Eager to get started? This page gives a good introduction in how to get started
with Requests.
First, make sure that:
-
Requests is installed
-
Requests is up-to-date
Let’s get started with some simple examples.
Make a Request¶
Making a request with Requests is very simple.
Begin by importing the Requests module:
Now, let’s try to get a webpage. For this example, let’s get GitHub’s public
timeline:
>>> r = requests.get('https://api.github.com/events')
Now, we have a Response object called r. We can
get all the information we need from this object.
Requests’ simple API means that all forms of HTTP request are as obvious. For
example, this is how you make an HTTP POST request:
>>> r = requests.post('https://httpbin.org/post', data={'key': 'value'})
Nice, right? What about the other HTTP request types: PUT, DELETE, HEAD and
OPTIONS? These are all just as simple:
>>> r = requests.put('https://httpbin.org/put', data={'key': 'value'}) >>> r = requests.delete('https://httpbin.org/delete') >>> r = requests.head('https://httpbin.org/get') >>> r = requests.options('https://httpbin.org/get')
That’s all well and good, but it’s also only the start of what Requests can
do.
Passing Parameters In URLs¶
You often want to send some sort of data in the URL’s query string. If
you were constructing the URL by hand, this data would be given as key/value
pairs in the URL after a question mark, e.g. httpbin.org/get?key=val.
Requests allows you to provide these arguments as a dictionary of strings,
using the params keyword argument. As an example, if you wanted to pass
key1=value1 and key2=value2 to httpbin.org/get, you would use the
following code:
>>> payload = {'key1': 'value1', 'key2': 'value2'} >>> r = requests.get('https://httpbin.org/get', params=payload)
You can see that the URL has been correctly encoded by printing the URL:
>>> print(r.url) https://httpbin.org/get?key2=value2&key1=value1
Note that any dictionary key whose value is None will not be added to the
URL’s query string.
You can also pass a list of items as a value:
>>> payload = {'key1': 'value1', 'key2': ['value2', 'value3']} >>> r = requests.get('https://httpbin.org/get', params=payload) >>> print(r.url) https://httpbin.org/get?key1=value1&key2=value2&key2=value3
Response Content¶
We can read the content of the server’s response. Consider the GitHub timeline
again:
>>> import requests >>> r = requests.get('https://api.github.com/events') >>> r.text '[{"repository":{"open_issues":0,"url":"https://github.com/...
Requests will automatically decode content from the server. Most unicode
charsets are seamlessly decoded.
When you make a request, Requests makes educated guesses about the encoding of
the response based on the HTTP headers. The text encoding guessed by Requests
is used when you access r.text. You can find out what encoding Requests is
using, and change it, using the r.encoding property:
>>> r.encoding 'utf-8' >>> r.encoding = 'ISO-8859-1'
If you change the encoding, Requests will use the new value of r.encoding
whenever you call r.text. You might want to do this in any situation where
you can apply special logic to work out what the encoding of the content will
be. For example, HTML and XML have the ability to specify their encoding in
their body. In situations like this, you should use r.content to find the
encoding, and then set r.encoding. This will let you use r.text with
the correct encoding.
Requests will also use custom encodings in the event that you need them. If
you have created your own encoding and registered it with the codecs
module, you can simply use the codec name as the value of r.encoding and
Requests will handle the decoding for you.
Binary Response Content¶
You can also access the response body as bytes, for non-text requests:
>>> r.content b'[{"repository":{"open_issues":0,"url":"https://github.com/...
The gzip and deflate transfer-encodings are automatically decoded for you.
The br transfer-encoding is automatically decoded for you if a Brotli library
like brotli or brotlicffi is installed.
For example, to create an image from binary data returned by a request, you can
use the following code:
>>> from PIL import Image >>> from io import BytesIO >>> i = Image.open(BytesIO(r.content))
JSON Response Content¶
There’s also a builtin JSON decoder, in case you’re dealing with JSON data:
>>> import requests >>> r = requests.get('https://api.github.com/events') >>> r.json() [{'repository': {'open_issues': 0, 'url': 'https://github.com/...
In case the JSON decoding fails, r.json() raises an exception. For example, if
the response gets a 204 (No Content), or if the response contains invalid JSON,
attempting r.json() raises requests.exceptions.JSONDecodeError. This wrapper exception
provides interoperability for multiple exceptions that may be thrown by different
python versions and json serialization libraries.
It should be noted that the success of the call to r.json() does not
indicate the success of the response. Some servers may return a JSON object in a
failed response (e.g. error details with HTTP 500). Such JSON will be decoded
and returned. To check that a request is successful, use
r.raise_for_status() or check r.status_code is what you expect.
Raw Response Content¶
In the rare case that you’d like to get the raw socket response from the
server, you can access r.raw. If you want to do this, make sure you set
stream=True in your initial request. Once you do, you can do this:
>>> r = requests.get('https://api.github.com/events', stream=True) >>> r.raw <urllib3.response.HTTPResponse object at 0x101194810> >>> r.raw.read(10) b'x1fx8bx08x00x00x00x00x00x00x03'
In general, however, you should use a pattern like this to save what is being
streamed to a file:
with open(filename, 'wb') as fd: for chunk in r.iter_content(chunk_size=128): fd.write(chunk)
Using Response.iter_content will handle a lot of what you would otherwise
have to handle when using Response.raw directly. When streaming a
download, the above is the preferred and recommended way to retrieve the
content. Note that chunk_size can be freely adjusted to a number that
may better fit your use cases.
Note
An important note about using Response.iter_content versus Response.raw.
Response.iter_content will automatically decode the gzip and deflate
transfer-encodings. Response.raw is a raw stream of bytes – it does not
transform the response content. If you really need access to the bytes as they
were returned, use Response.raw.
More complicated POST requests¶
Typically, you want to send some form-encoded data — much like an HTML form.
To do this, simply pass a dictionary to the data argument. Your
dictionary of data will automatically be form-encoded when the request is made:
>>> payload = {'key1': 'value1', 'key2': 'value2'} >>> r = requests.post('https://httpbin.org/post', data=payload) >>> print(r.text) { ... "form": { "key2": "value2", "key1": "value1" }, ... }
The data argument can also have multiple values for each key. This can be
done by making data either a list of tuples or a dictionary with lists
as values. This is particularly useful when the form has multiple elements that
use the same key:
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')] >>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples) >>> payload_dict = {'key1': ['value1', 'value2']} >>> r2 = requests.post('https://httpbin.org/post', data=payload_dict) >>> print(r1.text) { ... "form": { "key1": [ "value1", "value2" ] }, ... } >>> r1.text == r2.text True
There are times that you may want to send data that is not form-encoded. If
you pass in a string instead of a dict, that data will be posted directly.
For example, the GitHub API v3 accepts JSON-Encoded POST/PATCH data:
>>> import json >>> url = 'https://api.github.com/some/endpoint' >>> payload = {'some': 'data'} >>> r = requests.post(url, data=json.dumps(payload))
Please note that the above code will NOT add the Content-Type header
(so in particular it will NOT set it to application/json).
If you need that header set and you don’t want to encode the dict yourself,
you can also pass it directly using the json parameter (added in version 2.4.2)
and it will be encoded automatically:
>>> url = 'https://api.github.com/some/endpoint' >>> payload = {'some': 'data'}
>>> r = requests.post(url, json=payload)
Note, the json parameter is ignored if either data or files is passed.
POST a Multipart-Encoded File¶
Requests makes it simple to upload Multipart-encoded files:
>>> url = 'https://httpbin.org/post' >>> files = {'file': open('report.xls', 'rb')} >>> r = requests.post(url, files=files) >>> r.text { ... "files": { "file": "<censored...binary...data>" }, ... }
You can set the filename, content_type and headers explicitly:
>>> url = 'https://httpbin.org/post' >>> files = {'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})} >>> r = requests.post(url, files=files) >>> r.text { ... "files": { "file": "<censored...binary...data>" }, ... }
If you want, you can send strings to be received as files:
>>> url = 'https://httpbin.org/post' >>> files = {'file': ('report.csv', 'some,data,to,sendnanother,row,to,sendn')} >>> r = requests.post(url, files=files) >>> r.text { ... "files": { "file": "some,data,to,send\nanother,row,to,send\n" }, ... }
In the event you are posting a very large file as a multipart/form-data
request, you may want to stream the request. By default, requests does not
support this, but there is a separate package which does —
requests-toolbelt. You should read the toolbelt’s documentation for more details about how to use it.
For sending multiple files in one request refer to the advanced
section.
Warning
It is strongly recommended that you open files in binary
mode. This is because Requests may attempt to provide
the Content-Length header for you, and if it does this value
will be set to the number of bytes in the file. Errors may occur
if you open the file in text mode.
Response Status Codes¶
We can check the response status code:
>>> r = requests.get('https://httpbin.org/get') >>> r.status_code 200
Requests also comes with a built-in status code lookup object for easy
reference:
>>> r.status_code == requests.codes.ok True
If we made a bad request (a 4XX client error or 5XX server error response), we
can raise it with
Response.raise_for_status():
>>> bad_r = requests.get('https://httpbin.org/status/404') >>> bad_r.status_code 404 >>> bad_r.raise_for_status() Traceback (most recent call last): File "requests/models.py", line 832, in raise_for_status raise http_error requests.exceptions.HTTPError: 404 Client Error
But, since our status_code for r was 200, when we call
raise_for_status() we get:
>>> r.raise_for_status() None
All is well.
Cookies¶
If a response contains some Cookies, you can quickly access them:
>>> url = 'http://example.com/some/cookie/setting/url' >>> r = requests.get(url) >>> r.cookies['example_cookie_name'] 'example_cookie_value'
To send your own cookies to the server, you can use the cookies
parameter:
>>> url = 'https://httpbin.org/cookies' >>> cookies = dict(cookies_are='working') >>> r = requests.get(url, cookies=cookies) >>> r.text '{"cookies": {"cookies_are": "working"}}'
Cookies are returned in a RequestsCookieJar,
which acts like a dict but also offers a more complete interface,
suitable for use over multiple domains or paths. Cookie jars can
also be passed in to requests:
>>> jar = requests.cookies.RequestsCookieJar() >>> jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies') >>> jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/elsewhere') >>> url = 'https://httpbin.org/cookies' >>> r = requests.get(url, cookies=jar) >>> r.text '{"cookies": {"tasty_cookie": "yum"}}'
Redirection and History¶
By default Requests will perform location redirection for all verbs except
HEAD.
We can use the history property of the Response object to track redirection.
The Response.history list contains the
Response objects that were created in order to
complete the request. The list is sorted from the oldest to the most recent
response.
For example, GitHub redirects all HTTP requests to HTTPS:
>>> r = requests.get('http://github.com/') >>> r.url 'https://github.com/' >>> r.status_code 200 >>> r.history [<Response [301]>]
If you’re using GET, OPTIONS, POST, PUT, PATCH or DELETE, you can disable
redirection handling with the allow_redirects parameter:
>>> r = requests.get('http://github.com/', allow_redirects=False) >>> r.status_code 301 >>> r.history []
If you’re using HEAD, you can enable redirection as well:
>>> r = requests.head('http://github.com/', allow_redirects=True) >>> r.url 'https://github.com/' >>> r.history [<Response [301]>]
Timeouts¶
You can tell Requests to stop waiting for a response after a given number of
seconds with the timeout parameter. Nearly all production code should use
this parameter in nearly all requests. Failure to do so can cause your program
to hang indefinitely:
>>> requests.get('https://github.com/', timeout=0.001) Traceback (most recent call last): File "<stdin>", line 1, in <module> requests.exceptions.Timeout: HTTPConnectionPool(host='github.com', port=80): Request timed out. (timeout=0.001)
Note
timeout is not a time limit on the entire response download;
rather, an exception is raised if the server has not issued a
response for timeout seconds (more precisely, if no bytes have been
received on the underlying socket for timeout seconds). If no timeout is specified explicitly, requests do
not time out.
Errors and Exceptions¶
In the event of a network problem (e.g. DNS failure, refused connection, etc),
Requests will raise a ConnectionError exception.
Response.raise_for_status() will
raise an HTTPError if the HTTP request
returned an unsuccessful status code.
If a request times out, a Timeout exception is
raised.
If a request exceeds the configured number of maximum redirections, a
TooManyRedirects exception is raised.
All exceptions that Requests explicitly raises inherit from
requests.exceptions.RequestException.
Ready for more? Check out the advanced section.
If you’re on the job market, consider taking this programming quiz. A substantial donation will be made to this project, if you find a job through this platform.
#статьи
- 12 апр 2023
-

0
Разбираемся в методах работы с HTTP-запросами в Python на практике.
Иллюстрация: Катя Павловская для Skillbox Media

Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Библиотека Requests для Python позволяет работать с HTTP-запросами любого уровня сложности, используя простой синтаксис. Это помогает не тратить время на написание кода, а быстро взаимодействовать с серверами.
Python Requests — это библиотека, которая создана для быстрой и простой работы с запросами. Стандартные HTTP-библиотеки Python, например та же Urllib3, часто требуют значительно больше кода для выполнения одного и того же действия, а это затрудняет работу. Давайте сравним код для простой задачи, написанный с помощью Urllib3 и Requests.
Urllib3:
import urllib3
http = urllib3.PoolManager()
gh_url = 'https://api.github.com'
headers = urllib3.util.make_headers(user_agent= 'my-agent/1.0.1', basic_auth='abc:xyz')
requ = http.request('GET', gh_url, headers=headers)
print (requ.headers)
print(requ.data)
# ------# 200# 'application/json'
Requests:
import requests
r = requests.get('https://api.github.com', auth=('user', 'pass'))
print r.status_codeprint r.headers['content-type']
# ------# 200# 'application/json'
Количество строк различается в два раза: на Urllib3 — восемь строк, а на Requests — четыре. И это только один небольшой запрос.
Писать код на Python лучше всего в специальной IDE, например в PyCharm или Visual Studio Code. Они подсвечивают синтаксис и предлагают автодополнение кода — это сильно упрощает работу программиста. Весь код из этой статьи мы писали в Visual Studio Code.
Для начала работы с библиотекой Requests её необходимо установить в IDE. Для этого откройте IDE и введите команду в терминале:
pip install requests
Библиотека готова к работе. Остаётся только импортировать её:
import requests
Из всех HTTP-запросов наиболее часто используется GET. Он позволяет получить данные из указанного источника — обычно с какого-то веб-сайта. Чтобы отправить GET-запрос, используется метод requests.get(), в который в качестве параметра добавляется URL-адрес назначения:
requests.get('https://skillbox.ru')
Этот код совершает одно действие — связывается с указанным адресом и получает от сервера информацию о нём. Когда вы вводите домен в адресную строку браузера и переходите на сайт, под капотом выполняются те же самые операции. Единственное различие в том, что Requests позволяет получить чистый HTML-код страницы без рендеринга, то есть мы не видим вёрстку и разные визуальные компоненты — только код и техническую информацию.
Для проверки ответа на запрос существуют специальные НТТР-коды состояния. Чтобы воспользоваться ими, необходимо присвоить запрос переменной и «распечатать» её значение:
res = requests.get('https://skillbox.ru') # Создаём переменную, в которую сохраним код состояния запрашиваемой страницы.
print(res) # Выводим код состояния.
Если запустить этот код, то в терминале выведется <Response [200]>. Это хороший результат — значит, запрос прошёл успешно. Но бывают и другие HTTP-коды состояний.
Коды состояний имеют вид трёхзначных чисел от 100 до 500. Чаще всего встречаются следующие:
- 200 — «OK». Запрос прошёл успешно, и мы получили ответ.
- 400 — «Плохой запрос». Его получаем тогда, когда сервер не может понять запрос, отправленный клиентом. Как правило, это указывает на неправильный синтаксис запроса, неправильное оформление сообщения запроса и так далее.
- 401 — «Unauthorized». Для выполнения запроса необходимы актуальные учётные данные.
- 403 — «Forbidden». Сервер понял запрос, но не может его выполнить. Например, у используемой учётной записи нет достаточных прав для просмотра содержимого.
- 404 — «Не найдено». Сервер не нашёл содержимого, соответствующего запросу.
Кодов состояния намного больше. С полным списком можно ознакомиться здесь.
Для получения содержимого страницы используется метод content. Он позволяет получить информацию в виде байтов, то есть в итоге у нас будет вся информация, не только строковая. Запустим его и посмотрим на результат:
response = requests.get('https://api.github.com')
response.content
Ответ:
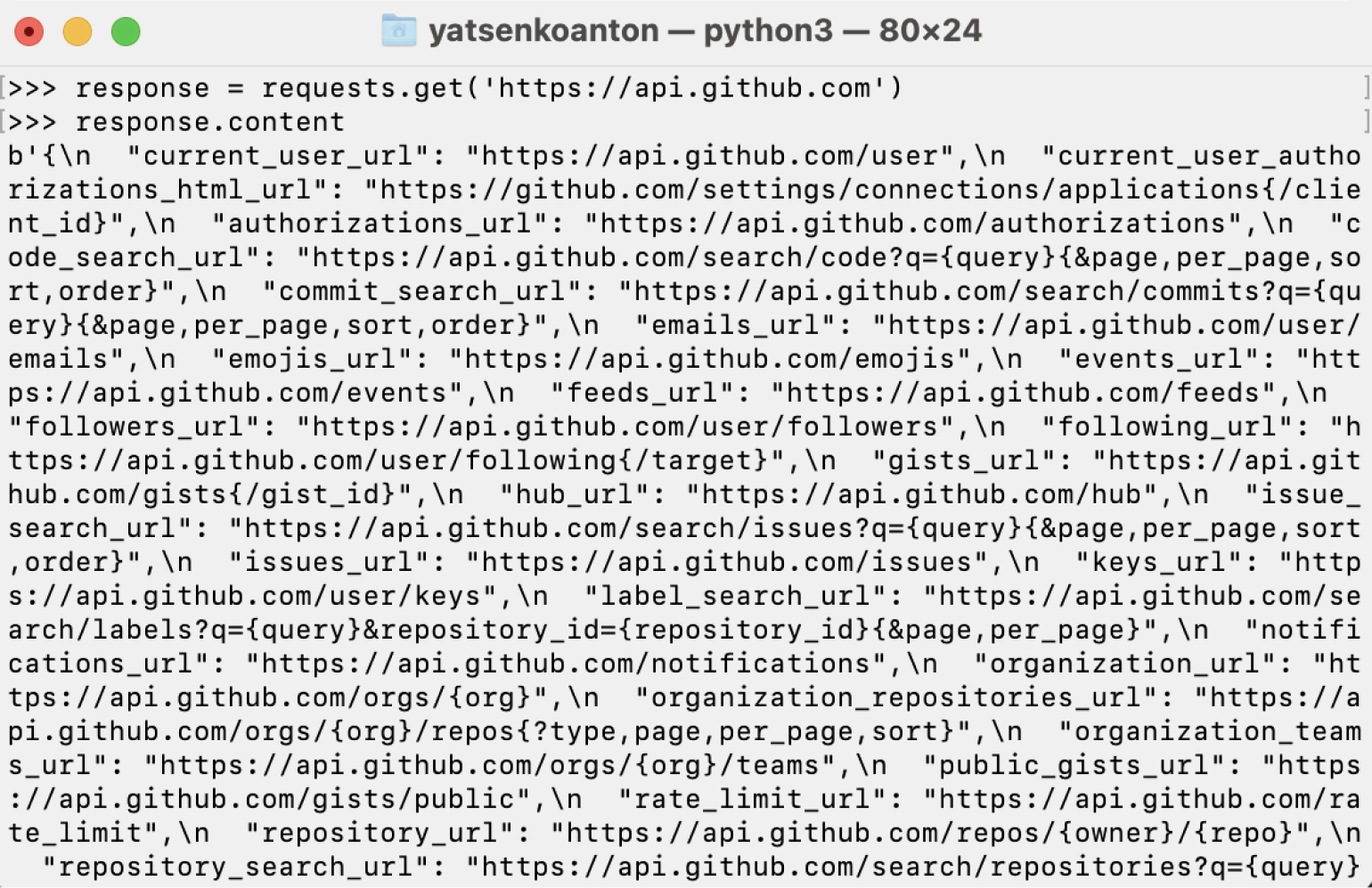
Информацию из байтового вида в строковый можно декодировать с помощью метода text:
response = requests.get('https://api.github.com')
response.text
Ответ:
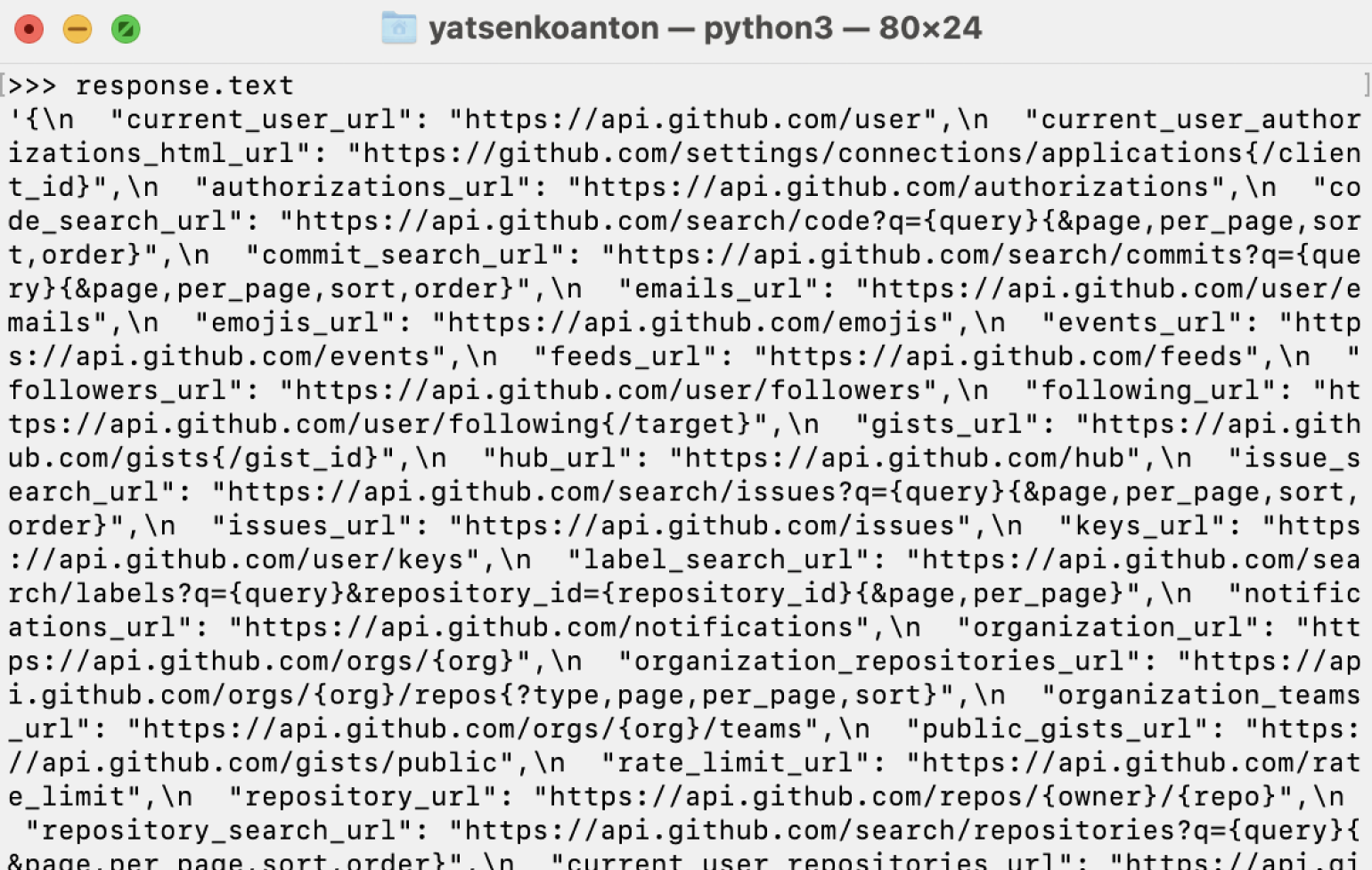
В обоих случаях мы получаем классический JSON-текст, который можно использовать как словарь, получая доступ к нужным значениям по известному ключу.
Заголовки ответа — важная часть запроса. Хотя в них и нет содержимого исходного сообщения, зато там можно обнаружить множество важных деталей ответа: информация о сервере, дата, кодировка и так далее. Для работы с ними используется метод headers:
print(response.headers)
Ответ:
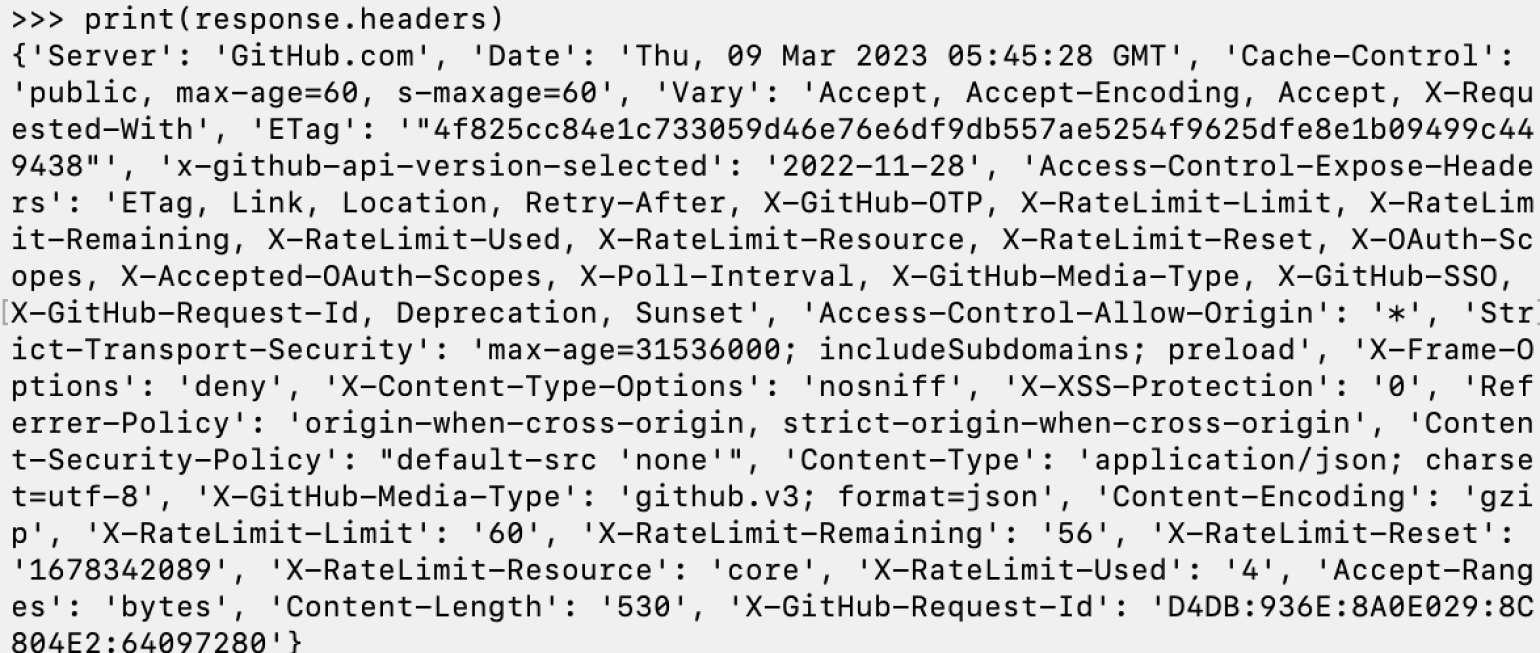
Зачем это надо? Например, таким образом мы можем узнать дату и время на сервере в момент получения запроса. В нашем случае ответ пришёл 9 марта в 05:45:28 GMT. Это помогает логировать действия для их последующей оценки, например, при поиске ошибок выполнения.
| Метод | Описание |
|---|---|
| GET | GET-метод используется для обычного запроса к серверу и получения информации по URL. |
| POST | Метод запроса POST запрашивает веб-сервис для приёма данных, например для хранения информации. |
| PUT | Метод PUT просит, чтобы вложенный в него объект был сохранён под определённым URI. Если URI ссылается на уже существующий ресурс, он модифицируется, а если URI указывает на несуществующий ресурс, сервер может создать новый ресурс с этим URI. |
| DELETE | Метод DELETE удаляет объект с сервера. |
| HEAD | Метод HEAD запрашивает ответ, идентичный запросу GET, но без тела ответа. |
| PATCH | Метод используется для модификации информации на сервере. |
Подробнее о методах можно прочитать в официальной документации.
Запрос GET можно настроить с помощью передачи параметров в методе params. Посмотрим, как это работает на простом примере — попробуем найти изображение на фотостоке Pixabay.
Для начала создадим переменную, которая будет содержать необходимые нам параметры:
query = {'q': 'Forest', 'order': 'popular', 'min_width': '1000', 'min_height': '800'}
Наш запрос для поиска изображений на стоке Pixabay представлен словарём, где:
- q — передаём ключевые слова для поиска;
- order — порядок фильтрации поиска, в нашем случае — по популярности;
- min_width и min_height — минимальная ширина и высота соответственно.
Напишем запрос и посмотрим на результат выполнения:
req = requests.get('<a
href="https://pixabay.com/en/photos/">https://pixabay.com/en/photos/</a>', params=query)
req.url
В ответе мы получим ссылку с нужными параметрами запроса:
‘<a href=»https://pixabay.com/en/photos/?order=popular_height=800&q=Forest&min_width=1000″>https://pixabay.com/en/photos/?order=popular_height=800&q=Forest&min_width=1000</a>’
Откроём её в браузере:
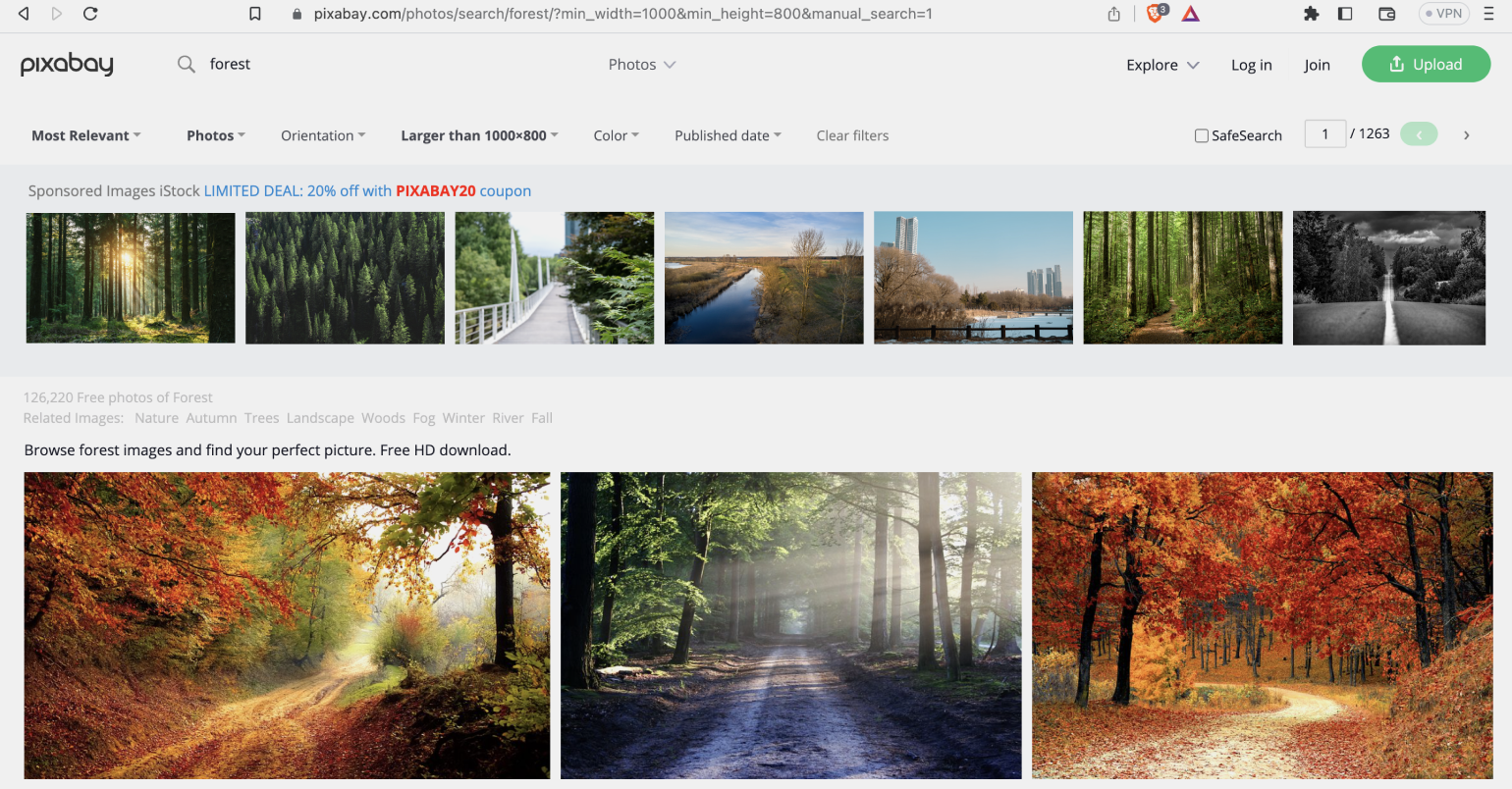
Всё получилось. У нас правильно настроена сортировка и размеры изображений.
Аутентификацию используют в тех случаях, когда сервис должен понять, кто вы. Например, это часто необходимо при работе с API. Аутентификация в библиотеке Requests очень простая — для этого достаточно использовать параметр с именем auth. Попробуем написать код для доступа к API GitHub. Для него вам потребуются данные учётной записи на сервисе — логин и пароль. Поставьте их в нужные места кода:
from getpass import getpass # Импортируем метод getpass из одноимённой библиотеки для ввода пароля доступа. requests.get('https://api.github.com/user', auth=('username', getpass())
При запуске кода вам будет необходимо ввести пароль от своего профиля. Если пароль правильный, вернётся ответ 200, если нет — 401.
SSL-сертификат указывает на то, что установленное через HTTP соединение безопасно и зашифровано. Важно, что библиотека Requests не только умеет работать с SSL-сертификатами «из коробки», но и позволяет настраивать взаимодействие с ними. Для примера отключим проверку SSL-сертификата, передав параметру функции запроса verify значение False:
requests.get('https://api.github.com', verify=False)
Ответ:

Мы видим, что ответ на запрос содержит предупреждение о неверифицированном сертификате. Всё дело в том, что мы отключили его получение вручную в коде выше с помощью функции verify.
Метод GET позволяет работать с запросами на высоком уровне абстракции, не разбираясь в деталях их выполнения, при этом надо настроить лишь базовые параметры.
Однако возможности библиотеки Requests на этом не заканчиваются: с помощью класса Session мы можем контролировать выполнение запросов и увеличивать скорость их выполнения.
Класс Session позволяет создавать сеансы — базовые запросы с сохранёнными параметрами (то есть без повторного указания параметров).
Напишем код для простой сессии, позволяющей получить доступ к GitHub:
import requests from getpass import getpass with requests.Session() as session: session.auth = ('login', getpass()) response = session.get('https://api.github.com/user') # Выведем ответ на экран. print(response.headers) print(response.json())
Запустим его и введём пароль. Как видим, всё сработало:

Запрос возвращает информацию с сервера при этом работает с помощью session. То есть теперь нам не придётся вводить повторные параметры авторизации при следующих запросах.
Библиотека Requests — простой инструмент для работы с HTTP-запросами разного уровня сложности. Рекомендуем подробно изучить возможности библиотеки, методы и примеры их использования в официальной документации.

Научитесь: Профессия Python-разработчик
Узнать больше
HTTP
Давайте подумаем о том, каким образом данные передаются от одного устройства другому в компьютерных сетях. Данные изначально представлены в виде последовательности байтов. А между устройствами эти байты уже передаются в виде физического сигнала различной природы: электричество, радиоволна, свет и др. Всего выделяют семь уровней, которые проходят данные, начиная с представления в виде байтов и заканчивая физическим сигналом.
Эти уровни передачи определены в стандарте OSI (The Open Systems Interconnection model, модель взаимодействия открытых систем). На каждом уровне описаны протоколы, по которым происходит обмен данными. Протокол — это набор правил, который определяет процесс обмена данными между различными устройствами или программами.

Программы работают на самом высоком уровне — прикладном. Программисты для передачи данных между программами выбирают один из существующих протоколов прикладного уровня и следуют его правилам. Такой подход позволяет не задумываться о том, как передавать данные на более низких уровнях. Это упрощает и ускоряет разработку сетевых программ.
Для обмена данными между программами в компьютерных сетях используются различные протоколы прикладного уровня. Один из самых популярных протоколов — HTTP (HyperText Transfer Protocol, протокол передачи гипертекста). Он создавался для передачи гипертекстовых документов формата HTML (веб-страницы), однако в настоящее время используется для обмена произвольными данными: графическими и видеофайлами, документами и т. д.
Протокол HTTP работает по принципу «запрос — ответ». В протоколе описаны виды запросов, правила формирования запросов и возможные варианты ответов на запросы.
Ответы в протоколе HTTP имеют коды состояния, которые представляют собой числовые значения. По коду состояния всегда можно определить, верно ли был обработан запрос или произошла ошибка.
Например, вам, скорее всего, знаком код состояния 404, который означает, что запрошенный объект (чаще всего веб-страница) не был найден.
В протоколе HTTP описаны различные виды запросов: на получение данных (GET), на передачу данных (POST), на добавление и изменение данных (PUT), на удаление данных (DELETE) и др.
Итак, многие сетевые программы взаимодействуют по протоколу HTTP. Часто разработчикам веб-сервисов нужно отправлять в качестве ответа на запросы не веб-страницы, а данные, например информацию о географических объектах в формате JSON или графический файл с определённой областью географической карты. Порой это помогает расширить функционал сервиса. К примеру, добавить авторизацию через соцсети.
Бывает и коммерческий вариант такого взаимодействия, когда сторонние разработчики платят за то, чтобы использовать возможность работы с сервисами для создания собственных продуктов.
Реализация взаимодействия с сервисом через такой набор правил происходит посредством API (Application Programming Interface). Правила API описывают возможные запросы к сервису и ответы сервиса на эти запросы. Так, API отдельного веб-сервиса можно назвать нестандартным протоколом этого сервиса, действующим над протоколом HTTP.
Для работы с API можно не писать программу, а просто выполнить запрос в браузере, так как он также работает по протоколу HTTP.
Static API
Воспользуемся в качестве примера одним из API сервиса Яндекс Карт — Static API. Static API возвращает изображение карты в ответ на HTTPS-запрос. Добавляя в URL разные параметры и задавая их значения, вы можете определить центр карты, её размер и область показа, отметить нужные объекты и отобразить пробки. Данные будут обновляться при каждом новом обращении, поэтому карта всегда будет актуальной.
Обратите внимание: у каждого API есть условия использования, которые нужно обязательно изучить перед началом работы и которым нужно следовать при разработке программ на основе API. Например, для Static API в бесплатной версии API Яндекс Карт изображение карты обязательно должно быть размещено на общедоступном сайте или в приложении. Есть и другие условия бесплатного использования.
Давайте сделаем первый запрос к Static API. Для этого надо открыть документацию и понять, каким должен быть запрос.
Запрос к Static API имеет следующий формат:
https://static-maps.yandex.ru/1.x/?{параметры URL}.
Воспользуемся примерами использования и выполним в браузере следующий запрос:
https://static-maps.yandex.ru/1.x/?ll=37.677751,55.757718&spn=0.016457,0.00619&l=map
Параметр ll отвечает за координаты центра карты (через запятую указываются долгота и широта в градусах). Параметр spn определяет область показа (протяжённость карты в градусах по долготе и широте). Параметр l определяет тип карты (в запросе используется тип map — схема). Все возможные параметры запроса можно посмотреть в документации.
В ответе на запрос сервер пришлёт часть карты по запрошенным координатам.
Чтобы воспользоваться API в программе, нужно из неё отправить такой же запрос, а затем получить ответ сервера. Для удобного формирования HTTP-запросов и получения ответов можно использовать библиотеку requests.
Библиотека requests является нестандартной и устанавливается следующей командой:
pip install requests
В библиотеке requests функции для формирования HTTP-запросов называются так же, как и сами запросы. Например, для выполнения GET-запроса используем функцию get():
from requests import get
response = get("https://static-maps.yandex.ru/1.x/?"
"ll=37.677751,55.757718&"
"spn=0.016457,0.00619&"
"l=map")
print(response)
Вывод программы:
<Response [200]>
Функция get() вернула ответ HTTP-сервера с кодом 200. Значит, запрос был обработан успешно. Для получения данных из ответа сервера воспользуемся атрибутом content. В этом атрибуте находятся данные в виде последовательности байтов. Из документации Static API известно, что ответом сервера на успешный запрос должен быть графический файл формата PNG. Запишем данные из ответа сервера в новый файл с расширением .png. Для этого откроем файл функцией open() на запись в бинарном режиме (wb), так как будем сохранять байты, а не текст. А затем воспользуемся методом write() созданного файлового объекта:
with open("map.png", "wb") as file:
file.write(response.content)
В папке с программой будет создан файл map.png с запрошенной областью карты.
В нашей программе запрос формируется в виде длинной строки, включающей в себя адрес сервера и параметры запроса. Функция get() имеет аргумент params, в который можно передать словарь с параметрами запроса:
params = {"ll": "37.677751,55.757718",
"spn": "0.016457,0.00619",
"l": "map"}
response = get("https://static-maps.yandex.ru/1.x/", params=params)
При выполнении запроса к серверу могут происходить нештатные ситуации. Например, отсутствие подключения к сети. В таком случае программа вызовет исключение ConnectionError из модуля requests. Обработка исключения поможет нашей программе не падать с ошибкой, а сообщить о необходимости проверки подключения к сети:
from requests import get, ConnectionError
params = {"ll": "37.677751,55.757718",
"spn": "0.016457,0.00619",
"l": "map"}
try:
response = get("https://static-maps.yandex.ru/1.x/", params=params)
except ConnectionError:
print("Проверьте подключение к сети.")
else:
with open("map.png", "wb") as file:
file.write(response.content)
Static API имеет очень широкий функционал, поэтому рассмотреть его весь в данной главе невозможно. Для более детального изучения API воспользуйтесь документацией.
API Яндекс Диск
Рассмотрим ещё один пример взаимодействия с API. Яндекс Диск — это облачный сервис для хранения файлов и обмена ими. Он предоставляет API для сохранения файлов и организации доступа к ним. Полный список запросов к API и формат ответов сервера находится в документации.
Для работы с API Яндекс Диска требуется авторизация пользователя по протоколу OAuth 2.0. Открытый протокол авторизации OAuth 2.0 обеспечивает предоставление третьей стороне ограниченного доступа к защищённым ресурсам пользователя без передачи ей логина и пароля. Вместо логина и пароля авторизация производится по OAuth-токену. Токен — это уникальная для каждого пользователя строка-ключ для доступа с помощью API к файлам в облаке.
Для работы с API необходимо создать и зарегистрировать приложение-сервис по инструкции. При создании сервиса выполните следующие действия:
- Заполнить поле «Название сервиса».
- Выбрать вариант платформы «Веб-сервисы».
- Выбрать значение «Подставить URL для разработки» в поле Callback URL.
- В качестве доступных сервису данных указать «Яндекс Диск REST API» и выдать все четыре возможных права доступа.
- Нажать кнопку «Создать приложение».
После выполнения указанных действий появится окно, в котором будут указаны значения для полей ClientID, Client secret и Redirect URL. Эти значения мы будем использовать для получения токена по протоколу авторизации OAuth 2.0. Данный протокол реализован в библиотеке requests-oauthlib.
Приложение-сервис должно перенаправить пользователя по ссылке для авторизации. Пользователь переходит по ссылке и копирует сгенерированный одноразовый код, а затем вводит его в приложение. Библиотека requests-oauthlib на основе введённого кода делает запрос на получение токена и возвращает его. Более детальный порядок получения токена изложен в инструкции.
Напишем программу с авторизацией сервиса и получением токена. Значения переменных client_id и client_secret нужно скопировать из полей ClientID, Client secret со страницы информации о зарегистрированном сервисе.
from requests_oauthlib import OAuth2Session
from requests import get, post, put, delete
client_id = ""
client_secret = ""
auth_url = "https://oauth.yandex.ru/authorize"
token_url = "https://oauth.yandex.ru/token"
oauth = OAuth2Session(client_id=client_id)
authorization_url, state = oauth.authorization_url(auth_url, force_confirm="true")
print("Перейдите по ссылке, авторизуйтесь и скопируйте код:", authorization_url)
code = input("Вставьте одноразовый код: ")
token = oauth.fetch_token(token_url=token_url,
code=code,
client_secret=client_secret)
access_token = token["access_token"]
print(access_token)
Переменная token является словарём, в котором необходимый для выполнения запросов токен находится по ключу access_token.
Полученный на этапе авторизации токен необходимо передавать во всех запросах к API. Для этого нужно заполнять в заголовке запроса поле Authorization значением OAuth <ваш токен>.
Создадим словарь headers с соответствующими ключом и значением. Заголовок с токеном будут передаваться в функции запросов модуля requests через именованный аргумент с таким же именем headers.
Все возможные запросы к сервису, их формат и ответы сервера можно посмотреть в документации.
Выполним GET-запрос по адресу https://cloud-api.yandex.net/v1/disk для получения информации о состоянии облачного хранилища:
headers = {"Authorization": f"OAuth {access_token}"}
r = get("https://cloud-api.yandex.net/v1/disk", headers=headers)
print(r.json())
Данные в ответе на запрос имеют формат JSON. Они преобразуются в словарь методом json(). В ответе содержится информация о максимальном размере файла на диске (поле max_file_size), о размере диска (поле total_space), об использованном объёме (used_space) и др. Полное описание полей ответа можно посмотреть в документации.
Создадим в корневой папке диска новую папку Тест API. Скопируем файл map.png, полученный в примерах для Static API, в эту папку. Для создания папки потребуется выполнить PUT-запрос по адресу https://cloud-api.yandex.net/v1/disk/resources с обязательным параметром path, в котором должен быть записан путь к создаваемой папке.
params = {"path": "Тест API"}
r = put("https://cloud-api.yandex.net/v1/disk/resources", headers=headers, params=params)
print(r)
В случае успешного запроса программа выведет код ответа <Response [201]>, а в корневой папке облачного диска будет создана папка Тест API:

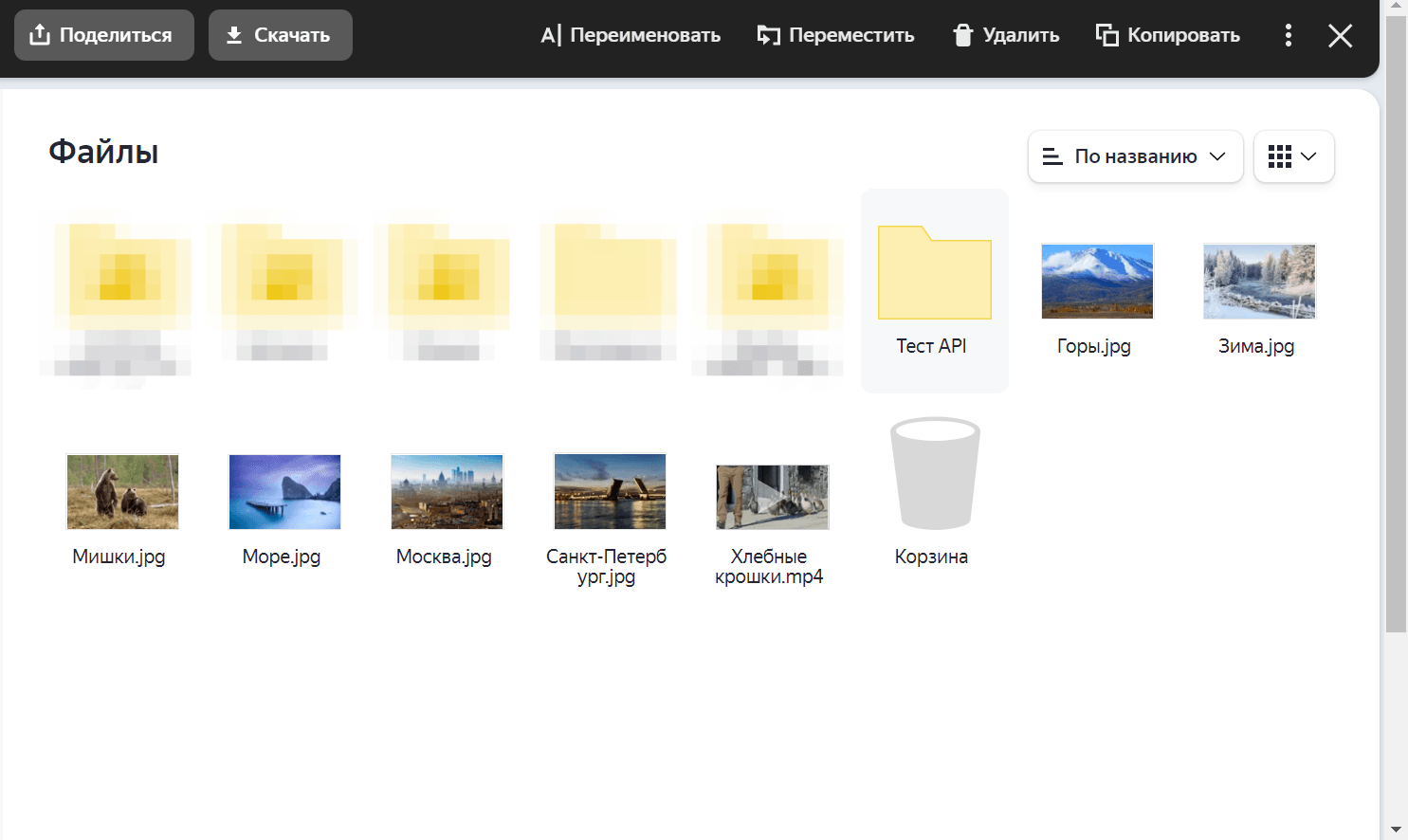
Для копирования файла в папку необходимо выполнить два запроса:
- GET-запрос по адресу https://cloud-api.yandex.net/v1/disk/resources/upload для получения ссылки на загрузку файла в облако. Если запрос будет успешен, то URL для загрузки файла будет в поле
hrefJSON-ответа сервера. - PUT-запрос по URL из предыдущего пункта. В аргумент
filesфункцииputпередаётся словарь с ключомfileи значением — файловым объектом, открытым в режиме бинарного чтенияrb. Передавать токен в данном запросе не нужно.
Выполним указанные запросы в программе:
params = {"path": "Тест API/map.png"}
r = get("https://cloud-api.yandex.net/v1/disk/resources/upload",
headers=headers, params=params)
href = r.json()["href"]
files = {"file": open("map.png", "rb")}
r = put(href, files=files)
print(r)
В результате успешного запроса программа выведет <Response [201]>, а в папке Тест API в облаке появится файл map.png:

Попробуйте реализовать другие операции с хранилищем через запросы к API в соответствии с документацией.
Кроме рассмотренных API сервисов Яндекса существует большое количество других сервисов. Теперь вы знаете, как ваше приложение должно с ними взаимодействовать для обмена данными.
Прежде чем начать, убедитесь, что установлена последняя версия Requests.
Для начала, давайте рассмотрим простые примеры.
Импортируйте модуль Requests:
Попробуем получить веб-страницу с помощью get-запроса. В этом примере давайте рассмотрим общий тайм-лайн GitHub:
r = requests.get('https://api.github.com/events')
Мы получили объект Response с именем r. С помощью этого объекта можно получить всю необходимую информацию.
Простой API Requests означает, что все типы HTTP запросов очевидны. Ниже приведен пример того, как вы можете сделать POST запрос:
r = requests.post('https://httpbin.org/post', data = {'key':'value'})
Другие типы HTTP запросов, такие как : PUT, DELETE, HEAD и OPTIONS так же очень легко выполнить:
r = requests.put('https://httpbin.org/put', data = {'key':'value'})
r = requests.delete('https://httpbin.org/delete')
r = requests.head('https://httpbin.org/get')
r = requests.options('https://httpbin.org/get')
Передача параметров в URL
Часто вам может понадобится отправить какие-то данные в строке запроса URL. Если вы настраиваете URL вручную, эти данные будут представлены в нем в виде пар ключ/значение после знака вопроса. Например, httpbin.org/get?key=val. Requests позволяет передать эти аргументы в качестве словаря, используя аргумент params. Если вы хотите передать key1=value1 и key2=value2 ресурсу httpbin.org/get, вы должны использовать следующий код:
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get('https://httpbin.org/get', params=payload)
print(r.url)
Как видно, URL был сформирован правильно:
https://httpbin.org/get?key2=value2&key1=value1Ключ словаря, значение которого None, не будет добавлен в строке запроса URL.
Вы можете передать список параметров в качестве значения:
>>> payload = {'key1': 'value1', 'key2': ['value2', 'value3']}
>>> r = requests.get('https://httpbin.org/get', params=payload)
>>> print(r.url)
https://httpbin.org/get?key1=value1&key2=value2&key2=value3
Содержимое ответа (response)
Мы можем прочитать содержимое ответа сервера. Рассмотрим снова тайм-лайн GitHub:
>>> import requests
>>> r = requests.get('https://api.github.com/events')
>>> r.text
'[{"repository":{"open_issues":0,"url":"https://github.com/...
Requests будет автоматически декодировать содержимое ответа сервера. Большинство кодировок unicode декодируются без проблем.
Когда вы делаете запрос, Requests делает предположение о кодировке, основанное на заголовках HTTP. Эта же кодировка текста, используется при обращение к r.text. Можно узнать, какую кодировку использует Requests, и изменить её с помощью r.encoding:
>>> r.encoding
'utf-8'
>>> r.encoding = 'ISO-8859-1'
Если вы измените кодировку, Requests будет использовать новое значение r.encoding всякий раз, когда вы будете использовать r.text. Вы можете сделать это в любой ситуации, где нужна более специализированная логика работы с кодировкой содержимого ответа.
Например, в HTML и XML есть возможность задавать кодировку прямо в теле документа. В подобных ситуациях вы должны использовать r.content, чтобы найти кодировку, а затем установить r.encoding. Это позволит вам использовать r.text с правильной кодировкой.
Requests может также использовать пользовательские кодировки в случае, если в них есть потребность. Если вы создали свою собственную кодировку и зарегистрировали ее в модуле codecs, используйте имя кодека в качестве значения r.encoding.
Бинарное содержимое ответа
Вы можете также получить доступ к телу ответа в виде байтов для не текстовых ответов:
>>> r.content
b'[{"repository":{"open_issues":0,"url":"https://github.com/...
Передача со сжатием gzip и deflate автоматически декодируются для вас.
Например, чтобы создать изображение на основе бинарных данных, возвращаемых при ответе на запрос, используйте следующий код:
from PIL import Image
from io import BytesIO
i = Image.open(BytesIO(r.content))
Содержимое ответа в JSON
Если вы работаете с данными в формате JSON, воспользуйтесь встроенным JSON декодером:
>>> import requests
>>> r = requests.get('https://api.github.com/events')
>>> r.json()
[{'repository': {'open_issues': 0, 'url': 'https://github.com/...
Если декодирование в JSON не удалось, r.json() вернет исключение. Например, если ответ с кодом 204 (No Content), или на случай если ответ содержит не валидный JSON, попытка обращения к r.json() будет возвращать ValueError: No JSON object could be decoded.
Следует отметить, что успешный вызов r.json() не указывает на успешный ответ сервера. Некоторые серверы могут возвращать объект JSON при неудачном ответе (например, сведения об ошибке HTTP 500). Такой JSON будет декодирован и возвращен. Для того, чтобы проверить успешен ли запрос, используйте r.raise_for_status() или проверьте какой r.status_code.
Необработанное содержимое ответа
В тех редких случаях, когда вы хотите получить доступ к “сырому” ответу сервера на уровне сокета, обратитесь к r.raw. Если вы хотите сделать это, убедитесь, что вы указали stream=True в вашем первом запросе. После этого вы уже можете проделать следующее:
>>> r = requests.get('https://api.github.com/events', stream=True)
>>> r.raw
>>> r.raw.read(10)
'x1fx8bx08x00x00x00x00x00x00x03'
Однако, можно использовать подобный код как шаблон, чтобы сохранить результат в файл:
with open(filename, 'wb') as fd:
for chunk in r.iter_content(chunk_size=128):
fd.write(chunk)
Использование r.iter_content обработает многое из того, с чем бы вам пришлось иметь дело при использовании r.raw напрямую. Для извлечения содержимого при потоковой загрузке, используйте способ, описанный выше. Обратите внимание, что chunk_size можно свободно скорректировать до числа, которое лучше подходит в вашем случае.
Важное замечание об использовании
Response.iter_contentиResponse.raw.Response.iter_contentбудет автоматически декодироватьgzipиdeflate.Response.raw— необработанный поток байтов, он не меняет содержимое ответа. Если вам действительно нужен доступ к байтам по мере их возврата, используйтеResponse.raw.
Пользовательские заголовки
Если вы хотите добавить HTTP заголовки в запрос, просто передайте соответствующий dict в параметре headers.
Например, мы не указали наш user-agent в предыдущем примере:
url = 'https://api.github.com/some/endpoint'
headers = {'user-agent': 'my-app/0.0.1'}
r = requests.get(url, headers=headers)
Заголовкам дается меньший приоритет, чем более конкретным источникам информации. Например:
- Заголовки авторизации, установленные с помощью
headers=будут переопределены, если учетные данные указаны.netrc, которые, в свою очередь переопределены параметромauth=. - Они же будут удалены при редиректе.
- Заголовки авторизации с прокси будут переопределены учетными данными прокси-сервера, которые указаны в вашем URL.
- Content-Length будут переопределены, когда вы определите длину содержимого.
Кроме того, запросы не меняют свое поведение вообще, основываясь на указанных пользовательских заголовках.
Значения заголовка должны быть
string, bytestring или unicode. Хотя это разрешено, рекомендуется избегать передачи значений заголовковunicode.
Более сложные POST запросы
Часто вы хотите послать некоторые form-encoded данные таким же образом, как это делается в HTML форме. Для этого просто передайте соответствующий словарь в аргументе data. Ваш словарь данных в таком случае будет автоматически закодирован как HTML форма, когда будет сделан запрос:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
Аргумент data также может иметь несколько значений для каждого ключа. Это можно сделать, указав data в формате tuple, либо в виде словаря со списками в качестве значений. Особенно полезно, когда форма имеет несколько элементов, которые используют один и тот же ключ:
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
Бывают случаи, когда нужно отправить данные не закодированные методом form-encoded. Если вы передадите в запрос строку вместо словаря, эти данные отправятся в не измененном виде.
К примеру, GitHub API v3 принимает закодированные JSON POST/PATCH данные:
import json
url = 'https://api.github.com/some/endpoint'
payload = {'some': 'data'}
r = requests.post(url, data=json.dumps(payload))
Вместо того, чтобы кодировать dict, вы можете передать его напрямую, используя параметр json (добавленный в версии 2.4.2), и он будет автоматически закодирован:
url = 'https://api.github.com/some/endpoint'
payload = {'some': 'data'}
r = requests.post(url, json=payload)
Обратите внимание, параметр json игнорируется, если передаются data или files.
Использование параметра json в запросе изменит заголовок Content-Type на application/json.
POST отправка Multipart-Encoded файла
Запросы упрощают загрузку файлов с многостраничным кодированием (Multipart-Encoded) :
>>> url = 'https://httpbin.org/post'
>>> files = {'file': open('report.xls', 'rb')}
>>> r = requests.post(url, files=files)
>>> r.text
{
...
"files": {
"file": ""
},
...
}
Вы можете установить имя файла, content_type и заголовки в явном виде:
>>> url = 'https://httpbin.org/post'
>>> files = {'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})}
>>> r = requests.post(url, files=files)
>>> r.text
{
...
"files": {
"file": ""
},
...
}
Можете отправить строки, которые будут приняты в виде файлов:
>>> url = 'https://httpbin.org/post'
>>> files = {'file': ('report.csv', 'some,data,to,sendnanother,row,to,sendn')}
>>> r = requests.post(url, files=files)
>>> r.text
{
...
"files": {
"file": "some,data,to,send\nanother,row,to,send\n"
},
...
}
В случае, если вы отправляете очень большой файл как запрос multipart/form-data, возможно понадобиться отправить запрос потоком. По умолчанию, requests не поддерживает этого, но есть отдельный пакет, который это делает — requests-toolbelt. Ознакомьтесь с документацией toolbelt для получения более детальной информации о том, как им пользоваться.
Для отправки нескольких файлов в одном запросе, обратитесь к расширенной документации.
Предупреждение!
Настоятельно рекомендуется открывать файлы в бинарном режиме. Это связано с тем, что запросы могут пытаться предоставить для вас заголовок Content-Length, и если это значение будет установлено на количество байтов в файле будут возникать ошибки, при открытии файла в текстовом режиме.
Коды состояния ответа
Мы можем проверить код состояния ответа:
>>> r = requests.get('https://httpbin.org/get')
>>> r.status_code
200
У requests есть встроенный объект вывода кодов состояния:
>>> r.status_code == requests.codes.ok
True
Если мы сделали неудачный запрос (ошибка 4XX или 5XX), то можем вызвать исключение с помощью r.raise_for_status():
>>> bad_r = requests.get('https://httpbin.org/status/404')
>>> bad_r.status_code
404
>>> bad_r.raise_for_status()
Traceback (most recent call last):
File "requests/models.py", line 832, in raise_for_status
raise http_error
requests.exceptions.HTTPError: 404 Client Error
Но если status_code для r оказался 200, то когда мы вызываем raise_for_status() мы получаем:
>>> r.raise_for_status()
None
Заголовки ответов
Мы можем просматривать заголовки ответа сервера, используя словарь Python:
>>> r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}
Это словарь особого рода, он создан специально для HTTP заголовков. Согласно с RFC 7230, имена заголовков HTTP нечувствительны к регистру.
Теперь мы можем получить доступ к заголовкам с большим буквами или без, если захотим:
>>> r.headers['Content-Type']
'application/json'
>>> r.headers.get('content-type')
'application/json'
Cookies
Если в запросе есть cookies, вы сможете быстро получить к ним доступ:
>>> url = 'https://example.com/some/cookie/setting/url'
>>> r = requests.get(url)
>>> r.cookies['example_cookie_name']
'example_cookie_value'
Чтобы отправить собственные cookies на сервер, используйте параметр cookies:
>>> url = 'https://httpbin.org/cookies'
>>> cookies = dict(cookies_are='working')
>>> r = requests.get(url, cookies=cookies)
>>> r.text
'{"cookies": {"cookies_are": "working"}}'
Cookies возвращаются в RequestsCookieJar, который работает как dict, но также предлагает более полный интерфейс, подходящий для использования в нескольких доменах или путях. Словарь с cookie может также передаваться в запросы:
>>> jar = requests.cookies.RequestsCookieJar()
>>> jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies')
>>> jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/elsewhere')
>>> url = 'https://httpbin.org/cookies'
>>> r = requests.get(url, cookies=jar)
>>> r.text
'{"cookies": {"tasty_cookie": "yum"}}'
Редиректы и история
По умолчанию Requests будет выполнять редиректы для всех HTTP глаголов, кроме HEAD.
Мы можем использовать свойство history объекта Response, чтобы отслеживать редиректы .
Список Response.history содержит объекты Response, которые были созданы для того, чтобы выполнить запрос. Список сортируется от более ранних, до более поздних ответов.
Например, GitHub перенаправляет все запросы HTTP на HTTPS:
>>> r = requests.get('https://github.com/')
>>> r.url
'https://github.com/'
>>> r.status_code
200
>>> r.history
[]
Если вы используете запросы GET, OPTIONS, POST, PUT, PATCH или DELETE, вы можете отключить обработку редиректа с помощью параметра allow_redirects:
>>> r = requests.get('https://github.com/', allow_redirects=False)
>>> r.status_code
301
>>> r.history
[]
Если вы используете HEAD, вы также можете включить редирект:
>>> r = requests.head('https://github.com/', allow_redirects=True)
>>> r.url
'https://github.com/'
>>> r.history
[]
Тайм-ауты
Вы можете сделать так, чтобы Requests прекратил ожидание ответа после определенного количества секунд с помощью параметра timeout.
Почти весь код должен использовать этот параметр в запросах. Несоблюдение этого требования может привести к зависанию вашей программы:
>>> requests.get('https://github.com/', timeout=0.001)
Traceback (most recent call last):
File "", line 1, in
requests.exceptions.Timeout: HTTPConnectionPool(host='github.com', port=80): Request timed out. (timeout=0.001)
Timeout это не ограничение по времени полной загрузки ответа. Исключение возникает, если сервер не дал ответ за timeout секунд (точнее, если ни одного байта не было получено от основного сокета за timeout секунд).
Ошибки и исключения
В случае неполадок в сети (например, отказа DNS, отказа соединения и т.д.), Requests вызовет исключение ConnectionError.
Response.raise_for_status() вызовет HTTPError если в запросе HTTP возникнет статус код ошибки.
Если выйдет время запроса, вызывается исключение Timeout. Если запрос превышает заданное значение максимального количества редиректов, то вызывают исключение TooManyRedirects.
Все исключения, которые вызывает непосредственно Requests унаследованы от requests.exceptions.RequestException.
Тест на знание основ Requests
Какой из HTTP-запросов является правильным?
requests.post(url, data={‘key’:’value’})
requests.get(url, params={‘key’:’value’})
requests.post(url, params={‘key’:’value’})
Какое из утверждений верно?
response.json() возвращает содержимое ответа в виде объекта dict
response.text возвращает содержимое ответа в виде байтового объекта
response.content возвращает содержимое ответа в виде строкового объекта
response.json возвращает содержимое ответа в виде объекта dict
Как получить куки из ответа на запрос?
Что вернет метод status_code объекта Response?
Ошибку, если запрос неудачный
Какой код сформирует url «https://test.com/page?key1=value1&key2=value21,value22»
r.get(‘https://test.com/page’, params={‘key1’: ‘value1’, ‘key2’: [‘value21’, ‘value22’]})
r.get(‘https://test.com/page’, params={‘key1’: ‘value1’, ‘key2’: ‘value21,value22’})
r.get(‘https://test.com/page’, params={‘key1’: ‘value1’, ‘key2’: ‘value21’, ‘key2’: ‘value22’})
24 Дек. 2015, Python, 344005 просмотров,
Стандартная библиотека Python имеет ряд готовых модулей по работе с HTTP.
- urllib
- httplib
Если уж совсем хочется хардкора, то можно и сразу с socket поработать. Но у всех этих модулей есть один большой недостаток — неудобство работы.
Во-первых, большое обилие классов и функций. Во-вторых, код получается вовсе не pythonic. Многие программисты любят Python за его элегантность и простоту, поэтому и был создан модуль, призванный решать проблему существующих и имя ему requests или HTTP For Humans. На момент написания данной заметки, последняя версия библиотеки — 2.9.1. С момента выхода Python версии 3.5 я дал себе негласное обещание писать новый код только на Py >= 3.5. Пора бы уже полностью перебираться на 3-ю ветку змеюки, поэтому в моих примерах print отныне является функцией, а не оператором 
Что же умеет requests?
Для начала хочется показать как выглядит код работы с http, используя модули из стандартной библиотеки Python и код при работе с requests. В качестве мишени для стрельбы http запросами будет использоваться очень удобный сервис httpbin.org
>>> import urllib.request
>>> response = urllib.request.urlopen('https://httpbin.org/get')
>>> print(response.read())
b'{n "args": {}, n "headers": {n "Accept-Encoding": "identity", n "Host": "httpbin.org", n "User-Agent": "Python-urllib/3.5"n }, n "origin": "95.56.82.136", n "url": "https://httpbin.org/get"n}n'
>>> print(response.getheader('Server'))
nginx
>>> print(response.getcode())
200
>>>
Кстати, urllib.request это надстройка над «низкоуровневой» библиотекой httplib о которой я писал выше.
>>> import requests
>>> response = requests.get('https://httpbin.org/get')
>>> print(response.content)
b'{n "args": {}, n "headers": {n "Accept": "*/*", n "Accept-Encoding": "gzip, deflate", n "Host": "httpbin.org", n "User-Agent": "python-requests/2.9.1"n }, n "origin": "95.56.82.136", n "url": "https://httpbin.org/get"n}n'
>>> response.json()
{'headers': {'Accept-Encoding': 'gzip, deflate', 'User-Agent': 'python-requests/2.9.1', 'Host': 'httpbin.org', 'Accept': '*/*'}, 'args': {}, 'origin': '95.56.82.136', 'url': 'https://httpbin.org/get'}
>>> response.headers
{'Connection': 'keep-alive', 'Content-Type': 'application/json', 'Server': 'nginx', 'Access-Control-Allow-Credentials': 'true', 'Access-Control-Allow-Origin': '*', 'Content-Length': '237', 'Date': 'Wed, 23 Dec 2015 17:56:46 GMT'}
>>> response.headers.get('Server')
'nginx'
В простых методах запросов значительных отличий у них не имеется. Но давайте взглянем на работы с Basic Auth:
>>> import urllib.request
>>> password_mgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
>>> top_level_url = 'https://httpbin.org/basic-auth/user/passwd'
>>> password_mgr.add_password(None, top_level_url, 'user', 'passwd')
>>> handler = urllib.request.HTTPBasicAuthHandler(password_mgr)
>>> opener = urllib.request.build_opener(handler)
>>> response = opener.open(top_level_url)
>>> response.getcode()
200
>>> response.read()
b'{n "authenticated": true, n "user": "user"n}n'
>>> import requests
>>> response = requests.get('https://httpbin.org/basic-auth/user/passwd', auth=('user', 'passwd'))
>>> print(response.content)
b'{n "authenticated": true, n "user": "user"n}n'
>>> print(response.json())
{'user': 'user', 'authenticated': True}
А теперь чувствуется разница между pythonic и non-pythonic? Я думаю разница на лицо. И несмотря на тот факт, что requests ничто иное как обёртка над urllib3, а последняя является надстройкой над стандартными средствами Python, удобство написания кода в большинстве случаев является приоритетом номер один.
В requests имеется:
- Множество методов http аутентификации
- Сессии с куками
- Полноценная поддержка SSL
- Различные методы-плюшки вроде .json(), которые вернут данные в нужном формате
- Проксирование
- Грамотная и логичная работа с исключениями
О последнем пункте мне бы хотелось поговорить чуточку подробнее.
Обработка исключений в requests
При работе с внешними сервисами никогда не стоит полагаться на их отказоустойчивость. Всё упадёт рано или поздно, поэтому нам, программистам, необходимо быть всегда к этому готовыми, желательно заранее и в спокойной обстановке.
Итак, как у requests дела обстоят с различными факапами в момент сетевых соединений? Для начала определим ряд проблем, которые могут возникнуть:
- Хост недоступен. Обычно такого рода ошибка происходит из-за проблем конфигурирования DNS. (DNS lookup failure)
- «Вылет» соединения по таймауту
- Ошибки HTTP. Подробнее о HTTP кодах можно посмотреть здесь.
- Ошибки SSL соединений (обычно при наличии проблем с SSL сертификатом: просрочен, не является доверенным и т.д.)
Базовым классом-исключением в requests является RequestException. От него наследуются все остальные
- HTTPError
- ConnectionError
- Timeout
- SSLError
- ProxyError
И так далее. Полный список всех исключений можно посмотреть в requests.exceptions.
Timeout
В requests имеется 2 вида таймаут-исключений:
- ConnectTimeout — таймаут на соединения
- ReadTimeout — таймаут на чтение
>>> import requests
>>> try:
... response = requests.get('https://httpbin.org/user-agent', timeout=(0.00001, 10))
... except requests.exceptions.ConnectTimeout:
... print('Oops. Connection timeout occured!')
...
Oops. Connection timeout occured!
>>> try:
... response = requests.get('https://httpbin.org/user-agent', timeout=(10, 0.0001))
... except requests.exceptions.ReadTimeout:
... print('Oops. Read timeout occured')
... except requests.exceptions.ConnectTimeout:
... print('Oops. Connection timeout occured!')
...
Oops. Read timeout occured
ConnectionError
>>> import requests
>>> try:
... response = requests.get('http://urldoesnotexistforsure.bom')
... except requests.exceptions.ConnectionError:
... print('Seems like dns lookup failed..')
...
Seems like dns lookup failed..HTTPError
>>> import requests
>>> try:
... response = requests.get('https://httpbin.org/status/500')
... response.raise_for_status()
... except requests.exceptions.HTTPError as err:
... print('Oops. HTTP Error occured')
... print('Response is: {content}'.format(content=err.response.content))
...
Oops. HTTP Error occured
Response is: b''
Я перечислил основные виды исключений, которые покрывают, пожалуй, 90% всех проблем, возникающих при работе с http. Главное помнить, что если мы действительно намерены отловить что-то и обработать, то это необходимо явно запрограммировать, если же нам неважен тип конкретного исключения, то можно отлавливать общий базовый класс RequestException и действовать уже от конкретного случая, например, залоггировать исключение и выкинуть его дальше наверх. Кстати, о логгировании я напишу отдельный подробный пост.
У блога появился свой Telegram канал, где я стараюсь делиться интересными находками из сети на тему разработки программного обеспечения. Велком, как говорится
Полезные «плюшки»
- httpbin.org очень полезный сервис для тестирования http клиентов, в частности удобен для тестирования нестандартного поведения сервиса
- httpie консольный http клиент (замена curl) написанный на Python
- responses mock библиотека для работы с requests
- HTTPretty mock библиотека для работы с http модулями
💌 Присоединяйтесь к рассылке
Понравился контент? Пожалуйста, подпишись на рассылку.