Как работает распознавание лиц? Разбор
Время на прочтение
4 мин
Количество просмотров 23K
Среднестатистический человек может идентифицировать знакомое лицо в толпе с точностью 97,53%. Вы скажете, это немало и будете правы. Но это ничто по сравнению с современными алгоритмами, которые добились точности 99,8% еще в 2014 году. А в последние несколько лет они достигли практически совершенства! Современный алгоритм, использующийся в камерах видеонаблюдения в Москве способен обрабатывать 1 миллиард изображений менее чем за полсекунды с точностью близкой к 100%.

Этот алгоритм насколько крут, что уже в этом году в Московском Метро планируют ввести систему прохода по лицу — FacePay. При этом нам обещают, что система будет работать даже если человек в медицинской маске.
Как вы понимаете, жизнь уже не будет прежней. Поэтому давайте разберемся:
- Как работают алгоритмы распознавания лиц?
- Страшны ли эти алгоритмы на самом деле и где их применяют во благо?
- А также поговорим какого будущего нам ждать.
Причины
Технологии машинного зрения и распознавания лиц развивались очень активно с середины прошлого века. Но только сейчас стали по-настоящему хорошо работать. Причин тому три штуки:
- Появились действительно мощные компьютеры, способные справиться с задачей. За это спасибо закону Мура.
- Появились базы данных с нашими с вами фотографиями. За что спасибо социальным сетям.
- Ну и конечно, произошел прорыв в области нейросетей.
Все эти события позволили создать практически идеальные алгоритмы распознавания лиц. Так давайте же разберемся, как они работают.
Этап 1. Обнаружение
В первую очередь, для того, чтобы лицо распознать, надо его сначала обнаружить. Задача на самом деле не тривиальная. Для этого мы бы могли использовать натренированные нейросети, но это слишком долго, дорого и ресурсоемко. Поэтому для обнаружения лица используется очень простой метод Виолы — Джонса, разработанный еще в 2001 году.
Как эта штука работает?
Этот алгоритм просто сканирует изображение при помощи вот таких прямоугольников, они называются примитивами Хаара:

И еще вот таких прямоугольников:
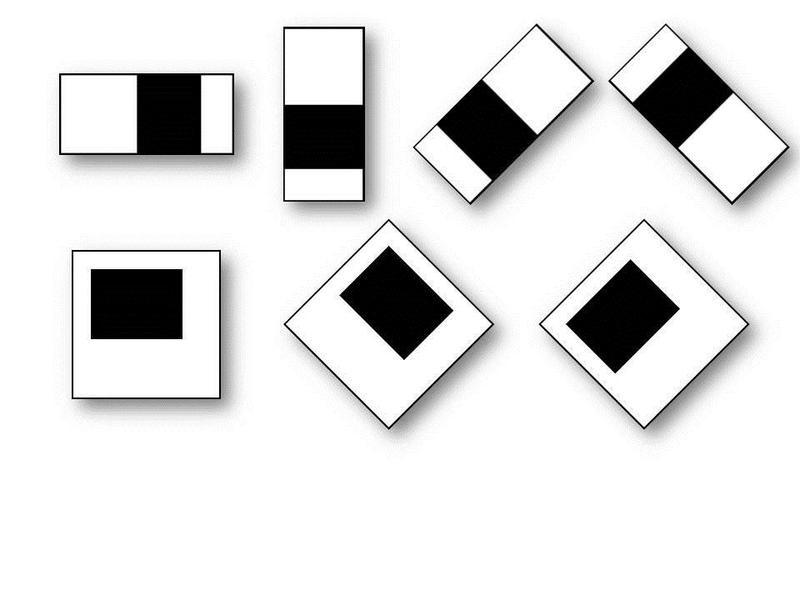
Задача этих объектов — находить более светлые и темные области на изображении, характерных конкретно для человеческих лиц.
Например, если усреднить значения яркости область глаз будет темнее щек или лба, а переносица будет светлее бровей.

В общем таких характерных признаков много и естественно не только у человеческих лиц могут быть подобные паттерны. Поэтому алгоритм работает в несколько этапов:

Сначала находится первый признак, система понимает: «В этой области может быть лицо». Тогда она начинает там же искать второй признак, а потом третий. И если в одной области найдено 3 признака, уже можно уверенно сказать — да, это лицо! После чего система получает область изображения, в котором есть только лицо.
Этап 2. Антропометрические точки
Получив область для анализа, дальше в дело вступает главный секрет каждой системы распознавания — биометрический алгоритм.
Он расставляет на лице антропометрические точки, по которым впоследствии и будут вычисляться индивидуальные характеристики человека: разрез глаз, форма носа, подбородка, расстояние между ними и прочее. Таких признаков может быть много, вплоть до нескольких тысяч. Но в целом, таких точек должно быть как минимум 68.

Этап 3. Исправление искажений
А дальше начинается настоящая магия. В идеале нам нужно лицо, которое смотрит анфас, то есть прямо в камеру. Но такая удача бывает редко, особенно если речь идет о распознавании человека в толпе.
Поэтому система производит дополнительное преобразование изображения: устранятся поворот и наклон головы. А также проводится 3D-реконструкция лица из 2D-изображения. Таким образом, даже если человек на изображении смотрел вбок, мы всё равно можем получить четкий фронтальный снимок, что существенно повышает качество распознавания.

Этап 4. Вектор лица
Ну а дальше происходит самое главное. В бой вступает нейросеть, которая присваивает каждому лицу вектор признаков. Что это такое?
По сути, это просто какое-то число, которое складывается из суммы характеристик лица: расстояний между опорными точками, текстуры определенных областей на лице и прочее. Таких характеристик может быть множество. Основное правило: они должны описывать лицо независимо от посторонних факторов: макияжа, прически, возрастных изменений.
Этап 5. Идентификация
Ну а дальше остаётся сравнить полученный вектор с базой других векторов. И готово. Система вас идентифицировала.
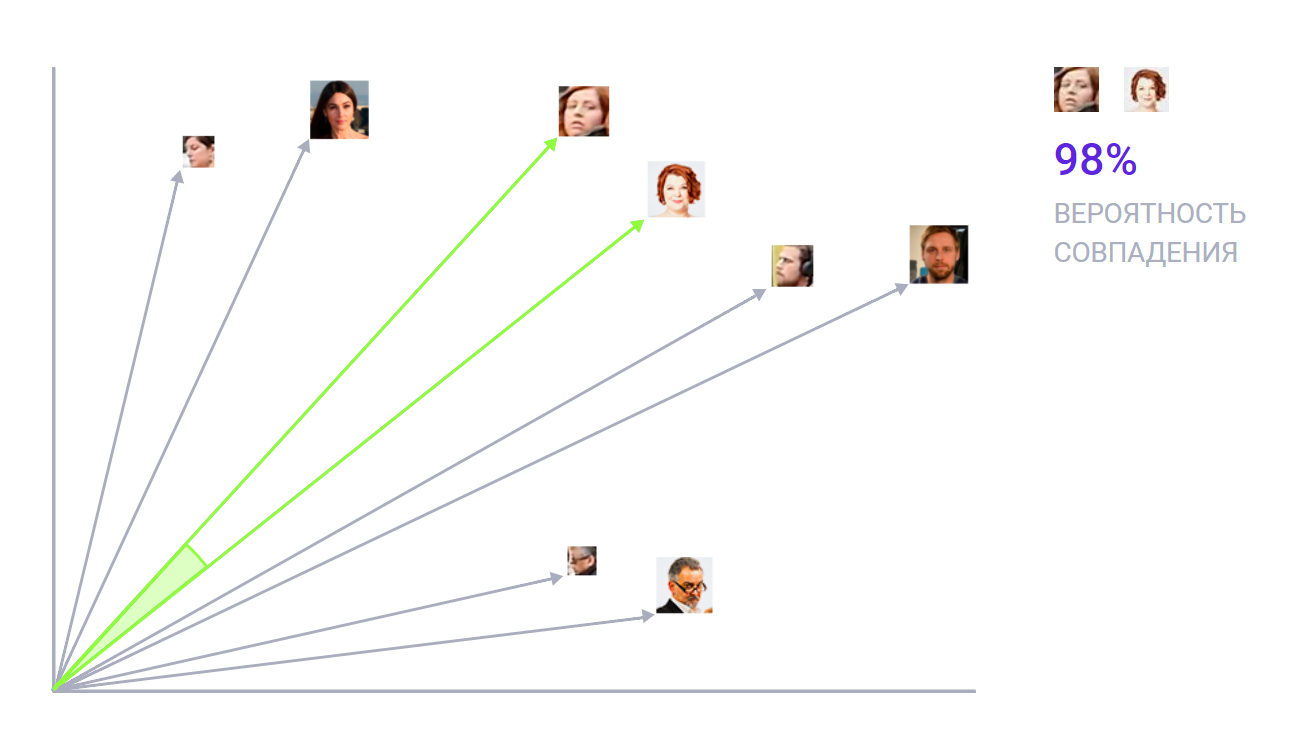
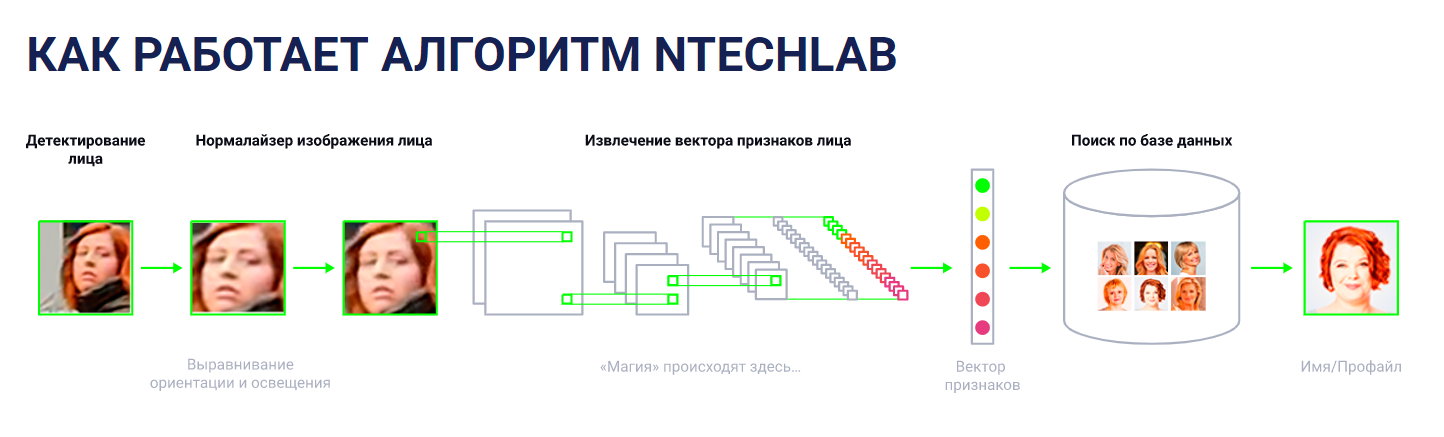
Где и как используется?
Помимо очевидных кейсов применения, помимо обнаружения правонарушителей в общественных пространствах и оплаты билетов в метро. Где и как могут применяться эти технологии?
Во-первых, системы могут быть настроены не на идентификацию а на анализ поведения или настроения. В такси можно можно быстро вычислять неадекватных водителей или пассажиров. В магазинах, можно находить грустных покупателей и повышать уровень сервиса. Ритейлеры одежды или продуктовые магазины используют камеры для анализа поведения покупателя, чтобы проанализировать настроение покупателя на кассе. Или например в школах, можно искать скучающих детей и корректировать программу обучения. Так, кстати уже делают в Китае. Вот такой мир будущего, и мы уже в нём живём не зная этого.
Что будет в будущем?
Чего же нам ждать в будущем? Распознавание лиц для разблокировки iPhone, входа в Windows или во время конференций — это прекрасная, удобная технология, упрощающая жизнь и мы уже ей пользуемся. Но вот повсеместные камеры наблюдения в городах рисуют в воображении самые мрачные картины в духе Джорджа Оруэлла.
Отсюда возникает вопрос — можно ли защитить себя от систем видеонаблюдения? Конечно, с развитием технологий развиваются и средства обхода этих технологий.
Люди придумывают макияж и украшения, которые сбивают с толку алгоритм обнаружения лиц, тот самый из 2001 года, создают инфракрасные очки, засвечивающие сенсоры камер, а также делают всякую криповую одежду и маски.





Но по большому счету такой лук скорее больше привлечет внимания, а алгоритмы подстроятся под обманки. Поэтому единственный способ защиты — это закон. Бизнес активно не внедряет системы распознавания лиц только потому, что это несет большие юридические издержки. В ЕС активно разрабатывается новый закон, который уже прозвали GDPR 2: он будет строго регулировать системы распознавания лиц и прочие системы искусственного интеллекта, вызывающие законные опасения.
В России с этим пока что не так хорошо. Тем не менее отечественные компании, которые присутствуют на международном рынке также будут вынуждены соблюдать новые правила игры, как произошло с первым GDPR.

То есть, как вы поняли, есть светлая сторона технологии, которая упрощает нам жизнь и темная, что приближает нас к миру большого брата.
Перевод
Ссылка на автора

В этом руководстве мы увидим, как создать и запустить алгоритм обнаружения лиц в Python с использованием OpenCV и Dlib. Мы также добавим некоторые функции для одновременного обнаружения глаз и рта на нескольких лицах. В этой статье будут рассмотрены самые основные реализации распознавания лиц, в том числе каскадные классификаторы, окна HOG и Deep Learning CNN.
Мы рассмотрим обнаружение лица с помощью:
- Классификаторы Хаара с использованием OpenCV
- Гистограмма ориентированных градиентов с использованием Dlib
- Сверточные нейронные сети с использованием Dlib
Эта статья была первоначально опубликована в моем личном блоге: https://maelfabien.github.io/tutorials/face-detection/#
Github-репозиторий этой статьи (и все остальные из моего блога) можно найти здесь:
maelfabien / Machine_Learning_Tutorials
Этот репозиторий содержит упражнения, код, учебные пособия и статьи из моего личного блога — maelfabien / Machine_Learning_Tutorials
github.com
Введение
Мы будем использовать OpenCV, библиотеку с открытым исходным кодом для компьютерного зрения, написанную на C / C ++, которая имеет интерфейсы на C ++, Python и Java. Он поддерживает Windows, Linux, MacOS, iOS и Android. Некоторые из наших работ также потребуют использования Dlib, современного инструментария C ++, содержащего алгоритмы машинного обучения и инструменты для создания сложного программного обеспечения.
Требования
Первым шагом является установка OpenCV и Dlib. Запустите следующую команду:
pip install opencv-pythonpip install dlib
В зависимости от вашей версии файл будет установлен здесь:
/usr/local/lib/python3.7/site-packages/cv2
Если у вас возникли проблемы с Dlib, проверьте Эта статья,
Импорт и модели пути
Мы создадим новый файл Jupyter notebook / python и начнем с:
import cv2
import matplotlib.pyplot as plt
import dlib
from imutils import face_utilsfont = cv2.FONT_HERSHEY_SIMPLEX
I. Каскадные классификаторы
Сначала рассмотрим каскадные классификаторы.
I.1. теория
Каскадный классификатор, или, в частности, каскад повышенных классификаторов, работающих с хаароподобными функциями, представляет собой особый случай ансамблевого обучения, называемый повышением. Как правило, опирается на AdaBoost классификаторы (и другие модели, такие как Real Adaboost, Gentle Adaboost или Logitboost).
Каскадные классификаторы обучаются на нескольких сотнях изображений изображений, которые содержат объект, который мы хотим обнаружить, и других изображениях, которые не содержат этих изображений.
Как мы можем определить, есть ли там лицо или нет? Существует алгоритм, называемый средой обнаружения объектов Viola – Jones, который включает в себя все этапы, необходимые для обнаружения живого лица:
- Выбор объектов Хаара, особенности, полученные из вейвлетов Хаара
- Создать целостное изображение
- Adaboost Training
- Каскадные классификаторы
Оригинал бумага был опубликован в 2001 году.
I.1.a. Выбор Хаара
Есть некоторые общие черты, которые мы находим на самых обычных человеческих лицах:
- область темных глаз по сравнению с верхними щеками
- яркая область переносицы по сравнению с глазами
- какое-то конкретное расположение глаз, рта, носа…
Характеристики называются Haar Features. Процесс извлечения функции будет выглядеть так:

В этом примере первый признак измеряет разницу в интенсивности между областью глаз и областью через верхние щеки. Значение объекта просто вычисляется путем суммирования пикселей в черной области и вычитания пикселей в белой области.

Затем мы применяем этот прямоугольник как сверточное ядро по всему нашему изображению. Чтобы быть исчерпывающим, мы должны применить все возможные размеры и положения каждого ядра. Простые 24 * 24 изображения обычно дают более 160 000 объектов, каждое из которых состоит из суммы / вычитания значений пикселей. В вычислительном отношении это было бы невозможно для живого обнаружения лица. Итак, как мы можем ускорить этот процесс?
- как только хорошая область была идентифицирована прямоугольником, бесполезно запускать окно по совершенно другой области изображения. Это может быть достигнуто Adaboost.
- вычислить прямоугольные элементы, используя принцип интегрального изображения, который намного быстрее. Мы рассмотрим это в следующем разделе.

Существует несколько типов прямоугольников, которые можно применять для извлечения объектов Haar. Согласно оригинальной статье:
- двухугольный признак — это разница между суммой пикселей в двух прямоугольных областях, используемая в основном для обнаружения краев (a, b)
- функция трех прямоугольников вычисляет сумму в двух внешних прямоугольниках, вычтенных из суммы в центральном прямоугольнике, используемой в основном для обнаружения линий (c, d)
- функция четырехугольника вычисляет разницу между диагональными парами прямоугольника (e)

Теперь, когда функции выбраны, мы применяем их к набору обучающих изображений, используя классификацию Adaboost, которая объединяет набор слабых классификаторов для создания точной модели ансамбля. Благодаря 200 функциям (вместо 160 000 изначально) достигается точность 95%. Авторы статьи выбрали 6’000 функций.
I.1.b Цельное изображение
Вычисление элементов прямоугольника в стиле сверточного ядра может быть долгим, очень долгим. По этой причине авторы, Виола и Джонс, предложили промежуточное представление для изображения: целостное изображение. Роль интегрального изображения заключается в том, чтобы просто вычислить любую прямоугольную сумму, используя только четыре значения. Посмотрим, как это работает!
Предположим, мы хотим определить объекты прямоугольника в данном пикселе с координатами (x, y). Затем выполняется интегральное изображение пикселя в сумме пикселей выше и слева от данного пикселя.

где ii (x, y) — интегральное изображение, а i (x, y) — исходное изображение.
Когда вы вычисляете целое целое изображение, возникает рецидив формы, который требует только одного прохода исходного изображения. Действительно, мы можем определить следующую пару повторений:

где s (x, y) — совокупная сумма строк, а s (xâ1 ’) = 0, ii (â’’1, y) = 0.
Чем это может быть полезно? Хорошо, рассмотрим область D, для которой мы хотели бы оценить сумму пикселей. Мы определили 3 других региона: A, B и C.
- Значение интегрального изображения в точке 1 является суммой пикселей в прямоугольнике А.
- Значение в точке 2 A + B
- Значение в точке 3 A + C
- Значение в точке 4 — A + B + C + D.
Следовательно, сумма пикселей в области D может быть просто вычислена как: 4 + 1 (2 + 3).
И за один проход мы вычислили значение внутри прямоугольника, используя только 4 ссылки на массив.

Нужно просто помнить, что прямоугольники — довольно простые функции на практике, но достаточные для обнаружения лица. Управляемые фильтры имеют тенденцию быть более гибкими, когда речь идет о сложных проблемах.

I.1c. Изучение функции классификации с Adaboost
Учитывая набор помеченных тренировочных образов (положительных или отрицательных), Adaboost используется для:
- выберите небольшой набор функций
- и обучить классификатор
Поскольку предполагается, что большинство функций из 160 000 не имеют никакого значения, слабый алгоритм обучения, на основе которого мы строим улучшающую модель, предназначен для выбора одного прямоугольника, который разделяет лучшие отрицательные и положительные примеры.
I.1.d. Каскадный классификатор
Хотя процесс, описанный выше, довольно эффективен, основная проблема остается. На изображении большая часть изображения — это область без лица. Придавать одинаковую важность каждой области изображения не имеет смысла, поскольку мы должны сосредоточиться в основном на областях, которые, скорее всего, содержат изображение. Виола и Джонс достигли повышенной скорости обнаружения, сократив при этом время вычислений с помощью каскадных классификаторов.
Ключевая идея состоит в том, чтобы отклонить подокна, которые не содержат граней, при определении областей, которые имеют. Поскольку задача состоит в том, чтобы правильно идентифицировать лицо, мы хотим минимизировать количество ложных отрицательных результатов, то есть подокна, которые содержат лицо и не были идентифицированы как таковые.
Ряд классификаторов применяется к каждому подокну. Эти классификаторы являются простыми деревьями решений:
- если первый классификатор положительный, мы переходим ко второму
- если второй классификатор положительный, мы переходим к третьему
- â € |
Любой отрицательный результат в некоторой точке приводит к отклонению подокна как потенциально содержащего лицо. Первоначальный классификатор исключает большинство отрицательных примеров при низких вычислительных затратах, а следующие классификаторы устраняют дополнительные отрицательные примеры, но требуют больших вычислительных усилий.

Классификаторы обучаются с использованием Adaboost и настройкой порога, чтобы минимизировать ложную оценку. При обучении такой модели переменными являются следующие:
- количество ступеней классификатора
- количество функций на каждом этапе
- порог каждого этапа
К счастью, в OpenCV вся эта модель уже прошла обучение по распознаванию лиц.
Если вы хотите узнать больше о методах повышения, я предлагаю вам проверить мою статью на AdaBoost,
I.2. импорт
Следующий шаг — найти предварительно подготовленные веса. Мы будем использовать предварительно обученные модели по умолчанию для определения лица, глаз и рта. В зависимости от вашей версии Python файлы должны находиться где-то здесь:
/usr/local/lib/python3.7/site-packages/cv2/data
После определения мы объявим каскадные классификаторы следующим образом:
cascPath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_frontalface_default.xml"
eyePath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_eye.xml"
smilePath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_smile.xml"faceCascade = cv2.CascadeClassifier(cascPath)
eyeCascade = cv2.CascadeClassifier(eyePath)
smileCascade = cv2.CascadeClassifier(smilePath)
I.3. Определить лицо на изображении
Перед реализацией алгоритма распознавания лиц в режиме реального времени, давайте попробуем простую версию изображения. Мы можем начать с загрузки тестового изображения:
# Load the image
gray = cv2.imread('face_detect_test.jpeg', 0)plt.figure(figsize=(12,8))
plt.imshow(gray, cmap='gray')
plt.show()

Затем мы обнаруживаем лицо и добавляем вокруг него прямоугольник:
# Detect faces
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
flags=cv2.CASCADE_SCALE_IMAGE
)# For each face
for (x, y, w, h) in faces:
# Draw rectangle around the face
cv2.rectangle(gray, (x, y), (x+w, y+h), (255, 255, 255), 3)
Вот список наиболее распространенных параметровdetectMultiScaleфункция:
- scaleFactor: параметр, указывающий, насколько уменьшается размер изображения при каждом масштабе изображения.
- minNeighbors: параметр, указывающий, сколько соседей должен иметь каждый прямоугольник-кандидат для его сохранения.
- minSize: минимально возможный размер объекта. Объекты меньшего размера игнорируются.
- maxSize: максимально возможный размер объекта. Объекты большего размера игнорируются
Наконец, отобразите результат:
plt.figure(figsize=(12,8))
plt.imshow(gray, cmap='gray')
plt.show()

Распознавание лиц хорошо работает на нашем тестовом изображении. Давайте перейдем к реальному времени сейчас!
I.4. Распознавание лиц в реальном времени
Давайте перейдем к реализации Python для распознавания лиц в реальном времени. Первым шагом является запуск камеры и захват видео. Затем мы преобразуем изображение в изображение в оттенках серого. Это используется для уменьшения размера входного изображения. Действительно, вместо 3 точек на пиксель, описывающих красный, зеленый, синий, мы применяем простое линейное преобразование:

Это реализовано по умолчанию в OpenCV.
video_capture = cv2.VideoCapture(0)while True:
# Capture frame-by-frame
ret, frame = video_capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
Теперь мы будем использоватьfaceCascadeПеременная определите выше, которая содержит предварительно обученный алгоритм, и примените его к изображению серой шкалы.
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE
)
Для каждого обнаруженного лица мы нарисуем прямоугольник вокруг лица:
for (x, y, w, h) in faces:
if w > 250 :
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 3)
roi_gray = gray[y:y+h, x:x+w]
roi_color = frame[y:y+h, x:x+w]
Для каждого обнаруженного рта нарисуйте вокруг него прямоугольник:
smile = smileCascade.detectMultiScale(
roi_gray,
scaleFactor= 1.16,
minNeighbors=35,
minSize=(25, 25),
flags=cv2.CASCADE_SCALE_IMAGE
)
for (sx, sy, sw, sh) in smile:
cv2.rectangle(roi_color, (sh, sy), (sx+sw, sy+sh), (255, 0, 0), 2)
cv2.putText(frame,'Smile',(x + sx,y + sy), 1, 1, (0, 255, 0), 1)
Для каждого обнаруженного глаза нарисуйте вокруг него прямоугольник:
eyes = eyeCascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
cv2.putText(frame,'Eye',(x + ex,y + ey), 1, 1, (0, 255, 0), 1)
Затем подсчитайте общее количество лиц и отобразите общее изображение:
cv2.putText(frame,'Number of Faces : ' + str(len(faces)),(40, 40), font, 1,(255,0,0),2)
# Display the resulting frame
cv2.imshow('Video', frame)
И реализовать вариант выхода, когда мы хотим остановить камеру, нажавq:
if cv2.waitKey(1) & 0xFF == ord('q'):
break
Наконец, когда все будет сделано, отпустите захват и уничтожьте все окна. Существуют некоторые проблемы, связанные с уничтожением окон на Mac, которые могут потребовать позже удаления Python из диспетчера активности.
video_capture.release()
cv2.destroyAllWindows()
В.5. Завершение
I.6. Полученные результаты
Я сделал быстрый YouTube иллюстрация алгоритма распознавания лиц.
II. Гистограмма ориентированных градиентов (HOG) в Dlib
Второй наиболее популярный инструмент для распознавания лиц предлагается Dlib и использует концепцию, называемую Гистограмма ориентированных градиентов (HOG). Это реализация оригинала бумага Далала и Триггса,
II.1. теория
Идея HOG состоит в том, чтобы извлечь объекты в вектор и передать их в алгоритм классификации, такой как, например, машина опорных векторов, которая будет оценивать, присутствует ли лицо (или любой объект, который вы обучаете его распознавать) в регионе или нет ,
Выделенные особенности — это распределение (гистограммы) направлений градиентов (ориентированных градиентов) изображения. Градиенты, как правило, большие по краям и углам и позволяют нам обнаруживать эти области.
В оригинальной статье процесс был реализован для обнаружения человеческого тела, и цепочка обнаружения была следующей:

II.1.a. предварительная обработка
Прежде всего, входные изображения должны быть одинакового размера (кадрировать и масштабировать изображения). Для патчей, которые мы будем применять, требуется соотношение сторон 1: 2, поэтому размеры входных изображений могут быть64x128или100x200например.
II.1.b. Вычислить градиентные изображения
Первым шагом является вычисление горизонтального и вертикального градиентов изображения с применением следующих ядер:

Градиент изображения обычно удаляет ненужную информацию.
Градиент изображения, который мы рассматривали выше, можно найти в Python следующим образом:
gray = cv2.imread('images/face_detect_test.jpeg', 0)im = np.float32(gray) / 255.0# Calculate gradient
gx = cv2.Sobel(im, cv2.CV_32F, 1, 0, ksize=1)
gy = cv2.Sobel(im, cv2.CV_32F, 0, 1, ksize=1)
mag, angle = cv2.cartToPolar(gx, gy, angleInDegrees=True)
И нарисуйте картинку:
plt.figure(figsize=(12,8))
plt.imshow(mag)
plt.show()

Мы не обрабатывали изображение ранее, хотя.
II.1.c. Вычислить боров
Затем изображение делится на 8×8 ячеек, чтобы обеспечить компактное представление и сделать наш HOG более устойчивым к шуму. Затем мы вычисляем HOG для каждой из этих ячеек.
Чтобы оценить направление градиента внутри области, мы просто строим гистограмму среди 64 значений направлений градиента (8×8) и их величины (еще 64 значения) внутри каждой области. Категории гистограммы соответствуют углам градиента от 0 до 180 °. Всего 9 категорий: 0 °, 20 °, 40 °… 160 °.
Код выше дал нам 2 информации:
- направление градиента
- и величина градиента
Когда мы строим HOG, есть 3 случая:
- угол меньше 160 ° и не на полпути между двумя классами. В таком случае угол будет добавлен в правильной категории HOG
- угол меньше 160 ° и ровно между 2 классами. В таком случае мы рассматриваем равный вклад в 2 ближайших класса и делим величину на 2

- угол больше 160 °. В таком случае мы считаем, что пиксель вносил вклад пропорционально 160 ° и 0 °.

HOG выглядит так для каждой ячейки 8×8:

II.1.d. Блок нормализации
Наконец, блок 16×16 может быть применен, чтобы нормализовать изображение и сделать его инвариантным, например, к освещению. Это просто достигается путем деления каждого значения HOG размера 8×8 на L2-норму HOG содержащего его блока 16×16, который на самом деле является простым вектором длины9*4 = 36,
II.1.e. Блок нормализации
Наконец, все векторы 36×1 объединяются в большой вектор. И мы сделали! У нас есть вектор признаков, по которому мы можем обучить мягкий классификатор SVM (C = 0,01).
II.2. Определить лицо на изображении
Реализация довольно проста:
face_detect = dlib.get_frontal_face_detector()rects = face_detect(gray, 1)for (i, rect) in enumerate(rects):
(x, y, w, h) = face_utils.rect_to_bb(rect)
cv2.rectangle(gray, (x, y), (x + w, y + h), (255, 255, 255), 3)plt.figure(figsize=(12,8))
plt.imshow(gray, cmap='gray')
plt.show()

II.3. Распознавание лиц в реальном времени
Как и ранее, алгоритм довольно прост в реализации. Мы также реализуем более легкую версию, обнаруживая только лицо Dlib также позволяет легко определять ключевые точки лица, но это уже другая тема.
III. Сверточная нейронная сеть в Dlib
Этот последний метод основан на сверточных нейронных сетях (CNN). Он также реализует бумага на Max-Margin Object Detection (MMOD) для улучшения результатов.
III.1. Немного теории
Сверточная нейронная сеть (CNN) — это нейронная сеть с прямой связью, которая в основном используется для компьютерного зрения. Они предлагают автоматическую предварительную обработку изображений, а также плотную часть нейронной сети. CNN — это особые типы нейронных сетей для обработки данных с топологией, подобной сетке. Архитектура CNN вдохновлена визуальной корой животных.
В предыдущих подходах большая часть работы заключалась в том, чтобы выбрать фильтры для создания функций, чтобы извлечь как можно больше информации из изображения. С ростом глубокого обучения и большей вычислительной мощности эта работа теперь может быть автоматизирована. Название CNN происходит от того факта, что мы объединяем начальный ввод изображения с набором фильтров. Параметром, который нужно выбрать, остается количество применяемых фильтров и размерность фильтров. Размер фильтра называется длиной шага. Типичные значения для шага лежат между 2 и 5.

Выходные данные CNN в этом конкретном случае представляют собой двоичную классификацию, которая принимает значение 1, если есть грань, 0 в противном случае.
III.2. Определить лицо на изображении
Некоторые элементы изменяются в реализации.
Первый шаг — загрузить предварительно обученную модель. Вот, Переместите веса в вашу папку и определитеdnnDaceDetector:
dnnFaceDetector = dlib.cnn_face_detection_model_v1("mmod_human_face_detector.dat")
Тогда, очень похоже на то, что мы сделали до сих пор:
rects = dnnFaceDetector(gray, 1)for (i, rect) in enumerate(rects): x1 = rect.rect.left()
y1 = rect.rect.top()
x2 = rect.rect.right()
y2 = rect.rect.bottom() # Rectangle around the face
cv2.rectangle(gray, (x1, y1), (x2, y2), (255, 255, 255), 3)plt.figure(figsize=(12,8))
plt.imshow(gray, cmap='gray')
plt.show()

III.3. Распознавание лиц в реальном времени
Наконец, мы реализуем версию распознавания лиц CNN в режиме реального времени:
Внутривенно Какой выбрать?
Сложный вопрос, но мы просто пройдемся по двум важным метрикам:
- время расчета
- Точность
С точки зрения скорости, HoG кажется самым быстрым алгоритмом, за которым следует классификатор Haar Cascade и CNN.
Тем не менее, CNN в Dlib, как правило, являются наиболее точным алгоритмом. HoG работают довольно хорошо, но есть некоторые проблемы с распознаванием маленьких лиц. Классификаторы HaarCascade работают так же хорошо, как и HoG.
Я лично использовал главным образом HoG в своих личных проектах из-за его скорости обнаружения живого лица.
ВыводНадеюсь, вам понравился этот краткий учебник по OpenCV и Dlib по распознаванию лиц. Не стесняйтесь оставлять комментарии, если у вас есть какие-либо вопросы / замечания.
V. Источники:
- HOG
- DLIB
- Альт-Джонс Бумага
- Обнаружение лица 1
- Обнаружение Лица 2
- Обнаружение Лица 3
- DetectMultiScale
- Viola-Jones
Неофициальный перевод ООО «Развитие правовых систем»
Распознавание лиц — это автоматическая обработка цифровых изображений, содержащих лица людей, для идентификации или проверки данных людей с использованием лицевых шаблонов.
В статье 6 обновленной Конвенции о защите физических лиц при автоматизированной обработке персональных данных1) (далее — Конвенция 108+) конфиденциальность информации биометрического характера была особо отмечена путем отнесения данных, уникальным образом идентифицирующих физических лиц, к специальным категориям данных.
Контекст обработки изображений имеет значение для определения конфиденциального характера данных, поскольку не любая обработка изображений предполагает обработку конфиденциальной информации. Изображения охватываются понятием биометрических данных, только если они обрабатываются при помощи особого технического средства, которое делает возможной уникальную идентификацию или аутентификацию физического лица2).
Настоящее руководство касается использования технологий распознавания лиц, в том числе технологий распознавания лиц в режиме реального времени. Данные технологии широко используются с применением различных способов, некоторые из которых могут серьезно нарушать права субъектов персональных данных. Законодательство, которое разрешает обширное наблюдение за физическими лицами, может вступать в противоречие с правом на уважение частной жизни3).
Интеграция технологий распознавания лиц в существующие системы наблюдения представляет собой серьезную угрозу для права на конфиденциальность и права на защиту персональных данных, а также для других базовых прав, поскольку использование данных технологий не всегда требует осведомленности или согласия физических лиц, чьи биометрические данные обрабатываются, если рассмотреть, например, возможность получения доступа к цифровым изображениям людей в Интернете.
С целью предупреждения таких нарушений государства — участники Конвенции 108+ должны обеспечивать соблюдение прав на конфиденциальность и на защиту персональных данных в рамках развития и использования технологий распознавания лиц, тем самым укрепляя права человека и основные свободы путем применения принципов, закрепленных в Конвенции, в специфическом контексте технологий распознавания лиц.
Данное руководство4) содержит справочный список тех мер, которым власти, разработчики технологий распознавания лиц, изготовители, сервис-провайдеры и организации, использующие данные технологии, должны следовать и которые они должны применять с целью предупреждения негативных последствий для человеческого достоинства, прав человека и основных свобод любого физического лица, в том числе права на защиту персональных данных.
Руководство имеет общую сферу действия и распространяется на использование технологий распознавания лиц как в частном, так и в публичном секторе. Оно не исключают того, что в рамках соответствующей правовой системы могут потребоваться дополнительные меры защиты в зависимости от конкретного случая такого использования. Оно оценивает различные случаи использования данных технологий в разных секторах с учетом целей такого использования и его потенциальных последствий для права на защиту персональных данных и других основных прав.
Под правоохранительными целями в данном руководстве понимаются предупреждение, расследование преступлений и исполнение уголовных наказаний. Это включает в себя поддержание полицией общественного порядка (далее — правоохранительные цели)5). Под «правоохранительными органами» понимаются также, в более широком смысле, прокуратура и (или) другие государственные и (или) частные организации, которые на основании закона наделены правом обработки персональных данных для тех же целей (далее — правоохранительные органы).
Ничто в настоящем руководстве не должно пониматься как исключение или ограничение положений Конвенции 1086). Данное руководство также принимает во внимание новые гарантии, закрепленные в Конвенции 108+.
Как предусматривает статья 6 Конвенции 108+, обработка особых категорий данных, таких как биометрические данные, может быть разрешена только в том случае, если для нее установлена надлежащая правовая база, а в законодательстве государства закреплены дополнительные и надлежащие гарантии. Данные гарантии должны быть адаптированы к соответствующим рискам и к интересам, правам и свободам, которые подлежат защите.
В некоторых нормативных актах7).)) запрет такой обработки закреплен в качестве общего правила, и обработка допускается только в виде исключения, в некоторых конкретных случаях (например, с ясно выраженного согласия физических лиц, для защиты их жизненно важных интересов или если обработка необходима из соображений универсального общественного интереса) и сопровождается гарантиями, которые необходимы с учетом соответствующих рисков.
Необходимость использования технологий распознавания лиц должна оцениваться вместе с соразмерностью такого использования по отношению к соответствующей цели, а также последствиями для прав субъектов данных.
Различные случаи использования должны быть категоризированы, и должна быть создана правовая база для обработки биометрических данных путем распознавания лиц. Данная правовая база для каждого отдельного вида использования должна включать в себя, в частности:
— подробное объяснение конкретного использования и его цели;
— требования к минимальной надежности и точности  используемого алгоритма;
используемого алгоритма;
— требования относительно продолжительности хранения используемых фотографий;
— возможность проверки данных критериев;
— возможность отслеживать обработку;
— гарантии.
1.1. СТРОГИЕ ЗАКОНОДАТЕЛЬНЫЕ ОГРАНИЧЕНИЯ В ОТНОШЕНИИ НЕКОТОРЫХ ВИДОВ ИСПОЛЬЗОВАНИЯ
Уровень интрузивности распознавания лиц и связанные с ним нарушения права на конфиденциальность и защиту данных различаются в зависимости от конкретной ситуации использования данных технологий, и существуют случаи, когда закон строго ограничивает или даже полностью запрещает такое использование, когда к такому решению приводит демократический процесс.
Использование технологий распознавания лиц в режиме реального времени в неконтролируемой обстановке9), в свете его интрузивности для права на конфиденциальность и достоинство индивидов, в сочетании с риском негативных последствий для других прав человека и основных свобод10), должны быть предметом демократического обсуждения, и должна существовать возможность моратория на время, необходимое для полного анализа.
Использование распознавания лиц исключительно для цели определения цвета кожи индивида, его религиозных или других верований, пола, расовой или этнической принадлежности, возраста, состояния здоровья или социального положения должно быть запрещено, если законом не предусмотрены соответствующие гарантии с целью исключения риска дискриминации11).
Аналогичным образом эмоциональное распознавание12) также может проводиться с помощью технологий распознавания лиц с предполагаемой целью выявления личностных черт, чувств, состояния психического здоровья или мотивированности работников на основе изображений лиц. Установление связи между эмоциональным распознаванием, например, с подбором персонала, получением страховки, образованием может нести в себе риски, которые вызывают большую озабоченность с точки зрения как отдельных индивидов, так и общества в целом и которые должны быть запрещены.
1.2. ПРАВОВАЯ БАЗА В РАЗЛИЧНЫХ КОНТЕКСТАХ
Правовая база для обработки биометрических данных путем распознавания лиц должна, в дополнение к элементам, указанным в разделе 1, касаться следующего:
— различных стадий использования технологий распознавания лиц, в том числе стадий создания баз данных и развертывания;
— секторов, в которых используются данные технологии;
— интрузивности различных типов технологий распознавания лиц, таких как технологий распознавания лиц в режиме реального времени или офлайн, и при этом содержать ясное руководство относительно законности.
1.2.1. Интеграция цифровых изображений в технологии распознавания лиц
Законодатели и принимающие решения органы должны обеспечивать, чтобы изображения, доступные в цифровом формате, не могли быть обработаны с целью получения биометрических образцов13) или интегрированы в биометрические системы без конкретных правовых оснований для новой обработки, если первоначально данные изображения были получены для других целей (например, из социальных сетей).
Поскольку получение биометрических образцов из цифровых изображений связано с обработкой конфиденциальной информации, следует обеспечивать возможную правовую базу, рассматриваемую ниже, меняющуюся в зависимости от секторов и разновидностей использования.
Более конкретно, использование цифровых изображений, которые были загружены в Интернет, в том числе в социальных сетях, или на сайтах редактирования фотографий, или были получены с записей камер видеонаблюдения, не может считаться законным только на основании того, что субъекты данных явно опубликовали свои персональные данные в общем доступе.
Законодатели и принимающие решения органы должны обеспечивать, чтобы существующие базы цифровых изображений, которые первоначально использовались для других целей, могли быть использованы для получения биометрических образцов и их интеграции в биометрические системы, когда это необходимо для первостепенных правомерных целей, предусмотрено законом, строго необходимо для достижения данных целей и соразмерно им (например, правоохранительные цели или медицинские цели).
1.2.2. Использование технологий распознавания лиц в публичном секторе
Наличие согласия, как правило, не должно быть правовым основанием для распознавания лиц органами власти ввиду дисбаланса полномочий между субъектами данных и органами власти. По той же причине, как правило, это не должно являться правовым основанием для использования технологий распознавания лиц частными организациями, уполномоченными на выполнение задач, аналогичных задачам властей.
Правомерность использования технологий распознавания лиц должна быть основана на целях биометрической обработки, предусмотренных законом, и на необходимых гарантиях, дополняющих Конвенцию 108+.
Законодатели и принимающие решения органы должны определять конкретные правила биометрической обработки путем технологий распознавания лиц для правоохранительных целей. Данные законы должны обеспечивать, чтобы такое использование всегда было строго необходимо для достижения данных целей и было соразмерно им, и предусматривать необходимые гарантии, которые должны быть предоставлены.
Правоохранительные органы
Биометрическая обработка с помощью технологий распознавания лиц для целей идентификации в контролируемой14) или неконтролируемой обстановке должна быть ограничена в целом правоохранительными целями. Она должна выполняться только уполномоченными в сфере безопасности органами.
Законом могут быть предусмотрены различные тесты необходимости и соразмерности в зависимости от того, является ли целью идентификация или проверка, с учетом потенциальных рисков для основных прав, при условии, что изображения физических лиц получены законно.
Для целей идентификации требование строгой необходимости и соразмерности должно соблюдаться и на стадии создания базы данных (списка наблюдения), и на стадии развертывания технологий распознавания лиц (онлайн) в неконтролируемой обстановке.
Законом должны быть предусмотрены ясные параметры и критерии, которые должны соблюдаться правоохранительными органами при создании баз данных (списков наблюдения) для конкретных, правомерных и явных правоохранительных целей (например, подозрение в тяжком преступлении или риск для общественной безопасности).
Принимая во внимание интрузивность данных технологий, на стадии развертывания технологий распознавания лиц в режиме реального времени в неконтролируемой обстановке закон должен обеспечивать обоснование правоохранительными органами того, что различные факторы, в том числе место и время развертывания данных технологий, оправдывают строгую необходимость и соразмерность их использования.
Иные государственные органы
Законодатели и принимающие решения органы должны определить конкретные правила для биометрической обработки данных с помощью технологий распознавания лиц для иных существенных общественных интересов государственными органами, которые не преследуют правоохранительные цели.
Законом могут быть предусмотрены различные тесты необходимости и соразмерности в зависимости от того, является ли целью идентификация или проверка, с учетом потенциальных рисков для основных прав и при условии, что изображения физических лиц получены законным путем.
Принимая во внимание потенциальную интрузивность данных технологий, законодатели и принимающие решения органы должны обеспечить наличие ясной и четкой правовой базы, предусматривающей необходимые гарантии для обработки биометрических данных. Такая правовая база должна предусматривать строгую необходимость и соразмерность использования данных технологий и учитывать уязвимость субъектов данных и характер обстановки, в которой данные технологии используются для целей проверки.
Например, обеспечение безопасности в контролируемой и неконтролируемой обстановке, в том числе в школах и других общественных зданиях, как правило, не должно считаться строго необходимым и соразмерным при наличии менее интрузивных альтернативных механизмов.
1.2.3. Использование технологий распознавания лиц в частном секторе
Использование технологий распознавания лиц частными организациями, за исключением частных организаций, наделенных полномочиями по выполнению задач, аналогичных тем, которые выполняют органы власти, требует в соответствии со статьей 5 Конвенции 108+ добровольного, четко выраженного, информированного и однозначного согласия субъектов данных, чьи биометрические данные подвергаются обработке.
Принимая во внимание требование о наличии такого согласия субъектов данных, использование технологий распознавания лиц может иметь место только в контролируемой обстановке для целей проверки, аутентификации или категоризации15).
В зависимости от цели необходимо уделять особое внимание качеству ясно выраженного согласия субъектов данных, когда оно является правовым основанием для обработки.
С целью обеспечения добровольного характера согласия субъектам данных необходимо предлагать альтернативы использованию технологий распознавания лиц (например, использование пароля или идентификационного бэйджа), которые легко использовать, поскольку если их слишком долго или слишком сложно использовать по сравнению с технологиями распознавания лиц, выбор не был бы подлинным.
Если согласие должно быть получено для конкретной цели, персональные данные не должны обрабатываться таким образом, который противоречит данной цели. Аналогичным образом в случае раскрытия данных третьей стороне, такое раскрытие также должно быть предметом конкретно выраженного согласия.
Частные организации не должны использовать технологии распознавания лиц в неконтролируемой обстановке, такой как торговые центры, особенно для идентификации лиц, которые представляют собой интерес для маркетинговых целей или из соображений частной безопасности.
Прохождение через пространство, в котором применяются технологии распознавания лиц, не может рассматриваться как ясно выраженное согласие.
В соответствии с пунктом 3 статьи 15 Конвенции 108+ у надзорных органов необходимо запрашивать мнение по любым предложениям о принятии законодательных или административных мер, предполагающих обработку персональных данных с помощью технологий распознавания лиц. Необходимо систематически привлекать надзорные органы и, в частности, запрашивать их мнение по любым возможным экспериментам или запланированному развертыванию.
Таким образом, необходимо систематически консультироваться с данными органами до реализации соответствующих проектов. Аналогичным образом у них должен быть доступ к оценкам последствий таких проектов, а также всем аудиторским, аналитическим и другим заключениям, полученным в контексте таких экспериментов или проектов.
Законодатели и принимающие решения органы должны обеспечивать эффективное сотрудничество между различными надзорными органами, уполномоченными осуществлять надзор в отношении различных аспектов обработки таких данных, если контроль за соблюдением требований закона в ходе такой деятельности осуществляют разные органы власти.
Законодатели и принимающие решения органы должны пользоваться различными механизмами для обеспечения ответственности разработчиков, изготовителей, сервис-провайдеров или организаций, использующих данные технологии.
Создание независимого и квалифицированного механизма сертификации для распознавания лиц и защиты данных с целью подтверждения полного соответствия операций обработки соответствующим требованиям могло бы стать главным элементом, позволяющим добиться доверия со стороны пользователей.
Такая сертификация может внедряться в зависимости от применения искусственного интеллекта для технологии распознавания лиц: один вид сертификации для категоризации структур (дизайна алгоритма, интеграции алгоритма и так далее) и другой вид для категоризации алгоритмов (компьютерное распознавание, умный поиск и так далее).
Осведомленность субъектов данных и понимание широкой общественностью технологий распознавания лиц и их последствий для основных прав должны активно обеспечиваться путем доступных и образовательных действий.
Идея заключается в том, что предоставить доступ к простым понятиям, которые могут позволить субъектам данных до того, как они примут решение об использовании технологии распознавания лиц, понять, что означает использование конфиденциальных данных, таких как биометрические данные, как работает распознавание лиц и какова потенциальная опасность, в частности, в случае ненадлежащего использования.
Законодатели и принимающие решения органы должны способствовать участию общественности в разработке и использовании данных технологий и в предоставлении надлежащих гарантий защиты основных прав при использовании распознавания лиц.
Данный раздел руководства отдельно касается вопросов, связанных со стадиями разработки и изготовления технологий распознавания лиц. В случае обработки биометрических данных разработчиками, изготовителями и провайдерами услуг для своих собственных целей на стадии разработки к ним будет также применяться раздел III, который касается организаций, использующих данные технологии.
1.1. РЕПРЕЗЕНТАТИВНОСТЬ ИСПОЛЬЗУЕМЫХ ДАННЫХ
Как и другие применимые нормативные акты, Конвенция 108+ в статье 5 предусматривает требование о точности данных. Таким образом, разработчики или изготовители технологий распознавания лиц должны принимать шаги с целью обеспечить точность данных распознавания лиц. В частности, они должны избегать неправильной идентификации путем достаточного тестирования своих систем, идентификации и устранения неточностей, например, в отношении демографических вариаций цвета кожи, возраста и пола и тем самым избегать непреднамеренной дискриминации.
Кроме того, с целью обеспечить как качество данных, так и эффективность алгоритмов последние должны разрабатываться с использованием синтетических наборов данных, основанных на достаточно разнообразных фотографиях мужчин и женщин с различным цветом кожи, различной морфологией, различных возрастов, при этом фотографии должны быть сделаны под разным углом. Должны быть предусмотрены резервные процедуры на случай сбоя системы, если физические характеристики не соответствуют техническим стандартам.
К биометрическим данным, которые неизбежно раскрывают другие конфиденциальные данные, такие как информация о типе заболевания или физической инвалидности, должны применяться соответствующие дополнительные гарантии.
1.2. СРОК ХРАНЕНИЯ ДАННЫХ
Система распознавания лиц требует периодического обновления данных (фотографии лиц, которые необходимо распознать) с целью обучения и улучшения используемого алгоритма.
Для каждого алгоритма существует определенный процент надежности распознавания, как в ходе его разработки, так и во время его использования. Таким образом, представляется важным датировать и фиксировать данный процент для отслеживания развития алгоритма. В случае ухудшения его надежности будет необходимо обновить «тренировочные» фотографии и в связи с этим запросить более новые фотографии. Это также позволит защитить алгоритм от последствий изменения формы лиц (в связи с возрастом, наличием аксессуаров — пирсинг и так далее — или другими изменениями).
Физическим лицам, заинтересованным покупателям или организациям, использующим технологии распознавания лиц, должен обеспечиваться простой доступ к данным показателям надежности, например, в форме информационной панели, с целью помочь им сделать выбор при приобретении и развертывании той или иной технологии.
Надежность используемых инструментов зависит от эффективности алгоритма. Данная эффективность основывается на различных факторах, в том числе: ложные позитивы, ложные негативы, результативность при различном освещении, надежность в случаях, когда лица повернуты в сторону от камеры или когда лицо чем-то закрыто.
Должен обеспечиваться настолько высокий уровень надежности, насколько это возможно, с учетом того, что использование системы распознавания лиц может привести к очень значительным негативным последствиям для физического лица.
Компании, которые осуществляют разработку и продажу технологий распознавания лиц, должны принимать разумные шаги, такие как рекомендации или советы, чтобы помочь организациям, использующим данные технологии, обеспечивать транспарентность и соблюдение конфиденциальности (путем предоставления им примеров политики конфиденциальности или рекомендаций относительно ясного и доступного для понимания обозначения, указывающего на то, что в том или ином пространстве используется технология распознавания лиц).
Компании, которые осуществляют разработку и продажу технологий распознавания лиц, должны принимать конкретные меры с целью обеспечения соблюдения принципов защиты данных, такие как:
— интеграция защиты данных в дизайн и архитектуру продукции и услуг, связанных с распознаванием лиц, а также во внутренние IT-системы и интеграция использования специально предназначенных для этого инструментов, в том числе автоматического удаления исходных данных после извлечения биометрических образцов;
— обеспечение определенного уровня гибкости при разработке данных технологий с целью адаптации технических гарантий в соответствии с принципами целевых ограничений, минимизации данных и ограничения срока хранения данных;
— имплементация внутреннего процесса проверки, целью которого является выявление и снижение возможных последствий для прав и основных свобод до того, как технологии распознавания лиц будут предоставлены в распоряжение пользователей;
— интеграция подхода защиты данных в их организационную практику, в том числе назначение специальных сотрудников, проведение тренингов по вопросам конфиденциальности для работников, а также проведение оценки последствий защиты данных на разработку или изменение продукции и услуг, связанных с распознаванием лиц.
Организации16) должны соблюдать все соответствующие принципы положения о защите данных, обрабатывая биометрические данные при использовании технологий распознавания лиц. Организации, использующие технологии распознавания лиц, должны быть в состоянии доказать, что такое использование строго необходимо и соразмерно в конкретном контексте и что оно не нарушает права субъектов персональных данных.
Организации могут ссылаться на исключения, предусмотренные применимым законодательством, отвечающим требованиям статьи 11 Конвенции 108+ (использование, которое предусмотрено законом, преследует правомерную цель, не нарушает самой сути основных прав и свобод и является необходимой и соразмерной мерой в демократическом обществе).
Организации, использующие технологии распознавания лиц, должны обеспечивать, что добровольное использование технологии не будет иметь последствий для физических лиц, которые непреднамеренно будут с ними контактировать.
Субъекты (обработки данных) будут опираться на различную правовую базу, в зависимости от сектора, к которому они принадлежат, и целей использования технологий распознавания лиц, упомянутых в разделе I.
Транспарентность и справедливость
Поскольку технологии распознавания лиц могут использоваться без какого-либо намерения или содействия со стороны субъектов данных, транспарентность и справедливость обработки имеют наиважнейшее значение и должны надлежащим образом приниматься во внимание организациями, которые используют данные технологии.
Организации должны предоставлять всю необходимую информацию об обработке, как указано в статье 8 Конвенции 108+.
Факторы, которые определяют, обеспечивается ли транспарентность, включают в себя, например, предоставление информации физическим лицам, контекст сбора данных, разумные ожидания относительно того, как будут использованы данные, то, является ли распознавание лиц лишь одним из свойств продукции или услуги или же, наоборот, их неотъемлемой частью. Также должна быть предоставлена информация о том, как сбор, использование или распространение данных распознавания лиц может затронуть физических лиц, особенно если речь идет о лицах, которые находятся в уязвимом положении. Также должна быть предоставлена информация о правах субъектов данных и о средствах правовой защиты, которыми они имеют право воспользоваться.
Политика конфиденциальности в области распознавания лиц или информационные материалы, касающиеся технологий, должны включать в себя, в дополнение к информации, указанной в статье 8 Конвенции 108+, следующую информацию17):
— могут ли данные распознавания лиц быть переданы третьим сторонам и в какой степени (если да, должна быть также предоставлена информация о личности контрагентов, получающих данные в ходе предоставления товаров или услуг);
— сведения относительно хранения, удаления или деидентификации данных распознавания лиц;
— контактные данные лиц, к которым физические лица могут обратиться с вопросами по поводу сбора, использования и распространения данных распознавания лиц;
— если практика сбора, использования и распространения данных значительно изменились, организации должны обновлять политику конфиденциальности или делать доступной информацию о данных изменениях в свете контекста изменений и их последствий для физических лиц.
В случае, если базы данных созданы правоохранительными органами для целей идентификации и проверки, обязательство обеспечения транспарентности может быть соразмерным образом ограничено, чтобы не ущемлять правоохранительные цели, в соответствии со статьей 11 Конвенции 108+ и при условии соблюдения закрепленных в ней требований.
Если технологии распознавания лиц развертываются в неконтролируемой обстановке, правоохранительные органы могут придерживаться многоуровневого подхода к предоставлению необходимой информации субъектам данных, которые проходят через неконтролируемое пространство.
Первый уровень предоставления информации касается читабельной и понятной информации о цели обработки, органе, использующем технологию, продолжительности обработки и соответствующем периметре; данные сведения должны быть размещены в зоне видимости в том месте, где используются технологии.
Второй уровень касается всей необходимой информации, которая требуется в соответствии со статьей 8 Конвенции 108+; данная информация должна быть размещена при входе в места, где установлена (система распознавания лиц).
Скрытое использование технологий распознавания лиц правоохранительными органами может допускаться только в том случае, когда оно является строго необходимым и соразмерным для предупреждения непосредственного и существенного риска для общественной безопасности, который должен быть подтвержден документально до начала скрытого использования.
Целевое ограничение, минимизация данных и ограниченная продолжительность хранения
Персональные данные, подлежащие обработке, должны быть получены для ясно обозначенных, конкретных и правомерных целей и не должны обрабатываться таким образом, который несовместим с данными целями, в соответствии с пунктом 4 статьи 5 Конвенции 108+.
Кроме того, перед любой последующей обработкой организации должны проверить, совместимы ли цели новой обработки с изначальными целями. В противном случае для новой обработки потребуется отдельное правовое основание.
Организации должны соблюдать принцип минимизации данных, в соответствии с которым обработке подлежит только требуемая информация, а не вся информация, к которой у организаций есть доступ.
Организации также должны установить срок хранения, который не может превышать тот, который необходим для конкретной цели обработки, и обеспечивать удаление биометрических образцов, когда данная цель достигнута. При определении срока хранения необходимо принимать во внимание биометрический характер персональных данных.
При развертывании технологий распознавания лиц в режиме реального времени организации также должны обеспечивать, что к разным стадиям обработки применяются разные сроки хранения данных:
— если совпадения с биометрическими образцами не зафиксировано, биометрические образцы физических лиц, оказавшихся в неконтролируемом пространстве, не подлежат хранению и должны быть автоматически удалены;
— если зафиксировано совпадение, биометрические образцы могут храниться в течение строго ограниченного срока, установленного законом наряду с необходимыми гарантиями, и отчеты о совпадениях, включающие персональные данные, также могут храниться в течение ограниченного срока;
— в любом случае список наблюдения и биометрические образцы должны быть удалены, когда достигнута цель, которую преследовало использование технологии распознавания лиц онлайн.
Точность
Организации должны обеспечивать, что биометрические образцы и цифровые изображения являются точными и обновленными. Например, качество изображений и биометрических образцов, включенных в списки наблюдения, должны проверяться для предупреждения потенциальных ложных совпадений, поскольку низкое качество изображений может являться причиной ряда ошибок. Это напрямую связано с источниками изображений, включенных в список наблюдения, от которых требуется строгое соблюдение принципов защиты данных, таких как принцип целевого ограничения.
В случае ложных совпадений организации должны принимать все разумные шаги для исправления ситуации и обеспечения точности цифровых изображений и биометрических образцов.
Любое нарушение безопасности данных может иметь особенно тяжкие последствия для субъектов данных, поскольку несанкционированное раскрытие такой конфиденциальной информации невозможно исправить.
Поэтому как на техническом, так и на организационном уровне должны применяться строгие меры безопасности с целью защиты данных распознавания лиц и наборов изображений от утечки и несанкционированного доступа или использования данных на всех этапах обработки, будь то сбор, передача или хранение.
Организации должны принимать меры для предупреждения специфических для данных технологий атак, в том числе презентационных и морфинговых атак.
О любом нарушении безопасности данных, которое может серьезно затронуть права и основные свободы субъектов данных, необходимо докладывать в надзорный орган и, в случае необходимости, сообщать субъектам данных.
Меры безопасности должны меняться с течением времени и в ответ на изменение угроз и выявление уязвимостей. Они также должны быть соразмерными конфиденциальности данных, контексту использования конкретной технологии распознавания лиц и ее целям, вероятности причинения вреда физическим лицам и другим значимым факторам.
Строгие практики хранения и удаления — через безопасные процедуры — для данных распознавания лиц и максимально короткие периоды хранения, также способствуют снижению рисков для безопасности.
Организации должны принимать надлежащие меры для того, чтобы выполнять свои обязательства и иметь возможность доказать, что обработка данных, которая осуществляется под их контролем, соответствует данным обязательствам, как предусмотрено в статье 10 Конвенции 108+.
Следующие организационные меры должны рассматриваться организациями, использующими технологии распознавания лиц:
— применение транспарентной политики, процедур и практик для обеспечения того, что в основе использования технологий распознавания лиц лежит защита прав субъектов данных;
— публикация докладов о транспарентности в отношении конкретных случаев использования технологий распознавания лиц;
— создание и проведение образовательных программ и аудиторских процедур для тех, кто отвечает за обработку данных распознавания лиц;
— создание комитетов внутреннего надзора для оценки и улучшения любой обработки с использованием данных распознавания лиц;
— распространение договорных обязательств по соблюдению соответствующих требований на третьи стороны — сервис-провайдеров, деловых партнеров или другие организации, использующие технологии распознавания лиц (и отказ в доступе третьим сторонам, которые не выполняют данные обязательства);
— в публичном секторе: предварительная оценка ограничений процедур государственных закупок с участием инструментов распознавания лиц, оценка минимальных уровней результативности в плане точности, особенно если речь идет о правоохранительных целях.
Организации должны принимать все необходимые технические меры для обеспечения качества биометрических данных путем соблюдения международных технических стандартов в зависимости от контекста их использования.
Организации, использующие технологии распознавания лиц, должны обеспечивать, что люди продолжают играть решающую роль в действиях, предпринимаемых по итогам использования данных технологий. Организации, использующие данные технологии, должны принимать организационные меры для контроля за лицами, принимающими решения, которые могут привести к значительным последствиям для индивидов.
3.1. ОЦЕНКА ПОСЛЕДСТВИЙ ЗАЩИТЫ ДАННЫХ
Организации, использующие технологии распознавания лиц, должны проводить оценку последствий до обработки, поскольку использование данных технологий предполагает обработку биометрических данных и влечет за собой высокие риски для основных прав субъектов данных.
В ходе подготовки оценки последствий организации должны не только признать риски, связанные с возможной обработкой, но также рассмотреть необходимые смягчающие меры для снижения этих рисков, принимая необходимые технические и организационные меры. В рамках оценки они должны объяснять среди прочего:
— правомерность использования данных технологий;
— какие основные права затронуты биометрической обработкой;
— уязвимость субъектов данных;
— каким образом эти риски могут быть эффективно снижены.
Более конкретно, при рассмотрении возможности развертывания технологий распознавания лиц в неконтролируемой обстановке правоохранительные органы должны:
— оценить и объяснить строгую необходимость и соразмерность развертывания данных технологий;
— оценить риски для разных основных прав, в том числе защиты данных, личной жизни, свободы выражения, свободы собраний, свободы передвижения или запрета дискриминации, в зависимости от возможных случаев использования в разных местах.
Оценка последствий должна проводиться либо самими организациями, либо независимым наблюдательным органом, либо аудитором с надлежащим опытом, позволяющим выявить, измерить или предугадать возникающие со временем последствия и риски.
В ходе подготовки оценки последствий организации должны контактировать с заинтересованными лицами, в том числе физическими лицами, интересы которых могут быть затронуты, для оценки потенциальных последствий с их стороны.
Такая оценка последствия должна проводиться регулярно.
В случае выявления риска соответствующие организации должны иметь возможность обратиться в любые существующие комитеты по этике, а также в уполномоченные надзорные органы для рассмотрения потенциальных рисков.
После завершения оценки организации должны опубликовать ее результаты с целью получения отзывов со стороны общественности по вопросу возможного развертывания технологий распознавания лиц.
3.2. ЗАЩИТА ДАННЫХ НА СТАДИИ РАЗРАБОТКИ
Защита данных на стадии разработки охватывает всю цепочку активности обработки с помощью технологий распознавания лиц. Организации, использующие данные технологии для целей идентификации или проверки, должны обеспечивать, чтобы продукция или услуги, которыми они пользуются, были разработаны для обработки биометрических данных в соответствии с принципами целевых ограничений, минимизации данных или ограниченного срока хранения и чтобы в них были интегрированы все другие необходимые гарантии.
Если организации устанавливают технические свойства данных технологий, они должны соблюдать данные принципы с целью обеспечения того, что развертывание не будет нарушать право на защиту данных.
В дополнение к соблюдению юридических обязательств также очень важно обозначить этические принципы использования данных технологий, в частности, с учетом повышенных рисков, неразрывно связанных с использованием технологий распознавания лиц в некоторых секторах. Для этого могут быть созданы независимые консультативные советы по этике, с которыми могут быть проведены консультации перед и во время длительных развертываний, которые могут проводить проверки и публиковать результаты своих исследований, чтобы дополнять или подтверждать ответственность организации. Этические соображения могут помочь в соблюдении надлежащего баланса между противоположными интересами явно справедливым образом18).
Кроме того, с целью избежать нарушений прав человека комитеты экспертов в разных областях знаний, вероятно, смогут определить наиболее потенциально сложные случаи, возникающие при использовании технологий распознавания лиц.
В этой сфере важную роль также играют информаторы (разоблачители), и работники организаций, использующих данные технологии, должны иметь возможность пользоваться надлежащей защитой, как предусмотрено, в частности, в Рекомендации (2014)7 Комитета Министров «О защите информаторов, сообщающих о противозаконной деятельности»19).
Поскольку распознавание лиц основано на обработке персональных данных, субъектам данных гарантируются все права, предусмотренные в статье 9 Конвенции 108+, в частности, право на информацию, право на доступ, право на получение сведений об основании обработки, право на возражение и право на ректификацию.
Данные права могут быть ограничены, но при условии, что ограничение предусмотрено законом, не нарушает саму суть основных прав и свобод и представляет собой необходимую и соразмерную меру в демократическом обществе для достижения конкретных правомерных целей (таких, как правоохранительные) в соответствии со статьей 11 Конвенции 108+.
В случае ограничения прав субъектов данных правоохранительные органы должны информировать субъектов данных, помимо прочего, об их праве подать жалобу в надзорные органы и об их общем праве на средство правовой защиты.
В случае ложных совпадений субъекты данных могут требовать ректификации с целью предупреждения дальнейших/повторяющихся ложных совпадений.
Когда использование технологий распознавания лиц направлено на то, чтобы решение было принято исключительно на основании автоматизированной обработки, что может в значительной степени затронуть субъекта данных, последний должен, в частности, иметь право на то, чтобы такая обработка не проводилась без учета его или ее мнения.
При развертывании технологий распознавания лиц в режиме реального времени, если операторы-люди действуют только на основании результатов использования данных технологий, это может рассматриваться как исключительно автоматизированный процесс принятия решений, который в значительной степени затронет субъекта данных в связи с последствиями возможных ложных совпадений. В связи с этим субъект данных может требовать в соответствии с подпунктом «а» пункта 1 статьи 9 Конвенции 108+, чтобы его мнение было принято во внимание.
Выясняем, как устроено распознавание лиц на видео и фото, и пробуем самостоятельно создать собственный детектор вместе с программистом Александром Белозеровым.

Где нужно распознавание лиц?
Разработкой ПО для распознавания и улучшением алгоритмов занимаются программисты и дата-сайентисты. Эта технология нужна в разных сферах:
- Государство: видеоаналитика используется службами безопасности стран для пограничного контроля, а в Москве так находили нарушителей карантина. Службы безопасности организаций, имеющих дело с секретностью, также используют алгоритмы идентификации для контроля доступа сотрудников к секретным объектам.
- IT-индустрия: Microsoft, Google, Яндекс, ВКонтакте тоже разрабатывают собственные алгоритмы.
- Медицина: технология помогает выявить болезни и отслеживать прогресс в лечении.
- Банкинг: банки используют идентификацию по лицу, чтобы снять деньги в банкомате или получить кредит.
- Образование: распознавание лица помогает поймать тех, кто списывает, — сервисы подключаются к камере на компьютере студента и отслеживают его поведение и движение глаз.
- Персональные портативные устройства: на смартфонах помимо идентификации пользователя распознавание лица выполняет и развлекательную функцию — у приложений Samsung и Snapchat оно лежит в основе AR-фильтров и масок для лица.
Как работает распознавание лиц: метод Виолы-Джонса
Один из способов распознать образ — найти контур объекта и исследовать его свойства. По этому принципу работает метод Виолы-Джонса с использованием признаков Хаара, который придумал венгерский математик Альфред Хаар.
Признаки — это набор геометрических фигур с черно-белым узором, их еще называют маски. Они помогают найти границы какой-либо формы, например очертания лица, линии бровей, носа или рта.

В алгоритме Виолы-Джонса маски накладываются на разные части кадра, а программа определяет, может ли в них находиться объект. Работает это так:
- Классификатор (алгоритм, который будет искать объект в кадре) обучают на фотографиях лиц и получают пороговое значение — его превышение будет сигнализировать о том, что в кадре есть лицо.
- В классификатор загружают изображение, на котором будут искать лицо.
- Классификатор накладывает на него маски и отдельно складывает яркость пикселей, попавших в белую часть маски, и яркость пикселей, попавших в черную часть маски. Потом из первого значения он вычитает второе.
Результат сравнивается с пороговой величиной.
Если результат меньше пороговой величины, значит, в части кадра нет лица, и алгоритм заканчивает свою работу. А если больше, он переходит к следующей части кадра.
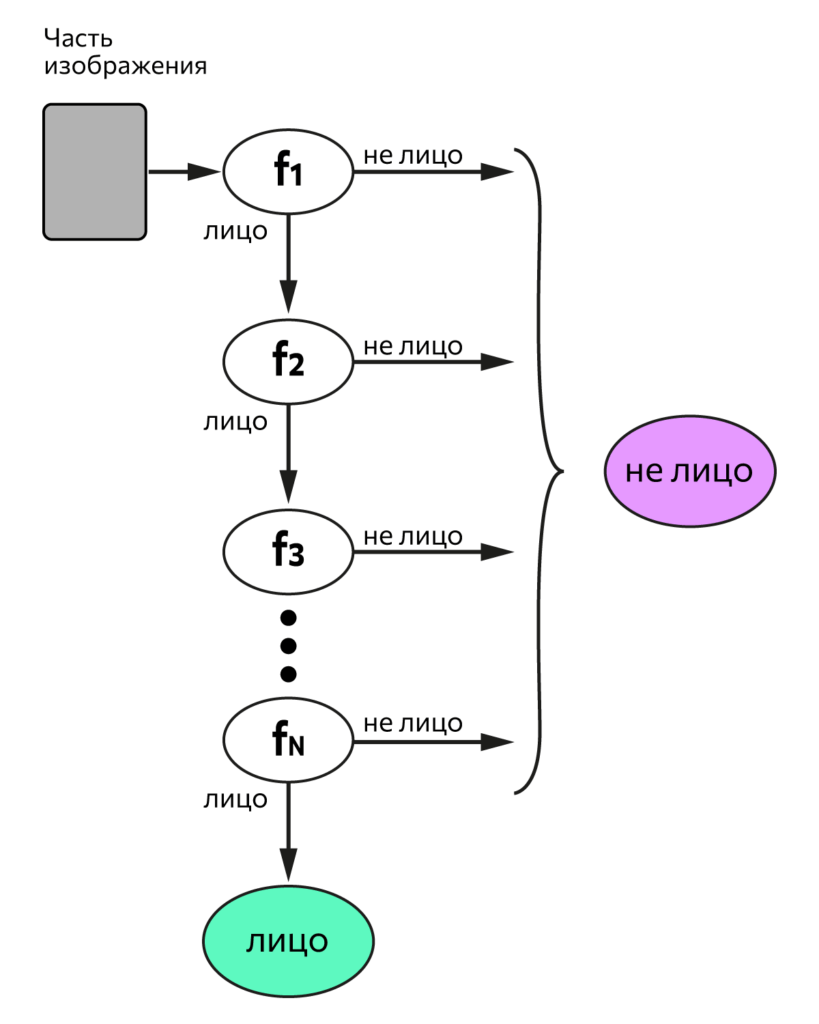
На практике маски находят лицо на фотографии так:
Алгоритмы OpenCV
У изображения лица есть свои характеристики:
- Темные и светлые участки и зоны (темные — глаза, губы; светлые — лоб, щеки, подбородок).
- Лица всех людей устроены по одному принципу (глаза — на одной линии, под глазами — нос, под носом — губы, под губами — подбородок).
Это значит, что можно подобрать такой набор масок и составить такой классификатор, который будет учитывать эти особенности.
Для этого можно использовать OpenCV — библиотеку алгоритмов компьютерного зрения и обработки изображений. Реализована она на C/C++, также разрабатывается для Python, Java, Ruby, Matlab, Lua и других языков.
Инструкция: распознаем лицо на фото
Шаг 1. Скачайте готовый классификатор. Мы будем использовать классификатор OpenCV, обученный находить лица, а также глаза, улыбки и другие черты. Скачать его в виде xml-файлов можно с GitHub.
Шаг 2. Скачайте PyCharm.

Для разработки мы советуем кроссплатформенную среду разработки PyCharm — в ней есть полезные инструменты для управления версиями пакетов, анализа кода и его отладки. Скачать ее можно тут.
Шаг 3. Создайте новый проект на Python, мы назвали его opencv_face_recognition.
Шаг 4. По правому клику на названии проекта в дереве каталогов добавьте новый файл main.py.
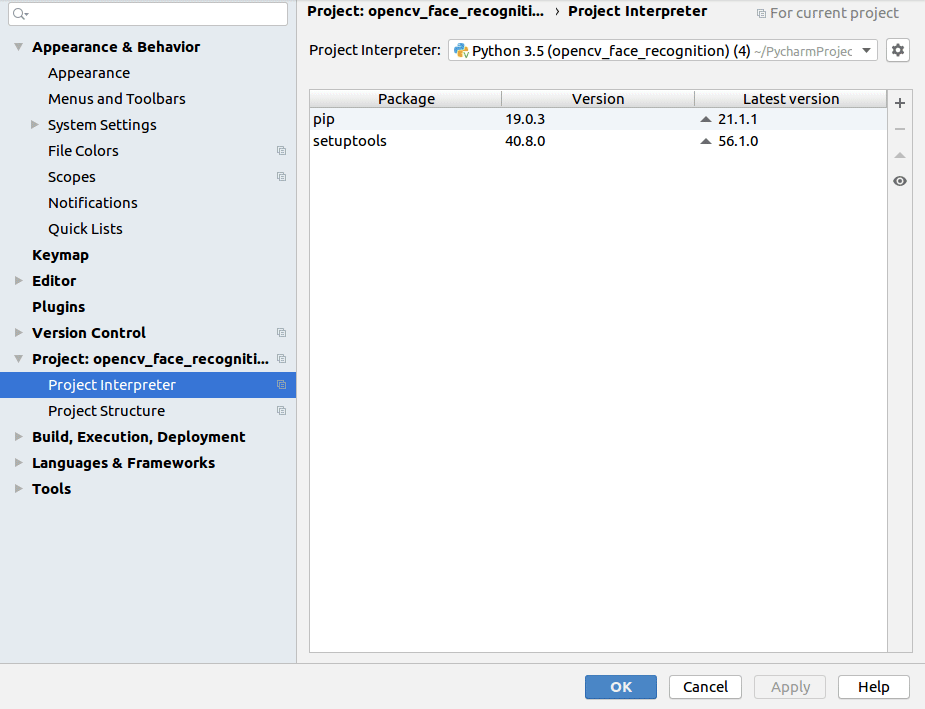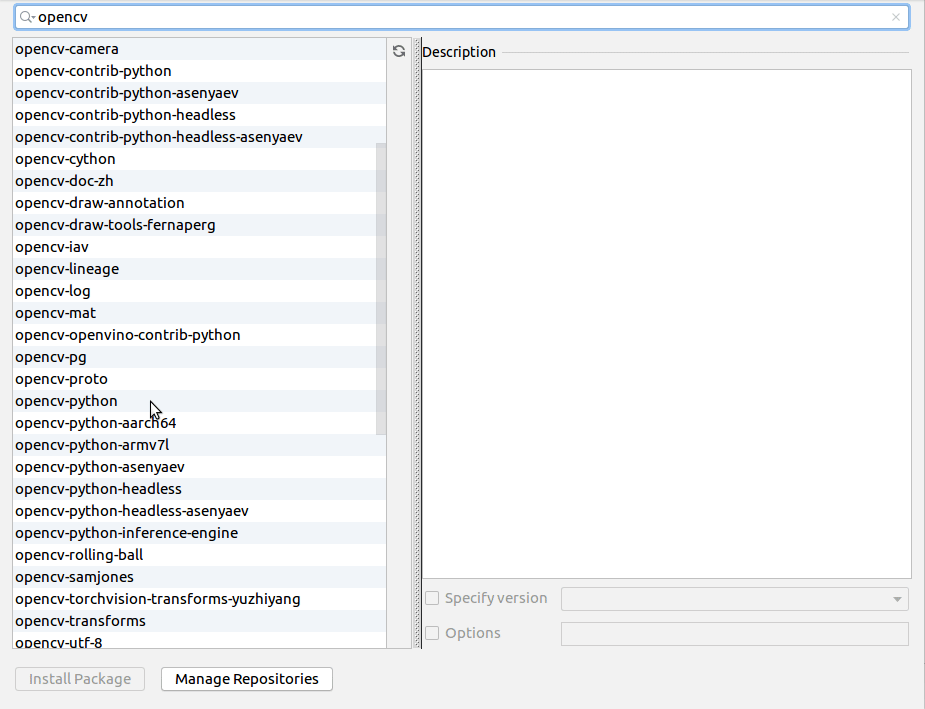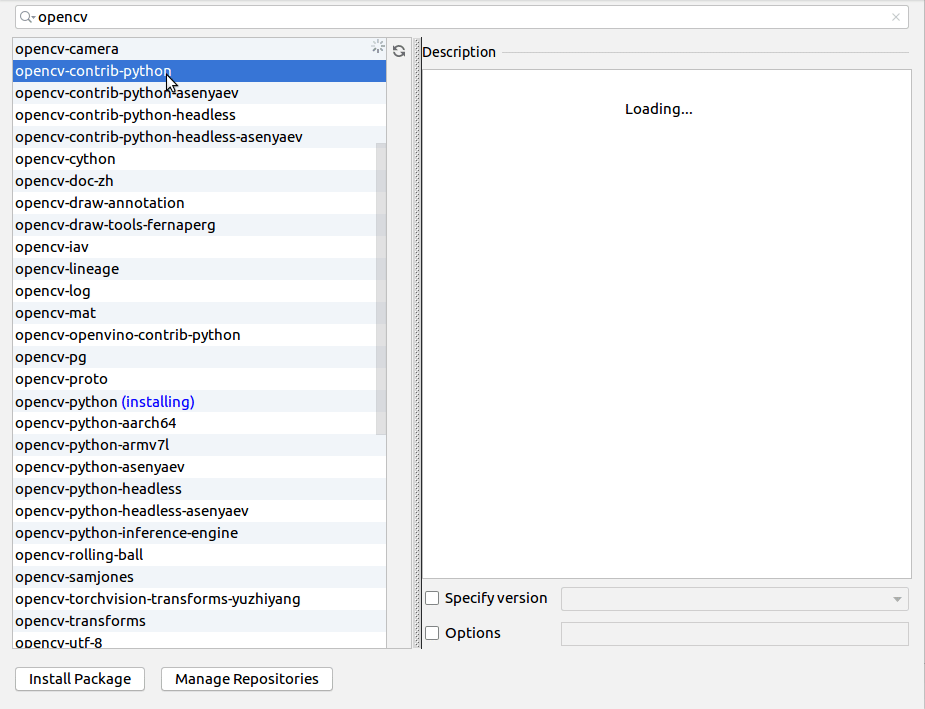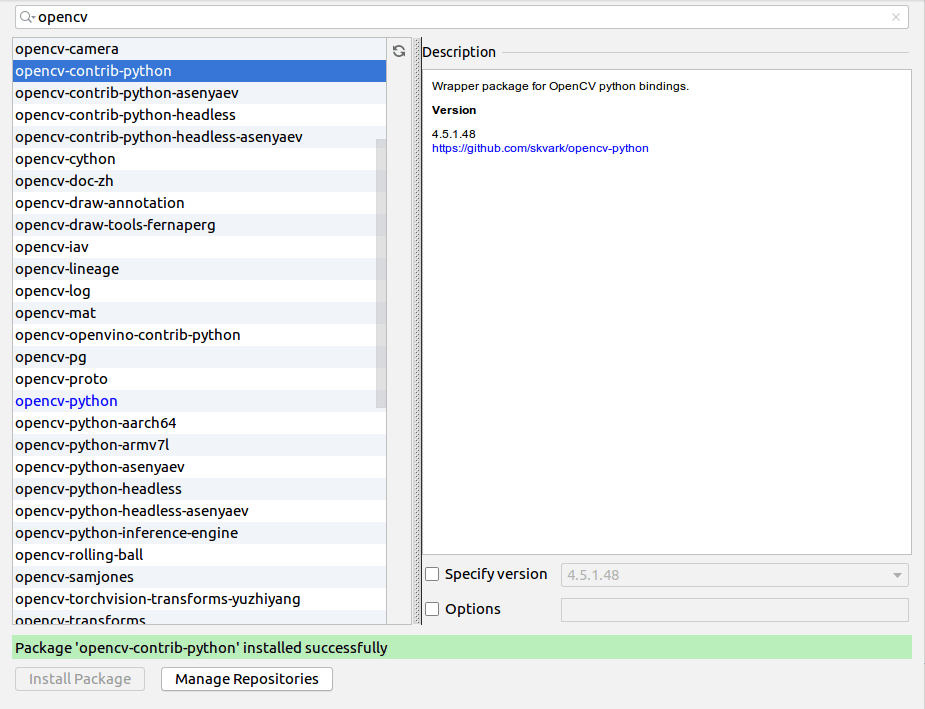
Шаг 5. Установите библиотеку. Для этого в настройках (Settings) проекта нужно найти вкладку с управлением конфигурацией интерпретатора, нажать на «+», вбить в поиск последовательно «opencv—python» и «opencv-contrib-python» и установить эти пакеты.
Это облегченная версия, которая использует для расчетов только процессор, но процесс установки все равно может занять до 15 минут.
Шаг 6. Чтобы использовать установленную библиотеку OpenCV, импортируйте модуль cv2:
import cv2
До тех пор пока мы не обратимся к каким-либо именам из него, он будет подсвечиваться серым, как неиспользуемый.
Шаг 7. Поместите ранее скачанный классификатор haarcascade_frontalface_default.xml в папку проекта
и загрузите его следующим образом:
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
Обратите внимание, что в PyCharm для его корректной подсветки синтаксиса нам пришлось переписать первую строку с импортом.
Шаг 8. Загрузите изображение, на котором мы будем искать лицо, в режиме оттенков серого — информация о цвете алгоритму не важна, только его интенсивность:
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
img = cv2.imread(‘xfiles4.jpg’)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
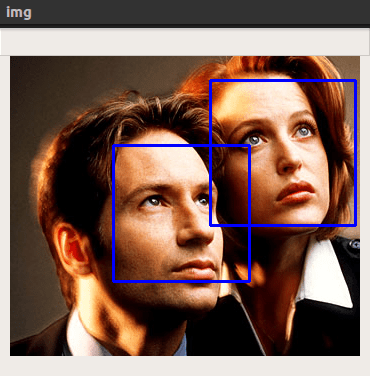
Мы будем использовать кадр из сериала «Секретные материалы» с Малдером и Скалли; вы можете поместить в папку проекта любое другое фото.

Шаг 9. Напишите код. Для поиска лиц на изображении мы используем метод с сигнатурой (его именем и списком параметров)
cv2.CascadeClassifier.detectMultiScale (image [, scaleFactor [, minNeighbors [, flags [, minSize [, maxSize]]]]]):
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
img = cv2.imread(‘xfiles4.jpg’)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
Нам хватит первых трех параметров.
- В image надо будет передать 8-битную матрицу изображения.
- scaleFactor показывает, во сколько раз мы будем уменьшать исходное изображение, пытаясь обнаружить объект: это делается потому, что мы изначально не знаем, какого размера будет лицо. Чем меньше будет этот коэффициент, тем дольше будет работать алгоритм.
- minNeighbors влияет на качество обнаружения: чем больше его значение, тем меньше образов сможет обнаружить алгоритм, но тем точнее будет его работа.
Дефолтные значения для последних двух параметров — 1.1 и 3. Их можно заменить на любые другие и подобрать для конкретного случая, если на дефолтных значениях алгоритм будет работать плохо.
Шаг 10. Если лица будут обнаружены, функция вернет набор объектов типа Rect (x, y, w, h) — прямоугольников, начало которых задано парой координат (x, y), а ширина и высота — как w и h. В цикле for добавим эти прямоугольники в исходное изображение image при помощи cv2.rectangle(image, start_point, end_point, color, thickness) по координатам их противоположных вершин (x, y) и (x+w, y+h):
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
img = cv2.imread(‘xfiles4.jpg’)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
Шаг 11. Для отображения результата и закрытия программы по нажатию клавиши добавим еще несколько строк: вывод картинки, ожидание нажатия любой клавиши и последующее закрытие окна. В итоге весь наш проект будет выглядеть так:
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
img = cv2.imread(‘xfiles4.jpg’)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
cv2.imshow(‘img’, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Шаг 12. Сочетанием клавиш Ctrl-Shift-F10 (Ctrl-Shift-R на MacOS) запустим скрипт:
Инструкция: распознаем лицо в видеопотоке с веб-камеры
Модернизируем наш код так, чтобы в реальном времени обнаруживать лица в кадре, например, на видео с веб-камеры.
Шаг 1. Создайте объект для захвата видеострима:
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
capture_io = cv2.VideoCapture(2)
Число для cv2.VideoCapture() придется поперебирать, индексом нашей внешней веб-камеры оказалась двойка.
Шаг 2. Считывать кадры с видеоустройства будем в вечном цикле: cv2.VideoCapture.read() возвращает булево значение об успешном считывании из потока (оно нам не нужно) в паре с самой картинкой. Преобразуем ее в 8-битную матрицу так же, как и раньше:
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
capture_io = cv2.VideoCapture(2)
while True:
_, img = capture_io.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
Шаг 3. Остается переписать только конец цикла — чтобы у него было условие выхода, например, по нажатию на «q» (от quit, «выйти»). cv2.waitKey(time) 10 мс ожидает ввода с клавиатуры юникод-символа, который приведет к закрытию стрима и программы.
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
capture_io = cv2.VideoCapture(2)
while True:
_, img = capture_io.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
cv2.imshow(‘img’, img)
if cv2.waitKey(10) & 0xFF == ord(«q»):
break
capture_io.release()
cv2.destroyAllWindows()
Шаг 4. Код готов, нажимаем Ctrl-Shift-F10 (Ctrl-Shift-R на MacOS) и наблюдаем результат вживую:

У вас в телефоне наверняка уже есть технология распознавания лиц. Ещё она есть в городских камерах наблюдения, на заводах и военных объектах, в лабораториях и даже в автомобилях. Посмотрим, как они устроены.
Из чего состоит распознавание лиц
Чтобы машина узнала лицо с помощью камеры, нужны такие компоненты:
- Оптическая камера или лидар, чтобы получить изображение или объёмную карту лица.
- База данных с заранее проанализированными лицами.
- Алгоритм, который находит в кадре лицо.
- Алгоритм приведения лица к какому-то набору векторов.
- Алгоритм сравнения векторов с эталонами.
Теперь посмотрим детали.
Получаем изображение с камеры
Это самая простая часть, которая может даже не зависеть от алгоритма распознавания лиц. Задача компьютера — взять видеопоток с камеры, в реальном времени нарезать его на несколько кадров и эти кадры отправить в алгоритм.
Некоторые алгоритмы используют плоское изображение с камеры. Другие используют лидары — это когда лазерная пушка быстро-быстро стреляет лазером во все стороны и измеряет скорость возвращения лучей. Получается не слишком точная, но в некоторой степени объёмная картинка. Часто её совмещают с изображением основной камеры, чтобы убедиться, что перед нами действительно человек, а не его фотография.
Иногда алгоритм настроен так, чтобы получать только подвижные изображения с меняющейся мимикой — чтобы не сканировали спящих людей или маски.
Некоторые алгоритмы вычисляют трёхмерную модель на основании поворота головы. Прямо говорят: посмотрите налево, посмотрите направо, приблизьтесь, отдалитесь. Так они пытаются построить более точную объёмную модель лица. Всё это — для безопасности.

Находим лицо в кадре
Перед тем как алгоритм приступит к распознаванию, ему нужно найти лицо на картинке. Для этого он использует метод Виолы — Джонса и специальные чёрно-белые прямоугольники (примитивы Хаара), которые выглядят примерно так:

С помощью этих прямоугольников алгоритм пытается найти на картинке похожие переходы между светлыми и тёмными областями. Если в одном месте программа находит много таких совпадений, то, скорее всего, это лицо человека. Например, вот как с помощью этих примитивов алгоритм находит нос и глаза:

Все примитивы специально подобраны так, чтобы с их помощью можно было найти границы лица и отсечь всё остальное. Поэтому, как только алгоритм находит место скопления таких совпадений, он для проверки сравнивает там остальные прямоугольники:

Если их набирается достаточное количество — это точно лицо. Обычно алгоритмы поиска лиц для контроля обводят рамкой найденную область — она помогает разработчикам понять, всё ли в порядке с логикой программы:

Строим модель по ключевым точкам
После того как алгоритм нашёл лицо, он строит его цифровую модель. Для этого он:
- Расставляет точки в ключевых местах: нос, рот, глаза, брови и так далее.
- Считает расстояние между точками.
- По этим расстояниям строит цифровую карту или вектор. Про векторы поговорим ниже.

От того, как будут расставлены эти точки, зависит точность распознавания, поэтому каждая коммерческая компания держит свой метод в секрете. Чем больше точек — тем выше точность, но минимально нужно проставить 68 точек. Если точек будет меньше, алгоритм может не сработать.
Считаем вектор и сравниваем с базой
Когда все точки найдены, алгоритм считает вектор — математический результат обработки свойств этих точек. Например, он находит расстояние между глазами, форму носа, толщину губ, форму бровей, расстояния между ними и ещё массу других параметров. В результате получается набор чисел, который называется вектором.
Если алгоритм работает в режиме «выучить новое лицо», то он записывает полученный вектор в базу данных с каким-то именем или идентификатором. Условно говоря, в базе это выглядит так:
«Вот здоровенный вектор из 900 чисел — я назову его Мишей»

Другой режим работы алгоритма — сопоставление с эталоном. В базе данных уже есть один или несколько векторов, а задача алгоритма — сравнить их с новым вектором, который посчитали только что по картинке с камеры. Тогда алгоритм считает, насколько новый вектор отличается от тех, которые уже лежат в базе данных. Если этот вектор отличается достаточно мало, считаем, что мы распознали лицо.
На картинке видно, что синий неизвестный вектор, который мы хотим распознать, ближе всех находится к Мише. Если расстояние между векторами будет достаточно маленьким, алгоритм скажет, что человек в кадре — это Миша.

У каждого алгоритма свои коэффициенты совпадения: где-то допустимо совпадение только на 98% и выше — тогда алгоритм не будет вас узнавать, если вы в маске или вокруг плохое освещение. Есть алгоритмы, где совпадение может быть меньше — тогда это менее безопасно, но лучше работает. Есть алгоритмы, которые в одном месте требуют точного совпадения, а в других — менее точного (например, глаза должны совпасть точно, а рот может двигаться). Это уже нюансы настройки и подкрутки конкретного алгоритма.
Уточнение векторов и самообучение
Есть алгоритмы, которые уточняются и узнают вас всё лучше со временем. При каждом распознавании лица они видят, что в вас изменилось с прошлого раза, и уточняют свою модель. Например, вы занесли себя в базу данных с бодуна, а на следующий день пришли огурцом. Алгоритм запомнил вас в обоих состояниях.
Что дальше
Теперь, когда мы знаем, как работает эта технология, попробуем повторить это сами — сделаем систему распознавания лиц на Python.
Вёрстка:
Кирилл Климентьев