
Деятельность людей во множестве случаев предполагает работу с данными, а она в свою очередь может подразумевать не только оперирование ими, но и их изучение, обработку и анализ. Например, когда нужно уплотнить информацию, найти какие-то взаимосвязи или определить структуры. И как раз для аналитики в этом случае очень удобно пользоваться не только разными техниками мышления, но и применять статистические методы.
Особенностью методов статистического анализа является их комплексность, обусловленная многообразием форм статистических закономерностей, а также сложностью процесса статистических исследований. Однако мы хотим поговорить именно о таких методах, которые может применять каждый, причем делать это эффективно и с удовольствием.
Статистическое исследование может проводиться посредством следующих методик:
- Статистическое наблюдение;
- Сводка и группировка материалов статистического наблюдения;
- Абсолютные и относительные статистические величины;
- Вариационные ряды;
- Выборка;
- Корреляционный и регрессионный анализ;
- Ряды динамики.
Далее мы рассмотрим каждый из них более подробно. Но отметим, что представим лишь основные характеристики без подробного описания алгоритмов действий. Впрочем, понять их не составит никакого труда.
Статистическое наблюдение
Статистическое наблюдение является планомерным, организованным и в большинстве случаев систематическим сбором информации, направленным, главным образом, на явления социальной жизни. Реализуется данный метод через регистрацию предварительно определенных наиболее ярких признаков, цель которой состоит в последующем получении характеристик изучаемых явлений.
Статистическое наблюдение должно выполняться с учетом некоторых важных требований:
- Оно должно полностью охватывать изучаемые явления;
- Получаемые данные должны быть точными и достоверными;
- Получаемые данные должны быть однообразными и легкосопоставимыми.
Также статистическое наблюдение может иметь две формы:
- Отчетность – это такая форма статистического наблюдения, где информация поступает в конкретные статистические подразделения организаций, учреждений или предприятий. В этом случае данные вносятся в специальные отчеты.
- Специально организованное наблюдение – наблюдение, которое организуется с определенной целью, чтобы получить сведения, которых не имеется в отчетах, или же для уточнения и установления достоверности информации отчетов. К этой форме относятся опросы (например, опросы мнений людей), перепись населения и т.п.
Кроме того, статистическое наблюдение может быть категоризировано на основе двух признаков: либо на основе характера регистрации данных, либо на основе охвата единиц наблюдения. К первой категории относятся опросы, документирование и прямое наблюдение, а ко второй – наблюдение сплошное и несплошное, т.е. выборочное.
Для получения данных при помощи статистического наблюдения можно применять такие способы как анкетирование, корреспондентская деятельность, самоисчисление (когда наблюдаемые, например, сами заполняют соответствующие документы), экспедиции и составление отчетов.
Сводка и группировка материалов статистического наблюдения
Говоря о втором методе, в первую очередь следует сказать о сводке. Сводка представляет собой процесс обработки определенных единичных фактов, которые образуют общую совокупность данных, собранных при наблюдении. Если сводка проводится грамотно, огромное количество единичных данных об отдельных объектах наблюдения может превратиться в целый комплекс статистических таблиц и результатов. Также такое исследование способствует определению общих черт и закономерностей исследуемых явлений.
С учетом показателей точности и глубины изучения можно выделить простую и сложную сводку, но любая из них должна основываться на конкретных этапах:
- Выбирается группировочный признак;
- Определяется порядок формирования групп;
- Разрабатывается система показателей, позволяющих охарактеризовать группу и объект или явление в целом;
- Разрабатываются макеты таблиц, где будут представлены результаты сводки.
Важно заметить, что есть и разные формы сводки:
- Централизованная сводка, требующая передачи полученного первичного материала в вышестоящий центр для последующей обработки;
- Децентрализованная сводка, где изучение данных происходит на нескольких ступенях по восходящей.
Выполняться же сводка может при помощи специализированного оборудования, например, с использованием компьютерного ПО или вручную.
Что же касается группировки, то этот процесс отличается разделением исследуемых данных на группы по признакам. Особенности поставленных статистическим анализом задач влияют на то, какой именно будет группировка: типологической, структурной или аналитической. Именно поэтому для сводки и группировки либо прибегают к услугам узкопрофильных специалистов, либо применяют конкретные техники мышления.
Абсолютные и относительные статистические величины
Абсолютные величина считаются самой первой формой представления статистических данных. С ее помощью удается придать явлениям размерные характеристики, например, по времени, по протяженности, по объему, по площади, по массе и т.д.
Если требуется узнать об индивидуальных абсолютных статистических величинах, можно прибегнуть к замерам, оценке, подсчету или взвешиванию. А если нужно получить итоговые объемные показатели, следует использовать сводку и группировку. Нужно иметь в виду, что абсолютные статистические величины отличаются наличием единиц измерения. К таким единицам относят стоимостные, трудовые и натуральные.
А относительные величины выражают количественные соотношения, касающиеся явлений социальной жизни. Чтобы их получить, одни величины всегда делятся на другие. Показатель, с которым сравнивают (это знаменатель), называют основанием сравнения, а показатель, которой сравнивают (это числитель), называют отчетной величиной.
Относительные величины могут быть разными, что зависит от их содержательной части. Например, существуют величины сравнения, величины уровня развития, величины интенсивности конкретного процесса, величины координации, структуры, динамики и т.д. и т.п.
Чтобы изучить какую-то совокупность по дифференцирующимся признакам, в статистическом анализе применяются средние величины – обобщающие качественные характеристики совокупности однородных явлений по какому-либо дифференцирующемуся признаку.
Крайне важным свойством средних величин является то, что они говорят о значениях конкретных признаков во всем их комплексе единым числом. Невзирая на то, что у отдельных единиц может наблюдаться количественная разница, средние величины выражают общие значения, свойственные всем единицам исследуемого комплекса. Получается, что при помощи характеристики чего-то одного можно получить характеристику целого.
Следует иметь в виду, что одним из самых важных условий применения средних величин, если проводится статистический анализ социальных явлений, считается однородность их комплекса, для которого и нужно узнать среднюю величину. А от такого, как именно будут представлены начальные данные для исчисления средней величины, будет зависеть и формула ее определения.
Вариационные ряды
В некоторых случаях данных о средних показателях тех или иных изучаемых величин может быть недостаточно, чтобы провести обработку, оценку и глубокий анализ какого-то явления или процесса. Тогда во внимание следует брать вариацию или разброс показателей отдельных единиц, который тоже представляет собой важную характеристику исследуемой совокупности.
На индивидуальные значения величин могут воздействовать многие факторы, а сами изучаемые явления или процессы могут быть очень многообразны, т.е. обладать вариацией (это многообразие и есть вариационные ряды), причины которой следует искать в сущности того, что изучается.
Вышеназванные абсолютные величины находятся в непосредственной зависимости от единиц измерения признаков, а значит, делают процесс изучения, оценки и сравнения двух и более вариационных рядов более сложным. А относительные показатели нужно вычислять в качестве соотношения абсолютных и средних показателей.
Выборка
Смысл выборочного метода (или проще – выборки) состоит в том, что по свойствам одной части определяются численные характеристики целого (это называется генеральной совокупностью). Основной выборочного метода является внутренняя связь, объединяющая части и целое, единичное и общее.
Метод выборки отличается рядом существенных преимуществ перед остальными, т.к. благодаря уменьшению количества наблюдений позволяет сократить объемы работы, затрачиваемые средства и усилия, а также успешно получать данные о таких процессах и явлениях, где либо нецелесообразно, либо просто невозможно исследовать их полностью.
Соответствие характеристик выборки характеристикам изучаемого явления или процесса будет зависеть от комплекса условий, и в первую очередь от того, как вообще будет реализовываться выборочный метод на практике. Это может быть как планомерный отбор, идущий по подготовленной схеме, так и непланомерный, когда выборка производится из генеральной совокупности.
Но во всех случаях выборочный метод должен быть типичным и соответствовать критериям объективности. Данные требования нужно выполнять всегда, т.к. именно от них будет зависеть соответствие характеристик метода и характеристик того, что подвергается статистическому анализу.
Таким образом, перед обработкой выборочного материала необходимо провести его тщательную проверку, избавившись тем самым от всего ненужного и второстепенного. Одновременно с этим, составляя выборку, в обязательном порядке нужно обходить стороной любую самодеятельность. Это означает, что ни в коем случае не следует делать выборку только из вариантов, кажущихся типичными, а все другие – отбрасывать.
Эффективная и качественная выборка должна составляться объективно, т.е. производить ее нужно так, чтобы были исключены любые субъективные влияния и предвзятые побуждения. И чтобы это условие было соблюдено должным образом, требуется прибегнуть к принципу рандомизации или, проще говоря, к принципу случайного отбора вариантов из всей их генеральной совокупности.
Представленный принцип служит основой теории выборочного метода, и следовать ему нужно всегда, когда требуется создать эффективную выборочную совокупность, причем случаи планомерного отбора исключением здесь не являются.
Корреляционный и регрессионный анализ
Корреляционный анализ и регрессионный анализ – это два высокоэффективных метода, позволяющие проводить анализ больших объемов данных для изучения возможной взаимосвязи двух или большего количества показателей.
В случае с корреляционным анализом задачами являются:
- Измерить тесноту имеющейся связи дифференцирующихся признаков;
- Определить неизвестные причинные связи;
- Оценить факторы, в наибольшей степени воздействующие на окончательный признак.
А в случае с регрессионным анализом задачи следующие:
- Определить форму связи;
- Установить степень воздействия независимых показателей на зависимый;
- Определить расчетные значения зависимого показателя.
Чтобы решить все вышеназванные задачи, практически всегда нужно применять и корреляционный и регрессионный анализ в комплексе.
Ряды динамики
Посредством этого метода статистического анализа очень удобно определять интенсивность или скорость, с которой развиваются явления, находить тенденцию их развития, выделять колебания, сравнивать динамику развития, находить взаимосвязь развивающихся во времени явлений.
Ряд динамики – это такой ряд, в котором во времени последовательно расположены статистические показатели, изменения которых характеризуют процесс развития исследуемого объекта или явления.
Ряд динамики включает в себя два компонента:
- Период или момент времени, связанный с имеющимися данными;
- Уровень или статистический показатель.
В совокупности эти компоненты представляют собой два члена ряда динамики, где первый член (временной период) обозначается буквой «t», а второй (уровень) – буквой «y».
Исходя из длительности временных промежутков, с которыми взаимосвязаны уровни, ряды динамики могут быть моментными и интервальными. Интервальные ряды позволяют складывать уровни для получения общей величины периодов, следующих один за другим, а в моментных такой возможности нет, но этого там и не требуется.
Ряды динамики также существуют с равными и разными интервалами. Суть же интервалов в моментных и интервальных рядах всегда разная. В первом случае интервалом является временной промежуток между датами, к которым привязаны данные для анализа (удобно использовать такой ряд, например, для определения количества действий за месяц, год и т.д.). А во втором случае – временной промежуток, к которому привязана совокупность обобщенных данных (такой ряд можно использовать для определения качества тех же самых действий за месяц, год и т.п.). Интервалы могут быть равными и разными, независимо от типа ряда.
Естественно, чтобы научиться грамотно применять каждый из методов статистического анализа, недостаточно просто знать о них, ведь, по сути, статистика – это целая наука, требующая еще и определенных навыков и умений. Но чтобы она давалась проще, можно и нужно тренировать свое мышление и улучшать когнитивные способности.
В остальном же исследование, оценка, обработка и анализ информации – очень интересные процессы. И даже в тех случаях, когда это не приводит к какому-то конкретному результату, за время исследования можно узнать множество интересных вещей. Статистический анализ нашел свое применение в огромном количестве сфер деятельности человека, а вы можете использовать его в учебе, работе, бизнесе и других областях, включая развитие детей и самообразование.

Все сводится к использованию возможностей методов статистического анализа, с помощью которых ученые сотрудничают и собирают данные для выявления тенденций и закономерностей.
За последние десять лет повседневный бизнес претерпел значительные изменения. Нередко кажется, что все осталось по-прежнему, будь то технологии, используемые на рабочих местах, или программное обеспечение, применяемое для общения.
Сейчас доступно огромное количество информации, которая раньше была редкостью. Но она может быть подавляющей, если вы не имеете ни малейшего представления о том, как проанализировать данные вашей компании, чтобы найти в них значимый и точный смысл.
В этом блоге будут рассмотрены 5 различных методов статистического анализа, а также подробное обсуждение каждого метода.
Что такое метод статистического анализа?
Практика сбора и анализа данных для выявления закономерностей и тенденций известна как статистический анализ. Это метод устранения предвзятости при оценке данных с помощью численного анализа.
Эти методы статистического анализа полезны для сбора интерпретаций исследований, создания статистических моделей и организации опросов и исследований.
Для анализа данных используются два основных статистических метода:
- описательная статистика, которая использует такие показатели, как среднее и медиана, для обобщения данных,
- инференциальная статистика, экстраполирующая результаты из данных с помощью статистических тестов, таких как t-тест студента.
Следующие три фактора определяют, является ли статистический подход наиболее подходящим:
- Цель и основная задача исследования,
- Вид и дисперсия используемых данных, и
- Тип наблюдений (парные/непарные).
«Параметрический» относится ко всем типам статистических процедур, используемых для сравнения средних. Напротив, «непараметрические» относятся к статистическим методам, которые сравнивают меры, отличные от средних, такие как медианы, средние ранги и пропорции.
Для каждого уникального обстоятельства статистические методы анализа в биостатистике могут быть использованы для анализа и интерпретации данных. Знание допущений и условий применения статистических методов необходимо для выбора наилучшего статистического метода анализа данных.
5 методов статистического анализа для исследований и анализа
Независимо от того, являетесь ли вы специалистом по исследованию данных или нет, нет сомнений в том, что большие данные захватывают мир. В результате вы должны знать, с чего начать. Существует 5 вариантов этого метода статистического анализа:
-
Среднее значение
Большие данные захватывают мир, как бы вы их ни нарезали. Среднее значение, чаще известное как среднее, является исходным методом, используемым для проведения статистического анализа. Чтобы найти среднее значение, нужно сложить список чисел, разделить общую сумму на составляющие списка, а затем добавить еще один список чисел.
Применение этой техники позволяет быстро просмотреть данные и одновременно определить общую тенденцию сбора данных. Простой и быстрый расчет также выгоден пользователям метода.
Центр рассматриваемых данных определяется с помощью среднего статистического значения. Результат известен как среднее значение представленных данных. В реальном мире при взаимодействии в сфере исследований, образования и спорта часто используются уничижительные выражения. Подумайте, как часто в разговоре упоминается средний показатель бейсболиста — его среднее значение, если вы считаете себя специалистом по исследованию данных. В результате вы должны знать, с чего начать.
-
Стандартное отклонение
Статистический метод, называемый стандартным отклонением, измеряет, насколько широко распределены данные от среднего значения.
При работе с данными высокое стандартное отклонение указывает на то, что данные сильно разбросаны от среднего значения. Низкое отклонение указывает на то, что большинство данных соответствует среднему значению и может также называться ожидаемым значением набора.
Стандартное отклонение часто используется при анализе дисперсии точек данных — независимо от того, сгруппированы они или нет.
Представьте, что вы маркетолог, который только что закончил опрос клиентов. Предположим, вы хотите определить, будет ли большая группа клиентов давать такие же ответы. В этом случае после получения результатов опроса вам следует оценить зависимость ответов. Если стандартное отклонение низкое, то можно спрогнозировать ответы большего числа клиентов.
-
Регрессия
Регрессия в статистике изучает связь между независимой переменной и зависимой переменной (информацией, которую вы пытаетесь оценить) (данные, используемые для прогнозирования зависимой переменной).
Это также можно объяснить с точки зрения того, как одна переменная влияет на другую, или как изменения в одной непоследовательной величине приводят к изменениям в другой, или наоборот, простая причина и следствие. Это предполагает, что результат зависит от одного или нескольких факторов.
На графиках и диаграммах регрессионного анализа используются линии, показывающие тенденции за заранее определенный период, а также силу или слабость корреляций между переменными.
-
Проверка гипотез
Два набора случайных переменных в наборе данных должны быть проверены с помощью проверки гипотез, иногда называемой «Т-тестированием» в статистическом анализе.
Этот подход фокусируется на определении того, справедливо ли данное утверждение или заключение для набора данных. Он позволяет сравнить данные с многочисленными предположениями и гипотезами. Он также может помочь в прогнозировании того, как выбор повлияет на компанию.
Проверка гипотезы в статистике определяет количество при определенном предположении. Результат проверки показывает, верно ли предположение или оно нарушено. Нулевая гипотеза, иногда известная как гипотеза 0, является этим предположением. Первая гипотеза, часто известная как гипотеза 1, — это любая другая теория, которая противоречит гипотезе 0.
При проверке гипотез результаты теста считаются статистически значимыми, если они показывают, что событие не могло произойти случайно или случайным образом.
-
Определение размера выборки
При оценке данных для статистического анализа сбор достоверных данных иногда может быть затруднен, поскольку набор данных слишком велик. В таких случаях большинство выбирает метод, известный как определение размера выборки, который предполагает изучение выборки или меньшего объема данных.
Для эффективного выполнения этой задачи необходимо выбрать подходящий размер выборки. Вы не получите достоверных результатов после анализа, если размер выборки будет слишком мал.
Для достижения этого результата вы будете использовать несколько методов выборки данных. Для этого вы можете разослать опрос своим клиентам, а затем использовать метод прямой случайной выборки, чтобы отобрать данные клиентов для выборочного анализа.
И наоборот, чрезмерный размер выборки может привести к потере времени и денег. Чтобы определить размер выборки, можно рассмотреть такие факторы, как стоимость, время или простота сбора данных.
Вы запутались? Не волнуйтесь! Вы можете воспользоваться нашим калькулятором размера выборки.
Вывод
Способность аналитически мыслить жизненно важна для корпоративного успеха. Поскольку данные являются одним из наиболее важных ресурсов, доступных сегодня, их эффективное использование может привести к лучшим результатам и принятию решений.
Независимо от выбранных вами методов статистического анализа, обязательно обратите пристальное внимание на каждый потенциальный недостаток и его конкретную формулу. Ни один метод не является правильным или неправильным, и не существует золотого стандарта. Все будет зависеть от собранной вами информации и выводов, которые вы надеетесь сделать.
Основы статистики: просто о сложных формулах
Время на прочтение
6 мин
Количество просмотров 267K
Статистика вокруг нас
Статистика и анализ данных пронизывают практически любую современную область знаний. Все сложнее становится провести границу между современной биологией, математикой и информатикой. Экономические исследования и регрессионный анализ уже практически неотделимы друг от друга. Один из известных методов проверки распределения на нормальность — критерий Колмогорова-Смирнова. А вы знали, что именно Колмогоров внес огромный вклад в развитие математической лингвистики?
Еще будучи студентом психологического факультета СПбГУ, я заинтересовался когнитивной психологией. Кстати, Иммануил Кант не считал психологию наукой, так как не видел возможности применять в ней математические методы. Мои текущие исследования посвящены моделированию психических процессов, и я надеюсь, что такие направления в современной когнитивной психологии, как вычислительные и коннективисткие модели, смягчили бы его отношение!
Конечно, статистика применяется далеко за пределами научных лабораторий: в рекламе, маркетинге, бизнесе, медицине, образовании и т.д. Но, что самое интересное, базовые знания анализа данных крайне полезны и в повседневной жизни. Например, думаю, все вы знакомы с понятием среднего арифметического. Среднее значение очень часто используется в СМИ при обсуждении различных социально-экономических показателей — доходов, уровня безработицы и т.д. В 2005 году британские СМИ писали о том, что средний уровень дохода населения не только не возрос, но снизился на 0,2 % по сравнению с предыдущим годом. Мелькали заголовки «Доходы населения снизились впервые с 1990 года». Некоторые политики даже использовали этот факт, критикуя действующее правительство. Однако, важно понимать, что среднее арифметическое — хороший показатель, когда наш признак имеет симметричное распределение (богатых столько же, сколько бедных). Реальное же распределение доходов имеет скорее следующий вид:
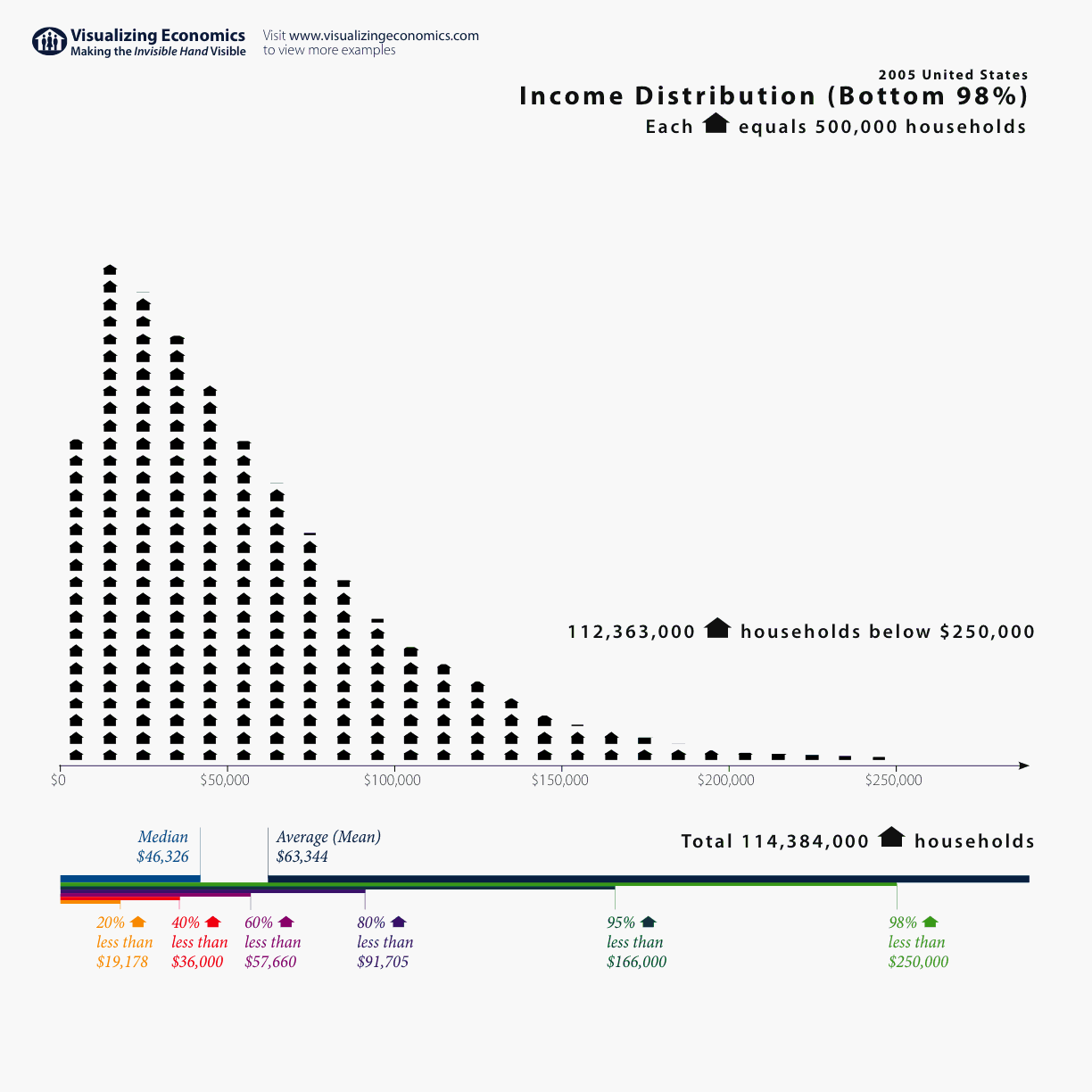
Распределение имеет явно выраженную асимметрию: очень состоятельных людей заметно меньше, чем представителей среднего класса. Это приводит к тому, что в данном случае банкротство одного из миллионеров может значительно повлиять на этот показатель. Гораздо информативнее использовать значение медианы для описания таких данных. Медиана — это значение зарплаты, которое находится в самой середине распределения доходов (50% всех наблюдений меньше медианы, 50% — больше). И, как ни удивительно, медиана дохода в 2005 году в Великобритании, в отличие от среднего значения, продолжила свой рост. Таким образом, если вы знаете о различных типах распределения и различных мерах центральной тенденции (среднее и медиана), то вас не так просто ввести в заблуждение в таких случаях, как описаны в примере.
Черный ящик статистического анализа
Как мы уже выяснили, чем бы вы ни планировали заниматься, вероятность столкнуться с курсом «математическая статистика в вашей области» постепенно приближается к единице. Однако, часто занятия по введению в статистику не вызывают восторга у студентов нетехнических факультетов. Через несколько занятий выясняется, что такие базовые понятия, как, например, корреляция представляют собой нечто следующее:
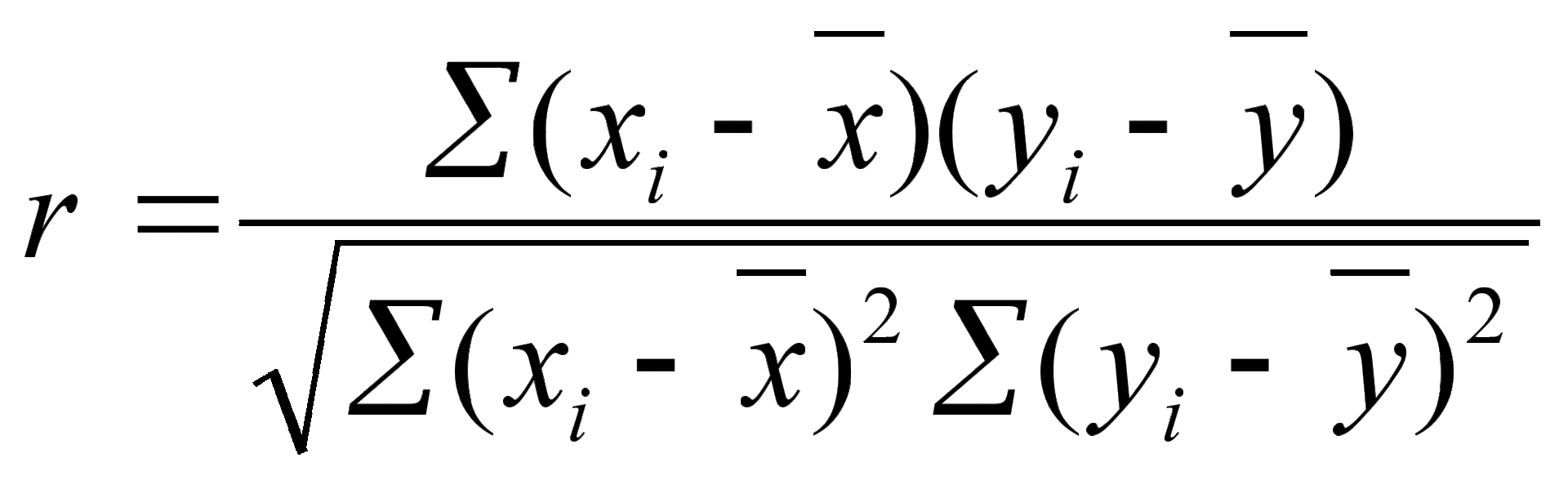
И, отчаявшись досконально разобраться с происхождением этих сумм и квадратных корней, студент может начать воспринимать статистику следующим образом: «если r > 0, то положительная связь, а если меньше 0, то отрицательная»; «если p уровень значимости меньше 0.05 — то хорошо, если от 0.05 до 0.1 — то не очень хорошо, а если больше 0.1 — то плохо». Помогая студентам готовиться к экзамену, не раз сталкивался с такими заклинаниями! Также, разумеется, никто не рассчитывает все эти показатели вручную, и используя, например, SPSS, можно за секунду загуглить пошаговую инструкцию «как сравнить два средних».
- Жмем сюда
- Снимаем/ставим галочки тут
- p < 0.05 —> profit
Статистический анализ начинает напоминать черный ящик: на вход подаются данные, на выход — таблица основных результатов и значение p-уровня значимости (p-value), который и расставит все точки над i.
О чем нам, собственно, говорит p-value?
Предположим, мы решили выяснить, существует ли взаимосвязь между пристрастием к кровавым компьютерным играм и агрессивностью в реальной жизни. Для этого были случайным образом сформированы две группы школьников по 100 человек в каждой (1 группа — фанаты стрелялок, вторая группа — не играющие в компьютерные игры). В качестве показателя агрессивности выступает, например, число драк со сверстниками. В нашем воображаемом исследовании оказалось, что группа школьников-игроманов действительно заметно чаще конфликтует с товарищами. Но как нам выяснить, насколько статистически достоверны полученные различия? Может быть, мы получили наблюдаемую разницу совершенно случайно? Для ответа на эти вопросы и используется значение p-уровня значимости (p-value) — это вероятность получить такие или более выраженные различия при условии, что в генеральной совокупности никаких различий на самом деле нет. Иными словами, это вероятность получить такие или еще более сильные различия между нашими группами, при условии, что, на самом деле, компьютерные игры никак не влияют на агрессивность. Звучит не так уж и сложно. Однако, именно этот статистический показатель очень часто интерпретируется неправильно.
А теперь несколько примеров про p-value

Итак, мы сравнили две группы школьников между собой по уровню агрессивности при помощи стандартного t-теста (или непараметрического критерия Хи — квадрат более уместного в данной ситуации) и получили, что заветный p-уровень значимости меньше 0.05 (например 0.04). Но о чем в действительности говорит нам полученное значение p-уровня значимости? Итак, если p-value — это вероятность получить такие или более выраженные различия при условии, что в генеральной совокупности никаких различий на самом деле нет, то какое, на ваш взгляд, верноеутверждение:
- Компьютерные игры — причина агрессивного поведения с вероятностью 96%.
- Вероятность того, что агрессивность и компьютерные игры не связаны, равна 0.04.
- Если бы мы получили p-уровень значимости больше, чем 0.05, это означало бы, что агрессивность и компьютерные игры никак не связаны между собой.
- Вероятность случайно получить такие различия равняется 0.04.
- Все утверждения неверны.
Если вы выбрали пятый вариант, то абсолютно правы! Но, как показывают многочисленные исследования, даже люди со значительным опытом в анализе данных часто некорректно интерпретируют значение p-value (например, можно посмотреть эту интересную статью).
Давайте разберем все ответы по порядку:
- Первое утверждение — пример ошибки корреляции: факт значимой взаимосвязи двух переменных ничего не говорит нам о причинах и следствиях. Может быть, это более агрессивные люди предпочитают проводить время за компьютерными играми, а вовсе не компьютерные игры делают людей агрессивнее.
- Это уже более интересное утверждение. Все дело в том, что мы изначально принимаем за данное, что никаких различий на самом деле нет. И, держа это в уме как факт, рассчитываем значение p-value. Поэтому правильная интерпретация: «Если предположить, что агрессивность и компьютерные игры никак не связаны, то вероятность получить такие или еще более выраженные различия составила 0.04».
- А что делать, если мы получили незначимые различия? Значит ли это, что никакой связи между исследуемыми переменными нет? Нет, это означает лишь то, что различия, может быть, и есть, но наши результаты не позволили их обнаружить.
- Это напрямую связано с самим определением p-value. 0.04 — это вероятность получить такие или еще более экстремальные различия. Оценить вероятность получить именно такие различия, как в нашем эксперименте, в принципе невозможно!
Вот такие подводные камни могут скрываться в интерпретации такого показателя, как p-value. Поэтому очень важно понимать механизмы, заложенные в основании методов анализа и расчета основных статистических показателей.
Онлайн-курс по основам статистики: сложные формулы несложным языком
Сейчас я пишу диссертацию на факультете психологии СПбГУ и преподаю статистику биологам в Институте биоинформатики. Основываясь на курсе читаемых лекций и собственного исследовательского опыта, возникла идея создать онлайн-курс по введению в статистику на русском языке для всех желающих, необязательно биоинформатиков или биологов.
Существует много хороших онлайн-курсов по анализу данных и статистике (например, такой, такой, или такой), но практически все они на английском языке. Надеюсь, что курс будет полезен для тех, кто только знакомится с основами статистики. В нем я стараюсь в максимально доступной форме разобрать основные идеи и методы анализа данных, уделяя особое внимание самой идее статистической проверки гипотез и интерпретации получаемых результатов. В качестве примеров будут задачи из различных областей: от биоинформатики до социологии. Курс бесплатный и все его материалы останутся открытыми после окончания, начинается 15 февраля.
Полезные материалы
Если вы знаете какие-либо полезные курсы или материалы по введению в статистику — делитесь в комментариях!