW после имени таблицы.
Ниже приведен синтаксис создания триггера для операции UPDATE для одного или нескольких указанных столбцов таблицы следующим образом:
CREATE TRIGGER trigger_name [BEFORE|AFTER] UPDATE OF column_name ON table_name [ -- Trigger logic goes here.... ];
пример
Давайте рассмотрим случай, когда мы хотим сохранить аудиторскую проверку для каждой записи, вставляемой в таблицу COMPANY, которую мы создадим заново следующим образом (удалите таблицу COMPANY, если она у вас уже есть).
testdb=# CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
Чтобы продолжить аудит, мы создадим новую таблицу с именем AUDIT, куда будут добавляться сообщения журнала всякий раз, когда в таблице COMPANY есть запись для новой записи –
testdb=# CREATE TABLE AUDIT( EMP_ID INT NOT NULL, ENTRY_DATE TEXT NOT NULL );
Здесь ID – это идентификатор записи AUDIT, а EMP_ID – это идентификатор, который будет получен из таблицы COMPANY, а DATE сохранит временную метку, когда запись будет создана в таблице COMPANY. Итак, теперь давайте создадим триггер для таблицы COMPANY следующим образом:
testdb=# CREATE TRIGGER example_trigger AFTER INSERT ON COMPANY FOR EACH ROW EXECUTE PROCEDURE auditlogfunc();
Где auditlogfunc () является процедурой PostgreSQL и имеет следующее определение:
CREATE OR REPLACE FUNCTION auditlogfunc() RETURNS TRIGGER AS $example_table$ BEGIN INSERT INTO AUDIT(EMP_ID, ENTRY_DATE) VALUES (new.ID, current_timestamp); RETURN NEW; END; $example_table$ LANGUAGE plpgsql;
Теперь мы начнем реальную работу. Давайте начнем вставлять запись в таблицу COMPANY, что должно привести к созданию записи журнала аудита в таблице AUDIT. Итак, давайте создадим одну запись в таблице COMPANY следующим образом:
testdb=# INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Paul', 32, 'California', 20000.00 );
Это создаст одну запись в таблице COMPANY, которая выглядит следующим образом:
id | name | age | address | salary ----+------+-----+--------------+-------- 1 | Paul | 32 | California | 20000
Одновременно в таблице AUDIT будет создана одна запись. Эта запись является результатом триггера, который мы создали в операции INSERT для таблицы COMPANY. Точно так же вы можете создавать свои триггеры для операций UPDATE и DELETE в соответствии с вашими требованиями.
emp_id | entry_date --------+------------------------------- 1 | 2013-05-05 15:49:59.968+05:30 (1 row)
Листинг ТРИГГЕРС
Вы можете перечислить все триггеры в текущей базе данных из таблицы pg_trigger следующим образом:
testdb=# SELECT * FROM pg_trigger;
Приведенный выше оператор PostgreSQL перечислит все триггеры.
Если вы хотите перечислить триггеры в конкретной таблице, используйте предложение AND с именем таблицы следующим образом:
testdb=# SELECT tgname FROM pg_trigger, pg_class WHERE tgrelid=pg_class.oid AND relname='company';
Приведенный выше оператор PostgreSQL также перечислит только одну запись следующим образом:
tgname ----------------- example_trigger (1 row)
Отбрасывание ТРИГГЕРС
Ниже приведена команда DROP, с помощью которой можно удалить существующий триггер:
testdb=# DROP TRIGGER trigger_name;
PostgreSQL – ИНДЕКСЫ
Индексы – это специальные таблицы поиска, которые поисковая система базы данных может использовать для ускорения поиска данных. Проще говоря, индекс – это указатель на данные в таблице. Индекс в базе данных очень похож на индекс в конце книги.
Например, если вы хотите сослаться на все страницы в книге, где обсуждается определенная тема, вы должны сначала обратиться к индексу, в котором перечислены все темы в алфавитном порядке, а затем к одному или нескольким конкретным номерам страниц.
Индекс помогает ускорить запросы SELECT и предложения WHERE; однако это замедляет ввод данных с помощью операторов UPDATE и INSERT. Индексы могут быть созданы или удалены без влияния на данные.
Создание индекса включает в себя инструкцию CREATE INDEX, которая позволяет указать имя индекса, указать таблицу и столбец или столбцы для индексации и указать, находится ли индекс в порядке возрастания или убывания.
Индексы также могут быть уникальными, подобно ограничению UNIQUE, в том смысле, что индекс предотвращает дублирование записей в столбце или комбинации столбцов, для которых существует индекс.
Команда CREATE INDEX
Основной синтаксис CREATE INDEX следующий:
CREATE INDEX index_name ON table_name;
Типы индексов
PostgreSQL предоставляет несколько типов индексов: B-дерево, Hash, GiST, SP-GiST и GIN. Каждый тип индекса использует свой алгоритм, который лучше всего подходит для разных типов запросов. По умолчанию команда CREATE INDEX создает индексы B-дерева, которые соответствуют наиболее распространенным ситуациям.
Одноколонные индексы
Индекс с одним столбцом – это индекс, который создается на основе только одного столбца таблицы. Основной синтаксис выглядит следующим образом –
CREATE INDEX index_name ON table_name (column_name);
Многоколонные индексы
Многоколонный индекс определяется более чем в одном столбце таблицы. Основной синтаксис выглядит следующим образом –
CREATE INDEX index_name ON table_name (column1_name, column2_name);
Независимо от того, хотите ли вы создать индекс из одного столбца или индекс из нескольких столбцов, примите во внимание столбцы, которые вы можете использовать очень часто в предложении WHERE запроса в качестве условий фильтра.
Если используется только один столбец, то должен быть выбран индекс из одного столбца. Если в предложении WHERE в качестве фильтров часто используются два или более столбца, наилучшим выбором будет многоколонный индекс.
Уникальные индексы
Уникальные индексы используются не только для производительности, но и для целостности данных. Уникальный индекс не позволяет вставлять повторяющиеся значения в таблицу. Основной синтаксис выглядит следующим образом –
CREATE UNIQUE INDEX index_name on table_name (column_name);
Частичные индексы
Частичный индекс – это индекс, построенный на подмножестве таблицы; подмножество определяется условным выражением (называемым предикатом частичного индекса). Индекс содержит записи только для тех строк таблицы, которые удовлетворяют предикату. Основной синтаксис выглядит следующим образом –
CREATE INDEX index_name on table_name (conditional_expression);
Неявные индексы
Неявные индексы – это индексы, которые автоматически создаются сервером базы данных при создании объекта. Индексы автоматически создаются для ограничений первичного ключа и уникальных ограничений.
пример
Ниже приведен пример, где мы создадим индекс для таблицы COMPANY для столбца зарплаты:
# CREATE INDEX salary_index ON COMPANY (salary);
Теперь давайте перечислим все индексы, доступные в таблице COMPANY, с помощью команды d company .
# d company
Это приведет к следующему результату, где company_pkey – неявный индекс, который был создан при создании таблицы.
Table "public.company" Column | Type | Modifiers ---------+---------------+----------- id | integer | not null name | text | not null age | integer | not null address | character(50) | salary | real | Indexes: "company_pkey" PRIMARY KEY, btree (id) "salary_index" btree (salary)
Вы можете составить список всей базы данных индексов, используя команду di –
Команда DROP INDEX
Индекс можно удалить с помощью команды PostgreSQL DROP . При отбрасывании индекса следует соблюдать осторожность, поскольку производительность может быть замедлена или улучшена.
Основной синтаксис выглядит следующим образом –
DROP INDEX index_name;
Вы можете использовать следующую инструкцию для удаления ранее созданного индекса –
# DROP INDEX salary_index;
Когда следует избегать индексов?
Хотя индексы предназначены для повышения производительности базы данных, бывают случаи, когда их следует избегать. Следующие рекомендации указывают, когда следует пересмотреть использование индекса:
-
Индексы не должны использоваться на маленьких столах.
-
Таблицы с частыми, крупными пакетными обновлениями или операциями вставки.
-
Индексы не должны использоваться для столбцов, которые содержат большое количество значений NULL.
-
Столбцы, которыми часто манипулируют, не должны индексироваться.
Индексы не должны использоваться на маленьких столах.
Таблицы с частыми, крупными пакетными обновлениями или операциями вставки.
Индексы не должны использоваться для столбцов, которые содержат большое количество значений NULL.
Столбцы, которыми часто манипулируют, не должны индексироваться.
PostgreSQL – команда ALTER TABLE
Команда PostgreSQL ALTER TABLE используется для добавления, удаления или изменения столбцов в существующей таблице.
Вы также можете использовать команду ALTER TABLE для добавления и удаления различных ограничений в существующей таблице.
Синтаксис
Основной синтаксис ALTER TABLE для добавления нового столбца в существующую таблицу выглядит следующим образом:
ALTER TABLE table_name ADD column_name datatype;
Основной синтаксис ALTER TABLE to DROP COLUMN в существующей таблице следующий:
ALTER TABLE table_name DROP COLUMN column_name;
Основной синтаксис ALTER TABLE для изменения типа данных столбца в таблице выглядит следующим образом:
ALTER TABLE table_name ALTER COLUMN column_name TYPE datatype;
Основной синтаксис ALTER TABLE для добавления ограничения NOT NULL к столбцу в таблице следующий:
ALTER TABLE table_name MODIFY column_name datatype NOT NULL;
Основной синтаксис ALTER TABLE для ДОБАВЛЕНИЯ УНИКАЛЬНОГО ОГРАНИЧЕНИЯ в таблицу выглядит следующим образом:
ALTER TABLE table_name ADD CONSTRAINT MyUniqueConstraint UNIQUE(column1, column2...);
Основной синтаксис команды ALTER TABLE to ADD CHECK CONSTRAINT для таблицы следующий:
ALTER TABLE table_name ADD CONSTRAINT MyUniqueConstraint CHECK (CONDITION);
Основной синтаксис ограничения ALTER TABLE to ADD PRIMARY KEY для таблицы следующий:
ALTER TABLE table_name ADD CONSTRAINT MyPrimaryKey PRIMARY KEY (column1, column2...);
Основной синтаксис ALTER TABLE to DROP CONSTRAINT из таблицы следующий:
ALTER TABLE table_name DROP CONSTRAINT MyUniqueConstraint;
Если вы используете MySQL, код выглядит следующим образом –
ALTER TABLE table_name DROP INDEX MyUniqueConstraint;
Основной синтаксис ограничения ALTER TABLE to DROP PRIMARY KEY из таблицы следующий:
ALTER TABLE table_name DROP CONSTRAINT MyPrimaryKey;
Если вы используете MySQL, код выглядит следующим образом –
ALTER TABLE table_name DROP PRIMARY KEY;
пример
Считайте, что наша таблица КОМПАНИИ имеет следующие записи –
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
Ниже приведен пример добавления нового столбца в существующую таблицу:
testdb=# ALTER TABLE COMPANY ADD GENDER char(1);
Теперь таблица COMPANY изменяется, и следующий результат будет выводиться из оператора SELECT –
id | name | age | address | salary | gender ----+-------+-----+-------------+--------+-------- 1 | Paul | 32 | California | 20000 | 2 | Allen | 25 | Texas | 15000 | 3 | Teddy | 23 | Norway | 20000 | 4 | Mark | 25 | Rich-Mond | 65000 | 5 | David | 27 | Texas | 85000 | 6 | Kim | 22 | South-Hall | 45000 | 7 | James | 24 | Houston | 10000 | (7 rows)
Ниже приведен пример удаления столбца пола из существующей таблицы:
testdb=# ALTER TABLE COMPANY DROP GENDER;
Теперь таблица COMPANY изменяется, и следующий результат будет выводиться из оператора SELECT –
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
PostgreSQL – команда TRUNCATE TABLE
Команда PostgreSQL TRUNCATE TABLE используется для удаления полных данных из существующей таблицы. Вы также можете использовать команду DROP TABLE для удаления полной таблицы, но это приведет к удалению полной структуры таблицы из базы данных, и вам потребуется заново создать эту таблицу, если вы хотите сохранить некоторые данные.
Он имеет тот же эффект, что и DELETE для каждой таблицы, но поскольку он фактически не сканирует таблицы, он работает быстрее. Кроме того, он немедленно восстанавливает дисковое пространство, а не требует последующей операции VACUUM. Это наиболее полезно на больших столах.
Синтаксис
Основной синтаксис TRUNCATE TABLE следующий:
TRUNCATE TABLE table_name;
пример
Предположим, что таблица COMPANY содержит следующие записи:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (7 rows)
Ниже приведен пример усечения –
testdb=# TRUNCATE TABLE COMPANY;
Теперь таблица COMPANY усекается, и следующим будет вывод оператора SELECT –
testdb=# SELECT * FROM CUSTOMERS; id | name | age | address | salary ----+------+-----+---------+-------- (0 rows)
PostgreSQL – ВИДЫ
Представления являются псевдотабличными. То есть они не являются настоящими таблицами; тем не менее отображаются как обычные таблицы для выбора. Представление может представлять подмножество реальной таблицы, выбирая определенные столбцы или определенные строки из обычной таблицы. Представление может даже представлять объединенные таблицы. Поскольку представлениям назначаются отдельные разрешения, их можно использовать для ограничения доступа к таблице, чтобы пользователи могли видеть только определенные строки или столбцы таблицы.
Представление может содержать все строки таблицы или выбранные строки из одной или нескольких таблиц. Представление может быть создано из одной или нескольких таблиц, что зависит от написанного запроса PostgreSQL для создания представления.
Представления, которые являются своего рода виртуальными таблицами, позволяют пользователям делать следующее:
-
Структурируйте данные так, чтобы пользователи или классы пользователей находили естественные или интуитивно понятные.
-
Ограничьте доступ к данным таким образом, чтобы пользователь мог видеть только ограниченные данные вместо полной таблицы.
-
Суммируйте данные из различных таблиц, которые можно использовать для создания отчетов.
Структурируйте данные так, чтобы пользователи или классы пользователей находили естественные или интуитивно понятные.
Ограничьте доступ к данным таким образом, чтобы пользователь мог видеть только ограниченные данные вместо полной таблицы.
Суммируйте данные из различных таблиц, которые можно использовать для создания отчетов.
Поскольку представления не являются обычными таблицами, вы не сможете выполнить оператор DELETE, INSERT или UPDATE для представления. Однако вы можете создать ПРАВИЛО, чтобы исправить эту проблему, используя DELETE, INSERT или UPDATE для представления.
Создание видов
Представления PostgreSQL создаются с помощью оператора CREATE VIEW . Представления PostgreSQL могут быть созданы из одной таблицы, нескольких таблиц или другого представления.
Основной синтаксис CREATE VIEW следующий:
CREATE [TEMP | TEMPORARY] VIEW view_name AS SELECT column1, column2..... FROM table_name WHERE [condition];
Вы можете включить несколько таблиц в свой оператор SELECT таким же образом, как вы используете их в обычном запросе PostgreSQL SELECT. Если присутствует необязательное ключевое слово TEMP или TEMPORARY, представление будет создано во временном пространстве. Временные представления автоматически удаляются в конце текущего сеанса.
пример
Представьте, что таблица COMPANY содержит следующие записи:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000
Далее приведен пример создания представления из таблицы COMPANY. Это представление будет использоваться только для нескольких столбцов из таблицы COMPANY –
testdb=# CREATE VIEW COMPANY_VIEW AS SELECT ID, NAME, AGE FROM COMPANY;
Теперь вы можете запросить COMPANY_VIEW аналогично запросу реальной таблицы. Ниже приведен пример –
testdb=# SELECT * FROM COMPANY_VIEW;
Это даст следующий результат –
id | name | age ----+-------+----- 1 | Paul | 32 2 | Allen | 25 3 | Teddy | 23 4 | Mark | 25 5 | David | 27 6 | Kim | 22 7 | James | 24 (7 rows)
Отбрасывание просмотров
Чтобы отбросить представление, просто используйте оператор DROP VIEW с view_name . Основной синтаксис DROP VIEW выглядит следующим образом:
testdb=# DROP VIEW view_name;
Следующая команда удалит представление COMPANY_VIEW, которое мы создали в последнем разделе –
testdb=# DROP VIEW COMPANY_VIEW;
PostgreSQL – СДЕЛКИ
Транзакция – это единица работы, выполняемая с базой данных. Транзакции – это единицы или последовательности работы, выполняемые в логическом порядке, либо вручную пользователем, либо автоматически какой-либо программой базы данных.
Транзакция – это распространение одного или нескольких изменений в базе данных. Например, если вы создаете запись, обновляете запись или удаляете запись из таблицы, то вы выполняете транзакцию для таблицы. Важно контролировать транзакции для обеспечения целостности данных и обработки ошибок базы данных.
Практически вы объедините много запросов PostgreSQL в группу и выполните все их вместе как часть транзакции.
Свойства сделок
Транзакции имеют следующие четыре стандартных свойства, обычно обозначаемых аббревиатурой ACID –
-
Атомарность – гарантирует, что все операции внутри рабочего блока успешно завершены; в противном случае транзакция прерывается в точке сбоя, а предыдущие операции возвращаются в прежнее состояние.
-
Согласованность – Гарантирует, что база данных корректно меняет состояния при успешной фиксации транзакции.
-
Изоляция – позволяет транзакциям работать независимо друг от друга и быть прозрачными друг для друга.
-
Долговечность – Гарантирует, что результат или результат совершенной транзакции сохраняется в случае сбоя системы.
Атомарность – гарантирует, что все операции внутри рабочего блока успешно завершены; в противном случае транзакция прерывается в точке сбоя, а предыдущие операции возвращаются в прежнее состояние.
Согласованность – Гарантирует, что база данных корректно меняет состояния при успешной фиксации транзакции.
Изоляция – позволяет транзакциям работать независимо друг от друга и быть прозрачными друг для друга.
Долговечность – Гарантирует, что результат или результат совершенной транзакции сохраняется в случае сбоя системы.
Контроль транзакций
Следующие команды используются для управления транзакциями –
-
BEGIN TRANSACTION – начать транзакцию.
-
COMMIT – для сохранения изменений вы также можете использовать команду END TRANSACTION .
-
ROLLBACK – для отката изменений.
BEGIN TRANSACTION – начать транзакцию.
COMMIT – для сохранения изменений вы также можете использовать команду END TRANSACTION .
ROLLBACK – для отката изменений.
Команды управления транзакциями используются только с командами DML INSERT, UPDATE и DELETE. Их нельзя использовать при создании таблиц или их удалении, поскольку эти операции автоматически фиксируются в базе данных.
Команда НАЧАЛО СДЕЛКИ
Транзакции могут быть начаты с использованием BEGIN TRANSACTION или просто BEGIN. Такие транзакции обычно сохраняются до следующей команды COMMIT или ROLLBACK. Но транзакция также ROLLBACK, если база данных закрыта или возникает ошибка.
Ниже приведен простой синтаксис для запуска транзакции:
BEGIN; or BEGIN TRANSACTION;
Команда COMMIT
Команда COMMIT – это команда транзакций, используемая для сохранения изменений, вызванных транзакцией, в базу данных.
Команда COMMIT сохраняет все транзакции в базе данных с момента последней команды COMMIT или ROLLBACK.
Синтаксис команды COMMIT следующий:
COMMIT; or END TRANSACTION;
Команда ROLLBACK
Команда ROLLBACK – это команда транзакций, используемая для отмены транзакций, которые еще не были сохранены в базе данных.
Команду ROLLBACK можно использовать только для отмены транзакций с момента выполнения последней команды COMMIT или ROLLBACK.
Синтаксис команды ROLLBACK следующий:
ROLLBACK;
пример
Предположим, что таблица COMPANY содержит следующие записи:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
Теперь давайте запустим транзакцию и удалим записи из таблицы, имеющие возраст = 25, и, наконец, мы используем команду ROLLBACK, чтобы отменить все изменения.
testdb=# BEGIN; DELETE FROM COMPANY WHERE AGE = 25; ROLLBACK;
Если вы проверите, в таблице COMPANY все еще есть следующие записи –
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
Теперь давайте запустим еще одну транзакцию и удалим записи из таблицы, имеющие возраст = 25, и, наконец, мы используем команду COMMIT, чтобы зафиксировать все изменения.
testdb=# BEGIN; DELETE FROM COMPANY WHERE AGE = 25; COMMIT;
Если вы проверите таблицу COMPANY, она все еще имеет следующие записи –
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 3 | Teddy | 23 | Norway | 20000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (5 rows)
PostgreSQL – LOCKS
Блокировки или эксклюзивные блокировки или блокировки записи не позволяют пользователям изменять строку или всю таблицу. Строки, измененные UPDATE и DELETE, затем автоматически блокируются исключительно на время транзакции. Это не позволяет другим пользователям изменять строку, пока транзакция не будет зафиксирована или откатана.
Единственный раз, когда пользователи должны ждать других пользователей, это когда они пытаются изменить одну и ту же строку. Если они изменяют разные строки, ожидание не требуется. Запросы SELECT никогда не должны ждать.
База данных выполняет блокировку автоматически. Однако в некоторых случаях блокировка должна контролироваться вручную. Ручная блокировка может быть выполнена с помощью команды LOCK. Это позволяет указывать тип и область блокировки транзакции.
Синтаксис для команды LOCK
Основной синтаксис команды LOCK следующий:
LOCK [ TABLE ] name IN lock_mode
-
name – Имя (возможно, дополненное схемой) существующей таблицы для блокировки. Если перед именем таблицы указано ТОЛЬКО, блокируется только эта таблица. Если не указано ТОЛЬКО, таблица и все ее дочерние таблицы (если есть) заблокированы.
-
lock_mode – режим блокировки определяет, с какими блокировками конфликтует эта блокировка. Если режим блокировки не указан, то используется ACCESS EXCLUSIVE, наиболее ограниченный режим. Возможные значения: ДОСТУП РАЗДЕЛИТЬ, СТРОИТЬ ПОДЕЛИТЬСЯ, СТРОИТЬ ЭКСКЛЮЗИВ, ПОДЕЛИТЬСЯ ОБНОВИТЬ ЭКСКЛЮЗИВ, ПОДЕЛИТЬСЯ, ПОДЕЛИТЬСЯ СТРОК ЭКСКЛЮЗИВНО, ЭКСКЛЮЗИВНО, ДОСТУП ЭКСКЛЮЗИВНО.
name – Имя (возможно, дополненное схемой) существующей таблицы для блокировки. Если перед именем таблицы указано ТОЛЬКО, блокируется только эта таблица. Если не указано ТОЛЬКО, таблица и все ее дочерние таблицы (если есть) заблокированы.
lock_mode – режим блокировки определяет, с какими блокировками конфликтует эта блокировка. Если режим блокировки не указан, то используется ACCESS EXCLUSIVE, наиболее ограниченный режим. Возможные значения: ДОСТУП РАЗДЕЛИТЬ, СТРОИТЬ ПОДЕЛИТЬСЯ, СТРОИТЬ ЭКСКЛЮЗИВ, ПОДЕЛИТЬСЯ ОБНОВИТЬ ЭКСКЛЮЗИВ, ПОДЕЛИТЬСЯ, ПОДЕЛИТЬСЯ СТРОК ЭКСКЛЮЗИВНО, ЭКСКЛЮЗИВНО, ДОСТУП ЭКСКЛЮЗИВНО.
После получения блокировка удерживается до конца текущей транзакции. Нет команды UNLOCK TABLE; блокировки всегда снимаются в конце транзакции.
ТУПИКИ
Взаимные блокировки могут возникать, когда две транзакции ожидают завершения друг друга. Хотя PostgreSQL может обнаружить их и завершить их ROLLBACK, взаимоблокировки могут быть неудобными. Чтобы ваши приложения не сталкивались с этой проблемой, проектируйте их так, чтобы они блокировали объекты в том же порядке.
Консультативные Замки
PostgreSQL предоставляет средства для создания блокировок, которые имеют значения, определенные приложением. Это так называемые консультативные блокировки . Поскольку система не обеспечивает их использование, приложение должно правильно их использовать. Консультативные блокировки могут быть полезны для стратегий блокировки, которые неудобно подходят для модели MVCC.
Например, обычное использование консультативных блокировок состоит в том, чтобы эмулировать стратегии пессимистической блокировки, типичные для так называемых систем управления данными «плоских файлов». Хотя флаг, хранящийся в таблице, может использоваться для той же цели, консультативные блокировки быстрее, избегают раздувания таблиц и автоматически очищаются сервером в конце сеанса.
пример
Рассмотрим таблицу COMPANY, имеющую записи следующим образом:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
В следующем примере таблица COMPANY блокируется в базе данных testdb в режиме ACCESS EXCLUSIVE. Оператор LOCK работает только в режиме транзакции –
testdb=#BEGIN; LOCK TABLE company1 IN ACCESS EXCLUSIVE MODE;
Приведенный выше оператор PostgreSQL даст следующий результат:
LOCK TABLE
Приведенное выше сообщение указывает, что таблица заблокирована до завершения транзакции, и для завершения транзакции вам придется либо откатить, либо зафиксировать транзакцию.
PostgreSQL – подзапросы
Подзапрос, Внутренний запрос или Вложенный запрос – это запрос в другом запросе PostgreSQL, встроенный в предложение WHERE.
Подзапрос используется для возврата данных, которые будут использоваться в основном запросе в качестве условия для дальнейшего ограничения данных, подлежащих извлечению.
Подзапросы могут использоваться с операторами SELECT, INSERT, UPDATE и DELETE вместе с такими операторами, как =, <,>,> =, <=, IN и т. Д.
Есть несколько правил, которым должны следовать подзапросы –
-
Подзапросы должны быть заключены в круглые скобки.
-
У подзапроса может быть только один столбец в предложении SELECT, если в основном запросе нет нескольких столбцов для подзапроса для сравнения его выбранных столбцов.
-
ORDER BY нельзя использовать в подзапросе, хотя основной запрос может использовать ORDER BY. GROUP BY может использоваться для выполнения той же функции, что и ORDER BY в подзапросе.
-
Подзапросы, которые возвращают более одной строки, могут использоваться только с несколькими операторами значений, такими как операторы IN, EXISTS, NOT IN, ANY / SOME, ALL.
-
Оператор BETWEEN нельзя использовать с подзапросом; тем не менее, МЕЖДУ можно использовать в подзапросе.
Подзапросы должны быть заключены в круглые скобки.
У подзапроса может быть только один столбец в предложении SELECT, если в основном запросе нет нескольких столбцов для подзапроса для сравнения его выбранных столбцов.
ORDER BY нельзя использовать в подзапросе, хотя основной запрос может использовать ORDER BY. GROUP BY может использоваться для выполнения той же функции, что и ORDER BY в подзапросе.
Подзапросы, которые возвращают более одной строки, могут использоваться только с несколькими операторами значений, такими как операторы IN, EXISTS, NOT IN, ANY / SOME, ALL.
Оператор BETWEEN нельзя использовать с подзапросом; тем не менее, МЕЖДУ можно использовать в подзапросе.
Подзапросы с оператором SELECT
Подзапросы чаще всего используются с оператором SELECT. Основной синтаксис выглядит следующим образом –
SELECT column_name [, column_name ] FROM table1 [, table2 ] WHERE column_name OPERATOR (SELECT column_name [, column_name ] FROM table1 [, table2 ] [WHERE])
пример
Рассмотрим таблицу COMPANY, имеющую следующие записи:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Теперь давайте проверим следующий подзапрос с оператором SELECT –
testdb=# SELECT * FROM COMPANY WHERE ID IN (SELECT ID FROM COMPANY WHERE SALARY > 45000) ;
Это даст следующий результат –
id | name | age | address | salary ----+-------+-----+-------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (2 rows)
Подзапросы с оператором INSERT
Подзапросы также могут использоваться с операторами INSERT. Оператор INSERT использует данные, возвращенные из подзапроса, для вставки в другую таблицу. Выбранные данные в подзапросе могут быть изменены с помощью любой символьной, даты или числовой функции.
Основной синтаксис выглядит следующим образом –
INSERT INTO table_name [ (column1 [, column2 ]) ] SELECT [ *|column1 [, column2 ] ] FROM table1 [, table2 ] [ WHERE VALUE OPERATOR ]
пример
Рассмотрим таблицу COMPANY_BKP, имеющую структуру, аналогичную таблице COMPANY, и ее можно создать с использованием того же CREATE TABLE, используя COMPANY_BKP, что и имя таблицы. Теперь, чтобы скопировать полную таблицу COMPANY в COMPANY_BKP, следующий синтаксис –
testdb=# INSERT INTO COMPANY_BKP SELECT * FROM COMPANY WHERE ID IN (SELECT ID FROM COMPANY) ;
Подзапросы с оператором UPDATE
Подзапрос может использоваться вместе с оператором UPDATE. Можно использовать один или несколько столбцов в таблице при использовании подзапроса с оператором UPDATE.
Основной синтаксис выглядит следующим образом –
UPDATE table SET column_name = new_value [ WHERE OPERATOR [ VALUE ] (SELECT COLUMN_NAME FROM TABLE_NAME) [ WHERE) ]
пример
Предполагая, что у нас есть таблица COMPANY_BKP, которая является резервной копией таблицы COMPANY.
В следующем примере значение SALARY обновляется в 0,5 раза в таблице COMPANY для всех клиентов, возраст которых больше или равен 27 –
testdb=# UPDATE COMPANY SET SALARY = SALARY * 0.50 WHERE AGE IN (SELECT AGE FROM COMPANY_BKP WHERE AGE >= 27 );
Это повлияет на две строки, и, наконец, таблица COMPANY будет иметь следующие записи:
id | name | age | address | salary ----+-------+-----+-------------+-------- 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 1 | Paul | 32 | California | 10000 5 | David | 27 | Texas | 42500 (7 rows)
Подзапросы с оператором DELETE
Подзапрос может использоваться вместе с оператором DELETE, как и любые другие операторы, упомянутые выше.
Основной синтаксис выглядит следующим образом –
DELETE FROM TABLE_NAME [ WHERE OPERATOR [ VALUE ] (SELECT COLUMN_NAME FROM TABLE_NAME) [ WHERE) ]
пример
Предположим, у нас есть таблица COMPANY_BKP, которая является резервной копией таблицы COMPANY.
В следующем примере удаляются записи из таблицы COMPANY для всех клиентов, возраст которых больше или равен 27 –
testdb=# DELETE FROM COMPANY WHERE AGE IN (SELECT AGE FROM COMPANY_BKP WHERE AGE > 27 );
Это повлияет на две строки, и, наконец, таблица COMPANY будет иметь следующие записи:
id | name | age | address | salary ----+-------+-----+-------------+-------- 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 5 | David | 27 | Texas | 42500 (6 rows)
PostgreSQL – АВТОМАТИЧЕСКИЙ УЧЕТ
PostgreSQL имеет типы данных smallserial , serial и bigserial ; это не настоящие типы, а просто удобство для создания столбцов с уникальным идентификатором. Они похожи на свойство AUTO_INCREMENT, поддерживаемое некоторыми другими базами данных.
Если вы хотите, чтобы последовательный столбец имел уникальное ограничение или был первичным ключом, теперь он должен быть указан, как и любой другой тип данных.
Тип имени serial создает целочисленные столбцы. Имя типа bigserial создает столбец bigint . Следует использовать bigserial , если вы предполагаете использовать более 2 31 идентификаторов за время существования таблицы. Имя типа smallserial создает столбец smallint .
Синтаксис
Основное использование данных SERIAL следующее:
CREATE TABLE tablename ( colname SERIAL );
пример
Рассмотрим таблицу COMPANY, которая будет создана следующим образом:
testdb=# CREATE TABLE COMPANY( ID SERIAL PRIMARY KEY, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
Теперь вставьте следующие записи в таблицу COMPANY –
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY) VALUES ( 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY) VALUES ('Allen', 25, 'Texas', 15000.00 ); INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY) VALUES ('Teddy', 23, 'Norway', 20000.00 ); INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY) VALUES ( 'Mark', 25, 'Rich-Mond ', 65000.00 ); INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY) VALUES ( 'David', 27, 'Texas', 85000.00 ); INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY) VALUES ( 'Kim', 22, 'South-Hall', 45000.00 ); INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY) VALUES ( 'James', 24, 'Houston', 10000.00 );
Это вставит семь кортежей в таблицу COMPANY, и COMPANY будет иметь следующие записи:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000
PostgreSQL – ПРИВИЛЕГИИ
Всякий раз, когда объект создается в базе данных, ему назначается владелец. Обычно владельцем является тот, кто выполнил оператор создания. Для большинства типов объектов начальное состояние таково, что только владелец (или суперпользователь) может изменить или удалить объект. Чтобы позволить другим ролям или пользователям использовать его, должны быть предоставлены привилегии или разрешение.
Различные виды привилегий в PostgreSQL –
- ВЫБРАТЬ,
- ВСТАВИТЬ,
- ОБНОВИТЬ,
- УДАЛЯТЬ,
- TRUNCATE,
- РЕКОМЕНДАЦИИ,
- СПУСКОВОЙ КРЮЧОК,
- СОЗДАЙТЕ,
- CONNECT,
- ВРЕМЕННОЕ,
- ВЫПОЛНИТЬ, и
- ИСПОЛЬЗОВАНИЕ
В зависимости от типа объекта (таблицы, функции и т. Д.) К объекту применяются привилегии. Чтобы назначить привилегии пользователям, используется команда GRANT.
Синтаксис для GRANT
Основной синтаксис для команды GRANT выглядит следующим образом:
GRANT privilege [, ...]
ON object [, ...]
TO { PUBLIC | GROUP group | username }
-
значениями привилегий могут быть: SELECT, INSERT, UPDATE, DELETE, RULE, ALL.
-
object – имя объекта, к которому предоставляется доступ. Возможные объекты: таблица, представление, последовательность
-
ПУБЛИЧНЫЙ – краткая форма, представляющая всех пользователей.
-
ГРУППА ГРУППА – группа, которой нужно предоставить привилегии.
-
username – имя пользователя, которому необходимо предоставить привилегии. PUBLIC – это краткая форма, представляющая всех пользователей.
значениями привилегий могут быть: SELECT, INSERT, UPDATE, DELETE, RULE, ALL.
object – имя объекта, к которому предоставляется доступ. Возможные объекты: таблица, представление, последовательность
ПУБЛИЧНЫЙ – краткая форма, представляющая всех пользователей.
ГРУППА ГРУППА – группа, которой нужно предоставить привилегии.
username – имя пользователя, которому необходимо предоставить привилегии. PUBLIC – это краткая форма, представляющая всех пользователей.
Привилегии могут быть отменены с помощью команды REVOKE.
Синтаксис для REVOKE
Основной синтаксис команды REVOKE следующий:
REVOKE privilege [, ...]
ON object [, ...]
FROM { PUBLIC | GROUP groupname | username }
-
значениями привилегий могут быть: SELECT, INSERT, UPDATE, DELETE, RULE, ALL.
-
object – имя объекта, к которому предоставляется доступ. Возможные объекты: таблица, представление, последовательность
-
ПУБЛИЧНЫЙ – краткая форма, представляющая всех пользователей.
-
ГРУППА ГРУППА – группа, которой нужно предоставить привилегии.
-
username – имя пользователя, которому необходимо предоставить привилегии. PUBLIC – это краткая форма, представляющая всех пользователей.
значениями привилегий могут быть: SELECT, INSERT, UPDATE, DELETE, RULE, ALL.
object – имя объекта, к которому предоставляется доступ. Возможные объекты: таблица, представление, последовательность
ПУБЛИЧНЫЙ – краткая форма, представляющая всех пользователей.
ГРУППА ГРУППА – группа, которой нужно предоставить привилегии.
username – имя пользователя, которому необходимо предоставить привилегии. PUBLIC – это краткая форма, представляющая всех пользователей.
пример
Чтобы понять привилегии, давайте сначала создадим пользователя USER следующим образом:
testdb=# CREATE USER manisha WITH PASSWORD 'password'; CREATE ROLE
Сообщение CREATE ROLE указывает, что пользователь “manisha” создан.
Рассмотрим таблицу COMPANY, имеющую записи следующим образом:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Далее, давайте предоставим все привилегии на таблицу COMPANY пользователю “manisha” следующим образом –
testdb=# GRANT ALL ON COMPANY TO manisha; GRANT
Сообщение GRANT указывает, что все привилегии назначены пользователю.
Далее, давайте отзовем привилегии у USER “маниша” следующим образом –
testdb=# REVOKE ALL ON COMPANY FROM manisha; REVOKE
Сообщение REVOKE указывает, что все привилегии отозваны у пользователя.
Вы даже можете удалить пользователя следующим образом –
testdb=# DROP USER manisha; DROP ROLE
Сообщение DROP ROLE указывает, что пользователь ‘Manisha’ удален из базы данных.
PostgreSQL – ДАТА / ВРЕМЯ Функции и операторы
Мы обсуждали типы данных Date / Time в главе « Типы данных» . Теперь давайте посмотрим на операторы даты и времени и функции.
В следующей таблице перечислены поведения основных арифметических операторов –
| оператор | пример | Результат |
|---|---|---|
| + | дата ‘2001-09-28’ + целое число ‘7’ | дата ‘2001-10-05’ |
| + | дата ‘2001-09-28’ + интервал ‘1 час’ | метка времени ‘2001-09-28 01:00:00’ |
| + | дата ‘2001-09-28’ + время ’03: 00 ‘ | метка времени ‘2001-09-28 03:00:00’ |
| + | интервал «1 день» + интервал «1 час» | интервал «1 день 01:00:00» |
| + | метка времени ‘2001-09-28 01:00’ + интервал ’23 часа ‘ | метка времени ‘2001-09-29 00:00:00’ |
| + | время «01: 00» + интервал «3 часа» | время ’04: 00: 00 ‘ |
| – | – интервал «23 часа» | интервал ‘-23: 00: 00’ |
| – | дата ‘2001-10-01’ – дата ‘2001-09-28’ | целое число «3» (дни) |
| – | дата ‘2001-10-01’ – целое число ‘7’ | дата ‘2001-09-24’ |
| – | дата ‘2001-09-28’ – интервал ‘1 час’ | метка времени ‘2001-09-27 23:00:00’ |
| – | время ’05: 00 ‘- время ’03: 00’ | интервал ’02: 00: 00 ‘ |
| – | время ’05: 00 ‘- интервал’ 2 часа ‘ | время ’03: 00: 00 ‘ |
| – | метка времени ‘2001-09-28 23:00′ – интервал ’23 часов’ | метка времени ‘2001-09-28 00:00:00’ |
| – | интервал «1 день» – интервал «1 час» | интервал «1 день -01: 00: 00» |
| – | метка времени ‘2001-09-29 03:00’ – метка времени ‘2001-09-27 12:00’ | интервал «1 день 15:00:00» |
| * | 900 * интервал «1 секунда» | интервал ’00: 15: 00 ‘ |
| * | 21 * интервал «1 день» | интервал 21 день |
| * | двойная точность ‘3.5’ * интервал ‘1 час’ | интервал ’03: 30: 00 ‘ |
| / | интервал «1 час» / двойная точность «1,5» | интервал ’00: 40: 00 ‘ |
Ниже приведен список всех важных функций, связанных с датой и временем.
| С. Нет. | Описание функции |
|---|---|
| 1 | ВОЗРАСТ()
Вычесть аргументы |
| 2 | ТЕКУЩАЯ ДАТА / ВРЕМЯ ()
Текущая дата и время |
| 3 | Date_part ()
Получить подполе (эквивалентное извлечению) |
| 4 | ВЫПИСКА ()
Получить подполе |
| 5 | ISFINITE ()
Тест на конечную дату, время и интервал (не +/- бесконечность) |
| 6 | ОПРАВДАТЬ
Отрегулируйте интервал |
Вычесть аргументы
Текущая дата и время
Получить подполе (эквивалентное извлечению)
Получить подполе
Тест на конечную дату, время и интервал (не +/- бесконечность)
Отрегулируйте интервал
ВОЗРАСТ (временная метка, timestamp), ВОЗРАСТ (временная метка)
| С. Нет. | Описание функции |
|---|---|
| 1 |
ВОЗРАСТ (временная метка, timestamp) Когда вызывается с формой TIMESTAMP второго аргумента, AGE () вычитает аргументы, производя «символический» результат, который использует годы и месяцы и имеет тип INTERVAL. |
| 2 |
AGE (метка времени) Когда вызывается только с TIMESTAMP в качестве аргумента, AGE () вычитает из current_date (в полночь). |
ВОЗРАСТ (временная метка, timestamp)
Когда вызывается с формой TIMESTAMP второго аргумента, AGE () вычитает аргументы, производя «символический» результат, который использует годы и месяцы и имеет тип INTERVAL.
AGE (метка времени)
Когда вызывается только с TIMESTAMP в качестве аргумента, AGE () вычитает из current_date (в полночь).
Примером функции AGE (timestamp, timestamp) является –
testdb=# SELECT AGE(timestamp '2001-04-10', timestamp '1957-06-13');
Приведенный выше оператор PostgreSQL даст следующий результат:
age ------------------------- 43 years 9 mons 27 days
Примером функции AGE (отметка времени) является –
testdb=# select age(timestamp '1957-06-13');
Приведенный выше оператор PostgreSQL даст следующий результат:
age -------------------------- 55 years 10 mons 22 days
ТЕКУЩАЯ ДАТА / ВРЕМЯ ()
PostgreSQL предоставляет ряд функций, которые возвращают значения, связанные с текущей датой и временем. Ниже приведены некоторые функции –
| С. Нет. | Описание функции |
|---|---|
| 1 |
ТЕКУЩАЯ ДАТА Поставляет текущую дату. |
| 2 |
ТЕКУЩЕЕ ВРЕМЯ Поставляет значения с часовым поясом. |
| 3 |
CURRENT_TIMESTAMP Поставляет значения с часовым поясом. |
| 4 |
CURRENT_TIME (точность) При желании принимает параметр точности, который приводит к тому, что результат округляется до такого количества дробных цифр в поле секунд. |
| 5 |
CURRENT_TIMESTAMP (точность) При желании принимает параметр точности, который приводит к тому, что результат округляется до такого количества дробных цифр в поле секунд. |
| 6 |
МЕСТНОЕ ВРЕМЯ Доставляет значения без часового пояса. |
| 7 |
LOCALTIMESTAMP Доставляет значения без часового пояса. |
| 8 |
МестноеВремя (точность) При желании принимает параметр точности, который приводит к тому, что результат округляется до такого количества дробных цифр в поле секунд. |
| 9 |
LOCALTIMESTAMP (точность) При желании принимает параметр точности, который приводит к тому, что результат округляется до такого количества дробных цифр в поле секунд. |
ТЕКУЩАЯ ДАТА
Поставляет текущую дату.
ТЕКУЩЕЕ ВРЕМЯ
Поставляет значения с часовым поясом.
CURRENT_TIMESTAMP
Поставляет значения с часовым поясом.
CURRENT_TIME (точность)
При желании принимает параметр точности, который приводит к тому, что результат округляется до такого количества дробных цифр в поле секунд.
CURRENT_TIMESTAMP (точность)
При желании принимает параметр точности, который приводит к тому, что результат округляется до такого количества дробных цифр в поле секунд.
МЕСТНОЕ ВРЕМЯ
Доставляет значения без часового пояса.
LOCALTIMESTAMP
Доставляет значения без часового пояса.
МестноеВремя (точность)
При желании принимает параметр точности, который приводит к тому, что результат округляется до такого количества дробных цифр в поле секунд.
LOCALTIMESTAMP (точность)
При желании принимает параметр точности, который приводит к тому, что результат округляется до такого количества дробных цифр в поле секунд.
Примеры использования функций из таблицы выше –
testdb=# SELECT CURRENT_TIME; timetz -------------------- 08:01:34.656+05:30 (1 row) testdb=# SELECT CURRENT_DATE; date ------------ 2013-05-05 (1 row) testdb=# SELECT CURRENT_TIMESTAMP; now ------------------------------- 2013-05-05 08:01:45.375+05:30 (1 row) testdb=# SELECT CURRENT_TIMESTAMP(2); timestamptz ------------------------------ 2013-05-05 08:01:50.89+05:30 (1 row) testdb=# SELECT LOCALTIMESTAMP; timestamp ------------------------ 2013-05-05 08:01:55.75 (1 row)
PostgreSQL также предоставляет функции, которые возвращают время начала текущего оператора, а также фактическое текущее время в момент вызова функции. Эти функции –
| С. Нет. | Описание функции |
|---|---|
| 1 |
transaction_timestamp () Он эквивалентен CURRENT_TIMESTAMP, но назван так, чтобы четко отражать, что он возвращает. |
| 2 |
statement_timestamp () Возвращает время начала текущего оператора. |
| 3 |
clock_timestamp () Он возвращает текущее текущее время, и, следовательно, его значение изменяется даже в пределах одной команды SQL. |
| 4 |
TimeOfDay () Возвращает текущее текущее время, но в виде отформатированной текстовой строки, а не метки времени со значением часового пояса. |
| 5 |
сейчас() Это традиционный PostgreSQL, эквивалентныйaction_timestamp (). |
transaction_timestamp ()
Он эквивалентен CURRENT_TIMESTAMP, но назван так, чтобы четко отражать, что он возвращает.
statement_timestamp ()
Возвращает время начала текущего оператора.
clock_timestamp ()
Он возвращает текущее текущее время, и, следовательно, его значение изменяется даже в пределах одной команды SQL.
TimeOfDay ()
Возвращает текущее текущее время, но в виде отформатированной текстовой строки, а не метки времени со значением часового пояса.
сейчас()
Это традиционный PostgreSQL, эквивалентныйaction_timestamp ().
DATE_PART (текст, метка времени), DATE_PART (текст, интервал), DATE_TRUNC (текст, метка времени)
| С. Нет. | Описание функции |
|---|---|
| 1 |
DATE_PART (‘поле’, источник) Эти функции получают подполя. Параметр поля должен быть строковым значением, а не именем. Допустимые имена полей: век, день, декада, доу, дой, эпоха, час, изода, год, микросекунды, тысячелетия, миллисекунды, минуты, месяц, квартал, секунда, часовой пояс, часовой пояс_час, часовой пояс_минута, неделя, год. |
| 2 |
DATE_TRUNC (‘field’, source) Эта функция концептуально аналогична функции усечения для чисел. source – это выражение значения типа timestamp или interval. поле выбирает, с какой точностью обрезать входное значение. Возвращаемое значение имеет тип отметки времени или интервала . Допустимые значения для поля : микросекунды, миллисекунды, секунды, минуты, часы, день, неделя, месяц, квартал, год, десятилетие, век, тысячелетия |
DATE_PART (‘поле’, источник)
Эти функции получают подполя. Параметр поля должен быть строковым значением, а не именем.
Допустимые имена полей: век, день, декада, доу, дой, эпоха, час, изода, год, микросекунды, тысячелетия, миллисекунды, минуты, месяц, квартал, секунда, часовой пояс, часовой пояс_час, часовой пояс_минута, неделя, год.
DATE_TRUNC (‘field’, source)
Эта функция концептуально аналогична функции усечения для чисел. source – это выражение значения типа timestamp или interval. поле выбирает, с какой точностью обрезать входное значение. Возвращаемое значение имеет тип отметки времени или интервала .
Допустимые значения для поля : микросекунды, миллисекунды, секунды, минуты, часы, день, неделя, месяц, квартал, год, десятилетие, век, тысячелетия
Ниже приведены примеры функций DATE_PART ( ‘field’ , source):
testdb=# SELECT date_part('day', TIMESTAMP '2001-02-16 20:38:40'); date_part ----------- 16 (1 row) testdb=# SELECT date_part('hour', INTERVAL '4 hours 3 minutes'); date_part ----------- 4 (1 row)
Ниже приведены примеры функций DATE_TRUNC ( ‘field’ , source):
testdb=# SELECT date_trunc('hour', TIMESTAMP '2001-02-16 20:38:40'); date_trunc --------------------- 2001-02-16 20:00:00 (1 row) testdb=# SELECT date_trunc('year', TIMESTAMP '2001-02-16 20:38:40'); date_trunc --------------------- 2001-01-01 00:00:00 (1 row)
EXTRACT (поле из метки времени), EXTRACT (поле из интервала)
Функция EXTRACT (поле FROM source) извлекает подполя, такие как год или час, из значений даты / времени. Источник должен быть выражением значения типа timestamp, time или interval . Поле является идентификатором или строкой, которая выбирает, какое поле извлечь из исходного значения. Функция EXTRACT возвращает значения типа двойной точности .
Ниже приведены допустимые имена полей (аналогично именам полей функции DATE_PART): век, день, декада, доу, дой, эпоха, час, изода, год, микросекунды, тысячелетия, миллисекунды, минуты, месяц, квартал, секунда, часовой пояс, часовой пояс_час , timezone_minute, неделя, год.
Ниже приведены примеры функций EXTRACT ( ‘field’ , source):
testdb=# SELECT EXTRACT(CENTURY FROM TIMESTAMP '2000-12-16 12:21:13'); date_part ----------- 20 (1 row) testdb=# SELECT EXTRACT(DAY FROM TIMESTAMP '2001-02-16 20:38:40'); date_part ----------- 16 (1 row)
ISFINITE (дата), ISFINITE (метка времени), ISFINITE (интервал)
| С. Нет. | Описание функции |
|---|---|
| 1 |
ISFINITE (дата) Тесты на конечную дату. |
| 2 |
ISFINITE (метка времени) Тесты на конечную отметку времени. |
| 3 |
ISFINITE (интервал) Тесты на конечный интервал. |
ISFINITE (дата)
Тесты на конечную дату.
ISFINITE (метка времени)
Тесты на конечную отметку времени.
ISFINITE (интервал)
Тесты на конечный интервал.
Ниже приведены примеры функций ISFINITE ():
testdb=# SELECT isfinite(date '2001-02-16'); isfinite ---------- t (1 row) testdb=# SELECT isfinite(timestamp '2001-02-16 21:28:30'); isfinite ---------- t (1 row) testdb=# SELECT isfinite(interval '4 hours'); isfinite ---------- t (1 row)
JUSTIFY_DAYS (интервал), JUSTIFY_HOURS (интервал), JUSTIFY_INTERVAL (интервал)
| С. Нет. | Описание функции |
|---|---|
| 1 |
JUSTIFY_DAYS (интервал) Настраивает интервал так, чтобы 30-дневные периоды времени были представлены месяцами. Вернуть тип интервала |
| 2 |
JUSTIFY_HOURS (интервал) Настраивает интервал, чтобы 24-часовой период времени отображался в днях. Вернуть тип интервала |
| 3 |
JUSTIFY_INTERVAL (интервал) Регулирует интервал с помощью JUSTIFY_DAYS и JUSTIFY_HOURS, с дополнительными настройками знака. Вернуть тип интервала |
JUSTIFY_DAYS (интервал)
Настраивает интервал так, чтобы 30-дневные периоды времени были представлены месяцами. Вернуть тип интервала
JUSTIFY_HOURS (интервал)
Настраивает интервал, чтобы 24-часовой период времени отображался в днях. Вернуть тип интервала
JUSTIFY_INTERVAL (интервал)
Регулирует интервал с помощью JUSTIFY_DAYS и JUSTIFY_HOURS, с дополнительными настройками знака. Вернуть тип интервала
Ниже приведены примеры для функций ISFINITE ():
testdb=# SELECT justify_days(interval '35 days'); justify_days -------------- 1 mon 5 days (1 row) testdb=# SELECT justify_hours(interval '27 hours'); justify_hours ---------------- 1 day 03:00:00 (1 row) testdb=# SELECT justify_interval(interval '1 mon -1 hour'); justify_interval ------------------ 29 days 23:00:00 (1 row)
PostgreSQL – Функции
Функции PostgreSQL, также известные как хранимые процедуры, позволяют вам выполнять операции, которые обычно принимают несколько запросов и циклических переходов в одной функции в базе данных. Функции позволяют повторное использование базы данных, так как другие приложения могут напрямую взаимодействовать с вашими хранимыми процедурами вместо кода среднего уровня или дублирующего кода.
Функции могут быть созданы на любом языке по вашему выбору, например, SQL, PL / pgSQL, C, Python и т. Д.
Синтаксис
Основной синтаксис для создания функции следующий:
CREATE [OR REPLACE] FUNCTION function_name (arguments)
RETURNS return_datatype AS $variable_name$
DECLARE
declaration;
[...]
BEGIN
< function_body >
[...]
RETURN { variable_name | value }
END; LANGUAGE plpgsql;
Куда,
-
имя-функции указывает имя функции.
-
Опция [ИЛИ ЗАМЕНА] позволяет изменить существующую функцию.
-
Функция должна содержать инструкцию возврата .
-
Предложение RETURN указывает тип данных, который вы собираетесь возвращать из функции. Аргумент return_datatype может быть базовым, составным или доменным типом или может ссылаться на тип столбца таблицы.
-
Функция body содержит исполняемую часть.
-
Ключевое слово AS используется для создания автономной функции.
-
plpgsql – это имя языка, на котором реализована функция. Здесь мы используем эту опцию для PostgreSQL, это может быть SQL, C, внутренний или имя пользовательского процедурного языка. Для обратной совместимости имя может быть заключено в одинарные кавычки.
имя-функции указывает имя функции.
Опция [ИЛИ ЗАМЕНА] позволяет изменить существующую функцию.
Функция должна содержать инструкцию возврата .
Предложение RETURN указывает тип данных, который вы собираетесь возвращать из функции. Аргумент return_datatype может быть базовым, составным или доменным типом или может ссылаться на тип столбца таблицы.
Функция body содержит исполняемую часть.
Ключевое слово AS используется для создания автономной функции.
plpgsql – это имя языка, на котором реализована функция. Здесь мы используем эту опцию для PostgreSQL, это может быть SQL, C, внутренний или имя пользовательского процедурного языка. Для обратной совместимости имя может быть заключено в одинарные кавычки.
пример
Следующий пример иллюстрирует создание и вызов отдельной функции. Эта функция возвращает общее количество записей в таблице COMPANY. Мы будем использовать таблицу COMPANY , в которой есть следующие записи:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Функция totalRecords () работает следующим образом –
CREATE OR REPLACE FUNCTION totalRecords () RETURNS integer AS $total$ declare total integer; BEGIN SELECT count(*) into total FROM COMPANY; RETURN total; END; $total$ LANGUAGE plpgsql;
Когда вышеуказанный запрос будет выполнен, результатом будет –
testdb# CREATE FUNCTION
Теперь давайте выполним вызов этой функции и проверим записи в таблице COMPANY.
testdb=# select totalRecords();
Когда вышеуказанный запрос будет выполнен, результатом будет –
totalrecords
--------------
7
(1 row)
PostgreSQL – полезные функции
Встроенные функции PostgreSQL, также называемые агрегатными функциями, используются для выполнения обработки строковых или числовых данных.
Ниже приведен список всех встроенных функций PostgreSQL общего назначения:
-
Функция COUNT в PostgreSQL – агрегатная функция COGT в PostgreSQL используется для подсчета количества строк в таблице базы данных.
-
Функция PostgreSQL MAX – Функция агрегации PostgreSQL MAX позволяет нам выбрать максимальное (максимальное) значение для определенного столбца.
-
Функция PostgreSQL MIN – агрегатная функция PostgreSQL MIN позволяет нам выбрать самое низкое (минимальное) значение для определенного столбца.
-
Функция PostgreSQL AVG – Функция агрегирования PostgreSQL AVG выбирает среднее значение для определенного столбца таблицы.
-
Функция PostgreSQL SUM – агрегатная функция PostgreSQL SUM позволяет выбрать сумму для числового столбца.
-
Функции ARGAY в PostgreSQL – Агрегирующая функция PostgreSQL ARRAY помещает входные значения, включая нули, в массив.
-
Числовые функции PostgreSQL – Полный список функций PostgreSQL, необходимых для работы с числами в SQL.
-
Строковые функции PostgreSQL – Полный список функций PostgreSQL, необходимых для работы со строками в PostgreSQL.
Функция COUNT в PostgreSQL – агрегатная функция COGT в PostgreSQL используется для подсчета количества строк в таблице базы данных.
Функция PostgreSQL MAX – Функция агрегации PostgreSQL MAX позволяет нам выбрать максимальное (максимальное) значение для определенного столбца.
Функция PostgreSQL MIN – агрегатная функция PostgreSQL MIN позволяет нам выбрать самое низкое (минимальное) значение для определенного столбца.
Функция PostgreSQL AVG – Функция агрегирования PostgreSQL AVG выбирает среднее значение для определенного столбца таблицы.
Функция PostgreSQL SUM – агрегатная функция PostgreSQL SUM позволяет выбрать сумму для числового столбца.
Функции ARGAY в PostgreSQL – Агрегирующая функция PostgreSQL ARRAY помещает входные значения, включая нули, в массив.
Числовые функции PostgreSQL – Полный список функций PostgreSQL, необходимых для работы с числами в SQL.
Строковые функции PostgreSQL – Полный список функций PostgreSQL, необходимых для работы со строками в PostgreSQL.
PostgreSQL – интерфейс C / C ++
В этом руководстве будет использоваться библиотека libpqxx , которая является официальным клиентским API C ++ для PostgreSQL. Исходный код для libpqxx доступен по лицензии BSD, поэтому вы можете свободно загружать его, передавать другим, изменять, продавать, включать в свой собственный код и делиться своими изменениями с любым пользователем по своему выбору.
Монтаж
Последнюю версию libpqxx можно скачать по ссылке Download Libpqxx . Поэтому загрузите последнюю версию и выполните следующие действия:
wget http://pqxx.org/download/software/libpqxx/libpqxx-4.0.tar.gz tar xvfz libpqxx-4.0.tar.gz cd libpqxx-4.0 ./configure make make install
Прежде чем начать использовать интерфейс C / C ++ PostgreSQL, найдите файл pg_hba.conf в установочном каталоге PostgreSQL и добавьте следующую строку:
# IPv4 local connections: host all all 127.0.0.1/32 md5
Вы можете запустить / перезапустить сервер postgres, если он не работает, с помощью следующей команды –
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
API интерфейса C / C ++
Ниже приведены важные интерфейсные процедуры, которые могут удовлетворить ваши требования по работе с базой данных PostgreSQL из вашей программы на C / C ++. Если вы ищете более сложное приложение, вы можете посмотреть официальную документацию libpqxx или использовать имеющиеся в продаже API.
| С. Нет. | API и описание |
|---|---|
| 1 |
pqxx :: соединение C (const std :: string & dbstring) Это typedef, который будет использоваться для подключения к базе данных. Здесь dbstring предоставляет обязательные параметры для подключения к базе данных, например, dbname = testdb user = postgres password = pass123 hostaddr = 127.0.0.1 port = 5432 . Если соединение установлено успешно, то создается C с объектом соединения, который предоставляет различные полезные функции public function. |
| 2 |
C.is_open () Метод is_open () является открытым методом объекта соединения и возвращает логическое значение. Если соединение активно, то этот метод возвращает true, в противном случае он возвращает false. |
| 3 |
C.disconnect () Этот метод используется для отключения открытого соединения с базой данных. |
| 4 |
pqxx :: работа W (C) Это typedef, который будет использоваться для создания транзакционного объекта с использованием соединения C, который в конечном итоге будет использоваться для выполнения операторов SQL в транзакционном режиме. Если объект транзакции успешно создан, он присваивается переменной W, которая будет использоваться для доступа к открытым методам, связанным с объектом транзакции. |
| 5 |
W.exec (const std :: string & sql) Этот открытый метод из транзакционного объекта будет использоваться для выполнения оператора SQL. |
| 6 |
W.commit () Этот открытый метод из транзакционного объекта будет использоваться для фиксации транзакции. |
| 7 |
W.abort () Этот открытый метод из транзакционного объекта будет использоваться для отката транзакции. |
| 8 |
pqxx :: нетранзакция N (C) Это typedef, который будет использоваться для создания нетранзакционного объекта с использованием соединения C, который в конечном итоге будет использоваться для выполнения операторов SQL в нетранзакционном режиме. Если объект транзакции успешно создан, он присваивается переменной N, которая будет использоваться для доступа к открытым методам, связанным с нетранзакционным объектом. |
| 9 |
N.exec (const std :: string & sql) Этот открытый метод из нетранзакционного объекта будет использоваться для выполнения оператора SQL и возвращает объект результата, который на самом деле является интегратором, содержащим все возвращенные записи. |
pqxx :: соединение C (const std :: string & dbstring)
Это typedef, который будет использоваться для подключения к базе данных. Здесь dbstring предоставляет обязательные параметры для подключения к базе данных, например, dbname = testdb user = postgres password = pass123 hostaddr = 127.0.0.1 port = 5432 .
Если соединение установлено успешно, то создается C с объектом соединения, который предоставляет различные полезные функции public function.
C.is_open ()
Метод is_open () является открытым методом объекта соединения и возвращает логическое значение. Если соединение активно, то этот метод возвращает true, в противном случае он возвращает false.
C.disconnect ()
Этот метод используется для отключения открытого соединения с базой данных.
pqxx :: работа W (C)
Это typedef, который будет использоваться для создания транзакционного объекта с использованием соединения C, который в конечном итоге будет использоваться для выполнения операторов SQL в транзакционном режиме.
Если объект транзакции успешно создан, он присваивается переменной W, которая будет использоваться для доступа к открытым методам, связанным с объектом транзакции.
W.exec (const std :: string & sql)
Этот открытый метод из транзакционного объекта будет использоваться для выполнения оператора SQL.
W.commit ()
Этот открытый метод из транзакционного объекта будет использоваться для фиксации транзакции.
W.abort ()
Этот открытый метод из транзакционного объекта будет использоваться для отката транзакции.
pqxx :: нетранзакция N (C)
Это typedef, который будет использоваться для создания нетранзакционного объекта с использованием соединения C, который в конечном итоге будет использоваться для выполнения операторов SQL в нетранзакционном режиме.
Если объект транзакции успешно создан, он присваивается переменной N, которая будет использоваться для доступа к открытым методам, связанным с нетранзакционным объектом.
N.exec (const std :: string & sql)
Этот открытый метод из нетранзакционного объекта будет использоваться для выполнения оператора SQL и возвращает объект результата, который на самом деле является интегратором, содержащим все возвращенные записи.
Подключение к базе данных
В следующем сегменте кода C показано, как подключиться к существующей базе данных, работающей на локальном компьютере через порт 5432. Здесь я использовал обратную косую черту для продолжения строки.
#include <iostream> #include <pqxx/pqxx> using namespace std; using namespace pqxx; int main(int argc, char* argv[]) { try { connection C("dbname = testdb user = postgres password = cohondob hostaddr = 127.0.0.1 port = 5432"); if (C.is_open()) { cout << "Opened database successfully: " << C.dbname() << endl; } else { cout << "Can't open database" << endl; return 1; } C.disconnect (); } catch (const std::exception &e) { cerr << e.what() << std::endl; return 1; } }
Теперь давайте скомпилируем и запустим указанную выше программу для подключения к нашей базе данных testdb , которая уже доступна в вашей схеме и доступна для доступа с помощью пользовательских postgres и пароля pass123 .
Вы можете использовать идентификатор пользователя и пароль в зависимости от настроек вашей базы данных. Не забудьте сохранить -lpqxx и -lpq в указанном порядке! В противном случае компоновщик будет горько жаловаться на отсутствующие функции с именами, начинающимися с «PQ».
$g++ test.cpp -lpqxx -lpq $./a.out Opened database successfully: testdb
Создать таблицу
Следующий сегмент кода C будет использоваться для создания таблицы в ранее созданной базе данных –
#include <iostream> #include <pqxx/pqxx> using namespace std; using namespace pqxx; int main(int argc, char* argv[]) { char * sql; try { connection C("dbname = testdb user = postgres password = cohondob hostaddr = 127.0.0.1 port = 5432"); if (C.is_open()) { cout << "Opened database successfully: " << C.dbname() << endl; } else { cout << "Can't open database" << endl; return 1; } /* Create SQL statement */ sql = "CREATE TABLE COMPANY(" "ID INT PRIMARY KEY NOT NULL," "NAME TEXT NOT NULL," "AGE INT NOT NULL," "ADDRESS CHAR(50)," "SALARY REAL );"; /* Create a transactional object. */ work W(C); /* Execute SQL query */ W.exec( sql ); W.commit(); cout << "Table created successfully" << endl; C.disconnect (); } catch (const std::exception &e) { cerr << e.what() << std::endl; return 1; } return 0; }
Когда вышеупомянутая программа скомпилирована и выполнена, она создаст таблицу COMPANY в вашей базе данных testdb и отобразит следующие операторы:
Opened database successfully: testdb Table created successfully
ВСТАВИТЬ Операция
Следующий сегмент кода C показывает, как мы можем создавать записи в нашей таблице COMPANY, созданной в приведенном выше примере.
#include <iostream> #include <pqxx/pqxx> using namespace std; using namespace pqxx; int main(int argc, char* argv[]) { char * sql; try { connection C("dbname = testdb user = postgres password = cohondob hostaddr = 127.0.0.1 port = 5432"); if (C.is_open()) { cout << "Opened database successfully: " << C.dbname() << endl; } else { cout << "Can't open database" << endl; return 1; } /* Create SQL statement */ sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " "VALUES (1, 'Paul', 32, 'California', 20000.00 ); " "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " "VALUES (2, 'Allen', 25, 'Texas', 15000.00 ); " "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" "VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );" "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" "VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );"; /* Create a transactional object. */ work W(C); /* Execute SQL query */ W.exec( sql ); W.commit(); cout << "Records created successfully" << endl; C.disconnect (); } catch (const std::exception &e) { cerr << e.what() << std::endl; return 1; } return 0; }
Когда указанная выше программа компилируется и выполняется, она создает указанные записи в таблице COMPANY и отображает следующие две строки:
Opened database successfully: testdb Records created successfully
ВЫБЕРИТЕ Операцию
Следующий сегмент кода C показывает, как мы можем получать и отображать записи из нашей таблицы COMPANY, созданной в приведенном выше примере.
#include <iostream> #include <pqxx/pqxx> using namespace std; using namespace pqxx; int main(int argc, char* argv[]) { char * sql; try { connection C("dbname = testdb user = postgres password = cohondob hostaddr = 127.0.0.1 port = 5432"); if (C.is_open()) { cout << "Opened database successfully: " << C.dbname() << endl; } else { cout << "Can't open database" << endl; return 1; } /* Create SQL statement */ sql = "SELECT * from COMPANY"; /* Create a non-transactional object. */ nontransaction N(C); /* Execute SQL query */ result R( N.exec( sql )); /* List down all the records */ for (result::const_iterator c = R.begin(); c != R.end(); ++c) { cout << "ID = " << c[0].as<int>() << endl; cout << "Name = " << c[1].as<string>() << endl; cout << "Age = " << c[2].as<int>() << endl; cout << "Address = " << c[3].as<string>() << endl; cout << "Salary = " << c[4].as<float>() << endl; } cout << "Operation done successfully" << endl; C.disconnect (); } catch (const std::exception &e) { cerr << e.what() << std::endl; return 1; } return 0; }
Когда вышеупомянутая программа скомпилирована и выполнена, она даст следующий результат –
Opened database successfully: testdb ID = 1 Name = Paul Age = 32 Address = California Salary = 20000 ID = 2 Name = Allen Age = 25 Address = Texas Salary = 15000 ID = 3 Name = Teddy Age = 23 Address = Norway Salary = 20000 ID = 4 Name = Mark Age = 25 Address = Rich-Mond Salary = 65000 Operation done successfully
ОБНОВЛЕНИЕ Операция
Следующий сегмент кода C показывает, как мы можем использовать инструкцию UPDATE, чтобы обновить любую запись, а затем извлечь и отобразить обновленные записи из нашей таблицы COMPANY –
#include <iostream> #include <pqxx/pqxx> using namespace std; using namespace pqxx; int main(int argc, char* argv[]) { char * sql; try { connection C("dbname = testdb user = postgres password = cohondob hostaddr = 127.0.0.1 port = 5432"); if (C.is_open()) { cout << "Opened database successfully: " << C.dbname() << endl; } else { cout << "Can't open database" << endl; return 1; } /* Create a transactional object. */ work W(C); /* Create SQL UPDATE statement */ sql = "UPDATE COMPANY set SALARY = 25000.00 where ID=1"; /* Execute SQL query */ W.exec( sql ); W.commit(); cout << "Records updated successfully" << endl; /* Create SQL SELECT statement */ sql = "SELECT * from COMPANY"; /* Create a non-transactional object. */ nontransaction N(C); /* Execute SQL query */ result R( N.exec( sql )); /* List down all the records */ for (result::const_iterator c = R.begin(); c != R.end(); ++c) { cout << "ID = " << c[0].as<int>() << endl; cout << "Name = " << c[1].as<string>() << endl; cout << "Age = " << c[2].as<int>() << endl; cout << "Address = " << c[3].as<string>() << endl; cout << "Salary = " << c[4].as<float>() << endl; } cout << "Operation done successfully" << endl; C.disconnect (); } catch (const std::exception &e) { cerr << e.what() << std::endl; return 1; } return 0; }
Когда вышеупомянутая программа скомпилирована и выполнена, она даст следующий результат –
Opened database successfully: testdb Records updated successfully ID = 2 Name = Allen Age = 25 Address = Texas Salary = 15000 ID = 3 Name = Teddy Age = 23 Address = Norway Salary = 20000 ID = 4 Name = Mark Age = 25 Address = Rich-Mond Salary = 65000 ID = 1 Name = Paul Age = 32 Address = California Salary = 25000 Operation done successfully
УДАЛЕНИЕ Операция
Следующий сегмент кода C показывает, как мы можем использовать инструкцию DELETE, чтобы удалить любую запись, а затем извлечь и отобразить оставшиеся записи из нашей таблицы COMPANY –
#include <iostream> #include <pqxx/pqxx> using namespace std; using namespace pqxx; int main(int argc, char* argv[]) { char * sql; try { connection C("dbname = testdb user = postgres password = cohondob hostaddr = 127.0.0.1 port = 5432"); if (C.is_open()) { cout << "Opened database successfully: " << C.dbname() << endl; } else { cout << "Can't open database" << endl; return 1; } /* Create a transactional object. */ work W(C); /* Create SQL DELETE statement */ sql = "DELETE from COMPANY where ID = 2"; /* Execute SQL query */ W.exec( sql ); W.commit(); cout << "Records deleted successfully" << endl; /* Create SQL SELECT statement */ sql = "SELECT * from COMPANY"; /* Create a non-transactional object. */ nontransaction N(C); /* Execute SQL query */ result R( N.exec( sql )); /* List down all the records */ for (result::const_iterator c = R.begin(); c != R.end(); ++c) { cout << "ID = " << c[0].as<int>() << endl; cout << "Name = " << c[1].as<string>() << endl; cout << "Age = " << c[2].as<int>() << endl; cout << "Address = " << c[3].as<string>() << endl; cout << "Salary = " << c[4].as<float>() << endl; } cout << "Operation done successfully" << endl; C.disconnect (); } catch (const std::exception &e) { cerr << e.what() << std::endl; return 1; } return 0; }
Когда вышеупомянутая программа скомпилирована и выполнена, она даст следующий результат –
Opened database successfully: testdb Records deleted successfully ID = 3 Name = Teddy Age = 23 Address = Norway Salary = 20000 ID = 4 Name = Mark Age = 25 Address = Rich-Mond Salary = 65000 ID = 1 Name = Paul Age = 32 Address = California Salary = 25000 Operation done successfully
PostgreSQL – интерфейс JAVA
Монтаж
Прежде чем мы начнем использовать PostgreSQL в наших программах на Java, мы должны убедиться, что на компьютере установлены PostgreSQL JDBC и Java. Вы можете проверить учебник Java для установки Java на вашем компьютере. Теперь давайте проверим, как настроить драйвер JDBC PostgreSQL.
-
Загрузите последнюю версию postgresql- (VERSION) .jdbc.jar из репозитория postgresql-jdbc .
-
Добавьте скачанный файл jar postgresql- (VERSION) .jdbc.jar в путь к классу или используйте его вместе с параметром -classpath, как описано ниже в примерах.
Загрузите последнюю версию postgresql- (VERSION) .jdbc.jar из репозитория postgresql-jdbc .
Добавьте скачанный файл jar postgresql- (VERSION) .jdbc.jar в путь к классу или используйте его вместе с параметром -classpath, как описано ниже в примерах.
В следующем разделе предполагается, что у вас мало знаний о концепциях Java JDBC. Если у вас его нет, то рекомендуется потратить полчаса с JDBC Tutorial, чтобы освоиться с концепциями, описанными ниже.
Подключение к базе данных
Следующий код Java показывает, как подключиться к существующей базе данных. Если база данных не существует, она будет создана и, наконец, будет возвращен объект базы данных.
import java.sql.Connection; import java.sql.DriverManager; public class PostgreSQLJDBC { public static void main(String args[]) { Connection c = null; try { Class.forName("org.postgresql.Driver"); c = DriverManager .getConnection("jdbc:postgresql://localhost:5432/testdb", "postgres", "123"); } catch (Exception e) { e.printStackTrace(); System.err.println(e.getClass().getName()+": "+e.getMessage()); System.exit(0); } System.out.println("Opened database successfully"); } }
Перед тем, как скомпилировать и запустить вышеуказанную программу, найдите файл pg_hba.conf в вашем каталоге установки PostgreSQL и добавьте следующую строку –
# IPv4 local connections: host all all 127.0.0.1/32 md5
Вы можете запустить / перезапустить сервер postgres, если он не работает, с помощью следующей команды –
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
Теперь давайте скомпилируем и запустим вышеуказанную программу для соединения с testdb. Здесь мы используем postgres в качестве идентификатора пользователя и 123 в качестве пароля для доступа к базе данных. Вы можете изменить это согласно конфигурации и настройке базы данных. Мы также предполагаем, что текущая версия драйвера JDBC postgresql-9.2-1002.jdbc3.jar доступна по текущему пути.
C:JavaPostgresIntegration>javac PostgreSQLJDBC.java C:JavaPostgresIntegration>java -cp c:toolspostgresql-9.2-1002.jdbc3.jar;C:JavaPostgresIntegration PostgreSQLJDBC Open database successfully
Создать таблицу
Следующая Java-программа будет использоваться для создания таблицы в ранее открытой базе данных. Убедитесь, что у вас нет этой таблицы в целевой базе данных.
import java.sql.*; import java.sql.Connection; import java.sql.DriverManager; import java.sql.Statement; public class PostgreSQLJDBC { public static void main( String args[] ) { Connection c = null; Statement stmt = null; try { Class.forName("org.postgresql.Driver"); c = DriverManager .getConnection("jdbc:postgresql://localhost:5432/testdb", "manisha", "123"); System.out.println("Opened database successfully"); stmt = c.createStatement(); String sql = "CREATE TABLE COMPANY " + "(ID INT PRIMARY KEY NOT NULL," + " NAME TEXT NOT NULL, " + " AGE INT NOT NULL, " + " ADDRESS CHAR(50), " + " SALARY REAL)"; stmt.executeUpdate(sql); stmt.close(); c.close(); } catch ( Exception e ) { System.err.println( e.getClass().getName()+": "+ e.getMessage() ); System.exit(0); } System.out.println("Table created successfully"); } }
Когда программа компилируется и выполняется, она создает таблицу COMPANY в базе данных testdb и отображает следующие две строки:
Opened database successfully Table created successfully
ВСТАВИТЬ Операция
Следующая Java-программа показывает, как мы можем создавать записи в нашей таблице COMPANY, созданной в приведенном выше примере.
import java.sql.Connection; import java.sql.DriverManager; import java.sql.Statement; public class PostgreSQLJDBC { public static void main(String args[]) { Connection c = null; Statement stmt = null; try { Class.forName("org.postgresql.Driver"); c = DriverManager .getConnection("jdbc:postgresql://localhost:5432/testdb", "manisha", "123"); c.setAutoCommit(false); System.out.println("Opened database successfully"); stmt = c.createStatement(); String sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " + "VALUES (1, 'Paul', 32, 'California', 20000.00 );"; stmt.executeUpdate(sql); sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " + "VALUES (2, 'Allen', 25, 'Texas', 15000.00 );"; stmt.executeUpdate(sql); sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " + "VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );"; stmt.executeUpdate(sql); sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " + "VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );"; stmt.executeUpdate(sql); stmt.close(); c.commit(); c.close(); } catch (Exception e) { System.err.println( e.getClass().getName()+": "+ e.getMessage() ); System.exit(0); } System.out.println("Records created successfully"); } }
Когда вышеупомянутая программа скомпилирована и выполнена, она создаст данные записи в таблице COMPANY и отобразит следующие две строки:
Opened database successfully Records created successfully
ВЫБЕРИТЕ Операцию
Следующая Java-программа показывает, как мы можем получать и отображать записи из нашей таблицы COMPANY, созданной в приведенном выше примере.
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; public class PostgreSQLJDBC { public static void main( String args[] ) { Connection c = null; Statement stmt = null; try { Class.forName("org.postgresql.Driver"); c = DriverManager .getConnection("jdbc:postgresql://localhost:5432/testdb", "manisha", "123"); c.setAutoCommit(false); System.out.println("Opened database successfully"); stmt = c.createStatement(); ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" ); while ( rs.next() ) { int id = rs.getInt("id"); String name = rs.getString("name"); int age = rs.getInt("age"); String address = rs.getString("address"); float salary = rs.getFloat("salary"); System.out.println( "ID = " + id ); System.out.println( "NAME = " + name ); System.out.println( "AGE = " + age ); System.out.println( "ADDRESS = " + address ); System.out.println( "SALARY = " + salary ); System.out.println(); } rs.close(); stmt.close(); c.close(); } catch ( Exception e ) { System.err.println( e.getClass().getName()+": "+ e.getMessage() ); System.exit(0); } System.out.println("Operation done successfully"); } }
Когда программа скомпилирована и выполнена, она даст следующий результат –
Opened database successfully ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 20000.0 ID = 2 NAME = Allen AGE = 25 ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
ОБНОВЛЕНИЕ Операция
Следующий код Java показывает, как мы можем использовать инструкцию UPDATE для обновления любой записи, а затем извлекать и отображать обновленные записи из нашей таблицы COMPANY –
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; public class PostgreSQLJDBC { public static void main( String args[] ) { Connection c = null; Statement stmt = null; try { Class.forName("org.postgresql.Driver"); c = DriverManager .getConnection("jdbc:postgresql://localhost:5432/testdb", "manisha", "123"); c.setAutoCommit(false); System.out.println("Opened database successfully"); stmt = c.createStatement(); String sql = "UPDATE COMPANY set SALARY = 25000.00 where ID=1;"; stmt.executeUpdate(sql); c.commit(); ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" ); while ( rs.next() ) { int id = rs.getInt("id"); String name = rs.getString("name"); int age = rs.getInt("age"); String address = rs.getString("address"); float salary = rs.getFloat("salary"); System.out.println( "ID = " + id ); System.out.println( "NAME = " + name ); System.out.println( "AGE = " + age ); System.out.println( "ADDRESS = " + address ); System.out.println( "SALARY = " + salary ); System.out.println(); } rs.close(); stmt.close(); c.close(); } catch ( Exception e ) { System.err.println( e.getClass().getName()+": "+ e.getMessage() ); System.exit(0); } System.out.println("Operation done successfully"); } }
Когда программа скомпилирована и выполнена, она даст следующий результат –
Opened database successfully ID = 2 NAME = Allen AGE = 25 ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 25000.0 Operation done successfully
УДАЛЕНИЕ Операция
Следующий код Java показывает, как мы можем использовать инструкцию DELETE, чтобы удалить любую запись, а затем извлечь и отобразить оставшиеся записи из нашей таблицы COMPANY –
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; public class PostgreSQLJDBC6 { public static void main( String args[] ) { Connection c = null; Statement stmt = null; try { Class.forName("org.postgresql.Driver"); c = DriverManager .getConnection("jdbc:postgresql://localhost:5432/testdb", "manisha", "123"); c.setAutoCommit(false); System.out.println("Opened database successfully"); stmt = c.createStatement(); String sql = "DELETE from COMPANY where ID = 2;"; stmt.executeUpdate(sql); c.commit(); ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" ); while ( rs.next() ) { int id = rs.getInt("id"); String name = rs.getString("name"); int age = rs.getInt("age"); String address = rs.getString("address"); float salary = rs.getFloat("salary"); System.out.println( "ID = " + id ); System.out.println( "NAME = " + name ); System.out.println( "AGE = " + age ); System.out.println( "ADDRESS = " + address ); System.out.println( "SALARY = " + salary ); System.out.println(); } rs.close(); stmt.close(); c.close(); } catch ( Exception e ) { System.err.println( e.getClass().getName()+": "+ e.getMessage() ); System.exit(0); } System.out.println("Operation done successfully"); } }
Когда программа скомпилирована и выполнена, она даст следующий результат –
Opened database successfully ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 25000.0 Operation done successfully
PostgreSQL – интерфейс PHP
Монтаж
Расширение PostgreSQL включено по умолчанию в последних версиях PHP 5.3.x. Это можно отключить, используя –without-pgsql во время компиляции. Тем не менее, вы можете использовать команду yum для установки PHP-интерфейса PostgreSQL –
yum install php-pgsql
Прежде чем вы начнете использовать интерфейс PHP PostgreSQL, найдите файл pg_hba.conf в вашем установочном каталоге PostgreSQL и добавьте следующую строку:
# IPv4 local connections: host all all 127.0.0.1/32 md5
Вы можете запустить / перезапустить сервер postgres, если он не работает, с помощью следующей команды –
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
Пользователи Windows должны включить php_pgsql.dll, чтобы использовать это расширение. Эта DLL включена в дистрибутивы Windows в последних версиях PHP 5.3.x
Для получения подробных инструкций по установке, пожалуйста, просмотрите наш учебник по PHP и его официальный сайт.
API интерфейса PHP
Ниже приведены важные процедуры PHP, которые могут удовлетворить ваши требования для работы с базой данных PostgreSQL из вашей программы PHP. Если вы ищете более сложное приложение, вы можете заглянуть в официальную документацию PHP.
| С. Нет. | API и описание |
|---|---|
| 1 |
ресурс pg_connect (строка $ connection_string [, int $ connect_type]) Это открывает соединение с базой данных PostgreSQL, указанной в параметре connection_string. Если PGSQL_CONNECT_FORCE_NEW передается как connect_type, то создается новое соединение в случае второго вызова pg_connect (), даже если строка_соединения идентична существующему соединению. |
| 2 |
bool pg_connection_reset (ресурс $ соединение) Эта процедура сбрасывает соединение. Это полезно для восстановления после ошибок. Возвращает TRUE в случае успеха или FALSE в случае неудачи. |
| 3 |
int pg_connection_status (ресурс $ connection) Эта процедура возвращает состояние указанного соединения. Возвращает PGSQL_CONNECTION_OK или PGSQL_CONNECTION_BAD. |
| 4 |
строка pg_dbname ([ресурс $ соединение]) Эта подпрограмма возвращает имя базы данных, к которой относится данный ресурс соединения PostgreSQL. |
| 5 |
ресурс pg_prepare ([ресурс $ соединение], строка $ stmtname, строка $ запрос) Это отправляет запрос на создание подготовленного оператора с заданными параметрами и ожидает завершения. |
| 6 |
ресурс pg_execute ([ресурс $ connection], строка $ stmtname, массив $ params) Эта подпрограмма отправляет запрос на выполнение подготовленного оператора с заданными параметрами и ожидает результата. |
| 7 |
ресурс pg_query ([ресурс $ соединение], строка $ запрос) Эта подпрограмма выполняет запрос для указанного соединения с базой данных. |
| 8 |
массив pg_fetch_row (ресурс $ result [, int $ row]) Эта процедура извлекает одну строку данных из результата, связанного с указанным ресурсом результата. |
| 9 |
массив pg_fetch_all (ресурс $ результат) Эта подпрограмма возвращает массив, содержащий все строки (записи) в результирующем ресурсе. |
| 10 |
int pg_affered_rows (ресурс $ результат) Эта подпрограмма возвращает количество строк, затронутых запросами INSERT, UPDATE и DELETE. |
| 11 |
int pg_num_rows (ресурс $ результат) Эта подпрограмма возвращает количество строк в результирующем ресурсе PostgreSQL, например, количество строк, возвращаемых оператором SELECT. |
| 12 |
bool pg_close ([ресурс $ соединение]) Эта процедура закрывает непостоянное соединение с базой данных PostgreSQL, связанной с данным ресурсом соединения. |
| 13 |
строка pg_last_error ([ресурс $ соединение]) Эта процедура возвращает последнее сообщение об ошибке для данного соединения. |
| 14 |
строка pg_escape_literal ([ресурс $ соединение], строка $ данные) Эта подпрограмма экранирует литерал для вставки в текстовое поле. |
| 15 |
строка pg_escape_string ([ресурс $ соединение], строка $ данные) Эта подпрограмма экранирует строку для запроса к базе данных. |
ресурс pg_connect (строка $ connection_string [, int $ connect_type])
Это открывает соединение с базой данных PostgreSQL, указанной в параметре connection_string.
Если PGSQL_CONNECT_FORCE_NEW передается как connect_type, то создается новое соединение в случае второго вызова pg_connect (), даже если строка_соединения идентична существующему соединению.
bool pg_connection_reset (ресурс $ соединение)
Эта процедура сбрасывает соединение. Это полезно для восстановления после ошибок. Возвращает TRUE в случае успеха или FALSE в случае неудачи.
int pg_connection_status (ресурс $ connection)
Эта процедура возвращает состояние указанного соединения. Возвращает PGSQL_CONNECTION_OK или PGSQL_CONNECTION_BAD.
строка pg_dbname ([ресурс $ соединение])
Эта подпрограмма возвращает имя базы данных, к которой относится данный ресурс соединения PostgreSQL.
ресурс pg_prepare ([ресурс $ соединение], строка $ stmtname, строка $ запрос)
Это отправляет запрос на создание подготовленного оператора с заданными параметрами и ожидает завершения.
ресурс pg_execute ([ресурс $ connection], строка $ stmtname, массив $ params)
Эта подпрограмма отправляет запрос на выполнение подготовленного оператора с заданными параметрами и ожидает результата.
ресурс pg_query ([ресурс $ соединение], строка $ запрос)
Эта подпрограмма выполняет запрос для указанного соединения с базой данных.
массив pg_fetch_row (ресурс $ result [, int $ row])
Эта процедура извлекает одну строку данных из результата, связанного с указанным ресурсом результата.
массив pg_fetch_all (ресурс $ результат)
Эта подпрограмма возвращает массив, содержащий все строки (записи) в результирующем ресурсе.
int pg_affered_rows (ресурс $ результат)
Эта подпрограмма возвращает количество строк, затронутых запросами INSERT, UPDATE и DELETE.
int pg_num_rows (ресурс $ результат)
Эта подпрограмма возвращает количество строк в результирующем ресурсе PostgreSQL, например, количество строк, возвращаемых оператором SELECT.
bool pg_close ([ресурс $ соединение])
Эта процедура закрывает непостоянное соединение с базой данных PostgreSQL, связанной с данным ресурсом соединения.
строка pg_last_error ([ресурс $ соединение])
Эта процедура возвращает последнее сообщение об ошибке для данного соединения.
строка pg_escape_literal ([ресурс $ соединение], строка $ данные)
Эта подпрограмма экранирует литерал для вставки в текстовое поле.
строка pg_escape_string ([ресурс $ соединение], строка $ данные)
Эта подпрограмма экранирует строку для запроса к базе данных.
Подключение к базе данных
Следующий код PHP показывает, как подключиться к существующей базе данных на локальном компьютере, и, наконец, будет возвращен объект подключения к базе данных.
<?php $host = "host = 127.0.0.1"; $port = "port = 5432"; $dbname = "dbname = testdb"; $credentials = "user = postgres password=pass123"; $db = pg_connect( "$host $port $dbname $credentials" ); if(!$db) { echo "Error : Unable to open databasen"; } else { echo "Opened database successfullyn"; } ?>
Теперь давайте запустим указанную выше программу, чтобы открыть нашу базу данных testdb : если база данных успешно открыта, она выдаст следующее сообщение:
Opened database successfully
Создать таблицу
Следующая программа PHP будет использоваться для создания таблицы в ранее созданной базе данных –
<?php $host = "host = 127.0.0.1"; $port = "port = 5432"; $dbname = "dbname = testdb"; $credentials = "user = postgres password=pass123"; $db = pg_connect( "$host $port $dbname $credentials" ); if(!$db) { echo "Error : Unable to open databasen"; } else { echo "Opened database successfullyn"; } $sql =<<<EOF CREATE TABLE COMPANY (ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL); EOF; $ret = pg_query($db, $sql); if(!$ret) { echo pg_last_error($db); } else { echo "Table created successfullyn"; } pg_close($db); ?>
Когда приведенная выше программа будет выполнена, она создаст таблицу COMPANY в вашей тестовой базе данных и отобразит следующие сообщения:
Opened database successfully Table created successfully
ВСТАВИТЬ Операция
Следующая программа PHP показывает, как мы можем создавать записи в нашей таблице COMPANY, созданной в приведенном выше примере:
<?php $host = "host=127.0.0.1"; $port = "port=5432"; $dbname = "dbname = testdb"; $credentials = "user = postgres password=pass123"; $db = pg_connect( "$host $port $dbname $credentials" ); if(!$db) { echo "Error : Unable to open databasen"; } else { echo "Opened database successfullyn"; } $sql =<<<EOF INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (2, 'Allen', 25, 'Texas', 15000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (3, 'Teddy', 23, 'Norway', 20000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 ); EOF; $ret = pg_query($db, $sql); if(!$ret) { echo pg_last_error($db); } else { echo "Records created successfullyn"; } pg_close($db); ?>
Когда указанная выше программа будет выполнена, она создаст указанные записи в таблице COMPANY и отобразит следующие две строки:
Opened database successfully Records created successfully
ВЫБЕРИТЕ Операцию
Следующая программа PHP показывает, как мы можем получать и отображать записи из нашей таблицы COMPANY, созданной в приведенном выше примере.
<?php $host = "host = 127.0.0.1"; $port = "port = 5432"; $dbname = "dbname = testdb"; $credentials = "user = postgres password=pass123"; $db = pg_connect( "$host $port $dbname $credentials" ); if(!$db) { echo "Error : Unable to open databasen"; } else { echo "Opened database successfullyn"; } $sql =<<<EOF SELECT * from COMPANY; EOF; $ret = pg_query($db, $sql); if(!$ret) { echo pg_last_error($db); exit; } while($row = pg_fetch_row($ret)) { echo "ID = ". $row[0] . "n"; echo "NAME = ". $row[1] ."n"; echo "ADDRESS = ". $row[2] ."n"; echo "SALARY = ".$row[4] ."nn"; } echo "Operation done successfullyn"; pg_close($db); ?>
Когда приведенная выше программа выполняется, она даст следующий результат. Помните, что поля возвращаются в той последовательности, в которой они использовались при создании таблицы.
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
ОБНОВЛЕНИЕ Операция
Следующий код PHP показывает, как мы можем использовать оператор UPDATE для обновления любой записи, а затем извлекать и отображать обновленные записи из нашей таблицы COMPANY –
<?php $host = "host=127.0.0.1"; $port = "port=5432"; $dbname = "dbname = testdb"; $credentials = "user = postgres password=pass123"; $db = pg_connect( "$host $port $dbname $credentials" ); if(!$db) { echo "Error : Unable to open databasen"; } else { echo "Opened database successfullyn"; } $sql =<<<EOF UPDATE COMPANY set SALARY = 25000.00 where ID=1; EOF; $ret = pg_query($db, $sql); if(!$ret) { echo pg_last_error($db); exit; } else { echo "Record updated successfullyn"; } $sql =<<<EOF SELECT * from COMPANY; EOF; $ret = pg_query($db, $sql); if(!$ret) { echo pg_last_error($db); exit; } while($row = pg_fetch_row($ret)) { echo "ID = ". $row[0] . "n"; echo "NAME = ". $row[1] ."n"; echo "ADDRESS = ". $row[2] ."n"; echo "SALARY = ".$row[4] ."nn"; } echo "Operation done successfullyn"; pg_close($db); ?>
Когда вышеуказанная программа будет выполнена, она даст следующий результат –
Opened database successfully Record updated successfully ID = 2 NAME = Allen ADDRESS = 25 SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = 23 SALARY = 20000 ID = 4 NAME = Mark ADDRESS = 25 SALARY = 65000 ID = 1 NAME = Paul ADDRESS = 32 SALARY = 25000 Operation done successfully
УДАЛЕНИЕ Операция
Следующий код PHP показывает, как мы можем использовать инструкцию DELETE, чтобы удалить любую запись, а затем извлечь и отобразить оставшиеся записи из нашей таблицы COMPANY –
<?php $host = "host = 127.0.0.1"; $port = "port = 5432"; $dbname = "dbname = testdb"; $credentials = "user = postgres password=pass123"; $db = pg_connect( "$host $port $dbname $credentials" ); if(!$db) { echo "Error : Unable to open databasen"; } else { echo "Opened database successfullyn"; } $sql =<<<EOF DELETE from COMPANY where ID=2; EOF; $ret = pg_query($db, $sql); if(!$ret) { echo pg_last_error($db); exit; } else { echo "Record deleted successfullyn"; } $sql =<<<EOF SELECT * from COMPANY; EOF; $ret = pg_query($db, $sql); if(!$ret) { echo pg_last_error($db); exit; } while($row = pg_fetch_row($ret)) { echo "ID = ". $row[0] . "n"; echo "NAME = ". $row[1] ."n"; echo "ADDRESS = ". $row[2] ."n"; echo "SALARY = ".$row[4] ."nn"; } echo "Operation done successfullyn"; pg_close($db); ?>
Когда вышеуказанная программа будет выполнена, она даст следующий результат –
Opened database successfully Record deleted successfully ID = 3 NAME = Teddy ADDRESS = 23 SALARY = 20000 ID = 4 NAME = Mark ADDRESS = 25 SALARY = 65000 ID = 1 NAME = Paul ADDRESS = 32 SALARY = 25000 Operation done successfully
PostgreSQL – интерфейс Perl
Монтаж
PostgreSQL может быть интегрирован с Perl с помощью модуля Perl DBI, который является модулем доступа к базе данных для языка программирования Perl. Он определяет набор методов, переменных и соглашений, которые обеспечивают стандартный интерфейс базы данных.
Вот простые шаги для установки модуля DBI на вашем компьютере с Linux / Unix –
$ wget http://search.cpan.org/CPAN/authors/id/T/TI/TIMB/DBI-1.625.tar.gz $ tar xvfz DBI-1.625.tar.gz $ cd DBI-1.625 $ perl Makefile.PL $ make $ make install
Если вам нужно установить драйвер SQLite для DBI, его можно установить следующим образом:
$ wget http://search.cpan.org/CPAN/authors/id/T/TU/TURNSTEP/DBD-Pg-2.19.3.tar.gz $ tar xvfz DBD-Pg-2.19.3.tar.gz $ cd DBD-Pg-2.19.3 $ perl Makefile.PL $ make $ make install
Прежде чем вы начнете использовать интерфейс Perl PostgreSQL, найдите файл pg_hba.conf в вашем каталоге установки PostgreSQL и добавьте следующую строку –
# IPv4 local connections: host all all 127.0.0.1/32 md5
Вы можете запустить / перезапустить сервер postgres, если он не работает, с помощью следующей команды –
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
API интерфейса DBI
Ниже приведены важные подпрограммы DBI, которые могут удовлетворить ваши требования для работы с базой данных SQLite из вашей программы Perl. Если вы ищете более сложное приложение, вы можете посмотреть официальную документацию Perl DBI.
| С. Нет. | API и описание |
|---|---|
| 1 |
DBI → connect ($ data_source, “userid”, “password”, % attr) Устанавливает соединение базы данных или сеанс с запрошенным $ data_source. Возвращает объект дескриптора базы данных, если соединение установлено успешно. Источник данных имеет вид: DBI: Pg: dbname = $ database; host = 127.0.0.1; port = 5432 Pg – это имя драйвера PostgreSQL, а testdb – имя базы данных. |
| 2 |
$ ДВГ → сделать ($ SQL) Эта подпрограмма подготавливает и выполняет один оператор SQL. Возвращает количество затронутых строк или undef при ошибке. Возвращаемое значение -1 означает, что количество строк неизвестно, неприменимо или недоступно. Здесь $ dbh – дескриптор, возвращаемый вызовом DBI → connect (). |
| 3 |
$ ДВГ → подготовить ($ SQL) Эта подпрограмма подготавливает оператор для последующего выполнения ядром базы данных и возвращает ссылку на объект дескриптора оператора. |
| 4 |
$ STH → Execute () Эта процедура выполняет любую обработку, необходимую для выполнения подготовленного оператора. Undef возвращается, если произошла ошибка. Успешное выполнение всегда возвращает true независимо от количества затронутых строк. Здесь $ sth – дескриптор оператора, возвращаемый вызовом $ dbh → prepare ($ sql). |
| 5 |
$ STH → fetchrow_array () Эта процедура извлекает следующую строку данных и возвращает ее в виде списка, содержащего значения полей. Пустые поля возвращаются как неопределенные значения в списке. |
| 6 |
$ DBI :: эээ Это эквивалентно $ h → err, где $ h – любой из типов дескрипторов, таких как $ dbh, $ sth или $ drh. Это возвращает собственный код ошибки ядра базы данных из последнего вызванного метода драйвера. |
| 7 |
$ DBI :: ErrStr Это эквивалентно $ h → errstr, где $ h – любой из типов дескрипторов, таких как $ dbh, $ sth или $ drh. Это возвращает собственное сообщение об ошибке ядра СУБД из последнего вызванного метода DBI. |
| 8 |
$ dbh-> разъединение () Эта процедура закрывает соединение с базой данных, ранее открытое с помощью вызова DBI → connect (). |
DBI → connect ($ data_source, “userid”, “password”, % attr)
Устанавливает соединение базы данных или сеанс с запрошенным $ data_source. Возвращает объект дескриптора базы данных, если соединение установлено успешно.
Источник данных имеет вид: DBI: Pg: dbname = $ database; host = 127.0.0.1; port = 5432 Pg – это имя драйвера PostgreSQL, а testdb – имя базы данных.
$ ДВГ → сделать ($ SQL)
Эта подпрограмма подготавливает и выполняет один оператор SQL. Возвращает количество затронутых строк или undef при ошибке. Возвращаемое значение -1 означает, что количество строк неизвестно, неприменимо или недоступно. Здесь $ dbh – дескриптор, возвращаемый вызовом DBI → connect ().
$ ДВГ → подготовить ($ SQL)
Эта подпрограмма подготавливает оператор для последующего выполнения ядром базы данных и возвращает ссылку на объект дескриптора оператора.
$ STH → Execute ()
Эта процедура выполняет любую обработку, необходимую для выполнения подготовленного оператора. Undef возвращается, если произошла ошибка. Успешное выполнение всегда возвращает true независимо от количества затронутых строк. Здесь $ sth – дескриптор оператора, возвращаемый вызовом $ dbh → prepare ($ sql).
$ STH → fetchrow_array ()
Эта процедура извлекает следующую строку данных и возвращает ее в виде списка, содержащего значения полей. Пустые поля возвращаются как неопределенные значения в списке.
$ DBI :: эээ
Это эквивалентно $ h → err, где $ h – любой из типов дескрипторов, таких как $ dbh, $ sth или $ drh. Это возвращает собственный код ошибки ядра базы данных из последнего вызванного метода драйвера.
$ DBI :: ErrStr
Это эквивалентно $ h → errstr, где $ h – любой из типов дескрипторов, таких как $ dbh, $ sth или $ drh. Это возвращает собственное сообщение об ошибке ядра СУБД из последнего вызванного метода DBI.
$ dbh-> разъединение ()
Эта процедура закрывает соединение с базой данных, ранее открытое с помощью вызова DBI → connect ().
Подключение к базе данных
Следующий код Perl показывает, как подключиться к существующей базе данных. Если база данных не существует, она будет создана и, наконец, будет возвращен объект базы данных.
#!/usr/bin/perl use DBI; use strict; my $driver = "Pg"; my $database = "testdb"; my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432"; my $userid = "postgres"; my $password = "pass123"; my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 }) or die $DBI::errstr; print "Opened database successfullyn";
Теперь давайте запустим указанную выше программу, чтобы открыть нашу базу данных testdb ; если база данных успешно открыта, она выдаст следующее сообщение:
Open database successfully
Создать таблицу
Следующая Perl-программа будет использоваться для создания таблицы в ранее созданной базе данных –
#!/usr/bin/perl use DBI; use strict; my $driver = "Pg"; my $database = "testdb"; my $dsn = "DBI:$driver:dbname=$database;host=127.0.0.1;port=5432"; my $userid = "postgres"; my $password = "pass123"; my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 }) or die $DBI::errstr; print "Opened database successfullyn"; my $stmt = qq(CREATE TABLE COMPANY (ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL);); my $rv = $dbh->do($stmt); if($rv < 0) { print $DBI::errstr; } else { print "Table created successfullyn"; } $dbh->disconnect();
Когда приведенная выше программа будет выполнена, она создаст таблицу COMPANY в вашей тестовой базе данных и отобразит следующие сообщения:
Opened database successfully Table created successfully
ВСТАВИТЬ Операция
Следующая программа на Perl показывает, как мы можем создавать записи в нашей таблице COMPANY, созданной в приведенном выше примере.
#!/usr/bin/perl use DBI; use strict; my $driver = "Pg"; my $database = "testdb"; my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432"; my $userid = "postgres"; my $password = "pass123"; my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 }) or die $DBI::errstr; print "Opened database successfullyn"; my $stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Paul', 32, 'California', 20000.00 )); my $rv = $dbh->do($stmt) or die $DBI::errstr; $stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (2, 'Allen', 25, 'Texas', 15000.00 )); $rv = $dbh->do($stmt) or die $DBI::errstr; $stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )); $rv = $dbh->do($stmt) or die $DBI::errstr; $stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );); $rv = $dbh->do($stmt) or die $DBI::errstr; print "Records created successfullyn"; $dbh->disconnect();
Когда указанная выше программа будет выполнена, она создаст указанные записи в таблице COMPANY и отобразит следующие две строки:
Opened database successfully Records created successfully
ВЫБЕРИТЕ Операцию
Следующая программа Perl показывает, как мы можем получать и отображать записи из нашей таблицы COMPANY, созданной в приведенном выше примере.
#!/usr/bin/perl use DBI; use strict; my $driver = "Pg"; my $database = "testdb"; my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432"; my $userid = "postgres"; my $password = "pass123"; my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 }) or die $DBI::errstr; print "Opened database successfullyn"; my $stmt = qq(SELECT id, name, address, salary from COMPANY;); my $sth = $dbh->prepare( $stmt ); my $rv = $sth->execute() or die $DBI::errstr; if($rv < 0) { print $DBI::errstr; } while(my @row = $sth->fetchrow_array()) { print "ID = ". $row[0] . "n"; print "NAME = ". $row[1] ."n"; print "ADDRESS = ". $row[2] ."n"; print "SALARY = ". $row[3] ."nn"; } print "Operation done successfullyn"; $dbh->disconnect();
Когда вышеуказанная программа будет выполнена, она даст следующий результат –
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
ОБНОВЛЕНИЕ Операция
Следующий код Perl показывает, как мы можем использовать инструкцию UPDATE, чтобы обновить любую запись, а затем извлечь и отобразить обновленные записи из нашей таблицы COMPANY –
#!/usr/bin/perl use DBI; use strict; my $driver = "Pg"; my $database = "testdb"; my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432"; my $userid = "postgres"; my $password = "pass123"; my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 }) or die $DBI::errstr; print "Opened database successfullyn"; my $stmt = qq(UPDATE COMPANY set SALARY = 25000.00 where ID=1;); my $rv = $dbh->do($stmt) or die $DBI::errstr; if( $rv < 0 ) { print $DBI::errstr; }else{ print "Total number of rows updated : $rvn"; } $stmt = qq(SELECT id, name, address, salary from COMPANY;); my $sth = $dbh->prepare( $stmt ); $rv = $sth->execute() or die $DBI::errstr; if($rv < 0) { print $DBI::errstr; } while(my @row = $sth->fetchrow_array()) { print "ID = ". $row[0] . "n"; print "NAME = ". $row[1] ."n"; print "ADDRESS = ". $row[2] ."n"; print "SALARY = ". $row[3] ."nn"; } print "Operation done successfullyn"; $dbh->disconnect();
Когда вышеуказанная программа будет выполнена, она даст следующий результат –
Opened database successfully Total number of rows updated : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
УДАЛЕНИЕ Операция
Следующий код Perl показывает, как мы можем использовать инструкцию DELETE, чтобы удалить любую запись, а затем извлечь и отобразить оставшиеся записи из нашей таблицы COMPANY –
#!/usr/bin/perl use DBI; use strict; my $driver = "Pg"; my $database = "testdb"; my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432"; my $userid = "postgres"; my $password = "pass123"; my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 }) or die $DBI::errstr; print "Opened database successfullyn"; my $stmt = qq(DELETE from COMPANY where ID=2;); my $rv = $dbh->do($stmt) or die $DBI::errstr; if( $rv < 0 ) { print $DBI::errstr; } else{ print "Total number of rows deleted : $rvn"; } $stmt = qq(SELECT id, name, address, salary from COMPANY;); my $sth = $dbh->prepare( $stmt ); $rv = $sth->execute() or die $DBI::errstr; if($rv < 0) { print $DBI::errstr; } while(my @row = $sth->fetchrow_array()) { print "ID = ". $row[0] . "n"; print "NAME = ". $row[1] ."n"; print "ADDRESS = ". $row[2] ."n"; print "SALARY = ". $row[3] ."nn"; } print "Operation done successfullyn"; $dbh->disconnect();
Когда вышеуказанная программа будет выполнена, она даст следующий результат –
Opened database successfully Total number of rows deleted : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
PostgreSQL – интерфейс Python
Монтаж
PostgreSQL может быть интегрирован с Python с помощью модуля psycopg2. sycopg2 – это адаптер базы данных PostgreSQL для языка программирования Python. psycopg2 был написан с целью быть очень маленьким, быстрым и стабильным как скала. Вам не нужно устанавливать этот модуль отдельно, потому что он поставляется по умолчанию вместе с Python версии 2.5.x и выше.
Если он не установлен на вашем компьютере, вы можете использовать команду yum для его установки следующим образом:
$yum install python-psycopg2
Чтобы использовать модуль psycopg2, вы должны сначала создать объект Connection, который представляет базу данных, а затем при желании вы можете создать объект курсора, который поможет вам в выполнении всех операторов SQL.
API модуля Python psycopg2
Ниже приведены важные подпрограммы модуля psycopg2, которые могут удовлетворить ваши требования по работе с базой данных PostgreSQL из вашей программы Python. Если вы ищете более сложное приложение, вы можете посмотреть официальную документацию модуля Python psycopg2.
| С. Нет. | API и описание |
|---|---|
| 1 |
psycopg2.connect (database = “testdb”, user = “postgres”, password = “cohondob”, host = “127.0.0.1”, port = “5432”) Этот API-интерфейс открывает соединение с базой данных PostgreSQL. Если база данных открыта успешно, она возвращает объект подключения. |
| 2 |
connection.cursor () Эта подпрограмма создает курсор, который будет использоваться при программировании вашей базы данных на Python. |
| 3 |
cursor.execute (sql [, необязательные параметры]) Эта подпрограмма выполняет инструкцию SQL. Оператор SQL может быть параметризован (т. Е. Заполнители вместо литералов SQL). Модуль psycopg2 поддерживает заполнитель с использованием знака% s Например: cursor.execute («вставить в людей значения (% s,% s)», (кто, возраст)) |
| 4 |
cursor.executemany (sql, seq_of_parameters) Эта подпрограмма выполняет команду SQL для всех последовательностей параметров или отображений, найденных в последовательности sql. |
| 5 |
cursor.callproc (procname [, параметры]) Эта процедура выполняет хранимую процедуру базы данных с заданным именем. Последовательность параметров должна содержать одну запись для каждого аргумента, ожидаемого процедурой. |
| 6 |
cursor.rowcount Этот атрибут только для чтения, который возвращает общее количество строк базы данных, которые были изменены, вставлены или удалены последним последним выполнением * (). |
| 7 |
connection.commit () Этот метод фиксирует текущую транзакцию. Если вы не вызываете этот метод, все, что вы сделали после последнего вызова commit (), не будет видно из других соединений с базой данных. |
| 8 |
connection.rollback () Этот метод откатывает любые изменения в базе данных с момента последнего вызова commit (). |
| 9 |
connection.close () Этот метод закрывает соединение с базой данных. Обратите внимание, что это не вызывает автоматически commit (). Если вы просто закроете соединение с базой данных без предварительного вызова commit (), ваши изменения будут потеряны! |
| 10 |
cursor.fetchone () Этот метод извлекает следующую строку из набора результатов запроса, возвращая одну последовательность или None, если больше нет данных. |
| 11 |
cursor.fetchmany ([размер = cursor.arraysize]) Эта процедура извлекает следующий набор строк результата запроса, возвращая список. Пустой список возвращается, когда больше нет доступных строк. Метод пытается извлечь столько строк, сколько указано параметром size. |
| 12 |
cursor.fetchall () Эта процедура извлекает все (оставшиеся) строки результата запроса, возвращая список. Пустой список возвращается, когда нет доступных строк. |
psycopg2.connect (database = “testdb”, user = “postgres”, password = “cohondob”, host = “127.0.0.1”, port = “5432”)
Этот API-интерфейс открывает соединение с базой данных PostgreSQL. Если база данных открыта успешно, она возвращает объект подключения.
connection.cursor ()
Эта подпрограмма создает курсор, который будет использоваться при программировании вашей базы данных на Python.
cursor.execute (sql [, необязательные параметры])
Эта подпрограмма выполняет инструкцию SQL. Оператор SQL может быть параметризован (т. Е. Заполнители вместо литералов SQL). Модуль psycopg2 поддерживает заполнитель с использованием знака% s
Например: cursor.execute («вставить в людей значения (% s,% s)», (кто, возраст))
cursor.executemany (sql, seq_of_parameters)
Эта подпрограмма выполняет команду SQL для всех последовательностей параметров или отображений, найденных в последовательности sql.
cursor.callproc (procname [, параметры])
Эта процедура выполняет хранимую процедуру базы данных с заданным именем. Последовательность параметров должна содержать одну запись для каждого аргумента, ожидаемого процедурой.
cursor.rowcount
Этот атрибут только для чтения, который возвращает общее количество строк базы данных, которые были изменены, вставлены или удалены последним последним выполнением * ().
connection.commit ()
Этот метод фиксирует текущую транзакцию. Если вы не вызываете этот метод, все, что вы сделали после последнего вызова commit (), не будет видно из других соединений с базой данных.
connection.rollback ()
Этот метод откатывает любые изменения в базе данных с момента последнего вызова commit ().
connection.close ()
Этот метод закрывает соединение с базой данных. Обратите внимание, что это не вызывает автоматически commit (). Если вы просто закроете соединение с базой данных без предварительного вызова commit (), ваши изменения будут потеряны!
cursor.fetchone ()
Этот метод извлекает следующую строку из набора результатов запроса, возвращая одну последовательность или None, если больше нет данных.
cursor.fetchmany ([размер = cursor.arraysize])
Эта процедура извлекает следующий набор строк результата запроса, возвращая список. Пустой список возвращается, когда больше нет доступных строк. Метод пытается извлечь столько строк, сколько указано параметром size.
cursor.fetchall ()
Эта процедура извлекает все (оставшиеся) строки результата запроса, возвращая список. Пустой список возвращается, когда нет доступных строк.
Подключение к базе данных
Следующий код Python показывает, как подключиться к существующей базе данных. Если база данных не существует, она будет создана и, наконец, будет возвращен объект базы данных.
#!/usr/bin/python import psycopg2 conn = psycopg2.connect(database="testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432") print "Opened database successfully"
Здесь вы также можете указать базу данных testdb в качестве имени, и если база данных будет успешно открыта, она выдаст следующее сообщение:
Open database successfully
Создать таблицу
Следующая программа Python будет использоваться для создания таблицы в ранее созданной базе данных –
#!/usr/bin/python import psycopg2 conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432") print "Opened database successfully" cur = conn.cursor() cur.execute('''CREATE TABLE COMPANY (ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL);''') print "Table created successfully" conn.commit() conn.close()
Когда вышеуказанная программа будет выполнена, она создаст таблицу COMPANY в вашем test.db и отобразит следующие сообщения:
Opened database successfully Table created successfully
ВСТАВИТЬ Операция
Следующая программа на Python показывает, как мы можем создавать записи в нашей таблице COMPANY, созданной в приведенном выше примере.
#!/usr/bin/python import psycopg2 conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432") print "Opened database successfully" cur = conn.cursor() cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Paul', 32, 'California', 20000.00 )"); cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (2, 'Allen', 25, 'Texas', 15000.00 )"); cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )"); cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )"); conn.commit() print "Records created successfully"; conn.close()
Когда указанная выше программа будет выполнена, она создаст указанные записи в таблице COMPANY и отобразит следующие две строки:
Opened database successfully Records created successfully
ВЫБЕРИТЕ Операцию
Следующая программа на Python показывает, как мы можем получать и отображать записи из нашей таблицы COMPANY, созданной в приведенном выше примере.
#!/usr/bin/python import psycopg2 conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432") print "Opened database successfully" cur = conn.cursor() cur.execute("SELECT id, name, address, salary from COMPANY") rows = cur.fetchall() for row in rows: print "ID = ", row[0] print "NAME = ", row[1] print "ADDRESS = ", row[2] print "SALARY = ", row[3], "n" print "Operation done successfully"; conn.close()
Когда вышеуказанная программа будет выполнена, она даст следующий результат –
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000.0 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
ОБНОВЛЕНИЕ Операция
Следующий код Python показывает, как мы можем использовать инструкцию UPDATE, чтобы обновить любую запись, а затем извлечь и отобразить обновленные записи из нашей таблицы COMPANY –
#!/usr/bin/python import psycopg2 conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432") print "Opened database successfully" cur = conn.cursor() cur.execute("UPDATE COMPANY set SALARY = 25000.00 where ID = 1") conn.commit() print "Total number of rows updated :", cur.rowcount cur.execute("SELECT id, name, address, salary from COMPANY") rows = cur.fetchall() for row in rows: print "ID = ", row[0] print "NAME = ", row[1] print "ADDRESS = ", row[2] print "SALARY = ", row[3], "n" print "Operation done successfully"; conn.close()
Когда вышеуказанная программа будет выполнена, она даст следующий результат –
Opened database successfully Total number of rows updated : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000.0 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
УДАЛЕНИЕ Операция
Следующий код Python показывает, как мы можем использовать инструкцию DELETE, чтобы удалить любую запись, а затем извлечь и отобразить остальные записи из нашей таблицы COMPANY –
#!/usr/bin/python import psycopg2 conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432") print "Opened database successfully" cur = conn.cursor() cur.execute("DELETE from COMPANY where ID=2;") conn.commit() print "Total number of rows deleted :", cur.rowcount cur.execute("SELECT id, name, address, salary from COMPANY") rows = cur.fetchall() for row in rows: print "ID = ", row[0] print "NAME = ", row[1] print "ADDRESS = ", row[2] print "SALARY = ", row[3], "n" print "Operation done successfully"; conn.close()
Когда вышеуказанная программа будет выполнена, она даст следующий результат –
Welcome to the PostgreSQL Tutorial. The following few chapters are intended to give a simple introduction to PostgreSQL, relational database concepts, and the SQL language to those who are new to any one of these aspects. We only assume some general knowledge about how to use computers. No particular Unix or programming experience is required. This part is mainly intended to give you some hands-on experience with important aspects of the PostgreSQL system. It makes no attempt to be a complete or thorough treatment of the topics it covers.
After you have worked through this tutorial you might want to move on to reading Part II to gain a more formal knowledge of the SQL language, or Part IV for information about developing applications for PostgreSQL. Those who set up and manage their own server should also read Part III.

Хочу поделиться полезными приемами работы с PostgreSQL (другие СУБД имеют схожий функционал, но могут иметь иной синтаксис).
Постараюсь охватить множество тем и приемов, которые помогут при работе с данными, стараясь не углубляться в подробное описание того или иного функционала. Я любил подобные статьи, когда обучался самостоятельно. Пришло время
отдать должное бесплатному интернет самообразованию и
написать собственную статью.
Данный материал будет полезен тем, кто полностью освоил базовые навыки SQL и желает учиться дальше. Советую выполнять и экспериментировать с примерами в pgAdmin‘e, я сделал все SQL-запросы выполнимыми без разворачивания каких-либо дампов.
Поехали!
1. Использование временных таблиц
При решении сложных задач трудно поместить решение в один запрос (хотя, многие стараются так сделать). В таких случаях удобно помещать какие-либо промежуточные данные во временную таблицу, для использования их в дальнейшем.
Такие таблицы создаются как обычные, но с ключевым словом TEMP, и автоматически удаляются после завершения сессии.
Ключ ON COMMIT DROP автоматически удаляет таблицу (и все связанные с ней объекты) при завершении транзакции.
Пример:
ROLLBACK;
BEGIN;
CREATE TEMP TABLE my_fist_temp_table -- стоит использовать наиболее уникальное имя
ON COMMIT DROP -- удаляем таблицу при завершении транзакции
AS
SELECT 1 AS id, CAST ('какие-то значения' AS TEXT) AS val;
------------ Дополнительные манипуляции с таблицей: ------------------
-- изменим таблицу, добавив столбец. Буду частенько затрагивать смежные темы
ALTER TABLE my_fist_temp_table
ADD COLUMN is_deleted BOOLEAN NOT NULL DEFAULT FALSE;
-- для тех, кто не в курсе, чаще всего данные в таблицах не удаляются, а помечаются как удаленные подобным флагом
CREATE UNIQUE INDEX ON my_fist_temp_table (lower(val))
WHERE is_deleted = FALSE; -- можно даже создать индекс/ограничение, если это необходимо
-- данный индекс не позволит вставить дубликат(не зависимо от регистра) для столбца VAL, для не удаленных строк
-- манипулируем данными таблицы
UPDATE my_fist_temp_table
SET id=id+3;
-- проверяем/используем содержание таблицы
SELECT * FROM my_fist_temp_table;
--COMMIT;2. Часто используемый сокращенный синтаксис Postgres
- Преобразование типов данных.
Выражение:
SELECT CAST ('365' AS INT);можно записать менее громоздко:
SELECT '365'::INT;- Сокращенная запись конструкции (I)LIKE ‘%text%’
LIKE воспринимает
шаблонные выражения
. Подробности в мануале
оператор LIKE можно заменить на ~~ (две тильды)
оператор ILIKE можно заменить на ~~* (две тильды со звездочкой)
Поиск
регулярными выражениями
(имеет отличный от LIKE синтаксис)
оператор ~ (одна тильда) воспринимает регулярные выражения
оператор ~* (одна тильда и звездочка) регистронезависимая версия ~
Приведу пример поиска разными способами строк, которые содержат слово text
| Cокращенный синтаксис | Описание | Аналог (I)LIKE |
|---|---|---|
| ~ ‘text’ or ~~ ‘%text%’ |
Проверяет соответствие выражению с учётом регистра | LIKE ‘%text%’ |
| ~* ‘text’ ~~* ‘%text%’ |
Проверяет соответствие выражению без учёта регистра | ILIKE ‘%text%’ |
| !~ ‘text’ !~~ ‘%text%’ |
Проверяет несоответствие выражению с учётом регистра | NOT LIKE ‘%text%’ |
| !~* ‘text’ !~~* ‘%text%’ |
Проверяет несоответствие выражению без учёта регистра | NOT ILIKE ‘%text%’ |
3. Общие табличные выражения (CTE). Конструкция WITH
Очень удобная конструкция, позволяет поместить результат запроса во временную таблицу и тут же использовать ее.
Примеры будут примитивны, чтобы уловить суть.
a) Простой SELECT
WITH cte_table_name AS ( -- задаем удобное нам имя таблицы
SELECT schemaname, tablename -- наш любой запрос
FROM pg_catalog.pg_tables -- к примеру, системная таблица с таблицами базы
ORDER BY 1,2
)
SELECT * FROM cte_table_name; -- указываем нашу таблицу
--по факту получим результат выполнения запроса в скобкахТаким способом можно ‘оборачивать’ какие-либо запросы (даже UPDATE, DELETE и INSERT, об этом будет ниже) и использовать их результаты в дальнейшем.
b) Можно создать несколько таблиц, перечисляя их нижеописанным способом
WITH
table_1 (col,b) AS (SELECT 1,1), -- первая таблица
table_2 (col,c) AS (SELECT 2,2) -- вторая таблица
--,table_3 (cool,yah) AS (SELECT 2,2 from table_2) -- совсем недавно узнал, что можно обращаться к вышестоящей таблице
SELECT * FROM table_1 FULL JOIN table_2 USING (col);c) Можно даже вложить вышеуказанную конструкцию в еще один (и более) WITH
WITH super_with (col,b,c) AS ( /* можем задать имена столбцов в скобках после имени таблицы */
WITH
table_1 (col,b) AS (SELECT 1,1),
table_2 (col,c) AS (SELECT 2,2)
SELECT * FROM table_1 FULL JOIN table_2 USING (col)-- указываем нашу таблицу
)
SELECT col, b*20, c*30 FROM super_with;По производительности следует сказать, что не стоит помещать в секцию WITH данные, которые будут в значительной степени фильтроваться последующими внешними условиями (за пределами скобок запроса), ибо оптимизатор не сможет построить эффективный запрос. Удобнее всего положить в CTE результаты, к которым требуется несколько раз обращаться.
4. Функция array_agg(MyColumn).
Значения в реляционной базе хранятся разрозненно (атрибуты по одному объекту могут быть представлены в нескольких строках). Для передачи данных какому-либо приложению часто возникает необходимость собрать данные в одну строку (ячейку) или массив.
В PostgreSQL для этого существует функция array_agg(), она позволяет собрать в массив данные всего столбца (если выборка из одного столбца).
При использовании GROUP BY в массив попадут данные какого-либо столбца относительно каждой группы.
Сразу опишу еще одну функцию и перейдем к примеру.
array_to_string(array[], ‘;’) позволяет преобразовать массив в строку: первым параметром указывается массив, вторым — удобный нам разделитель в одинарных кавычках (апострофах). В качестве разделителя можно использовать
спецсимволы
Табуляция t — к примеру, позволит при вставки ячейки в EXCEL без усилий разбить значения на столбцы (использовать так: array_to_string(array[], E’t’) )
Перевод строки n — разложит значения массива по строкам в одной ячейке (использовать так: array_to_string(array[], E’n’) — объясню ниже почему)
Пример:
-- создадим и наполним данными таблицу вышеописанным способом
WITH my_table (ID, year, any_val) AS (
VALUES (1, 2017,56)
,(2, 2017,67)
,(3, 2017,12)
,(4, 2017,30)
,(5, 2020,8)
,(6, 2030,17)
,(7, 2030,50)
)
SELECT year
,array_agg(any_val) -- собираю данные (по каждому году) в массив
,array_agg(any_val ORDER BY any_val) AS sort_array_agg -- порядок элементов можно отсортировать (с 9+ версии Postgres)
,array_to_string(array_agg(any_val),';') -- преобразовываю массив в строку
,ARRAY['This', 'is', 'my' , 'array'] AS my_simple_array -- способ создания массива
FROM my_table
GROUP BY year; -- группируем данные по каждому году
Выдаст результат:

Выполним обратное действие. Разложим массив в строки при помощи функции UNNEST, заодно продемонстрирую конструкцию SELECT columns INTO table_name. Помещу это в спойлер, чтобы статья не сильно разбухала.
UNNEST запрос
-- 1 Подготовительный этап
-- в процессе запроса будет создана таблица tst_unnest_for_del, с помощью конструкции SELECT INTO
-- чтобы запрос не приводил к ошибке, в случае если вы будете несколько раз прогонять этот скрипт, начну этот скрипт с удаления таблицы.
-- я также надеюсь, что вы запускаете это не на production сервере какого-либо проекта, где есть такая таблица
DROP TABLE IF EXISTS tst_unnest_for_del; /* IF EXISTS не вызовет ошибки, если таблицы для удаления не существует */
WITH my_table (ID, year, any_val) AS (
VALUES (1, 2017,56)
,(2, 2017,67)
,(3, 2017,12)
,(4, 2017,30)
,(5, 2020,8)
,(6, 2030,17)
,(7, 2030,50)
)
SELECT year
,array_agg(id) AS arr_id -- собираю данные(id) по каждому году в массив
,array_agg(any_val) AS arr_any_val -- собираю данные(any_val) по каждому году в массив
INTO tst_unnest_for_del -- !! способ создания и заполнения таблицы из полученного результата
FROM my_table
GROUP BY year;
--2 Демонстрирование функции Unnest
SELECT unnest(arr_id) unnest_id -- разбираем столбец id
,year
,unnest(arr_any_val) unnest_any_val -- разбираем столбец any_val
FROM tst_unnest_for_del
ORDER BY 1 -- восстанавливаем сортировку по id, без принудительной сортировки данные могут быть расположены хаотично
Результат:
5. Ключевое слово RETURNIG *
указанное после запросов INSERT, UPDATE или DELETE позволяет увидеть строки, которых коснулась модификация (обычно сервер сообщает лишь количество модифицированных строк).
Удобно в связке с BEGIN посмотреть на что именно повлияет запрос, в случае неуверенности в результате или для передачи каких либо id на следующий шаг.
Пример:
--1
DROP TABLE IF EXISTS for_del_tmp; /* IF EXISTS не вызовет ошибки, если таблицы для удаления не существует */
CREATE TABLE for_del_tmp -- Создаем таблицу
AS --Наполняем сгенерированными данными из запроса ниже
SELECT generate_series(1,1000) AS id, -- Генерируем 1000 пронумерованных строк
random() AS values; -- Наполняем случайными числами
--2
DELETE FROM for_del_tmp
WHERE id > 500
RETURNING *;
/*Покажет все удаленные строки данной командой,
RETURNING * - вернет все столбцы таблицы test,
так же можно перечислить столбцы как в SELECT (прим. RETURNING id,name)*/Можно использовать в связке с CTE, организую
безумный
пример.
P.S.
Я весьма заморочился, боюсь, что вышло сложно, но я постарался все прокомментировать.
--1
DROP TABLE IF EXISTS for_del_tmp; /* IF EXISTS не вызовет ошибки, если таблицы для удаления не существует */
CREATE TABLE for_del_tmp -- Создаем таблицу
AS --Наполняем сгенерированными данными из запроса ниже
SELECT generate_series(1,1000) AS id, -- Генерируем 1000 пронумерованных строк
((random()*1000)::INTEGER)::text as values; /* Наполняем случайными числами. P.S. У меня Postgre 9.2 Random() возвращает дробное число меньше единицы, умножаю на 1000, чтобы получить целую часть, затем преобразовываю к INTEGER для избавления от дробной части, и преобразовываю к тексту, т.к. хочу, чтобы тип данных созданного столбца был TEXT*/
--2
DELETE FROM for_del_tmp
WHERE id > 500
RETURNING *; -- Данный запрос просто удалит записи, вернув удаленные строки на экран
--3
WITH deleted_id (id) AS
(
DELETE FROM for_del_tmp
WHERE id > 25
RETURNING id -- удаляем еще часть данных, записывая id в наше CTE "deleted_id"
)
INSERT INTO for_del_tmp -- инициируем INSERT
SELECT id, 'Удаленная строка в ' || now()::TIME || ' а если быть точным, то ' || timeofday()::TIMESTAMP /* здесь можно проследить за тем, как отличается время возвращаемое функциями (зависит от описания функции, углубляться не буду, и так далеко зашел)*/
FROM deleted_id -- вставляем удаленные данные из "for_del_tmp" в нее же
RETURNING *; -- сразу видим что проинсертилось
--весь блок можно выполнять бесконечно, мы будем вставлять удаляемые данные в эту же таблицу.
--4
SELECT * FROM for_del_tmp; -- проверяем, что вышло в итогеТаким образом, выполнится удаление данных, и удаленные значения передадутся на следующий этап. Все зависит от вашей фантазии и целей. Перед применением сложных конструкций обязательно изучите документацию вашей версии СУБД! (при параллельном комбинировании INSERT, UPDATE или DELETE существуют тонкости)
6. Сохранение результата запроса в файл
У команды COPY много разных параметров и назначений, опишу самое простое применение для ознакомления.
COPY (
SELECT * FROM pg_stat_activity /* Наш запрос. Для примера: системная таблица выполняемых процессов БД */
--) TO 'C:/TEMP/my_proc_tst.csv' -- Запись результата запроса в файл. Пример для Windows
) TO '/tmp/my_proc_tst.csv' -- Запись результата запроса в файл. Пример для LINUX
--) TO STDOUT -- выведет данные в консоль или лог pgAdmin
WITH CSV HEADER -- Необязательная строка. Передает название столбцов таблицы в файл7. Выполнение запроса на другой базе
Не так давно узнал, что можно адресовать запрос к другой базе, для этого есть функция dblink (все подробности в мануале)
Пример:
SELECT * FROM dblink(
'host=localhost user=postgres dbname=postgres', /* host и user можно не указывать, если вы хотите использовать текущие */
'SELECT ''Удаленная база: '' || current_database()' /* есть свои нюансы и ограничения. Как пример, запрос передается в одинарных кавычках, поэтому кавычки внутри запроса должны быть экранированы (в данном примере для экранирования использую две одинарных кавычки подряд). */
)
RETURNS (col_name TEXT)
UNION ALL
SELECT 'Текущая база: ' || current_database();
Если возникает ошибка:
«ERROR: function dblink(unknown, unknown) does not exist»
необходимо выполнить установку расширения следующей командой:
CREATE EXTENSION dblink;8. Функция similarity
Функция определения схожести одного значения к другому.
Использовал для сопоставления текстовых данных, которые были похожи, но не равны друг другу (имелись опечатки). Сэкономил уйму времени и нервов, сведя к минимуму ручную привязку.
similarity(a, b) выдает дробное число от 0 до 1, чем ближе к 1, тем точнее совпадение.
Перейдем к примеру. С помощью WITH организуем временную таблицу с вымышленными данными (и специально исковерканными для демонстрации функции), и будем сравнивать каждую строку с нашим текстом. В примере ниже будем искать то, что больше похоже на
ООО «РОМАШКА»
(подставим во второй параметр функции).
WITH company (id,c_name) AS (
VALUES (1, 'ООО РОМАШка')
UNION ALL
/* P.S. UNION ALL работает быстрее, чем UNION, т.к. отсутствует принудительная сортировка для устранения дубликатов, которая нам не требуется в данном случае */
VALUES (2, 'ООО "РОМАШКА"')
UNION ALL
VALUES (3, 'ООО РаМАШКА')
UNION ALL
VALUES (4, 'ОАО "РОМАКША"')
UNION ALL
VALUES (5, 'ЗАО РОМАШКА')
UNION ALL
VALUES (6, 'ООО РО МАШКА')
UNION ALL
VALUES (7, 'ООО РОГА И КОПЫТА')
UNION ALL
VALUES (8, 'ZAO РОМАШКА')
UNION ALL
VALUES (9, 'Как это сюда попало?')
UNION ALL
VALUES (10, 'Ромашка 33')
UNION ALL
VALUES (11, 'ИП "РомаШкович"')
UNION ALL
VALUES (12, 'ООО "Рома Шкович"')
UNION ALL
VALUES (13, 'ИП "Рома Шкович"')
)
SELECT *, similarity(c_name, 'ООО "РОМАШКА"')
,dense_rank() OVER (ORDER BY similarity(c_name, 'ООО "РОМАШКА"') DESC)
AS "Ранжирование результатов" -- оконная функций, о ней будет сказано ниже
FROM company
WHERE similarity(c_name, 'ООО "РОМАШКА"') >0.25 -- значения от 0 до 1, чем ближе к 1, тем точнее совпадение
ORDER BY similarity DESC;
Получим следующий результат:
Если возникает ошибка
«ERROR: function similarity(unknown, unknown) does not exist»
необходимо выполнить установку расширения следующей командой:
CREATE EXTENSION pg_trgm;Пример посложнее
WITH company (id,c_name) AS ( -- входная таблица с данными
VALUES (1, 'ООО РОМАШка')
,(2, 'ООО "РОМАШКА"')
,(3, 'ООО РаМАШКА')
,(4, 'ОАО "РОМАКША"')
,(5, 'ЗАО РОМАШКА')
,(6, 'ООО РО МАШКА')
,(7, 'ООО РОГА И КОПЫТА')
,(8, 'ZAO РОМАШКА')
,(9, 'Как это сюда попало?')
,(10, 'Ромашка 33')
,(11, 'ИП "РомаШкович"')
,(12, 'ООО "Рома Шкович"')
,(14, 'ИП "Рома Шкович"')
,(13, 'ООО РАГА И КАПЫТА')
),
compare (id, need) AS -- наша база для сопоставления
(VALUES (100500, 'ООО "РОМАШКА"')
,(9999, 'ООО "РОГА И КОПЫТА"')
)
SELECT c1.id, c1.c_name, 'сравниваем с ' || c2.need, similarity(c1.c_name, c2.need)
,dense_rank() OVER (PARTITION BY c2.need ORDER BY similarity(c1.c_name, c2.need) DESC)
AS "Ранжирование результатов" -- оконная функций, о ней будет сказано ниже
FROM company c1 CROSS JOIN compare c2
WHERE similarity(c_name, c2.need) >0.25 -- значения от 0 до 1, чем ближе к 1, тем точнее совпадение
ORDER BY similarity DESC;
Получим такой результат:
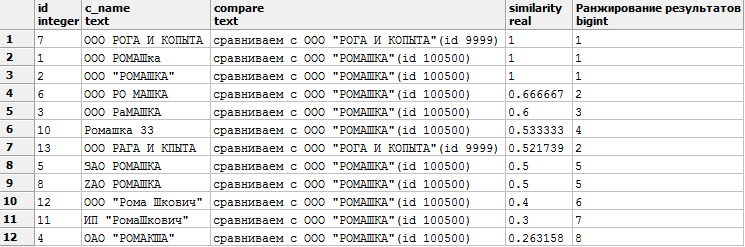
Сортируем по similarity DESC. Первыми результатами видим наиболее похожие строки (1— полное сходство).
Необязательно выводить значение similarity в SELECT, можно просто использовать его в условии WHERE similarity(c_name, ‘ООО «РОМАШКА»’) >0.7
и самим задавать устраивающий нас параметр.
P.S. Буду признателен, если подскажете какие еще есть способы сопоставления текстовых данных. Пробовал убирать регулярными выражениями все кроме букв/цифр, и сопоставлять по равенству, но такой вариант не срабатывает, если присутствуют опечатки.
9. Оконные функции OVER() (PARTITION BY __ ORDER BY __ )
Почти описав в своем черновике этот очень мощный инструмент, обнаружил
(с грустью и радостью)
, что подобная качественная статья на эту тему уже существует. Не вижу смысла дублировать информацию, поэтому рекомендую обязательно ознакомиться с данной статьей (ссылка — habrahabr.ru/post/268983/, автору низкий поклон ) тем, кто еще не умеет пользоваться оконными функциями SQL.
10. Множественный шаблон для LIKE
Задача. Необходимо отфильтровать список пользователей, имена которых должны соответствовать определенным шаблонам.
Как всегда, представлю простейший пример:
-- Создаем таблицу с данными
CREATE TEMP TABLE users_tst (id, u_name)
AS (VALUES (1::INT, NULL::VARCHAR(50))
,(2, 'Ульяна Х.')
,(3, 'Семён И.')
,(4, 'Виктория Т.')
,(5, 'Ольга С.')
,(6, 'Елизавета И.')
,(7, 'Николай Х.')
,(8, 'Исаак Р.')
,(9, 'Елисей А.')
);Имеем запрос, который выполняет свою функцию, но становится громоздким при большом количестве фильтров.
SELECT * FROM users_tst
WHERE u_name LIKE 'В%'
OR u_name LIKE '%аа%'
OR u_name LIKE 'Ульяна Х.'
OR u_name LIKE 'Елисей%'
-- и т.д.Продемонстрирую, как сделать его более компактным:
SELECT * FROM users_tst
WHERE u_name LIKE ANY (ARRAY['В%', '%аа%', 'Ульяна Х.', 'Елисей%'])
Можно проделать интересные трюки, используя подобный подход.
Напишите в комментариях, если есть мысли, как еще можно переписать исходный запрос.
11. Несколько полезных функций
NULLIF(a,b)
Возникают ситуации, когда определенное значение нужно трактовать как NULL.
Например, строки нулевой длины ( » — пустые строки) или ноль(0).
Можно написать CASE, но лаконичнее использовать функцию NULLIF, которая имеет 2 параметра, при равенстве которых возвращается NULL, иначе выводит исходное значение.
SELECT id
,param
,CASE WHEN param = 0 THEN NULL ELSE param END -- решение через CASE
,NULLIF(param,0) -- решение через NULLIF
,val
FROM(
VALUES( 1, 0, 'В столбце слева был 0' )
) AS tst (id,param,val);COALESCE выбирает первое не NULL значение
SELECT COALESCE(NULL,NULL,-20,1,NULL,-7); --выберет -20GREATEST выбирает наибольшее значение из перечисленных
SELECT GREATEST(2,1,NULL,5,7,4,-9); --выберет 7LEAST выбирает наименьшее значение из перечисленных
SELECT LEAST(2,1,NULL,5,7,4,-9); -- выберет -9 PG_TYPEOF показывает тип данных столбца
SELECT pg_typeof(id), pg_typeof(arr), pg_typeof(NULL)
FROM (VALUES ('1'::SMALLINT, array[1,2,'3',3.5])) AS x(id,arr);
-- покажет smallint, numeric[] и unknown соответственно PG_CANCEL_BACKEND останавливаем нежелательные процессы в базе
SELECT pid, query, * FROM pg_stat_activity -- таблица с процессами БД. В старых версиях postgres столбец PID назывался PROCPID
WHERE state <> 'idle' and pid <> pg_backend_pid(); -- исключаем подключения и свой только что вызванный процесс
SELECT pg_terminate_backend(PID); /* подставляем сюда PID процесса который мы хотим остановить, в отличие от нижеприведенной команды, посылает более щадящий сигнал о завершении, который не всегда может убить процесс*/
SELECT pg_cancel_backend(PID); /* подставляем сюда PID процесса который мы хотим остановить. Практически гарантированно убивает запрос, что-то вроде KILL -9 в LINUX */
Подробнее в мануале
P.S.
SELECT pg_cancel_backend(pid) FROM pg_stat_activity -- примера ради убиваем все процессы
WHERE state <> 'idle' and pid <> pg_backend_pid();
Внимание! Ни в коем случае не убивайте зависший процесс через консоль KILL -9 или диспетчер задач.
Это может привести к краху БД, потере данных и долгому автоматическому восстановлению базы.
12. Экранирование символов
Начну с основ.
В SQL строковые значения обрамляются ‘ апострофом (одинарной кавычкой).
Числовые значения можно не обрамлять апострофами, а для разделения дробной части нужно использовать точку, т.к. запятая будет воспринята как разделитель
SELECT 'Мой текст', 365, 567.6, 567,6
результат:

Все хорошо, до тех пор пока не требуется выводить сам знак апострофа ‘
Для этого существуют два способа экранирования (известных мне)
SELECT 1, 'Апостроф '' и два апострофа подряд '''' ' -- Экранирование двойным написанием ''
UNION ALL
SELECT 2, E'Апостроф ' и два апострофа подряд '' ' -- экранирование обратным слешем, , английская буква E перед первой кавычкой необходима, чтобы символ воспринимался как символ экранирования
результат одинаковый:

В PostgreSQL существуют более удобный способ использовать данные, без экранирования символов. В обрамленной двумя знаками доллара $$ строке можно использовать практически любые символы.
Пример:
select $$необязательно писать '' чтобы просто вывести апостроф ', или заморачиваться с E'' $$
получаю данные в первозданном виде:

Если этого мало, и внутри требуется использовать два символа доллара подряд $$, то Postgres позволяет задать свой «ограничитель». Стоит лишь между двумя долларами написать свой текст, например:
select $uniq_tAg$ необязательно писать '' чтобы просто вывести апостроф ', или заморачиваться с E'', обрамляйте в $$ или $any_text$ $uniq_tAg$
Увидим наш текст:

Для себя этот способ открыл не так давно, когда начал изучать написание функций.
Заключение
Надеюсь, данный материал поможет узнать много нового начинающим и «средничкам». Сам я не являюсь разработчиком, а могу лишь назвать себя любителем SQL, поэтому то, как использовать описанные приемы — решать Вам.
Желаю успехов в изучении SQL. Жду комментариев и благодарю за прочтение!
UPD. Вышло продолжение
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Была ли полезна статья?
50.61%
Да, узнал много нового
209
45.04%
Было несколько интересных моментов
186
4.36%
Ничего нового не узнал
18
Проголосовали 413 пользователей.
Воздержались 52 пользователя.
PostgreSQL — Overview
PostgreSQL is a powerful, open source object-relational database system. It has more than 15 years of active development phase and a proven architecture that has earned it a strong reputation for reliability, data integrity, and correctness.
This tutorial will give you a quick start with PostgreSQL and make you comfortable with PostgreSQL programming.
What is PostgreSQL?
PostgreSQL (pronounced as post-gress-Q-L) is an open source relational database management system (DBMS) developed by a worldwide team of volunteers. PostgreSQL is not controlled by any corporation or other private entity and the source code is available free of charge.
A Brief History of PostgreSQL
PostgreSQL, originally called Postgres, was created at UCB by a computer science professor named Michael Stonebraker. Stonebraker started Postgres in 1986 as a follow-up project to its predecessor, Ingres, now owned by Computer Associates.
-
1977-1985 − A project called INGRES was developed.
-
Proof-of-concept for relational databases
-
Established the company Ingres in 1980
-
Bought by Computer Associates in 1994
-
-
1986-1994 − POSTGRES
-
Development of the concepts in INGRES with a focus on object orientation and the query language — Quel
-
The code base of INGRES was not used as a basis for POSTGRES
-
Commercialized as Illustra (bought by Informix, bought by IBM)
-
-
1994-1995 − Postgres95
-
Support for SQL was added in 1994
-
Released as Postgres95 in 1995
-
Re-released as PostgreSQL 6.0 in 1996
-
Establishment of the PostgreSQL Global Development Team
-
Key Features of PostgreSQL
PostgreSQL runs on all major operating systems, including Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64), and Windows. It supports text, images, sounds, and video, and includes programming interfaces for C / C++, Java, Perl, Python, Ruby, Tcl and Open Database Connectivity (ODBC).
PostgreSQL supports a large part of the SQL standard and offers many modern features including the following −
- Complex SQL queries
- SQL Sub-selects
- Foreign keys
- Trigger
- Views
- Transactions
- Multiversion concurrency control (MVCC)
- Streaming Replication (as of 9.0)
- Hot Standby (as of 9.0)
You can check official documentation of PostgreSQL to understand the above-mentioned features. PostgreSQL can be extended by the user in many ways. For example by adding new −
- Data types
- Functions
- Operators
- Aggregate functions
- Index methods
Procedural Languages Support
PostgreSQL supports four standard procedural languages, which allows the users to write their own code in any of the languages and it can be executed by PostgreSQL database server. These procedural languages are — PL/pgSQL, PL/Tcl, PL/Perl and PL/Python. Besides, other non-standard procedural languages like PL/PHP, PL/V8, PL/Ruby, PL/Java, etc., are also supported.
PostgreSQL — Environment Setup
To start understanding the PostgreSQL basics, first let us install the PostgreSQL. This chapter explains about installing the PostgreSQL on Linux, Windows and Mac OS platforms.
Installing PostgreSQL on Linux/Unix
Follow the given steps to install PostgreSQL on your Linux machine. Make sure you are logged in as root before you proceed for the installation.
-
Pick the version number of PostgreSQL you want and, as exactly as possible, the platform you want from EnterpriseDB
-
I downloaded postgresql-9.2.4-1-linux-x64.run for my 64 bit CentOS-6 machine. Now, let us execute it as follows −
[root@host]# chmod +x postgresql-9.2.4-1-linux-x64.run [root@host]# ./postgresql-9.2.4-1-linux-x64.run ------------------------------------------------------------------------ Welcome to the PostgreSQL Setup Wizard. ------------------------------------------------------------------------ Please specify the directory where PostgreSQL will be installed. Installation Directory [/opt/PostgreSQL/9.2]:
-
Once you launch the installer, it asks you a few basic questions like location of the installation, password of the user who will use database, port number, etc. So keep all of them at their default values except password, which you can provide password as per your choice. It will install PostgreSQL at your Linux machine and will display the following message −
Please wait while Setup installs PostgreSQL on your computer. Installing 0% ______________ 50% ______________ 100% ######################################### ----------------------------------------------------------------------- Setup has finished installing PostgreSQL on your computer.
-
Follow the following post-installation steps to create your database −
[root@host]# su - postgres Password: bash-4.1$ createdb testdb bash-4.1$ psql testdb psql (8.4.13, server 9.2.4) test=#
-
You can start/restart postgres server in case it is not running using the following command −
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
-
If your installation was correct, you will have PotsgreSQL prompt test=# as shown above.
Installing PostgreSQL on Windows
Follow the given steps to install PostgreSQL on your Windows machine. Make sure you have turned Third Party Antivirus off while installing.
-
Pick the version number of PostgreSQL you want and, as exactly as possible, the platform you want from EnterpriseDB
-
I downloaded postgresql-9.2.4-1-windows.exe for my Windows PC running in 32bit mode, so let us run postgresql-9.2.4-1-windows.exe as administrator to install PostgreSQL. Select the location where you want to install it. By default, it is installed within Program Files folder.
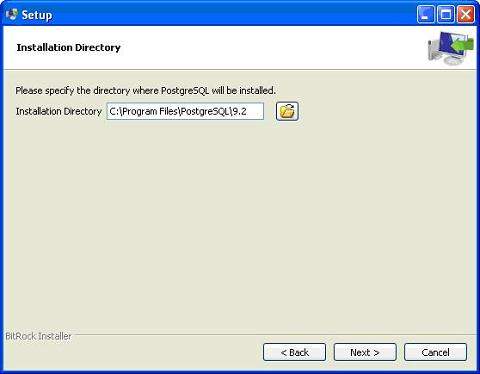
-
The next step of the installation process would be to select the directory where your data would be stored. By default, it is stored under the «data» directory.
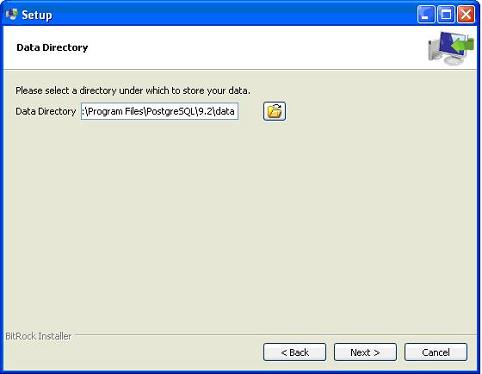
-
Next, the setup asks for password, so you can use your favorite password.
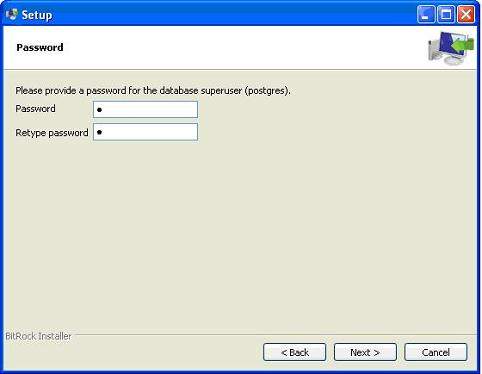
-
The next step; keep the port as default.
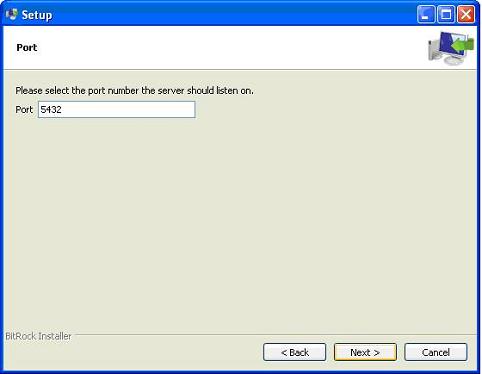
-
In the next step, when asked for «Locale», I selected «English, United States».
-
It takes a while to install PostgreSQL on your system. On completion of the installation process, you will get the following screen. Uncheck the checkbox and click the Finish button.
After the installation process is completed, you can access pgAdmin III, StackBuilder and PostgreSQL shell from your Program Menu under PostgreSQL 9.2.
Installing PostgreSQL on Mac
Follow the given steps to install PostgreSQL on your Mac machine. Make sure you are logged in as administrator before you proceed for the installation.
-
Pick the latest version number of PostgreSQL for Mac OS available at EnterpriseDB
-
I downloaded postgresql-9.2.4-1-osx.dmg for my Mac OS running with OS X version 10.8.3. Now, let us open the dmg image in finder and just double click it which will give you PostgreSQL installer in the following window −
-
Next, click the postgres-9.2.4-1-osx icon, which will give a warning message. Accept the warning and proceed for further installation. It will ask for the administrator password as seen in the following window −
Enter the password, proceed for the installation, and after this step, restart your Mac machine. If you do not see the following window, start your installation once again.

-
Once you launch the installer, it asks you a few basic questions like location of the installation, password of the user who will use database, port number etc. Therefore, keep all of them at their default values except the password, which you can provide as per your choice. It will install PostgreSQL in your Mac machine in the Application folder which you can check −
-
Now, you can launch any of the program to start with. Let us start with SQL Shell. When you launch SQL Shell, just use all the default values it displays except, enter your password, which you had selected at the time of installation. If everything goes fine, then you will be inside postgres database and a postgress# prompt will be displayed as shown below −
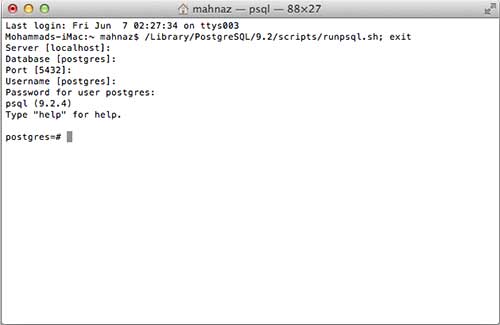
Congratulations!!! Now you have your environment ready to start with PostgreSQL database programming.
PostgreSQL — Syntax
This chapter provides a list of the PostgreSQL SQL commands, followed by the precise syntax rules for each of these commands. This set of commands is taken from the psql command-line tool. Now that you have Postgres installed, open the psql as −
Program Files → PostgreSQL 9.2 → SQL Shell(psql).
Using psql, you can generate a complete list of commands by using the help command. For the syntax of a specific command, use the following command −
postgres-# help <command_name>
The SQL Statement
An SQL statement is comprised of tokens where each token can represent either a keyword, identifier, quoted identifier, constant, or special character symbol. The table given below uses a simple SELECT statement to illustrate a basic, but complete, SQL statement and its components.
| SELECT | id, name | FROM | states | |
|---|---|---|---|---|
| Token Type | Keyword | Identifiers | Keyword | Identifier |
| Description | Command | Id and name columns | Clause | Table name |
PostgreSQL SQL commands
ABORT
Abort the current transaction.
ABORT [ WORK | TRANSACTION ]
ALTER AGGREGATE
Change the definition of an aggregate function.
ALTER AGGREGATE name ( type ) RENAME TO new_name ALTER AGGREGATE name ( type ) OWNER TO new_owner
ALTER CONVERSION
Change the definition of a conversion.
ALTER CONVERSION name RENAME TO new_name ALTER CONVERSION name OWNER TO new_owner
ALTER DATABASE
Change a database specific parameter.
ALTER DATABASE name SET parameter { TO | = } { value | DEFAULT }
ALTER DATABASE name RESET parameter
ALTER DATABASE name RENAME TO new_name
ALTER DATABASE name OWNER TO new_owner
ALTER DOMAIN
Change the definition of a domain specific parameter.
ALTER DOMAIN name { SET DEFAULT expression | DROP DEFAULT }
ALTER DOMAIN name { SET | DROP } NOT NULL
ALTER DOMAIN name ADD domain_constraint
ALTER DOMAIN name DROP CONSTRAINT constraint_name [ RESTRICT | CASCADE ]
ALTER DOMAIN name OWNER TO new_owner
ALTER FUNCTION
Change the definition of a function.
ALTER FUNCTION name ( [ type [, ...] ] ) RENAME TO new_name ALTER FUNCTION name ( [ type [, ...] ] ) OWNER TO new_owner
ALTER GROUP
Change a user group.
ALTER GROUP groupname ADD USER username [, ... ] ALTER GROUP groupname DROP USER username [, ... ] ALTER GROUP groupname RENAME TO new_name
ALTER INDEX
Change the definition of an index.
ALTER INDEX name OWNER TO new_owner ALTER INDEX name SET TABLESPACE indexspace_name ALTER INDEX name RENAME TO new_name
ALTER LANGUAGE
Change the definition of a procedural language.
ALTER LANGUAGE name RENAME TO new_name
ALTER OPERATOR
Change the definition of an operator.
ALTER OPERATOR name ( { lefttype | NONE }, { righttype | NONE } )
OWNER TO new_owner
ALTER OPERATOR CLASS
Change the definition of an operator class.
ALTER OPERATOR CLASS name USING index_method RENAME TO new_name ALTER OPERATOR CLASS name USING index_method OWNER TO new_owner
ALTER SCHEMA
Change the definition of a schema.
ALTER SCHEMA name RENAME TO new_name ALTER SCHEMA name OWNER TO new_owner
ALTER SEQUENCE
Change the definition of a sequence generator.
ALTER SEQUENCE name [ INCREMENT [ BY ] increment ] [ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ] [ RESTART [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
ALTER TABLE
Change the definition of a table.
ALTER TABLE [ ONLY ] name [ * ] action [, ... ] ALTER TABLE [ ONLY ] name [ * ] RENAME [ COLUMN ] column TO new_column ALTER TABLE name RENAME TO new_name
Where action is one of the following lines −
ADD [ COLUMN ] column_type [ column_constraint [ ... ] ]
DROP [ COLUMN ] column [ RESTRICT | CASCADE ]
ALTER [ COLUMN ] column TYPE type [ USING expression ]
ALTER [ COLUMN ] column SET DEFAULT expression
ALTER [ COLUMN ] column DROP DEFAULT
ALTER [ COLUMN ] column { SET | DROP } NOT NULL
ALTER [ COLUMN ] column SET STATISTICS integer
ALTER [ COLUMN ] column SET STORAGE { PLAIN | EXTERNAL | EXTENDED | MAIN }
ADD table_constraint
DROP CONSTRAINT constraint_name [ RESTRICT | CASCADE ]
CLUSTER ON index_name
SET WITHOUT CLUSTER
SET WITHOUT OIDS
OWNER TO new_owner
SET TABLESPACE tablespace_name
ALTER TABLESPACE
Change the definition of a tablespace.
ALTER TABLESPACE name RENAME TO new_name ALTER TABLESPACE name OWNER TO new_owner
ALTER TRIGGER
Change the definition of a trigger.
ALTER TRIGGER name ON table RENAME TO new_name
ALTER TYPE
Change the definition of a type.
ALTER TYPE name OWNER TO new_owner
ALTER USER
Change a database user account.
ALTER USER name [ [ WITH ] option [ ... ] ]
ALTER USER name RENAME TO new_name
ALTER USER name SET parameter { TO | = } { value | DEFAULT }
ALTER USER name RESET parameter
Where option can be −
[ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password' | CREATEDB | NOCREATEDB | CREATEUSER | NOCREATEUSER | VALID UNTIL 'abstime'
ANALYZE
Collect statistics about a database.
ANALYZE [ VERBOSE ] [ table [ (column [, ...] ) ] ]
BEGIN
Start a transaction block.
BEGIN [ WORK | TRANSACTION ] [ transaction_mode [, ...] ]
Where transaction_mode is one of −
ISOLATION LEVEL {
SERIALIZABLE | REPEATABLE READ | READ COMMITTED
| READ UNCOMMITTED
}
READ WRITE | READ ONLY
CHECKPOINT
Force a transaction log checkpoint.
CHECKPOINT
CLOSE
Close a cursor.
CLOSE name
CLUSTER
Cluster a table according to an index.
CLUSTER index_name ON table_name CLUSTER table_name CLUSTER
COMMENT
Define or change the comment of an object.
COMMENT ON {
TABLE object_name |
COLUMN table_name.column_name |
AGGREGATE agg_name (agg_type) |
CAST (source_type AS target_type) |
CONSTRAINT constraint_name ON table_name |
CONVERSION object_name |
DATABASE object_name |
DOMAIN object_name |
FUNCTION func_name (arg1_type, arg2_type, ...) |
INDEX object_name |
LARGE OBJECT large_object_oid |
OPERATOR op (left_operand_type, right_operand_type) |
OPERATOR CLASS object_name USING index_method |
[ PROCEDURAL ] LANGUAGE object_name |
RULE rule_name ON table_name |
SCHEMA object_name |
SEQUENCE object_name |
TRIGGER trigger_name ON table_name |
TYPE object_name |
VIEW object_name
}
IS 'text'
COMMIT
Commit the current transaction.
COMMIT [ WORK | TRANSACTION ]
COPY
Copy data between a file and a table.
COPY table_name [ ( column [, ...] ) ]
FROM { 'filename' | STDIN }
[ WITH ]
[ BINARY ]
[ OIDS ]
[ DELIMITER [ AS ] 'delimiter' ]
[ NULL [ AS ] 'null string' ]
[ CSV [ QUOTE [ AS ] 'quote' ]
[ ESCAPE [ AS ] 'escape' ]
[ FORCE NOT NULL column [, ...] ]
COPY table_name [ ( column [, ...] ) ]
TO { 'filename' | STDOUT }
[ [ WITH ]
[ BINARY ]
[ OIDS ]
[ DELIMITER [ AS ] 'delimiter' ]
[ NULL [ AS ] 'null string' ]
[ CSV [ QUOTE [ AS ] 'quote' ]
[ ESCAPE [ AS ] 'escape' ]
[ FORCE QUOTE column [, ...] ]
CREATE AGGREGATE
Define a new aggregate function.
CREATE AGGREGATE name ( BASETYPE = input_data_type, SFUNC = sfunc, STYPE = state_data_type [, FINALFUNC = ffunc ] [, INITCOND = initial_condition ] )
CREATE CAST
Define a new cast.
CREATE CAST (source_type AS target_type) WITH FUNCTION func_name (arg_types) [ AS ASSIGNMENT | AS IMPLICIT ] CREATE CAST (source_type AS target_type) WITHOUT FUNCTION [ AS ASSIGNMENT | AS IMPLICIT ]
CREATE CONSTRAINT TRIGGER
Define a new constraint trigger.
CREATE CONSTRAINT TRIGGER name AFTER events ON table_name constraint attributes FOR EACH ROW EXECUTE PROCEDURE func_name ( args )
CREATE CONVERSION
Define a new conversion.
CREATE [DEFAULT] CONVERSION name FOR source_encoding TO dest_encoding FROM func_name
CREATE DATABASE
Create a new database.
CREATE DATABASE name [ [ WITH ] [ OWNER [=] db_owner ] [ TEMPLATE [=] template ] [ ENCODING [=] encoding ] [ TABLESPACE [=] tablespace ] ]
CREATE DOMAIN
Define a new domain.
CREATE DOMAIN name [AS] data_type [ DEFAULT expression ] [ constraint [ ... ] ]
Where constraint is −
[ CONSTRAINT constraint_name ]
{ NOT NULL | NULL | CHECK (expression) }
CREATE FUNCTION
Define a new function.
CREATE [ OR REPLACE ] FUNCTION name ( [ [ arg_name ] arg_type [, ...] ] )
RETURNS ret_type
{ LANGUAGE lang_name
| IMMUTABLE | STABLE | VOLATILE
| CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT
| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
| AS 'definition'
| AS 'obj_file', 'link_symbol'
} ...
[ WITH ( attribute [, ...] ) ]
CREATE GROUP
Define a new user group.
CREATE GROUP name [ [ WITH ] option [ ... ] ] Where option can be: SYSID gid | USER username [, ...]
CREATE INDEX
Define a new index.
CREATE [ UNIQUE ] INDEX name ON table [ USING method ]
( { column | ( expression ) } [ opclass ] [, ...] )
[ TABLESPACE tablespace ]
[ WHERE predicate ]
CREATE LANGUAGE
Define a new procedural language.
CREATE [ TRUSTED ] [ PROCEDURAL ] LANGUAGE name HANDLER call_handler [ VALIDATOR val_function ]
CREATE OPERATOR
Define a new operator.
CREATE OPERATOR name ( PROCEDURE = func_name [, LEFTARG = left_type ] [, RIGHTARG = right_type ] [, COMMUTATOR = com_op ] [, NEGATOR = neg_op ] [, RESTRICT = res_proc ] [, JOIN = join_proc ] [, HASHES ] [, MERGES ] [, SORT1 = left_sort_op ] [, SORT2 = right_sort_op ] [, LTCMP = less_than_op ] [, GTCMP = greater_than_op ] )
CREATE OPERATOR CLASS
Define a new operator class.
CREATE OPERATOR CLASS name [ DEFAULT ] FOR TYPE data_type
USING index_method AS
{ OPERATOR strategy_number operator_name [ ( op_type, op_type ) ] [ RECHECK ]
| FUNCTION support_number func_name ( argument_type [, ...] )
| STORAGE storage_type
} [, ... ]
CREATE RULE
Define a new rewrite rule.
CREATE [ OR REPLACE ] RULE name AS ON event
TO table [ WHERE condition ]
DO [ ALSO | INSTEAD ] { NOTHING | command | ( command ; command ... ) }
CREATE SCHEMA
Define a new schema.
CREATE SCHEMA schema_name [ AUTHORIZATION username ] [ schema_element [ ... ] ] CREATE SCHEMA AUTHORIZATION username [ schema_element [ ... ] ]
CREATE SEQUENCE
Define a new sequence generator.
CREATE [ TEMPORARY | TEMP ] SEQUENCE name [ INCREMENT [ BY ] increment ] [ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ] [ START [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
CREATE TABLE
Define a new table.
CREATE [ [ GLOBAL | LOCAL ] {
TEMPORARY | TEMP } ] TABLE table_name ( {
column_name data_type [ DEFAULT default_expr ] [ column_constraint [ ... ] ]
| table_constraint
| LIKE parent_table [ { INCLUDING | EXCLUDING } DEFAULTS ]
} [, ... ]
)
[ INHERITS ( parent_table [, ... ] ) ]
[ WITH OIDS | WITHOUT OIDS ]
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ]
[ TABLESPACE tablespace ]
Where column_constraint is −
[ CONSTRAINT constraint_name ] {
NOT NULL |
NULL |
UNIQUE [ USING INDEX TABLESPACE tablespace ] |
PRIMARY KEY [ USING INDEX TABLESPACE tablespace ] |
CHECK (expression) |
REFERENCES ref_table [ ( ref_column ) ]
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
[ ON DELETE action ] [ ON UPDATE action ]
}
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
And table_constraint is −
[ CONSTRAINT constraint_name ]
{ UNIQUE ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] |
PRIMARY KEY ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] |
CHECK ( expression ) |
FOREIGN KEY ( column_name [, ... ] )
REFERENCES ref_table [ ( ref_column [, ... ] ) ]
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
[ ON DELETE action ] [ ON UPDATE action ] }
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
CREATE TABLE AS
Define a new table from the results of a query.
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } ] TABLE table_name
[ (column_name [, ...] ) ] [ [ WITH | WITHOUT ] OIDS ]
AS query
CREATE TABLESPACE
Define a new tablespace.
CREATE TABLESPACE tablespace_name [ OWNER username ] LOCATION 'directory'
CREATE TRIGGER
Define a new trigger.
CREATE TRIGGER name { BEFORE | AFTER } { event [ OR ... ] }
ON table [ FOR [ EACH ] { ROW | STATEMENT } ]
EXECUTE PROCEDURE func_name ( arguments )
CREATE TYPE
Define a new data type.
CREATE TYPE name AS
( attribute_name data_type [, ... ] )
CREATE TYPE name (
INPUT = input_function,
OUTPUT = output_function
[, RECEIVE = receive_function ]
[, SEND = send_function ]
[, ANALYZE = analyze_function ]
[, INTERNALLENGTH = { internal_length | VARIABLE } ]
[, PASSEDBYVALUE ]
[, ALIGNMENT = alignment ]
[, STORAGE = storage ]
[, DEFAULT = default ]
[, ELEMENT = element ]
[, DELIMITER = delimiter ]
)
CREATE USER
Define a new database user account.
CREATE USER name [ [ WITH ] option [ ... ] ]
Where option can be −
SYSID uid | [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password' | CREATEDB | NOCREATEDB | CREATEUSER | NOCREATEUSER | IN GROUP group_name [, ...] | VALID UNTIL 'abs_time'
CREATE VIEW
Define a new view.
CREATE [ OR REPLACE ] VIEW name [ ( column_name [, ...] ) ] AS query
DEALLOCATE
Deallocate a prepared statement.
DEALLOCATE [ PREPARE ] plan_name
DECLARE
Define a cursor.
DECLARE name [ BINARY ] [ INSENSITIVE ] [ [ NO ] SCROLL ]
CURSOR [ { WITH | WITHOUT } HOLD ] FOR query
[ FOR { READ ONLY | UPDATE [ OF column [, ...] ] } ]
DELETE
Delete rows of a table.
DELETE FROM [ ONLY ] table [ WHERE condition ]
DROP AGGREGATE
Remove an aggregate function.
DROP AGGREGATE name ( type ) [ CASCADE | RESTRICT ]
DROP CAST
Remove a cast.
DROP CAST (source_type AS target_type) [ CASCADE | RESTRICT ]
DROP CONVERSION
Remove a conversion.
DROP CONVERSION name [ CASCADE | RESTRICT ]
DROP DATABASE
Remove a database.
DROP DATABASE name
DROP DOMAIN
Remove a domain.
DROP DOMAIN name [, ...] [ CASCADE | RESTRICT ]
DROP FUNCTION
Remove a function.
DROP FUNCTION name ( [ type [, ...] ] ) [ CASCADE | RESTRICT ]
DROP GROUP
Remove a user group.
DROP GROUP name
DROP INDEX
Remove an index.
DROP INDEX name [, ...] [ CASCADE | RESTRICT ]
DROP LANGUAGE
Remove a procedural language.
DROP [ PROCEDURAL ] LANGUAGE name [ CASCADE | RESTRICT ]
DROP OPERATOR
Remove an operator.
DROP OPERATOR name ( { left_type | NONE }, { right_type | NONE } )
[ CASCADE | RESTRICT ]
DROP OPERATOR CLASS
Remove an operator class.
DROP OPERATOR CLASS name USING index_method [ CASCADE | RESTRICT ]
DROP RULE
Remove a rewrite rule.
DROP RULE name ON relation [ CASCADE | RESTRICT ]
DROP SCHEMA
Remove a schema.
DROP SCHEMA name [, ...] [ CASCADE | RESTRICT ]
DROP SEQUENCE
Remove a sequence.
DROP SEQUENCE name [, ...] [ CASCADE | RESTRICT ]
DROP TABLE
Remove a table.
DROP TABLE name [, ...] [ CASCADE | RESTRICT ]
DROP TABLESPACE
Remove a tablespace.
DROP TABLESPACE tablespace_name
DROP TRIGGER
Remove a trigger.
DROP TRIGGER name ON table [ CASCADE | RESTRICT ]
DROP TYPE
Remove a data type.
DROP TYPE name [, ...] [ CASCADE | RESTRICT ]
DROP USER
Remove a database user account.
DROP USER name
DROP VIEW
Remove a view.
DROP VIEW name [, ...] [ CASCADE | RESTRICT ]
END
Commit the current transaction.
END [ WORK | TRANSACTION ]
EXECUTE
Execute a prepared statement.
EXECUTE plan_name [ (parameter [, ...] ) ]
EXPLAIN
Show the execution plan of a statement.
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
FETCH
Retrieve rows from a query using a cursor.
FETCH [ direction { FROM | IN } ] cursor_name
Where direction can be empty or one of −
NEXT PRIOR FIRST LAST ABSOLUTE count RELATIVE count count ALL FORWARD FORWARD count FORWARD ALL BACKWARD BACKWARD count BACKWARD ALL
GRANT
Define access privileges.
GRANT { { SELECT | INSERT | UPDATE | DELETE | RULE | REFERENCES | TRIGGER }
[,...] | ALL [ PRIVILEGES ] }
ON [ TABLE ] table_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { { CREATE | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] }
ON DATABASE db_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { CREATE | ALL [ PRIVILEGES ] }
ON TABLESPACE tablespace_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { EXECUTE | ALL [ PRIVILEGES ] }
ON FUNCTION func_name ([type, ...]) [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { USAGE | ALL [ PRIVILEGES ] }
ON LANGUAGE lang_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { { CREATE | USAGE } [,...] | ALL [ PRIVILEGES ] }
ON SCHEMA schema_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
INSERT
Create new rows in a table.
INSERT INTO table [ ( column [, ...] ) ]
{ DEFAULT VALUES | VALUES ( { expression | DEFAULT } [, ...] ) | query }
LISTEN
Listen for a notification.
LISTEN name
LOAD
Load or reload a shared library file.
LOAD 'filename'
LOCK
Lock a table.
LOCK [ TABLE ] name [, ...] [ IN lock_mode MODE ] [ NOWAIT ]
Where lock_mode is one of −
ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE | SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE
MOVE
Position a cursor.
MOVE [ direction { FROM | IN } ] cursor_name
NOTIFY
Generate a notification.
NOTIFY name
PREPARE
Prepare a statement for execution.
PREPARE plan_name [ (data_type [, ...] ) ] AS statement
REINDEX
Rebuild indexes.
REINDEX { DATABASE | TABLE | INDEX } name [ FORCE ]
RELEASE SAVEPOINT
Destroy a previously defined savepoint.
RELEASE [ SAVEPOINT ] savepoint_name
RESET
Restore the value of a runtime parameter to the default value.
RESET name RESET ALL
REVOKE
Remove access privileges.
REVOKE [ GRANT OPTION FOR ]
{ { SELECT | INSERT | UPDATE | DELETE | RULE | REFERENCES | TRIGGER }
[,...] | ALL [ PRIVILEGES ] }
ON [ TABLE ] table_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { CREATE | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] }
ON DATABASE db_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ CREATE | ALL [ PRIVILEGES ] }
ON TABLESPACE tablespace_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ EXECUTE | ALL [ PRIVILEGES ] }
ON FUNCTION func_name ([type, ...]) [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ USAGE | ALL [ PRIVILEGES ] }
ON LANGUAGE lang_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { CREATE | USAGE } [,...] | ALL [ PRIVILEGES ] }
ON SCHEMA schema_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
ROLLBACK
Abort the current transaction.
ROLLBACK [ WORK | TRANSACTION ]
ROLLBACK TO SAVEPOINT
Roll back to a savepoint.
ROLLBACK [ WORK | TRANSACTION ] TO [ SAVEPOINT ] savepoint_name
SAVEPOINT
Define a new savepoint within the current transaction.
SAVEPOINT savepoint_name
SELECT
Retrieve rows from a table or view.
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ AS output_name ] [, ...]
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start ]
[ FOR UPDATE [ OF table_name [, ...] ] ]
Where from_item can be one of:
[ ONLY ] table_name [ * ] [ [ AS ] alias [ ( column_alias [, ...] ) ] ] ( select ) [ AS ] alias [ ( column_alias [, ...] ) ] function_name ( [ argument [, ...] ] ) [ AS ] alias [ ( column_alias [, ...] | column_definition [, ...] ) ] function_name ( [ argument [, ...] ] ) AS ( column_definition [, ...] ) from_item [ NATURAL ] join_type from_item [ ON join_condition | USING ( join_column [, ...] ) ]
SELECT INTO
Define a new table from the results of a query.
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ AS output_name ] [, ...]
INTO [ TEMPORARY | TEMP ] [ TABLE ] new_table
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start ]
[ FOR UPDATE [ OF table_name [, ...] ] ]
SET
Change a runtime parameter.
SET [ SESSION | LOCAL ] name { TO | = } { value | 'value' | DEFAULT }
SET [ SESSION | LOCAL ] TIME ZONE { time_zone | LOCAL | DEFAULT }
SET CONSTRAINTS
Set constraint checking modes for the current transaction.
SET CONSTRAINTS { ALL | name [, ...] } { DEFERRED | IMMEDIATE }
SET SESSION AUTHORIZATION
Set the session user identifier and the current user identifier of the current session.
SET [ SESSION | LOCAL ] SESSION AUTHORIZATION username SET [ SESSION | LOCAL ] SESSION AUTHORIZATION DEFAULT RESET SESSION AUTHORIZATION
SET TRANSACTION
Set the characteristics of the current transaction.
SET TRANSACTION transaction_mode [, ...] SET SESSION CHARACTERISTICS AS TRANSACTION transaction_mode [, ...]
Where transaction_mode is one of −
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED
| READ UNCOMMITTED }
READ WRITE | READ ONLY
SHOW
Show the value of a runtime parameter.
SHOW name SHOW ALL
START TRANSACTION
Start a transaction block.
START TRANSACTION [ transaction_mode [, ...] ]
Where transaction_mode is one of −
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED
| READ UNCOMMITTED }
READ WRITE | READ ONLY
TRUNCATE
Empty a table.
TRUNCATE [ TABLE ] name
UNLISTEN
Stop listening for a notification.
UNLISTEN { name | * }
UPDATE
Update rows of a table.
UPDATE [ ONLY ] table SET column = { expression | DEFAULT } [, ...]
[ FROM from_list ]
[ WHERE condition ]
VACUUM
Garbage-collect and optionally analyze a database.
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ table ] VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] ANALYZE [ table [ (column [, ...] ) ] ]
PostgreSQL — Data Type
In this chapter, we will discuss about the data types used in PostgreSQL. While creating table, for each column, you specify a data type, i.e., what kind of data you want to store in the table fields.
This enables several benefits −
-
Consistency − Operations against columns of same data type give consistent results and are usually the fastest.
-
Validation − Proper use of data types implies format validation of data and rejection of data outside the scope of data type.
-
Compactness − As a column can store a single type of value, it is stored in a compact way.
-
Performance − Proper use of data types gives the most efficient storage of data. The values stored can be processed quickly, which enhances the performance.
PostgreSQL supports a wide set of Data Types. Besides, users can create their own custom data type using CREATE TYPE SQL command. There are different categories of data types in PostgreSQL. They are discussed below.
Numeric Types
Numeric types consist of two-byte, four-byte, and eight-byte integers, four-byte and eight-byte floating-point numbers, and selectable-precision decimals. The following table lists the available types.
| Name | Storage Size | Description | Range |
|---|---|---|---|
| smallint | 2 bytes | small-range integer | -32768 to +32767 |
| integer | 4 bytes | typical choice for integer | -2147483648 to +2147483647 |
| bigint | 8 bytes | large-range integer | -9223372036854775808 to 9223372036854775807 |
| decimal | variable | user-specified precision,exact | up to 131072 digits before the decimal point; up to 16383 digits after the decimal point |
| numeric | variable | user-specified precision,exact | up to 131072 digits before the decimal point; up to 16383 digits after the decimal point |
| real | 4 bytes | variable-precision,inexact | 6 decimal digits precision |
| double precision | 8 bytes | variable-precision,inexact | 15 decimal digits precision |
| smallserial | 2 bytes | small autoincrementing integer | 1 to 32767 |
| serial | 4 bytes | autoincrementing integer | 1 to 2147483647 |
| bigserial | 8 bytes | large autoincrementing integer | 1 to 9223372036854775807 |
Monetary Types
The money type stores a currency amount with a fixed fractional precision. Values of the numeric, int, and bigint data types can be cast to money. Using Floating point numbers is not recommended to handle money due to the potential for rounding errors.
| Name | Storage Size | Description | Range |
|---|---|---|---|
| money | 8 bytes | currency amount | -92233720368547758.08 to +92233720368547758.07 |
Character Types
The table given below lists the general-purpose character types available in PostgreSQL.
| S. No. | Name & Description |
|---|---|
| 1 |
character varying(n), varchar(n) variable-length with limit |
| 2 |
character(n), char(n) fixed-length, blank padded |
| 3 |
text variable unlimited length |
Binary Data Types
The bytea data type allows storage of binary strings as in the table given below.
| Name | Storage Size | Description |
|---|---|---|
| bytea | 1 or 4 bytes plus the actual binary string | variable-length binary string |
Date/Time Types
PostgreSQL supports a full set of SQL date and time types, as shown in table below. Dates are counted according to the Gregorian calendar. Here, all the types have resolution of 1 microsecond / 14 digits except date type, whose resolution is day.
| Name | Storage Size | Description | Low Value | High Value |
|---|---|---|---|---|
| timestamp [(p)] [without time zone ] | 8 bytes | both date and time (no time zone) | 4713 BC | 294276 AD |
| TIMESTAMPTZ | 8 bytes | both date and time, with time zone | 4713 BC | 294276 AD |
| date | 4 bytes | date (no time of day) | 4713 BC | 5874897 AD |
| time [ (p)] [ without time zone ] | 8 bytes | time of day (no date) | 00:00:00 | 24:00:00 |
| time [ (p)] with time zone | 12 bytes | times of day only, with time zone | 00:00:00+1459 | 24:00:00-1459 |
| interval [fields ] [(p) ] | 12 bytes | time interval | -178000000 years | 178000000 years |
Boolean Type
PostgreSQL provides the standard SQL type Boolean. The Boolean data type can have the states true, false, and a third state, unknown, which is represented by the SQL null value.
| Name | Storage Size | Description |
|---|---|---|
| boolean | 1 byte | state of true or false |
Enumerated Type
Enumerated (enum) types are data types that comprise a static, ordered set of values. They are equivalent to the enum types supported in a number of programming languages.
Unlike other types, Enumerated Types need to be created using CREATE TYPE command. This type is used to store a static, ordered set of values. For example compass directions, i.e., NORTH, SOUTH, EAST, and WEST or days of the week as shown below −
CREATE TYPE week AS ENUM ('Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun');
Enumerated, once created, can be used like any other types.
Geometric Type
Geometric data types represent two-dimensional spatial objects. The most fundamental type, the point, forms the basis for all of the other types.
| Name | Storage Size | Representation | Description |
|---|---|---|---|
| point | 16 bytes | Point on a plane | (x,y) |
| line | 32 bytes | Infinite line (not fully implemented) | ((x1,y1),(x2,y2)) |
| lseg | 32 bytes | Finite line segment | ((x1,y1),(x2,y2)) |
| box | 32 bytes | Rectangular box | ((x1,y1),(x2,y2)) |
| path | 16+16n bytes | Closed path (similar to polygon) | ((x1,y1),…) |
| path | 16+16n bytes | Open path | [(x1,y1),…] |
| polygon | 40+16n | Polygon (similar to closed path) | ((x1,y1),…) |
| circle | 24 bytes | Circle | <(x,y),r> (center point and radius) |
Network Address Type
PostgreSQL offers data types to store IPv4, IPv6, and MAC addresses. It is better to use these types instead of plain text types to store network addresses, because these types offer input error checking and specialized operators and functions.
| Name | Storage Size | Description |
|---|---|---|
| cidr | 7 or 19 bytes | IPv4 and IPv6 networks |
| inet | 7 or 19 bytes | IPv4 and IPv6 hosts and networks |
| macaddr | 6 bytes | MAC addresses |
Bit String Type
Bit String Types are used to store bit masks. They are either 0 or 1. There are two SQL bit types: bit(n) and bit varying(n), where n is a positive integer.
Text Search Type
This type supports full text search, which is the activity of searching through a collection of natural-language documents to locate those that best match a query. There are two Data Types for this −
| S. No. | Name & Description |
|---|---|
| 1 |
tsvector This is a sorted list of distinct words that have been normalized to merge different variants of the same word, called as «lexemes». |
| 2 |
tsquery This stores lexemes that are to be searched for, and combines them honoring the Boolean operators & (AND), | (OR), and ! (NOT). Parentheses can be used to enforce grouping of the operators. |
UUID Type
A UUID (Universally Unique Identifiers) is written as a sequence of lower-case hexadecimal digits, in several groups separated by hyphens, specifically a group of eight digits, followed by three groups of four digits, followed by a group of 12 digits, for a total of 32 digits representing the 128 bits.
An example of a UUID is − 550e8400-e29b-41d4-a716-446655440000
XML Type
The XML data type can be used to store XML data. For storing XML data, first you have to create XML values using the function xmlparse as follows −
XMLPARSE (DOCUMENT '<?xml version="1.0"?> <tutorial> <title>PostgreSQL Tutorial </title> <topics>...</topics> </tutorial>') XMLPARSE (CONTENT 'xyz<foo>bar</foo><bar>foo</bar>')
JSON Type
The json data type can be used to store JSON (JavaScript Object Notation) data. Such data can also be stored as text, but the json data type has the advantage of checking that each stored value is a valid JSON value. There are also related support functions available, which can be used directly to handle JSON data type as follows.
| Example | Example Result |
|---|---|
| array_to_json(‘{{1,5},{99,100}}’::int[]) | [[1,5],[99,100]] |
| row_to_json(row(1,’foo’)) | {«f1″:1,»f2″:»foo»} |
Array Type
PostgreSQL gives the opportunity to define a column of a table as a variable length multidimensional array. Arrays of any built-in or user-defined base type, enum type, or composite type can be created.
Declaration of Arrays
Array type can be declared as
CREATE TABLE monthly_savings ( name text, saving_per_quarter integer[], scheme text[][] );
or by using the keyword «ARRAY» as
CREATE TABLE monthly_savings ( name text, saving_per_quarter integer ARRAY[4], scheme text[][] );
Inserting values
Array values can be inserted as a literal constant, enclosing the element values within curly braces and separating them by commas. An example is shown below −
INSERT INTO monthly_savings
VALUES (‘Manisha’,
‘{20000, 14600, 23500, 13250}’,
‘{{“FD”, “MF”}, {“FD”, “Property”}}’);
Accessing Arrays
An example for accessing Arrays is shown below. The command given below will select the persons whose savings are more in second quarter than fourth quarter.
SELECT name FROM monhly_savings WHERE saving_per_quarter[2] > saving_per_quarter[4];
Modifying Arrays
An example of modifying arrays is as shown below.
UPDATE monthly_savings SET saving_per_quarter = '{25000,25000,27000,27000}'
WHERE name = 'Manisha';
or using the ARRAY expression syntax −
UPDATE monthly_savings SET saving_per_quarter = ARRAY[25000,25000,27000,27000] WHERE name = 'Manisha';
Searching Arrays
An example of searching arrays is as shown below.
SELECT * FROM monthly_savings WHERE saving_per_quarter[1] = 10000 OR saving_per_quarter[2] = 10000 OR saving_per_quarter[3] = 10000 OR saving_per_quarter[4] = 10000;
If the size of array is known, the search method given above can be used. Else, the following example shows how to search when the size is not known.
SELECT * FROM monthly_savings WHERE 10000 = ANY (saving_per_quarter);
Composite Types
This type represents a list of field names and their data types, i.e., structure of a row or record of a table.
Declaration of Composite Types
The following example shows how to declare a composite type
CREATE TYPE inventory_item AS ( name text, supplier_id integer, price numeric );
This data type can be used in the create tables as below −
CREATE TABLE on_hand ( item inventory_item, count integer );
Composite Value Input
Composite values can be inserted as a literal constant, enclosing the field values within parentheses and separating them by commas. An example is shown below −
INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
This is valid for the inventory_item defined above. The ROW keyword is actually optional as long as you have more than one field in the expression.
Accessing Composite Types
To access a field of a composite column, use a dot followed by the field name, much like selecting a field from a table name. For example, to select some subfields from our on_hand example table, the query would be as shown below −
SELECT (item).name FROM on_hand WHERE (item).price > 9.99;
You can even use the table name as well (for instance in a multitable query), like this −
SELECT (on_hand.item).name FROM on_hand WHERE (on_hand.item).price > 9.99;
Range Types
Range types represent data types that uses a range of data. Range type can be discrete ranges (e.g., all integer values 1 to 10) or continuous ranges (e.g., any point in time between 10:00am and 11:00am).
The built-in range types available include the following ranges −
-
int4range − Range of integer
-
int8range − Range of bigint
-
numrange − Range of numeric
-
tsrange − Range of timestamp without time zone
-
tstzrange − Range of timestamp with time zone
-
daterange − Range of date
Custom range types can be created to make new types of ranges available, such as IP address ranges using the inet type as a base, or float ranges using the float data type as a base.
Range types support inclusive and exclusive range boundaries using the [ ] and ( ) characters, respectively. For example ‘[4,9)’ represents all the integers starting from and including 4 up to but not including 9.
Object Identifier Types
Object identifiers (OIDs) are used internally by PostgreSQL as primary keys for various system tables. If WITH OIDS is specified or default_with_oids configuration variable is enabled, only then, in such cases OIDs are added to user-created tables. The following table lists several alias types. The OID alias types have no operations of their own except for specialized input and output routines.
| Name | References | Description | Value Example |
|---|---|---|---|
| oid | any | numeric object identifier | 564182 |
| regproc | pg_proc | function name | sum |
| regprocedure | pg_proc | function with argument types | sum(int4) |
| regoper | pg_operator | operator name | + |
| regoperator | pg_operator | operator with argument types | *(integer,integer) or -(NONE,integer) |
| regclass | pg_class | relation name | pg_type |
| regtype | pg_type | data type name | integer |
| regconfig | pg_ts_config | text search configuration | English |
| regdictionary | pg_ts_dict | text search dictionary | simple |
Pseudo Types
The PostgreSQL type system contains a number of special-purpose entries that are collectively called pseudo-types. A pseudo-type cannot be used as a column data type, but it can be used to declare a function’s argument or result type.
The table given below lists the existing pseudo-types.
| S. No. | Name & Description |
|---|---|
| 1 |
any Indicates that a function accepts any input data type. |
| 2 |
anyelement Indicates that a function accepts any data type. |
| 3 |
anyarray Indicates that a function accepts any array data type. |
| 4 |
anynonarray Indicates that a function accepts any non-array data type. |
| 5 |
anyenum Indicates that a function accepts any enum data type. |
| 6 |
anyrange Indicates that a function accepts any range data type. |
| 7 |
cstring Indicates that a function accepts or returns a null-terminated C string. |
| 8 |
internal Indicates that a function accepts or returns a server-internal data type. |
| 9 |
language_handler A procedural language call handler is declared to return language_handler. |
| 10 |
fdw_handler A foreign-data wrapper handler is declared to return fdw_handler. |
| 11 |
record Identifies a function returning an unspecified row type. |
| 12 |
trigger A trigger function is declared to return trigger. |
| 13 |
void Indicates that a function returns no value. |
PostgreSQL — CREATE Database
This chapter discusses about how to create a new database in your PostgreSQL. PostgreSQL provides two ways of creating a new database −
- Using CREATE DATABASE, an SQL command.
- Using createdb a command-line executable.
Using CREATE DATABASE
This command will create a database from PostgreSQL shell prompt, but you should have appropriate privilege to create a database. By default, the new database will be created by cloning the standard system database template1.
Syntax
The basic syntax of CREATE DATABASE statement is as follows −
CREATE DATABASE dbname;
where dbname is the name of a database to create.
Example
The following is a simple example, which will create testdb in your PostgreSQL schema
postgres=# CREATE DATABASE testdb; postgres-#
Using createdb Command
PostgreSQL command line executable createdb is a wrapper around the SQL command CREATE DATABASE. The only difference between this command and SQL command CREATE DATABASE is that the former can be directly run from the command line and it allows a comment to be added into the database, all in one command.
Syntax
The syntax for createdb is as shown below −
createdb [option...] [dbname [description]]
Parameters
The table given below lists the parameters with their descriptions.
| S. No. | Parameter & Description |
|---|---|
| 1 |
dbname The name of a database to create. |
| 2 |
description Specifies a comment to be associated with the newly created database. |
| 3 |
options command-line arguments, which createdb accepts. |
Options
The following table lists the command line arguments createdb accepts −
| S. No. | Option & Description |
|---|---|
| 1 |
-D tablespace Specifies the default tablespace for the database. |
| 2 |
-e Echo the commands that createdb generates and sends to the server. |
| 3 |
-E encoding Specifies the character encoding scheme to be used in this database. |
| 4 |
-l locale Specifies the locale to be used in this database. |
| 5 |
-T template Specifies the template database from which to build this database. |
| 6 |
—help Show help about createdb command line arguments, and exit. |
| 7 |
-h host Specifies the host name of the machine on which the server is running. |
| 8 |
-p port Specifies the TCP port or the local Unix domain socket file extension on which the server is listening for connections. |
| 9 |
-U username User name to connect as. |
| 10 |
-w Never issue a password prompt. |
| 11 |
-W Force createdb to prompt for a password before connecting to a database. |
Open the command prompt and go to the directory where PostgreSQL is installed. Go to the bin directory and execute the following command to create a database.
createdb -h localhost -p 5432 -U postgres testdb password ******
The above given command will prompt you for password of the PostgreSQL admin user, which is postgres, by default. Hence, provide a password and proceed to create your new database
Once a database is created using either of the above-mentioned methods, you can check it in the list of databases using l, i.e., backslash el command as follows −
postgres-# l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+---------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
testdb | postgres | UTF8 | C | C |
(4 rows)
postgres-#
PostgreSQL — SELECT Database
This chapter explains various methods of accessing the database. Assume that we have already created a database in our previous chapter. You can select the database using either of the following methods −
- Database SQL Prompt
- OS Command Prompt
Database SQL Prompt
Assume you have already launched your PostgreSQL client and you have landed at the following SQL prompt −
postgres=#
You can check the available database list using l, i.e., backslash el command as follows −
postgres-# l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+---------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
testdb | postgres | UTF8 | C | C |
(4 rows)
postgres-#
Now, type the following command to connect/select a desired database; here, we will connect to the testdb database.
postgres=# c testdb; psql (9.2.4) Type "help" for help. You are now connected to database "testdb" as user "postgres". testdb=#
OS Command Prompt
You can select your database from the command prompt itself at the time when you login to your database. Following is a simple example −
psql -h localhost -p 5432 -U postgress testdb Password for user postgress: **** psql (9.2.4) Type "help" for help. You are now connected to database "testdb" as user "postgres". testdb=#
You are now logged into PostgreSQL testdb and ready to execute your commands inside testdb. To exit from the database, you can use the command q.
PostgreSQL — DROP Database
In this chapter, we will discuss how to delete the database in PostgreSQL. There are two options to delete a database −
- Using DROP DATABASE, an SQL command.
- Using dropdb a command-line executable.
Be careful before using this operation because deleting an existing database would result in loss of complete information stored in the database.
Using DROP DATABASE
This command drops a database. It removes the catalog entries for the database and deletes the directory containing the data. It can only be executed by the database owner. This command cannot be executed while you or anyone else is connected to the target database (connect to postgres or any other database to issue this command).
Syntax
The syntax for DROP DATABASE is given below −
DROP DATABASE [ IF EXISTS ] name
Parameters
The table lists the parameters with their descriptions.
| S. No. | Parameter & Description |
|---|---|
| 1 |
IF EXISTS Do not throw an error if the database does not exist. A notice is issued in this case. |
| 2 |
name The name of the database to remove. |
We cannot drop a database that has any open connections, including our own connection from psql or pgAdmin III. We must switch to another database or template1 if we want to delete the database we are currently connected to. Thus, it might be more convenient to use the program dropdb instead, which is a wrapper around this command.
Example
The following is a simple example, which will delete testdb from your PostgreSQL schema −
postgres=# DROP DATABASE testdb; postgres-#
Using dropdb Command
PostgresSQL command line executable dropdb is a command-line wrapper around the SQL command DROP DATABASE. There is no effective difference between dropping databases via this utility and via other methods for accessing the server. dropdb destroys an existing PostgreSQL database. The user, who executes this command must be a database super user or the owner of the database.
Syntax
The syntax for dropdb is as shown below −
dropdb [option...] dbname
Parameters
The following table lists the parameters with their descriptions
| S. No. | Parameter & Description |
|---|---|
| 1 |
dbname The name of a database to be deleted. |
| 2 |
option command-line arguments, which dropdb accepts. |
Options
The following table lists the command-line arguments dropdb accepts −
| S. No. | Option & Description |
|---|---|
| 1 |
-e Shows the commands being sent to the server. |
| 2 |
-i Issues a verification prompt before doing anything destructive. |
| 3 |
-V Print the dropdb version and exit. |
| 4 |
—if-exists Do not throw an error if the database does not exist. A notice is issued in this case. |
| 5 |
—help Show help about dropdb command-line arguments, and exit. |
| 6 |
-h host Specifies the host name of the machine on which the server is running. |
| 7 |
-p port Specifies the TCP port or the local UNIX domain socket file extension on which the server is listening for connections. |
| 8 |
-U username User name to connect as. |
| 9 |
-w Never issue a password prompt. |
| 10 |
-W Force dropdb to prompt for a password before connecting to a database. |
| 11 |
—maintenance-db=dbname Specifies the name of the database to connect to in order to drop the target database. |
Example
The following example demonstrates deleting a database from OS command prompt −
dropdb -h localhost -p 5432 -U postgress testdb Password for user postgress: ****
The above command drops the database testdb. Here, I have used the postgres (found under the pg_roles of template1) username to drop the database.
PostgreSQL — CREATE Table
The PostgreSQL CREATE TABLE statement is used to create a new table in any of the given database.
Syntax
Basic syntax of CREATE TABLE statement is as follows −
CREATE TABLE table_name( column1 datatype, column2 datatype, column3 datatype, ..... columnN datatype, PRIMARY KEY( one or more columns ) );
CREATE TABLE is a keyword, telling the database system to create a new table. The unique name or identifier for the table follows the CREATE TABLE statement. Initially, the empty table in the current database is owned by the user issuing the command.
Then, in brackets, comes the list, defining each column in the table and what sort of data type it is. The syntax will become clear with an example given below.
Examples
The following is an example, which creates a COMPANY table with ID as primary key and NOT NULL are the constraints showing that these fields cannot be NULL while creating records in this table −
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
Let us create one more table, which we will use in our exercises in subsequent chapters −
CREATE TABLE DEPARTMENT( ID INT PRIMARY KEY NOT NULL, DEPT CHAR(50) NOT NULL, EMP_ID INT NOT NULL );
You can verify if your table has been created successfully using d command, which will be used to list down all the tables in an attached database.
testdb-# d
The above given PostgreSQL statement will produce the following result −
List of relations Schema | Name | Type | Owner --------+------------+-------+---------- public | company | table | postgres public | department | table | postgres (2 rows)
Use d tablename to describe each table as shown below −
testdb-# d company
The above given PostgreSQL statement will produce the following result −
Table "public.company"
Column | Type | Modifiers
-----------+---------------+-----------
id | integer | not null
name | text | not null
age | integer | not null
address | character(50) |
salary | real |
join_date | date |
Indexes:
"company_pkey" PRIMARY KEY, btree (id)
PostgreSQL — DROP Table
The PostgreSQL DROP TABLE statement is used to remove a table definition and all associated data, indexes, rules, triggers, and constraints for that table.
You have to be careful while using this command because once a table is deleted then all the information available in the table would also be lost forever.
Syntax
Basic syntax of DROP TABLE statement is as follows −
DROP TABLE table_name;
Example
We had created the tables DEPARTMENT and COMPANY in the previous chapter. First, verify these tables (use d to list the tables) −
testdb-# d
This would produce the following result −
List of relations Schema | Name | Type | Owner --------+------------+-------+---------- public | company | table | postgres public | department | table | postgres (2 rows)
This means DEPARTMENT and COMPANY tables are present. So let us drop them as follows −
testdb=# drop table department, company;
This would produce the following result −
DROP TABLE testdb=# d relations found. testdb=#
The message returned DROP TABLE indicates that drop command is executed successfully.
PostgreSQL — Schema
A schema is a named collection of tables. A schema can also contain views, indexes, sequences, data types, operators, and functions. Schemas are analogous to directories at the operating system level, except that schemas cannot be nested. PostgreSQL statement CREATE SCHEMA creates a schema.
Syntax
The basic syntax of CREATE SCHEMA is as follows −
CREATE SCHEMA name;
Where name is the name of the schema.
Syntax to Create Table in Schema
The basic syntax to create table in schema is as follows −
CREATE TABLE myschema.mytable ( ... );
Example
Let us see an example for creating a schema. Connect to the database testdb and create a schema myschema as follows −
testdb=# create schema myschema; CREATE SCHEMA
The message «CREATE SCHEMA» signifies that the schema is created successfully.
Now, let us create a table in the above schema as follows −
testdb=# create table myschema.company( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
This will create an empty table. You can verify the table created with the command given below −
testdb=# select * from myschema.company;
This would produce the following result −
id | name | age | address | salary ----+------+-----+---------+-------- (0 rows)
Syntax to Drop Schema
To drop a schema if it is empty (all objects in it have been dropped), use the command −
DROP SCHEMA myschema;
To drop a schema including all contained objects, use the command −
DROP SCHEMA myschema CASCADE;
Advantages of using a Schema
-
It allows many users to use one database without interfering with each other.
-
It organizes database objects into logical groups to make them more manageable.
-
Third-party applications can be put into separate schemas so they do not collide with the names of other objects.
PostgreSQL — INSERT Query
The PostgreSQL INSERT INTO statement allows one to insert new rows into a table. One can insert a single row at a time or several rows as a result of a query.
Syntax
Basic syntax of INSERT INTO statement is as follows −
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN) VALUES (value1, value2, value3,...valueN);
-
Here, column1, column2,…columnN are the names of the columns in the table into which you want to insert data.
-
The target column names can be listed in any order. The values supplied by the VALUES clause or query are associated with the explicit or implicit column list left-to-right.
You may not need to specify the column(s) name in the SQL query if you are adding values for all the columns of the table. However, make sure the order of the values is in the same order as the columns in the table. The SQL INSERT INTO syntax would be as follows −
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);
Output
The following table summarizes the output messages and their meaning −
| S. No. | Output Message & Description |
|---|---|
| 1 |
INSERT oid 1 Message returned if only one row was inserted. oid is the numeric OID of the inserted row. |
| 2 |
INSERT 0 # Message returned if more than one rows were inserted. # is the number of rows inserted. |
Examples
Let us create COMPANY table in testdb as follows −
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL, JOIN_DATE DATE );
The following example inserts a row into the COMPANY table −
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (1, 'Paul', 32, 'California', 20000.00,'2001-07-13');
The following example is to insert a row; here salary column is omitted and therefore it will have the default value −
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,JOIN_DATE) VALUES (2, 'Allen', 25, 'Texas', '2007-12-13');
The following example uses the DEFAULT clause for the JOIN_DATE column rather than specifying a value −
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (3, 'Teddy', 23, 'Norway', 20000.00, DEFAULT );
The following example inserts multiple rows using the multirow VALUES syntax −
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00, '2007-12-13' ), (5, 'David', 27, 'Texas', 85000.00, '2007-12-13');
All the above statements would create the following records in COMPANY table. The next chapter will teach you how to display all these records from a table.
ID NAME AGE ADDRESS SALARY JOIN_DATE ---- ---------- ----- ---------- ------- -------- 1 Paul 32 California 20000.0 2001-07-13 2 Allen 25 Texas 2007-12-13 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 2007-12-13 5 David 27 Texas 85000.0 2007-12-13
PostgreSQL — SELECT Query
PostgreSQL SELECT statement is used to fetch the data from a database table, which returns data in the form of result table. These result tables are called result-sets.
Syntax
The basic syntax of SELECT statement is as follows −
SELECT column1, column2, columnN FROM table_name;
Here, column1, column2…are the fields of a table, whose values you want to fetch. If you want to fetch all the fields available in the field then you can use the following syntax −
SELECT * FROM table_name;
Example
Consider the table COMPANY having records as follows −
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
The following is an example, which would fetch ID, Name and Salary fields of the customers available in CUSTOMERS table −
testdb=# SELECT ID, NAME, SALARY FROM COMPANY ;
This would produce the following result −
id | name | salary ----+-------+-------- 1 | Paul | 20000 2 | Allen | 15000 3 | Teddy | 20000 4 | Mark | 65000 5 | David | 85000 6 | Kim | 45000 7 | James | 10000 (7 rows)
If you want to fetch all the fields of CUSTOMERS table, then use the following query −
testdb=# SELECT * FROM COMPANY;
This would produce the following result −
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
PostgreSQL — Operators
What is an Operator in PostgreSQL?
An operator is a reserved word or a character used primarily in a PostgreSQL statement’s WHERE clause to perform operation(s), such as comparisons and arithmetic operations.
Operators are used to specify conditions in a PostgreSQL statement and to serve as conjunctions for multiple conditions in a statement.
- Arithmetic operators
- Comparison operators
- Logical operators
- Bitwise operators
PostgreSQL Arithmetic Operators
Assume variable a holds 2 and variable b holds 3, then −
Example
| Operator | Description | Example |
|---|---|---|
| + | Addition — Adds values on either side of the operator | a + b will give 5 |
| — | Subtraction — Subtracts right hand operand from left hand operand | a — b will give -1 |
| * | Multiplication — Multiplies values on either side of the operator | a * b will give 6 |
| / | Division — Divides left hand operand by right hand operand | b / a will give 1 |
| % | Modulus — Divides left hand operand by right hand operand and returns remainder | b % a will give 1 |
| ^ | Exponentiation — This gives the exponent value of the right hand operand | a ^ b will give 8 |
| |/ | square root | |/ 25.0 will give 5 |
| ||/ | Cube root | ||/ 27.0 will give 3 |
| ! | factorial | 5 ! will give 120 |
| !! | factorial (prefix operator) | !! 5 will give 120 |
PostgreSQL Comparison Operators
Assume variable a holds 10 and variable b holds 20, then −
Show Examples
| Operator | Description | Example |
|---|---|---|
| = | Checks if the values of two operands are equal or not, if yes then condition becomes true. | (a = b) is not true. |
| != | Checks if the values of two operands are equal or not, if values are not equal then condition becomes true. | (a != b) is true. |
| <> | Checks if the values of two operands are equal or not, if values are not equal then condition becomes true. | (a <> b) is true. |
| > | Checks if the value of left operand is greater than the value of right operand, if yes then condition becomes true. | (a > b) is not true. |
| < | Checks if the value of left operand is less than the value of right operand, if yes then condition becomes true. | (a < b) is true. |
| >= | Checks if the value of left operand is greater than or equal to the value of right operand, if yes then condition becomes true. | (a >= b) is not true. |
| <= | Checks if the value of left operand is less than or equal to the value of right operand, if yes then condition becomes true. | (a <= b) is true. |
PostgreSQL Logical Operators
Here is a list of all the logical operators available in PostgresSQL.
Show Examples
| S. No. | Operator & Description |
|---|---|
| 1 |
AND The AND operator allows the existence of multiple conditions in a PostgresSQL statement’s WHERE clause. |
| 2 |
NOT The NOT operator reverses the meaning of the logical operator with which it is used. Eg. NOT EXISTS, NOT BETWEEN, NOT IN etc. This is negate operator. |
| 3 |
OR The OR operator is used to combine multiple conditions in a PostgresSQL statement’s WHERE clause. |
PostgreSQL Bit String Operators
Bitwise operator works on bits and performs bit-by-bit operation. The truth table for & and | is as follows −
| p | q | p & q | p | q |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 |
Assume if A = 60; and B = 13; now in binary format they will be as follows −
A = 0011 1100
B = 0000 1101
——————
A&B = 0000 1100
A|B = 0011 1101
~A = 1100 0011
Show Examples
The Bitwise operators supported by PostgreSQL are listed in the following table −
| Operator | Description | Example |
|---|---|---|
| & | Binary AND Operator copies a bit to the result if it exists in both operands. | (A & B) will give 12 which is 0000 1100 |
| | | Binary OR Operator copies a bit if it exists in either operand. | (A | B) will give 61 which is 0011 1101 |
| ~ | Binary Ones Complement Operator is unary and has the effect of ‘flipping’ bits. | (~A ) will give -61 which is 1100 0011 in 2’s complement form due to a signed binary number. |
| << | Binary Left Shift Operator. The left operands value is moved left by the number of bits specified by the right operand. | A << 2 will give 240 which is 1111 0000 |
| >> | Binary Right Shift Operator. The left operands value is moved right by the number of bits specified by the right operand. | A >> 2 will give 15 which is 0000 1111 |
| # | bitwise XOR. | A # B will give 49 which is 00110001 |
PostgreSQL — Expressions
An expression is a combination of one or more values, operators, and PostgresSQL functions that evaluate to a value.
PostgreSQL EXPRESSIONS are like formulas and they are written in query language. You can also use to query the database for specific set of data.
Syntax
Consider the basic syntax of the SELECT statement as follows −
SELECT column1, column2, columnN FROM table_name WHERE [CONDITION | EXPRESSION];
There are different types of PostgreSQL expressions, which are mentioned below −
PostgreSQL — Boolean Expressions
PostgreSQL Boolean Expressions fetch the data on the basis of matching single value. Following is the syntax −
SELECT column1, column2, columnN FROM table_name WHERE SINGLE VALUE MATCHTING EXPRESSION;
Consider the table COMPANY having records as follows −
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Here is the simple example showing usage of PostgreSQL Boolean Expressions −
testdb=# SELECT * FROM COMPANY WHERE SALARY = 10000;
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+-------+-----+----------+-------- 7 | James | 24 | Houston | 10000 (1 row)
PostgreSQL — Numeric Expression
These expressions are used to perform any mathematical operation in any query. Following is the syntax −
SELECT numerical_expression as OPERATION_NAME [FROM table_name WHERE CONDITION] ;
Here numerical_expression is used for mathematical expression or any formula. Following is a simple example showing usage of SQL Numeric Expressions −
testdb=# SELECT (15 + 6) AS ADDITION ;
The above given PostgreSQL statement will produce the following result −
addition
----------
21
(1 row)
There are several built-in functions like avg(), sum(), count() to perform what is known as aggregate data calculations against a table or a specific table column.
testdb=# SELECT COUNT(*) AS "RECORDS" FROM COMPANY;
The above given PostgreSQL statement will produce the following result −
RECORDS
---------
7
(1 row)
PostgreSQL — Date Expressions
Date Expressions return the current system date and time values and these expressions are used in various data manipulations.
testdb=# SELECT CURRENT_TIMESTAMP;
The above given PostgreSQL statement will produce the following result −
now ------------------------------- 2013-05-06 14:38:28.078+05:30 (1 row)
PostgreSQL — WHERE Clause
The PostgreSQL WHERE clause is used to specify a condition while fetching the data from single table or joining with multiple tables.
If the given condition is satisfied, only then it returns specific value from the table. You can filter out rows that you do not want included in the result-set by using the WHERE clause.
The WHERE clause not only is used in SELECT statement, but it is also used in UPDATE, DELETE statement, etc., which we would examine in subsequent chapters.
Syntax
The basic syntax of SELECT statement with WHERE clause is as follows −
SELECT column1, column2, columnN FROM table_name WHERE [search_condition]
You can specify a search_condition using comparison or logical operators. like >, <, =, LIKE, NOT, etc. The following examples would make this concept clear.
Example
Consider the table COMPANY having records as follows −
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Here are simple examples showing usage of PostgreSQL Logical Operators. Following SELECT statement will list down all the records where AGE is greater than or equal to 25 AND salary is greater than or equal to 65000.00 −
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+-------+-----+------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (2 rows)
The following SELECT statement lists down all the records where AGE is greater than or equal to 25 OR salary is greater than or equal to 65000.00 −
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (4 rows)
The following SELECT statement lists down all the records where AGE is not NULL which means all the records, because none of the record has AGE equal to NULL −
testdb=# SELECT * FROM COMPANY WHERE AGE IS NOT NULL;
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (7 rows)
The following SELECT statement lists down all the records where NAME starts with ‘Pa’, does not matter what comes after ‘Pa’.
testdb=# SELECT * FROM COMPANY WHERE NAME LIKE 'Pa%';
The above given PostgreSQL statement will produce the following result −
id | name | age |address | salary ----+------+-----+-----------+-------- 1 | Paul | 32 | California| 20000
The following SELECT statement lists down all the records where AGE value is either 25 or 27 −
testdb=# SELECT * FROM COMPANY WHERE AGE IN ( 25, 27 );
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+-------+-----+------------+-------- 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (3 rows)
The following SELECT statement lists down all the records where AGE value is neither 25 nor 27 −
testdb=# SELECT * FROM COMPANY WHERE AGE NOT IN ( 25, 27 );
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 3 | Teddy | 23 | Norway | 20000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (4 rows)
The following SELECT statement lists down all the records where AGE value is in BETWEEN 25 AND 27 −
testdb=# SELECT * FROM COMPANY WHERE AGE BETWEEN 25 AND 27;
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+-------+-----+------------+-------- 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (3 rows)
The following SELECT statement makes use of SQL subquery where subquery finds all the records with AGE field having SALARY > 65000 and later WHERE clause is being used along with EXISTS operator to list down all the records where AGE from the outside query exists in the result returned by sub-query −
testdb=# SELECT AGE FROM COMPANY
WHERE EXISTS (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
The above given PostgreSQL statement will produce the following result −
age ----- 32 25 23 25 27 22 24 (7 rows)
The following SELECT statement makes use of SQL subquery where subquery finds all the records with AGE field having SALARY > 65000 and later WHERE clause is being used along with > operator to list down all the records where AGE from outside query is greater than the age in the result returned by sub-query −
testdb=# SELECT * FROM COMPANY
WHERE AGE > (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+------+-----+------------+-------- 1 | Paul | 32 | California | 20000
AND and OR Conjunctive Operators
The PostgreSQL AND and OR operators are used to combine multiple conditions to narrow down selected data in a PostgreSQL statement. These two operators are called conjunctive operators.
These operators provide a means to make multiple comparisons with different operators in the same PostgreSQL statement.
The AND Operator
The AND operator allows the existence of multiple conditions in a PostgreSQL statement’s WHERE clause. While using AND operator, complete condition will be assumed true when all the conditions are true. For example [condition1] AND [condition2] will be true only when both condition1 and condition2 are true.
Syntax
The basic syntax of AND operator with WHERE clause is as follows −
SELECT column1, column2, columnN FROM table_name WHERE [condition1] AND [condition2]...AND [conditionN];
You can combine N number of conditions using AND operator. For an action to be taken by the PostgreSQL statement, whether it be a transaction or query, all conditions separated by the AND must be TRUE.
Example
Consider the table COMPANY having records as follows −
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
The following SELECT statement lists down all the records where AGE is greater than or equal to 25 AND salary is greater than or equal to 65000.00 −
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+-------+-----+------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (2 rows)
The OR Operator
The OR operator is also used to combine multiple conditions in a PostgreSQL statement’s WHERE clause. While using OR operator, complete condition will be assumed true when at least any of the conditions is true. For example [condition1] OR [condition2] will be true if either condition1 or condition2 is true.
Syntax
The basic syntax of OR operator with WHERE clause is as follows −
SELECT column1, column2, columnN FROM table_name WHERE [condition1] OR [condition2]...OR [conditionN]
You can combine N number of conditions using OR operator. For an action to be taken by the PostgreSQL statement, whether it be a transaction or query, only any ONE of the conditions separated by the OR must be TRUE.
Example
Consider the COMPANY table, having the following records −
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
The following SELECT statement lists down all the records where AGE is greater than or equal to 25 OR salary is greater than or equal to 65000.00 −
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (4 rows)
PostgreSQL — UPDATE Query
The PostgreSQL UPDATE Query is used to modify the existing records in a table. You can use WHERE clause with UPDATE query to update the selected rows. Otherwise, all the rows would be updated.
Syntax
The basic syntax of UPDATE query with WHERE clause is as follows −
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
You can combine N number of conditions using AND or OR operators.
Example
Consider the table COMPANY, having records as follows −
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
The following is an example, which would update ADDRESS for a customer, whose ID is 6 −
testdb=# UPDATE COMPANY SET SALARY = 15000 WHERE ID = 3;
Now, COMPANY table would have the following records −
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 3 | Teddy | 23 | Norway | 15000 (7 rows)
If you want to modify all ADDRESS and SALARY column values in COMPANY table, you do not need to use WHERE clause and UPDATE query would be as follows −
testdb=# UPDATE COMPANY SET ADDRESS = 'Texas', SALARY=20000;
Now, COMPANY table will have the following records −
id | name | age | address | salary ----+-------+-----+---------+-------- 1 | Paul | 32 | Texas | 20000 2 | Allen | 25 | Texas | 20000 4 | Mark | 25 | Texas | 20000 5 | David | 27 | Texas | 20000 6 | Kim | 22 | Texas | 20000 7 | James | 24 | Texas | 20000 3 | Teddy | 23 | Texas | 20000 (7 rows)
PostgreSQL — DELETE Query
The PostgreSQL DELETE Query is used to delete the existing records from a table. You can use WHERE clause with DELETE query to delete the selected rows. Otherwise, all the records would be deleted.
Syntax
The basic syntax of DELETE query with WHERE clause is as follows −
DELETE FROM table_name WHERE [condition];
You can combine N number of conditions using AND or OR operators.
Example
Consider the table COMPANY, having records as follows −
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
The following is an example, which would DELETE a customer whose ID is 7 −
testdb=# DELETE FROM COMPANY WHERE ID = 2;
Now, COMPANY table will have the following records −
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (6 rows)
If you want to DELETE all the records from COMPANY table, you do not need to use WHERE clause with DELETE queries, which would be as follows −
testdb=# DELETE FROM COMPANY;
Now, COMPANY table does not have any record because all the records have been deleted by the DELETE statement.
PostgreSQL — LIKE Clause
The PostgreSQL LIKE operator is used to match text values against a pattern using wildcards. If the search expression can be matched to the pattern expression, the LIKE operator will return true, which is 1.
There are two wildcards used in conjunction with the LIKE operator −
- The percent sign (%)
- The underscore (_)
The percent sign represents zero, one, or multiple numbers or characters. The underscore represents a single number or character. These symbols can be used in combinations.
If either of these two signs is not used in conjunction with the LIKE clause, then the LIKE acts like the equals operator.
Syntax
The basic syntax of % and _ is as follows −
SELECT FROM table_name WHERE column LIKE 'XXXX%' or SELECT FROM table_name WHERE column LIKE '%XXXX%' or SELECT FROM table_name WHERE column LIKE 'XXXX_' or SELECT FROM table_name WHERE column LIKE '_XXXX' or SELECT FROM table_name WHERE column LIKE '_XXXX_'
You can combine N number of conditions using AND or OR operators. Here XXXX could be any numeric or string value.
Example
Here are number of examples showing WHERE part having different LIKE clause with ‘%’ and ‘_’ operators −
| S. No. | Statement & Description |
|---|---|
| 1 |
WHERE SALARY::text LIKE ‘200%’ Finds any values that start with 200 |
| 2 |
WHERE SALARY::text LIKE ‘%200%’ Finds any values that have 200 in any position |
| 3 |
WHERE SALARY::text LIKE ‘_00%’ Finds any values that have 00 in the second and third positions |
| 4 |
WHERE SALARY::text LIKE ‘2_%_%’ Finds any values that start with 2 and are at least 3 characters in length |
| 5 |
WHERE SALARY::text LIKE ‘%2’ Finds any values that end with 2 |
| 6 |
WHERE SALARY::text LIKE ‘_2%3’ Finds any values that have 2 in the second position and end with a 3 |
| 7 |
WHERE SALARY::text LIKE ‘2___3’ Finds any values in a five-digit number that start with 2 and end with 3 |
Postgres LIKE is String compare only. Hence, we need to explicitly cast the integer column to string as in the examples above.
Let us take a real example, consider the table COMPANY, having records as follows −
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
The following is an example, which would display all the records from COMPANY table where AGE starts with 2 −
testdb=# SELECT * FROM COMPANY WHERE AGE::text LIKE '2%';
This would produce the following result −
id | name | age | address | salary ----+-------+-----+-------------+-------- 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 (7 rows)
The following is an example, which would display all the records from COMPANY table where ADDRESS will have a hyphen (-) inside the text −
testdb=# SELECT * FROM COMPANY WHERE ADDRESS LIKE '%-%';
This would produce the following result −
id | name | age | address | salary ----+------+-----+-------------------------------------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 (2 rows)
PostgreSQL — LIMIT Clause
The PostgreSQL LIMIT clause is used to limit the data amount returned by the SELECT statement.
Syntax
The basic syntax of SELECT statement with LIMIT clause is as follows −
SELECT column1, column2, columnN FROM table_name LIMIT [no of rows]
The following is the syntax of LIMIT clause when it is used along with OFFSET clause −
SELECT column1, column2, columnN FROM table_name LIMIT [no of rows] OFFSET [row num]
LIMIT and OFFSET allow you to retrieve just a portion of the rows that are generated by the rest of the query.
Example
Consider the table COMPANY having records as follows −
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
The following is an example, which limits the row in the table according to the number of rows you want to fetch from table −
testdb=# SELECT * FROM COMPANY LIMIT 4;
This would produce the following result −
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 (4 rows)
However, in certain situation, you may need to pick up a set of records from a particular offset. Here is an example, which picks up three records starting from the third position −
testdb=# SELECT * FROM COMPANY LIMIT 3 OFFSET 2;
This would produce the following result −
id | name | age | address | salary ----+-------+-----+-----------+-------- 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (3 rows)
PostgreSQL — ORDER BY Clause
The PostgreSQL ORDER BY clause is used to sort the data in ascending or descending order, based on one or more columns.
Syntax
The basic syntax of ORDER BY clause is as follows −
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC];
You can use more than one column in the ORDER BY clause. Make sure whatever column you are using to sort, that column should be available in column-list.
Example
Consider the table COMPANY having records as follows −
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
The following is an example, which would sort the result in ascending order by SALARY −
testdb=# SELECT * FROM COMPANY ORDER BY AGE ASC;
This would produce the following result −
id | name | age | address | salary ----+-------+-----+------------+-------- 6 | Kim | 22 | South-Hall | 45000 3 | Teddy | 23 | Norway | 20000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 4 | Mark | 25 | Rich-Mond | 65000 2 | Allen | 25 | Texas | 15000 5 | David | 27 | Texas | 85000 1 | Paul | 32 | California | 20000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 (10 rows)
The following is an example, which would sort the result in ascending order by NAME and SALARY −
testdb=# SELECT * FROM COMPANY ORDER BY NAME, SALARY ASC;
This would produce the following result −
id | name | age | address | salary ----+-------+-----+--------------+-------- 2 | Allen | 25 | Texas | 15000 5 | David | 27 | Texas | 85000 10 | James | 45 | Texas | 5000 9 | James | 44 | Norway | 5000 7 | James | 24 | Houston | 10000 6 | Kim | 22 | South-Hall | 45000 4 | Mark | 25 | Rich-Mond | 65000 1 | Paul | 32 | California | 20000 8 | Paul | 24 | Houston | 20000 3 | Teddy | 23 | Norway | 20000 (10 rows)
The following is an example, which would sort the result in descending order by NAME −
testdb=# SELECT * FROM COMPANY ORDER BY NAME DESC;
This would produce the following result −
id | name | age | address | salary ----+-------+-----+------------+-------- 3 | Teddy | 23 | Norway | 20000 1 | Paul | 32 | California | 20000 8 | Paul | 24 | Houston | 20000 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 5 | David | 27 | Texas | 85000 2 | Allen | 25 | Texas | 15000 (10 rows)
PostgreSQL — GROUP BY
The PostgreSQL GROUP BY clause is used in collaboration with the SELECT statement to group together those rows in a table that have identical data. This is done to eliminate redundancy in the output and/or compute aggregates that apply to these groups.
The GROUP BY clause follows the WHERE clause in a SELECT statement and precedes the ORDER BY clause.
Syntax
The basic syntax of GROUP BY clause is given below. The GROUP BY clause must follow the conditions in the WHERE clause and must precede the ORDER BY clause if one is used.
SELECT column-list FROM table_name WHERE [ conditions ] GROUP BY column1, column2....columnN ORDER BY column1, column2....columnN
You can use more than one column in the GROUP BY clause. Make sure whatever column you are using to group, that column should be available in column-list.
Example
Consider the table COMPANY having records as follows −
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
If you want to know the total amount of salary of each customer, then GROUP BY query would be as follows −
testdb=# SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME;
This would produce the following result −
name | sum -------+------- Teddy | 20000 Paul | 20000 Mark | 65000 David | 85000 Allen | 15000 Kim | 45000 James | 10000 (7 rows)
Now, let us create three more records in COMPANY table using the following INSERT statements −
INSERT INTO COMPANY VALUES (8, 'Paul', 24, 'Houston', 20000.00); INSERT INTO COMPANY VALUES (9, 'James', 44, 'Norway', 5000.00); INSERT INTO COMPANY VALUES (10, 'James', 45, 'Texas', 5000.00);
Now, our table has the following records with duplicate names −
id | name | age | address | salary ----+-------+-----+--------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 (10 rows)
Again, let us use the same statement to group-by all the records using NAME column as follows −
testdb=# SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME ORDER BY NAME;
This would produce the following result −
name | sum -------+------- Allen | 15000 David | 85000 James | 20000 Kim | 45000 Mark | 65000 Paul | 40000 Teddy | 20000 (7 rows)
Let us use ORDER BY clause along with GROUP BY clause as follows −
testdb=# SELECT NAME, SUM(SALARY)
FROM COMPANY GROUP BY NAME ORDER BY NAME DESC;
This would produce the following result −
name | sum -------+------- Teddy | 20000 Paul | 40000 Mark | 65000 Kim | 45000 James | 20000 David | 85000 Allen | 15000 (7 rows)
PostgreSQL — WITH Clause
In PostgreSQL, the WITH query provides a way to write auxiliary statements for use in a larger query. It helps in breaking down complicated and large queries into simpler forms, which are easily readable. These statements often referred to as Common Table Expressions or CTEs, can be thought of as defining temporary tables that exist just for one query.
The WITH query being CTE query, is particularly useful when subquery is executed multiple times. It is equally helpful in place of temporary tables. It computes the aggregation once and allows us to reference it by its name (may be multiple times) in the queries.
The WITH clause must be defined before it is used in the query.
Syntax
The basic syntax of WITH query is as follows −
WITH
name_for_summary_data AS (
SELECT Statement)
SELECT columns
FROM name_for_summary_data
WHERE conditions <=> (
SELECT column
FROM name_for_summary_data)
[ORDER BY columns]
Where name_for_summary_data is the name given to the WITH clause. The name_for_summary_data can be the same as an existing table name and will take precedence.
You can use data-modifying statements (INSERT, UPDATE or DELETE) in WITH. This allows you to perform several different operations in the same query.
Recursive WITH
Recursive WITH or Hierarchical queries, is a form of CTE where a CTE can reference to itself, i.e., a WITH query can refer to its own output, hence the name recursive.
Example
Consider the table COMPANY having records as follows −
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Now, let us write a query using the WITH clause to select the records from the above table, as follows −
With CTE AS (Select ID , NAME , AGE , ADDRESS , SALARY FROM COMPANY ) Select * From CTE;
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Now, let us write a query using the RECURSIVE keyword along with the WITH clause, to find the sum of the salaries less than 20000, as follows −
WITH RECURSIVE t(n) AS ( VALUES (0) UNION ALL SELECT SALARY FROM COMPANY WHERE SALARY < 20000 ) SELECT sum(n) FROM t;
The above given PostgreSQL statement will produce the following result −
sum ------- 25000 (1 row)
Let us write a query using data modifying statements along with the WITH clause, as shown below.
First, create a table COMPANY1 similar to the table COMPANY. The query in the example effectively moves rows from COMPANY to COMPANY1. The DELETE in WITH deletes the specified rows from COMPANY, returning their contents by means of its RETURNING clause; and then the primary query reads that output and inserts it into COMPANY1 TABLE −
CREATE TABLE COMPANY1(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
WITH moved_rows AS (
DELETE FROM COMPANY
WHERE
SALARY >= 30000
RETURNING *
)
INSERT INTO COMPANY1 (SELECT * FROM moved_rows);
The above given PostgreSQL statement will produce the following result −
INSERT 0 3
Now, the records in the tables COMPANY and COMPANY1 are as follows −
testdb=# SELECT * FROM COMPANY; id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 7 | James | 24 | Houston | 10000 (4 rows) testdb=# SELECT * FROM COMPANY1; id | name | age | address | salary ----+-------+-----+-------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 (3 rows)
PostgreSQL — HAVING Clause
The HAVING clause allows us to pick out particular rows where the function’s result meets some condition.
The WHERE clause places conditions on the selected columns, whereas the HAVING clause places conditions on groups created by the GROUP BY clause.
Syntax
The following is the position of the HAVING clause in a SELECT query −
SELECT FROM WHERE GROUP BY HAVING ORDER BY
The HAVING clause must follow the GROUP BY clause in a query and must also precede the ORDER BY clause if used. The following is the syntax of the SELECT statement, including the HAVING clause −
SELECT column1, column2 FROM table1, table2 WHERE [ conditions ] GROUP BY column1, column2 HAVING [ conditions ] ORDER BY column1, column2
Example
Consider the table COMPANY having records as follows −
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
The following is an example, which would display record for which the name count is less than 2 −
testdb-# SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) < 2;
This would produce the following result −
name ------- Teddy Paul Mark David Allen Kim James (7 rows)
Now, let us create three more records in COMPANY table using the following INSERT statements −
INSERT INTO COMPANY VALUES (8, 'Paul', 24, 'Houston', 20000.00); INSERT INTO COMPANY VALUES (9, 'James', 44, 'Norway', 5000.00); INSERT INTO COMPANY VALUES (10, 'James', 45, 'Texas', 5000.00);
Now, our table has the following records with duplicate names −
id | name | age | address | salary ----+-------+-----+--------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 (10 rows)
The following is the example, which would display record for which the name count is greater than 1 −
testdb-# SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) > 1;
This would produce the following result −
name ------- Paul James (2 rows)
PostgreSQL — DISTINCT Keyword
The PostgreSQL DISTINCT keyword is used in conjunction with SELECT statement to eliminate all the duplicate records and fetching only unique records.
There may be a situation when you have multiple duplicate records in a table. While fetching such records, it makes more sense to fetch only unique records instead of fetching duplicate records.
Syntax
The basic syntax of DISTINCT keyword to eliminate duplicate records is as follows −
SELECT DISTINCT column1, column2,.....columnN FROM table_name WHERE [condition]
Example
Consider the table COMPANY having records as follows −
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Let us add two more records to this table as follows −
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (8, 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (9, 'Allen', 25, 'Texas', 15000.00 );
Now, the records in the COMPANY table would be −
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 32 | California | 20000 9 | Allen | 25 | Texas | 15000 (9 rows)
First, let us see how the following SELECT query returns duplicate salary records −
testdb=# SELECT name FROM COMPANY;
This would produce the following result −
name ------- Paul Allen Teddy Mark David Kim James Paul Allen (9 rows)
Now, let us use DISTINCT keyword with the above SELECT query and see the result −
testdb=# SELECT DISTINCT name FROM COMPANY;
This would produce the following result where we do not have any duplicate entry −
name ------- Teddy Paul Mark David Allen Kim James (7 rows)
PostgreSQL — CONSTRAINTS
Constraints are the rules enforced on data columns on table. These are used to prevent invalid data from being entered into the database. This ensures the accuracy and reliability of the data in the database.
Constraints could be column level or table level. Column level constraints are applied only to one column whereas table level constraints are applied to the whole table. Defining a data type for a column is a constraint in itself. For example, a column of type DATE constrains the column to valid dates.
The following are commonly used constraints available in PostgreSQL.
-
NOT NULL Constraint − Ensures that a column cannot have NULL value.
-
UNIQUE Constraint − Ensures that all values in a column are different.
-
PRIMARY Key − Uniquely identifies each row/record in a database table.
-
FOREIGN Key − Constrains data based on columns in other tables.
-
CHECK Constraint − The CHECK constraint ensures that all values in a column satisfy certain conditions.
-
EXCLUSION Constraint − The EXCLUDE constraint ensures that if any two rows are compared on the specified column(s) or expression(s) using the specified operator(s), not all of these comparisons will return TRUE.
NOT NULL Constraint
By default, a column can hold NULL values. If you do not want a column to have a NULL value, then you need to define such constraint on this column specifying that NULL is now not allowed for that column. A NOT NULL constraint is always written as a column constraint.
A NULL is not the same as no data; rather, it represents unknown data.
Example
For example, the following PostgreSQL statement creates a new table called COMPANY1 and adds five columns, three of which, ID and NAME and AGE, specify not to accept NULL values −
CREATE TABLE COMPANY1( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
UNIQUE Constraint
The UNIQUE Constraint prevents two records from having identical values in a particular column. In the COMPANY table, for example, you might want to prevent two or more people from having identical age.
Example
For example, the following PostgreSQL statement creates a new table called COMPANY3 and adds five columns. Here, AGE column is set to UNIQUE, so that you cannot have two records with same age −
CREATE TABLE COMPANY3( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL UNIQUE, ADDRESS CHAR(50), SALARY REAL DEFAULT 50000.00 );
PRIMARY KEY Constraint
The PRIMARY KEY constraint uniquely identifies each record in a database table. There can be more UNIQUE columns, but only one primary key in a table. Primary keys are important when designing the database tables. Primary keys are unique ids.
We use them to refer to table rows. Primary keys become foreign keys in other tables, when creating relations among tables. Due to a ‘longstanding coding oversight’, primary keys can be NULL in SQLite. This is not the case with other databases
A primary key is a field in a table, which uniquely identifies each row/record in a database table. Primary keys must contain unique values. A primary key column cannot have NULL values.
A table can have only one primary key, which may consist of single or multiple fields. When multiple fields are used as a primary key, they are called a composite key.
If a table has a primary key defined on any field(s), then you cannot have two records having the same value of that field(s).
Example
You already have seen various examples above where we have created COMAPNY4 table with ID as primary key −
CREATE TABLE COMPANY4( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
FOREIGN KEY Constraint
A foreign key constraint specifies that the values in a column (or a group of columns) must match the values appearing in some row of another table. We say this maintains the referential integrity between two related tables. They are called foreign keys because the constraints are foreign; that is, outside the table. Foreign keys are sometimes called a referencing key.
Example
For example, the following PostgreSQL statement creates a new table called COMPANY5 and adds five columns.
CREATE TABLE COMPANY6( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
For example, the following PostgreSQL statement creates a new table called DEPARTMENT1, which adds three columns. The column EMP_ID is the foreign key and references the ID field of the table COMPANY6.
CREATE TABLE DEPARTMENT1( ID INT PRIMARY KEY NOT NULL, DEPT CHAR(50) NOT NULL, EMP_ID INT references COMPANY6(ID) );
CHECK Constraint
The CHECK Constraint enables a condition to check the value being entered into a record. If the condition evaluates to false, the record violates the constraint and is not entered into the table.
Example
For example, the following PostgreSQL statement creates a new table called COMPANY5 and adds five columns. Here, we add a CHECK with SALARY column, so that you cannot have any SALARY as Zero.
CREATE TABLE COMPANY5( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL CHECK(SALARY > 0) );
EXCLUSION Constraint
Exclusion constraints ensure that if any two rows are compared on the specified columns or expressions using the specified operators, at least one of these operator comparisons will return false or null.
Example
For example, the following PostgreSQL statement creates a new table called COMPANY7 and adds five columns. Here, we add an EXCLUDE constraint −
CREATE TABLE COMPANY7( ID INT PRIMARY KEY NOT NULL, NAME TEXT, AGE INT , ADDRESS CHAR(50), SALARY REAL, EXCLUDE USING gist (NAME WITH =, AGE WITH <>) );
Here, USING gist is the type of index to build and use for enforcement.
You need to execute the command CREATE EXTENSION btree_gist, once per database. This will install the btree_gist extension, which defines the exclusion constraints on plain scalar data types.
As we have enforced the age has to be same, let us see this by inserting records to the table −
INSERT INTO COMPANY7 VALUES(1, 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY7 VALUES(2, 'Paul', 32, 'Texas', 20000.00 ); INSERT INTO COMPANY7 VALUES(3, 'Paul', 42, 'California', 20000.00 );
For the first two INSERT statements, the records are added to the COMPANY7 table. For the third INSERT statement, the following error is displayed −
ERROR: conflicting key value violates exclusion constraint "company7_name_age_excl" DETAIL: Key (name, age)=(Paul, 42) conflicts with existing key (name, age)=(Paul, 32).
Dropping Constraints
To remove a constraint you need to know its name. If the name is known, it is easy to drop. Else, you need to find out the system-generated name. The psql command d table name can be helpful here. The general syntax is −
ALTER TABLE table_name DROP CONSTRAINT some_name;
PostgreSQL — JOINS
The PostgreSQL Joins clause is used to combine records from two or more tables in a database. A JOIN is a means for combining fields from two tables by using values common to each.
Join Types in PostgreSQL are −
- The CROSS JOIN
- The INNER JOIN
- The LEFT OUTER JOIN
- The RIGHT OUTER JOIN
- The FULL OUTER JOIN
Before we proceed, let us consider two tables, COMPANY and DEPARTMENT. We already have seen INSERT statements to populate COMPANY table. So just let us assume the list of records available in COMPANY table −
id | name | age | address | salary | join_date ----+-------+-----+-----------+--------+----------- 1 | Paul | 32 | California| 20000 | 2001-07-13 3 | Teddy | 23 | Norway | 20000 | 4 | Mark | 25 | Rich-Mond | 65000 | 2007-12-13 5 | David | 27 | Texas | 85000 | 2007-12-13 2 | Allen | 25 | Texas | | 2007-12-13 8 | Paul | 24 | Houston | 20000 | 2005-07-13 9 | James | 44 | Norway | 5000 | 2005-07-13 10 | James | 45 | Texas | 5000 | 2005-07-13
Another table is DEPARTMENT, has the following definition −
CREATE TABLE DEPARTMENT( ID INT PRIMARY KEY NOT NULL, DEPT CHAR(50) NOT NULL, EMP_ID INT NOT NULL );
Here is the list of INSERT statements to populate DEPARTMENT table −
INSERT INTO DEPARTMENT (ID, DEPT, EMP_ID) VALUES (1, 'IT Billing', 1 ); INSERT INTO DEPARTMENT (ID, DEPT, EMP_ID) VALUES (2, 'Engineering', 2 ); INSERT INTO DEPARTMENT (ID, DEPT, EMP_ID) VALUES (3, 'Finance', 7 );
Finally, we have the following list of records available in DEPARTMENT table −
id | dept | emp_id ----+-------------+-------- 1 | IT Billing | 1 2 | Engineering | 2 3 | Finance | 7
The CROSS JOIN
A CROSS JOIN matches every row of the first table with every row of the second table. If the input tables have x and y columns, respectively, the resulting table will have x+y columns. Because CROSS JOINs have the potential to generate extremely large tables, care must be taken to use them only when appropriate.
The following is the syntax of CROSS JOIN −
SELECT ... FROM table1 CROSS JOIN table2 ...
Based on the above tables, we can write a CROSS JOIN as follows −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY CROSS JOIN DEPARTMENT;
The above given query will produce the following result −
emp_id| name | dept
------|-------|--------------
1 | Paul | IT Billing
1 | Teddy | IT Billing
1 | Mark | IT Billing
1 | David | IT Billing
1 | Allen | IT Billing
1 | Paul | IT Billing
1 | James | IT Billing
1 | James | IT Billing
2 | Paul | Engineering
2 | Teddy | Engineering
2 | Mark | Engineering
2 | David | Engineering
2 | Allen | Engineering
2 | Paul | Engineering
2 | James | Engineering
2 | James | Engineering
7 | Paul | Finance
7 | Teddy | Finance
7 | Mark | Finance
7 | David | Finance
7 | Allen | Finance
7 | Paul | Finance
7 | James | Finance
7 | James | Finance
The INNER JOIN
A INNER JOIN creates a new result table by combining column values of two tables (table1 and table2) based upon the join-predicate. The query compares each row of table1 with each row of table2 to find all pairs of rows, which satisfy the join-predicate. When the join-predicate is satisfied, column values for each matched pair of rows of table1 and table2 are combined into a result row.
An INNER JOIN is the most common type of join and is the default type of join. You can use INNER keyword optionally.
The following is the syntax of INNER JOIN −
SELECT table1.column1, table2.column2... FROM table1 INNER JOIN table2 ON table1.common_filed = table2.common_field;
Based on the above tables, we can write an INNER JOIN as follows −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;
The above given query will produce the following result −
emp_id | name | dept
--------+-------+------------
1 | Paul | IT Billing
2 | Allen | Engineering
The LEFT OUTER JOIN
The OUTER JOIN is an extension of the INNER JOIN. SQL standard defines three types of OUTER JOINs: LEFT, RIGHT, and FULL and PostgreSQL supports all of these.
In case of LEFT OUTER JOIN, an inner join is performed first. Then, for each row in table T1 that does not satisfy the join condition with any row in table T2, a joined row is added with null values in columns of T2. Thus, the joined table always has at least one row for each row in T1.
The following is the syntax of LEFT OUTER JOIN −
SELECT ... FROM table1 LEFT OUTER JOIN table2 ON conditional_expression ...
Based on the above tables, we can write an inner join as follows −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
The above given query will produce the following result −
emp_id | name | dept
--------+-------+------------
1 | Paul | IT Billing
2 | Allen | Engineering
| James |
| David |
| Paul |
| Mark |
| Teddy |
| James |
The RIGHT OUTER JOIN
First, an inner join is performed. Then, for each row in table T2 that does not satisfy the join condition with any row in table T1, a joined row is added with null values in columns of T1. This is the converse of a left join; the result table will always have a row for each row in T2.
The following is the syntax of RIGHT OUTER JOIN −
SELECT ... FROM table1 RIGHT OUTER JOIN table2 ON conditional_expression ...
Based on the above tables, we can write an inner join as follows −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY RIGHT OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
The above given query will produce the following result −
emp_id | name | dept
--------+-------+--------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | | Finance
The FULL OUTER JOIN
First, an inner join is performed. Then, for each row in table T1 that does not satisfy the join condition with any row in table T2, a joined row is added with null values in columns of T2. In addition, for each row of T2 that does not satisfy the join condition with any row in T1, a joined row with null values in the columns of T1 is added.
The following is the syntax of FULL OUTER JOIN −
SELECT ... FROM table1 FULL OUTER JOIN table2 ON conditional_expression ...
Based on the above tables, we can write an inner join as follows −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY FULL OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
The above given query will produce the following result −
emp_id | name | dept
--------+-------+---------------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | | Finance
| James |
| David |
| Paul |
| Mark |
| Teddy |
| James |
PostgreSQL — UNIONS Clause
The PostgreSQL UNION clause/operator is used to combine the results of two or more SELECT statements without returning any duplicate rows.
To use UNION, each SELECT must have the same number of columns selected, the same number of column expressions, the same data type, and have them in the same order but they do not have to be the same length.
Syntax
The basic syntax of UNION is as follows −
SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition] UNION SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition]
Here, given condition could be any given expression based on your requirement.
Example
Consider the following two tables, (a) COMPANY table is as follows −
testdb=# SELECT * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
(b) Another table is DEPARTMENT as follows −
testdb=# SELECT * from DEPARTMENT; id | dept | emp_id ----+-------------+-------- 1 | IT Billing | 1 2 | Engineering | 2 3 | Finance | 7 4 | Engineering | 3 5 | Finance | 4 6 | Engineering | 5 7 | Finance | 6 (7 rows)
Now let us join these two tables using SELECT statement along with UNION clause as follows −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID
UNION
SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;
This would produce the following result −
emp_id | name | dept
--------+-------+--------------
5 | David | Engineering
6 | Kim | Finance
2 | Allen | Engineering
3 | Teddy | Engineering
4 | Mark | Finance
1 | Paul | IT Billing
7 | James | Finance
(7 rows)
The UNION ALL Clause
The UNION ALL operator is used to combine the results of two SELECT statements including duplicate rows. The same rules that apply to UNION apply to the UNION ALL operator as well.
Syntax
The basic syntax of UNION ALL is as follows −
SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition] UNION ALL SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition]
Here, given condition could be any given expression based on your requirement.
Example
Now, let us join above-mentioned two tables in our SELECT statement as follows −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID
UNION ALL
SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;
This would produce the following result −
emp_id | name | dept
--------+-------+--------------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | James | Finance
3 | Teddy | Engineering
4 | Mark | Finance
5 | David | Engineering
6 | Kim | Finance
1 | Paul | IT Billing
2 | Allen | Engineering
7 | James | Finance
3 | Teddy | Engineering
4 | Mark | Finance
5 | David | Engineering
6 | Kim | Finance
(14 rows)
PostgreSQL — NULL Values
The PostgreSQL NULL is the term used to represent a missing value. A NULL value in a table is a value in a field that appears to be blank.
A field with a NULL value is a field with no value. It is very important to understand that a NULL value is different from a zero value or a field that contains spaces.
Syntax
The basic syntax of using NULL while creating a table is as follows −
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
Here, NOT NULL signifies that column should always accept an explicit value of the given data type. There are two columns where we did not use NOT NULL. Hence, this means these columns could be NULL.
A field with a NULL value is one that has been left blank during record creation.
Example
The NULL value can cause problems when selecting data, because when comparing an unknown value to any other value, the result is always unknown and not included in the final results. Consider the following table, COMPANY having the following records −
ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 1 Paul 32 California 20000.0 2 Allen 25 Texas 15000.0 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0 6 Kim 22 South-Hall 45000.0 7 James 24 Houston 10000.0
Let us use the UPDATE statement to set few nullable values as NULL as follows −
testdb=# UPDATE COMPANY SET ADDRESS = NULL, SALARY = NULL where ID IN(6,7);
Now, COMPANY table should have the following records −
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | | 7 | James | 24 | | (7 rows)
Next, let us see the usage of IS NOT NULL operator to list down all the records where SALARY is not NULL −
testdb=# SELECT ID, NAME, AGE, ADDRESS, SALARY FROM COMPANY WHERE SALARY IS NOT NULL;
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (5 rows)
The following is the usage of IS NULL operator which will list down all the records where SALARY is NULL −
testdb=# SELECT ID, NAME, AGE, ADDRESS, SALARY
FROM COMPANY
WHERE SALARY IS NULL;
The above given PostgreSQL statement will produce the following result −
id | name | age | address | salary ----+-------+-----+---------+-------- 6 | Kim | 22 | | 7 | James | 24 | | (2 rows)
PostgreSQL — ALIAS Syntax
You can rename a table or a column temporarily by giving another name, which is known as ALIAS. The use of table aliases means to rename a table in a particular PostgreSQL statement. Renaming is a temporary change and the actual table name does not change in the database.
The column aliases are used to rename a table’s columns for the purpose of a particular PostgreSQL query.
Syntax
The basic syntax of table alias is as follows −
SELECT column1, column2.... FROM table_name AS alias_name WHERE [condition];
The basic syntax of column alias is as follows −
SELECT column_name AS alias_name FROM table_name WHERE [condition];
Example
Consider the following two tables, (a) COMPANY table is as follows −
testdb=# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
(b) Another table is DEPARTMENT as follows −
id | dept | emp_id ----+--------------+-------- 1 | IT Billing | 1 2 | Engineering | 2 3 | Finance | 7 4 | Engineering | 3 5 | Finance | 4 6 | Engineering | 5 7 | Finance | 6 (7 rows)
Now, following is the usage of TABLE ALIAS where we use C and D as aliases for COMPANY and DEPARTMENT tables, respectively −
testdb=# SELECT C.ID, C.NAME, C.AGE, D.DEPT FROM COMPANY AS C, DEPARTMENT AS D WHERE C.ID = D.EMP_ID;
The above given PostgreSQL statement will produce the following result −
id | name | age | dept ----+-------+-----+------------ 1 | Paul | 32 | IT Billing 2 | Allen | 25 | Engineering 7 | James | 24 | Finance 3 | Teddy | 23 | Engineering 4 | Mark | 25 | Finance 5 | David | 27 | Engineering 6 | Kim | 22 | Finance (7 rows)
Let us see an example for the usage of COLUMN ALIAS where COMPANY_ID is an alias of ID column and COMPANY_NAME is an alias of name column −
testdb=# SELECT C.ID AS COMPANY_ID, C.NAME AS COMPANY_NAME, C.AGE, D.DEPT FROM COMPANY AS C, DEPARTMENT AS D WHERE C.ID = D.EMP_ID;
The above given PostgreSQL statement will produce the following result −
company_id | company_name | age | dept
------------+--------------+-----+------------
1 | Paul | 32 | IT Billing
2 | Allen | 25 | Engineering
7 | James | 24 | Finance
3 | Teddy | 23 | Engineering
4 | Mark | 25 | Finance
5 | David | 27 | Engineering
6 | Kim | 22 | Finance
(7 rows)
PostgreSQL — TRIGGERS
PostgreSQL Triggers are database callback functions, which are automatically performed/invoked when a specified database event occurs.
The following are important points about PostgreSQL triggers −
-
PostgreSQL trigger can be specified to fire
-
Before the operation is attempted on a row (before constraints are checked and the INSERT, UPDATE or DELETE is attempted)
-
After the operation has completed (after constraints are checked and the INSERT, UPDATE, or DELETE has completed)
-
Instead of the operation (in the case of inserts, updates or deletes on a view)
-
-
A trigger that is marked FOR EACH ROW is called once for every row that the operation modifies. In contrast, a trigger that is marked FOR EACH STATEMENT only executes once for any given operation, regardless of how many rows it modifies.
-
Both, the WHEN clause and the trigger actions, may access elements of the row being inserted, deleted or updated using references of the form NEW.column-name and OLD.column-name, where column-name is the name of a column from the table that the trigger is associated with.
-
If a WHEN clause is supplied, the PostgreSQL statements specified are only executed for rows for which the WHEN clause is true. If no WHEN clause is supplied, the PostgreSQL statements are executed for all rows.
-
If multiple triggers of the same kind are defined for the same event, they will be fired in alphabetical order by name.
-
The BEFORE, AFTER or INSTEAD OF keyword determines when the trigger actions will be executed relative to the insertion, modification or removal of the associated row.
-
Triggers are automatically dropped when the table that they are associated with is dropped.
-
The table to be modified must exist in the same database as the table or view to which the trigger is attached and one must use just tablename, not database.tablename.
-
A CONSTRAINT option when specified creates a constraint trigger. This is the same as a regular trigger except that the timing of the trigger firing can be adjusted using SET CONSTRAINTS. Constraint triggers are expected to raise an exception when the constraints they implement are violated.
Syntax
The basic syntax of creating a trigger is as follows −
CREATE TRIGGER trigger_name [BEFORE|AFTER|INSTEAD OF] event_name ON table_name [ -- Trigger logic goes here.... ];
Here, event_name could be INSERT, DELETE, UPDATE, and TRUNCATE database operation on the mentioned table table_name. You can optionally specify FOR EACH ROW after table name.
The following is the syntax of creating a trigger on an UPDATE operation on one or more specified columns of a table as follows −
CREATE TRIGGER trigger_name [BEFORE|AFTER] UPDATE OF column_name ON table_name [ -- Trigger logic goes here.... ];
Example
Let us consider a case where we want to keep audit trial for every record being inserted in COMPANY table, which we will create newly as follows (Drop COMPANY table if you already have it).
testdb=# CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
To keep audit trial, we will create a new table called AUDIT where log messages will be inserted whenever there is an entry in COMPANY table for a new record −
testdb=# CREATE TABLE AUDIT( EMP_ID INT NOT NULL, ENTRY_DATE TEXT NOT NULL );
Here, ID is the AUDIT record ID, and EMP_ID is the ID, which will come from COMPANY table, and DATE will keep timestamp when the record will be created in COMPANY table. So now, let us create a trigger on COMPANY table as follows −
testdb=# CREATE TRIGGER example_trigger AFTER INSERT ON COMPANY FOR EACH ROW EXECUTE PROCEDURE auditlogfunc();
Where auditlogfunc() is a PostgreSQL procedure and has the following definition −
CREATE OR REPLACE FUNCTION auditlogfunc() RETURNS TRIGGER AS $example_table$
BEGIN
INSERT INTO AUDIT(EMP_ID, ENTRY_DATE) VALUES (new.ID, current_timestamp);
RETURN NEW;
END;
$example_table$ LANGUAGE plpgsql;
Now, we will start the actual work. Let us start inserting record in COMPANY table which should result in creating an audit log record in AUDIT table. So let us create one record in COMPANY table as follows −
testdb=# INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Paul', 32, 'California', 20000.00 );
This will create one record in COMPANY table, which is as follows −
id | name | age | address | salary ----+------+-----+--------------+-------- 1 | Paul | 32 | California | 20000
Same time, one record will be created in AUDIT table. This record is the result of a trigger, which we have created on INSERT operation on COMPANY table. Similarly, you can create your triggers on UPDATE and DELETE operations based on your requirements.
emp_id | entry_date
--------+-------------------------------
1 | 2013-05-05 15:49:59.968+05:30
(1 row)
Listing TRIGGERS
You can list down all the triggers in the current database from pg_trigger table as follows −
testdb=# SELECT * FROM pg_trigger;
The above given PostgreSQL statement will list down all triggers.
If you want to list the triggers on a particular table, then use AND clause with table name as follows −
testdb=# SELECT tgname FROM pg_trigger, pg_class WHERE tgrelid=pg_class.oid AND relname='company';
The above given PostgreSQL statement will also list down only one entry as follows −
tgname ----------------- example_trigger (1 row)
Dropping TRIGGERS
The following is the DROP command, which can be used to drop an existing trigger −
testdb=# DROP TRIGGER trigger_name;
PostgreSQL — INDEXES
Indexes are special lookup tables that the database search engine can use to speed up data retrieval. Simply put, an index is a pointer to data in a table. An index in a database is very similar to an index in the back of a book.
For example, if you want to reference all pages in a book that discusses a certain topic, you have to first refer to the index, which lists all topics alphabetically and then refer to one or more specific page numbers.
An index helps to speed up SELECT queries and WHERE clauses; however, it slows down data input, with UPDATE and INSERT statements. Indexes can be created or dropped with no effect on the data.
Creating an index involves the CREATE INDEX statement, which allows you to name the index, to specify the table and which column or columns to index, and to indicate whether the index is in ascending or descending order.
Indexes can also be unique, similar to the UNIQUE constraint, in that the index prevents duplicate entries in the column or combination of columns on which there’s an index.
The CREATE INDEX Command
The basic syntax of CREATE INDEX is as follows −
CREATE INDEX index_name ON table_name;
Index Types
PostgreSQL provides several index types: B-tree, Hash, GiST, SP-GiST and GIN. Each Index type uses a different algorithm that is best suited to different types of queries. By default, the CREATE INDEX command creates B-tree indexes, which fit the most common situations.
Single-Column Indexes
A single-column index is one that is created based on only one table column. The basic syntax is as follows −
CREATE INDEX index_name ON table_name (column_name);
Multicolumn Indexes
A multicolumn index is defined on more than one column of a table. The basic syntax is as follows −
CREATE INDEX index_name ON table_name (column1_name, column2_name);
Whether to create a single-column index or a multicolumn index, take into consideration the column(s) that you may use very frequently in a query’s WHERE clause as filter conditions.
Should there be only one column used, a single-column index should be the choice. Should there be two or more columns that are frequently used in the WHERE clause as filters, the multicolumn index would be the best choice.
Unique Indexes
Unique indexes are used not only for performance, but also for data integrity. A unique index does not allow any duplicate values to be inserted into the table. The basic syntax is as follows −
CREATE UNIQUE INDEX index_name on table_name (column_name);
Partial Indexes
A partial index is an index built over a subset of a table; the subset is defined by a conditional expression (called the predicate of the partial index). The index contains entries only for those table rows that satisfy the predicate. The basic syntax is as follows −
CREATE INDEX index_name on table_name (conditional_expression);
Implicit Indexes
Implicit indexes are indexes that are automatically created by the database server when an object is created. Indexes are automatically created for primary key constraints and unique constraints.
Example
The following is an example where we will create an index on COMPANY table for salary column −
# CREATE INDEX salary_index ON COMPANY (salary);
Now, let us list down all the indices available on COMPANY table using d company command.
# d company
This will produce the following result, where company_pkey is an implicit index, which got created when the table was created.
Table "public.company"
Column | Type | Modifiers
---------+---------------+-----------
id | integer | not null
name | text | not null
age | integer | not null
address | character(50) |
salary | real |
Indexes:
"company_pkey" PRIMARY KEY, btree (id)
"salary_index" btree (salary)
You can list down the entire indexes database wide using the di command −
The DROP INDEX Command
An index can be dropped using PostgreSQL DROP command. Care should be taken when dropping an index because performance may be slowed or improved.
The basic syntax is as follows −
DROP INDEX index_name;
You can use following statement to delete previously created index −
# DROP INDEX salary_index;
When Should Indexes be Avoided?
Although indexes are intended to enhance a database’s performance, there are times when they should be avoided. The following guidelines indicate when the use of an index should be reconsidered −
-
Indexes should not be used on small tables.
-
Tables that have frequent, large batch update or insert operations.
-
Indexes should not be used on columns that contain a high number of NULL values.
-
Columns that are frequently manipulated should not be indexed.
PostgreSQL — ALTER TABLE Command
The PostgreSQL ALTER TABLE command is used to add, delete or modify columns in an existing table.
You would also use ALTER TABLE command to add and drop various constraints on an existing table.
Syntax
The basic syntax of ALTER TABLE to add a new column in an existing table is as follows −
ALTER TABLE table_name ADD column_name datatype;
The basic syntax of ALTER TABLE to DROP COLUMN in an existing table is as follows −
ALTER TABLE table_name DROP COLUMN column_name;
The basic syntax of ALTER TABLE to change the DATA TYPE of a column in a table is as follows −
ALTER TABLE table_name ALTER COLUMN column_name TYPE datatype;
The basic syntax of ALTER TABLE to add a NOT NULL constraint to a column in a table is as follows −
ALTER TABLE table_name MODIFY column_name datatype NOT NULL;
The basic syntax of ALTER TABLE to ADD UNIQUE CONSTRAINT to a table is as follows −
ALTER TABLE table_name ADD CONSTRAINT MyUniqueConstraint UNIQUE(column1, column2...);
The basic syntax of ALTER TABLE to ADD CHECK CONSTRAINT to a table is as follows −
ALTER TABLE table_name ADD CONSTRAINT MyUniqueConstraint CHECK (CONDITION);
The basic syntax of ALTER TABLE to ADD PRIMARY KEY constraint to a table is as follows −
ALTER TABLE table_name ADD CONSTRAINT MyPrimaryKey PRIMARY KEY (column1, column2...);
The basic syntax of ALTER TABLE to DROP CONSTRAINT from a table is as follows −
ALTER TABLE table_name DROP CONSTRAINT MyUniqueConstraint;
If you are using MySQL, the code is as follows −
ALTER TABLE table_name DROP INDEX MyUniqueConstraint;
The basic syntax of ALTER TABLE to DROP PRIMARY KEY constraint from a table is as follows −
ALTER TABLE table_name DROP CONSTRAINT MyPrimaryKey;
If you are using MySQL, the code is as follows −
ALTER TABLE table_name DROP PRIMARY KEY;
Example
Consider our COMPANY table has the following records −
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
The following is the example to ADD a new column in an existing table −
testdb=# ALTER TABLE COMPANY ADD GENDER char(1);
Now, COMPANY table is changed and the following would be the output from SELECT statement −
id | name | age | address | salary | gender ----+-------+-----+-------------+--------+-------- 1 | Paul | 32 | California | 20000 | 2 | Allen | 25 | Texas | 15000 | 3 | Teddy | 23 | Norway | 20000 | 4 | Mark | 25 | Rich-Mond | 65000 | 5 | David | 27 | Texas | 85000 | 6 | Kim | 22 | South-Hall | 45000 | 7 | James | 24 | Houston | 10000 | (7 rows)
The following is the example to DROP gender column from existing table −
testdb=# ALTER TABLE COMPANY DROP GENDER;
Now, COMPANY table is changed and the following would be the output from SELECT statement −
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
PostgreSQL — TRUNCATE TABLE Command
The PostgreSQL TRUNCATE TABLE command is used to delete complete data from an existing table. You can also use DROP TABLE command to delete complete table but it would remove complete table structure from the database and you would need to re-create this table once again if you wish to store some data.
It has the same effect as DELETE on each table, but since it does not actually scan the tables, it is faster. Furthermore, it reclaims disk space immediately, rather than requiring a subsequent VACUUM operation. This is most useful on large tables.
Syntax
The basic syntax of TRUNCATE TABLE is as follows −
TRUNCATE TABLE table_name;
Example
Consider the COMPANY table has the following records −
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (7 rows)
The following is the example to truncate −
testdb=# TRUNCATE TABLE COMPANY;
Now, COMPANY table is truncated and the following would be the output of SELECT statement −
testdb=# SELECT * FROM CUSTOMERS; id | name | age | address | salary ----+------+-----+---------+-------- (0 rows)
PostgreSQL — VIEWS
Views are pseudo-tables. That is, they are not real tables; nevertheless appear as ordinary tables to SELECT. A view can represent a subset of a real table, selecting certain columns or certain rows from an ordinary table. A view can even represent joined tables. Because views are assigned separate permissions, you can use them to restrict table access so that the users see only specific rows or columns of a table.
A view can contain all rows of a table or selected rows from one or more tables. A view can be created from one or many tables, which depends on the written PostgreSQL query to create a view.
Views, which are kind of virtual tables, allow users to do the following −
-
Structure data in a way that users or classes of users find natural or intuitive.
-
Restrict access to the data such that a user can only see limited data instead of complete table.
-
Summarize data from various tables, which can be used to generate reports.
Since views are not ordinary tables, you may not be able to execute a DELETE, INSERT, or UPDATE statement on a view. However, you can create a RULE to correct this problem of using DELETE, INSERT or UPDATE on a view.
Creating Views
The PostgreSQL views are created using the CREATE VIEW statement. The PostgreSQL views can be created from a single table, multiple tables, or another view.
The basic CREATE VIEW syntax is as follows −
CREATE [TEMP | TEMPORARY] VIEW view_name AS SELECT column1, column2..... FROM table_name WHERE [condition];
You can include multiple tables in your SELECT statement in very similar way as you use them in normal PostgreSQL SELECT query. If the optional TEMP or TEMPORARY keyword is present, the view will be created in the temporary space. Temporary views are automatically dropped at the end of the current session.
Example
Consider, the COMPANY table is having the following records −
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000
Now, following is an example to create a view from COMPANY table. This view would be used to have only few columns from COMPANY table −
testdb=# CREATE VIEW COMPANY_VIEW AS SELECT ID, NAME, AGE FROM COMPANY;
Now, you can query COMPANY_VIEW in a similar way as you query an actual table. Following is the example −
testdb=# SELECT * FROM COMPANY_VIEW;
This would produce the following result −
id | name | age ----+-------+----- 1 | Paul | 32 2 | Allen | 25 3 | Teddy | 23 4 | Mark | 25 5 | David | 27 6 | Kim | 22 7 | James | 24 (7 rows)
Dropping Views
To drop a view, simply use the DROP VIEW statement with the view_name. The basic DROP VIEW syntax is as follows −
testdb=# DROP VIEW view_name;
The following command will delete COMPANY_VIEW view, which we created in the last section −
testdb=# DROP VIEW COMPANY_VIEW;
PostgreSQL — TRANSACTIONS
A transaction is a unit of work that is performed against a database. Transactions are units or sequences of work accomplished in a logical order, whether in a manual fashion by a user or automatically by some sort of a database program.
A transaction is the propagation of one or more changes to the database. For example, if you are creating a record, updating a record, or deleting a record from the table, then you are performing transaction on the table. It is important to control transactions to ensure data integrity and to handle database errors.
Practically, you will club many PostgreSQL queries into a group and you will execute all of them together as a part of a transaction.
Properties of Transactions
Transactions have the following four standard properties, usually referred to by the acronym ACID −
-
Atomicity − Ensures that all operations within the work unit are completed successfully; otherwise, the transaction is aborted at the point of failure and previous operations are rolled back to their former state.
-
Consistency − Ensures that the database properly changes states upon a successfully committed transaction.
-
Isolation − Enables transactions to operate independently of and transparent to each other.
-
Durability − Ensures that the result or effect of a committed transaction persists in case of a system failure.
Transaction Control
The following commands are used to control transactions −
-
BEGIN TRANSACTION − To start a transaction.
-
COMMIT − To save the changes, alternatively you can use END TRANSACTION command.
-
ROLLBACK − To rollback the changes.
Transactional control commands are only used with the DML commands INSERT, UPDATE and DELETE only. They cannot be used while creating tables or dropping them because these operations are automatically committed in the database.
The BEGIN TRANSACTION Command
Transactions can be started using BEGIN TRANSACTION or simply BEGIN command. Such transactions usually persist until the next COMMIT or ROLLBACK command is encountered. But a transaction will also ROLLBACK if the database is closed or if an error occurs.
The following is the simple syntax to start a transaction −
BEGIN; or BEGIN TRANSACTION;
The COMMIT Command
The COMMIT command is the transactional command used to save changes invoked by a transaction to the database.
The COMMIT command saves all transactions to the database since the last COMMIT or ROLLBACK command.
The syntax for COMMIT command is as follows −
COMMIT; or END TRANSACTION;
The ROLLBACK Command
The ROLLBACK command is the transactional command used to undo transactions that have not already been saved to the database.
The ROLLBACK command can only be used to undo transactions since the last COMMIT or ROLLBACK command was issued.
The syntax for ROLLBACK command is as follows −
ROLLBACK;
Example
Consider the COMPANY table is having the following records −
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
Now, let us start a transaction and delete records from the table having age = 25 and finally we use ROLLBACK command to undo all the changes.
testdb=# BEGIN; DELETE FROM COMPANY WHERE AGE = 25; ROLLBACK;
If you will check COMPANY table is still having the following records −
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
Now, let us start another transaction and delete records from the table having age = 25 and finally we use COMMIT command to commit all the changes.
testdb=# BEGIN; DELETE FROM COMPANY WHERE AGE = 25; COMMIT;
If you will check the COMPANY table, it still has the following records −
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 3 | Teddy | 23 | Norway | 20000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (5 rows)
PostgreSQL — LOCKS
Locks or Exclusive Locks or Write Locks prevent users from modifying a row or an entire table. Rows modified by UPDATE and DELETE are then exclusively locked automatically for the duration of the transaction. This prevents other users from changing the row until the transaction is either committed or rolled back.
The only time when users must wait for other users is when they are trying to modify the same row. If they modify different rows, no waiting is necessary. SELECT queries never have to wait.
The database performs locking automatically. In certain cases, however, locking must be controlled manually. Manual locking can be done by using the LOCK command. It allows specification of a transaction’s lock type and scope.
Syntax for LOCK command
The basic syntax for LOCK command is as follows −
LOCK [ TABLE ] name IN lock_mode
-
name − The name (optionally schema-qualified) of an existing table to lock. If ONLY is specified before the table name, only that table is locked. If ONLY is not specified, the table and all its descendant tables (if any) are locked.
-
lock_mode − The lock mode specifies which locks this lock conflicts with. If no lock mode is specified, then ACCESS EXCLUSIVE, the most restrictive mode, is used. Possible values are: ACCESS SHARE, ROW SHARE, ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE, ACCESS EXCLUSIVE.
Once obtained, the lock is held for the remainder of the current transaction. There is no UNLOCK TABLE command; locks are always released at the transaction end.
DeadLocks
Deadlocks can occur when two transactions are waiting for each other to finish their operations. While PostgreSQL can detect them and end them with a ROLLBACK, deadlocks can still be inconvenient. To prevent your applications from running into this problem, make sure to design them in such a way that they will lock objects in the same order.
Advisory Locks
PostgreSQL provides means for creating locks that have application-defined meanings. These are called advisory locks. As the system does not enforce their use, it is up to the application to use them correctly. Advisory locks can be useful for locking strategies that are an awkward fit for the MVCC model.
For example, a common use of advisory locks is to emulate pessimistic locking strategies typical of the so-called «flat file» data management systems. While a flag stored in a table could be used for the same purpose, advisory locks are faster, avoid table bloat, and are automatically cleaned up by the server at the end of the session.
Example
Consider the table COMPANY having records as follows −
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
The following example locks the COMPANY table within the testdb database in ACCESS EXCLUSIVE mode. The LOCK statement works only in a transaction mode −
testdb=#BEGIN; LOCK TABLE company1 IN ACCESS EXCLUSIVE MODE;
The above given PostgreSQL statement will produce the following result −
LOCK TABLE
The above message indicates that the table is locked until the transaction ends and to finish the transaction you will have to either rollback or commit the transaction.
PostgreSQL — Sub Queries
A subquery or Inner query or Nested query is a query within another PostgreSQL query and embedded within the WHERE clause.
A subquery is used to return data that will be used in the main query as a condition to further restrict the data to be retrieved.
Subqueries can be used with the SELECT, INSERT, UPDATE and DELETE statements along with the operators like =, <, >, >=, <=, IN, etc.
There are a few rules that subqueries must follow −
-
Subqueries must be enclosed within parentheses.
-
A subquery can have only one column in the SELECT clause, unless multiple columns are in the main query for the subquery to compare its selected columns.
-
An ORDER BY cannot be used in a subquery, although the main query can use an ORDER BY. The GROUP BY can be used to perform the same function as the ORDER BY in a subquery.
-
Subqueries that return more than one row can only be used with multiple value operators, such as the IN, EXISTS, NOT IN, ANY/SOME, ALL operator.
-
The BETWEEN operator cannot be used with a subquery; however, the BETWEEN can be used within the subquery.
Subqueries with the SELECT Statement
Subqueries are most frequently used with the SELECT statement. The basic syntax is as follows −
SELECT column_name [, column_name ]
FROM table1 [, table2 ]
WHERE column_name OPERATOR
(SELECT column_name [, column_name ]
FROM table1 [, table2 ]
[WHERE])
Example
Consider the COMPANY table having the following records −
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Now, let us check the following sub-query with SELECT statement −
testdb=# SELECT *
FROM COMPANY
WHERE ID IN (SELECT ID
FROM COMPANY
WHERE SALARY > 45000) ;
This would produce the following result −
id | name | age | address | salary ----+-------+-----+-------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (2 rows)
Subqueries with the INSERT Statement
Subqueries also can be used with INSERT statements. The INSERT statement uses the data returned from the subquery to insert into another table. The selected data in the subquery can be modified with any of the character, date, or number functions.
The basic syntax is as follows −
INSERT INTO table_name [ (column1 [, column2 ]) ] SELECT [ *|column1 [, column2 ] ] FROM table1 [, table2 ] [ WHERE VALUE OPERATOR ]
Example
Consider a table COMPANY_BKP, with similar structure as COMPANY table and can be created using the same CREATE TABLE using COMPANY_BKP as the table name. Now, to copy complete COMPANY table into COMPANY_BKP, following is the syntax −
testdb=# INSERT INTO COMPANY_BKP
SELECT * FROM COMPANY
WHERE ID IN (SELECT ID
FROM COMPANY) ;
Subqueries with the UPDATE Statement
The subquery can be used in conjunction with the UPDATE statement. Either single or multiple columns in a table can be updated when using a subquery with the UPDATE statement.
The basic syntax is as follows −
UPDATE table SET column_name = new_value [ WHERE OPERATOR [ VALUE ] (SELECT COLUMN_NAME FROM TABLE_NAME) [ WHERE) ]
Example
Assuming, we have COMPANY_BKP table available, which is backup of the COMPANY table.
The following example updates SALARY by 0.50 times in the COMPANY table for all the customers, whose AGE is greater than or equal to 27 −
testdb=# UPDATE COMPANY
SET SALARY = SALARY * 0.50
WHERE AGE IN (SELECT AGE FROM COMPANY_BKP
WHERE AGE >= 27 );
This would affect two rows and finally the COMPANY table would have the following records −
id | name | age | address | salary ----+-------+-----+-------------+-------- 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 1 | Paul | 32 | California | 10000 5 | David | 27 | Texas | 42500 (7 rows)
Subqueries with the DELETE Statement
The subquery can be used in conjunction with the DELETE statement like with any other statements mentioned above.
The basic syntax is as follows −
DELETE FROM TABLE_NAME [ WHERE OPERATOR [ VALUE ] (SELECT COLUMN_NAME FROM TABLE_NAME) [ WHERE) ]
Example
Assuming, we have COMPANY_BKP table available, which is a backup of the COMPANY table.
The following example deletes records from the COMPANY table for all the customers, whose AGE is greater than or equal to 27 −
testdb=# DELETE FROM COMPANY
WHERE AGE IN (SELECT AGE FROM COMPANY_BKP
WHERE AGE > 27 );
This would affect two rows and finally the COMPANY table would have the following records −
id | name | age | address | salary ----+-------+-----+-------------+-------- 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 5 | David | 27 | Texas | 42500 (6 rows)
PostgreSQL — AUTO INCREMENT
PostgreSQL has the data types smallserial, serial and bigserial; these are not true types, but merely a notational convenience for creating unique identifier columns. These are similar to AUTO_INCREMENT property supported by some other databases.
If you wish a serial column to have a unique constraint or be a primary key, it must now be specified, just like any other data type.
The type name serial creates an integer columns. The type name bigserial creates a bigint column. bigserial should be used if you anticipate the use of more than 231 identifiers over the lifetime of the table. The type name smallserial creates a smallint column.
Syntax
The basic usage of SERIAL dataype is as follows −
CREATE TABLE tablename ( colname SERIAL );
Example
Consider the COMPANY table to be created as follows −
testdb=# CREATE TABLE COMPANY( ID SERIAL PRIMARY KEY, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
Now, insert the following records into table COMPANY −
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Paul', 32, 'California', 20000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ('Allen', 25, 'Texas', 15000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ('Teddy', 23, 'Norway', 20000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Mark', 25, 'Rich-Mond ', 65000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'David', 27, 'Texas', 85000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Kim', 22, 'South-Hall', 45000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'James', 24, 'Houston', 10000.00 );
This will insert seven tuples into the table COMPANY and COMPANY will have the following records −
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000
PostgreSQL — PRIVILEGES
Whenever an object is created in a database, an owner is assigned to it. The owner is usually the one who executed the creation statement. For most kinds of objects, the initial state is that only the owner (or a superuser) can modify or delete the object. To allow other roles or users to use it, privileges or permission must be granted.
Different kinds of privileges in PostgreSQL are −
- SELECT,
- INSERT,
- UPDATE,
- DELETE,
- TRUNCATE,
- REFERENCES,
- TRIGGER,
- CREATE,
- CONNECT,
- TEMPORARY,
- EXECUTE, and
- USAGE
Depending on the type of the object (table, function, etc.,), privileges are applied to the object. To assign privileges to the users, the GRANT command is used.
Syntax for GRANT
Basic syntax for GRANT command is as follows −
GRANT privilege [, ...]
ON object [, ...]
TO { PUBLIC | GROUP group | username }
-
privilege − values could be: SELECT, INSERT, UPDATE, DELETE, RULE, ALL.
-
object − The name of an object to which to grant access. The possible objects are: table, view, sequence
-
PUBLIC − A short form representing all users.
-
GROUP group − A group to whom to grant privileges.
-
username − The name of a user to whom to grant privileges. PUBLIC is a short form representing all users.
The privileges can be revoked using the REVOKE command.
Syntax for REVOKE
Basic syntax for REVOKE command is as follows −
REVOKE privilege [, ...]
ON object [, ...]
FROM { PUBLIC | GROUP groupname | username }
-
privilege − values could be: SELECT, INSERT, UPDATE, DELETE, RULE, ALL.
-
object − The name of an object to which to grant access. The possible objects are: table, view, sequence
-
PUBLIC − A short form representing all users.
-
GROUP group − A group to whom to grant privileges.
-
username − The name of a user to whom to grant privileges. PUBLIC is a short form representing all users.
Example
To understand the privileges, let us first create a USER as follows −
testdb=# CREATE USER manisha WITH PASSWORD 'password'; CREATE ROLE
The message CREATE ROLE indicates that the USER «manisha» is created.
Consider the table COMPANY having records as follows −
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Next, let us grant all privileges on a table COMPANY to the user «manisha» as follows −
testdb=# GRANT ALL ON COMPANY TO manisha; GRANT
The message GRANT indicates that all privileges are assigned to the USER.
Next, let us revoke the privileges from the USER «manisha» as follows −
testdb=# REVOKE ALL ON COMPANY FROM manisha; REVOKE
The message REVOKE indicates that all privileges are revoked from the USER.
You can even delete the user as follows −
testdb=# DROP USER manisha; DROP ROLE
The message DROP ROLE indicates USER ‘Manisha’ is deleted from the database.
PostgreSQL — DATE/TIME Functions and Operators
We had discussed about the Date/Time data types in the chapter Data Types. Now, let us see the Date/Time operators and Functions.
The following table lists the behaviors of the basic arithmetic operators −
| Operator | Example | Result |
|---|---|---|
| + | date ‘2001-09-28’ + integer ‘7’ | date ‘2001-10-05’ |
| + | date ‘2001-09-28’ + interval ‘1 hour’ | timestamp ‘2001-09-28 01:00:00’ |
| + | date ‘2001-09-28′ + time ’03:00’ | timestamp ‘2001-09-28 03:00:00’ |
| + | interval ‘1 day’ + interval ‘1 hour’ | interval ‘1 day 01:00:00’ |
| + | timestamp ‘2001-09-28 01:00′ + interval ’23 hours’ | timestamp ‘2001-09-29 00:00:00’ |
| + | time ’01:00′ + interval ‘3 hours’ | time ’04:00:00′ |
| — | — interval ’23 hours’ | interval ‘-23:00:00’ |
| — | date ‘2001-10-01’ — date ‘2001-09-28’ | integer ‘3’ (days) |
| — | date ‘2001-10-01’ — integer ‘7’ | date ‘2001-09-24’ |
| — | date ‘2001-09-28’ — interval ‘1 hour’ | timestamp ‘2001-09-27 23:00:00’ |
| — | time ’05:00′ — time ’03:00′ | interval ’02:00:00′ |
| — | time ’05:00′ — interval ‘2 hours’ | time ’03:00:00′ |
| — | timestamp ‘2001-09-28 23:00′ — interval ’23 hours’ | timestamp ‘2001-09-28 00:00:00’ |
| — | interval ‘1 day’ — interval ‘1 hour’ | interval ‘1 day -01:00:00’ |
| — | timestamp ‘2001-09-29 03:00’ — timestamp ‘2001-09-27 12:00’ | interval ‘1 day 15:00:00’ |
| * | 900 * interval ‘1 second’ | interval ’00:15:00′ |
| * | 21 * interval ‘1 day’ | interval ’21 days’ |
| * | double precision ‘3.5’ * interval ‘1 hour’ | interval ’03:30:00′ |
| / | interval ‘1 hour’ / double precision ‘1.5’ | interval ’00:40:00′ |
The following is the list of all important Date and Time related functions available.
| S. No. | Function & Description |
|---|---|
| 1 | AGE()
Subtract arguments |
| 2 | CURRENT DATE/TIME()
Current date and time |
| 3 | DATE_PART()
Get subfield (equivalent to extract) |
| 4 | EXTRACT()
Get subfield |
| 5 | ISFINITE()
Test for finite date, time and interval (not +/-infinity) |
| 6 | JUSTIFY
Adjust interval |
AGE(timestamp, timestamp), AGE(timestamp)
| S. No. | Function & Description |
|---|---|
| 1 |
AGE(timestamp, timestamp) When invoked with the TIMESTAMP form of the second argument, AGE() subtract arguments, producing a «symbolic» result that uses years and months and is of type INTERVAL. |
| 2 |
AGE(timestamp) When invoked with only the TIMESTAMP as argument, AGE() subtracts from the current_date (at midnight). |
Example of the function AGE(timestamp, timestamp) is −
testdb=# SELECT AGE(timestamp '2001-04-10', timestamp '1957-06-13');
The above given PostgreSQL statement will produce the following result −
age ------------------------- 43 years 9 mons 27 days
Example of the function AGE(timestamp) is −
testdb=# select age(timestamp '1957-06-13');
The above given PostgreSQL statement will produce the following result −
age -------------------------- 55 years 10 mons 22 days
CURRENT DATE/TIME()
PostgreSQL provides a number of functions that return values related to the current date and time. Following are some functions −
| S. No. | Function & Description |
|---|---|
| 1 |
CURRENT_DATE Delivers current date. |
| 2 |
CURRENT_TIME Delivers values with time zone. |
| 3 |
CURRENT_TIMESTAMP Delivers values with time zone. |
| 4 |
CURRENT_TIME(precision) Optionally takes a precision parameter, which causes the result to be rounded to that many fractional digits in the seconds field. |
| 5 |
CURRENT_TIMESTAMP(precision) Optionally takes a precision parameter, which causes the result to be rounded to that many fractional digits in the seconds field. |
| 6 |
LOCALTIME Delivers values without time zone. |
| 7 |
LOCALTIMESTAMP Delivers values without time zone. |
| 8 |
LOCALTIME(precision) Optionally takes a precision parameter, which causes the result to be rounded to that many fractional digits in the seconds field. |
| 9 |
LOCALTIMESTAMP(precision) Optionally takes a precision parameter, which causes the result to be rounded to that many fractional digits in the seconds field. |
Examples using the functions from the table above −
testdb=# SELECT CURRENT_TIME;
timetz
--------------------
08:01:34.656+05:30
(1 row)
testdb=# SELECT CURRENT_DATE;
date
------------
2013-05-05
(1 row)
testdb=# SELECT CURRENT_TIMESTAMP;
now
-------------------------------
2013-05-05 08:01:45.375+05:30
(1 row)
testdb=# SELECT CURRENT_TIMESTAMP(2);
timestamptz
------------------------------
2013-05-05 08:01:50.89+05:30
(1 row)
testdb=# SELECT LOCALTIMESTAMP;
timestamp
------------------------
2013-05-05 08:01:55.75
(1 row)
PostgreSQL also provides functions that return the start time of the current statement, as well as the actual current time at the instant the function is called. These functions are −
| S. No. | Function & Description |
|---|---|
| 1 |
transaction_timestamp() It is equivalent to CURRENT_TIMESTAMP, but is named to clearly reflect what it returns. |
| 2 |
statement_timestamp() It returns the start time of the current statement. |
| 3 |
clock_timestamp() It returns the actual current time, and therefore its value changes even within a single SQL command. |
| 4 |
timeofday() It returns the actual current time, but as a formatted text string rather than a timestamp with time zone value. |
| 5 |
now() It is a traditional PostgreSQL equivalent to transaction_timestamp(). |
DATE_PART(text, timestamp), DATE_PART(text, interval), DATE_TRUNC(text, timestamp)
| S. No. | Function & Description |
|---|---|
| 1 |
DATE_PART(‘field’, source) These functions get the subfields. The field parameter needs to be a string value, not a name. The valid field names are: century, day, decade, dow, doy, epoch, hour, isodow, isoyear, microseconds, millennium, milliseconds, minute, month, quarter, second, timezone, timezone_hour, timezone_minute, week, year. |
| 2 |
DATE_TRUNC(‘field’, source) This function is conceptually similar to the trunc function for numbers. source is a value expression of type timestamp or interval. field selects to which precision to truncate the input value. The return value is of type timestamp or interval. The valid values for field are : microseconds, milliseconds, second, minute, hour, day, week, month, quarter, year, decade, century, millennium |
The following are examples for DATE_PART(‘field’, source) functions −
testdb=# SELECT date_part('day', TIMESTAMP '2001-02-16 20:38:40');
date_part
-----------
16
(1 row)
testdb=# SELECT date_part('hour', INTERVAL '4 hours 3 minutes');
date_part
-----------
4
(1 row)
The following are examples for DATE_TRUNC(‘field’, source) functions −
testdb=# SELECT date_trunc('hour', TIMESTAMP '2001-02-16 20:38:40');
date_trunc
---------------------
2001-02-16 20:00:00
(1 row)
testdb=# SELECT date_trunc('year', TIMESTAMP '2001-02-16 20:38:40');
date_trunc
---------------------
2001-01-01 00:00:00
(1 row)
EXTRACT(field from timestamp), EXTRACT(field from interval)
The EXTRACT(field FROM source) function retrieves subfields such as year or hour from date/time values. The source must be a value expression of type timestamp, time, or interval. The field is an identifier or string that selects what field to extract from the source value. The EXTRACT function returns values of type double precision.
The following are valid field names (similar to DATE_PART function field names): century, day, decade, dow, doy, epoch, hour, isodow, isoyear, microseconds, millennium, milliseconds, minute, month, quarter, second, timezone, timezone_hour, timezone_minute, week, year.
The following are examples of EXTRACT(‘field’, source) functions −
testdb=# SELECT EXTRACT(CENTURY FROM TIMESTAMP '2000-12-16 12:21:13');
date_part
-----------
20
(1 row)
testdb=# SELECT EXTRACT(DAY FROM TIMESTAMP '2001-02-16 20:38:40');
date_part
-----------
16
(1 row)
ISFINITE(date), ISFINITE(timestamp), ISFINITE(interval)
| S. No. | Function & Description |
|---|---|
| 1 |
ISFINITE(date) Tests for finite date. |
| 2 |
ISFINITE(timestamp) Tests for finite time stamp. |
| 3 |
ISFINITE(interval) Tests for finite interval. |
The following are the examples of the ISFINITE() functions −
testdb=# SELECT isfinite(date '2001-02-16'); isfinite ---------- t (1 row) testdb=# SELECT isfinite(timestamp '2001-02-16 21:28:30'); isfinite ---------- t (1 row) testdb=# SELECT isfinite(interval '4 hours'); isfinite ---------- t (1 row)
JUSTIFY_DAYS(interval), JUSTIFY_HOURS(interval), JUSTIFY_INTERVAL(interval)
| S. No. | Function & Description |
|---|---|
| 1 |
JUSTIFY_DAYS(interval) Adjusts interval so 30-day time periods are represented as months. Return the interval type |
| 2 |
JUSTIFY_HOURS(interval) Adjusts interval so 24-hour time periods are represented as days. Return the interval type |
| 3 |
JUSTIFY_INTERVAL(interval) Adjusts interval using JUSTIFY_DAYS and JUSTIFY_HOURS, with additional sign adjustments. Return the interval type |
The following are the examples for the ISFINITE() functions −
testdb=# SELECT justify_days(interval '35 days'); justify_days -------------- 1 mon 5 days (1 row) testdb=# SELECT justify_hours(interval '27 hours'); justify_hours ---------------- 1 day 03:00:00 (1 row) testdb=# SELECT justify_interval(interval '1 mon -1 hour'); justify_interval ------------------ 29 days 23:00:00 (1 row)
PostgreSQL — Functions
PostgreSQL functions, also known as Stored Procedures, allow you to carry out operations that would normally take several queries and round trips in a single function within the database. Functions allow database reuse as other applications can interact directly with your stored procedures instead of a middle-tier or duplicating code.
Functions can be created in a language of your choice like SQL, PL/pgSQL, C, Python, etc.
Syntax
The basic syntax to create a function is as follows −
CREATE [OR REPLACE] FUNCTION function_name (arguments)
RETURNS return_datatype AS $variable_name$
DECLARE
declaration;
[...]
BEGIN
< function_body >
[...]
RETURN { variable_name | value }
END; LANGUAGE plpgsql;
Where,
-
function-name specifies the name of the function.
-
[OR REPLACE] option allows modifying an existing function.
-
The function must contain a return statement.
-
RETURN clause specifies that data type you are going to return from the function. The return_datatype can be a base, composite, or domain type, or can reference the type of a table column.
-
function-body contains the executable part.
-
The AS keyword is used for creating a standalone function.
-
plpgsql is the name of the language that the function is implemented in. Here, we use this option for PostgreSQL, it Can be SQL, C, internal, or the name of a user-defined procedural language. For backward compatibility, the name can be enclosed by single quotes.
Example
The following example illustrates creating and calling a standalone function. This function returns the total number of records in the COMPANY table. We will use the COMPANY table, which has the following records −
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
Function totalRecords() is as follows −
CREATE OR REPLACE FUNCTION totalRecords () RETURNS integer AS $total$ declare total integer; BEGIN SELECT count(*) into total FROM COMPANY; RETURN total; END; $total$ LANGUAGE plpgsql;
When the above query is executed, the result would be −
testdb# CREATE FUNCTION
Now, let us execute a call to this function and check the records in the COMPANY table
testdb=# select totalRecords();
When the above query is executed, the result would be −
totalrecords
--------------
7
(1 row)
PostgreSQL — Useful Functions
PostgreSQL built-in functions, also called as Aggregate functions, are used for performing processing on string or numeric data.
The following is the list of all general-purpose PostgreSQL built-in functions −
-
PostgreSQL COUNT Function − The PostgreSQL COUNT aggregate function is used to count the number of rows in a database table.
-
PostgreSQL MAX Function − The PostgreSQL MAX aggregate function allows us to select the highest (maximum) value for a certain column.
-
PostgreSQL MIN Function − The PostgreSQL MIN aggregate function allows us to select the lowest (minimum) value for a certain column.
-
PostgreSQL AVG Function − The PostgreSQL AVG aggregate function selects the average value for certain table column.
-
PostgreSQL SUM Function − The PostgreSQL SUM aggregate function allows selecting the total for a numeric column.
-
PostgreSQL ARRAY Functions − The PostgreSQL ARRAY aggregate function puts input values, including nulls, concatenated into an array.
-
PostgreSQL Numeric Functions − Complete list of PostgreSQL functions required to manipulate numbers in SQL.
-
PostgreSQL String Functions − Complete list of PostgreSQL functions required to manipulate strings in PostgreSQL.
PostgreSQL — C/C++ Interface
This tutorial is going to use libpqxx library, which is the official C++ client API for PostgreSQL. The source code for libpqxx is available under the BSD license, so you are free to download it, pass it on to others, change it, sell it, include it in your own code, and share your changes with anyone you choose.
Installation
The the latest version of libpqxx is available to be downloaded from the link Download Libpqxx. So download the latest version and follow the following steps −
wget http://pqxx.org/download/software/libpqxx/libpqxx-4.0.tar.gz tar xvfz libpqxx-4.0.tar.gz cd libpqxx-4.0 ./configure make make install
Before you start using C/C++ PostgreSQL interface, find the pg_hba.conf file in your PostgreSQL installation directory and add the following line −
# IPv4 local connections: host all all 127.0.0.1/32 md5
You can start/restart postgres server in case it is not running using the following command −
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
C/C++ Interface APIs
The following are important interface routines which can sufice your requirement to work with PostgreSQL database from your C/C++ program. If you are looking for a more sophisticated application then you can look into the libpqxx official documentation, or you can use commercially available APIs.
| S. No. | API & Description |
|---|---|
| 1 |
pqxx::connection C( const std::string & dbstring ) This is a typedef which will be used to connect to the database. Here, dbstring provides required parameters to connect to the datbase, for example dbname = testdb user = postgres password=pass123 hostaddr=127.0.0.1 port=5432. If connection is setup successfully then it creates C with connection object which provides various useful function public function. |
| 2 |
C.is_open() The method is_open() is a public method of connection object and returns boolean value. If connection is active, then this method returns true otherwise it returns false. |
| 3 |
C.disconnect() This method is used to disconnect an opened database connection. |
| 4 |
pqxx::work W( C ) This is a typedef which will be used to create a transactional object using connection C, which ultimately will be used to execute SQL statements in transactional mode. If transaction object gets created successfully, then it is assigned to variable W which will be used to access public methods related to transactional object. |
| 5 |
W.exec(const std::string & sql) This public method from transactional object will be used to execute SQL statement. |
| 6 |
W.commit() This public method from transactional object will be used to commit the transaction. |
| 7 |
W.abort() This public method from transactional object will be used to rollback the transaction. |
| 8 |
pqxx::nontransaction N( C ) This is a typedef which will be used to create a non-transactional object using connection C, which ultimately will be used to execute SQL statements in non-transactional mode. If transaction object gets created successfully, then it is assigned to variable N which will be used to access public methods related to non-transactional object. |
| 9 |
N.exec(const std::string & sql) This public method from non-transactional object will be used to execute SQL statement and returns a result object which is actually an interator holding all the returned records. |
Connecting To Database
The following C code segment shows how to connect to an existing database running on local machine at port 5432. Here, I used backslash for line continuation.
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
try {
connection C("dbname = testdb user = postgres password = cohondob
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
}
Now, let us compile and run the above program to connect to our database testdb, which is already available in your schema and can be accessed using user postgres and password pass123.
You can use the user ID and password based on your database setting. Remember to keep the -lpqxx and -lpq in the given order! Otherwise, the linker will complain bitterly about the missing functions with names starting with «PQ.»
$g++ test.cpp -lpqxx -lpq $./a.out Opened database successfully: testdb
Create a Table
The following C code segment will be used to create a table in previously created database −
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create SQL statement */
sql = "CREATE TABLE COMPANY("
"ID INT PRIMARY KEY NOT NULL,"
"NAME TEXT NOT NULL,"
"AGE INT NOT NULL,"
"ADDRESS CHAR(50),"
"SALARY REAL );";
/* Create a transactional object. */
work W(C);
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Table created successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
When the above given program is compiled and executed, it will create COMPANY table in your testdb database and will display the following statements −
Opened database successfully: testdb Table created successfully
INSERT Operation
The following C code segment shows how we can create records in our COMPANY table created in above example −
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create SQL statement */
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
"VALUES (1, 'Paul', 32, 'California', 20000.00 ); "
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
"VALUES (2, 'Allen', 25, 'Texas', 15000.00 ); "
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)"
"VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );"
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)"
"VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );";
/* Create a transactional object. */
work W(C);
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Records created successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
When the above given program is compiled and executed, it will create given records in COMPANY table and will display the following two lines −
Opened database successfully: testdb Records created successfully
SELECT Operation
The following C code segment shows how we can fetch and display records from our COMPANY table created in above example −
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create SQL statement */
sql = "SELECT * from COMPANY";
/* Create a non-transactional object. */
nontransaction N(C);
/* Execute SQL query */
result R( N.exec( sql ));
/* List down all the records */
for (result::const_iterator c = R.begin(); c != R.end(); ++c) {
cout << "ID = " << c[0].as<int>() << endl;
cout << "Name = " << c[1].as<string>() << endl;
cout << "Age = " << c[2].as<int>() << endl;
cout << "Address = " << c[3].as<string>() << endl;
cout << "Salary = " << c[4].as<float>() << endl;
}
cout << "Operation done successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
When the above given program is compiled and executed, it will produce the following result −
Opened database successfully: testdb ID = 1 Name = Paul Age = 32 Address = California Salary = 20000 ID = 2 Name = Allen Age = 25 Address = Texas Salary = 15000 ID = 3 Name = Teddy Age = 23 Address = Norway Salary = 20000 ID = 4 Name = Mark Age = 25 Address = Rich-Mond Salary = 65000 Operation done successfully
UPDATE Operation
The following C code segment shows how we can use the UPDATE statement to update any record and then fetch and display updated records from our COMPANY table −
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create a transactional object. */
work W(C);
/* Create SQL UPDATE statement */
sql = "UPDATE COMPANY set SALARY = 25000.00 where ID=1";
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Records updated successfully" << endl;
/* Create SQL SELECT statement */
sql = "SELECT * from COMPANY";
/* Create a non-transactional object. */
nontransaction N(C);
/* Execute SQL query */
result R( N.exec( sql ));
/* List down all the records */
for (result::const_iterator c = R.begin(); c != R.end(); ++c) {
cout << "ID = " << c[0].as<int>() << endl;
cout << "Name = " << c[1].as<string>() << endl;
cout << "Age = " << c[2].as<int>() << endl;
cout << "Address = " << c[3].as<string>() << endl;
cout << "Salary = " << c[4].as<float>() << endl;
}
cout << "Operation done successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
When the above given program is compiled and executed, it will produce the following result −
Opened database successfully: testdb Records updated successfully ID = 2 Name = Allen Age = 25 Address = Texas Salary = 15000 ID = 3 Name = Teddy Age = 23 Address = Norway Salary = 20000 ID = 4 Name = Mark Age = 25 Address = Rich-Mond Salary = 65000 ID = 1 Name = Paul Age = 32 Address = California Salary = 25000 Operation done successfully
DELETE Operation
The following C code segment shows how we can use the DELETE statement to delete any record and then fetch and display remaining records from our COMPANY table −
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create a transactional object. */
work W(C);
/* Create SQL DELETE statement */
sql = "DELETE from COMPANY where ID = 2";
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Records deleted successfully" << endl;
/* Create SQL SELECT statement */
sql = "SELECT * from COMPANY";
/* Create a non-transactional object. */
nontransaction N(C);
/* Execute SQL query */
result R( N.exec( sql ));
/* List down all the records */
for (result::const_iterator c = R.begin(); c != R.end(); ++c) {
cout << "ID = " << c[0].as<int>() << endl;
cout << "Name = " << c[1].as<string>() << endl;
cout << "Age = " << c[2].as<int>() << endl;
cout << "Address = " << c[3].as<string>() << endl;
cout << "Salary = " << c[4].as<float>() << endl;
}
cout << "Operation done successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
When the above given program is compiled and executed, it will produce the following result −
Opened database successfully: testdb Records deleted successfully ID = 3 Name = Teddy Age = 23 Address = Norway Salary = 20000 ID = 4 Name = Mark Age = 25 Address = Rich-Mond Salary = 65000 ID = 1 Name = Paul Age = 32 Address = California Salary = 25000 Operation done successfully
PostgreSQL — JAVA Interface
Installation
Before we start using PostgreSQL in our Java programs, we need to make sure that we have PostgreSQL JDBC and Java set up on the machine. You can check Java tutorial for Java installation on your machine. Now let us check how to set up PostgreSQL JDBC driver.
-
Download the latest version of postgresql-(VERSION).jdbc.jar from postgresql-jdbc repository.
-
Add downloaded jar file postgresql-(VERSION).jdbc.jar in your class path, or you can use it along with -classpath option as explained below in the examples.
The following section assumes you have little knowledge about Java JDBC concepts. If you do not have, then it is suggested to spent half and hour with JDBC Tutorial to become comfortable with concepts explained below.
Connecting To Database
The following Java code shows how to connect to an existing database. If the database does not exist, then it will be created and finally a database object will be returned.
import java.sql.Connection;
import java.sql.DriverManager;
public class PostgreSQLJDBC {
public static void main(String args[]) {
Connection c = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://localhost:5432/testdb",
"postgres", "123");
} catch (Exception e) {
e.printStackTrace();
System.err.println(e.getClass().getName()+": "+e.getMessage());
System.exit(0);
}
System.out.println("Opened database successfully");
}
}
Before you compile and run above program, find pg_hba.conf file in your PostgreSQL installation directory and add the following line −
# IPv4 local connections: host all all 127.0.0.1/32 md5
You can start/restart the postgres server in case it is not running using the following command −
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
Now, let us compile and run the above program to connect with testdb. Here, we are using postgres as user ID and 123 as password to access the database. You can change this as per your database configuration and setup. We are also assuming current version of JDBC driver postgresql-9.2-1002.jdbc3.jar is available in the current path.
C:JavaPostgresIntegration>javac PostgreSQLJDBC.java C:JavaPostgresIntegration>java -cp c:toolspostgresql-9.2-1002.jdbc3.jar;C:JavaPostgresIntegration PostgreSQLJDBC Open database successfully
Create a Table
The following Java program will be used to create a table in previously opened database. Make sure you do not have this table already in your target database.
import java.sql.*;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main( String args[] ) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://localhost:5432/testdb",
"manisha", "123");
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "CREATE TABLE COMPANY " +
"(ID INT PRIMARY KEY NOT NULL," +
" NAME TEXT NOT NULL, " +
" AGE INT NOT NULL, " +
" ADDRESS CHAR(50), " +
" SALARY REAL)";
stmt.executeUpdate(sql);
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Table created successfully");
}
}
When a program is compiled and executed, it will create the COMPANY table in testdb database and will display the following two lines −
Opened database successfully Table created successfully
INSERT Operation
The following Java program shows how we can create records in our COMPANY table created in above example −
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main(String args[]) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://localhost:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (1, 'Paul', 32, 'California', 20000.00 );";
stmt.executeUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (2, 'Allen', 25, 'Texas', 15000.00 );";
stmt.executeUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );";
stmt.executeUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );";
stmt.executeUpdate(sql);
stmt.close();
c.commit();
c.close();
} catch (Exception e) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Records created successfully");
}
}
When the above program is compiled and executed, it will create given records in COMPANY table and will display the following two lines −
Opened database successfully Records created successfully
SELECT Operation
The following Java program shows how we can fetch and display records from our COMPANY table created in above example −
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main( String args[] ) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://localhost:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" );
while ( rs.next() ) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String address = rs.getString("address");
float salary = rs.getFloat("salary");
System.out.println( "ID = " + id );
System.out.println( "NAME = " + name );
System.out.println( "AGE = " + age );
System.out.println( "ADDRESS = " + address );
System.out.println( "SALARY = " + salary );
System.out.println();
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Operation done successfully");
}
}
When the program is compiled and executed, it will produce the following result −
Opened database successfully ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 20000.0 ID = 2 NAME = Allen AGE = 25 ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
UPDATE Operation
The following Java code shows how we can use the UPDATE statement to update any record and then fetch and display updated records from our COMPANY table −
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main( String args[] ) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://localhost:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "UPDATE COMPANY set SALARY = 25000.00 where ID=1;";
stmt.executeUpdate(sql);
c.commit();
ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" );
while ( rs.next() ) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String address = rs.getString("address");
float salary = rs.getFloat("salary");
System.out.println( "ID = " + id );
System.out.println( "NAME = " + name );
System.out.println( "AGE = " + age );
System.out.println( "ADDRESS = " + address );
System.out.println( "SALARY = " + salary );
System.out.println();
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Operation done successfully");
}
}
When the program is compiled and executed, it will produce the following result −
Opened database successfully ID = 2 NAME = Allen AGE = 25 ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 25000.0 Operation done successfully
DELETE Operation
The following Java code shows how we can use the DELETE statement to delete any record and then fetch and display remaining records from our COMPANY table −
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PostgreSQLJDBC6 {
public static void main( String args[] ) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://localhost:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "DELETE from COMPANY where ID = 2;";
stmt.executeUpdate(sql);
c.commit();
ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" );
while ( rs.next() ) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String address = rs.getString("address");
float salary = rs.getFloat("salary");
System.out.println( "ID = " + id );
System.out.println( "NAME = " + name );
System.out.println( "AGE = " + age );
System.out.println( "ADDRESS = " + address );
System.out.println( "SALARY = " + salary );
System.out.println();
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Operation done successfully");
}
}
When the program is compiled and executed, it will produce the following result −
Opened database successfully ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 25000.0 Operation done successfully
PostgreSQL — PHP Interface
Installation
The PostgreSQL extension is enabled by default in the latest releases of PHP 5.3.x. It is possible to disable it by using —without-pgsql at compile time. Still you can use yum command to install PHP -PostgreSQL interface −
yum install php-pgsql
Before you start using the PHP PostgreSQL interface, find the pg_hba.conf file in your PostgreSQL installation directory and add the following line −
# IPv4 local connections: host all all 127.0.0.1/32 md5
You can start/restart the postgres server, in case it is not running, using the following command −
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
Windows users must enable php_pgsql.dll in order to use this extension. This DLL is included with Windows distributions in the latest releases of PHP 5.3.x
For detailed installation instructions, kindly check our PHP tutorial and its official website.
PHP Interface APIs
The following are important PHP routines, which can suffice your requirement to work with PostgreSQL database from your PHP program. If you are looking for a more sophisticated application, then you can look into the PHP official documentation.
| S. No. | API & Description |
|---|---|
| 1 |
resource pg_connect ( string $connection_string [, int $connect_type ] ) This opens a connection to a PostgreSQL database specified by the connection_string. If PGSQL_CONNECT_FORCE_NEW is passed as connect_type, then a new connection is created in case of a second call to pg_connect(), even if the connection_string is identical to an existing connection. |
| 2 |
bool pg_connection_reset ( resource $connection ) This routine resets the connection. It is useful for error recovery. Returns TRUE on success or FALSE on failure. |
| 3 |
int pg_connection_status ( resource $connection ) This routine returns the status of the specified connection. Returns PGSQL_CONNECTION_OK or PGSQL_CONNECTION_BAD. |
| 4 |
string pg_dbname ([ resource $connection ] ) This routine returns the name of the database that the given PostgreSQL connection resource. |
| 5 |
resource pg_prepare ([ resource $connection ], string $stmtname, string $query ) This submits a request to create a prepared statement with the given parameters and waits for completion. |
| 6 |
resource pg_execute ([ resource $connection ], string $stmtname, array $params ) This routine sends a request to execute a prepared statement with given parameters and waits for the result. |
| 7 |
resource pg_query ([ resource $connection ], string $query ) This routine executes the query on the specified database connection. |
| 8 |
array pg_fetch_row ( resource $result [, int $row ] ) This routine fetches one row of data from the result associated with the specified result resource. |
| 9 |
array pg_fetch_all ( resource $result ) This routine returns an array that contains all rows (records) in the result resource. |
| 10 |
int pg_affected_rows ( resource $result ) This routine returns the number of rows affected by INSERT, UPDATE, and DELETE queries. |
| 11 |
int pg_num_rows ( resource $result ) This routine returns the number of rows in a PostgreSQL result resource for example number of rows returned by SELECT statement. |
| 12 |
bool pg_close ([ resource $connection ] ) This routine closes the non-persistent connection to a PostgreSQL database associated with the given connection resource. |
| 13 |
string pg_last_error ([ resource $connection ] ) This routine returns the last error message for a given connection. |
| 14 |
string pg_escape_literal ([ resource $connection ], string $data ) This routine escapes a literal for insertion into a text field. |
| 15 |
string pg_escape_string ([ resource $connection ], string $data ) This routine escapes a string for querying the database. |
Connecting to Database
The following PHP code shows how to connect to an existing database on a local machine and finally a database connection object will be returned.
<?php
$host = "host = 127.0.0.1";
$port = "port = 5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open databasen";
} else {
echo "Opened database successfullyn";
}
?>
Now, let us run the above given program to open our database testdb: if the database is successfully opened, then it will give the following message −
Opened database successfully
Create a Table
The following PHP program will be used to create a table in a previously created database −
<?php
$host = "host = 127.0.0.1";
$port = "port = 5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open databasen";
} else {
echo "Opened database successfullyn";
}
$sql =<<<EOF
CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
} else {
echo "Table created successfullyn";
}
pg_close($db);
?>
When the above given program is executed, it will create COMPANY table in your testdb and it will display the following messages −
Opened database successfully Table created successfully
INSERT Operation
The following PHP program shows how we can create records in our COMPANY table created in above example −
<?php
$host = "host=127.0.0.1";
$port = "port=5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open databasen";
} else {
echo "Opened database successfullyn";
}
$sql =<<<EOF
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Paul', 32, 'California', 20000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
} else {
echo "Records created successfullyn";
}
pg_close($db);
?>
When the above given program is executed, it will create the given records in COMPANY table and will display the following two lines −
Opened database successfully Records created successfully
SELECT Operation
The following PHP program shows how we can fetch and display records from our COMPANY table created in above example −
<?php
$host = "host = 127.0.0.1";
$port = "port = 5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open databasen";
} else {
echo "Opened database successfullyn";
}
$sql =<<<EOF
SELECT * from COMPANY;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
}
while($row = pg_fetch_row($ret)) {
echo "ID = ". $row[0] . "n";
echo "NAME = ". $row[1] ."n";
echo "ADDRESS = ". $row[2] ."n";
echo "SALARY = ".$row[4] ."nn";
}
echo "Operation done successfullyn";
pg_close($db);
?>
When the above given program is executed, it will produce the following result. Keep a note that fields are returned in the sequence they were used while creating table.
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
UPDATE Operation
The following PHP code shows how we can use the UPDATE statement to update any record and then fetch and display updated records from our COMPANY table −
<?php
$host = "host=127.0.0.1";
$port = "port=5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open databasen";
} else {
echo "Opened database successfullyn";
}
$sql =<<<EOF
UPDATE COMPANY set SALARY = 25000.00 where ID=1;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
} else {
echo "Record updated successfullyn";
}
$sql =<<<EOF
SELECT * from COMPANY;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
}
while($row = pg_fetch_row($ret)) {
echo "ID = ". $row[0] . "n";
echo "NAME = ". $row[1] ."n";
echo "ADDRESS = ". $row[2] ."n";
echo "SALARY = ".$row[4] ."nn";
}
echo "Operation done successfullyn";
pg_close($db);
?>
When the above given program is executed, it will produce the following result −
Opened database successfully Record updated successfully ID = 2 NAME = Allen ADDRESS = 25 SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = 23 SALARY = 20000 ID = 4 NAME = Mark ADDRESS = 25 SALARY = 65000 ID = 1 NAME = Paul ADDRESS = 32 SALARY = 25000 Operation done successfully
DELETE Operation
The following PHP code shows how we can use the DELETE statement to delete any record and then fetch and display the remaining records from our COMPANY table −
<?php
$host = "host = 127.0.0.1";
$port = "port = 5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open databasen";
} else {
echo "Opened database successfullyn";
}
$sql =<<<EOF
DELETE from COMPANY where ID=2;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
} else {
echo "Record deleted successfullyn";
}
$sql =<<<EOF
SELECT * from COMPANY;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
}
while($row = pg_fetch_row($ret)) {
echo "ID = ". $row[0] . "n";
echo "NAME = ". $row[1] ."n";
echo "ADDRESS = ". $row[2] ."n";
echo "SALARY = ".$row[4] ."nn";
}
echo "Operation done successfullyn";
pg_close($db);
?>
When the above given program is executed, it will produce the following result −
Opened database successfully Record deleted successfully ID = 3 NAME = Teddy ADDRESS = 23 SALARY = 20000 ID = 4 NAME = Mark ADDRESS = 25 SALARY = 65000 ID = 1 NAME = Paul ADDRESS = 32 SALARY = 25000 Operation done successfully
PostgreSQL — Perl Interface
Installation
The PostgreSQL can be integrated with Perl using Perl DBI module, which is a database access module for the Perl programming language. It defines a set of methods, variables and conventions that provide a standard database interface.
Here are simple steps to install DBI module on your Linux/Unix machine −
$ wget http://search.cpan.org/CPAN/authors/id/T/TI/TIMB/DBI-1.625.tar.gz $ tar xvfz DBI-1.625.tar.gz $ cd DBI-1.625 $ perl Makefile.PL $ make $ make install
If you need to install SQLite driver for DBI, then it can be installed as follows −
$ wget http://search.cpan.org/CPAN/authors/id/T/TU/TURNSTEP/DBD-Pg-2.19.3.tar.gz $ tar xvfz DBD-Pg-2.19.3.tar.gz $ cd DBD-Pg-2.19.3 $ perl Makefile.PL $ make $ make install
Before you start using Perl PostgreSQL interface, find the pg_hba.conf file in your PostgreSQL installation directory and add the following line −
# IPv4 local connections: host all all 127.0.0.1/32 md5
You can start/restart the postgres server, in case it is not running, using the following command −
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
DBI Interface APIs
Following are the important DBI routines, which can suffice your requirement to work with SQLite database from your Perl program. If you are looking for a more sophisticated application, then you can look into Perl DBI official documentation.
| S. No. | API & Description |
|---|---|
| 1 |
DBI→connect($data_source, «userid», «password», %attr) Establishes a database connection, or session, to the requested $data_source. Returns a database handle object if the connection succeeds. Datasource has the form like : DBI:Pg:dbname=$database;host=127.0.0.1;port=5432 Pg is PostgreSQL driver name and testdb is the name of database. |
| 2 |
$dbh→do($sql) This routine prepares and executes a single SQL statement. Returns the number of rows affected or undef on error. A return value of -1 means the number of rows is not known, not applicable, or not available. Here $dbh is a handle returned by DBI→connect() call. |
| 3 |
$dbh→prepare($sql) This routine prepares a statement for later execution by the database engine and returns a reference to a statement handle object. |
| 4 |
$sth→execute() This routine performs whatever processing is necessary to execute the prepared statement. An undef is returned if an error occurs. A successful execute always returns true regardless of the number of rows affected. Here $sth is a statement handle returned by $dbh→prepare($sql) call. |
| 5 |
$sth→fetchrow_array() This routine fetches the next row of data and returns it as a list containing the field values. Null fields are returned as undef values in the list. |
| 6 |
$DBI::err This is equivalent to $h→err, where $h is any of the handle types like $dbh, $sth, or $drh. This returns native database engine error code from the last driver method called. |
| 7 |
$DBI::errstr This is equivalent to $h→errstr, where $h is any of the handle types like $dbh, $sth, or $drh. This returns the native database engine error message from the last DBI method called. |
| 8 |
$dbh->disconnect() This routine closes a database connection previously opened by a call to DBI→connect(). |
Connecting to Database
The following Perl code shows how to connect to an existing database. If the database does not exist, then it will be created and finally a database object will be returned.
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfullyn";
Now, let us run the above given program to open our database testdb; if the database is successfully opened then it will give the following message −
Open database successfully
Create a Table
The following Perl program will be used to create a table in previously created database −
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname=$database;host=127.0.0.1;port=5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfullyn";
my $stmt = qq(CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL););
my $rv = $dbh->do($stmt);
if($rv < 0) {
print $DBI::errstr;
} else {
print "Table created successfullyn";
}
$dbh->disconnect();
When the above given program is executed, it will create COMPANY table in your testdb and it will display the following messages −
Opened database successfully Table created successfully
INSERT Operation
The following Perl program shows how we can create records in our COMPANY table created in above example −
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfullyn";
my $stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Paul', 32, 'California', 20000.00 ));
my $rv = $dbh->do($stmt) or die $DBI::errstr;
$stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 ));
$rv = $dbh->do($stmt) or die $DBI::errstr;
$stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 ));
$rv = $dbh->do($stmt) or die $DBI::errstr;
$stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 ););
$rv = $dbh->do($stmt) or die $DBI::errstr;
print "Records created successfullyn";
$dbh->disconnect();
When the above given program is executed, it will create given records in COMPANY table and will display the following two lines −
Opened database successfully Records created successfully
SELECT Operation
The following Perl program shows how we can fetch and display records from our COMPANY table created in above example −
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfullyn";
my $stmt = qq(SELECT id, name, address, salary from COMPANY;);
my $sth = $dbh->prepare( $stmt );
my $rv = $sth->execute() or die $DBI::errstr;
if($rv < 0) {
print $DBI::errstr;
}
while(my @row = $sth->fetchrow_array()) {
print "ID = ". $row[0] . "n";
print "NAME = ". $row[1] ."n";
print "ADDRESS = ". $row[2] ."n";
print "SALARY = ". $row[3] ."nn";
}
print "Operation done successfullyn";
$dbh->disconnect();
When the above given program is executed, it will produce the following result −
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
UPDATE Operation
The following Perl code shows how we can use the UPDATE statement to update any record and then fetch and display updated records from our COMPANY table −
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfullyn";
my $stmt = qq(UPDATE COMPANY set SALARY = 25000.00 where ID=1;);
my $rv = $dbh->do($stmt) or die $DBI::errstr;
if( $rv < 0 ) {
print $DBI::errstr;
}else{
print "Total number of rows updated : $rvn";
}
$stmt = qq(SELECT id, name, address, salary from COMPANY;);
my $sth = $dbh->prepare( $stmt );
$rv = $sth->execute() or die $DBI::errstr;
if($rv < 0) {
print $DBI::errstr;
}
while(my @row = $sth->fetchrow_array()) {
print "ID = ". $row[0] . "n";
print "NAME = ". $row[1] ."n";
print "ADDRESS = ". $row[2] ."n";
print "SALARY = ". $row[3] ."nn";
}
print "Operation done successfullyn";
$dbh->disconnect();
When the above given program is executed, it will produce the following result −
Opened database successfully Total number of rows updated : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
DELETE Operation
The following Perl code shows how we can use the DELETE statement to delete any record and then fetch and display the remaining records from our COMPANY table −
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfullyn";
my $stmt = qq(DELETE from COMPANY where ID=2;);
my $rv = $dbh->do($stmt) or die $DBI::errstr;
if( $rv < 0 ) {
print $DBI::errstr;
} else{
print "Total number of rows deleted : $rvn";
}
$stmt = qq(SELECT id, name, address, salary from COMPANY;);
my $sth = $dbh->prepare( $stmt );
$rv = $sth->execute() or die $DBI::errstr;
if($rv < 0) {
print $DBI::errstr;
}
while(my @row = $sth->fetchrow_array()) {
print "ID = ". $row[0] . "n";
print "NAME = ". $row[1] ."n";
print "ADDRESS = ". $row[2] ."n";
print "SALARY = ". $row[3] ."nn";
}
print "Operation done successfullyn";
$dbh->disconnect();
When the above given program is executed, it will produce the following result −
Opened database successfully Total number of rows deleted : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
PostgreSQL — Python Interface
Installation
The PostgreSQL can be integrated with Python using psycopg2 module. sycopg2 is a PostgreSQL database adapter for the Python programming language. psycopg2 was written with the aim of being very small and fast, and stable as a rock. You do not need to install this module separately because it is shipped, by default, along with Python version 2.5.x onwards.
If you do not have it installed on your machine then you can use yum command to install it as follows −
$yum install python-psycopg2
To use psycopg2 module, you must first create a Connection object that represents the database and then optionally you can create cursor object which will help you in executing all the SQL statements.
Python psycopg2 module APIs
The following are important psycopg2 module routines, which can suffice your requirement to work with PostgreSQL database from your Python program. If you are looking for a more sophisticated application, then you can look into Python psycopg2 module’s official documentation.
| S. No. | API & Description |
|---|---|
| 1 |
psycopg2.connect(database=»testdb», user=»postgres», password=»cohondob», host=»127.0.0.1″, port=»5432″) This API opens a connection to the PostgreSQL database. If database is opened successfully, it returns a connection object. |
| 2 |
connection.cursor() This routine creates a cursor which will be used throughout of your database programming with Python. |
| 3 |
cursor.execute(sql [, optional parameters]) This routine executes an SQL statement. The SQL statement may be parameterized (i.e., placeholders instead of SQL literals). The psycopg2 module supports placeholder using %s sign For example:cursor.execute(«insert into people values (%s, %s)», (who, age)) |
| 4 |
cursor.executemany(sql, seq_of_parameters) This routine executes an SQL command against all parameter sequences or mappings found in the sequence sql. |
| 5 |
cursor.callproc(procname[, parameters]) This routine executes a stored database procedure with the given name. The sequence of parameters must contain one entry for each argument that the procedure expects. |
| 6 |
cursor.rowcount This read-only attribute which returns the total number of database rows that have been modified, inserted, or deleted by the last last execute*(). |
| 7 |
connection.commit() This method commits the current transaction. If you do not call this method, anything you did since the last call to commit() is not visible from other database connections. |
| 8 |
connection.rollback() This method rolls back any changes to the database since the last call to commit(). |
| 9 |
connection.close() This method closes the database connection. Note that this does not automatically call commit(). If you just close your database connection without calling commit() first, your changes will be lost! |
| 10 |
cursor.fetchone() This method fetches the next row of a query result set, returning a single sequence, or None when no more data is available. |
| 11 |
cursor.fetchmany([size=cursor.arraysize]) This routine fetches the next set of rows of a query result, returning a list. An empty list is returned when no more rows are available. The method tries to fetch as many rows as indicated by the size parameter. |
| 12 |
cursor.fetchall() This routine fetches all (remaining) rows of a query result, returning a list. An empty list is returned when no rows are available. |
Connecting to Database
The following Python code shows how to connect to an existing database. If the database does not exist, then it will be created and finally a database object will be returned.
#!/usr/bin/python import psycopg2 conn = psycopg2.connect(database="testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432") print "Opened database successfully"
Here, you can also supply database testdb as name and if database is successfully opened, then it will give the following message −
Open database successfully
Create a Table
The following Python program will be used to create a table in previously created database −
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute('''CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);''')
print "Table created successfully"
conn.commit()
conn.close()
When the above given program is executed, it will create COMPANY table in your test.db and it will display the following messages −
Opened database successfully Table created successfully
INSERT Operation
The following Python program shows how we can create records in our COMPANY table created in the above example −
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Paul', 32, 'California', 20000.00 )");
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 )");
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )");
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )");
conn.commit()
print "Records created successfully";
conn.close()
When the above given program is executed, it will create given records in COMPANY table and will display the following two lines −
Opened database successfully Records created successfully
SELECT Operation
The following Python program shows how we can fetch and display records from our COMPANY table created in the above example −
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()
for row in rows:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "n"
print "Operation done successfully";
conn.close()
When the above given program is executed, it will produce the following result −
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000.0 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
UPDATE Operation
The following Python code shows how we can use the UPDATE statement to update any record and then fetch and display updated records from our COMPANY table −
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("UPDATE COMPANY set SALARY = 25000.00 where ID = 1")
conn.commit()
print "Total number of rows updated :", cur.rowcount
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()
for row in rows:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "n"
print "Operation done successfully";
conn.close()
When the above given program is executed, it will produce the following result −
Opened database successfully Total number of rows updated : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000.0 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
DELETE Operation
The following Python code shows how we can use the DELETE statement to delete any record and then fetch and display the remaining records from our COMPANY table −
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("DELETE from COMPANY where ID=2;")
conn.commit()
print "Total number of rows deleted :", cur.rowcount
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()
for row in rows:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "n"
print "Operation done successfully";
conn.close()
When the above given program is executed, it will produce the following result −
Opened database successfully Total number of rows deleted : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 20000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
Работа с PostgreSQL не отличается от работы с любой другой СУБД, но знать синтаксис все-таки полезно. Предлагаем вашему вниманию вводный курс по основам.
PostgreSQL – это опенсорсная реляционная СУБД. В статье будет рассматриваться процесс установки, настройки / управления, а также базовые операции с БД.
Установка
Если на вашей машине стоит MacOS, то процесс установки можно запустить командой:
brew install postgresql
На Linux СУБД устанавливается так:
sudo apt-get install postgresql postgresql-contrib
Если у вас другая ОС, есть непонятные моменты или вопросы – обращайтесь в официальный хелп.
После того, как все загружено и установлено, можно проверить, все ли в порядке, и какая стоит версия PostgreSQL. Для этого выполните следующую команду:
postgres --version
Разбираемся с настройками
Работа с PostgreSQL может быть произведена через командную строку (терминал) с использованием утилиты psql – инструмент командной строки PostgreSQL. Попробуйте ввести следующую команду:
psql postgres (для выхода из интерфейса используйте q)
Этой командой вы запустите утилиту psql. Хотя есть много сторонних инструментов для администрирования PostgreSQL, нет необходимости их устанавливать, т. к. psql удобен и отлично работает.
Если вам нужна помощь, введите help (или -h) в psql-терминале. Появится список всех доступных параметров справки. Вы можете ввести help [имя команды], если вам нужна помощь по конкретной команде. Например, если ввести help UPDATE в консоли psql, вы увидите синтаксис команды update.
Description: update rows of a table
[ WITH [ RECURSIVE ] with_query [, ...] ]
UPDATE [ ONLY ] table_name [ * ] [ [ AS ] alias ]
SET { column_name = { expression | DEFAULT } |
( column_name [, ...] ) = ( { expression | DEFAULT } [, ...] ) |
( column_name [, ...] ) = ( sub-SELECT )
} [, ...]
[ FROM from_list ]
[ WHERE condition | WHERE CURRENT OF cursor_name ]
[ RETURNING * | output_expression [ [ AS ] output_name ] [, ...] ]
Если у вас возникает много вопросов – не стоит отчаиваться. Поиск в интернете предоставит массу примеров, ну и официальную документацию psql никто не отменял.
Первым делом необходимо проверить наличие существующих пользователей и баз данных. Выполните следующую команду, чтобы вывести список всех баз данных:
list или l

На рисунке выше вы видите три базы данных по умолчанию и суперпользователя postgres, которые создаются при установке PostgreSQL.
Чтобы вывести список всех пользователей, выполните команду du. Атрибуты пользователя postgres говорят нам, что он суперпользователь.

Основные операции с БД
Чтобы выполнять базовые действия в СУБД, нужно знать Structured Query Language (SQL).
Создание базы данных
Для создания базы данных используется команда create database. В приведенном ниже примере создается база данных с именем proglib_db.

Если вы забыли точку с запятой в конце запроса, знак «=» в приглашении postgres заменяется на «-», как показано на рисунке ниже. Это зачастую указывает на то, что необходимо завершить (дописать) запрос.

На картинке нам сообщают об ошибке из-за того, что в нашем случае база уже создана. Вы поймете, что к чему, когда начнете писать более длинные запросы.
Создание нового юзера
Для создания пользователя существует команда create user. В приведенном ниже примере создается пользователь с именем author.

При создании пользователя отобразится сообщение CREATE ROLE. Каждый пользователь имеет свои права (доступ к базам, редактирование, создание БД / пользователей и т. д.). Вы могли заметить, что столбец Attributes для пользователя author пуст. Это означает, что пользователь author не имеет прав администратора. Он может только читать данные и не может создать другого пользователя или базу.
Вы можете установить пароль для существующего пользователя. С этой задачей справится команда password:
postgres=#password author
Чтобы задать пароль при создании пользователя, можно использовать следующую команду:
postgres=#create user author with login password 'qwerty';
Удаление базы или пользователя
Для этой операции используется команда drop: она умеет удалять как пользователя, так и БД.
drop database <database_name> drop user <user_name>
Данную команду нужно использовать очень осторожно, иначе удаленные данные будут потеряны, а восстановить их можно только из бэкапа (если он был).
Если вы укажете psql postgres (без имени пользователя), то postgreSQL пустит вас под стандартным суперюзером (postgres). Чтобы войти в базу данных под определенным пользователем, можно использовать следующую команду:
psql [database_name] [user_name]
Давайте войдем в базу proglib_db под пользователем author. Нажмите q, чтобы выйти из текущей БД, а затем выполните следующую команду:

Дополнительная литература
- Beginning PostgreSQL on the Cloud. Работа с PostgreSQL начинается с этой книги. Приступать к изучению чего-то нового лучше с практики. Эта публикация включает в себя огромное количество полезных рабочих примеров, взятых из реальных проектов.
- Администрирование PostgreSQL 9. Книга рецептов. Отличная настольная книга для разработчиков боевых проектов на PHP, Ruby, .NET, Java и Python. Рассматриваются распространенные общие вопросы по архитектуре, восстановлению, репликации и т. д.
- Семь баз данных за семь недель. Данная книга подойдет для общего развития специалиста с любым уровнем знаний. Автор рассказывает об организации каждой СУБД, а также о том, в каком случае выгодно выбрать ту или иную БД.
Надеемся, что наш небольшой туториал помог вам разобраться с основами.
Работа с PostgreSQL не так страшна, как кажется. Удачи в изучении!
Оригинал
Другие материалы по теме:
- 5 лучших материалов по PostgreSQL
- Подборка материалов для изучения баз данных и SQL
- О языке SQL на примере SQLite, MySQL и PostgreSQL