Протокол передачи гипертекста (HTTP) — это основа жизни в Интернете. Он используется каждый раз при передаче документа или в запросе AJAX. Но HTTP на удивление мало известен некоторым веб-разработчикам.
В этом введении мы познакомимся с принципами разработки REST, лежащими в основе HTTP и использованию их мощи для создания интерфейсов, которые могут выполняться практически с любого устройства или операционной системы.
Переизданный урок
Каждые несколько недель мы пересматриваем некоторые из любимых сообщений наших читателей за всю историю сайта. Этот урок впервые был опубликован в ноябре 2010 года.
Почему REST?
REST — простой способ организации взаимодействия между независимыми системами.
REST — простой способ организации взаимодействия между независимыми системами. Он пользуется популярностью с 2005 года и вдохновляет дизайн сервисов, таких как API Twitter. Благодаря тому, что REST обеспечивает взаимодействие с такими разнообразными клиентами, как мобильные телефоны и другие веб-сайты. Теоретически, REST не привязан к сети, но почти всегда реализован как таковой и был вдохновлен HTTP. В результате REST можно использовать везде, где возможен HTTP.
Альтернативой является создание относительно сложных соглашений поверх HTTP. Часто это принимает форму новых XML-языков. Самый яркий пример — SOAP. Вам нужно выучить совершенно новый набор соглашений, но вы никогда не используете HTTP в полную силу. Поскольку REST был вдохновлён HTTP и играет на его сильные стороны, это лучший способ узнать, как работает HTTP.
После первоначального обзора мы рассмотрим каждый из строительных блоков HTTP: URL-адреса, HTTP-команды и коды ответов. Мы также рассмотрим, как использовать их в RESTful. Попутно мы проиллюстрируем теорию примером приложения, которое имитирует процесс отслеживания данных, связанных с клиентами компании через веб-интерфейс.
HTTP
HTTP — это протокол, который позволяет отправлять документы в Интернете.
HTTP — это протокол, который позволяет отправлять документы в Интернете. Протокол — это набор правил, определяющих, какие сообщения можно обменивать, и какие сообщения являются подходящими ответами для других. Другим распространенным протоколом является POP3, который вы можете использовать для извлечения электронной почты на вашем жёстком диске.
В HTTP есть две разные роли: сервер и клиент. Как правило, клиент всегда инициирует разговор; сервер отвечает. HTTP основан на тексте; то есть сообщения по сути являются битами текста, хотя тело сообщения может также содержать другие носители. Использование текста позволяет легко отслеживать обмен HTTP.
HTTP-сообщения состоят из заголовка и тела. Тело часто может оставаться пустым; оно содержит данные, которые вы хотите передать по сети, чтобы использовать их в соответствии с инструкциями в заголовке. Заголовок содержит метаданные, например информацию о кодировке; но, в случае запроса, он также содержит важные HTTP-методы. В стиле REST вы обнаружите, что данные заголовка часто более значимы, чем тела.
Шпионство HTTP на работе
Если вы используете Chrome Developer Tools или Firefox с расширением Firebug, щелкните на панели Net и установите его в enabled. После этого у вас будет возможность просматривать информацию о HTTP-запросах по мере вашего поиска. Например:


Другим полезным способом ознакомиться с HTTP является использование выделенного клиента, такого как cURL.
cURL — это инструмент command line, который доступен во всех основных операционных системах.
После установки cURL введите:
Будет отображен полный диалог HTTP. Запросам предшествует >, а ответам предшествует <.
URLS
URL — это, как вы определяете то, на чём вы хотите работать. Мы говорим, что каждый URL-адрес идентифицирует ресурс. Это те же самые URL-адреса, которые назначены веб-страницам. Фактически, веб-страница — это тип ресурса. Давайте рассмотрим более экзотический пример с нашим образцом приложения, которое управляет списком клиентов компании:
будет идентифицировать всех клиентов, в то время как
определяет клиента с именем ‘Jim’, предполагая, что он единственный с таким именем.
В этих примерах мы обычно не включаем hostname в URL, так как это не имеет никакого отношения к организации интерфейса. Тем не менее, hostname важно для того, чтобы идентификатор ресурса был уникальным во всей сети. Мы часто говорим, что вы отправляете запрос на ресурс к host. Хост включается в заголовок отдельно от пути ресурса, который идёт прямо над заголовком запроса:
1 |
GET /clients/jim HTTP/1.1 |
2 |
|
3 |
Host: example.com |
Ресурсы лучше всего рассматривать как существительные. Например, следующее не RESTful:
Это связано с тем, что для описания действия используется URL-адрес. Это довольно фундаментальный момент в различиях систем RESTful от систем без RESTful.
Наконец, URL-адреса должны быть максимально точными; всё, что необходимо для уникальной идентификации ресурса, должно быть в URL-адресе. Вам не нужно включать в запрос данные, идентифицирующие ресурс. Таким образом, URL-адреса выступают в качестве полной карты всех данных, обрабатываемых приложением.
Но как вы определяете действие? Например, как сообщить, что вы хотите создать новую запись клиента вместо её получения? Именно здесь вступают в действие глаголы HTTP.
Глаголы HTTP
Каждый запрос указывает определенный HTTP глагол или метод в заголовке запроса. Это первое слово в заголовке запроса. Например,
означает, что используется метод GET, а
1 |
DELETE /clients/anne HTTP/1.1 |
означает использование метода DELETE .
Глаголы HTTP сообщают серверу, что делать с данными, указанными URL.
Глаголы HTTP сообщают серверу, что делать с данными, указанными URL. Запрос может ещё содержать дополнительную информацию в своем теле, которая может потребоваться для выполнения операции — например, данные, которые вы хотите сохранить с ресурсом. Эти данные можно указать в cURL с параметром -d.
Если вы когда-либо создавали HTML-формы, то знакомы с двумя из наиболее важных HTTP-глаголов: GET и POST. Но есть гораздо больше доступных HTTP-глаголов. Наиболее важными для построения RESTful API являются GET, POST, PUT и DELETE. Доступны другие методы, такие как HEAD и OPTIONS, но они более редки (если вы хотите знать обо всех других методах HTTP, официальным источником является IETF).
GET
GET — это самый простой тип HTTP-запроса; которым браузер пользуется каждый раз, когда вы нажимаете ссылку или вводите URL-адрес в адресную строку. Он инструктирует сервер передавать клиенту данные, идентифицированные URL-адресом. Никогда не последует изменений данных на стороне сервера в результате запроса GET. В этом смысле GET-запрос доступен только для чтения, но, конечно, как только клиент получит данные, он может самостоятельно выполнять любые операции с ними, например, форматировать для отображения.
PUT
Запрос PUT используется, когда вы хотите создать или обновить ресурс, указанный URL-адресом. Например,
может создать клиента с именем Robin на сервере. Вы заметите, что REST полностью независим от бэкэнда; в запросе нет ничего, что информирует сервер о том, как данные должны создаваться — просто так должно быть. Это позволяет вам легко менять базовую технологию по необходимости. Запросы PUT содержат данные для использования при обновлении или создании ресурса в body. В cURL вы можете добавить данные в запрос с помощью -d.
1 |
curl -v -X PUT -d "some text" |
DELETE
DELETE должен выполнять противоположное PUT; его следует использовать, если вы хотите удалить ресурс, указанный URL-адресом запроса.
1 |
curl -v -X DELETE /clients/anne |
Это приведёт к удалению всех данных, связанных с ресурсом, идентифицированных /clients/anne.
POST
POST используется, когда обработка, которую вы хотите выполнить на сервере, должна повторяться, если запрос POST повторяется (то есть, они не являются идемпотентными, подробнее об этом ниже). Кроме того, POST-запросы должны вызывать обработку body запроса как подчинённого URL-адреса, который вы отправляете.
Проще говоря:
не должен вызывать изменение ресурса в /clients/ сам, но ресурс URL начинается с него /clients/. Например, он может добавить в список нового клиента, с id, сгенерированным сервером.
1 |
/clients/some-unique-id |
Запросы PUT легко используются вместо запросов POST и наоборот. Некоторые системы используют только один, некоторые используют POST для создания операций и PUT для операций обновления (поскольку с запросом PUT вы всегда указываете полный URL-адрес), некоторые используют POST для обновлений и PUT для создания.
Часто запросы POST используются для запуска операций на сервере, которые не вписываются в парадигму Create/Update/Delete; но это, однако, выходит за рамки REST. В нашем примере мы будем полностью придерживаться PUT.
Классификация методов HTTP
Безопасные и небезопасные методы:
безопасными являются методы, которые никогда не изменяют ресурсы. Единственными безопасными методами, из четырёх перечисленных выше, является GET. Другие небезопасны, так как они могут привести к модификации ресурсов.
Idempotent методы:
Эти методы достигают того же результата, независимо от того, сколько раз запрос повторяется: это GET, PUT и DELETE. Единственным неидемпотентным методом является POST. PUT и DELETE, считающиеся идемпотентами, могут быть неожиданными, хотя, на самом деле, это довольно легко объяснить: повторение метода PUT с точно таким же body должно модифицировать ресурс таким образом, чтобы он оставался идентичным описанному в предыдущем запросе PUT: ничего не изменится! Аналогичным образом, нет смысла дважды удалять ресурс. Из этого следует, что независимо от того, сколько раз запрос PUT или DELETE повторяется, результат должен быть таким же, как если бы это было сделано только один раз.
Помните: именно вы, программист, в конечном счете решаете, что происходит, когда используется определённый HTTP-метод. В реализациях HTTP нет ничего, что автоматически приведёт к созданию ресурсов, их перечислению, удалению или обновлению. Вы должны быть осторожны, чтобы правильно применять HTTP-протокол и вводить эту семантику самостоятельно.
Представительства
HTTP-клиент и HTTP-сервер обмениваются информацией о ресурсах, определённых URL-адресами.
Мы можем суммировать то, что мы узнали до сих пор, следующим образом: HTTP-клиент и HTTP-сервер обмениваются информацией о ресурсах, определённых URL-адресами.
Мы говорим, что запрос и ответ содержат представление ресурса. Под представлением мы подразумеваем информацию в определённом формате о состоянии ресурса или о том, каким это состояние должно быть в будущем. Оба, и header, и body — являются частями представления.
Заголовки HTTP, содержащие метаданные, жёстко определяются спецификацией HTTP; они могут содержать только простой текст и должны быть отформатированы определённым образом.
Тело может содержать данные в любом формате, и именно здесь видна сила HTTP. Вы знаете, что можете отправлять простой текст, изображения, HTML и XML на любом человеческом языке. Через метаданные запроса или различные URL-адреса вы можете выбирать между различными представлениями для одного и того же ресурса. Например, вы можете отправить веб-страницу в браузеры и JSON в приложения.
HTTP-ответ должен указывать тип содержимого body. Это делается в заголовке, в поле Content-Type; например:
1 |
Content/Type: application/json |
Для простоты наше приложение только отправляет JSON туда и обратно, но приложение должно быть спроектировано таким образом, чтобы вы могли легко изменять формат данных, чтобы адаптироваться для разных клиентов или предпочтений пользователя.
Библиотеки клиента HTTP
cURL — это, чаще всего, HTTP-решение для PHP-разработчиков.
Чтобы поэкспериментировать с различными методами запроса, вам нужен клиент, который позволит указать, какой метод использовать. К сожалению, формы HTML не подходят для счёта, так как они позволяют делать только запросы GET и POST. В реальной жизни API-интерфейсы доступны программно через отдельное клиентское приложение или через JavaScript в браузере.
Именно поэтому в дополнение к серверу важно иметь хорошие возможности HTTP-клиента на выбранном вами языке программирования.
Очень популярная клиентская HTTP-библиотека, опять же, cURL. Вы уже были ознакомлены с командой cURL ранее в этом уроке. CURL включает в себя как автономную программу командной строки, так и библиотеку, которая может использоваться различными языками программирования. В частности, cURL является, чаще всего, идеальным решением HTTP-клиента для разработчиков PHP. Другие языки, такие как Python, предлагают больше собственных клиентских HTTP-библиотек.
Настройка примера приложения
Я хочу показать как можно более низкий уровень функциональности.
Наш пример PHP-приложения чрезвычайно тощ. Я хочу выставить как можно более низкоуровневую функциональность, без какой-либо магии framework . Я также не хотел использовать настоящий API, например, Twitter, потому что они могут неожиданно меняться, вам нужно настроить аутентификацию, что может быть проблемой и вы не сможете изучить реализацию.
Чтобы запустить пример приложения, вам необходимо установить PHP5 и веб-сервер с механизмом для запуска PHP. Текущая версия должна быть не ниже версии 5.2, чтобы иметь доступ к функциям json_encode () и json_decode ().
Что касается серверов, наиболее распространенным вариантом является Apache с mod_php, но вы можете использовать любые альтернативы, которые вам удобны. Существует пример конфигурации Apache, который содержит правила перезаписи, которые помогут вам быстро настроить приложение. Все запросы к любому URL, начиная с /clients/, должны быть направлены в наш файл server.php.
В Apache вам нужно включить mod_rewrite и поместить прилагаемую конфигурацию mod_rewrite где-нибудь в вашей конфигурации Apache или в ваш файл .htacess. Таким образом, server.php будет отвечать на все запросы, поступающие с сервера. То же самое должно быть достигнуто с Nginx, или с любым другим сервером, который вы решите использовать.
Как работает пример приложения
Есть два ключа по обработке запросов REST. Первый ключ — инициировать различную обработку, в зависимости от метода HTTP, даже когда URL-адреса одинаковы. В PHP в глобальном массиве $ _SERVER есть переменная, которая определяет, какой метод был использован для выполнения запроса:
1 |
$_SERVER['REQUEST_METHOD'] |
Эта переменная содержит имя метода в виде строки, например ‘GET‘, ‘PUT‘ и далее.
Другой ключ — узнать, какой URL был запрошен. Для этого мы используем другую стандартную переменную PHP:
1 |
$_SERVER['REQUEST_URI'] |
Эта переменная содержит URL-адрес, начинающийся с первой косой черты. Например, если имя хоста — ‘example.com‘, ‘http://example.com/‘ вернётся ‘/‘, как ‘http://example.com/test/‘ вернётся ‘/test/‘.
Давайте сначала попытаемся определить, какой URL-адрес был вызван. Мы рассматриваем только URL-адреса, начинающиеся с ‘clients‘. Все остальные недействительны.
1 |
$resource = array_shift($paths); |
2 |
|
3 |
if ($resource == 'clients') { |
4 |
$name = array_shift($paths); |
5 |
|
6 |
if (empty($name)) { |
7 |
$this->handle_base($method); |
8 |
} else { |
9 |
$this->handle_name($method, $name); |
10 |
}
|
11 |
|
12 |
} else { |
13 |
// We only handle resources under 'clients'
|
14 |
header('HTTP/1.1 404 Not Found'); |
15 |
}
|
У нас есть два возможных результата:
- Ресурс — это клиенты, и в этом случае мы возвращаем полный список
- Существует еще один идентификатор
Если есть ещё один идентификатор, мы предполагаем, что это имя клиента, и, опять же, перенаправляем его в другую функцию, в зависимости от method. Мы используем оператор switch, которого следует избегать в реальном приложении:
1 |
switch($method) { |
2 |
case 'PUT': |
3 |
$this->create_contact($name); |
4 |
break; |
5 |
|
6 |
case 'DELETE': |
7 |
$this->delete_contact($name); |
8 |
break; |
9 |
|
10 |
case 'GET': |
11 |
$this->display_contact($name); |
12 |
break; |
13 |
|
14 |
default: |
15 |
header('HTTP/1.1 405 Method Not Allowed'); |
16 |
header('Allow: GET, PUT, DELETE'); |
17 |
break; |
18 |
}
|
Коды ответов
Коды ответа HTTP стандартизируют способ информирования клиента о результате его запроса.
Вы могли заметить, что пример приложения использует PHP header(), передавая некоторые странные строки в качестве аргументов. Функция header() печатает HTTP headers и гарантирует, что они отформатированы соответствующим образом. Заголовки должны быть первым в ответе, поэтому не стоит выводить что-либо ещё до того, как вы закончите с заголовками. Иногда ваш HTTP-сервер может быть настроен для добавления других заголовков в дополнение к тем, которые вы указали в коде.
Заголовки содержат все виды метаинформации; например, текстовую кодировку, используемую в body сообщения, или MIME-тип содержимого body. В этом случае мы явно указываем коды ответа HTTP. Коды ответа HTTP стандартизируют способ информирования клиента о результате его запроса. По умолчанию PHP возвращает код ответа 200, что означает, что ответ выполнен успешно.
Сервер должен вернуть наиболее подходящий код ответа HTTP; таким образом клиент может попытаться исправить свои ошибки, если они есть. Большинство людей знакомы с распространенным кодом ответа 404 Not Found, однако есть много более доступных, в соответствии множеству ситуаций.
Имейте в виду, что значение кода ответа HTTP не является чрезвычайно точным; это следствие того, что HTTP сам по себе довольно общий. Вы должны попытаться найти код ответа, который наиболее точно соответствует ситуации. Но и не слишком переживайте, если не сможете найти точное соответствие.
Вот несколько HTTP-кодов ответа, которые часто используются с REST:
200 OK
Этот код ответа указывает, что запрос был успешным.
201 Created
Это означает, что запрос был успешным и был создан ресурс. Он используется в случае успеха запроса PUT или POST.
400 Bad Request
Запрос был утерян. Это происходит особенно с запросами POST и PUT, когда данные не проходят валидацию или находятся в неправильном формате.
404 Not Found
Этот ответ указывает, что необходимый ресурс не найден. Обычно это относится ко всем запросам, которые указывают на URL-адрес без соответствующего ресурса.
401 Unauthorized
Эта ошибка означает, что вам необходимо выполнить проверку подлинности перед доступом к ресурсу.
405 Method Not Allowed
Используемый метод HTTP не поддерживается для этого ресурса.
409 Conflict
Это указывает на конфликт. Например, вы используете запрос PUT для создания одного и того же ресурса дважды.
500 Internal Server Error
Когда всё остальное терпит неудачу; как правило, ответ 500 используется, когда обработка завершается неудачно из-за непредвиденных обстоятельств на стороне сервера, что вызывает ошибку сервера.
Выполнение образца приложения
Давайте начнем с простого извлечения информации из приложения. Нам нужны детали клиента, ‘jim‘, поэтому давайте отправим простой запрос GET на URL этого ресурса:
1 |
curl -v http://localhost:80/clients/jim
|
Это отобразит полные сообщения headers. Последней строкой ответа будет body сообщения; в этом случае это будет JSON, содержащий адрес Jim (помните, что пропуск имени метода приведет к GET-запросу, а также замените localhost: 80 на имя сервера и порт, который вы используете).
Затем мы можем получить информацию для всех клиентов одновременно:
1 |
curl -v http://localhost:80/clients/
|
Чтобы создать нового клиента с именем Paul …
1 |
curl -v -X PUT http://localhost:80/clients/paul -d '{"address":"Sunset Boulevard" } |
и вы получите список всех клиентов, содержащих Paul в качестве подтверждения.
Наконец, чтобы удалить клиента:
1 |
curl -v -X DELETE http://localhost:80/clients/anne |
Вы обнаружите, что возвращённый JSON больше не содержит никаких данных об Anne.
Если вы пытаетесь получить несуществующего клиента, например:
1 |
curl -v http://localhost:80/clients/jerry
|
Вы получите ошибку 404, в то время как при попытке создать уже существующего клиента:
curl -v -X PUT http://localhost:80/clients/anne
вместо этого получите ошибку 409.
Заключение
В общем, чем меньше предположений за пределами HTTP вы делаете, тем лучше.
Важно помнить, что HTTP был задуман для взаимодействия между системами, которые ничто не разделяет, кроме понимания протокола. В целом, чем меньше допущений за пределами HTTP вы делаете, тем лучше: это позволяет широкому кругу программ и устройств получать доступ к вашему API.
Я использовал PHP в этом уроке, потому что это, скорее всего, язык, наиболее знакомый читателям Nettuts +. Тем не менее, PHP, хотя и предназначен для Интернета, вероятно, не самый лучший язык для работы при REST-способе, поскольку он обрабатывает запросы PUT совсем иначе, чем GET и POST.
Помимо PHP, вы можете принять во внимание следующее:
- Различные Ruby frameworks (Rails и Sinatra)
- В Python есть отличная поддержка REST. Должны работать Plain Django и WebOb, или Werkzeug.
- node.js отлично поддерживает REST
Среди приложений, которые пытаются придерживаться принципов REST, классическим примером является Atom Publishing Protocol, хотя на самом деле он не используется слишком часто на практике. За современным приложением, основанным на философии использования HTTP в полной мере, обратитесь к Apache CouchDB.
Удачи!
Время на прочтение
9 мин
Количество просмотров 1.3M
Вашему вниманию предлагается описание основных аспектов протокола HTTP — сетевого протокола, с начала 90-х и по сей день позволяющего вашему браузеру загружать веб-страницы. Данная статья написана для тех, кто только начинает работать с компьютерными сетями и заниматься разработкой сетевых приложений, и кому пока что сложно самостоятельно читать официальные спецификации.
HTTP — широко распространённый протокол передачи данных, изначально предназначенный для передачи гипертекстовых документов (то есть документов, которые могут содержать ссылки, позволяющие организовать переход к другим документам).
Аббревиатура HTTP расшифровывается как HyperText Transfer Protocol, «протокол передачи гипертекста». В соответствии со спецификацией OSI, HTTP является протоколом прикладного (верхнего, 7-го) уровня. Актуальная на данный момент версия протокола, HTTP 1.1, описана в спецификации RFC 2616.
Протокол HTTP предполагает использование клиент-серверной структуры передачи данных. Клиентское приложение формирует запрос и отправляет его на сервер, после чего серверное программное обеспечение обрабатывает данный запрос, формирует ответ и передаёт его обратно клиенту. После этого клиентское приложение может продолжить отправлять другие запросы, которые будут обработаны аналогичным образом.
Задача, которая традиционно решается с помощью протокола HTTP — обмен данными между пользовательским приложением, осуществляющим доступ к веб-ресурсам (обычно это веб-браузер) и веб-сервером. На данный момент именно благодаря протоколу HTTP обеспечивается работа Всемирной паутины.
Также HTTP часто используется как протокол передачи информации для других протоколов прикладного уровня, таких как SOAP, XML-RPC и WebDAV. В таком случае говорят, что протокол HTTP используется как «транспорт».
API многих программных продуктов также подразумевает использование HTTP для передачи данных — сами данные при этом могут иметь любой формат, например, XML или JSON.
Как правило, передача данных по протоколу HTTP осуществляется через TCP/IP-соединения. Серверное программное обеспечение при этом обычно использует TCP-порт 80 (и, если порт не указан явно, то обычно клиентское программное обеспечение по умолчанию использует именно 80-й порт для открываемых HTTP-соединений), хотя может использовать и любой другой.
Как отправить HTTP-запрос?
Самый простой способ разобраться с протоколом HTTP — это попробовать обратиться к какому-нибудь веб-ресурсу вручную. Представьте, что вы браузер, и у вас есть пользователь, который очень хочет прочитать статьи Анатолия Ализара.
Предположим, что он ввёл в адресной строке следующее:
http://alizar.habrahabr.ru/
Соответственно вам, как веб-браузеру, теперь необходимо подключиться к веб-серверу по адресу alizar.habrahabr.ru.
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
telnet alizar.habrahabr.ru 80
Сразу уточню, что если вы вдруг передумаете, то нажмите Ctrl + «]», и затем ввод — это позволит вам закрыть HTTP-соединение. Помимо telnet можете попробовать nc (или ncat) — по вкусу.
После того, как вы подключитесь к серверу, нужно отправить HTTP-запрос. Это, кстати, очень легко — HTTP-запросы могут состоять всего из двух строчек.
Для того, чтобы сформировать HTTP-запрос, необходимо составить стартовую строку, а также задать по крайней мере один заголовок — это заголовок Host, который является обязательным, и должен присутствовать в каждом запросе. Дело в том, что преобразование доменного имени в IP-адрес осуществляется на стороне клиента, и, соответственно, когда вы открываете TCP-соединение, то удалённый сервер не обладает никакой информацией о том, какой именно адрес использовался для соединения: это мог быть, например, адрес alizar.habrahabr.ru, habrahabr.ru или m.habrahabr.ru — и во всех этих случаях ответ может отличаться. Однако фактически сетевое соединение во всех случаях открывается с узлом 212.24.43.44, и даже если первоначально при открытии соединения был задан не этот IP-адрес, а какое-либо доменное имя, то сервер об этом никак не информируется — и именно поэтому этот адрес необходимо передать в заголовке Host.
Стартовая (начальная) строка запроса для HTTP 1.1 составляется по следующей схеме:
Метод URI HTTP/Версия
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
GET / HTTP/1.1
Метод (в англоязычной тематической литературе используется слово method, а также иногда слово verb — «глагол») представляет собой последовательность из любых символов, кроме управляющих и разделителей, и определяет операцию, которую нужно осуществить с указанным ресурсом. Спецификация HTTP 1.1 не ограничивает количество разных методов, которые могут быть использованы, однако в целях соответствия общим стандартам и сохранения совместимости с максимально широким спектром программного обеспечения как правило используются лишь некоторые, наиболее стандартные методы, смысл которых однозначно раскрыт в спецификации протокола.
URI (Uniform Resource Identifier, унифицированный идентификатор ресурса) — путь до конкретного ресурса (например, документа), над которым необходимо осуществить операцию (например, в случае использования метода GET подразумевается получение ресурса). Некоторые запросы могут не относиться к какому-либо ресурсу, в этом случае вместо URI в стартовую строку может быть добавлена звёздочка (астериск, символ «*»). Например, это может быть запрос, который относится к самому веб-серверу, а не какому-либо конкретному ресурсу. В этом случае стартовая строка может выглядеть так:
OPTIONS * HTTP/1.1
Версия определяет, в соответствии с какой версией стандарта HTTP составлен запрос. Указывается как два числа, разделённых точкой (например 1.1).
Для того, чтобы обратиться к веб-странице по определённому адресу (в данном случае путь к ресурсу — это «/»), нам следует отправить следующий запрос:
GET / HTTP/1.1
Host: alizar.habrahabr.ru
При этом учитывайте, что для переноса строки следует использовать символ возврата каретки (Carriage Return), за которым следует символ перевода строки (Line Feed). После объявления последнего заголовка последовательность символов для переноса строки добавляется дважды.
Впрочем, в спецификации HTTP рекомендуется программировать HTTP-сервер таким образом, чтобы при обработке запросов в качестве межстрочного разделителя воспринимался символ LF, а предшествующий символ CR, при наличии такового, игнорировался. Соответственно, на практике бо́льшая часть серверов корректно обработает и такой запрос, где заголовки отделены символом LF, и он же дважды добавлен после объявления последнего заголовка.
Если вы хотите отправить запрос в точном соответствии со спецификацией, можете воспользоваться управляющими последовательностями r и n:
echo -en "GET / HTTP/1.1rnHost: alizar.habrahabr.rurnrn" | ncat alizar.habrahabr.ru 80
Как прочитать ответ?
Стартовая строка ответа имеет следующую структуру:
HTTP/Версия Код состояния Пояснение
Версия протокола здесь задаётся так же, как в запросе.
Код состояния (Status Code) — три цифры (первая из которых указывает на класс состояния), которые определяют результат совершения запроса. Например, в случае, если был использован метод GET, и сервер предоставляет ресурс с указанным идентификатором, то такое состояние задаётся с помощью кода 200. Если сервер сообщает о том, что такого ресурса не существует — 404. Если сервер сообщает о том, что не может предоставить доступ к данному ресурсу по причине отсутствия необходимых привилегий у клиента, то используется код 403. Спецификация HTTP 1.1 определяет 40 различных кодов HTTP, а также допускается расширение протокола и использование дополнительных кодов состояний.
Пояснение к коду состояния (Reason Phrase) — текстовое (но не включающее символы CR и LF) пояснение к коду ответа, предназначено для упрощения чтения ответа человеком. Пояснение может не учитываться клиентским программным обеспечением, а также может отличаться от стандартного в некоторых реализациях серверного ПО.
После стартовой строки следуют заголовки, а также тело ответа. Например:
HTTP/1.1 200 OK
Server: nginx/1.2.1
Date: Sat, 08 Mar 2014 22:53:46 GMT
Content-Type: application/octet-stream
Content-Length: 7
Last-Modified: Sat, 08 Mar 2014 22:53:30 GMT
Connection: keep-alive
Accept-Ranges: bytes
Wisdom
Тело ответа следует через два переноса строки после последнего заголовка. Для определения окончания тела ответа используется значение заголовка Content-Length (в данном случае ответ содержит 7 восьмеричных байтов: слово «Wisdom» и символ переноса строки).
Но вот по тому запросу, который мы составили ранее, веб-сервер вернёт ответ не с кодом 200, а с кодом 302. Таким образом он сообщает клиенту о том, что обращаться к данному ресурсу на данный момент нужно по другому адресу.
Смотрите сами:
HTTP/1.1 302 Moved Temporarily
Server: nginx
Date: Sat, 08 Mar 2014 22:29:53 GMT
Content-Type: text/html
Content-Length: 154
Connection: keep-alive
Keep-Alive: timeout=25
Location: http://habrahabr.ru/users/alizar/
<html>
<head><title>302 Found</title></head>
<body bgcolor="white">
<center><h1>302 Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
В заголовке Location передан новый адрес. Теперь URI (идентификатор ресурса) изменился на /users/alizar/, а обращаться нужно на этот раз к серверу по адресу habrahabr.ru (впрочем, в данном случае это тот же самый сервер), и его же указывать в заголовке Host.
То есть:
GET /users/alizar/ HTTP/1.1
Host: habrahabr.ru
В ответ на этот запрос веб-сервер Хабрахабра уже выдаст ответ с кодом 200 и достаточно большой документ в формате HTML.
Если вы уже успели вжиться в роль, то можете теперь прочитать полученный от сервера HTML-код, взять карандаш и блокнот, и нарисовать профайл Ализара — в принципе, именно этим бы на вашем месте браузер сейчас и занялся.
А что с безопасностью?
Сам по себе протокол HTTP не предполагает использование шифрования для передачи информации. Тем не менее, для HTTP есть распространённое расширение, которое реализует упаковку передаваемых данных в криптографический протокол SSL или TLS.
Название этого расширения — HTTPS (HyperText Transfer Protocol Secure). Для HTTPS-соединений обычно используется TCP-порт 443. HTTPS широко используется для защиты информации от перехвата, а также, как правило, обеспечивает защиту от атак вида man-in-the-middle — в том случае, если сертификат проверяется на клиенте, и при этом приватный ключ сертификата не был скомпрометирован, пользователь не подтверждал использование неподписанного сертификата, и на компьютере пользователя не были внедрены сертификаты центра сертификации злоумышленника.
На данный момент HTTPS поддерживается всеми популярными веб-браузерами.
А есть дополнительные возможности?
Протокол HTTP предполагает достаточно большое количество возможностей для расширения. В частности, спецификация HTTP 1.1 предполагает возможность использования заголовка Upgrade для переключения на обмен данными по другому протоколу. Запрос с таким заголовком отправляется клиентом. Если серверу требуется произвести переход на обмен данными по другому протоколу, то он может вернуть клиенту ответ со статусом «426 Upgrade Required», и в этом случае клиент может отправить новый запрос, уже с заголовком Upgrade.
Такая возможность используется, в частности, для организации обмена данными по протоколу WebSocket (протокол, описанный в спецификации RFC 6455, позволяющий обеим сторонам передавать данные в нужный момент, без отправки дополнительных HTTP-запросов): стандартное «рукопожатие» (handshake) сводится к отправке HTTP-запроса с заголовком Upgrade, имеющим значение «websocket», на который сервер возвращает ответ с состоянием «101 Switching Protocols», и далее любая сторона может начать передавать данные уже по протоколу WebSocket.
Что-то ещё, кстати, используют?
На данный момент существуют и другие протоколы, предназначенные для передачи веб-содержимого. В частности, протокол SPDY (произносится как английское слово speedy, не является аббревиатурой) является модификацией протокола HTTP, цель которой — уменьшить задержки при загрузке веб-страниц, а также обеспечить дополнительную безопасность.
Увеличение скорости обеспечивается посредством сжатия, приоритизации и мультиплексирования дополнительных ресурсов, необходимых для веб-страницы, чтобы все данные можно было передать в рамках одного соединения.
Опубликованный в ноябре 2012 года черновик спецификации протокола HTTP 2.0 (следующая версия протокола HTTP после версии 1.1, окончательная спецификация для которой была опубликована в 1999) базируется на спецификации протокола SPDY.
Многие архитектурные решения, используемые в протоколе SPDY, а также в других предложенных реализациях, которые рабочая группа httpbis рассматривала в ходе подготовки черновика спецификации HTTP 2.0, уже ранее были получены в ходе разработки протокола HTTP-NG, однако работы над протоколом HTTP-NG были прекращены в 1998.
На данный момент поддержка протокола SPDY есть в браузерах Firefox, Chromium/Chrome, Opera, Internet Exporer и Amazon Silk.
И что, всё?
В общем-то, да. Можно было бы описать конкретные методы и заголовки, но фактически эти знания нужны скорее в том случае, если вы пишете что-то конкретное (например, веб-сервер или какое-то клиентское программное обеспечение, которое связывается с серверами через HTTP), и для базового понимания принципа работы протокола не требуются. К тому же, всё это вы можете очень легко найти через Google — эта информация есть и в спецификациях, и в Википедии, и много где ещё.
Впрочем, если вы знаете английский и хотите углубиться в изучение не только самого HTTP, но и используемых для передачи пакетов TCP/IP, то рекомендую прочитать вот эту статью.
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.
Удачи и плодотворного обучения!
Протокол передачи гипертекста (HTTP) — это основа жизни в Интернете. Он используется каждый раз при передаче документа или в запросе AJAX. Но HTTP на удивление мало известен некоторым веб-разработчикам.
В этом введении мы познакомимся с принципами разработки REST, лежащими в основе HTTP и использованию их мощи для создания интерфейсов, которые могут выполняться практически с любого устройства или операционной системы.
Переизданный урок
Каждые несколько недель мы пересматриваем некоторые из любимых сообщений наших читателей за всю историю сайта. Этот урок впервые был опубликован в ноябре 2010 года.
Почему REST?
REST — простой способ организации взаимодействия между независимыми системами.
REST — простой способ организации взаимодействия между независимыми системами. Он пользуется популярностью с 2005 года и вдохновляет дизайн сервисов, таких как API Twitter. Благодаря тому, что REST обеспечивает взаимодействие с такими разнообразными клиентами, как мобильные телефоны и другие веб-сайты. Теоретически, REST не привязан к сети, но почти всегда реализован как таковой и был вдохновлен HTTP. В результате REST можно использовать везде, где возможен HTTP.
Альтернативой является создание относительно сложных соглашений поверх HTTP. Часто это принимает форму новых XML-языков. Самый яркий пример — SOAP. Вам нужно выучить совершенно новый набор соглашений, но вы никогда не используете HTTP в полную силу. Поскольку REST был вдохновлён HTTP и играет на его сильные стороны, это лучший способ узнать, как работает HTTP.
После первоначального обзора мы рассмотрим каждый из строительных блоков HTTP: URL-адреса, HTTP-команды и коды ответов. Мы также рассмотрим, как использовать их в RESTful. Попутно мы проиллюстрируем теорию примером приложения, которое имитирует процесс отслеживания данных, связанных с клиентами компании через веб-интерфейс.
HTTP
HTTP — это протокол, который позволяет отправлять документы в Интернете.
HTTP — это протокол, который позволяет отправлять документы в Интернете. Протокол — это набор правил, определяющих, какие сообщения можно обменивать, и какие сообщения являются подходящими ответами для других. Другим распространенным протоколом является POP3, который вы можете использовать для извлечения электронной почты на вашем жёстком диске.
В HTTP есть две разные роли: сервер и клиент. Как правило, клиент всегда инициирует разговор; сервер отвечает. HTTP основан на тексте; то есть сообщения по сути являются битами текста, хотя тело сообщения может также содержать другие носители. Использование текста позволяет легко отслеживать обмен HTTP.
HTTP-сообщения состоят из заголовка и тела. Тело часто может оставаться пустым; оно содержит данные, которые вы хотите передать по сети, чтобы использовать их в соответствии с инструкциями в заголовке. Заголовок содержит метаданные, например информацию о кодировке; но, в случае запроса, он также содержит важные HTTP-методы. В стиле REST вы обнаружите, что данные заголовка часто более значимы, чем тела.
Шпионство HTTP на работе
Если вы используете Chrome Developer Tools или Firefox с расширением Firebug, щелкните на панели Net и установите его в enabled. После этого у вас будет возможность просматривать информацию о HTTP-запросах по мере вашего поиска. Например:
Другим полезным способом ознакомиться с HTTP является использование выделенного клиента, такого как cURL.
cURL — это инструмент command line, который доступен во всех основных операционных системах.
После установки cURL введите:
curl -v google.com
Будет отображен полный диалог HTTP. Запросам предшествует >, а ответам предшествует <.
URLS
URL — это, как вы определяете то, на чём вы хотите работать. Мы говорим, что каждый URL-адрес идентифицирует ресурс. Это те же самые URL-адреса, которые назначены веб-страницам. Фактически, веб-страница — это тип ресурса. Давайте рассмотрим более экзотический пример с нашим образцом приложения, которое управляет списком клиентов компании:
/clients
будет идентифицировать всех клиентов, в то время как
/clients/jim
определяет клиента с именем «Jim», предполагая, что он единственный с таким именем.
В этих примерах мы обычно не включаем hostname в URL, так как это не имеет никакого отношения к организации интерфейса. Тем не менее, hostname важно для того, чтобы идентификатор ресурса был уникальным во всей сети. Мы часто говорим, что вы отправляете запрос на ресурс к host. Хост включается в заголовок отдельно от пути ресурса, который идёт прямо над заголовком запроса:
GET /clients/jim HTTP/1.1Host: example.com
Ресурсы лучше всего рассматривать как существительные. Например, следующее не RESTful:
/clients/add
Это связано с тем, что для описания действия используется URL-адрес. Это довольно фундаментальный момент в различиях систем RESTful от систем без RESTful.
Наконец, URL-адреса должны быть максимально точными; всё, что необходимо для уникальной идентификации ресурса, должно быть в URL-адресе. Вам не нужно включать в запрос данные, идентифицирующие ресурс. Таким образом, URL-адреса выступают в качестве полной карты всех данных, обрабатываемых приложением.
Но как вы определяете действие? Например, как сообщить, что вы хотите создать новую запись клиента вместо её получения? Именно здесь вступают в действие глаголы HTTP.
Глаголы HTTP
Каждый запрос указывает определенный HTTP глагол или метод в заголовке запроса. Это первое слово в заголовке запроса. Например,
GET / HTTP/1.1
означает, что используется метод GET, а
DELETE /clients/anne HTTP/1.1
означает использование метода DELETE .
Глаголы HTTP сообщают серверу, что делать с данными, указанными URL.
Глаголы HTTP сообщают серверу, что делать с данными, указанными URL. Запрос может ещё содержать дополнительную информацию в своем теле, которая может потребоваться для выполнения операции — например, данные, которые вы хотите сохранить с ресурсом. Эти данные можно указать в cURL с параметром -d.
Если вы когда-либо создавали HTML-формы, то знакомы с двумя из наиболее важных HTTP-глаголов: GET и POST. Но есть гораздо больше доступных HTTP-глаголов. Наиболее важными для построения RESTful API являются GET, POST, PUT и DELETE. Доступны другие методы, такие как HEAD и OPTIONS, но они более редки (если вы хотите знать обо всех других методах HTTP, официальным источником является IETF).
GET
GET — это самый простой тип HTTP-запроса; которым браузер пользуется каждый раз, когда вы нажимаете ссылку или вводите URL-адрес в адресную строку. Он инструктирует сервер передавать клиенту данные, идентифицированные URL-адресом. Никогда не последует изменений данных на стороне сервера в результате запроса GET. В этом смысле GET-запрос доступен только для чтения, но, конечно, как только клиент получит данные, он может самостоятельно выполнять любые операции с ними, например, форматировать для отображения.
PUT
Запрос PUT используется, когда вы хотите создать или обновить ресурс, указанный URL-адресом. Например,
PUT /clients/robin
может создать клиента с именем Robin на сервере. Вы заметите, что REST полностью независим от бэкэнда; в запросе нет ничего, что информирует сервер о том, как данные должны создаваться — просто так должно быть. Это позволяет вам легко менять базовую технологию по необходимости. Запросы PUT содержат данные для использования при обновлении или создании ресурса в body. В cURL вы можете добавить данные в запрос с помощью -d.
curl -v -X PUT -d "some text"
DELETE
DELETE должен выполнять противоположное PUT; его следует использовать, если вы хотите удалить ресурс, указанный URL-адресом запроса.
curl -v -X DELETE /clients/anne
Это приведёт к удалению всех данных, связанных с ресурсом, идентифицированных /clients/anne.
POST
POST используется, когда обработка, которую вы хотите выполнить на сервере, должна повторяться, если запрос POST повторяется (то есть, они не являются идемпотентными, подробнее об этом ниже). Кроме того, POST-запросы должны вызывать обработку body запроса как подчинённого URL-адреса, который вы отправляете.
Проще говоря:
POST /clients/
не должен вызывать изменение ресурса в /clients/ сам, но ресурс URL начинается с него /clients/. Например, он может добавить в список нового клиента, с id, сгенерированным сервером.
/clients/some-unique-id
Запросы PUT легко используются вместо запросов POST и наоборот. Некоторые системы используют только один, некоторые используют POST для создания операций и PUT для операций обновления (поскольку с запросом PUT вы всегда указываете полный URL-адрес), некоторые используют POST для обновлений и PUT для создания.
Часто запросы POST используются для запуска операций на сервере, которые не вписываются в парадигму Create/Update/Delete; но это, однако, выходит за рамки REST. В нашем примере мы будем полностью придерживаться PUT.
Классификация методов HTTP
Безопасные и небезопасные методы:
безопасными являются методы, которые никогда не изменяют ресурсы. Единственными безопасными методами, из четырёх перечисленных выше, является GET. Другие небезопасны, так как они могут привести к модификации ресурсов.
Idempotent методы:
Эти методы достигают того же результата, независимо от того, сколько раз запрос повторяется: это GET, PUT и DELETE. Единственным неидемпотентным методом является POST. PUT и DELETE, считающиеся идемпотентами, могут быть неожиданными, хотя, на самом деле, это довольно легко объяснить: повторение метода PUT с точно таким же body должно модифицировать ресурс таким образом, чтобы он оставался идентичным описанному в предыдущем запросе PUT: ничего не изменится! Аналогичным образом, нет смысла дважды удалять ресурс. Из этого следует, что независимо от того, сколько раз запрос PUT или DELETE повторяется, результат должен быть таким же, как если бы это было сделано только один раз.
Помните: именно вы, программист, в конечном счете решаете, что происходит, когда используется определённый HTTP-метод. В реализациях HTTP нет ничего, что автоматически приведёт к созданию ресурсов, их перечислению, удалению или обновлению. Вы должны быть осторожны, чтобы правильно применять HTTP-протокол и вводить эту семантику самостоятельно.
Представительства
HTTP-клиент и HTTP-сервер обмениваются информацией о ресурсах, определённых URL-адресами.
Мы можем суммировать то, что мы узнали до сих пор, следующим образом: HTTP-клиент и HTTP-сервер обмениваются информацией о ресурсах, определённых URL-адресами.
Мы говорим, что запрос и ответ содержат представление ресурса. Под представлением мы подразумеваем информацию в определённом формате о состоянии ресурса или о том, каким это состояние должно быть в будущем. Оба, и header, и body — являются частями представления.
Заголовки HTTP, содержащие метаданные, жёстко определяются спецификацией HTTP; они могут содержать только простой текст и должны быть отформатированы определённым образом.
Тело может содержать данные в любом формате, и именно здесь видна сила HTTP. Вы знаете, что можете отправлять простой текст, изображения, HTML и XML на любом человеческом языке. Через метаданные запроса или различные URL-адреса вы можете выбирать между различными представлениями для одного и того же ресурса. Например, вы можете отправить веб-страницу в браузеры и JSON в приложения.
HTTP-ответ должен указывать тип содержимого body. Это делается в заголовке, в поле Content-Type; например:
Content/Type: application/json
Для простоты наше приложение только отправляет JSON туда и обратно, но приложение должно быть спроектировано таким образом, чтобы вы могли легко изменять формат данных, чтобы адаптироваться для разных клиентов или предпочтений пользователя.
Библиотеки клиента HTTP
cURL — это, чаще всего, HTTP-решение для PHP-разработчиков.
Чтобы поэкспериментировать с различными методами запроса, вам нужен клиент, который позволит указать, какой метод использовать. К сожалению, формы HTML не подходят для счёта, так как они позволяют делать только запросы GET и POST. В реальной жизни API-интерфейсы доступны программно через отдельное клиентское приложение или через JavaScript в браузере.
Именно поэтому в дополнение к серверу важно иметь хорошие возможности HTTP-клиента на выбранном вами языке программирования.
Очень популярная клиентская HTTP-библиотека, опять же, cURL. Вы уже были ознакомлены с командой cURL ранее в этом уроке. CURL включает в себя как автономную программу командной строки, так и библиотеку, которая может использоваться различными языками программирования. В частности, cURL является, чаще всего, идеальным решением HTTP-клиента для разработчиков PHP. Другие языки, такие как Python, предлагают больше собственных клиентских HTTP-библиотек.
Настройка примера приложения
Я хочу показать как можно более низкий уровень функциональности.
Наш пример PHP-приложения чрезвычайно тощ. Я хочу выставить как можно более низкоуровневую функциональность, без какой-либо магии framework . Я также не хотел использовать настоящий API, например, Twitter, потому что они могут неожиданно меняться, вам нужно настроить аутентификацию, что может быть проблемой и вы не сможете изучить реализацию.
Чтобы запустить пример приложения, вам необходимо установить PHP5 и веб-сервер с механизмом для запуска PHP. Текущая версия должна быть не ниже версии 5.2, чтобы иметь доступ к функциям json_encode () и json_decode ().
Что касается серверов, наиболее распространенным вариантом является Apache с mod_php, но вы можете использовать любые альтернативы, которые вам удобны. Существует пример конфигурации Apache, который содержит правила перезаписи, которые помогут вам быстро настроить приложение. Все запросы к любому URL, начиная с /clients/, должны быть направлены в наш файл server.php.
В Apache вам нужно включить mod_rewrite и поместить прилагаемую конфигурацию mod_rewrite где-нибудь в вашей конфигурации Apache или в ваш файл .htacess. Таким образом, server.php будет отвечать на все запросы, поступающие с сервера. То же самое должно быть достигнуто с Nginx, или с любым другим сервером, который вы решите использовать.
Как работает пример приложения
Есть два ключа по обработке запросов REST. Первый ключ — инициировать различную обработку, в зависимости от метода HTTP, даже когда URL-адреса одинаковы. В PHP в глобальном массиве $ _SERVER есть переменная, которая определяет, какой метод был использован для выполнения запроса:
$_SERVER["REQUEST_METHOD"]
Эта переменная содержит имя метода в виде строки, например «GET«, «PUT» и далее.
Другой ключ — узнать, какой URL был запрошен. Для этого мы используем другую стандартную переменную PHP:
$_SERVER["REQUEST_URI"]
Эта переменная содержит URL-адрес, начинающийся с первой косой черты. Например, если имя хоста — «example.com«, «http://example.com/» вернётся «/«, как «http://example.com/test/» вернётся «/test/«.
Давайте сначала попытаемся определить, какой URL-адрес был вызван. Мы рассматриваем только URL-адреса, начинающиеся с «clients«. Все остальные недействительны.
$resource = array_shift($paths);if ($resource == "clients") { $name = array_shift($paths); if (empty($name)) { $this->handle_base($method); } else { $this->handle_name($method, $name); }} else { // We only handle resources under "clients" header("HTTP/1.1 404 Not Found");}
У нас есть два возможных результата:
- Ресурс — это клиенты, и в этом случае мы возвращаем полный список
- Существует еще один идентификатор
Если есть ещё один идентификатор, мы предполагаем, что это имя клиента, и, опять же, перенаправляем его в другую функцию, в зависимости от method. Мы используем оператор switch, которого следует избегать в реальном приложении:
switch($method) { case "PUT": $this->create_contact($name); break; case "DELETE": $this->delete_contact($name); break; case "GET": $this->display_contact($name); break; default: header("HTTP/1.1 405 Method Not Allowed"); header("Allow: GET, PUT, DELETE"); break; }
Коды ответов
Коды ответа HTTP стандартизируют способ информирования клиента о результате его запроса.
Вы могли заметить, что пример приложения использует PHP header(), передавая некоторые странные строки в качестве аргументов. Функция header() печатает HTTP headers и гарантирует, что они отформатированы соответствующим образом. Заголовки должны быть первым в ответе, поэтому не стоит выводить что-либо ещё до того, как вы закончите с заголовками. Иногда ваш HTTP-сервер может быть настроен для добавления других заголовков в дополнение к тем, которые вы указали в коде.
Заголовки содержат все виды метаинформации; например, текстовую кодировку, используемую в body сообщения, или MIME-тип содержимого body. В этом случае мы явно указываем коды ответа HTTP. Коды ответа HTTP стандартизируют способ информирования клиента о результате его запроса. По умолчанию PHP возвращает код ответа 200, что означает, что ответ выполнен успешно.
Сервер должен вернуть наиболее подходящий код ответа HTTP; таким образом клиент может попытаться исправить свои ошибки, если они есть. Большинство людей знакомы с распространенным кодом ответа 404 Not Found, однако есть много более доступных, в соответствии множеству ситуаций.
Имейте в виду, что значение кода ответа HTTP не является чрезвычайно точным; это следствие того, что HTTP сам по себе довольно общий. Вы должны попытаться найти код ответа, который наиболее точно соответствует ситуации. Но и не слишком переживайте, если не сможете найти точное соответствие.
Вот несколько HTTP-кодов ответа, которые часто используются с REST:
200 OK
Этот код ответа указывает, что запрос был успешным.
201 Created
Это означает, что запрос был успешным и был создан ресурс. Он используется в случае успеха запроса PUT или POST.
400 Bad Request
Запрос был утерян. Это происходит особенно с запросами POST и PUT, когда данные не проходят валидацию или находятся в неправильном формате.
404 Not Found
Этот ответ указывает, что необходимый ресурс не найден. Обычно это относится ко всем запросам, которые указывают на URL-адрес без соответствующего ресурса.
401 Unauthorized
Эта ошибка означает, что вам необходимо выполнить проверку подлинности перед доступом к ресурсу.
405 Method Not Allowed
Используемый метод HTTP не поддерживается для этого ресурса.
409 Conflict
Это указывает на конфликт. Например, вы используете запрос PUT для создания одного и того же ресурса дважды.
500 Internal Server Error
Когда всё остальное терпит неудачу; как правило, ответ 500 используется, когда обработка завершается неудачно из-за непредвиденных обстоятельств на стороне сервера, что вызывает ошибку сервера.
Выполнение образца приложения
Давайте начнем с простого извлечения информации из приложения. Нам нужны детали клиента, «jim«, поэтому давайте отправим простой запрос GET на URL этого ресурса:
curl -v http://localhost:80/clients/jim
Это отобразит полные сообщения headers. Последней строкой ответа будет body сообщения; в этом случае это будет JSON, содержащий адрес Jim (помните, что пропуск имени метода приведет к GET-запросу, а также замените localhost: 80 на имя сервера и порт, который вы используете).
Затем мы можем получить информацию для всех клиентов одновременно:
curl -v http://localhost:80/clients/
Чтобы создать нового клиента с именем Paul …
curl -v -X PUT http://localhost:80/clients/paul -d "{"address":"Sunset Boulevard" }
и вы получите список всех клиентов, содержащих Paul в качестве подтверждения.
Наконец, чтобы удалить клиента:
curl -v -X DELETE http://localhost:80/clients/anne
Вы обнаружите, что возвращённый JSON больше не содержит никаких данных об Anne.
Если вы пытаетесь получить несуществующего клиента, например:
curl -v http://localhost:80/clients/jerry
Вы получите ошибку 404, в то время как при попытке создать уже существующего клиента:
curl -v -X PUT http://localhost:80/clients/anne
вместо этого получите ошибку 409.
Заключение
В общем, чем меньше предположений за пределами HTTP вы делаете, тем лучше.
Важно помнить, что HTTP был задуман для взаимодействия между системами, которые ничто не разделяет, кроме понимания протокола. В целом, чем меньше допущений за пределами HTTP вы делаете, тем лучше: это позволяет широкому кругу программ и устройств получать доступ к вашему API.
Я использовал PHP в этом уроке, потому что это, скорее всего, язык, наиболее знакомый читателям Nettuts +. Тем не менее, PHP, хотя и предназначен для Интернета, вероятно, не самый лучший язык для работы при REST-способе, поскольку он обрабатывает запросы PUT совсем иначе, чем GET и POST.
Помимо PHP, вы можете принять во внимание следующее:
- Различные Ruby frameworks (Rails и Sinatra)
- В Python есть отличная поддержка REST. Должны работать Plain Django и WebOb, или Werkzeug.
- node.js отлично поддерживает REST
Среди приложений, которые пытаются придерживаться принципов REST, классическим примером является Atom Publishing Protocol, хотя на самом деле он не используется слишком часто на практике. За современным приложением, основанным на философии использования HTTP в полной мере, обратитесь к Apache CouchDB.
Удачи!
HTTP — это протокол передачи гипертекста между распределёнными системами. По сути, http является фундаментальным элементом современного Web-а. Как уважающие себя веб разработчики, мы должны знать о нём как можно больше.
Давайте взглянем на этот протокол через призму нашей профессии. В первой части пройдёмся по основам, посмотрим на запросы/ответы. В следующей статье разберём уже более детальные фишки, такие как кэширование, обработка подключения и аутентификация.
Также в этой статье я буду, в основном, ссылаться на стандарт RFC 2616: Hypertext Transfer Protocol — HTTP/1.1.
Основы HTTP
HTTP обеспечивает общение между множеством хостов и клиентов, а также поддерживает целый ряд сетевых настроек.
В основном, для общения используется TCP/IP, но это не единственный возможный вариант. По умолчанию, TCP/IP использует порт 80, но можно заюзать и другие.

Общение между хостом и клиентом происходит в два этапа: запрос и ответ. Клиент формирует HTTP запрос, в ответ на который сервер даёт ответ (сообщение). Чуть позже, мы более подробно рассмотрим эту схему работы.
Текущая версия протокола HTTP — 1.1, в которой были введены некоторые новые фишки. На мой взгляд, самые важные из них это: поддержка постоянно открытого соединения, новый механизм передачи данных chunked transfer encoding, новые заголовки для кэширования. Что-то из этого мы рассмотрим во второй части данной статьи.
URL
Сердцевиной веб-общения является запрос, который отправляется через Единый указатель ресурсов (URL). Я уверен, что вы уже знаете, что такое URL адрес, однако для полноты картины, решил всё-таки сказать пару слов. Структура URL очень проста и состоит из следующих компонентов:

Протокол может быть как http для обычных соединений, так и https для более безопасного обмена данными. Порт по умолчанию — 80. Далее следует путь к ресурсу на сервере и цепочка параметров.
Методы
С помощью URL, мы определяем точное название хоста, с которым хотим общаться, однако какое действие нам нужно совершить, можно сообщить только с помощью HTTP метода. Конечно же существует несколько видов действий, которые мы можем совершить. В HTTP реализованы самые нужные, подходящие под нужды большинства приложений.
Существующие методы:
GET: получить доступ к существующему ресурсу. В URL перечислена вся необходимая информация, чтобы сервер смог найти и вернуть в качестве ответа искомый ресурс.
POST: используется для создания нового ресурса. POST запрос обычно содержит в себе всю нужную информацию для создания нового ресурса.
PUT: обновить текущий ресурс. PUT запрос содержит обновляемые данные.
DELETE: служит для удаления существующего ресурса.
Данные методы самые популярные и чаще всего используются различными инструментами и фрэймворками. В некоторых случаях, PUT и DELETE запросы отправляются посредством отправки POST, в содержании которого указано действие, которое нужно совершить с ресурсом: создать, обновить или удалить.
Также HTTP поддерживает и другие методы:
HEAD: аналогичен GET. Разница в том, что при данном виде запроса не передаётся сообщение. Сервер получает только заголовки. Используется, к примеру, для того чтобы определить, был ли изменён ресурс.
TRACE: во время передачи запрос проходит через множество точек доступа и прокси серверов, каждый из которых вносит свою информацию: IP, DNS. С помощью данного метода, можно увидеть всю промежуточную информацию.
OPTIONS: используется для определения возможностей сервера, его параметров и конфигурации для конкретного ресурса.
Коды состояния
В ответ на запрос от клиента, сервер отправляет ответ, который содержит, в том числе, и код состояния. Данный код несёт в себе особый смысл для того, чтобы клиент мог отчётливей понять, как интерпретировать ответ:
1xx: Информационные сообщения
Набор этих кодов был введён в HTTP/1.1. Сервер может отправить запрос вида: Expect: 100-continue, что означает, что клиент ещё отправляет оставшуюся часть запроса. Клиенты, работающие с HTTP/1.0 игнорируют данные заголовки.
2xx: Сообщения об успехе
Если клиент получил код из серии 2xx, то запрос ушёл успешно. Самый распространённый вариант — это 200 OK. При GET запросе, сервер отправляет ответ в теле сообщения. Также существуют и другие возможные ответы:
- 202 Accepted: запрос принят, но может не содержать ресурс в ответе. Это полезно для асинхронных запросов на стороне сервера. Сервер определяет, отправить ресурс или нет.
- 204 No Content: в теле ответа нет сообщения.
- 205 Reset Content: указание серверу о сбросе представления документа.
- 206 Partial Content: ответ содержит только часть контента. В дополнительных заголовках определяется общая длина контента и другая инфа.
3xx: Перенаправление
Своеобразное сообщение клиенту о необходимости совершить ещё одно действие. Самый распространённый вариант применения: перенаправить клиент на другой адрес.
- 301 Moved Permanently: ресурс теперь можно найти по другому URL адресу.
- 303 See Other: ресурс временно можно найти по другому URL адресу. Заголовок Location содержит временный URL.
- 304 Not Modified: сервер определяет, что ресурс не был изменён и клиенту нужно задействовать закэшированную версию ответа. Для проверки идентичности информации используется ETag (хэш Сущности — Enttity Tag);
4xx: Клиентские ошибки
Данный класс сообщений используется сервером, если он решил, что запрос был отправлен с ошибкой. Наиболее распространённый код: 404 Not Found. Это означает, что ресурс не найден на сервере. Другие возможные коды:
- 400 Bad Request: вопрос был сформирован неверно.
- 401 Unauthorized: для совершения запроса нужна аутентификация. Информация передаётся через заголовок Authorization.
- 403 Forbidden: сервер не открыл доступ к ресурсу.
- 405 Method Not Allowed: неверный HTTP метод был задействован для того, чтобы получить доступ к ресурсу.
- 409 Conflict: сервер не может до конца обработать запрос, т.к. пытается изменить более новую версию ресурса. Это часто происходит при PUT запросах.
5xx: Ошибки сервера
Ряд кодов, которые используются для определения ошибки сервера при обработке запроса. Самый распространённый: 500 Internal Server Error. Другие варианты:
- 501 Not Implemented: сервер не поддерживает запрашиваемую функциональность.
- 503 Service Unavailable: это может случиться, если на сервере произошла ошибка или он перегружен. Обычно в этом случае, сервер не отвечает, а время, данное на ответ, истекает.
Форматы сообщений запроса/ответа
На следующем изображении вы можете увидеть схематично оформленный процесс отправки запроса клиентом, обработка и отправка ответа сервером.

Давайте посмотрим на структуру передаваемого сообщения через HTTP:
message = <start-line>
*(<message-header>)
CRLF
[<message-body>]
<start-line> = Request-Line | Status-Line
<message-header> = Field-Name ':' Field-Value
Между заголовком и телом сообщения должна обязательно присутствовать пустая строка. Заголовков может быть несколько:
- Общие заголовки
- Заголовки запроса
- Заголовки ответа
- Заголовки сущностей
Тело ответа может содержать полную информацию или её часть, если активирована соответствующая возможность (Transfer-Encoding: chunked). HTTP/1.1 также поддерживает заголовок Transfer-Encoding.
Общие заголовки
Вот несколько видов заголовков, которые используются как в запросах, так и в ответах:
general-header = Cache-Control
| Connection
| Date
| Pragma
| Trailer
| Transfer-Encoding
| Upgrade
| Via
| Warning
Что-то мы уже рассмотрели в этой статье, что-то подробней затронем во второй части.
Заголовок via используется в запросе типа TRACE, и обновляется всеми прокси-серверами.
Заголовок Pragma используется для перечисления собственных заголовков. К примеру, Pragma: no-cache — это то же самое, что Cache-Control: no-cache. Подробнее об этом поговорим во второй части.
Заголовок Date используется для хранения даты и времени запроса/ответа.
Заголовок Upgrade используется для изменения протокола.
Transfer-Encoding предназначается для разделения ответа на несколько фрагментов с помощью Transfer-Encoding: chunked. Это нововведение версии HTTP/1.1.
Заголовки сущностей
В заголовках сущностей передаётся мета-информация контента:
entity-header = Allow
| Content-Encoding
| Content-Language
| Content-Length
| Content-Location
| Content-MD5
| Content-Range
| Content-Type
| Expires
| Last-Modified
Все заголовки с префиксом Content- предоставляют информацию о структуре, кодировке и размере тела сообщения.
Заголовок Expires содержит время и дату истечения сущности. Значение “never expires” означает время + 1 код с текущего момента. Last-Modified содержит время и дату последнего изменения сущности.
С помощью данных заголовков, можно задать нужную для ваших задач информацию.
Формат запроса
Запрос выглядит примерно так:
Request-Line = Method SP URI SP HTTP-Version CRLF
Method = "OPTIONS"
| "HEAD"
| "GET"
| "POST"
| "PUT"
| "DELETE"
| "TRACE"
SP — это разделитель между токенами. Версия HTTP указывается в HTTP-Version. Реальный запрос выглядит так:
GET /articles/http-basics HTTP/1.1 Host: www.articles.com Connection: keep-alive Cache-Control: no-cache Pragma: no-cache Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Список возможных заголовков запроса:
request-header = Accept
| Accept-Charset
| Accept-Encoding
| Accept-Language
| Authorization
| Expect
| From
| Host
| If-Match
| If-Modified-Since
| If-None-Match
| If-Range
| If-Unmodified-Since
| Max-Forwards
| Proxy-Authorization
| Range
| Referer
| TE
| User-Agent
В заголовке Accept определяется поддерживаемые mime типы, язык, кодировку символов. Заголовки From, Host, Referer и User-Agent содержат информацию о клиенте. Префиксы If- предназначены для создания условий. Если условие не прошло, то возникнет ошибка 304 Not Modified.
Формат ответа
Формат ответа отличается только статусом и рядом заголовков. Статус выглядит так:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
- HTTP версия
- Код статуса
- Сообщение статуса, понятное для человека
Обычный статус выглядит примерно так:
Заголовки ответа могут быть следующими:
response-header = Accept-Ranges
| Age
| ETag
| Location
| Proxy-Authenticate
| Retry-After
| Server
| Vary
| WWW-Authenticate
- Age время в секундах, когда сообщение было создано на сервере.
- ETag MD5 сущности для проверки изменений и модификаций ответа.
- Location используется для перенаправления и содержит новый URL адрес.
- Server определяет сервер, где было сформирован ответ.
Думаю, на сегодня теории достаточно. Теперь давайте взглянем на инструменты, которыми мы можем пользоваться для мониторинга HTTP сообщений.
Инструменты для определения HTTP трафика
Существует множество инструментов для мониторинга HTTP трафика. Вот несколько из них:
Наиболее часто используемый — это Chrome Developers Tools:

Если говорить об отладчике, можно воспользоваться Fiddler:

Для отслеживания HTTP трафика вам потребуется curl, tcpdump и tshark.
Библиотеки для работы с HTTP — jQuery AJAX
Поскольку jQuery очень популярен, в нём также есть инструментарий для обработки HTTP ответов при AJAX запросах. Информацию о jQuery.ajax(settings) можете найти на официальном сайте.
Передав объект настроек (settings), а также воспользовавшись функцией обратного вызова beforeSend, мы можем задать заголовки запроса, с помощью метода setRequestHeader().
$.ajax({
url: 'http://www.articles.com/latest',
type: 'GET',
beforeSend: function (jqXHR) {
jqXHR.setRequestHeader('Accepts-Language', 'en-US,en');
}
});
Прочитать объект jqXHR можно с помощью метода jqXHR.getResponseHeader().
Если хотите обработать статус запроса, то это можно сделать так:
$.ajax({
statusCode: {
404: function() {
alert("page not found");
}
}
});
Итог
Вот такой вот он, тур по основам протокола HTTP. Во второй части будет ещё больше интересных фактов и примеров.
#статьи
- 30 сен 2022
-

0
Рассказываем об одном из самых популярных интернет-протоколов, на котором работает весь современный веб — HTTP.
Иллюстрация: Оля Ежак для Skillbox Media

Любитель научной фантастики и технологического прогресса. Хорошо сочетает в себе заумного технаря и утончённого гуманитария. Пишет про IT и радуется этому.
Каждый раз, когда вы включаете компьютер и заходите почитать статьи о программировании, браузер посылает куда-то какие-то запросы. Он делает это беспрерывно, пока вы сидите в интернете. Что это за запросы и зачем они нужны? Давайте разбираться.
HTTP означает «протокол передачи гипертекста» (или HyperText Transfer Protocol). Он представляет собой список правил, по которым компьютеры обмениваются данными в интернете. HTTP умеет передавать все возможные форматы файлов — например, видео, аудио, текст. Но при этом состоит только из текста.
Например, когда вы вписываете в строке браузера www.skillbox.ru, он составляет запрос и отправляет его на сервер, чтобы получить HTML-страницу сайта. Когда сервер обрабатывает запрос, то он отправляет ответ, в котором написано, что всё «ок» и вот вам сайт.
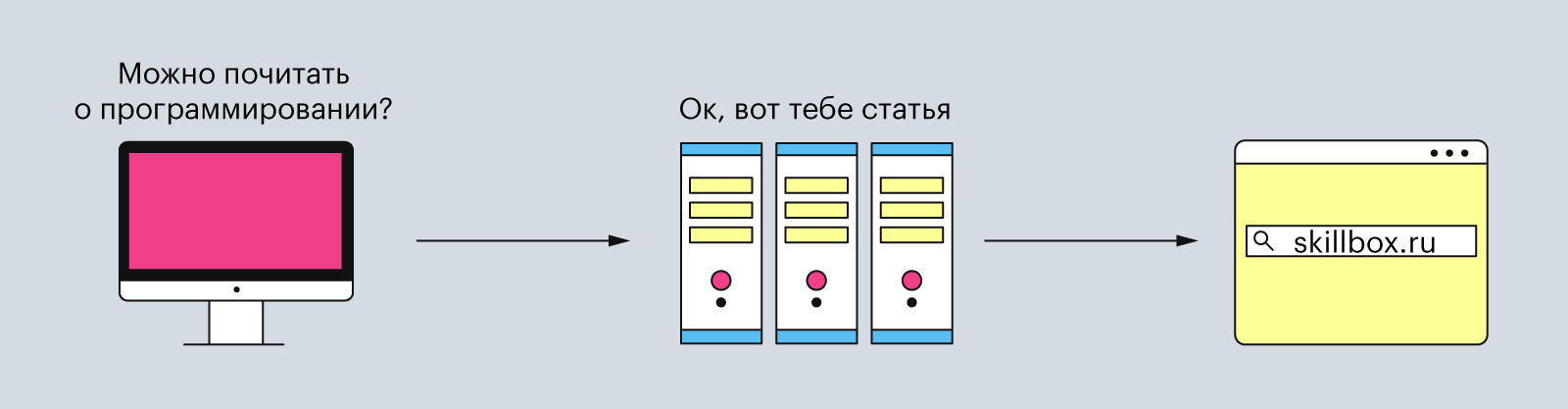
Иллюстрация: Polina Vari для Skillbox Media
Протокол HTTP используют ещё с 1992 года. Он очень простой, но при этом довольно функциональный. А ещё HTTP находится на самой вершине модели OSI (на прикладном уровне), где приложения обмениваются друг с другом данными. А работает HTTP с помощью протоколов TCP/IP и использует их, чтобы передавать данные.
Кроме HTTP в интернете работает ещё протокол HTTPS. Аббревиатура расшифровывается как «защищённый протокол передачи гипертекста» (или HyperText Transfer Protocol Secure). Он нужен для безопасной передачи данных по Сети. Всё происходит по тем же принципам, как и у HTTP, правда, перед отправкой данные дополнительно шифруются, а затем расшифровываются на сервере.
Например, HTTPS используют во время ввода данных банковской карты или паролей на сайтах — да и в целом большинство современных сайтов используют именно его.
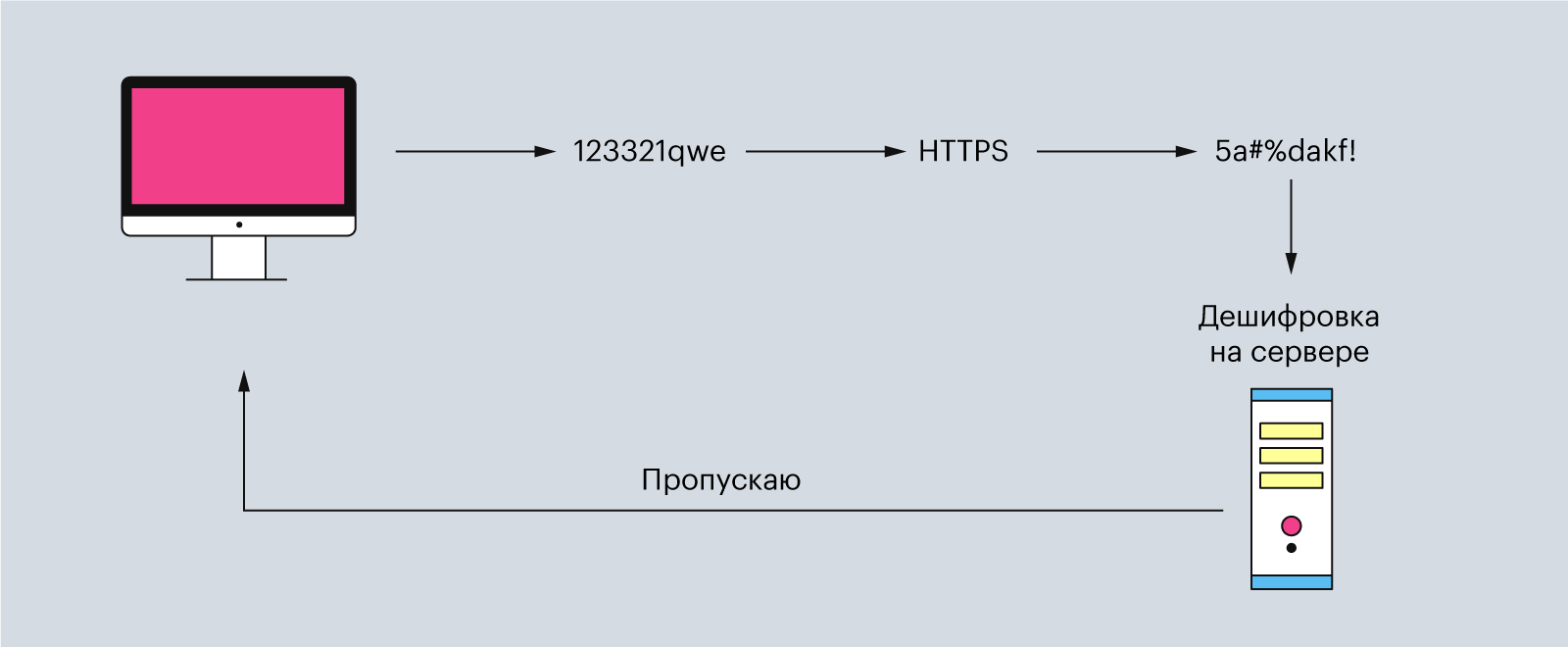
Иллюстрация: Polina Vari для Skillbox Media
HTTP состоит из двух элементов: клиента и сервера. Клиент отправляет запросы и ждёт данные от сервера. А сервер ждёт, пока ему придёт очередной запрос, обрабатывает его и возвращает ответ клиенту.
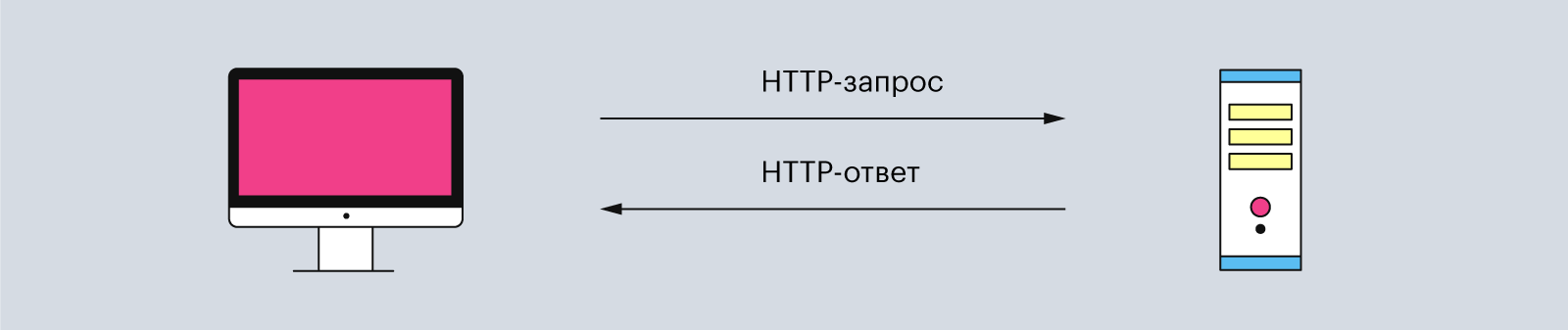
Иллюстрация: Polina Vari для Skillbox Media
Обычно эта связь между клиентом и сервером имеет посредников в виде прокси-серверов. Они нужны для разных операций — например, для безопасности и конфиденциальности, кэширования или распределения нагрузки на серверы.
Поэтому типичная процедура отправки HTTP-запроса от клиента выглядит так:
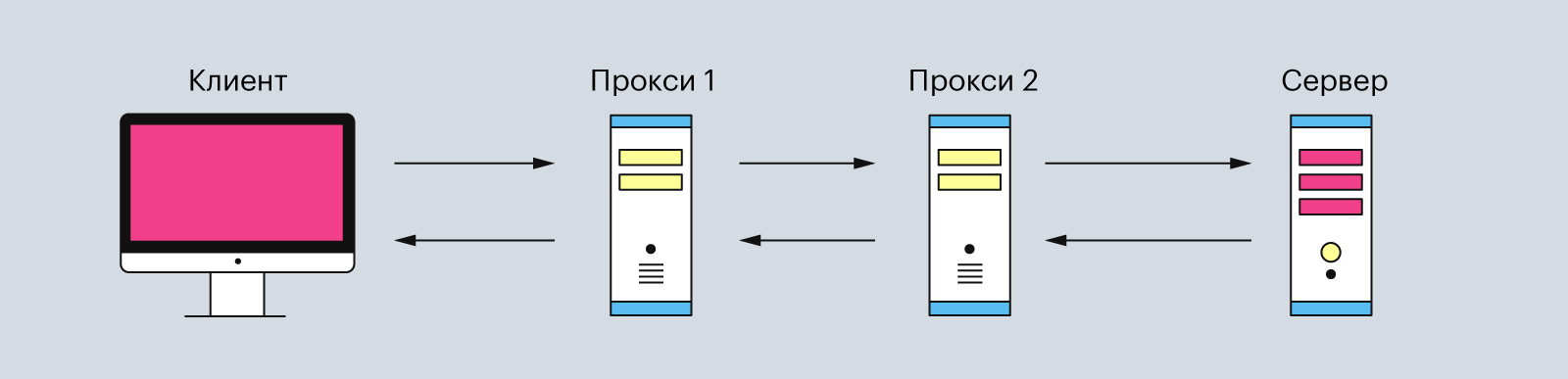
Иллюстрация: Polina Vari для Skillbox Media
Клиентом может быть любое устройство, через которое пользователь запрашивает данные. Часто в роли клиента выступает веб-браузер, программы для отладки приложений или даже командная строка. Главная особенность клиента — он всегда инициирует запрос.
Сервер — это устройство, которое обрабатывает запросы клиента. Он может состоять как из одного компьютера, так и из кластера. А ещё несколько виртуальных серверов могут находиться на одной физической машине.
Прокси-серверы — это второстепенные серверы, которые располагаются между клиентом и главным сервером. Они обрабатывают HTTP-запросы, а также ответы на них. Чаще всего прокси-серверы используют для кэширования и сжатия данных, обхода ограничений и анонимных запросов. И ещё — обычно между клиентом и основным сервером находится один или несколько таких прокси-серверов.
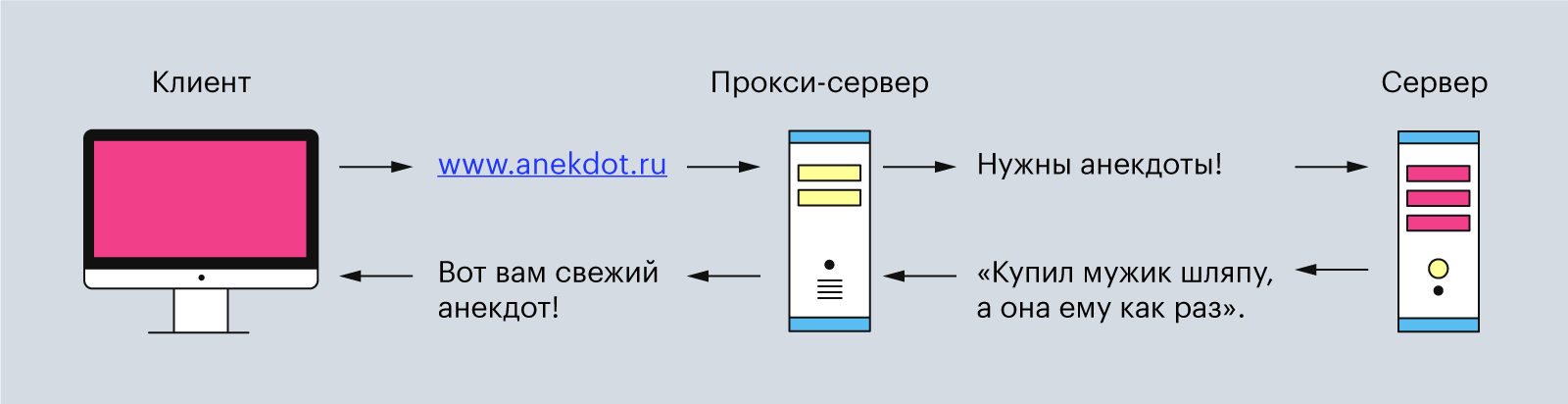
Иллюстрация: Polina Vari для Skillbox Media
Весь процесс передачи HTTP-запроса можно разбить на пять шагов. Давайте разберём их подробнее.
Чтобы отправить HTTP-запрос, нужно использовать URL-адрес — это «унифицированный указатель ресурса» (или Uniform Resource Locator). Он указывает браузеру, что нужно использовать HTTP-протокол, а затем получить файл с этого адреса обратно. Обычно URL-адреса начинаются с http:// или https:// (зависит от версии протокола).
Например, http://www.skillbox.ru — это URL-адрес. Он представляет собой главную страницу Skillbox. Но также в URL-адресе могут быть и поддомены — http://www.skillbox.ru/media. Теперь мы запросили главную страницу Skillbox Media.
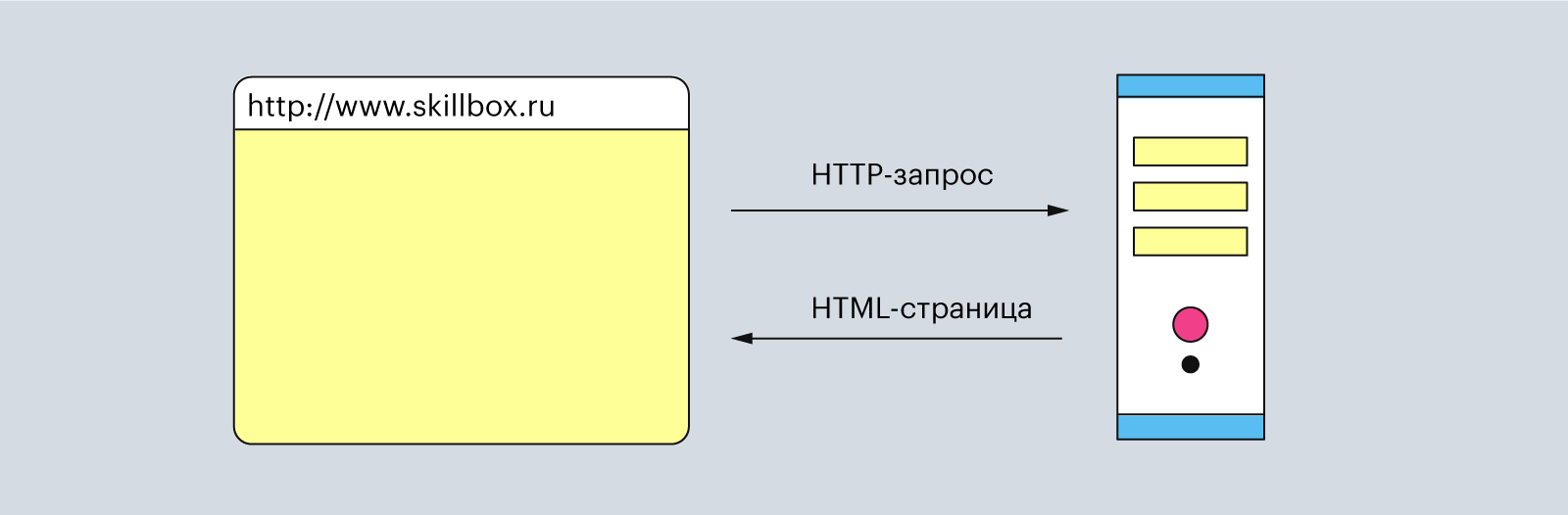
Иллюстрация: Polina Vari для Skillbox Media
Для пользователей URL-адрес — это набор понятных слов: Skillbox, Yandex, Google. Но для компьютера эти понятные нам слова — набор непонятных символов.
Поэтому браузер отправляет введённые вами слова в DNS, преобразователь URL-адресов в IP-адреса. DNS расшифровывается как «доменная система имён» (Domain Name System), и его можно представить как огромную таблицу со всеми зарегистрированными именами для сайтов и их IP-адресами.
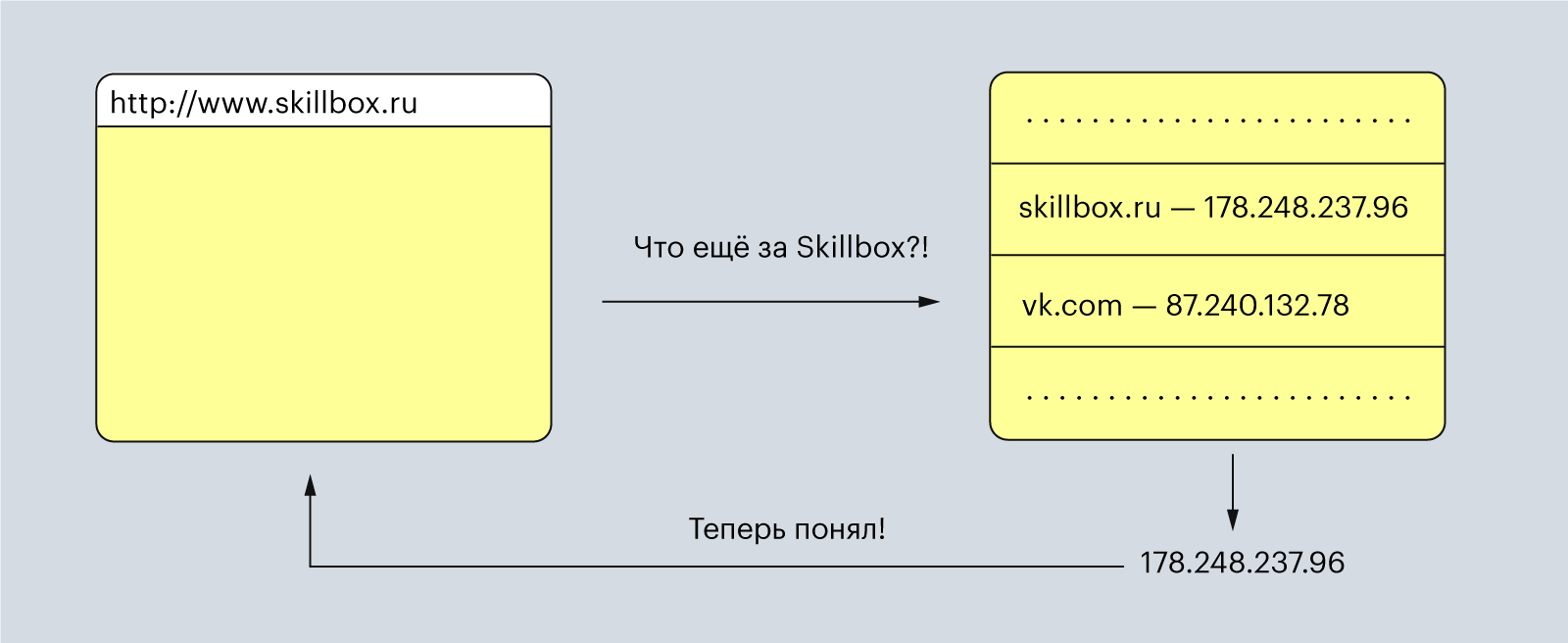
Иллюстрация: Polina Vari для Skillbox Media
DNS возвращает браузеру IP-адрес, с которым тот уже умеет работать. Теперь браузер начинает составлять HTTP-запрос с вложенным в него IP-адресом.
Сам HTTP-запрос может выглядеть так:

Здесь четыре элемента: метод — «GET», URI — «/», версия HTTP — «1.1» и адрес хоста — «www.skillbox.ru». Давайте разберём каждый из них подробнее.
Метод — это действие, которое клиент ждёт от сервера. Например, отправить ему HTML-страницу сайта или скачать документ. Протокол HTTP не ограничивает количество разных методов, но программисты договорились между собой использовать только три основных:
- GET — чтобы получить данные с сервера. Например, видео с YouTube или мем с Reddit.
- POST — чтобы отправить данные на сервер. Например, сообщение в Telegram или новый трек в SoundCloud.
- HEAD — чтобы получить только метаданные об HTML-странице сайта. Это те данные, которые находятся в <head>-теге HTML-файла.
URI расшифровывается как «унифицированный идентификатор ресурса» (или Uniform Resource Identifier) — это полный адрес сайта в Сети. Он состоит из двух частей: URL и URN. Первое — это адрес хоста. Например, www.skillbox.ru или www.vk.com. Второе — это то, что ставится после URL и символа / — например, для URI www.skillbox.ru/media URN-адресом будет /media. URN ещё можно назвать адресом до конкретного файла на сайте.
Версия HTTP указывает, какую версию HTTP браузер использует при отправке запроса. Если её не указывать, по умолчанию будет стоять версия 1.1. Она нужна, чтобы сервер вернул HTTP-ответ с той же версией HTTP-протокола и не создал ошибок с чтением у клиента.
Адрес хоста нужен, чтобы указать, с какого сайта клиент пытается получить данные. Адрес указывают в виде домена, но он сразу же меняется на IP-адрес перед отправкой запроса с помощью DNS.

Иллюстрация: Polina Vari для Skillbox Media
После получения и обработки HTTP-запроса сервер создаёт ответ и отправляет его обратно клиенту. В нём содержатся дополнительная информация (метаданные) и запрашиваемые данные.
Простой HTTP-ответ выглядит так:

Здесь три главные части: статус ответа — HTTP/1.1 200 OK, заголовки Content-Type и Content-Length и тело ответа — HTML-код. Рассмотрим их подробнее.
Статус ответа содержит версию HTTP-протокола, который клиент указал в HTTP-запросе. А после неё идёт код статуса ответа — 200, что означает успешное получение данных. Затем — словесное описание статуса ответа: «ок».
Всего статусов в спецификации HTTP 1.1 — 40. Вот самые популярные из них:
- 200 OK — данные успешно получены;
- 201 Created — значит, что запрос успешный, а данные созданы. Его используют, чтобы подтверждать успех запросов PUT или POST;
- 300 Moved Permanently — указывает, что URL-адрес изменили навсегда;
- 400 Bad Request — означает неверно сформированный запрос. Обычно это случается в связке с запросами POST и PUT, когда данные не прошли проверку или представлены в неправильном формате;
- 401 Unauthorized — нужно выполнить аутентификацию перед тем, как запрашивать доступ к ресурсу;
- 404 Not Found — значит, что не удалось найти запрашиваемый ресурс;
- 405 Forbidden — говорит, что указанный метод HTTP не поддерживается для запрашиваемого ресурса;
- 409 Conflict — произошёл конфликт. Например, когда клиент хочет создать дважды данные с помощью запроса PUT;
- 500 Internal Server Error — означает ошибку со стороны сервера.
Заголовки помогают браузеру разобраться с полученными данными и представить их в правильном виде. Например, заголовок Content-Type сообщает, какой формат файла пришёл и какие у него дополнительные параметры, а Content-Length — сколько места в байтах занимает этот файл.
Тело ответа содержит в себе сам файл. Например, сервер может вернуть код HTML-документа или отправить JPEG-картинку.

Иллюстрация: Polina Vari для Skillbox Media
Как только браузер получил ответ с веб-страницей, он отображает её с помощью внутреннего движка. И на этом весь процесс отправки и получение HTTP-запросов заканчивается, а клиент получает нужные ему данные.
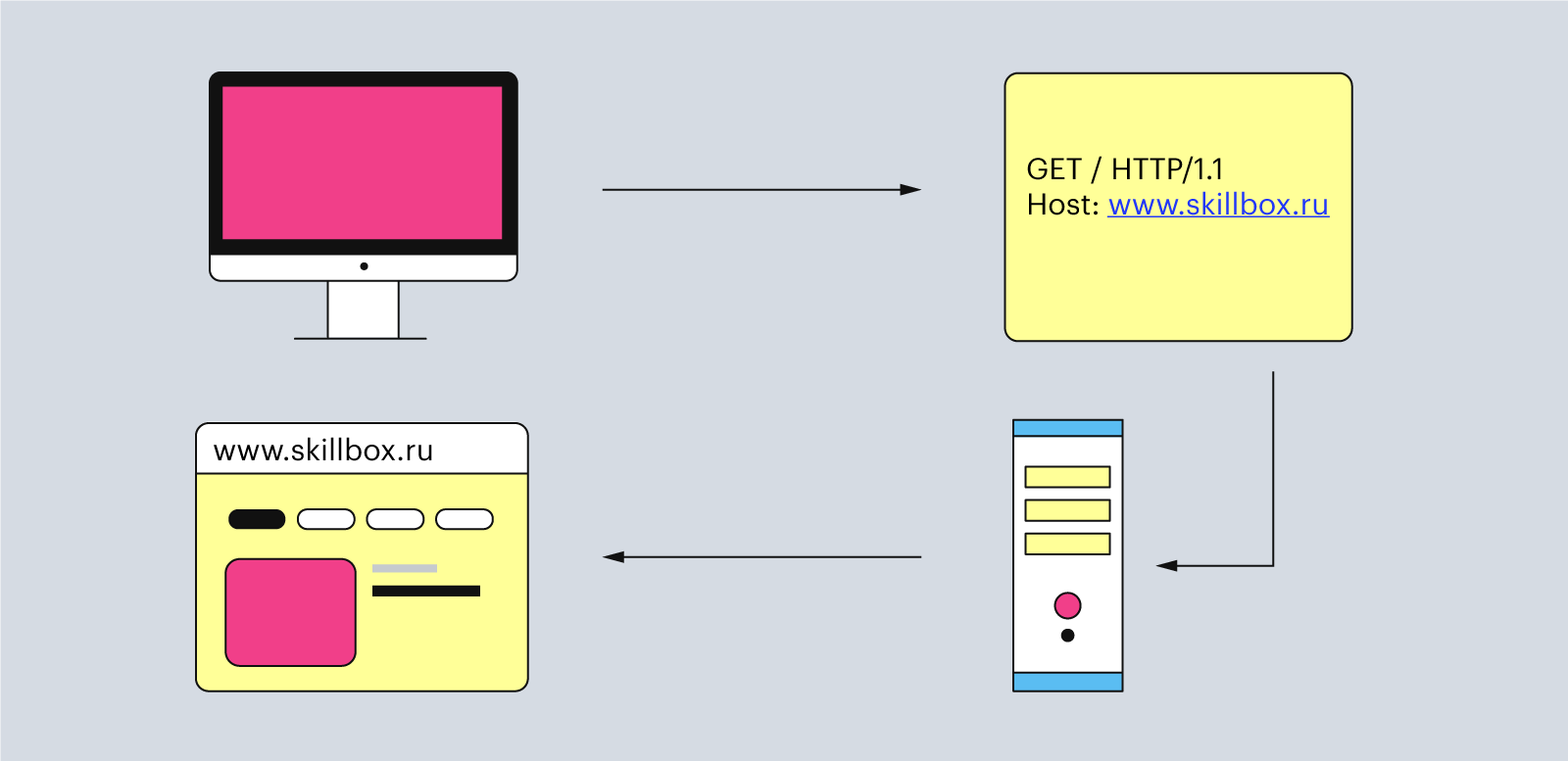
Иллюстрация: Polina Vari для Skillbox Media
- HTTP-протокол — это набор правил, по которым компьютеры обмениваются данными друг с другом. Его инициирует клиент (в данном случае — человек, заходящий в интернет с любого устройства), а обрабатывает сервер и возвращает обратно клиенту. Между ними могут находиться прокси-серверы, которые занимаются дополнительными задачами — шифрованием данных, перераспределением нагрузки или кэшированием.
- HTTP-запрос содержит четыре элемента: метод, URI, версию HTTP и адрес хоста. Метод указывает, какое действие нужно совершить. URI — это путь до конкретного файла на сайте. Версию HTTP нужно указывать, чтобы избежать ошибок, а адрес хоста помогает браузеру определить, куда отправлять HTTP-запрос.
- HTTP-ответ имеет три части: статус ответа, заголовки и тело ответа. В статусе ответа сообщается, всё ли прошло успешно и возникли ли ошибки. В заголовках указывается дополнительная информация, которая помогает браузеру корректно отобразить файл. А в тело ответа сервер кладёт запрашиваемый файл.

Научитесь: Профессия Веб-разработчик
Узнать больше