Приветствую Вас на сайте Info-Comp.ru! Сегодня мы с Вами подробно рассмотрим функционал одного очень популярного инструмента для работы с Microsoft SQL Server — графической среды SQL Server Management Studio (SSMS).

Заметка! Обзор инструментов для работы с Microsoft SQL Server.
Содержание
- Что такое SQL Server Management Studio
- Основной функционал SQL Server Management Studio
- Подключение к службам SQL Server
- Обозреватель объектов
- Обозреватель шаблонов
- Редактор SQL кода
- Просмотр плана выполнения запроса
- Обозреватель решений
- Конструктор таблиц
- Конструктор баз данных (Диаграммы баз данных)
- Конструктор запросов и представлений
- Просмотр свойств объектов
- Мастер создания скриптов
- Управление безопасностью SQL Server
- Присоединение и отсоединение баз данных
- Создание резервных копий баз данных и восстановление баз данных из архива
- Создание связанных серверов (Linked Server)
- Монитор активности SQL Server
- Настройка репликации баз данных
- Профилировщик XEvent
SQL Server Management Studio (SSMS) – это бесплатная графическая среда, включающая набор инструментов для разработки сценариев на T-SQL и управления инфраструктурой Microsoft SQL Server.
Среда SQL Server Management Studio – это основной, стандартный и полнофункциональный инструмент для работы с Microsoft SQL Server, разработанный компанией Microsoft, который предназначен как для разработчиков, так и для администраторов SQL Server.
С помощью SSMS Вы можете разрабатывать базы данных, выполнять инструкции T-SQL, а также администрировать Microsoft SQL Server.
Если в Ваши задачи входит полное сопровождение Microsoft SQL Server, начиная от создания баз данных, написания SQL запросов, создания хранимых процедур и функций, и заканчивая администрированием SQL Server, включая управление безопасностью, то основным Вашим инструментом будет как раз среда SQL Server Management Studio.
Среда SQL Server Management Studio реализована только под Windows, поэтому если Вам нужен инструмент для работы с Microsoft SQL Server, который будет работать на других платформах, например, на Linux или macOS, то Вам следует использовать инструмент Azure Data Studio, который также является официальным инструментом, разработанным компанией Microsoft.
Заметка! Сравнение Azure Data Studio с SQL Server Management Studio (SSMS).
Основной функционал SQL Server Management Studio
Теперь давайте рассмотрим функционал и возможности среды SQL Server Management Studio, иными словами, какие именно действия и операции мы можем выполнять, используя данный инструмент.
Сначала давайте посмотрим на общий перечень возможностей, которые нам предоставляет среда SQL Server Management Studio, а затем более подробно рассмотрим каждый пункт из этого перечня.
Подключение к службам SQL Server
Обозреватель объектов
Обозреватель шаблонов
Редактор SQL кода
Просмотр плана выполнения запроса
Обозреватель решений
Конструктор таблиц
Конструктор баз данных (Диаграммы баз данных)
Конструктор запросов и представлений
Просмотр свойств объектов
Мастер создания скриптов
Управление безопасностью SQL Server
Присоединение и отсоединение баз данных
Создание резервных копий баз данных и восстановление баз данных из архива
Создание связанных серверов (Linked Server)
Монитор активности SQL Server
Настройка репликации баз данных
Профилировщик XEvent
Заметка! Список и расшифровка версий Microsoft SQL Server.
Подключение к службам SQL Server
С помощью SQL Server Management Studio мы можем подключаться не только к ядру СУБД, но и к другим компонентам SQL Server, например, к службам Analysis Services (SSAS), Integration Services (SSIS) и Reporting Services (SSRS).
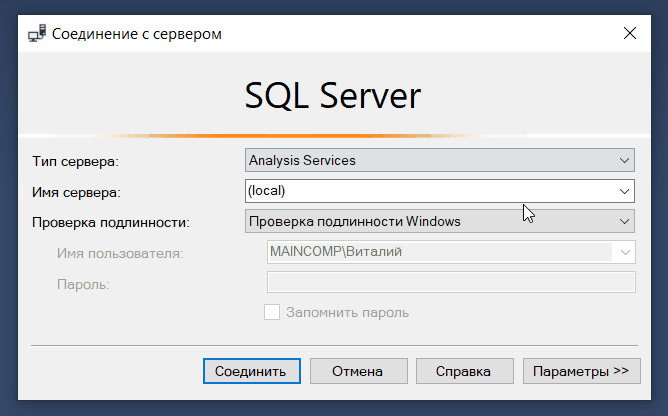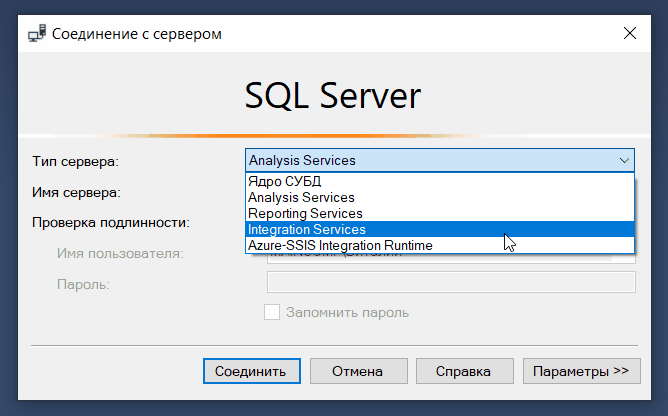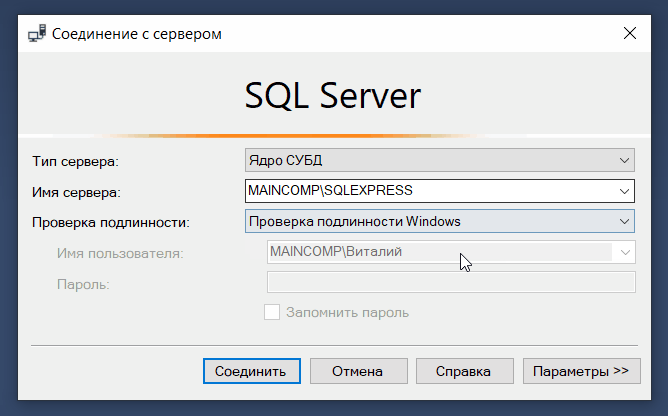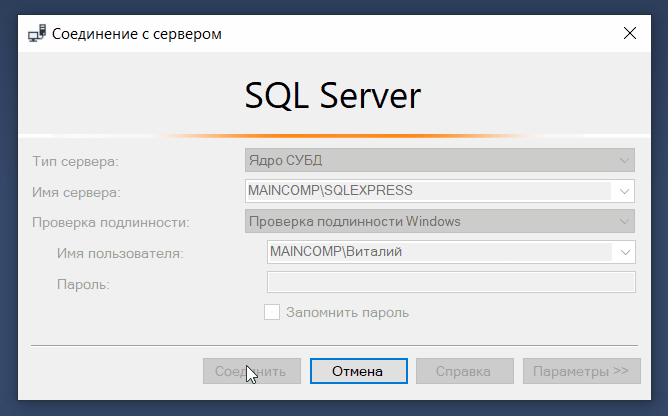
Таким образом, мы можем управлять объектами служб Analysis Services, например, выполнять их резервное копирование и обработку, создавать скрипты для служб Analysis Services и выполнять другие операции.
Также используя Management Studio мы можем управлять пакетами SSIS, например, выполнять импорт и экспорт пакетов.
Кроме этого SSMS позволяет администрировать службы Reporting Services, т.е. управлять ролями, заданиями и так далее.
Заметка! Не удается подключиться к Microsoft SQL Server по сети.
Обозреватель объектов
Обозреватель объектов среды SQL Server Management Studio – это графический пользовательский интерфейс для просмотра и управления объектами в каждом экземпляре SQL Server.
Обозреватель объектов Management Studio предоставляет интерфейс, в котором структура объектов сервера представлена в очень удобном иерархическом виде, напоминает что-то вроде файловой системы Windows, т.е. папки, подпапки, файлы и т.д.
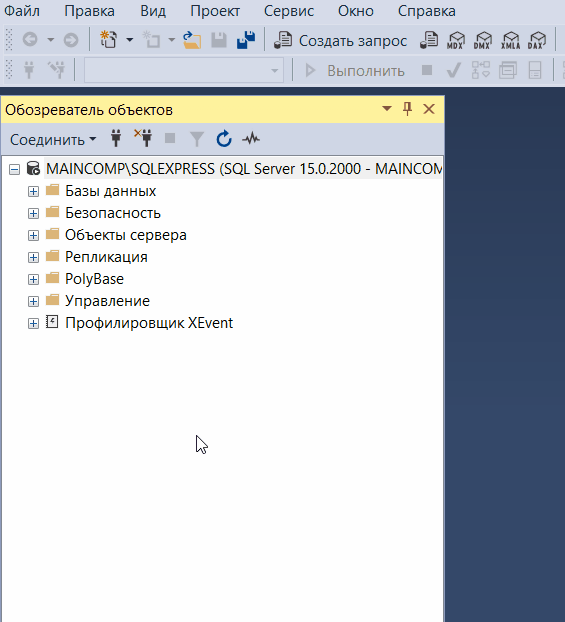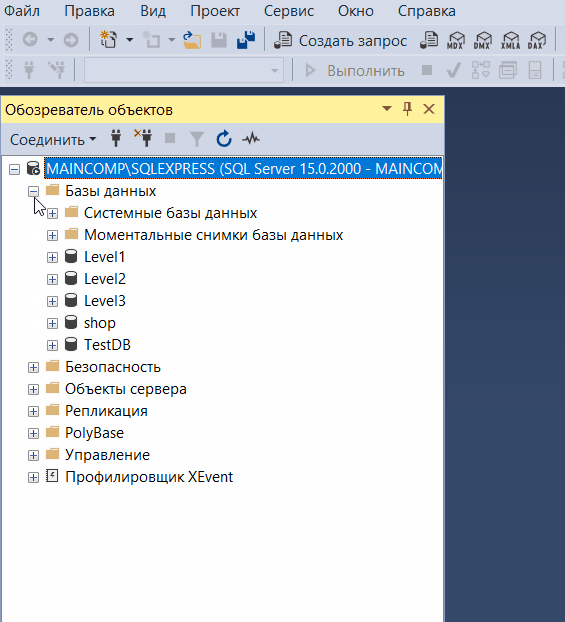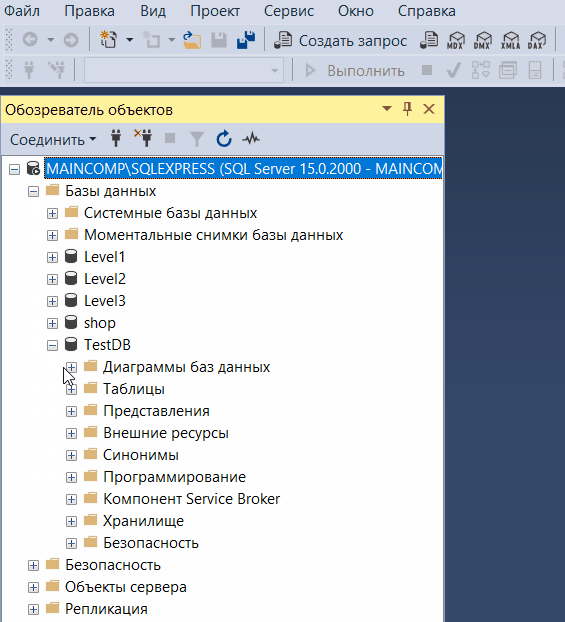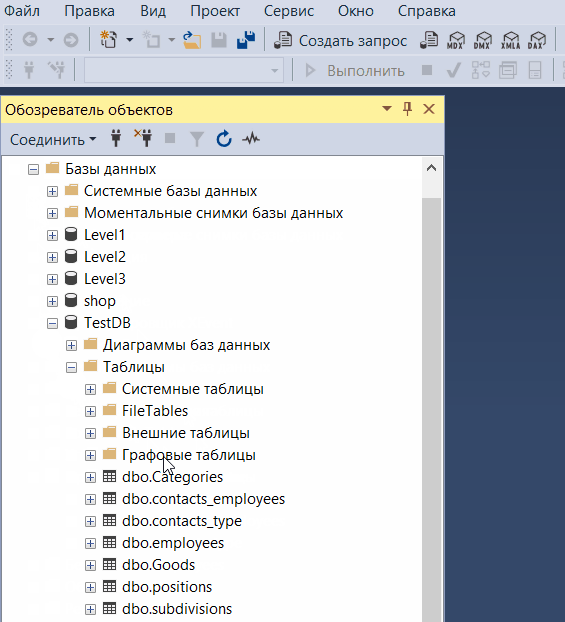
В случае если «Обозреватель объектов» скрыт или Вы его случайно закрыли, то для того, чтобы его отобразить, можно использовать меню «Вид -> Обозреватель объектов», хотя по умолчанию он отображен, так как это, наверное, основной компонент среды SQL Server Management Studio.
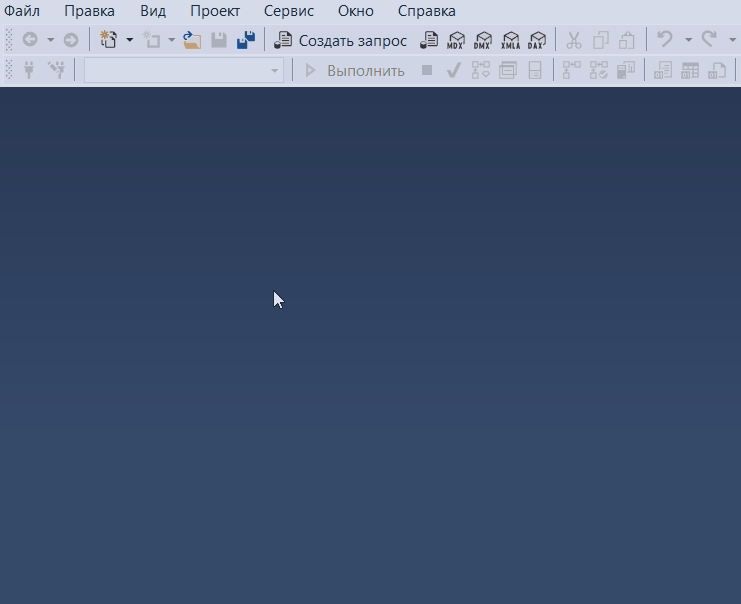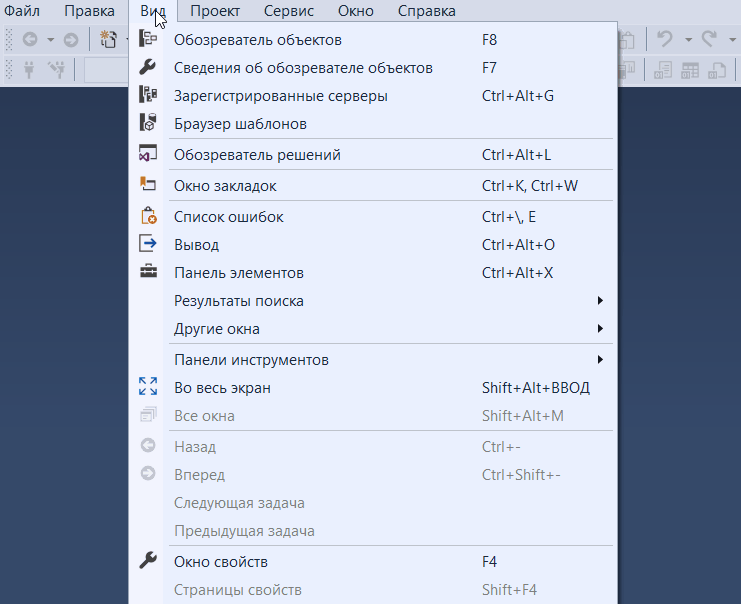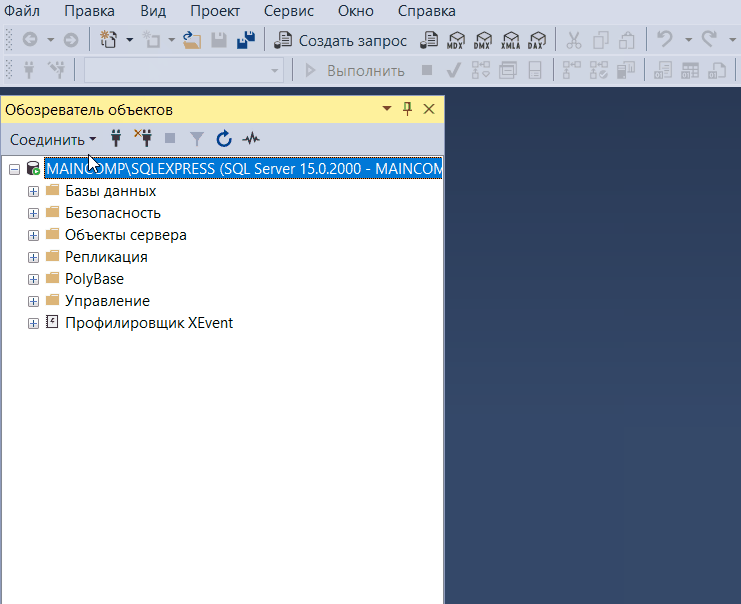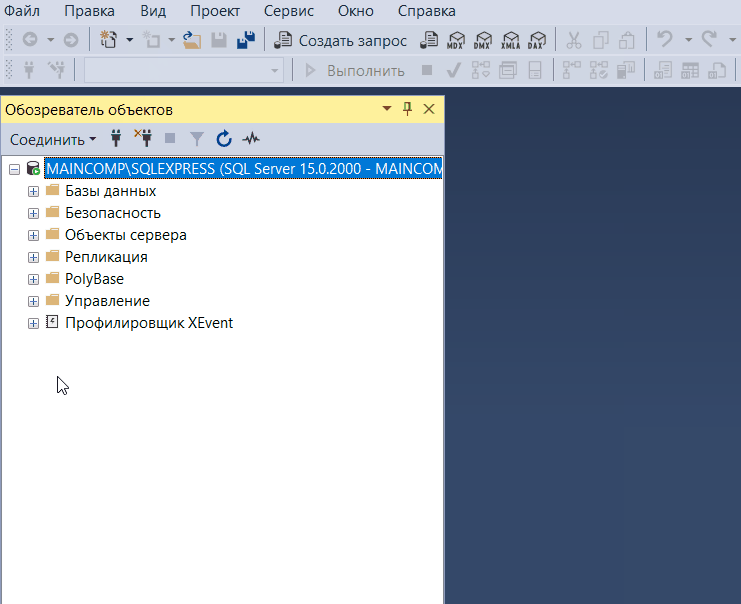
Таким образом, с помощью обозревателя объектов мы легко можем посмотреть, какие базы данных, таблицы, функции, хранимые процедуры и другие объекты есть на SQL Server, включая пользователей, связанные серверы и так далее.
Заметка! Чем отличаются функции от хранимых процедур в Microsoft SQL Server.
Обозреватель шаблонов
Шаблоны в SQL Server Management Studio – это файлы, содержащие стандартный SQL код, который предназначен для создания объектов на SQL Server.
Иными словами, это готовые SQL скрипты, содержащие заголовки SQL инструкций, в которые всего лишь необходимо подставить свои данные, например, имена объектов, чтобы создать тот или иной объект на SQL Server.
Обозреватель шаблонов Management Studio позволяет просматривать и использовать доступные шаблоны.
Открыть «Обозреватель шаблонов» можно из меню «Вид -> Браузер шаблонов».
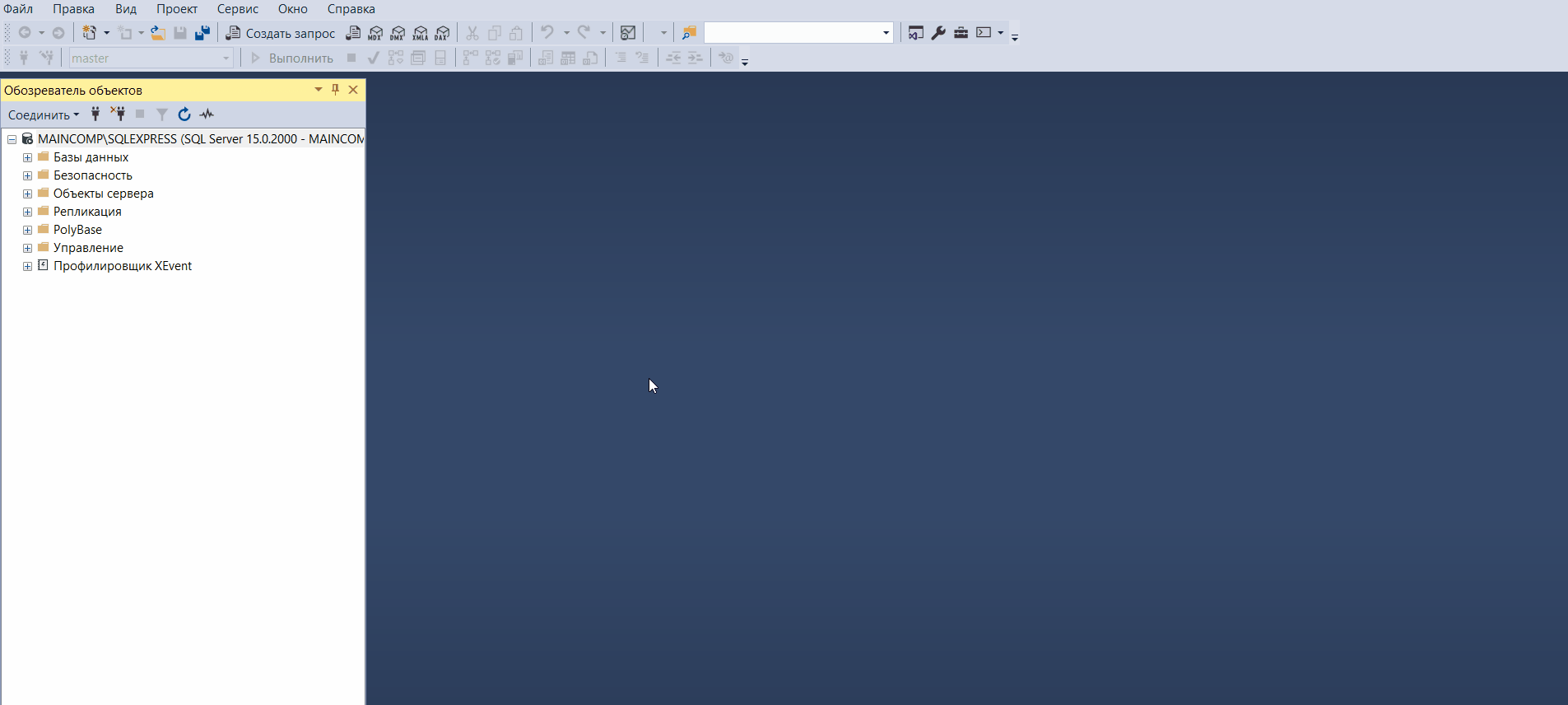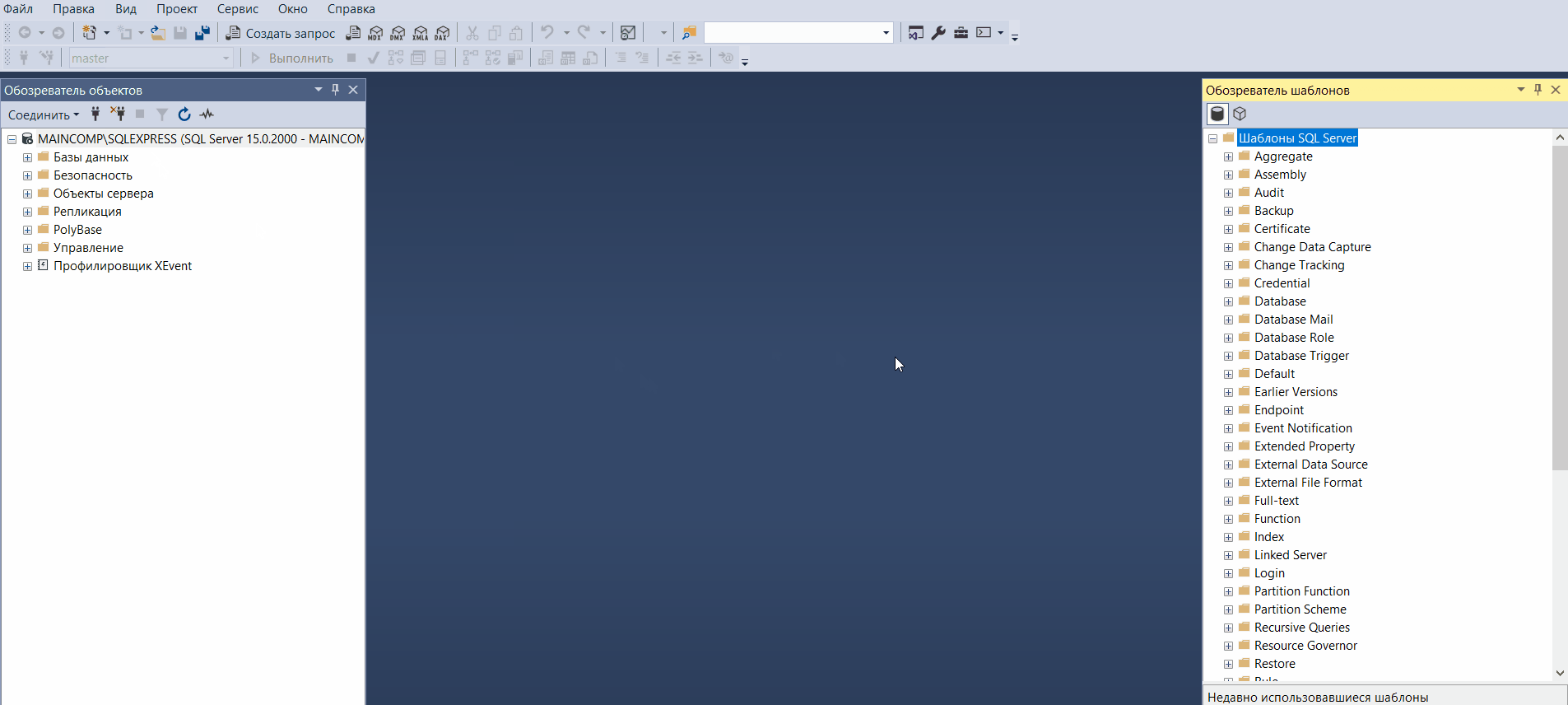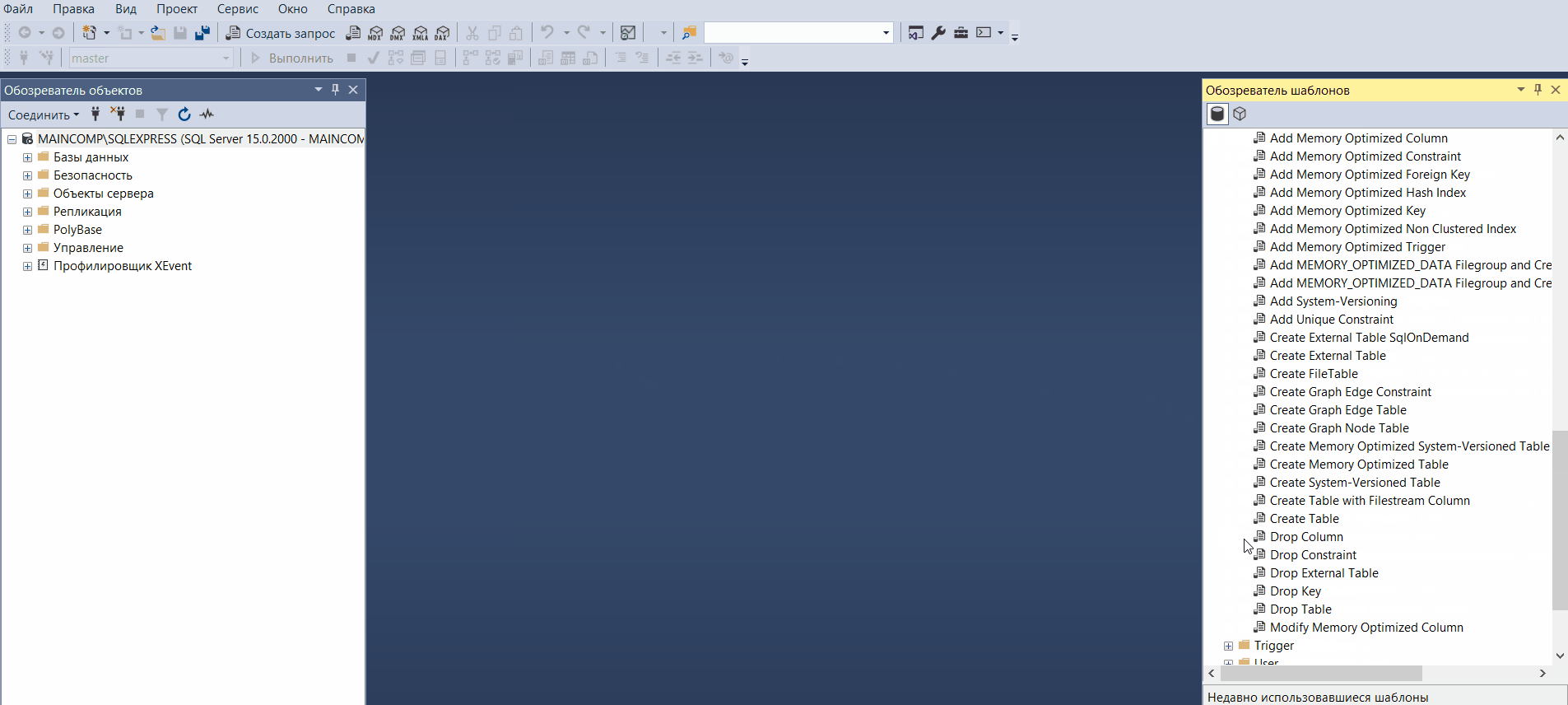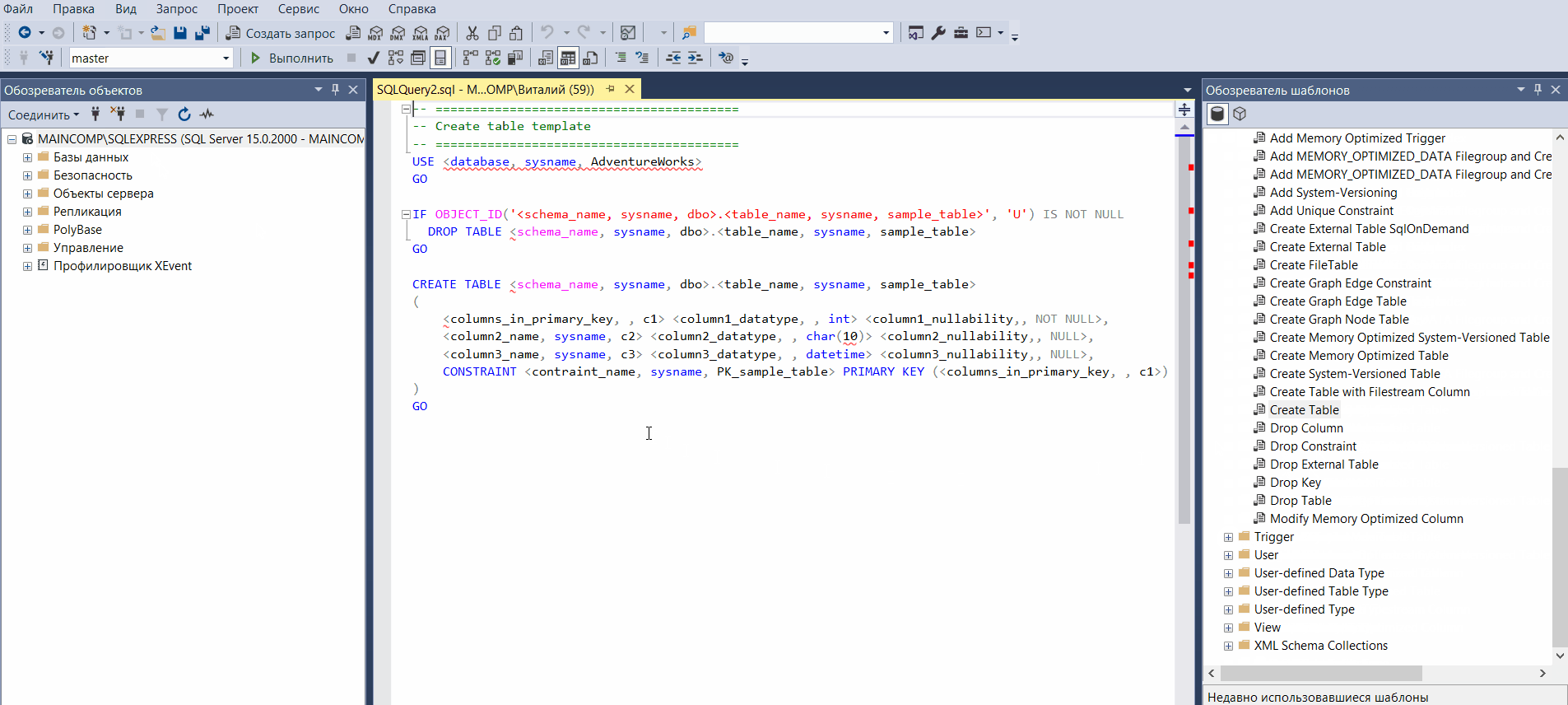
Таким образом, мы можем использовать шаблоны для создания или изменения таких объектов как:
- Базы данных
- Таблицы
- Представления
- Индексы
- Функции
- Хранимые процедуры
- Триггеры
- И другие объекты SQL Server
Кроме этого, для часто выполняемых задач мы можем создать свои собственные пользовательские шаблоны, для случаев когда нет подходящего встроенного шаблона, и тем самым упростить и ускорить выполнение таких задач.
Редактор SQL кода
Основное назначение среды SQL Server Management Studio – это, конечно же, разработка, выполнение и отладка кода на T-SQL, иными словами, написание и выполнение SQL запросов и инструкций. Поэтому SSMS обладает современным и продвинутым редактором SQL кода, который поддерживает технологию IntelliSense, т.е. автодополнение, например, Вы начинаете писать первые буквы объекта, а редактор сам дописывает его, точнее, показывает возможные варианты окончания.
Кроме этого у редактора есть подсветка синтаксиса и другие полезные возможности.
Заметка! Как включить нумерацию строк кода в SQL Server Management Studio.
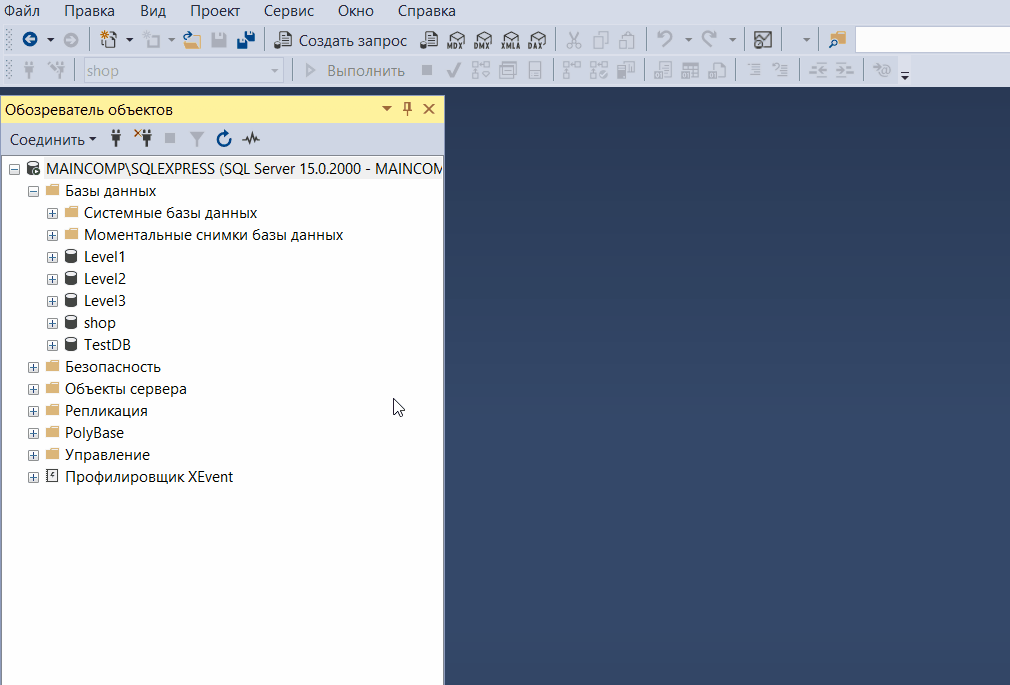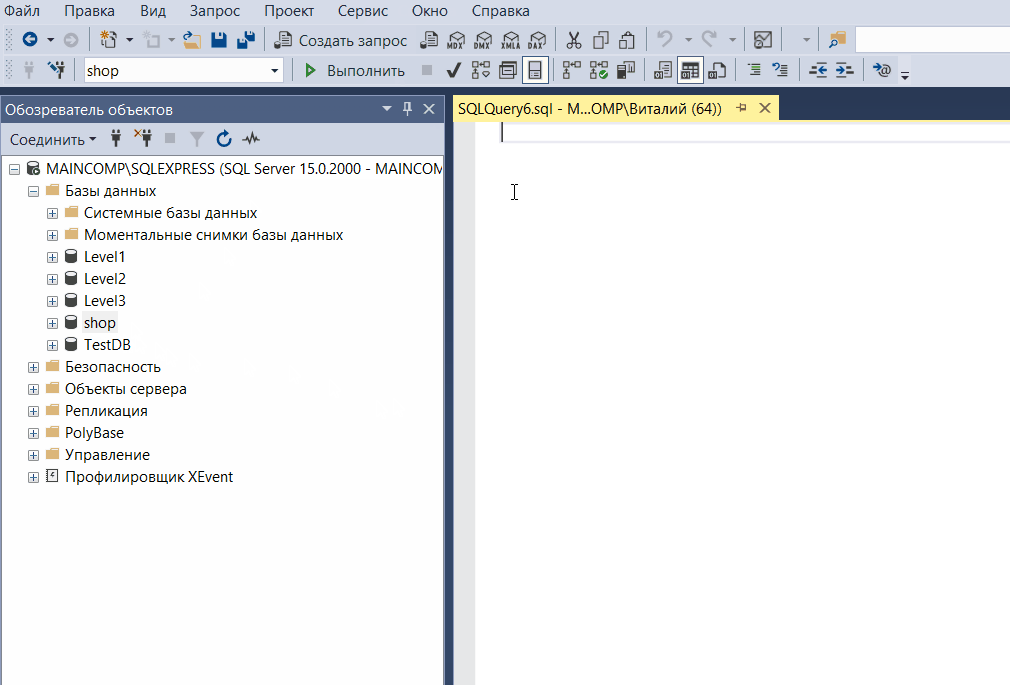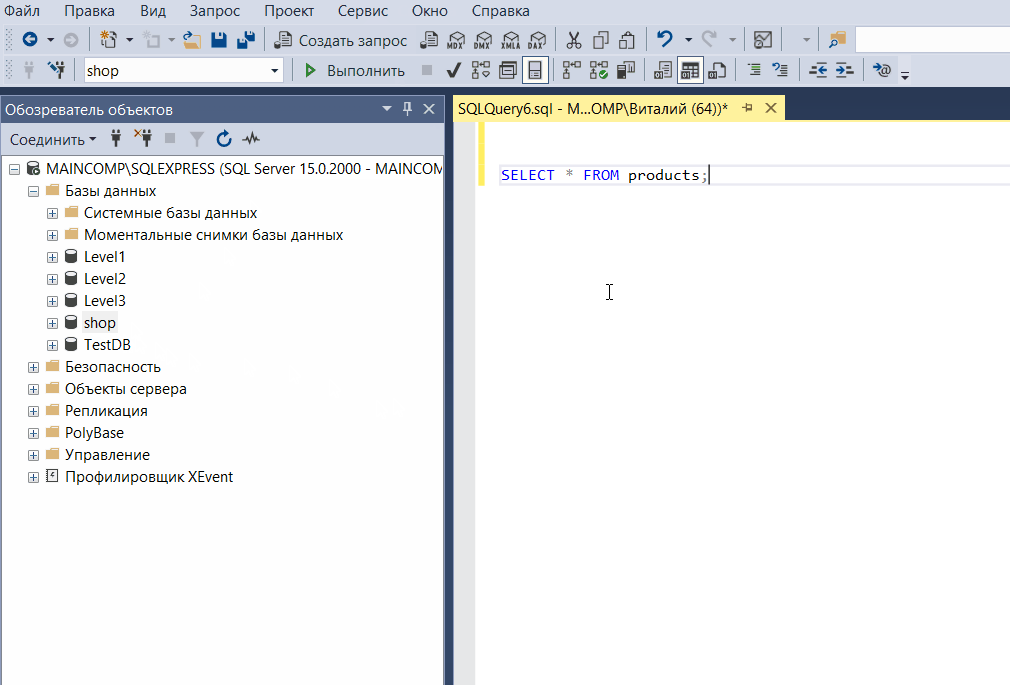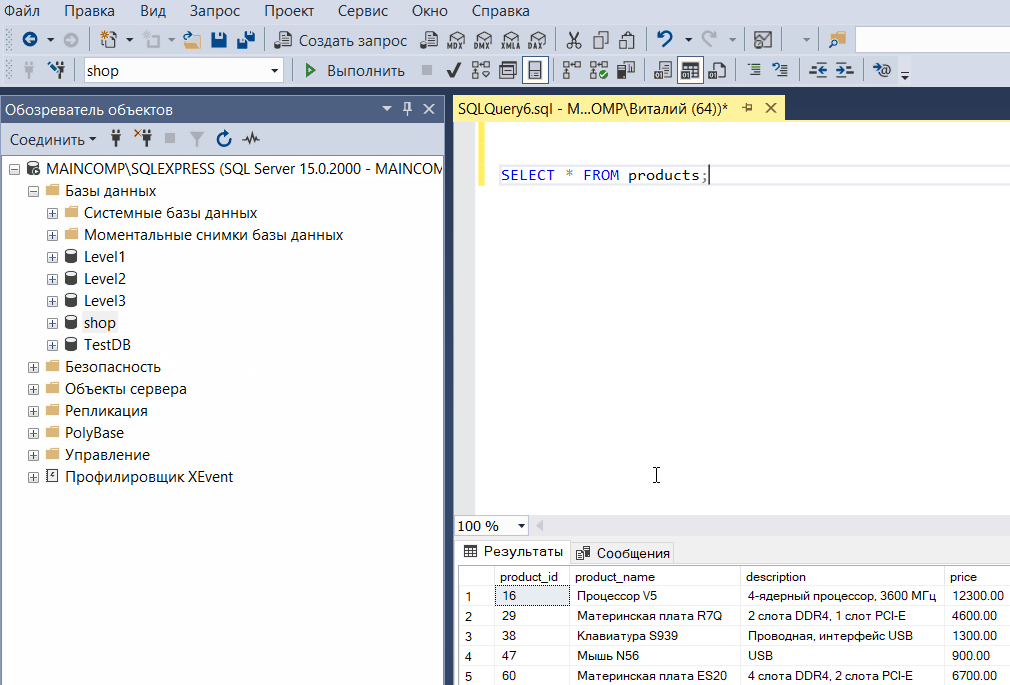
Чтобы открыть редактор SQL кода в среде Management Studio, необходимо на панели инструментов нажать на кнопку «Создать запрос». Именно здесь пишутся и выполняются все SQL запросы и инструкции к базам данных.
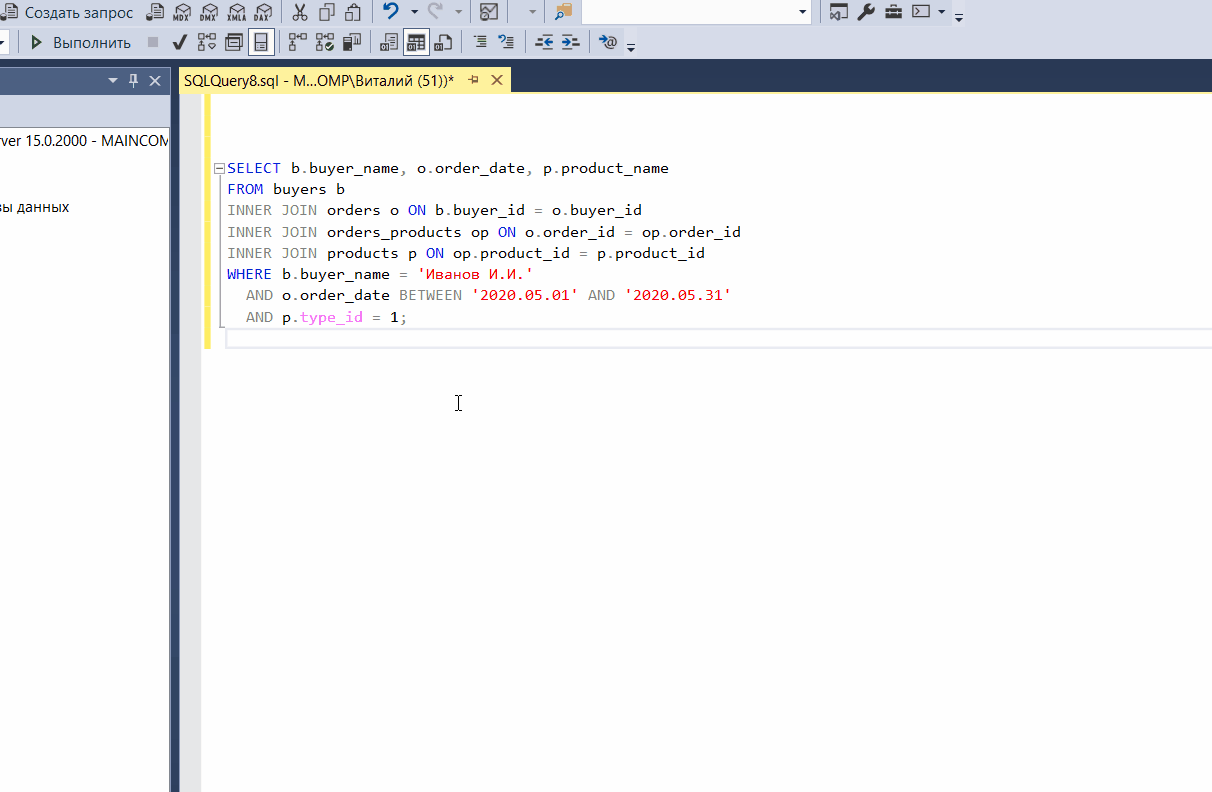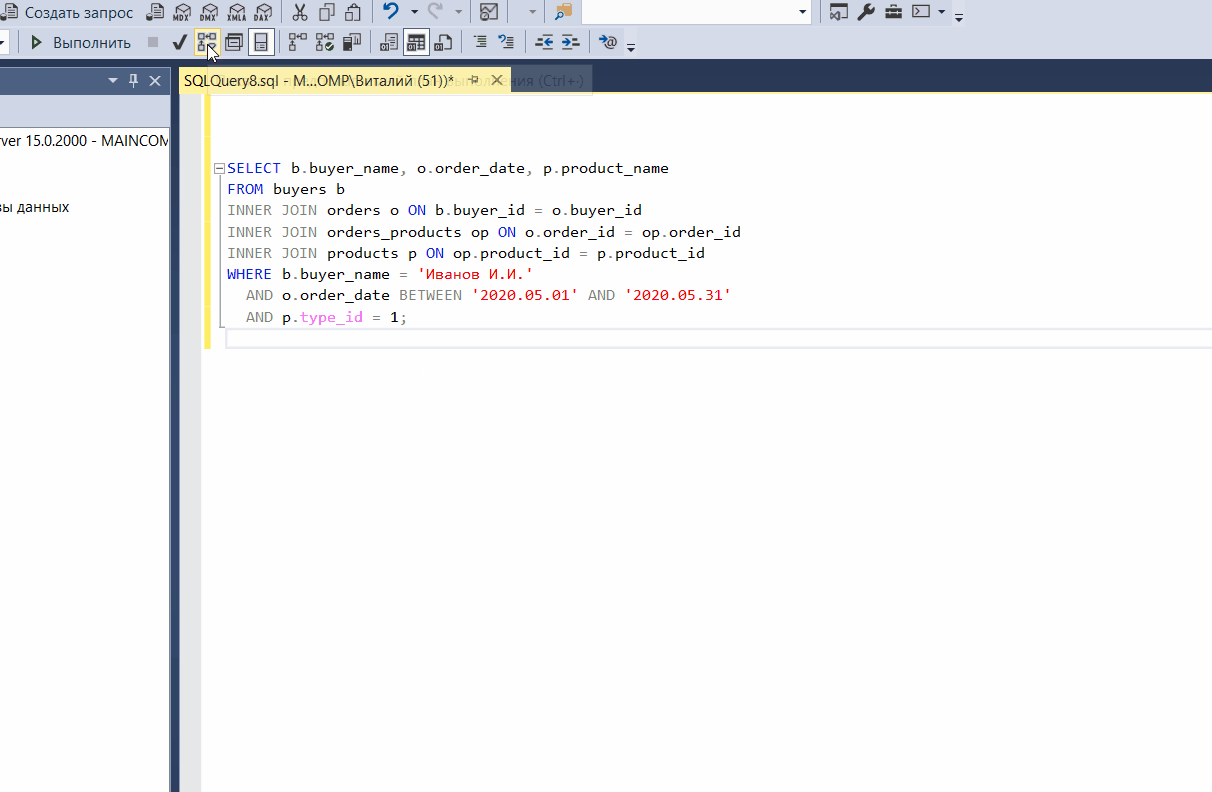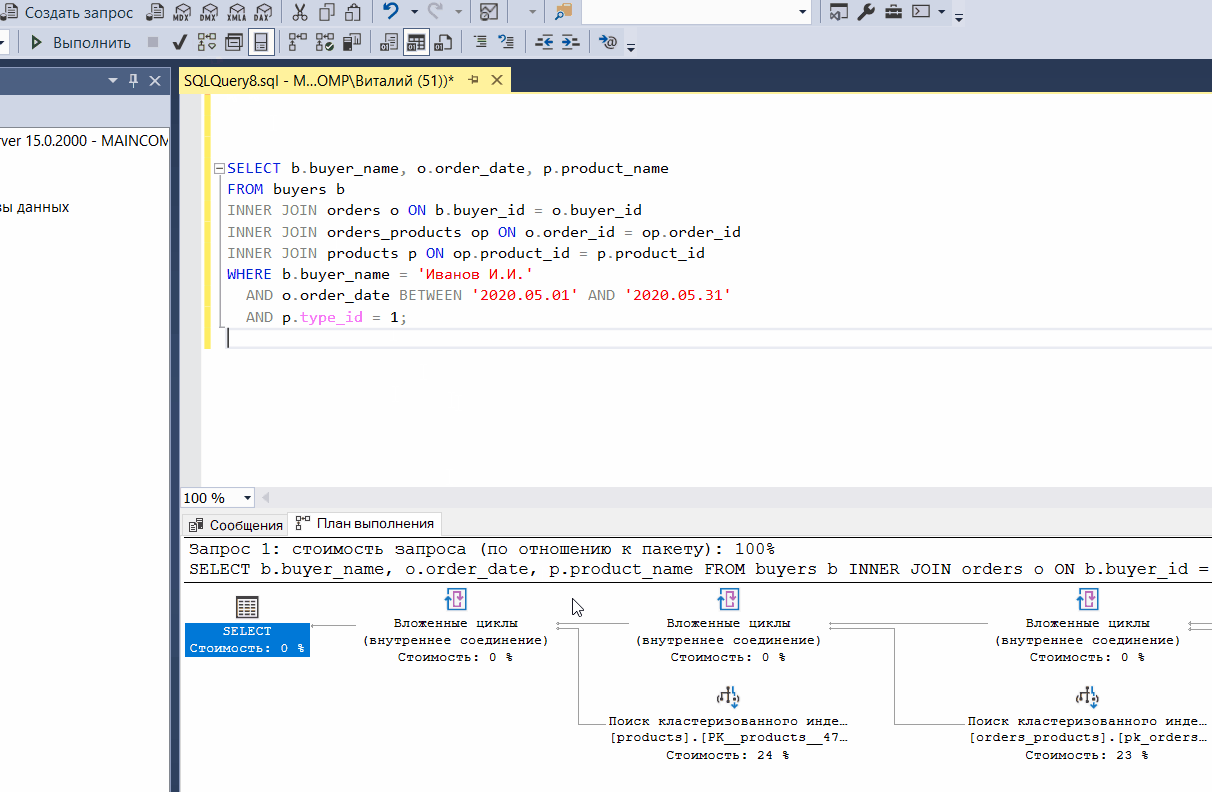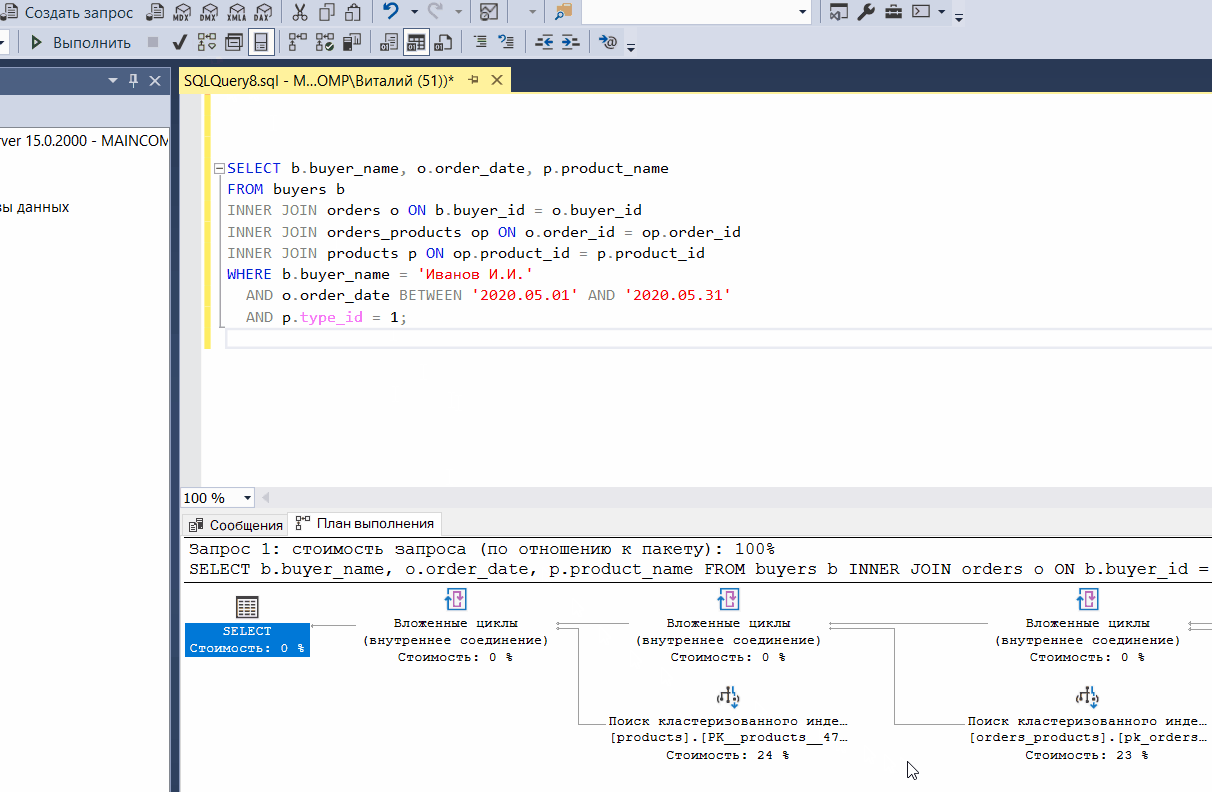
Просмотр плана выполнения запроса
План выполнения запроса – это последовательность операций, выполняемых внутри SQL Server, которые необходимы для получения результата SQL запроса.
Прежде чем выполнить SQL запрос SQL Server должен проанализировать инструкции и определить наиболее эффективный способ доступа к данным.
Этот анализ выполняется компонентом, который называется «Оптимизатор запросов». Входные данные оптимизатора запросов как раз и являются планом выполнения запроса.
SQL Server Management Studio позволяет просматривать план выполнения запроса и тем самым выявлять наиболее ресурсоемкие операции в запросе с целью оптимизации скорости выполнения этого запроса.
Чтобы показать план выполнения запроса, необходимо на панели нажать на иконку «Показать предлагаемый план выполнения».
Заметка! Visual Studio Code (VS Code) для разработки на Transact-SQL.
Обозреватель решений
Решение в SQL Server Management Studio – это набор из одного или нескольких взаимосвязанных проектов.
Проекты в SQL Server Management Studio – это контейнеры для организации взаимосвязанных файлов, например, файлов с SQL инструкциями, которые используются при разработке того или иного функционала в базах данных.
Обозреватель решений в Management Studio создан как раз для того, чтобы управлять всеми решениями и проектами.
Открыть «Обозреватель решений» можно из меню «Вид -> Обозреватель решений».
Таким образом, с помощью «Обозревателя решений» мы можем все свои SQL скрипты сгруппировать в проект, тем самым систематизировать все файлы и иметь к ним более удобный доступ.
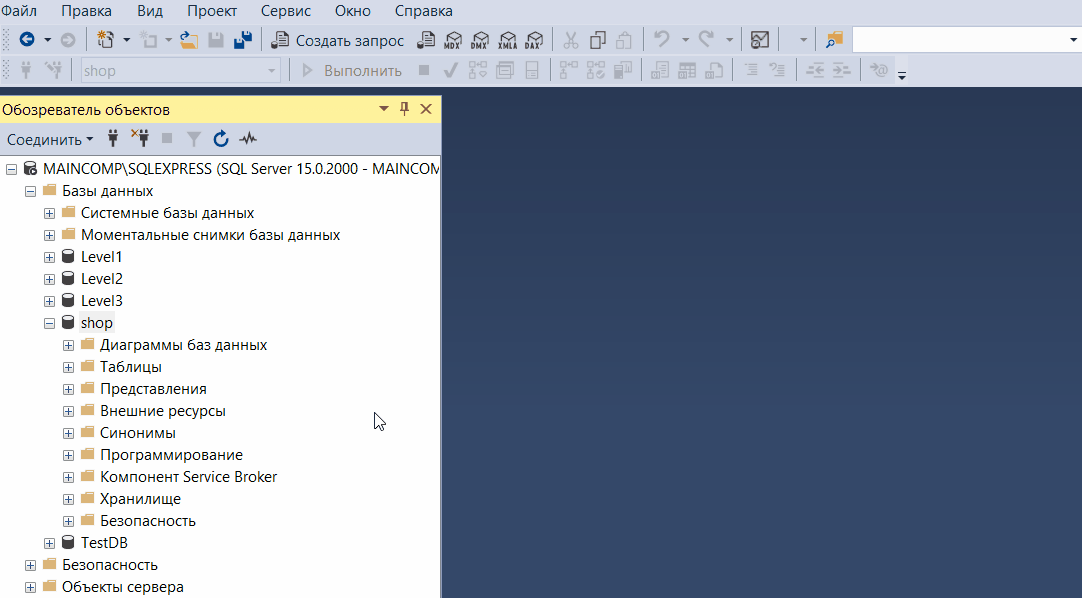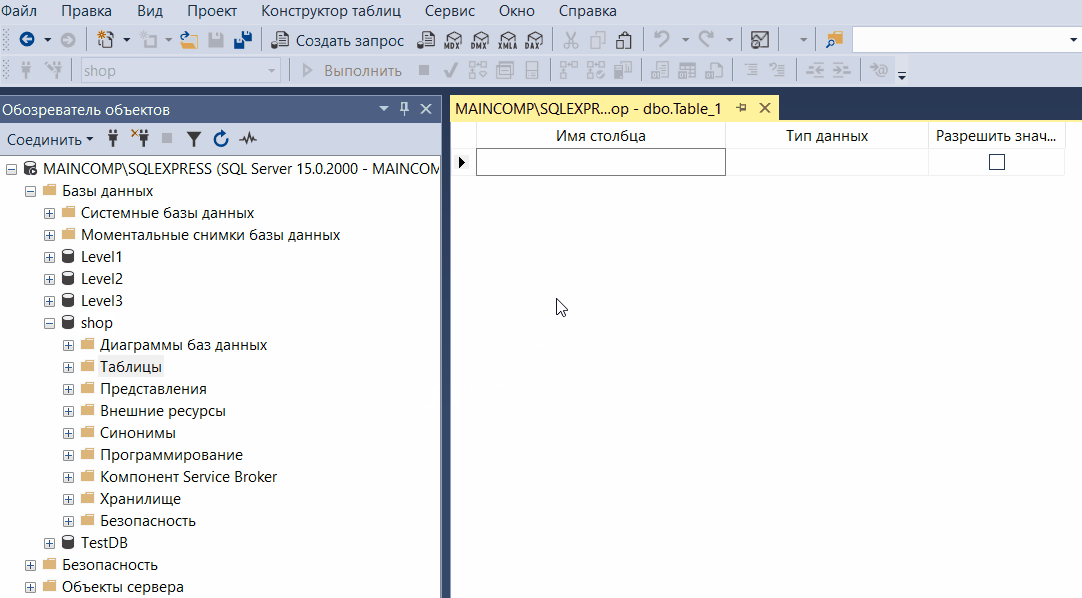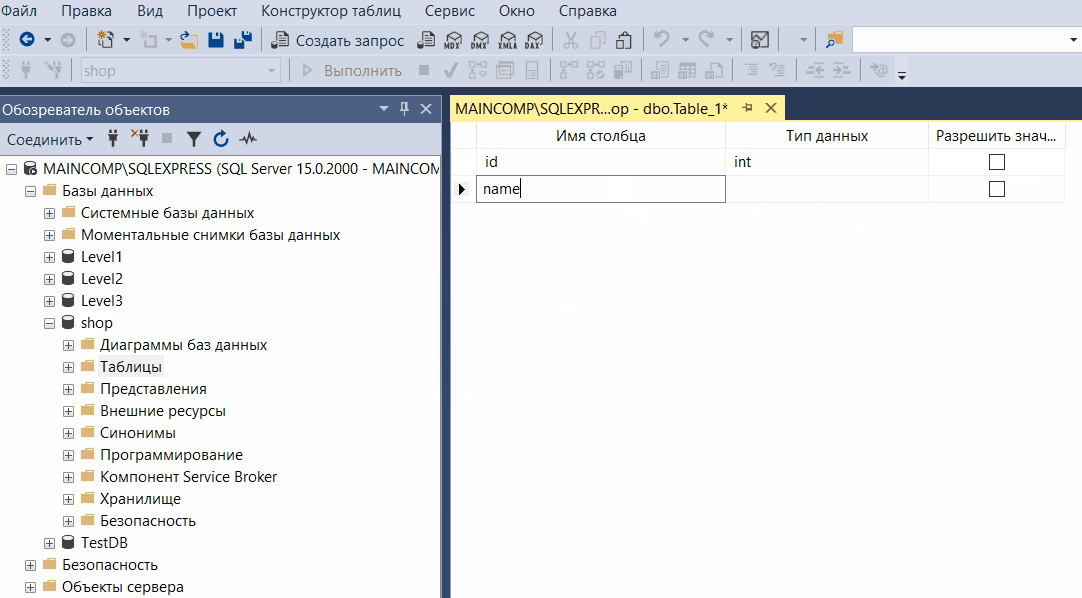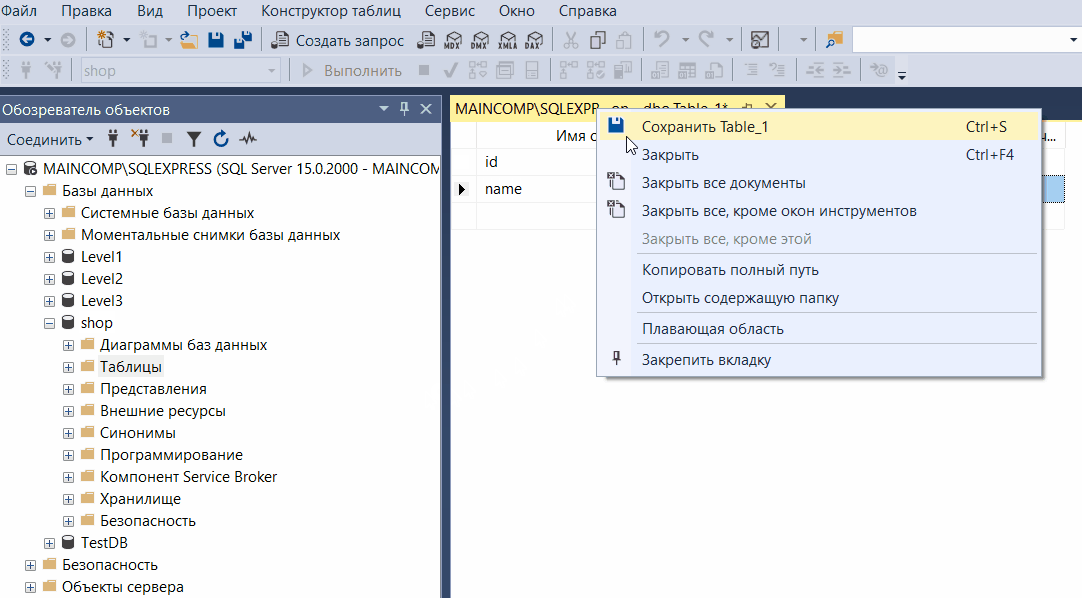
Конструктор таблиц
Конструктор таблиц – это визуальный инструмент для разработки таблиц в базах данных.
С помощью конструктора таблиц SQL Server Management Studio можно создавать, редактировать и удалять:

- Таблицы
- Столбцы
- Ключи
- Индексы
- Связи
- Ограничения
Чтобы запустить «Конструктор таблиц», необходимо щелкнуть правой кнопкой мыши по контейнеру «Таблицы» в обозревателе объектов, и выбрать пункт «Создать -> Таблица».
Таким образом, благодаря функционалу конструктора таблиц мы может создавать и редактировать таблицы базы данных, при этом даже не используя язык SQL.
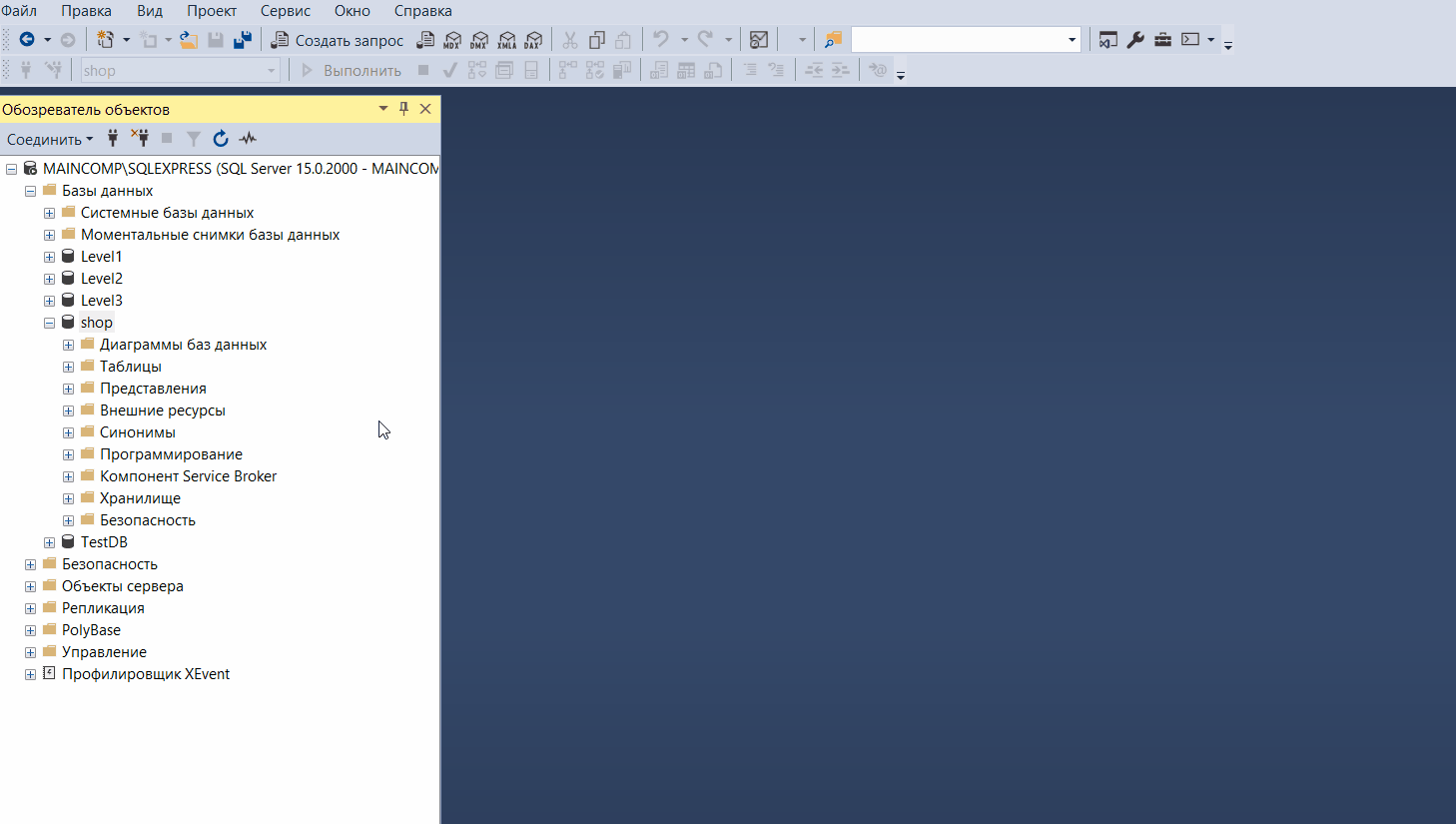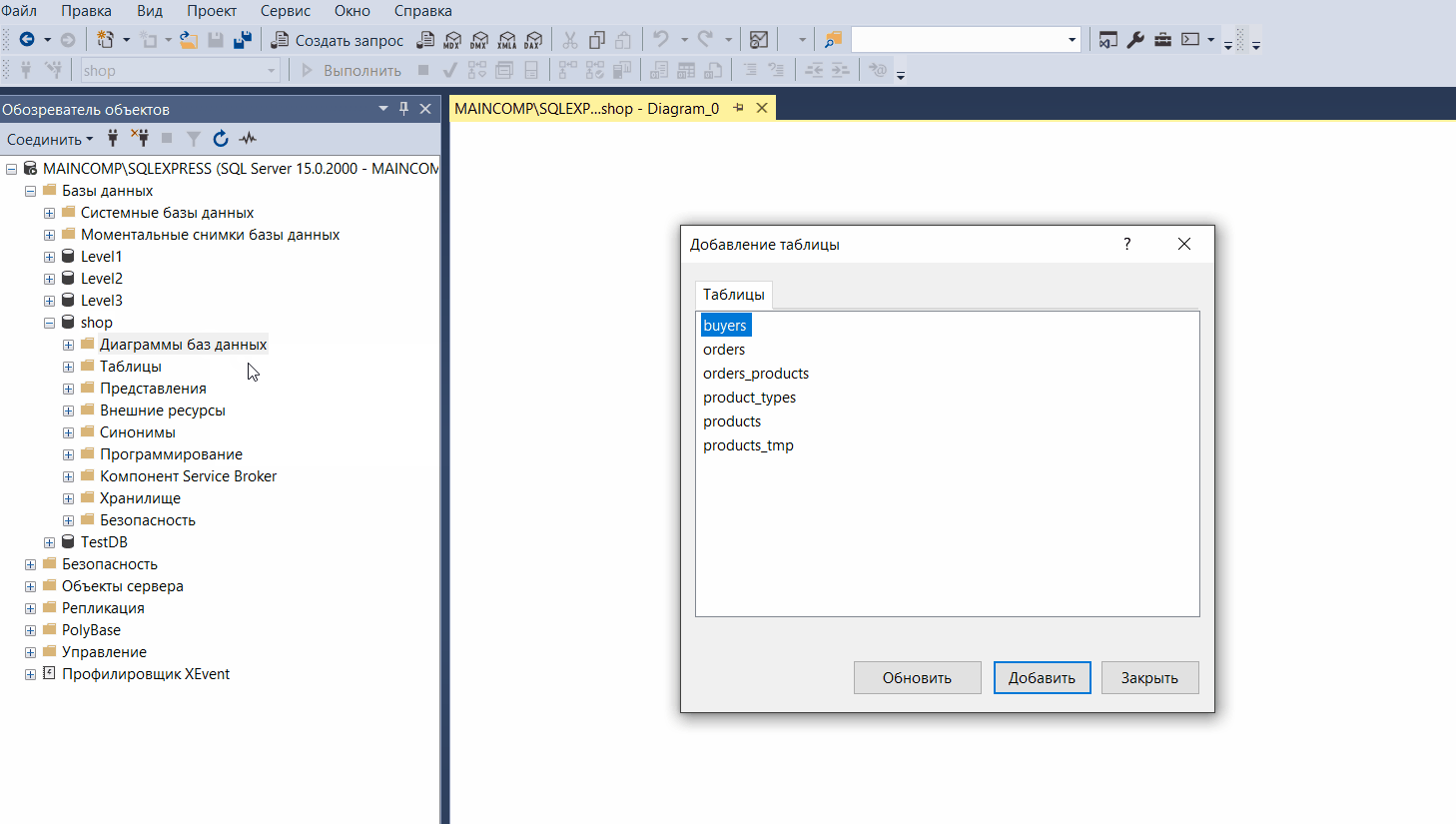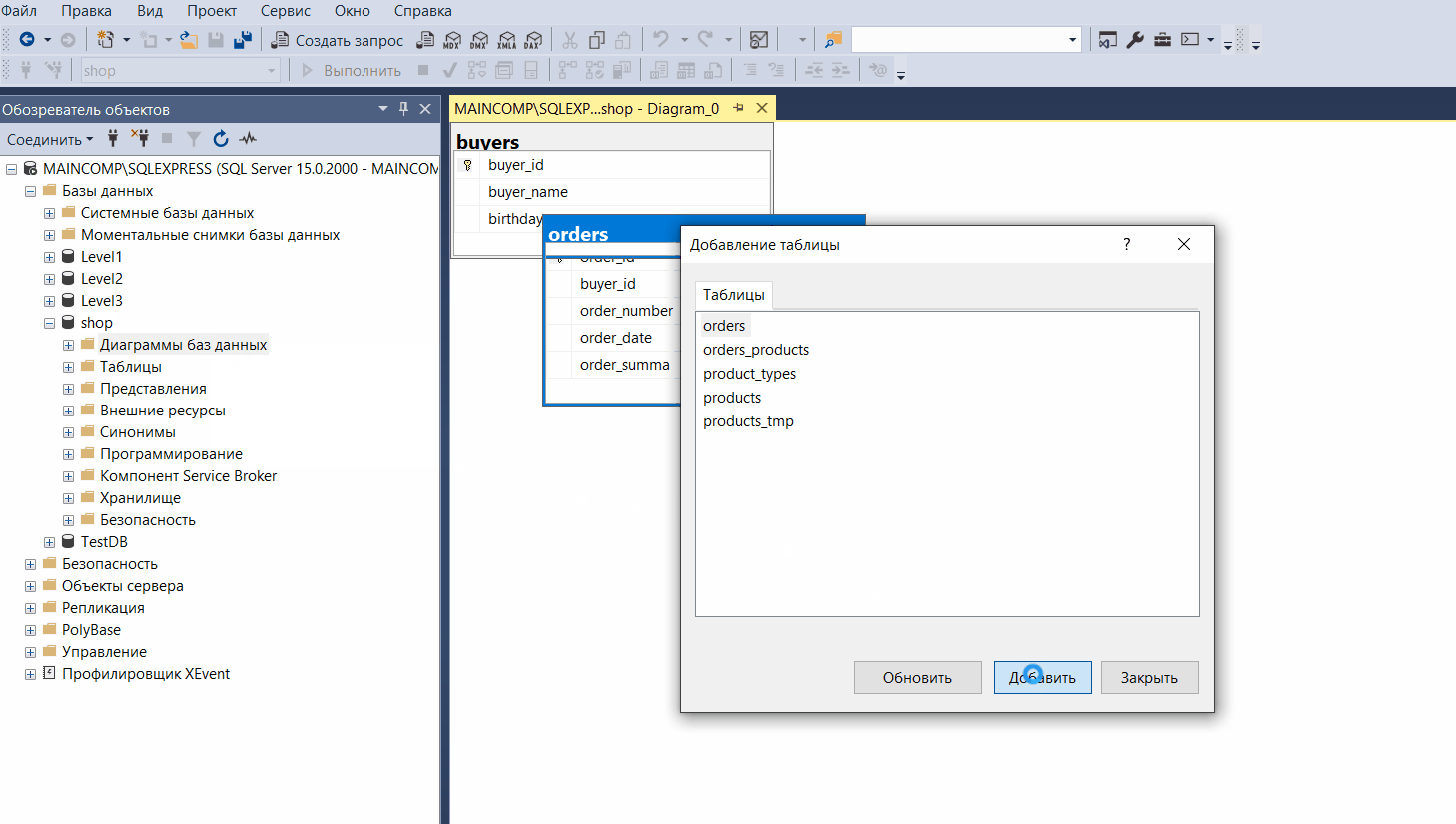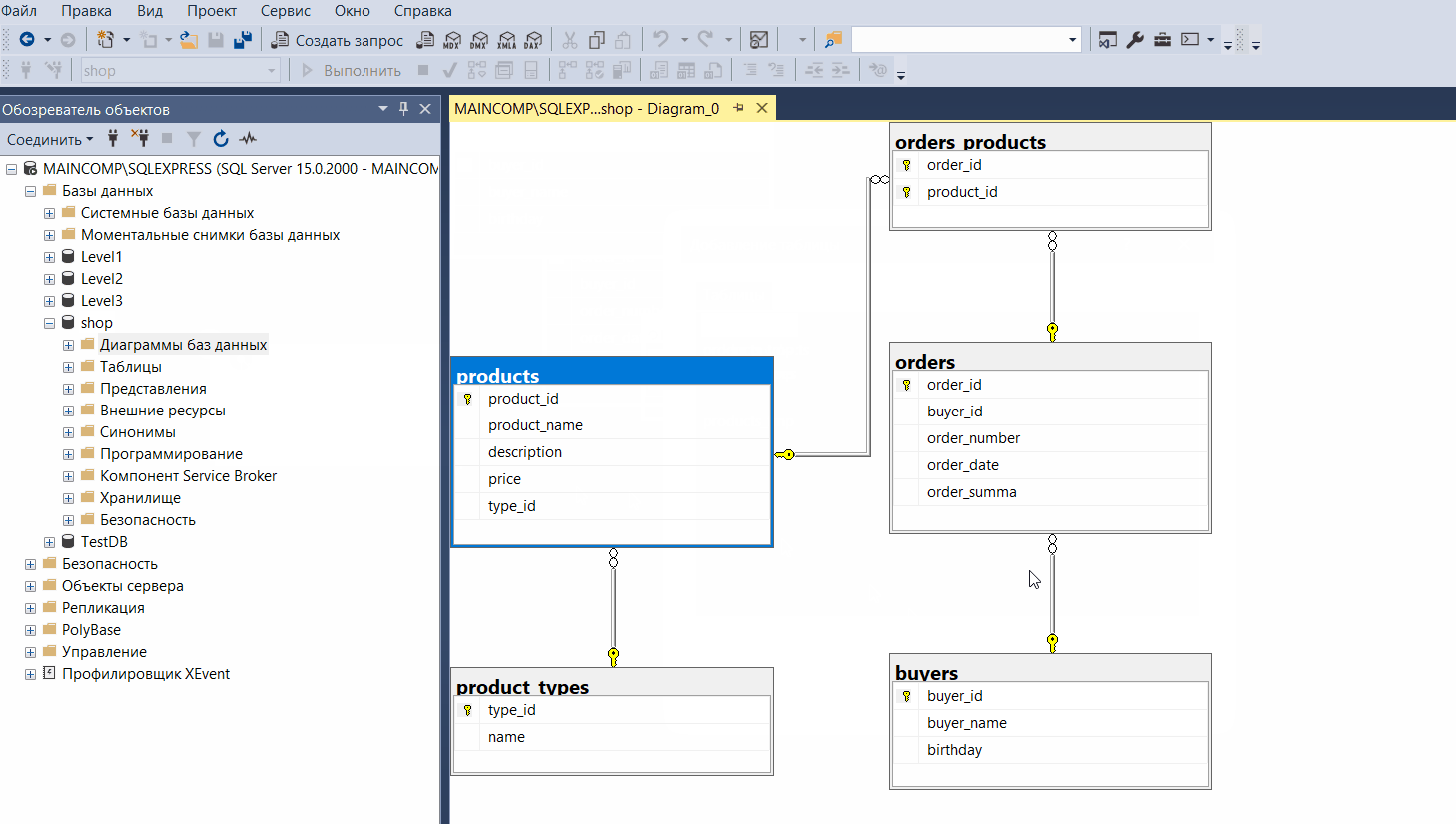
Конструктор баз данных (Диаграммы баз данных)
Конструктор баз данных — это визуальный инструмент для разработки баз данных, который позволяет конструировать и визуализировать базу данных, с которой установлено соединение.
Конструктор баз данных можно использовать для создания, редактирования и удаления таблиц, столбцов, ключей, индексов, связей и ограничений.
Кроме этого конструктор позволяет визуализировать базу данных, т.е. создать ER-диаграмму базы данных. Можно создать как одну, так и несколько диаграмм, иллюстрирующих некоторые или все имеющиеся в ней таблицы, столбцы, ключи и связи.
Чтобы запустить конструктор баз данных и создать диаграмму базы данных, необходимо в обозревателе объектов щелкнуть правой кнопкой мыши по контейнеру «Диаграммы баз данных» и выбрать пункт «Создать диаграмму базы данных».
Заметка! Нормализация баз данных простыми словами.
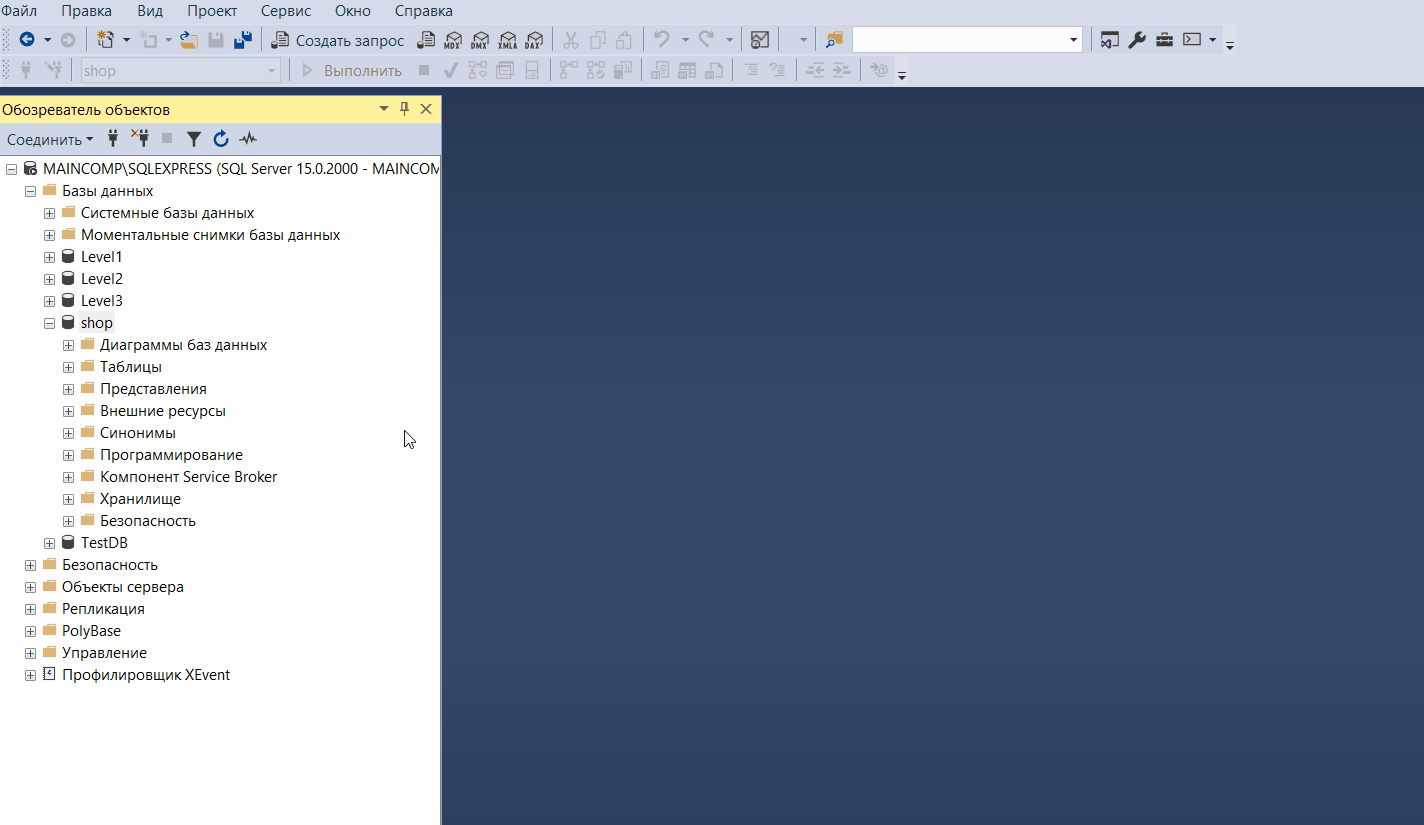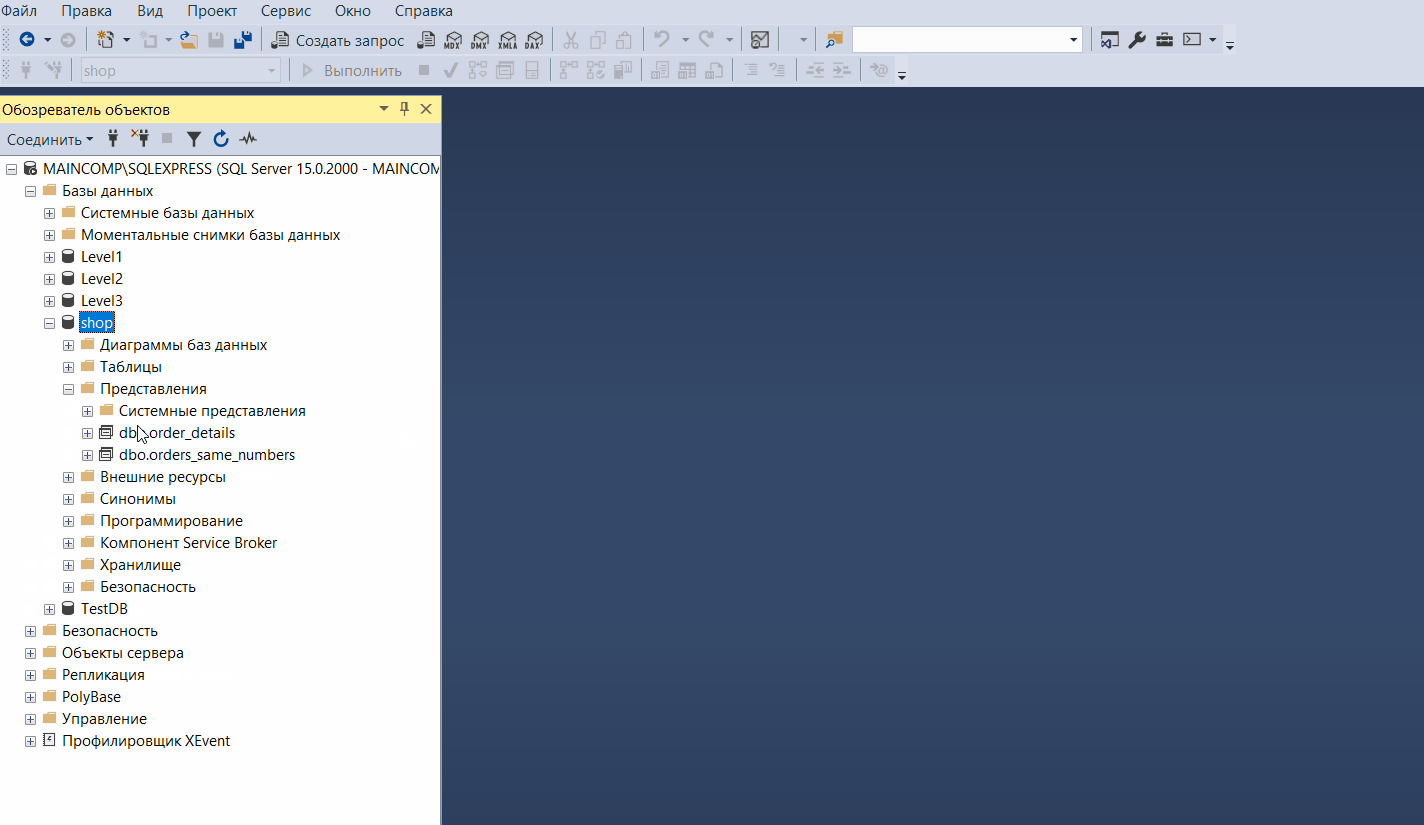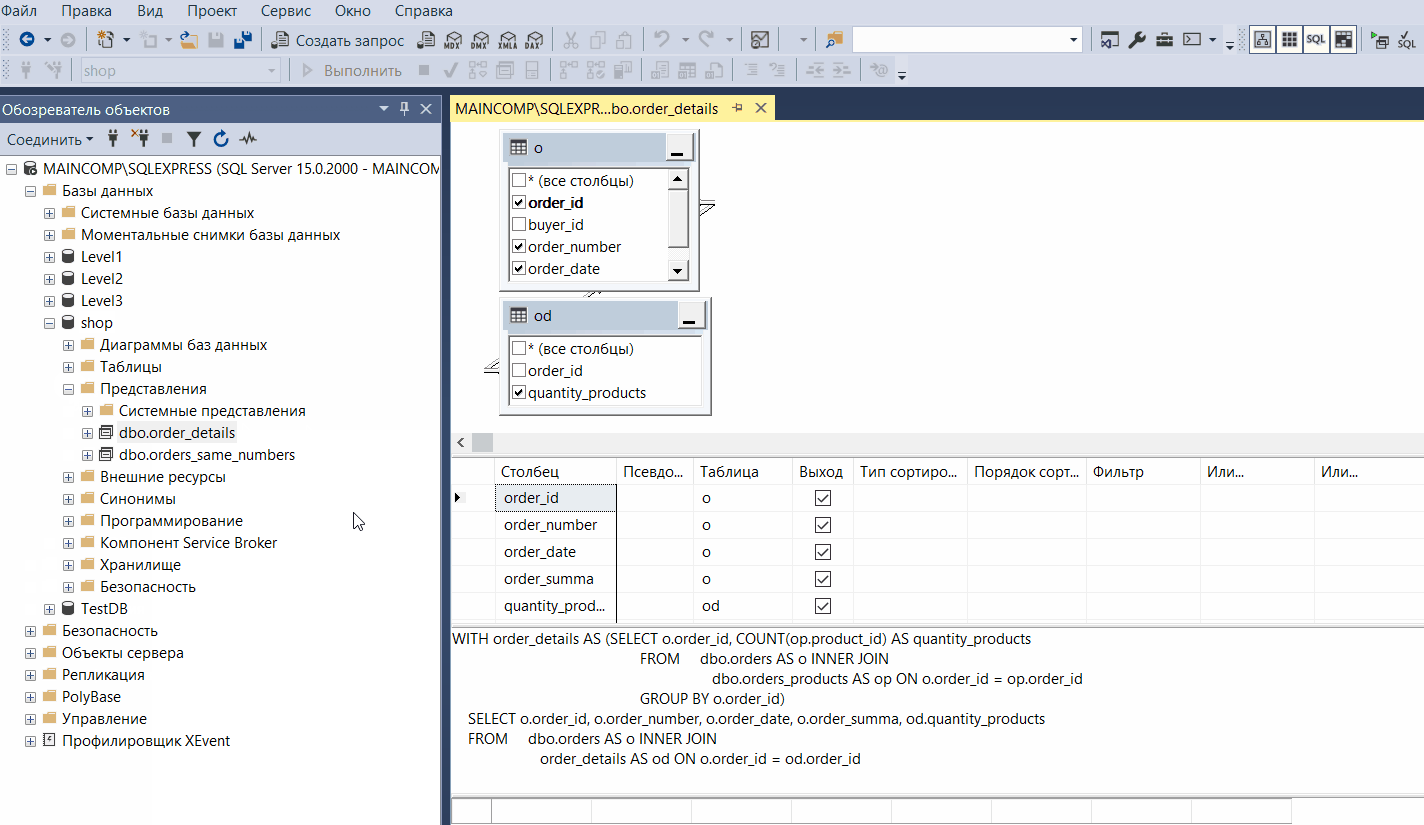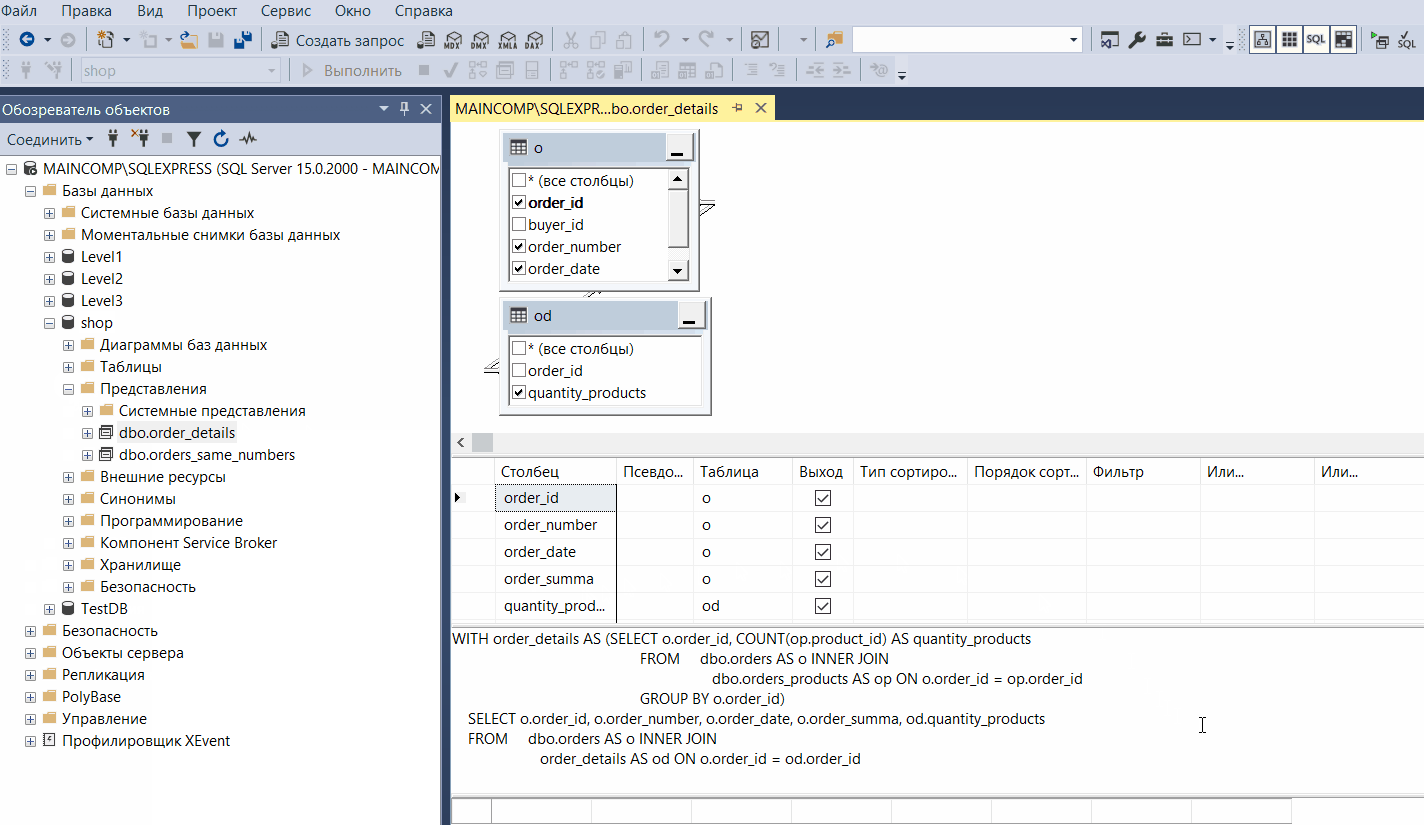
Конструктор запросов и представлений
Конструктор запросов и представлений – это визуальный инструмент для разработки запросов и представлений.
В данном конструкторе доступно 4 панели:
- Панель диаграмм – на ней в графическом виде представлен запрос, т.е. какие таблицы и столбцы задействованы в запросе;
- Панель критериев – на ней Вы задаете параметры запроса, например, указываете, какие столбцы будут задействованы в запросе, как отфильтровать данные, как упорядочивать результаты и т.д;
- Панель SQL – здесь запрос отображается в виде SQL инструкций, где Вы можете в случае необходимости внести изменения на языке SQL;
- Панель результатов – она показывает результаты выполнения запроса.
Таким образом, с помощью данного конструктора можно конструировать запросы к базе данных, при этом используя только мышку.
Чтобы открыть конструктор запросов, необходимо в редакторе запросов щелкнуть правой кнопкой мыши в любом месте и выбрать пункт «Создать запрос в редакторе», кстати, можно выделить существующий SQL запрос, если он есть, и точно также создать запрос в редакторе, в этом случае конструктор автоматически визуализирует данный SQL запрос.
Чтобы открыть конструктор представлений, необходимо в обозревателе щелкнуть правой кнопкой мыши по нужному представлению и выбрать пункт «Разработка».
Заметка! Как установить SQL Server Data Tools (SSDT) и что это такое.
Просмотр свойств объектов
Среда SQL Server Management Studio позволяет просматривать и изменять свойства объектов SQL Server в обозревателе объектов.
Практически у каждого объекта на SQL Server есть свойства, которые как раз и можно изменить с помощью графических инструментов среды SQL Server Management Studio или просто посмотреть.
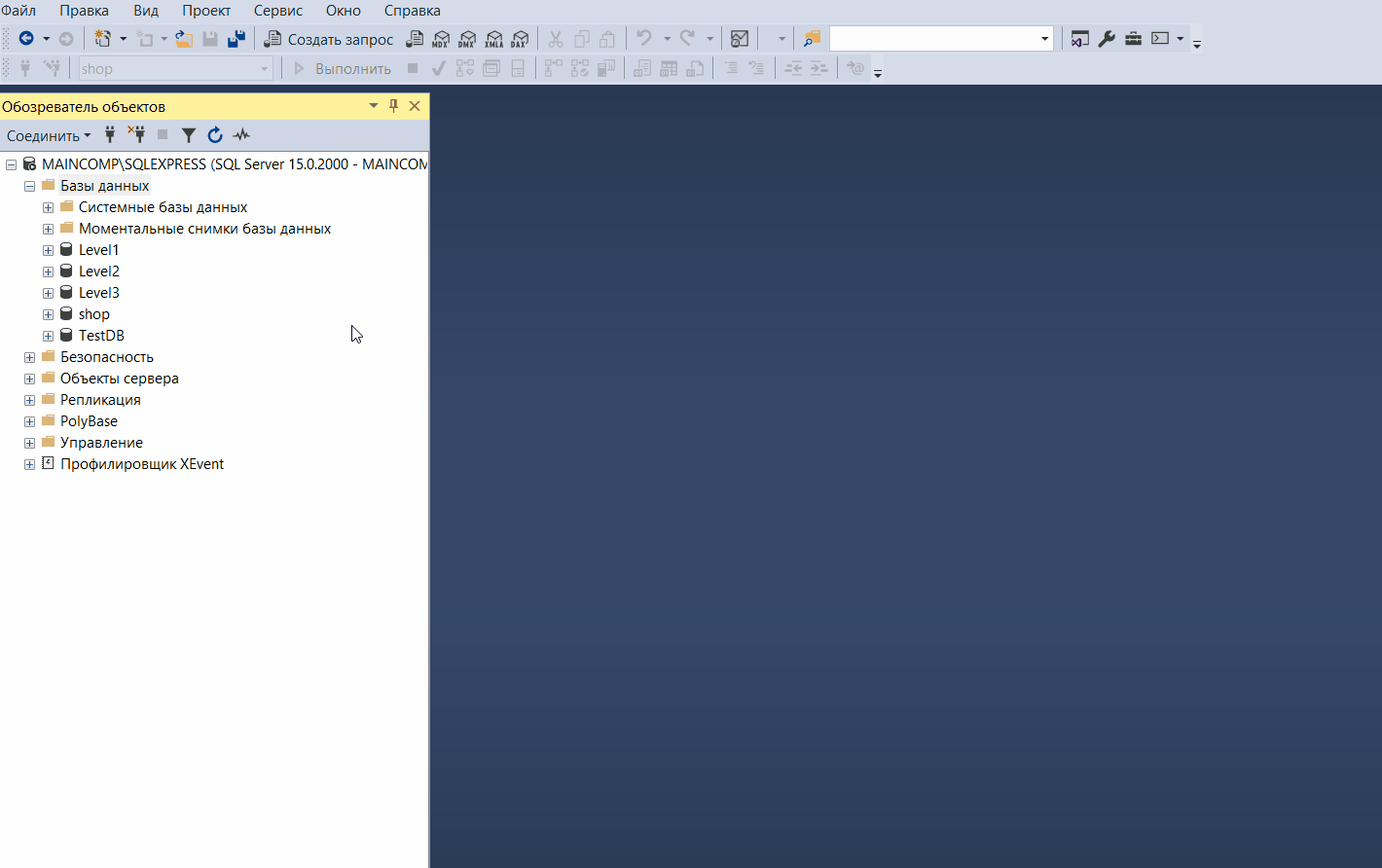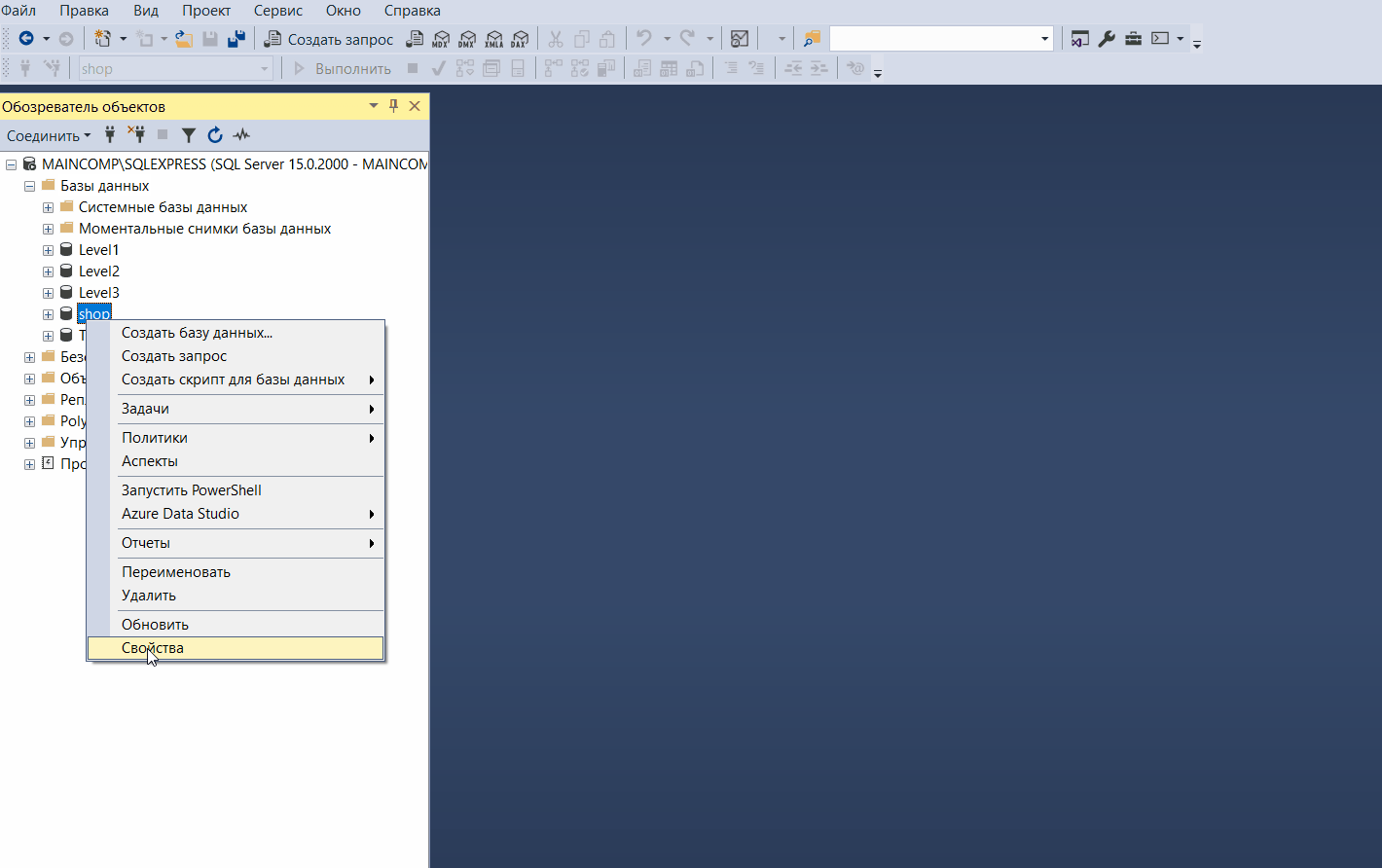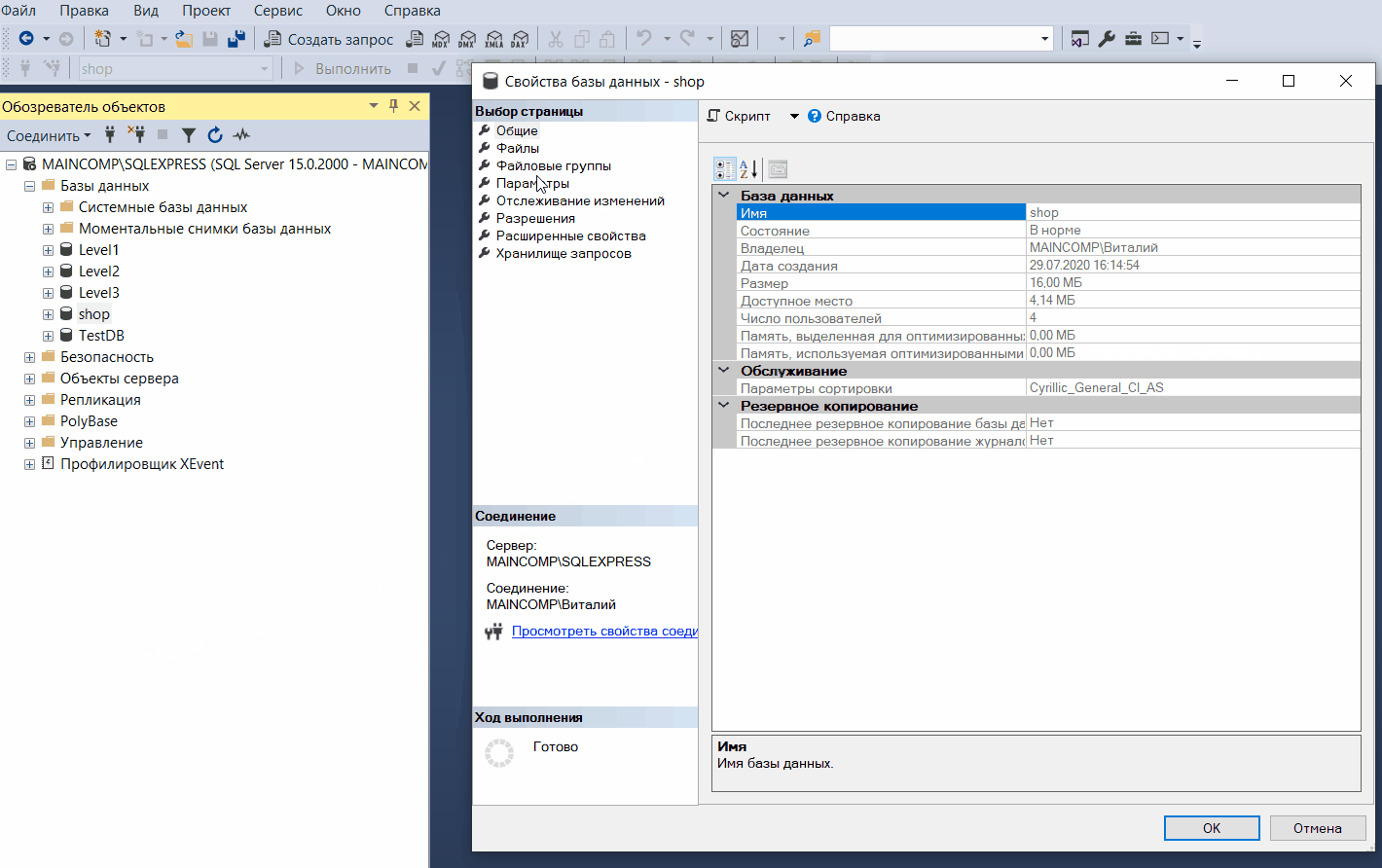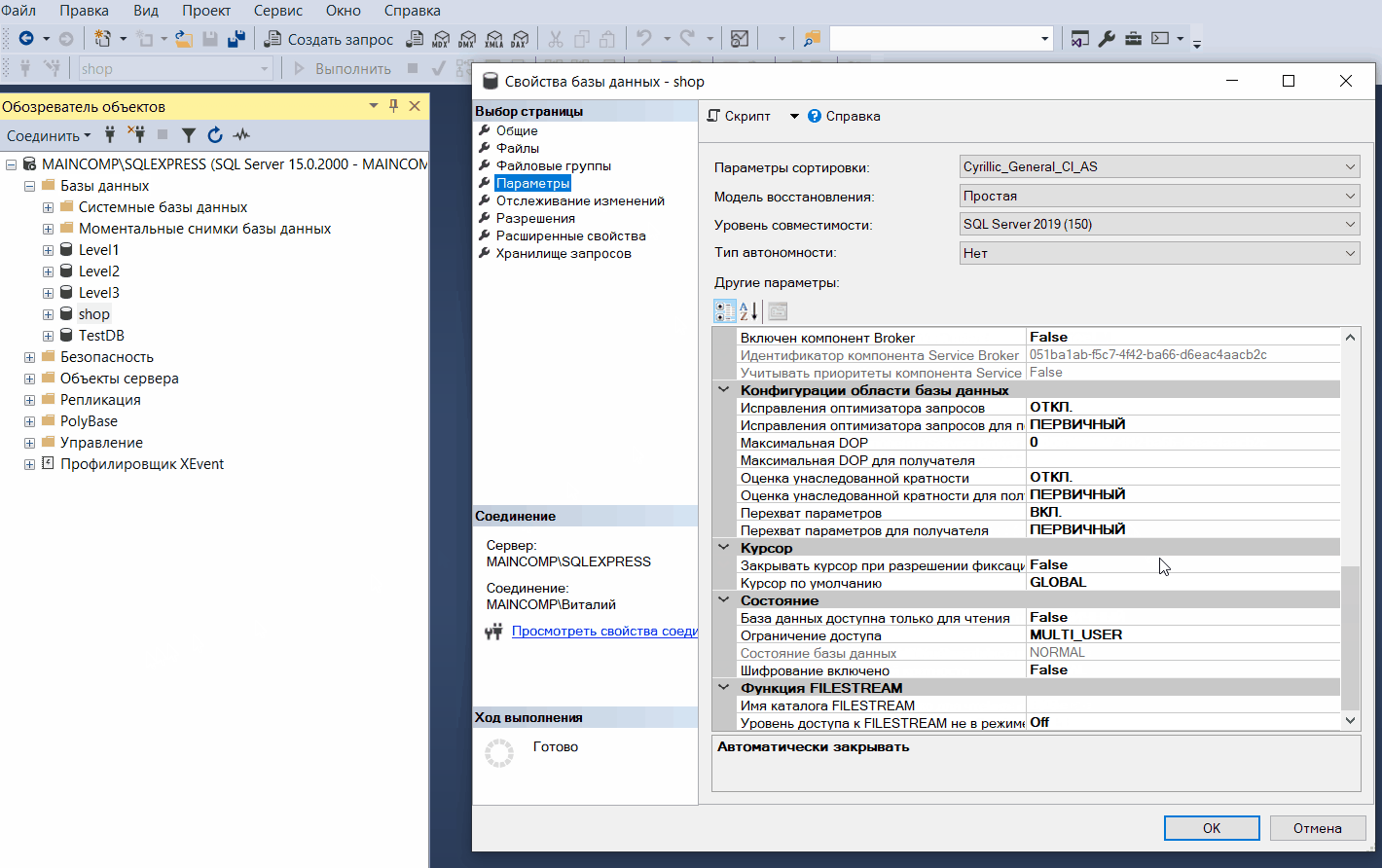
Например, для редактирования свойств базы данных необходимо в обозревателе объектов выбрать базу, щелкнуть по ней правой кнопкой мыши и выбрать «Свойства».
Заметка! Знакомство с Oracle Database Express Edition (XE) – что это такое?
Мастер создания скриптов
В SQL Server Management Studio есть очень полезный функционал, который позволяет сгенерировать скрипт создания объектов базы данных, чтобы, например, использовать этот скрипт на другом экземпляре SQL Server для создания точно таких же объектов.
SQL скрипт объекта базы данных – это SQL инструкция, с помощью которой создается этот объект, сохраненная в текстовом файле.
С помощью данного мастера мы можем очень легко сгенерировать SQL скрипт создания практически любого объекта на SQL Server.
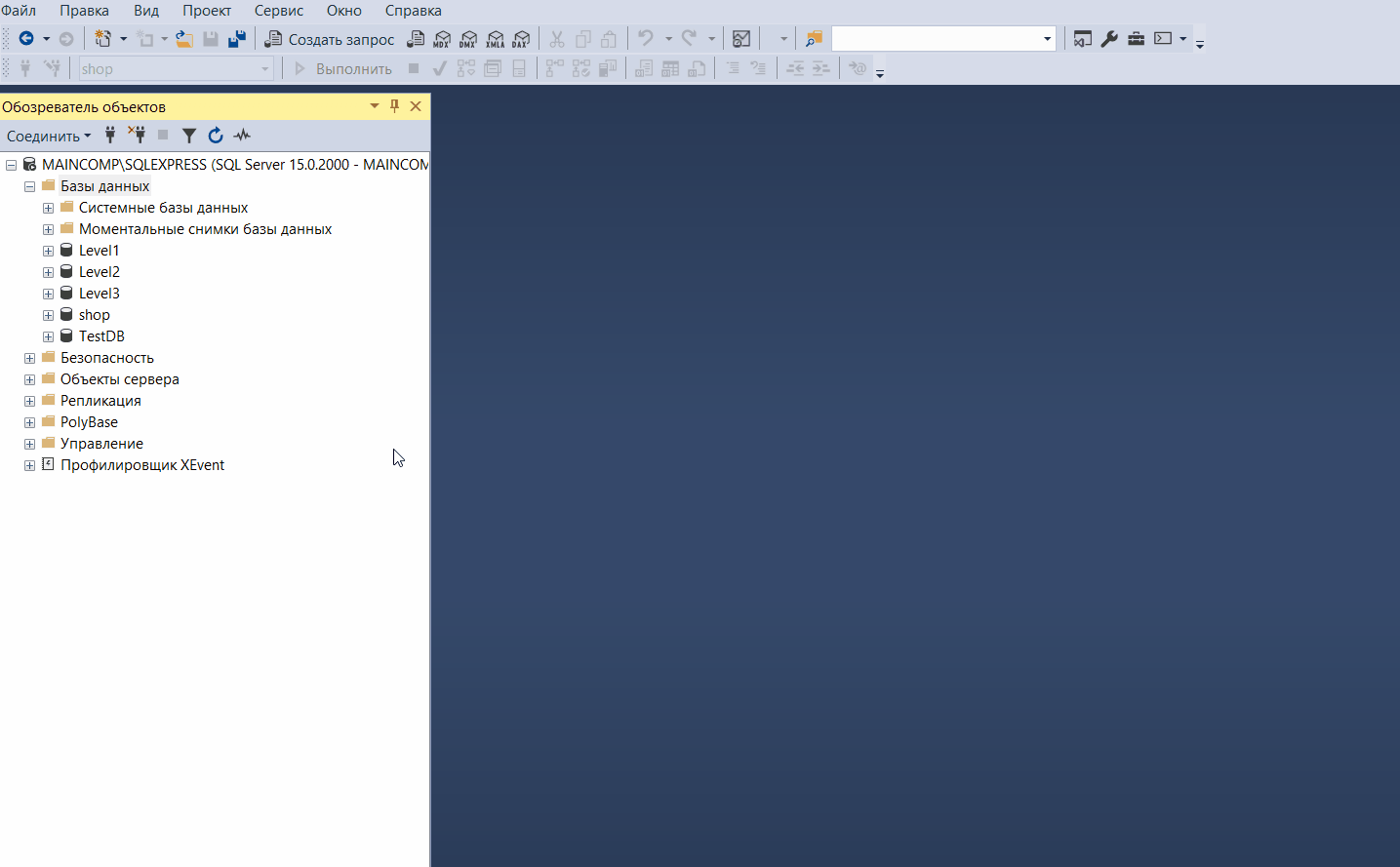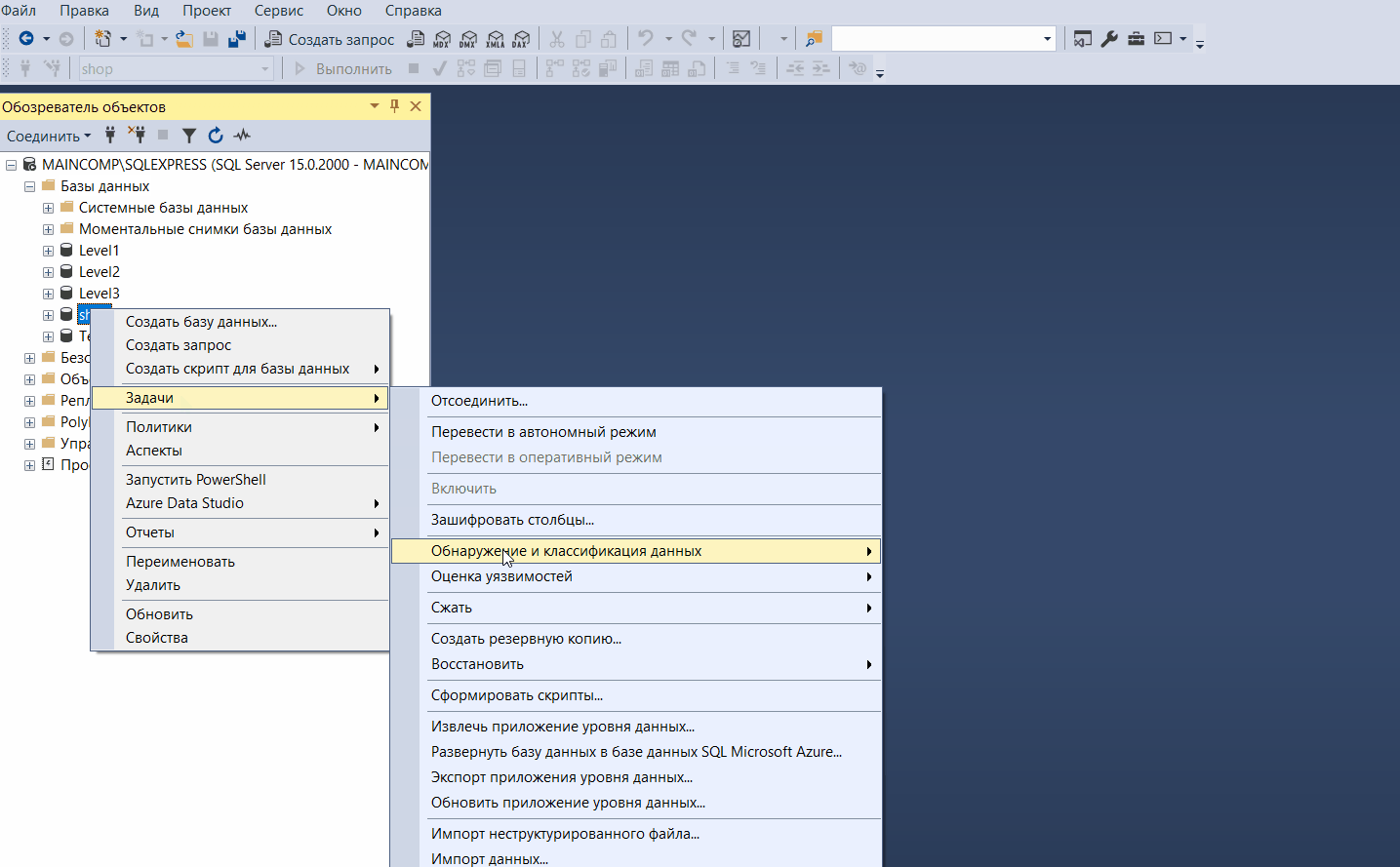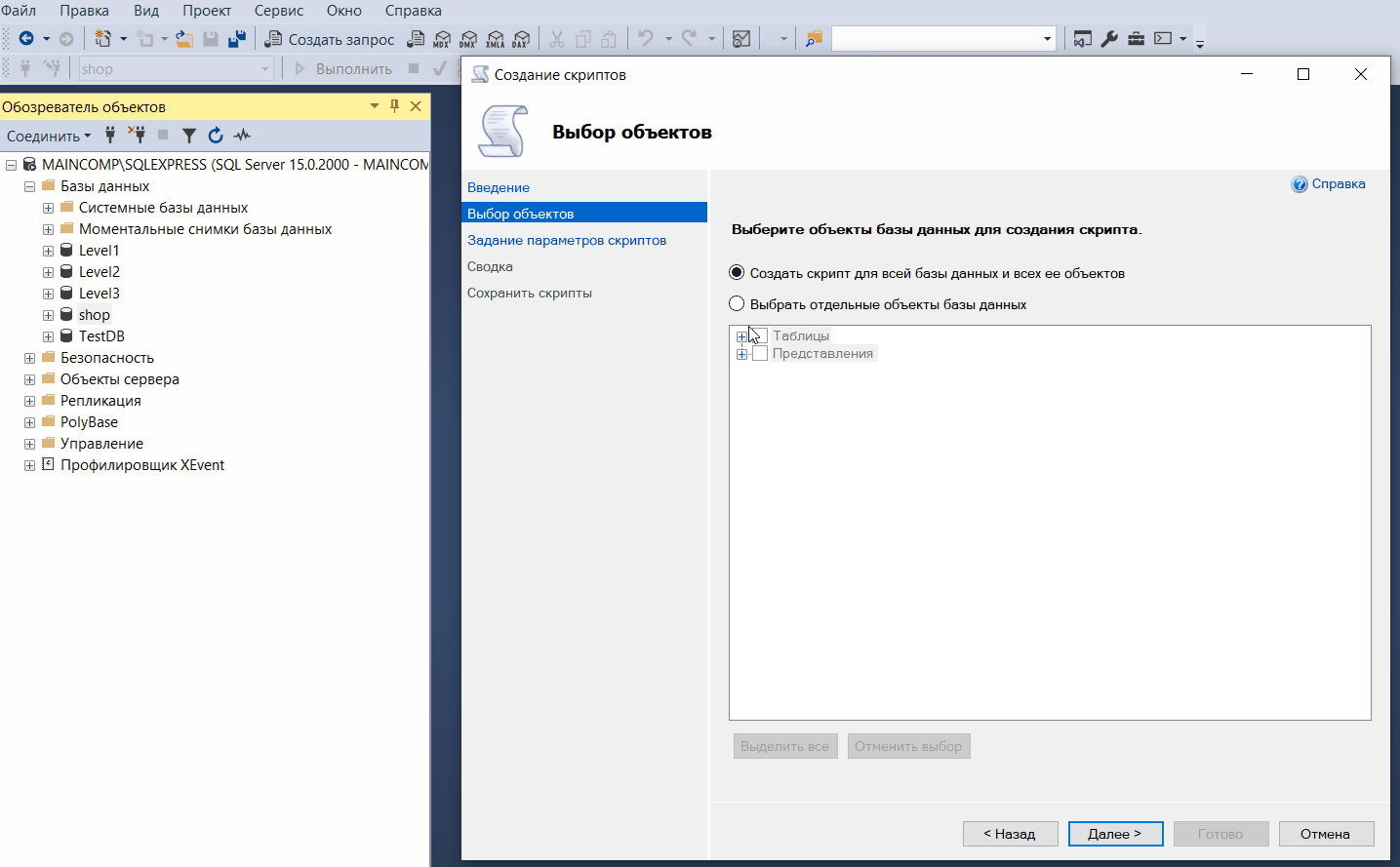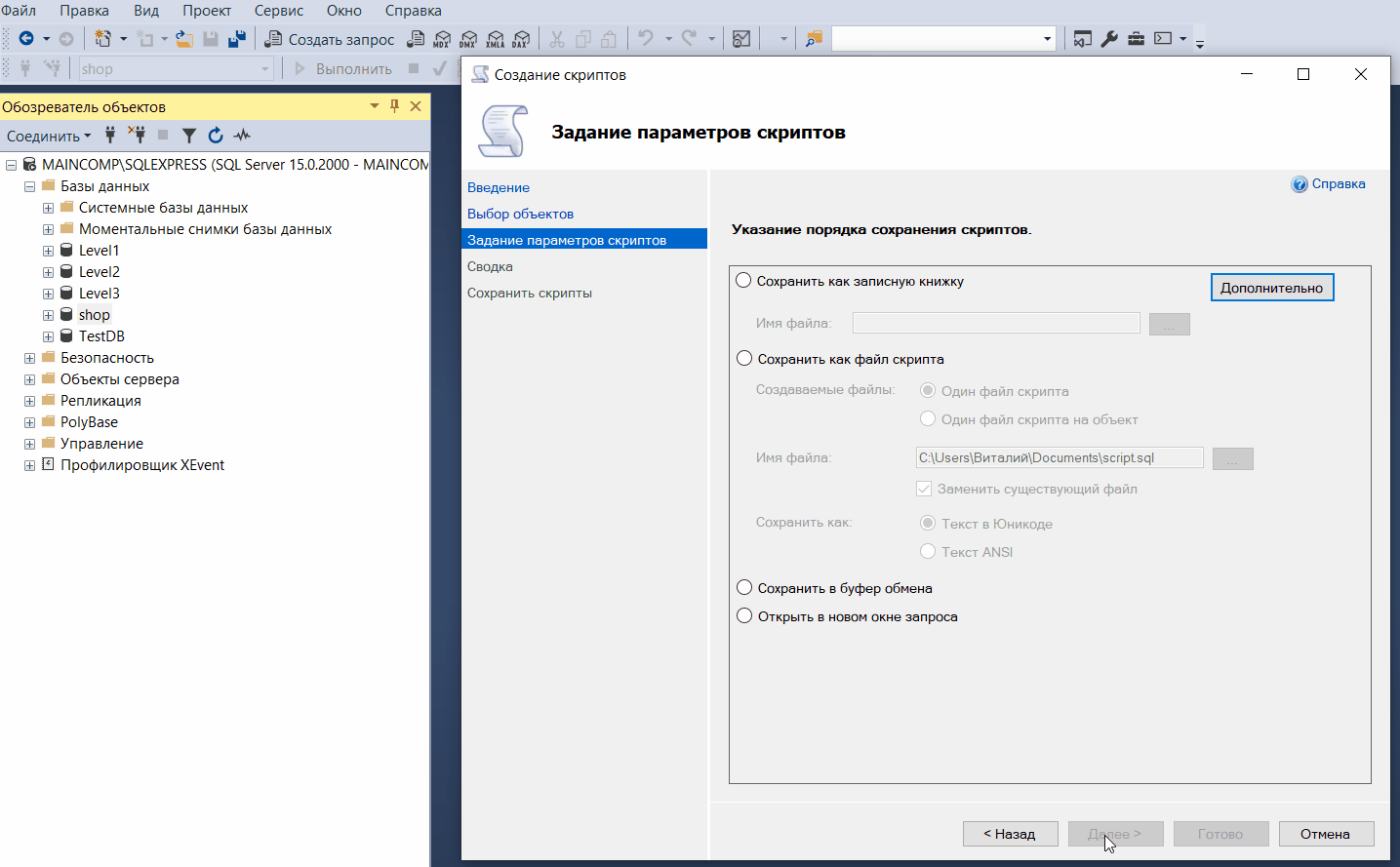
Такой скрипт может включать:
- Инструкции создания таблиц (CREATE);
- Инструкции добавления данных (INSERT);
- Определение представлений, функций, хранимых процедур, триггеров;
- Определение ограничений и индексов;
- И другие SQL инструкции.
Такие SQL скрипты могут быть очень полезны администраторам или разработчикам, например, для того, чтобы в случае необходимости иметь возможность быстро восстановить объекты базы данных с помощью этих скриптов, или для того, чтобы передать эти SQL скрипты другому администратору, разработчику или заказчику, чтобы он создал подобные объекты на своем экземпляре SQL Server.
Таким образом, с помощью данного мастера мы можем создать некий дамп базы данных, содержащий SQL скрипты создания объектов этой базы данных и наполнения их данными.
Заметка! Как сгенерировать SQL скрипт создания объектов и данных в Microsoft SQL Server?
Управление безопасностью SQL Server
Среда SQL Server Management Studio позволяет не только разрабатывать и выполнять T-SQL код, но управлять SQL сервером, в частности управлять безопасностью сервера.
С помощью SSMS можно создавать имена входа на сервер, пользователей баз данных, а также настраивать доступ к объектам сервера.
Для управления безопасностью на уровне сервера необходимо зайти в контейнер «Безопасность», для управления безопасностью базы данных необходимо зайти в одноимённый контейнер на уровне базы данных.
Присоединение и отсоединение баз данных
В среде SQL Server Management Studio есть визуальный инструмент для отсоединения и присоединения баз данных (detach, attach). Таким образом, если у Вас возникла необходимость, например, отсоединить базу данных и перенести ее на другой сервер, то это можно очень легко сделать с помощью SSMS.
Чтобы отсоединить базу данных, необходимо щелкнуть правой кнопкой по нужной базе данных и выбрать пункт «Задачи -> Отсоединить».
Чтобы присоединить базу данных, необходимо вызвать контекстное меню у контейнера «Базы данных» и выбрать пункт «Присоединить».
Заметка! Отсоединение и присоединение баз данных в Microsoft SQL Server (Detach и Attach).
Создание резервных копий баз данных и восстановление баз данных из архива
С помощью SQL Server Management Studio можно, используя графический интерфейс, создавать резервные копии баз данных, а также восстанавливать базы из этих резервных копий.
Чтобы создать резервную копию базы данных, нужно кликнуть правой кнопкой мыши по необходимой базе данных и в меню выбрать «Задачи -> Создать резервную копию», для восстановления базы данных из резервной копии — пункт «Задачи -> Восстановить».
Создание связанных серверов (Linked Server)
В SQL Server Management Studio кроме всего прочего есть графические инструменты для создания связанных серверов.
Монитор активности SQL Server
Монитор активности – это инструмент, который отображает сведения о текущих процессах в SQL Server.
С помощью данного монитора мы можем отслеживать активность на сервере, например, мы можем видеть, какие SQL запросы и инструкции в данный момент выполняются, какие пользователи подключены к SQL Server и так далее.
Для запуска монитора активности необходимо щелкнуть правой кнопкой мыши по серверу в обозревателе объектов и выбрать пункт «Монитор активности» или кликнуть на иконку на панели инструментов.
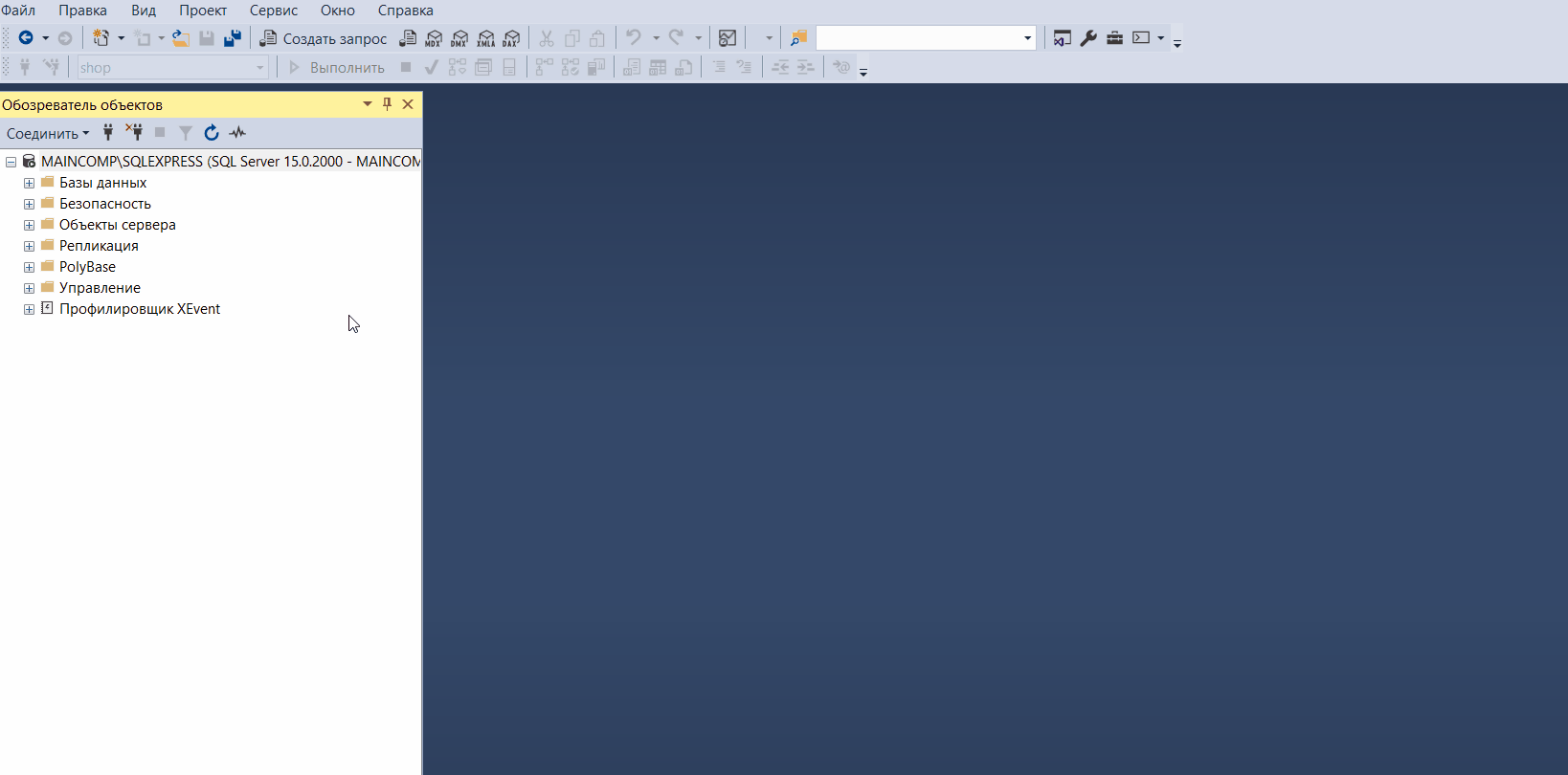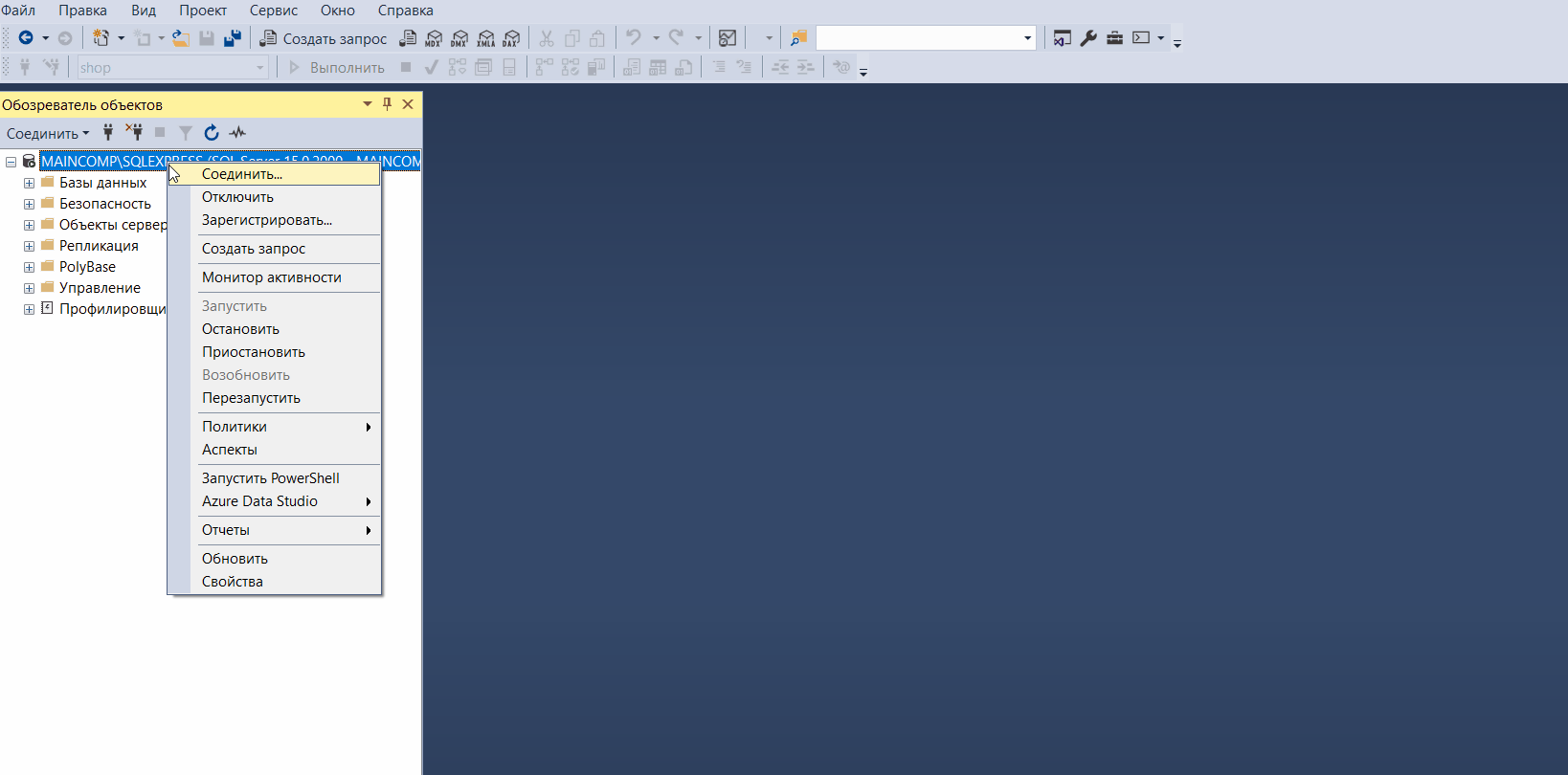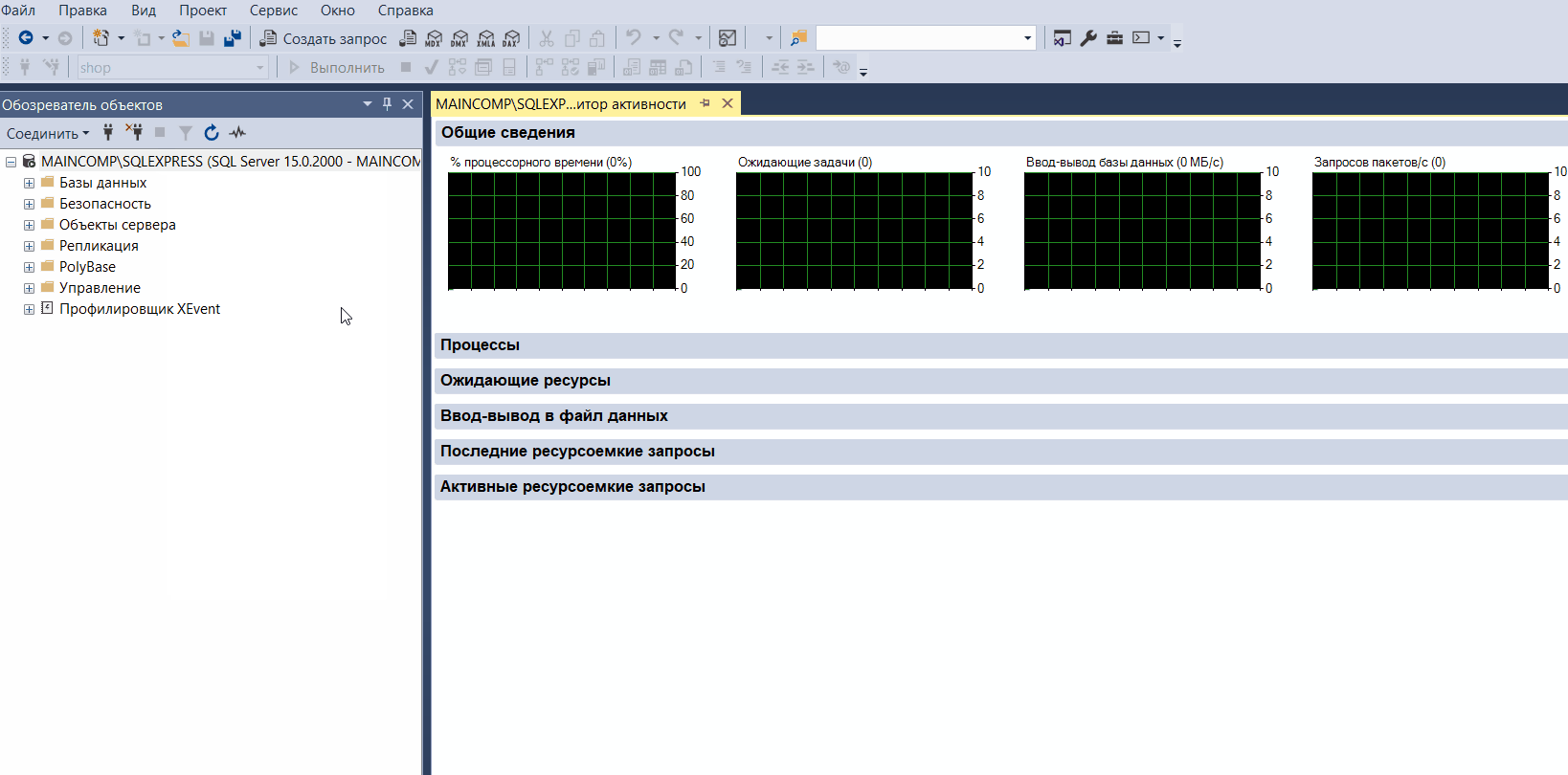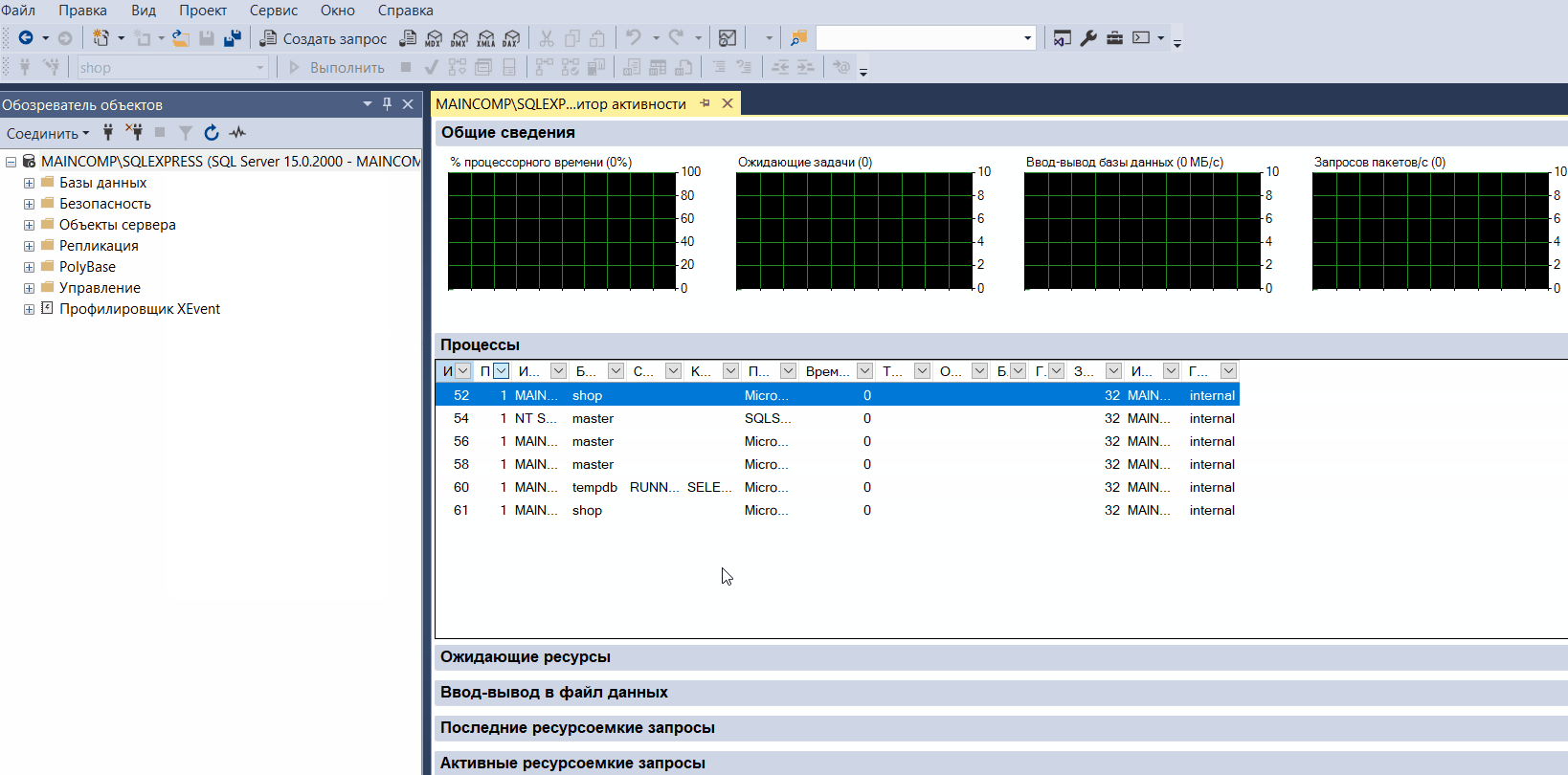
Монитор активности представляет собой окно с развертываемыми панелями, которые отображают: общие сведения в виде графиков, процессы, ожидающие ресурсы, ввод-вывод в файл данных, последние ресурсоемкие запросы и активные ресурсоемкие запросы.
Заметка! Установка SQL Server Management Studio (SSMS) на Windows 10.
Настройка репликации баз данных
В среде SQL Server Management Studio есть графический инструмент для настройки репликации баз данных.
В обозревателе объектов контейнер так и называется «Репликация».
Профилировщик XEvent
Профилировщик XEvent – это компонент SQL Server Management Studio, который отображает динамическое окно просмотра расширенных событий.
Профилировщик позволяет получить быстрый доступ к динамическому потоковому представлению диагностических событий в SQL Server, например, с целью выявления различных проблем.
Заметка! Курсы по Transact-SQL для начинающих.
Вот мы с Вами и рассмотрели основные возможности и функционал среды SQL Server Management Studio, конечно же, есть и другой полезный функционал, однако уместить все в одной статье не получится, поэтому на сегодня это все, надеюсь, материал был Вам интересен и полезен, пока!
| title | description | author | ms.author | ms.reviewer | ms.date | ms.service | ms.subservice | ms.topic | ms.custom | f1_keywords | helpviewer_keywords | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
SQL Server Management Studio (SSMS) |
Learn details about SQL Server Management Studio (SSMS) and what SSMS can do, including how to manage Analysis Services Solutions. |
markingmyname |
maghan |
randolphwest |
03/30/2023 |
sql |
ssms |
overview |
intro-overview |
sql13.ssms.viewhelp.f1 |
|
What is SQL Server Management Studio (SSMS)?
[!INCLUDE SQL Server ASDB, ASDBMI, ASDW]
SQL Server Management Studio (SSMS) is an integrated environment for managing any SQL infrastructure. Use SSMS to access, configure, manage, administer, and develop all components of [!INCLUDE ssnoversion-md], Azure SQL Database, Azure SQL Managed Instance, SQL Server on Azure VM, and Azure Synapse Analytics. SSMS provides a single comprehensive utility that combines a broad group of graphical tools with many rich script editors to provide access to [!INCLUDE ssnoversion-md] for developers and database administrators of all skill levels.
- Download SQL Server Management Studio (SSMS)
- Download SQL Server Developer
- Download Visual Studio
:::image type=»content» source=»media/sql-server-management-studio-ssms/ssms.png» alt-text=»Screenshot of SQL Server Management Studio.»:::
SQL Server Management Studio components
| Description | Component |
|---|---|
| Use Object Explorer to view and manage all of the objects in one or more instances of [!INCLUDE ssnoversion-md]. | Object Explorer |
| Use Template Explorer to build and manage files of boilerplate text that you use to speed the development of queries and scripts. | Template Explorer |
| Use the deprecated Solution Explorer to build projects used to manage administration items such as scripts and queries. | Solution Explorer |
| Use the visual design tools included in [!INCLUDEssManStudio] to build queries, tables, and diagram databases. | Visual Database Tools |
| Use the [!INCLUDEssManStudio] language editors to interactively build and debug queries and scripts. | Query and Text Editors |
SQL Server Management Studio for business intelligence
To access, configure, manage, and administer [!INCLUDEssASnoversion], Integration Services, and Reporting Services, use SSMS. Although all three business intelligence technologies rely on SSMS, the administrative tasks associated with each of these technologies are slightly different.
[!NOTE]
To create and modify Analysis Services, Reporting Services, and Integration Services solutions, use [!INCLUDEssBIDevStudioFull], not SSMS. [!INCLUDEssBIDevStudioFull] is a development environment that is based on Microsoft[!INCLUDEvsprvs].
Manage Analysis Services solutions using SQL Server Management Studio
SSMS enables you to manage [!INCLUDEssASnoversion] objects, such as performing back-ups and processing objects.
[!INCLUDEssManStudio] provides an [!INCLUDEssASnoversion] Script project in which you develop and save scripts written in Multidimensional Expressions (MDX), Data Mining Extensions (DMX), and XML for Analysis (XMLA). You use [!INCLUDEssASnoversion] Scripts projects to perform management tasks or re-create objects, such as database and cubes, on [!INCLUDEssASnoversion] instances. For example, you can develop an XMLA script in an [!INCLUDEssASnoversion] Script project that creates new objects directly on an existing [!INCLUDEssASnoversion] instance. The [!INCLUDEssASnoversion] Scripts projects can be saved as part of a solution and integrated with source code control.
For more information about how to use SSMS, see Developing and Implementing Using SQL Server Management Studio.
Manage Integration Services solutions using SQL Server Management Studio
SSMS enables you to use the Integration Services service to manage packages and monitor running packages. You can also use [!INCLUDEssManStudio] to organize packages into folders, run packages, import and export packages, migrate Data Transformation Services (DTS) packages, and upgrade Integration Services packages.
Manage Reporting Services projects using SQL Server Management Studio
Use SSMS to enable Reporting Services features, administer the server and databases, and manage roles and jobs.
You manage shared schedules by using the Shared Schedules folder, and manage report server databases (ReportServer, ReportServerTempDB). You also create a RSExecRole in the master system database when you move a report server database to a new or different [!INCLUDE ssde-md]. For more information about these tasks, see the following articles:
- Reporting Services in SSMS
- Administer a Report Server database
- Create the RSExecRole
You also manage the server by enabling and configuring various features, setting server defaults, and managing roles and jobs. For more information about these tasks, see the following articles:
- Set Report Server properties
- Create, delete, or modify a role
- Enabling and disabling client-side printing for Reporting Services
Non-English language versions of SQL Server Management Studio
The block on mixed languages setup has been lifted. You can install SSMS German on a French Windows. If the OS language doesn’t match the SSMS language, the user needs to change the language under Tools > Options > International Settings. Otherwise, SSMS shows the English UI.
For more information about different locale with previous versions, reference Install non-English language versions of SSMS.
Support policy for SSMS
- Starting with SSMS 17.0, the SQL Tools team has adopted the Microsoft Modern Lifecycle Policy.
- Read the original Modern Lifecycle Policy announcement. For more information, see Modern Policy FAQs.
- For information on diagnostic data collection and feature usage, see the SQL Server privacy supplement.
Cross-platform tool
[!INCLUDEssms-azure-data-studio-mention]
[!INCLUDEget-help-options]
Next steps
For more information about SSMS, common tasks, and related tools, see the following articles:
- Install non-English language versions of SSMS
- Connect to and query a SQL Server instance
- Writing Transact-SQL Statements
- Azure Data Studio
О чем данный учебник
Данный учебник представляет собой что-то типа «штампа моей памяти» по языку SQL (DDL, DML), т.е. это информация, которая накопилась по ходу профессиональной деятельности и постоянно хранится в моей голове. Это для меня достаточный минимум, который применяется при работе с базами данных наиболее часто. Если встает необходимость применять более полные конструкции SQL, то я обычно обращаюсь за помощью в библиотеку MSDN расположенную в интернет. На мой взгляд, удержать все в голове очень сложно, да и нет особой необходимости в этом. Но знать основные конструкции очень полезно, т.к. они применимы практически в таком же виде во многих реляционных базах данных, таких как Oracle, MySQL, Firebird. Отличия в основном состоят в типах данных, которые могут отличаться в деталях. Основных конструкций языка SQL не так много, и при постоянной практике они быстро запоминаются. Например, для создания объектов (таблиц, ограничений, индексов и т.п.) достаточно иметь под рукой текстовый редактор среды (IDE) для работы с базой данных, и нет надобности изучать визуальный инструментарий заточенный для работы с конкретным типом баз данных (MS SQL, Oracle, MySQL, Firebird, …). Это удобно и тем, что весь текст находится перед глазами, и не нужно бегать по многочисленным вкладкам для того чтобы создать, например, индекс или ограничение. При постоянной работе с базой данных, создать, изменить, а особенно пересоздать объект при помощи скриптов получается в разы быстрее, чем если это делать в визуальном режиме. Так же в скриптовом режиме (соответственно, при должной аккуратности), проще задавать и контролировать правила наименования объектов (мое субъективное мнение). К тому же скрипты удобно использовать в случае, когда изменения, делаемые в одной базе данных (например, тестовой), необходимо перенести в таком же виде в другую базу (продуктивную).
Язык SQL подразделяется на несколько частей, здесь я рассмотрю 2 наиболее важные его части:
- DDL – Data Definition Language (язык описания данных)
- DML – Data Manipulation Language (язык манипулирования данными), который содержит следующие конструкции:
- SELECT – выборка данных
- INSERT – вставка новых данных
- UPDATE – обновление данных
- DELETE – удаление данных
- MERGE – слияние данных
Т.к. я являюсь практиком, как таковой теории в данном учебнике будет мало, и все конструкции будут объясняться на практических примерах. К тому же я считаю, что язык программирования, а особенно SQL, можно освоить только на практике, самостоятельно пощупав его и поняв, что происходит, когда вы выполняете ту или иную конструкцию.
Данный учебник создан по принципу Step by Step, т.е. необходимо читать его последовательно и желательно сразу же выполняя примеры. Но если по ходу у вас возникает потребность узнать о какой-то команде более детально, то используйте конкретный поиск в интернет, например, в библиотеке MSDN.
При написании данного учебника использовалась база данных MS SQL Server версии 2014, для выполнения скриптов я использовал MS SQL Server Management Studio (SSMS).
Кратко о MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) — утилита для Microsoft SQL Server для конфигурирования, управления и администрирования компонентов базы данных. Данная утилита содержит редактор скриптов (который в основном и будет нами использоваться) и графическую программу, которая работает с объектами и настройками сервера. Главным инструментом SQL Server Management Studio является Object Explorer, который позволяет пользователю просматривать, извлекать объекты сервера, а также управлять ими. Данный текст частично позаимствован с википедии.
Для создания нового редактора скрипта используйте кнопку «New Query/Новый запрос»:
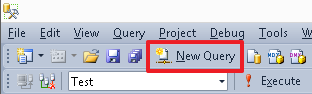
Для смены текущей базы данных можно использовать выпадающий список:

Для выполнения определенной команды (или группы команд) выделите ее и нажмите кнопку «Execute/Выполнить» или же клавишу «F5». Если в редакторе в текущий момент находится только одна команда, или же вам необходимо выполнить все команды, то ничего выделять не нужно.
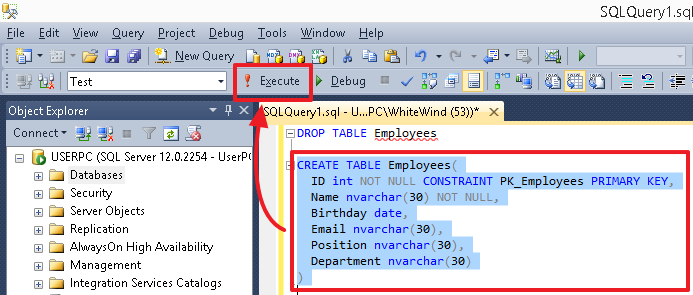
После выполнения скриптов, в особенности создающих объекты (таблицы, столбцы, индексы), чтобы увидеть изменения, используйте обновление из контекстного меню, выделив соответствующую группу (например, Таблицы), саму таблицу или группу Столбцы в ней.
Собственно, это все, что нам необходимо будет знать для выполнения приведенных здесь примеров. Остальное по утилите SSMS несложно изучить самостоятельно.
Немного теории
Реляционная база данных (РБД, или далее в контексте просто БД) представляет из себя совокупность таблиц, связанных между собой. Если говорить грубо, то БД – файл в котором данные хранятся в структурированном виде.
СУБД – Система Управления этими Базами Данных, т.е. это комплекс инструментов для работы с конкретным типом БД (MS SQL, Oracle, MySQL, Firebird, …).
Примечание
Т.к. в жизни, в разговорной речи, мы по большей части говорим: «БД Oracle», или даже просто «Oracle», на самом деле подразумевая «СУБД Oracle», то в контексте данного учебника иногда будет употребляться термин БД. Из контекста, я думаю, будет понятно, о чем именно идет речь.
Таблица представляет из себя совокупность столбцов. Столбцы, так же могут называть полями или колонками, все эти слова будут использоваться как синонимы, выражающие одно и тоже.
Таблица – это главный объект РБД, все данные РБД хранятся построчно в столбцах таблицы. Строки, записи – тоже синонимы.
Для каждой таблицы, как и ее столбцов задаются наименования, по которым впоследствии к ним идет обращение.
Наименование объекта (имя таблицы, имя столбца, имя индекса и т.п.) в MS SQL может иметь максимальную длину 128 символов.
Для справки – в БД ORACLE наименования объектов могут иметь максимальную длину 30 символов. Поэтому для конкретной БД нужно вырабатывать свои правила для наименования объектов, чтобы уложиться в лимит по количеству символов.
SQL — язык позволяющий осуществлять запросы в БД посредством СУБД. В конкретной СУБД, язык SQL может иметь специфичную реализацию (свой диалект).
DDL и DML — подмножество языка SQL:
- Язык DDL служит для создания и модификации структуры БД, т.е. для создания/изменения/удаления таблиц и связей.
- Язык DML позволяет осуществлять манипуляции с данными таблиц, т.е. с ее строками. Он позволяет делать выборку данных из таблиц, добавлять новые данные в таблицы, а так же обновлять и удалять существующие данные.
В языке SQL можно использовать 2 вида комментариев (однострочный и многострочный):
-- однострочный комментарий
и
/*
многострочный
комментарий
*/
Собственно, все для теории этого будет достаточно.
DDL – Data Definition Language (язык описания данных)
Для примера рассмотрим таблицу с данными о сотрудниках, в привычном для человека не являющимся программистом виде:
| Табельный номер | ФИО | Дата рождения | Должность | Отдел | |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | i.ivanov@test.tt | Директор | Администрация |
| 1001 | Петров П.П. | 03.12.1983 | p.petrov@test.tt | Программист | ИТ |
| 1002 | Сидоров С.С. | 07.06.1976 | s.sidorov@test.tt | Бухгалтер | Бухгалтерия |
| 1003 | Андреев А.А. | 17.04.1982 | a.andreev@test.tt | Старший программист | ИТ |
В данном случае столбцы таблицы имеют следующие наименования: Табельный номер, ФИО, Дата рождения, E-mail, Должность, Отдел.
Каждый из этих столбцов можно охарактеризовать по типу содержащемся в нем данных:
- Табельный номер – целое число
- ФИО – строка
- Дата рождения – дата
- E-mail – строка
- Должность – строка
- Отдел – строка
Тип столбца – характеристика, которая говорит о том какого рода данные может хранить данный столбец.
Для начала будет достаточно запомнить только следующие основные типы данных используемые в MS SQL:
| Значение | Обозначение в MS SQL | Описание |
|---|---|---|
| Строка переменной длины | varchar(N) и nvarchar(N) |
При помощи числа N, мы можем указать максимально возможную длину строки для соответствующего столбца. Например, если мы хотим сказать, что значение столбца «ФИО» может содержать максимум 30 символов, то необходимо задать ей тип nvarchar(30). Отличие varchar от nvarchar заключается в том, что varchar позволяет хранить строки в формате ASCII, где один символ занимает 1 байт, а nvarchar хранит строки в формате Unicode, где каждый символ занимает 2 байта. Тип varchar стоит использовать только в том случае, если вы на 100% уверены, что в данном поле не потребуется хранить Unicode символы. Например, varchar можно использовать для хранения адресов электронной почты, т.к. они обычно содержат только ASCII символы. |
| Строка фиксированной длины | char(N) и nchar(N) |
От строки переменной длины данный тип отличается тем, что если длина строка меньше N символов, то она всегда дополняется справа до длины N пробелами и сохраняется в БД в таком виде, т.е. в базе данных она занимает ровно N символов (где один символ занимает 1 байт для char и 2 байта для типа nchar). На моей практике данный тип очень редко находит применение, а если и используется, то он используется в основном в формате char(1), т.е. когда поле определяется одним символом. |
| Целое число | int | Данный тип позволяет нам использовать в столбце только целые числа, как положительные, так и отрицательные. Для справки (сейчас это не так актуально для нас) – диапазон чисел который позволяет тип int от -2 147 483 648 до 2 147 483 647. Обычно это основной тип, который используется для задания идентификаторов. |
| Вещественное или действительное число | float | Если говорить простым языком, то это числа, в которых может присутствовать десятичная точка (запятая). |
| Дата | date | Если в столбце необходимо хранить только Дату, которая состоит из трех составляющих: Числа, Месяца и Года. Например, 15.02.2014 (15 февраля 2014 года). Данный тип можно использовать для столбца «Дата приема», «Дата рождения» и т.п., т.е. в тех случаях, когда нам важно зафиксировать только дату, или, когда составляющая времени нам не важна и ее можно отбросить или если она не известна. |
| Время | time | Данный тип можно использовать, если в столбце необходимо хранить только данные о времени, т.е. Часы, Минуты, Секунды и Миллисекунды. Например, 17:38:31.3231603 Например, ежедневное «Время отправления рейса». |
| Дата и время | datetime | Данный тип позволяет одновременно сохранить и Дату, и Время. Например, 15.02.2014 17:38:31.323 Для примера это может быть дата и время какого-нибудь события. |
| Флаг | bit | Данный тип удобно применять для хранения значений вида «Да»/«Нет», где «Да» будет сохраняться как 1, а «Нет» будет сохраняться как 0. |
Так же значение поля, в том случае если это не запрещено, может быть не указано, для этой цели используется ключевое слово NULL.
Для выполнения примеров создадим тестовую базу под названием Test.
Простую базу данных (без указания дополнительных параметров) можно создать, выполнив следующую команду:
CREATE DATABASE Test
Удалить базу данных можно командой (стоит быть очень осторожным с данной командой):
DROP DATABASE Test
Для того, чтобы переключиться на нашу базу данных, можно выполнить команду:
USE Test
Или же выберите базу данных Test в выпадающем списке в области меню SSMS. При работе мною чаще используется именно этот способ переключения между базами.
Теперь в нашей БД мы можем создать таблицу используя описания в том виде как они есть, используя пробелы и символы кириллицы:
CREATE TABLE [Сотрудники](
[Табельный номер] int,
[ФИО] nvarchar(30),
[Дата рождения] date,
[E-mail] nvarchar(30),
[Должность] nvarchar(30),
[Отдел] nvarchar(30)
)
В данном случае нам придется заключать имена в квадратные скобки […].
Но в базе данных для большего удобства все наименования объектов лучше задавать на латинице и не использовать в именах пробелы. В MS SQL обычно в данном случае каждое слово начинается с прописной буквы, например, для поля «Табельный номер», мы могли бы задать имя PersonnelNumber. Так же в имени можно использовать цифры, например, PhoneNumber1.
На заметку
В некоторых СУБД более предпочтительным может быть следующий формат наименований «PHONE_NUMBER», например, такой формат часто используется в БД ORACLE. Естественно при задании имя поля желательно чтобы оно не совпадало с ключевыми словами используемые в СУБД.
По этой причине можете забыть о синтаксисе с квадратными скобками и удалить таблицу [Сотрудники]:
DROP TABLE [Сотрудники]
Например, таблицу с сотрудниками можно назвать «Employees», а ее полям можно задать следующие наименования:
- ID – Табельный номер (Идентификатор сотрудника)
- Name – ФИО
- Birthday – Дата рождения
- Email – E-mail
- Position – Должность
- Department – Отдел
Очень часто для наименования поля идентификатора используется слово ID.
Теперь создадим нашу таблицу:
CREATE TABLE Employees(
ID int,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Для того, чтобы задать обязательные для заполнения столбцы, можно использовать опцию NOT NULL.
Для уже существующей таблицы поля можно переопределить при помощи следующих команд:
-- обновление поля ID
ALTER TABLE Employees ALTER COLUMN ID int NOT NULL
-- обновление поля Name
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
На заметку
Общая концепция языка SQL для большинства СУБД остается одинаковой (по крайней мере, об этом я могу судить по тем СУБД, с которыми мне довелось поработать). Отличие DDL в разных СУБД в основном заключаются в типах данных (здесь могут отличаться не только их наименования, но и детали их реализации), так же может немного отличаться и сама специфика реализации языка SQL (т.е. суть команд одна и та же, но могут быть небольшие различия в диалекте, увы, но одного стандарта нет). Владея основами SQL вы легко сможете перейти с одной СУБД на другую, т.к. вам в данном случае нужно будет только разобраться в деталях реализации команд в новой СУБД, т.е. в большинстве случаев достаточно будет просто провести аналогию.Чтобы не быть голословным, приведу несколько примеров тех же команд для СУБД ORACLE:
-- создание таблицы CREATE TABLE Employees( ID int, -- в ORACLE тип int - это эквивалент(обертка) для number(38) Name nvarchar2(30), -- nvarchar2 в ORACLE эквивалентен nvarchar в MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30) ); -- обновление полей ID и Name (здесь вместо ALTER COLUMN используется MODIFY(…)) ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- добавление PK (в данном случае конструкция выглядит как и в MS SQL, она будет показана ниже) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);Для ORACLE есть отличия в плане реализации типа varchar2, его кодировка зависит настроек БД и текст может сохраняться, например, в кодировке UTF-8. Помимо этого длину поля в ORACLE можно задать как в байтах, так и в символах, для этого используются дополнительные опции BYTE и CHAR, которые указываются после длины поля, например:
NAME varchar2(30 BYTE) -- вместимость поля будет равна 30 байтам NAME varchar2(30 CHAR) -- вместимость поля будет равна 30 символовКакая опция будет использоваться по умолчанию BYTE или CHAR, в случае простого указания в ORACLE типа varchar2(30), зависит от настроек БД, так же она иногда может задаваться в настройках IDE. В общем порой можно легко запутаться, поэтому в случае ORACLE, если используется тип varchar2 (а это здесь порой оправдано, например, при использовании кодировки UTF-8) я предпочитаю явно прописывать CHAR (т.к. обычно длину строки удобнее считать именно в символах).
Но в данном случае если в таблице уже есть какие-нибудь данные, то для успешного выполнения команд необходимо, чтобы во всех строках таблицы поля ID и Name были обязательно заполнены. Продемонстрируем это на примере, вставим в таблицу данные в поля ID, Position и Department, это можно сделать следующим скриптом:
INSERT Employees(ID,Position,Department) VALUES
(1000,N'Директор',N'Администрация'),
(1001,N'Программист',N'ИТ'),
(1002,N'Бухгалтер',N'Бухгалтерия'),
(1003,N'Старший программист',N'ИТ')
В данном случае, команда INSERT также выдаст ошибку, т.к. при вставке мы не указали значения обязательного поля Name.
В случае, если бы у нас в первоначальной таблице уже имелись эти данные, то команда «ALTER TABLE Employees ALTER COLUMN ID int NOT NULL» выполнилась бы успешно, а команда «ALTER TABLE Employees ALTER COLUMN Name int NOT NULL» выдала сообщение об ошибке, что в поле Name имеются NULL (не указанные) значения.
Добавим значения для полю Name и снова зальем данные:
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N'Директор',N'Администрация',N'Иванов И.И.'),
(1001,N'Программист',N'ИТ',N'Петров П.П.'),
(1002,N'Бухгалтер',N'Бухгалтерия',N'Сидоров С.С.'),
(1003,N'Старший программист',N'ИТ',N'Андреев А.А.')
Так же опцию NOT NULL можно использовать непосредственно при создании новой таблицы, т.е. в контексте команды CREATE TABLE.
Сначала удалим таблицу при помощи команды:
DROP TABLE Employees
Теперь создадим таблицу с обязательными для заполнения столбцами ID и Name:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Можно также после имени столбца написать NULL, что будет означать, что в нем будут допустимы NULL-значения (не указанные), но этого делать не обязательно, так как данная характеристика подразумевается по умолчанию.
Если требуется наоборот сделать существующий столбец необязательным для заполнения, то используем следующий синтаксис команды:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
Или просто:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Так же данной командой мы можем изменить тип поля на другой совместимый тип, или же изменить его длину. Для примера давайте расширим поле Name до 50 символов:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Первичный ключ
При создании таблицы желательно, чтобы она имела уникальный столбец или же совокупность столбцов, которая уникальна для каждой ее строки – по данному уникальному значению можно однозначно идентифицировать запись. Такое значение называется первичным ключом таблицы. Для нашей таблицы Employees таким уникальным значением может быть столбец ID (который содержит «Табельный номер сотрудника» — пускай в нашем случае данное значение уникально для каждого сотрудника и не может повторяться).
Создать первичный ключ к уже существующей таблице можно при помощи команды:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
Где «PK_Employees» это имя ограничения, отвечающего за первичный ключ. Обычно для наименования первичного ключа используется префикс «PK_» после которого идет имя таблицы.
Если первичный ключ состоит из нескольких полей, то эти поля необходимо перечислить в скобках через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY(поле1,поле2,…)
Стоит отметить, что в MS SQL все поля, которые входят в первичный ключ, должны иметь характеристику NOT NULL.
Так же первичный ключ можно определить непосредственно при создании таблицы, т.е. в контексте команды CREATE TABLE. Удалим таблицу:
DROP TABLE Employees
А затем создадим ее, используя следующий синтаксис:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
CONSTRAINT PK_Employees PRIMARY KEY(ID) -- описываем PK после всех полей, как ограничение
)
После создания зальем в таблицу данные:
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N'Директор',N'Администрация',N'Иванов И.И.'),
(1001,N'Программист',N'ИТ',N'Петров П.П.'),
(1002,N'Бухгалтер',N'Бухгалтерия',N'Сидоров С.С.'),
(1003,N'Старший программист',N'ИТ',N'Андреев А.А.')
Если первичный ключ в таблице состоит только из значений одного столбца, то можно использовать следующий синтаксис:
CREATE TABLE Employees(
ID int NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, -- указываем как характеристику поля
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
На самом деле имя ограничения можно и не задавать, в этом случае ему будет присвоено системное имя (наподобие «PK__Employee__3214EC278DA42077»):
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
PRIMARY KEY(ID)
)
Или:
CREATE TABLE Employees(
ID int NOT NULL PRIMARY KEY,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Но я бы рекомендовал для постоянных таблиц всегда явно задавать имя ограничения, т.к. по явно заданному и понятному имени с ним впоследствии будет легче проводить манипуляции, например, можно произвести его удаление:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Но такой краткий синтаксис, без указания имен ограничений, удобно применять при создании временных таблиц БД (имя временной таблицы начинается с # или ##), которые после использования будут удалены.
Подытожим
На данный момент мы рассмотрели следующие команды:
- CREATE TABLE имя_таблицы (перечисление полей и их типов, ограничений) – служит для создания новой таблицы в текущей БД;
- DROP TABLE имя_таблицы – служит для удаления таблицы из текущей БД;
- ALTER TABLE имя_таблицы ALTER COLUMN имя_столбца … – служит для обновления типа столбца или для изменения его настроек (например для задания характеристики NULL или NOT NULL);
- ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY(поле1, поле2,…) – добавление первичного ключа к уже существующей таблице;
- ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения – удаление ограничения из таблицы.
Немного про временные таблицы
Вырезка из MSDN. В MS SQL Server существует два вида временных таблиц: локальные (#) и глобальные (##). Локальные временные таблицы видны только их создателям до завершения сеанса соединения с экземпляром SQL Server, как только они впервые созданы. Локальные временные таблицы автоматически удаляются после отключения пользователя от экземпляра SQL Server. Глобальные временные таблицы видны всем пользователям в течение любых сеансов соединения после создания этих таблиц и удаляются, когда все пользователи, ссылающиеся на эти таблицы, отключаются от экземпляра SQL Server.
Временные таблицы создаются в системной базе tempdb, т.е. создавая их мы не засоряем основную базу, в остальном же временные таблицы полностью идентичны обычным таблицам, их так же можно удалить при помощи команды DROP TABLE. Чаще используются локальные (#) временные таблицы.
Для создания временной таблицы можно использовать команду CREATE TABLE:
CREATE TABLE #Temp(
ID int,
Name nvarchar(30)
)
Так как временная таблица в MS SQL аналогична обычной таблице, ее соответственно так же можно удалить самому командой DROP TABLE:
DROP TABLE #Temp
Так же временную таблицу (как собственно и обычную таблицу) можно создать и сразу заполнить данными возвращаемые запросом используя синтаксис SELECT … INTO:
SELECT ID,Name
INTO #Temp
FROM Employees
На заметку
В разных СУБД реализация временных таблиц может отличаться. Например, в СУБД ORACLE и Firebird структура временных таблиц должна быть определена заранее командой CREATE GLOBAL TEMPORARY TABLE с указанием специфики хранения в ней данных, дальше уже пользователь видит ее среди основных таблиц и работает с ней как с обычной таблицей.
Нормализация БД – дробление на подтаблицы (справочники) и определение связей
Наша текущая таблица Employees имеет недостаток в том, что в полях Position и Department пользователь может ввести любой текст, что в первую очередь чревато ошибками, так как он у одного сотрудника может указать в качестве отдела просто «ИТ», а у второго сотрудника, например, ввести «ИТ-отдел», у третьего «IT». В итоге будет непонятно, что имел ввиду пользователь, т.е. являются ли данные сотрудники работниками одного отдела, или же пользователь описался и это 3 разных отдела? А тем более, в этом случае, мы не сможем правильно сгруппировать данные для какого-то отчета, где, может требоваться показать количество сотрудников в разрезе каждого отдела.
Второй недостаток заключается в объеме хранения данной информации и ее дублированием, т.е. для каждого сотрудника указывается полное наименование отдела, что требует в БД места для хранения каждого символа из названия отдела.
Третий недостаток – сложность обновления данных полей, в случае если изменится название какой-то должности, например, если потребуется переименовать должность «Программист», на «Младший программист». В данном случае нам придется вносить изменения в каждую строчку таблицы, у которой Должность равняется «Программист».
Чтобы избежать данных недостатков и применяется, так называемая, нормализация базы данных – дробление ее на подтаблицы, таблицы справочники. Не обязательно лезть в дебри теории и изучать что из себя представляют нормальные формы, достаточно понимать суть нормализации.
Давайте создадим 2 таблицы справочники «Должности» и «Отделы», первую назовем Positions, а вторую соответственно Departments:
CREATE TABLE Positions(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
CREATE TABLE Departments(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
Заметим, что здесь мы использовали новую опцию IDENTITY, которая говорит о том, что данные в столбце ID будут нумероваться автоматически, начиная с 1, с шагом 1, т.е. при добавлении новых записей им последовательно будут присваиваться значения 1, 2, 3, и т.д. Такие поля обычно называют автоинкрементными. В таблице может быть определено только одно поле со свойством IDENTITY и обычно, но необязательно, такое поле является первичным ключом для данной таблицы.
На заметку
В разных СУБД реализация полей со счетчиком может делаться по своему. В MySQL, например, такое поле определяется при помощи опции AUTO_INCREMENT. В ORACLE и Firebird раньше данную функциональность можно было съэмулировать при помощи использования последовательностей (SEQUENCE). Но насколько я знаю в ORACLE сейчас добавили опцию GENERATED AS IDENTITY.
Давайте заполним эти таблицы автоматически, на основании текущих данных записанных в полях Position и Department таблицы Employees:
-- заполняем поле Name таблицы Positions, уникальными значениями из поля Position таблицы Employees
INSERT Positions(Name)
SELECT DISTINCT Position
FROM Employees
WHERE Position IS NOT NULL -- отбрасываем записи у которых позиция не указана
То же самое проделаем для таблицы Departments:
INSERT Departments(Name)
SELECT DISTINCT Department
FROM Employees
WHERE Department IS NOT NULL
Если теперь мы откроем таблицы Positions и Departments, то увидим пронумерованный набор значений по полю ID:
SELECT * FROM Positions
| ID | Name |
|---|---|
| 1 | Бухгалтер |
| 2 | Директор |
| 3 | Программист |
| 4 | Старший программист |
SELECT * FROM Departments
| ID | Name |
|---|---|
| 1 | Администрация |
| 2 | Бухгалтерия |
| 3 | ИТ |
Данные таблицы теперь и будут играть роль справочников для задания должностей и отделов. Теперь мы будем ссылаться на идентификаторы должностей и отделов. В первую очередь создадим новые поля в таблице Employees для хранения данных идентификаторов:
-- добавляем поле для ID должности
ALTER TABLE Employees ADD PositionID int
-- добавляем поле для ID отдела
ALTER TABLE Employees ADD DepartmentID int
Тип ссылочных полей должен быть каким же, как и в справочниках, в данном случае это int.
Так же добавить в таблицу сразу несколько полей можно одной командой, перечислив поля через запятую:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Теперь пропишем ссылки (ссылочные ограничения — FOREIGN KEY) для этих полей, для того чтобы пользователь не имел возможности записать в данные поля, значения, отсутствующие среди значений ID находящихся в справочниках.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID
FOREIGN KEY(PositionID) REFERENCES Positions(ID)
И то же самое сделаем для второго поля:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID
FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Теперь пользователь в данные поля сможет занести только значения ID из соответствующего справочника. Соответственно, чтобы использовать новый отдел или должность, он первым делом должен будет добавить новую запись в соответствующий справочник. Т.к. должности и отделы теперь хранятся в справочниках в одном единственном экземпляре, то чтобы изменить название, достаточно изменить его только в справочнике.
Имя ссылочного ограничения, обычно является составным, оно состоит из префикса «FK_», затем идет имя таблицы и после знака подчеркивания идет имя поля, которое ссылается на идентификатор таблицы-справочника.
Идентификатор (ID) обычно является внутренним значением, которое используется только для связей и какое значение там хранится, в большинстве случаев абсолютно безразлично, поэтому не нужно пытаться избавиться от дырок в последовательности чисел, которые возникают по ходу работы с таблицей, например, после удаления записей из справочника.
Так же в некоторых случаях ссылку можно организовать по нескольким полям:
ALTER TABLE таблица ADD CONSTRAINT имя_ограничения
FOREIGN KEY(поле1,поле2,…) REFERENCES таблица_справочник(поле1,поле2,…)
В данном случае в таблице «таблица_справочник» первичный ключ представлен комбинацией из нескольких полей (поле1, поле2,…).
Собственно, теперь обновим поля PositionID и DepartmentID значениями ID из справочников. Воспользуемся для этой цели DML командой UPDATE:
UPDATE e
SET
PositionID=(SELECT ID FROM Positions WHERE Name=e.Position),
DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department)
FROM Employees e
Посмотрим, что получилось, выполнив запрос:
SELECT * FROM Employees
| ID | Name | Birthday | Position | Department | PositionID | DepartmentID | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | NULL | NULL | Директор | Администрация | 2 | 1 |
| 1001 | Петров П.П. | NULL | NULL | Программист | ИТ | 3 | 3 |
| 1002 | Сидоров С.С. | NULL | NULL | Бухгалтер | Бухгалтерия | 1 | 2 |
| 1003 | Андреев А.А. | NULL | NULL | Старший программист | ИТ | 4 | 3 |
Всё, поля PositionID и DepartmentID заполнены соответствующие должностям и отделам идентификаторами надобности в полях Position и Department в таблице Employees теперь нет, можно удалить эти поля:
ALTER TABLE Employees DROP COLUMN Position,Department
Теперь таблица у нас приобрела следующий вид:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | NULL | NULL | 2 | 1 |
| 1001 | Петров П.П. | NULL | NULL | 3 | 3 |
| 1002 | Сидоров С.С. | NULL | NULL | 1 | 2 |
| 1003 | Андреев А.А. | NULL | NULL | 4 | 3 |
Т.е. мы в итоге избавились от хранения избыточной информации. Теперь, по номерам должности и отдела можем однозначно определить их названия, используя значения в таблицах-справочниках:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName
FROM Employees e
LEFT JOIN Departments d ON d.ID=e.DepartmentID
LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
|---|---|---|---|
| 1000 | Иванов И.И. | Директор | Администрация |
| 1001 | Петров П.П. | Программист | ИТ |
| 1002 | Сидоров С.С. | Бухгалтер | Бухгалтерия |
| 1003 | Андреев А.А. | Старший программист | ИТ |
В инспекторе объектов мы можем увидеть все объекты, созданные для в данной таблицы. Отсюда же можно производить разные манипуляции с данными объектами – например, переименовывать или удалять объекты.
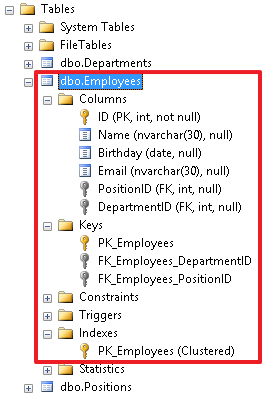
Так же стоит отметить, что таблица может ссылаться сама на себя, т.е. можно создать рекурсивную ссылку. Для примера добавим в нашу таблицу с сотрудниками еще одно поле ManagerID, которое будет указывать на сотрудника, которому подчиняется данный сотрудник. Создадим поле:
ALTER TABLE Employees ADD ManagerID int
В данном поле допустимо значение NULL, поле будет пустым, если, например, над сотрудником нет вышестоящих.
Теперь создадим FOREIGN KEY на таблицу Employees:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID
FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
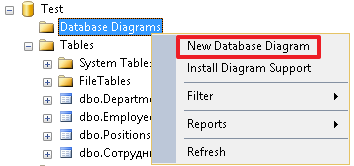
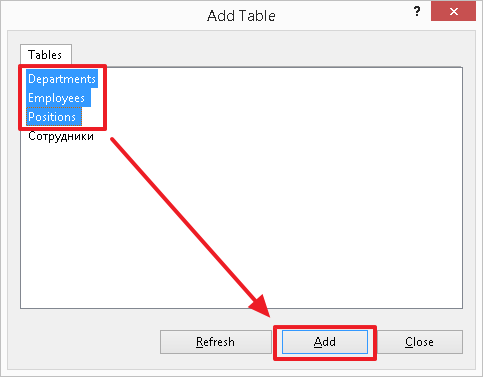
Давайте, теперь создадим диаграмму и посмотрим, как выглядят на ней связи между нашими таблицами:
В результате мы должны увидеть следующую картину (таблица Employees связана с таблицами Positions и Depertments, а так же ссылается сама на себя):
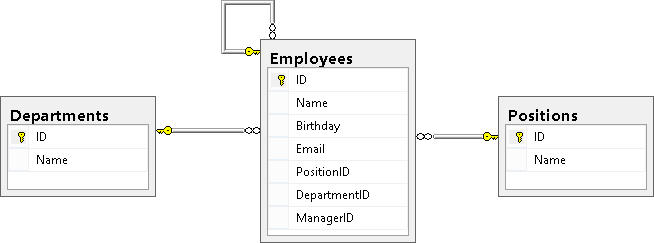
Напоследок стоит сказать, что ссылочные ключи могут включать дополнительные опции ON DELETE CASCADE и ON UPDATE CASCADE, которые говорят о том, как вести себя при удалении или обновлении записи, на которую есть ссылки в таблице-справочнике. Если эти опции не указаны, то мы не можем изменить ID в таблице справочнике у той записи, на которую есть ссылки из другой таблицы, так же мы не сможем удалить такую запись из справочника, пока не удалим все строки, ссылающиеся на эту запись или, же обновим в этих строках ссылки на другое значение.
Для примера пересоздадим таблицу с указанием опции ON DELETE CASCADE для FK_Employees_DepartmentID:
DROP TABLE Employees
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
ON DELETE CASCADE,
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
)
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219',2,1,NULL),
(1001,N'Петров П.П.','19831203',3,3,1003),
(1002,N'Сидоров С.С.','19760607',1,2,1000),
(1003,N'Андреев А.А.','19820417',4,3,1000)
Удалим отдел с идентификатором 3 из таблицы Departments:
DELETE Departments WHERE ID=3
Посмотрим на данные таблицы Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Сидоров С.С. | 1976-06-07 | NULL | 1 | 2 | 1000 |
Как видим, данные по отделу 3 из таблицы Employees так же удалились.
Опция ON UPDATE CASCADE ведет себя аналогично, но действует она при обновлении значения ID в справочнике. Например, если мы поменяем ID должности в справочнике должностей, то в этом случае будет производиться обновление DepartmentID в таблице Employees на новое значение ID которое мы задали в справочнике. Но в данном случае это продемонстрировать просто не получится, т.к. у колонки ID в таблице Departments стоит опция IDENTITY, которая не позволит нам выполнить следующий запрос (сменить идентификатор отдела 3 на 30):
UPDATE Departments
SET
ID=30
WHERE ID=3
Главное понять суть этих 2-х опций ON DELETE CASCADE и ON UPDATE CASCADE. Я применяю эти опции очень в редких случаях и рекомендую хорошо подумать, прежде чем указывать их в ссылочном ограничении, т.к. при нечаянном удалении записи из таблицы справочника это может привести к большим проблемам и создать цепную реакцию.
Восстановим отдел 3:
-- даем разрешение на добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name) VALUES(3,N'ИТ')
-- запрещаем добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments OFF
Полностью очистим таблицу Employees при помощи команды TRUNCATE TABLE:
TRUNCATE TABLE Employees
И снова перезальем в нее данные используя предыдущую команду INSERT:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219',2,1,NULL),
(1001,N'Петров П.П.','19831203',3,3,1003),
(1002,N'Сидоров С.С.','19760607',1,2,1000),
(1003,N'Андреев А.А.','19820417',4,3,1000)
Подытожим
На данным момент к нашим знаниям добавилось еще несколько команд DDL:
- Добавление свойства IDENTITY к полю – позволяет сделать это поле автоматически заполняемым (полем-счетчиком) для таблицы;
- ALTER TABLE имя_таблицы ADD перечень_полей_с_характеристиками – позволяет добавить новые поля в таблицу;
- ALTER TABLE имя_таблицы DROP COLUMN перечень_полей – позволяет удалить поля из таблицы;
- ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения FOREIGN KEY(поля) REFERENCES таблица_справочник(поля) – позволяет определить связь между таблицей и таблицей справочником.
Прочие ограничения – UNIQUE, DEFAULT, CHECK
При помощи ограничения UNIQUE можно сказать что значения для каждой строки в данном поле или в наборе полей должно быть уникальным. В случае таблицы Employees, такое ограничение мы можем наложить на поле Email. Только предварительно заполним Email значениями, если они еще не определены:
UPDATE Employees SET Email='i.ivanov@test.tt' WHERE ID=1000
UPDATE Employees SET Email='p.petrov@test.tt' WHERE ID=1001
UPDATE Employees SET Email='s.sidorov@test.tt' WHERE ID=1002
UPDATE Employees SET Email='a.andreev@test.tt' WHERE ID=1003
А теперь можно наложить на это поле ограничение-уникальности:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Теперь пользователь не сможет внести один и тот же E-Mail у нескольких сотрудников.
Ограничение уникальности обычно именуется следующим образом – сначала идет префикс «UQ_», далее название таблицы и после знака подчеркивания идет имя поля, на которое накладывается данное ограничение.
Соответственно если уникальной в разрезе строк таблицы должна быть комбинация полей, то перечисляем их через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения UNIQUE(поле1,поле2,…)
При помощи добавления к полю ограничения DEFAULT мы можем задать значение по умолчанию, которое будет подставляться в случае, если при вставке новой записи данное поле не будет перечислено в списке полей команды INSERT. Данное ограничение можно задать непосредственно при создании таблицы.
Давайте добавим в таблицу Employees новое поле «Дата приема» и назовем его HireDate и скажем что значение по умолчанию у данного поля будет текущая дата:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
Или если столбец HireDate уже существует, то можно использовать следующий синтаксис:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
Здесь я не указал имя ограничения, т.к. в случае DEFAULT у меня сложилось мнение, что это не столь критично. Но если делать по-хорошему, то, думаю, не нужно лениться и стоит задать нормальное имя. Делается это следующим образом:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
Та как данного столбца раньше не было, то при его добавлении в каждую запись в поле HireDate будет вставлено текущее значение даты.
При добавлении новой записи, текущая дата так же будет вставлена автоматом, конечно если мы ее явно не зададим, т.е. не укажем в списке столбцов. Покажем это на примере, не указав поле HireDate в перечне добавляемых значений:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Сергеев С.С.','s.sergeev@test.tt')
Посмотрим, что получилось:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | p.petrov@test.tt | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Андреев А.А. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Сергеев С.С. | NULL | s.sergeev@test.tt | NULL | NULL | NULL | 2015-04-08 |
Проверочное ограничение CHECK используется в том случае, когда необходимо осуществить проверку вставляемых в поле значений. Например, наложим данное ограничение на поле табельный номер, которое у нас является идентификатором сотрудника (ID). При помощи данного ограничения скажем, что табельные номера должны иметь значение от 1000 до 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
Ограничение обычно именуется так же, сначала идет префикс «CK_», затем имя таблицы и имя поля, на которое наложено это ограничение.
Попробуем вставить недопустимую запись для проверки, что ограничение работает (мы должны получить соответствующую ошибку):
INSERT Employees(ID,Email) VALUES(2000,'test@test.tt')
А теперь изменим вставляемое значение на 1500 и убедимся, что запись вставится:
INSERT Employees(ID,Email) VALUES(1500,'test@test.tt')
Можно так же создать ограничения UNIQUE и CHECK без указания имени:
ALTER TABLE Employees ADD UNIQUE(Email)
ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Но это не очень хорошая практика и лучше задавать имя ограничения в явном виде, т.к. чтобы разобраться потом, что будет сложнее, нужно будет открывать объект и смотреть, за что он отвечает.
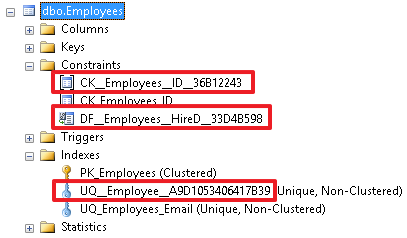
При хорошем наименовании много информации об ограничении можно узнать непосредственно по его имени.
И, соответственно, все эти ограничения можно создать сразу же при создании таблицы, если ее еще нет. Удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями одной командой CREATE TABLE:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL DEFAULT SYSDATETIME(), -- для DEFAULT я сделаю исключение
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT UQ_Employees_Email UNIQUE (Email),
CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999)
)
Напоследок вставим в таблицу наших сотрудников:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES
(1000,N'Иванов И.И.','19550219','i.ivanov@test.tt',2,1),
(1001,N'Петров П.П.','19831203','p.petrov@test.tt',3,3),
(1002,N'Сидоров С.С.','19760607','s.sidorov@test.tt',1,2),
(1003,N'Андреев А.А.','19820417','a.andreev@test.tt',4,3)
Немного про индексы, создаваемые при создании ограничений PRIMARY KEY и UNIQUE
Как можно увидеть на скриншоте выше, при создании ограничений PRIMARY KEY и UNIQUE автоматически создались индексы с такими же названиями (PK_Employees и UQ_Employees_Email). По умолчанию индекс для первичного ключа создается как CLUSTERED, а для всех остальных индексов как NONCLUSTERED. Стоит сказать, что понятие кластерного индекса есть не во всех СУБД. Таблица может иметь только один кластерный (CLUSTERED) индекс. CLUSTERED – означает, что записи таблицы будут сортироваться по этому индексу, так же можно сказать, что этот индекс имеет непосредственный доступ ко всем данным таблицы. Это так сказать главный индекс таблицы. Если сказать еще грубее, то это индекс, прикрученный к таблице. Кластерный индекс – это очень мощное средство, которое может помочь при оптимизации запросов, пока просто запомним это. Если мы хотим сказать, чтобы кластерный индекс использовался не в первичном ключе, а для другого индекса, то при создании первичного ключа мы должны указать опцию NONCLUSTERED:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения
PRIMARY KEY NONCLUSTERED(поле1,поле2,…)
Для примера сделаем индекс ограничения PK_Employees некластерным, а индекс ограничения UQ_Employees_Email кластерным. Первым делом удалим данные ограничения:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
А теперь создадим их с опциями CLUSTERED и NONCLUSTERED:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID)
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Теперь, выполнив выборку из таблицы Employees, мы увидим, что записи отсортировались по кластерному индексу UQ_Employees_Email:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
|---|---|---|---|---|---|---|
| 1003 | Андреев А.А. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 2015-04-08 |
| 1000 | Иванов И.И. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | p.petrov@test.tt | 3 | 3 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 2015-04-08 |
До этого, когда кластерным индексом был индекс PK_Employees, записи по умолчанию сортировались по полю ID.
Но в данном случае это всего лишь пример, который показывает суть кластерного индекса, т.к. скорее всего к таблице Employees будут делаться запросы по полю ID и в каких-то случаях, возможно, она сама будет выступать в роли справочника.
Для справочников обычно целесообразно, чтобы кластерный индекс был построен по первичному ключу, т.к. в запросах мы часто ссылаемся на идентификатор справочника для получения, например, наименования (Должности, Отдела). Здесь вспомним, о чем я писал выше, что кластерный индекс имеет прямой доступ к строкам таблицы, а отсюда следует, что мы можем получить значение любого столбца без дополнительных накладных расходов.
Кластерный индекс выгодно применять к полям, по которым выборка идет наиболее часто.
Иногда в таблицах создают ключ по суррогатному полю, вот в этом случае бывает полезно сохранить опцию CLUSTERED индекс для более подходящего индекса и указать опцию NONCLUSTERED при создании суррогатного первичного ключа.
Подытожим
На данном этапе мы познакомились со всеми видами ограничений, в их самом простом виде, которые создаются командой вида «ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения …»:
- PRIMARY KEY – первичный ключ;
- FOREIGN KEY – настройка связей и контроль ссылочной целостности данных;
- UNIQUE – позволяет создать уникальность;
- CHECK – позволяет осуществлять корректность введенных данных;
- DEFAULT – позволяет задать значение по умолчанию;
- Так же стоит отметить, что все ограничения можно удалить, используя команду «ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения».
Так же мы частично затронули тему индексов и разобрали понятие кластерный (CLUSTERED) и некластерный (NONCLUSTERED) индекс.
Создание самостоятельных индексов
Под самостоятельностью здесь имеются в виду индексы, которые создаются не для ограничения PRIMARY KEY или UNIQUE.
Индексы по полю или полям можно создавать следующей командой:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Так же здесь можно указать опции CLUSTERED, NONCLUSTERED, UNIQUE, а так же можно указать направление сортировки каждого отдельного поля ASC (по умолчанию) или DESC:
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
При создании некластерного индекса опцию NONCLUSTERED можно отпустить, т.к. она подразумевается по умолчанию, здесь она показана просто, чтобы указать позицию опции CLUSTERED или NONCLUSTERED в команде.
Удалить индекс можно следующей командой:
DROP INDEX IDX_Employees_Name ON Employees
Простые индексы так же, как и ограничения, можно создать в контексте команды CREATE TABLE.
Для примера снова удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями и индексами одной командой CREATE TABLE:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(),
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID),
CONSTRAINT UQ_Employees_Email UNIQUE(Email),
CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999),
INDEX IDX_Employees_Name(Name)
)
Напоследок вставим в таблицу наших сотрудников:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219','i.ivanov@test.tt',2,1,NULL),
(1001,N'Петров П.П.','19831203','p.petrov@test.tt',3,3,1003),
(1002,N'Сидоров С.С.','19760607','s.sidorov@test.tt',1,2,1000),
(1003,N'Андреев А.А.','19820417','a.andreev@test.tt',4,3,1000)
Дополнительно стоит отметить, что в некластерный индекс можно включать значения при помощи указания их в INCLUDE. Т.е. в данном случае INCLUDE-индекс чем-то будет напоминать кластерный индекс, только теперь не индекс прикручен к таблице, а необходимые значения прикручены к индексу. Соответственно, такие индексы могут очень повысить производительность запросов на выборку (SELECT), если все перечисленные поля имеются в индексе, то возможно обращений к таблице вообще не понадобится. Но это естественно повышает размер индекса, т.к. значения перечисленных полей дублируются в индексе.
Вырезка из MSDN. Общий синтаксис команды для создания индексов
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ]
Подытожим
Индексы могут повысить скорость выборки данных (SELECT), но индексы уменьшают скорость модификации данных таблицы, т.к. после каждой модификации системе будет необходимо перестроить все индексы для конкретной таблицы.
Желательно в каждом случае найти оптимальное решение, золотую середину, чтобы и производительность выборки, так и модификации данных была на должном уровне. Стратегия по созданию индексов и их количества может зависеть от многих факторов, например, насколько часто изменяются данные в таблице.
Заключение по DDL
Как можно увидеть, язык DDL не так сложен, как может показаться на первый взгляд. Здесь я смог показать практически все его основные конструкции, оперируя всего тремя таблицами.
Главное — понять суть, а остальное дело практики.
Удачи вам в освоении этого замечательного языка под названием SQL.
Часть вторая — habrahabr.ru/post/255523
You’re not alone if you’ve ever felt overwhelmed working with SQL Server Management Studios (SMSS). Figuring out how to use all features SMSS offers can be tricky. But take it easy. This tutorial is just what you need to get started.
In this tutorial, you’ll learn the basics of working with SSMS, like connecting to a server, running queries, and creating databases.
Read on and take your SQL server management skills to the next level!
Prerequisites
This tutorial will be a hands-on demonstration. If you’d like to follow along, be sure you have the following.
- A Windows machine – This tutorial uses Windows 10, but later versions will also work.
- MySQL Server installed on your machine – You can use Microsoft SQL Server Express, a free, lightweight version of SQL Server.
- A MySQL database server to connect to (local machine or a remote server).
Downloading and Installing SQL Server Management Studio (SSMS)
SSMS is a free integrated environment for managing any SQL infrastructure, from SQL Server to Azure SQL Database. SMSS provides a GUI to manage databases and objects on your server.
But before running queries or creating databases, you’ll first have to ensure SSMS is installed correctly. So write and test queries, and create and alter database schema on your local machine or in the cloud.
1. Open your favorite web browser, and head to SMSS’s download page.
2. Scroll down to the Download SSMS section and click the Free Download for SQL Server Management Studio (SSMS) hyperlink to start the download.
The file’s size is about 700MB, so the download process might take a few minutes to complete, depending on your internet connection.
3. Double-click the downloaded file to launch the SSMS installer.
4. Finally, click Install to start the installation process.
You can change the default installation directory if you want, but the default location is fine for most users.
SSMS loads, extracts, and installs the required files, which may take a few minutes.
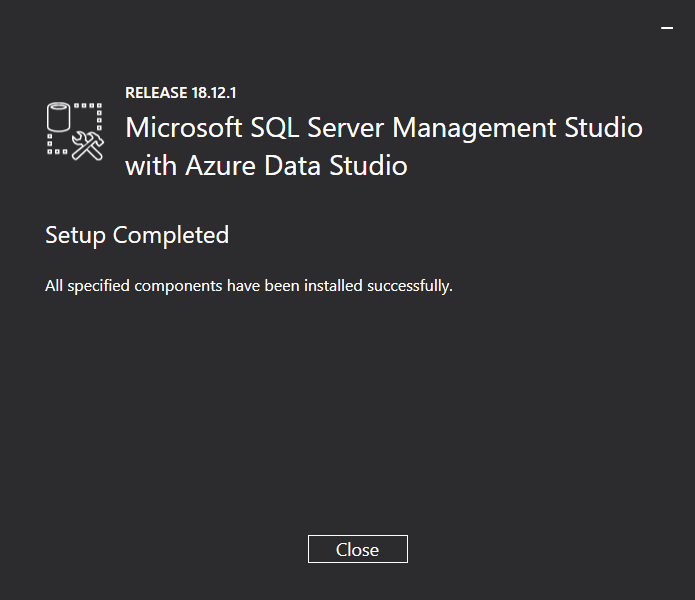
Once the installation completes, you’ll see the Setup Completed screen below.
Congratulations! You’ve successfully installed SSMS on your machine.
Verifying the MySQL Server is Running, and TCP/IP Port is Open
You’ve just installed SSMS, but you need to connect to a database server before you can do SQL server management. For this tutorial, you’ll connect to a MySQL server via SSMS.
Trying to connect to a MySQL server at the moment would be a stretch. So, first things first. Ensure your MySQL server is running and your TCP/IP port is open.
1. Open a PowerShell as administrator for elevated privileges.
2. Next, run the following ping command to verify your TCP/IP port is open. Replace your-ip with your MySQL database server’s IP address.
The ping responses in the output below indicate your MySQL database server is reachable.
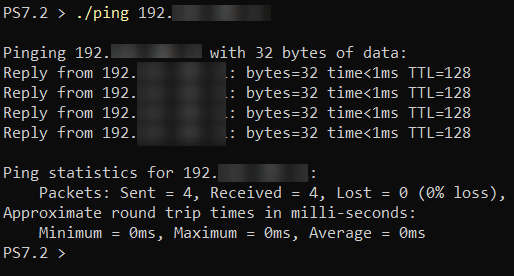
If you get a Request timed out error, like the one below, your database server is unreachable, and you need to check your network configuration.

3. Finally, run the below commands to check if the MySQL database server is running.
# Gets running services that contain the words "sql server"
Get-Service | Where {$_.status -eq 'running' -and $_.DisplayName -match "sql server*"}
# Verifies the MySQL (MSSQL15) folder exists
Get-ChildItem -Path "C:Program FilesMicrosoft SQL Servermssql*" -Recurse -Include Errorlog |select-string "SQL Server is now ready for client connections.” 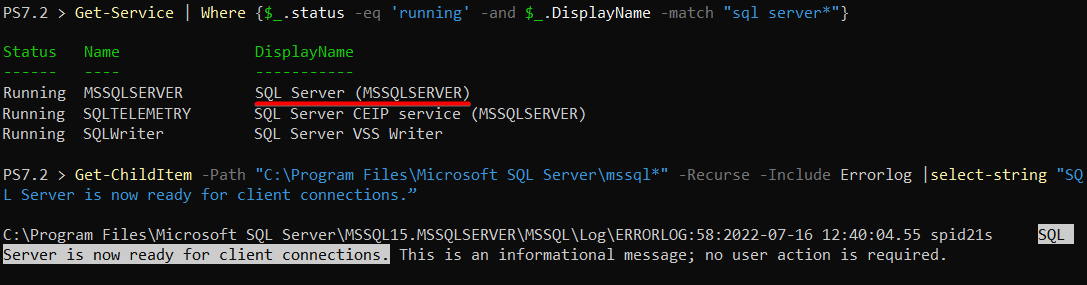
If the database engine service isn’t running, launch the Windows Services, and restart the service, as shown below.
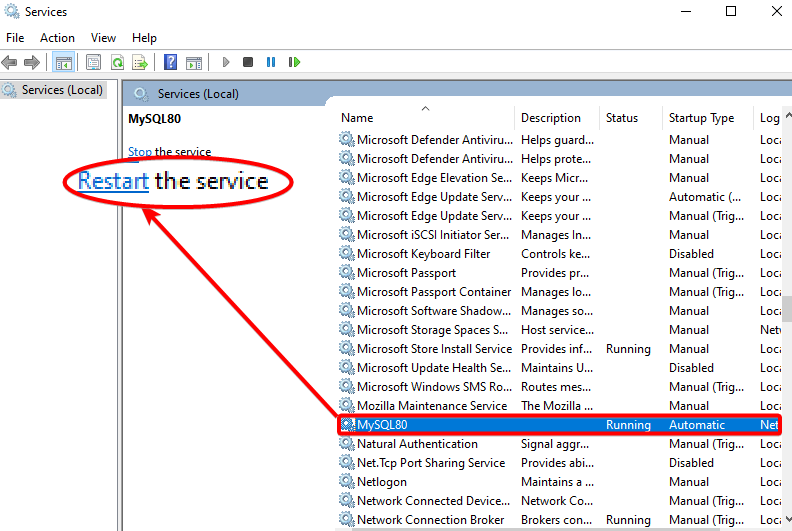
Connecting to the MySQL Database Server
Your MySQL database server is running, and that’s a good start. But the server doesn’t do much right now. To manage SQL databases, you’ll need to connect to your database server via SSMS.
Open SSMS, and you’ll be greeted with the Connect to Server dialog box shown below the first time you launch the tool.
Connect to your MySQL database server with the following:
- Server name – Input your MySQL database server’s IP address or hostname. If you’re running SSMS on the same machine as your database server, you can put localhost as the server name instead.
- Authentication – Select Windows Authentication to connect to the database server using Windows Authentication, which is more secure.
- Click the Connect button to connect to the database server.
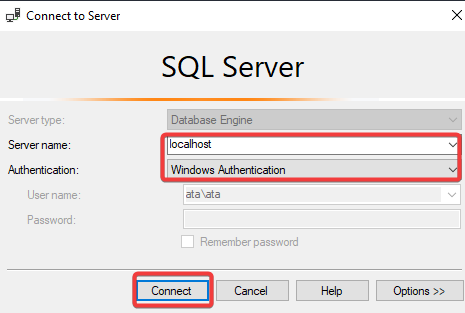
If you didn’t get the Connect to Server dialog box, click the Connect button (top-left) under the Object Explorer pane, and select Database Engine.
The Object Explorer is a tree view control that lets you browse objects in your database server — like File Explorer.
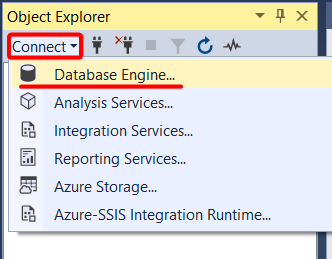
Once connected to the database server, you’ll see the Object Explorer populate with your database server and various objects within each database.
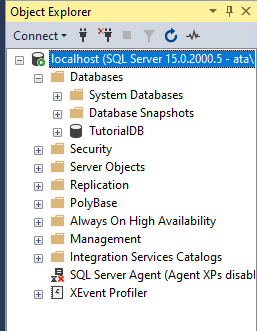
Creating a New Database
After connecting to your database server, it’s time to fill it up with databases and tables and insert data into tables. Having a central location (database) for all your data makes data fetching quicker when you need it.
To create a new database using SSMS:
1. In the Object Explorer panel, select the Databases node and click New Query at the toolbar, which opens a new query window (step two).
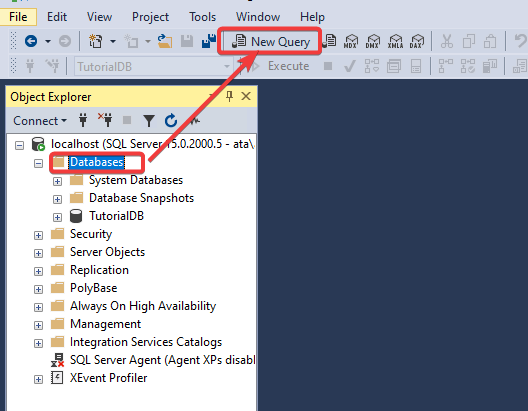
2. In the query window, enter the following T-SQL snippet, which checks if a database with the name ATADB already exists.
If the database exists, the statement does nothing. But if the database doesn’t exist, the statement creates a new database named ATADB.
-- Use the master database.
USE master
GO
-- Check if a database named ATADB exists.
IF NOT EXISTS (
SELECT name
FROM sys.databases
WHERE name = N'ATADB'
-- If the ATADB database exists, do nothing.
)
-- If the ATADB database doesn't exist, create the database.
CREATE DATABASE [ATADB]
GO3. Press F5 or click Execute to run the query, as shown below.
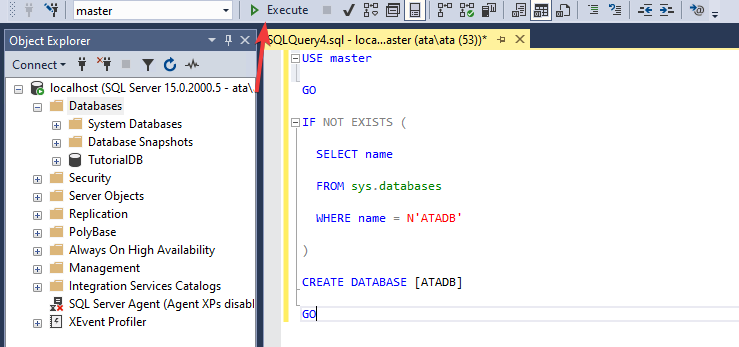
After running the query, you’ll see a message that says Command(s) completed successfully if the database is created successfully. The Completion time is the time SSMS took to execute the query and create the database.
4. Finally, click on the refresh icon in the Object Explorer panel, and you’ll see the newly created database ATADB.
Creating a New Table
You’ve just created a database and know what’s next — a table. A table lets you store data, organized in columns and tables.
To create a new table in SSMS:
1. Copy and paste the following SQL snippet into the query window, which creates a table called Users in the ATADB database. This table will have four columns: CustomerId, Name, Location, and Email.
The first column (CustomerId) is the primary key of the table. A primary key is a column that uniquely identifies each row in the table. The other columns are just regular data columns.
Notice a data type associated with each column:
- The
CustomerIdcolumn is anINTdata type used for storing whole numbers.
- The Name, Location, and Email columns are all NVARCHAR data types that store text data.
-- Use the ATADB database
USE [ATADB]
-- Check if the Users table
IF OBJECT_ID ('dbo.Users', 'U') IS NOT NULL
-- If the Users table exists, delete the table
DROP TABLE dbo.Users
GO
-- Create the Users table if it doesn't exist
CREATE TABLE dbo.Users
(
-- Primary key column
CustomerId INT NOT NULL PRIMARY KEY,
-- Regular columns
Name [NVARCHAR](50) NOT NULL,
Location [NVARCHAR](50) NOT NULL,
Email [NVARCHAR](50) NOT NULL
);
GO2. Execute the query to create the Users table if it doesn’t exist.
3. Lastly, click on the refresh icon again in the Object Explorer panel to see the newly created table (Users).
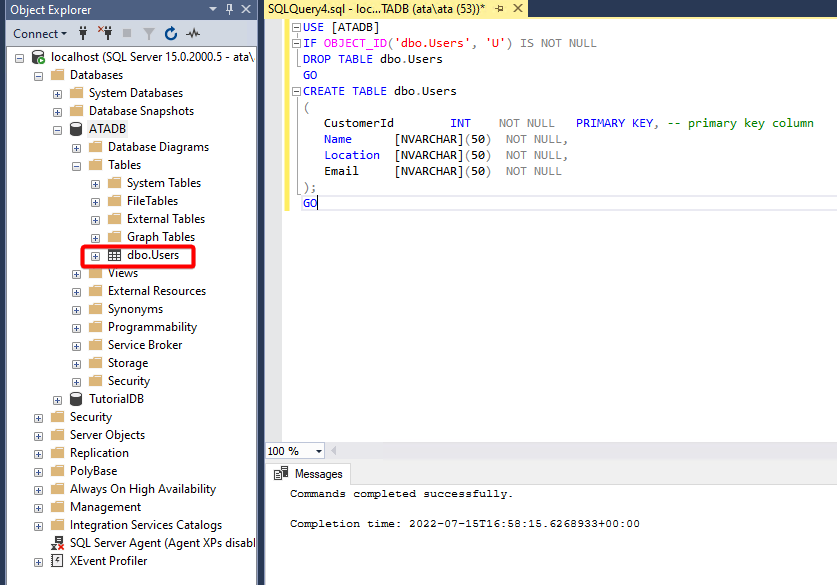
Inserting Data Into a Table
An empty table wouldn’t be useful, so why not insert data into your newly-created Users table? Inserting data into a table is just like copying and pasting text to a sheet’s cells. But with SSMS, you use the INSERT INTO query instead.
Populate the SQL snippet below to the query window to INSERT data INTO the Users table on each column respectively.
-- Insert data into the columns in the Users table
INSERT INTO dbo.Users
([CustomerId],[Name],[Location],[Email])
-- Set the values to add to the Users table
VALUES
( 1, N'Adam', N'US', N''),
( 2, N'Listek', N'India', N'[email protected]'),
( 3, N'Donna', N'Germany', N'[email protected]'),
( 4, N'Janet', N'United States', N'[email protected]')
GO
Execute the query and see SSMS inserts data into the Users table.
You can see below that the message says 4 rows affected. Jump to the following step to see the actual data.
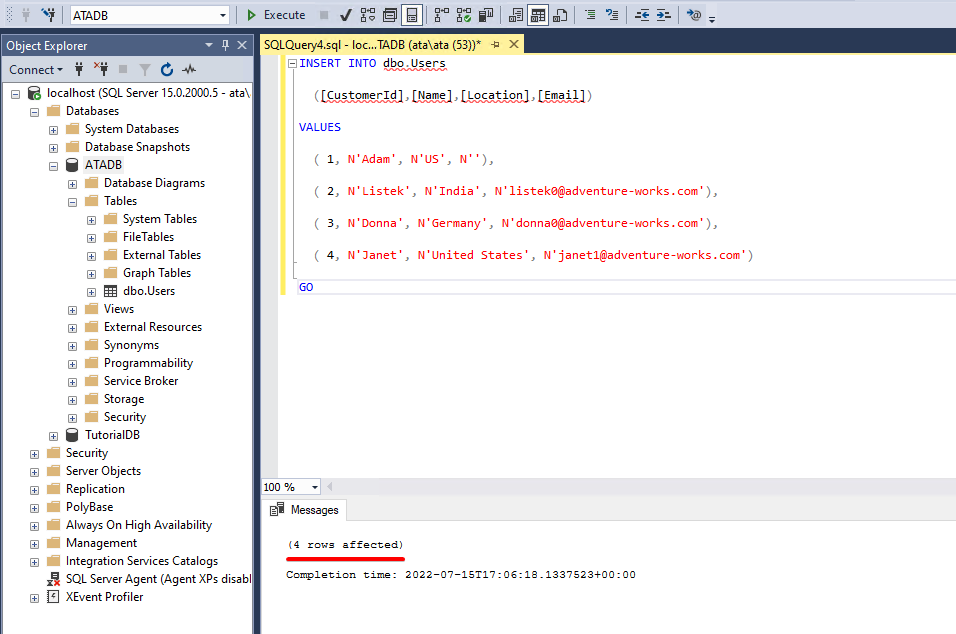
Querying Data From a Table
You’ve successfully inserted data to your Users table, but how do you verify that? Execute an SQL snippet to view the actual data inserted into your Users table.
Put the following SQL snippet into the query window. This query will SELECT all (*) of the columns and rows from the Users table.
Execute the query, and you’ll see the data from the Users table in the results pane, as shown below.
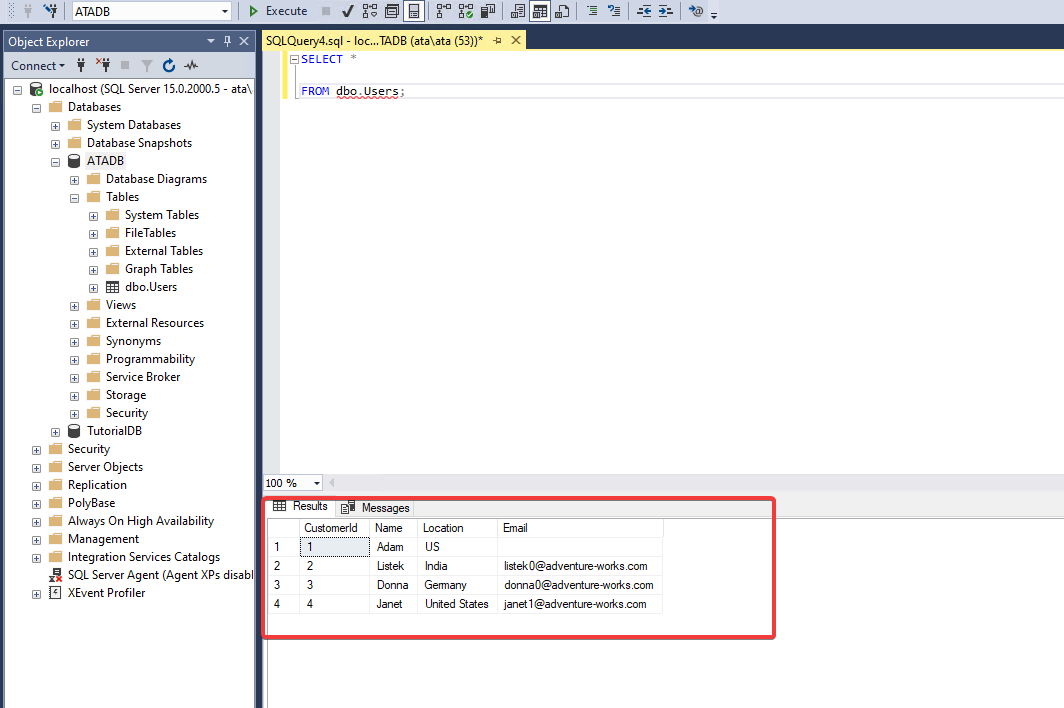
Conclusion
In this tutorial, you’ve learned how to install and use SQL Server Management Studio (SSMS) to create a database and table. You’ve inserted data into a table and realized how SSMS makes your life easier managing data in your database by verifying data in an actual table.
Why not use pre-built templates to quickly create databases to build on this newfound knowledge? Or perhaps create shortcut key bindings to work with SSMS easier?
In my earlier article, I’ve explained how to install SQL Server Developer Edition. In this article, I’ll walk you through Microsoft SQL Server Management Studio (SSMS) and how to connect to SQL Server Instance using management studio.
I’ve divided the management studio section into 2 parts. This is part 1. I’ll write the part 2 in the next article.
- In this first part, we will see about SSMS.
- How to login to SQL Server Management Studio.
- How to connect to SQL Server.
- About Object explorer window and how to use it.
- About Object explorer details window.
- About Properties window.
Video Walk Through On SQL Server Management Studio – Part-1
What is SSMS?
- SSMS is the short form of SQL Server Management Studio.
- Management studio is not a database. It’s just a client application or an user interface to connect to SQL Server installed in local pc or in a network on a server.
- Using SSMS we can configure, manage and administer the SQL Server components like Database, Reporting Services, Analysis Services, SQL Server agent, etc.
- SSMS connecting SQL Server:

- This is a diagrammatic representation of how the SSMS can connect to the SQL Server.
- In the right side of the diagram, there is a personal computer. In the computer both the SQL Server and SSMS are installed together. The SSMS in the PC can connect to the PC’s Local SQL Server. This is a straight forward way.
- This will not be the case in a big company or an organization or in a production environment.
- In companies, SQL Server is normally installed on a data server. The data server can be connected through the network.
- For example, in the left side of the diagram, the laptop and the workstations are connected to the SQL Server in the network. The laptop and workstation have SSMS installed in them.
- The developer can launch the SSMS from the laptop and connect to the SQL Server instance using the server’s IP or name.
- Management studio can also connect to SQL Server through the internet, provided the server has a static IP or registered domain name.
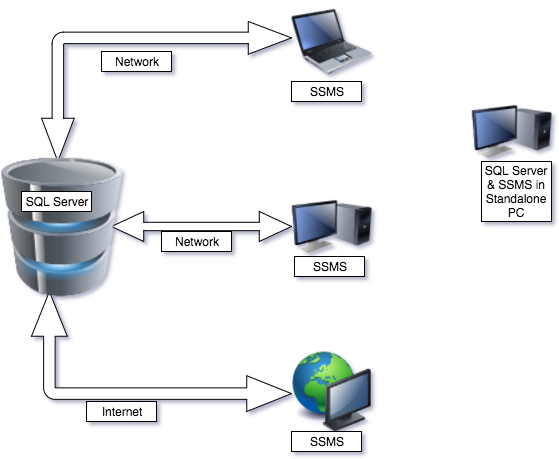
Starting SSMS
- To launch SSMS: I’m using Windows 10. In windows-10 first you have to go to start icon and then to All Apps.
- In all apps, scroll down and find Microsoft SQL Server 2014 folder.
- Under Microsoft SQL Server 2014 folder look for SQL Server 2014 Management Studio and click.

- The login screen of management screen will appear.

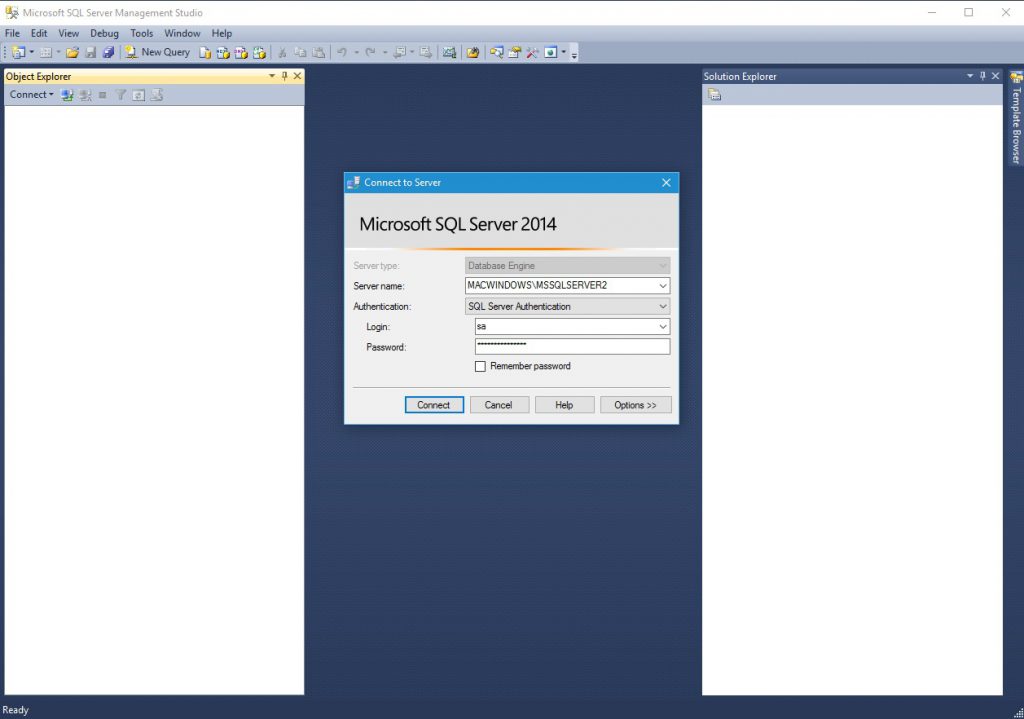
Connecting SQL Server
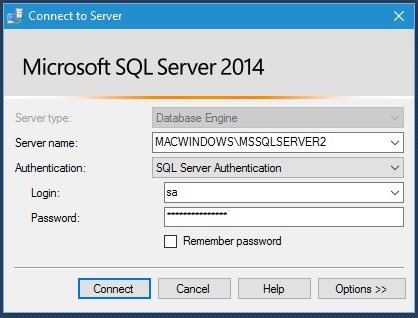
In the login screen there are several fields to configure the SQL Server connection details. Let’s see about the fields one by one.
Server Type
The first field in the login window is the server type. There are four server types:
- The Database Engine, which has the database and other database components.
- Analysis Services, which is used in decision support and business analysis.
- Reporting Services, which is used for generating user-friendly reports.
- Integration Services, which is used for building enterprise-level data integration and data transformations solutions.
As we are dealing with the database now, select the server type as Database Engine in Server Type Field.
Server Name
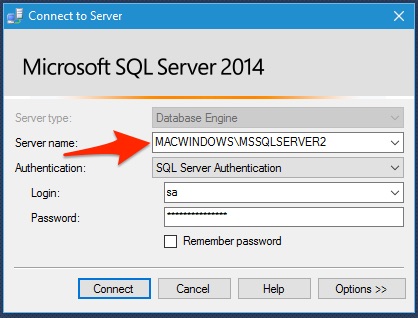
The second field is the Server Name. In the server field we have to enter the name or the IP address of the server where SQL Server database engine is installed. If there is a named instance then we have to specify the instance name after the slash.
An SQL Server Instance is a complete SQL server. You can install more than one instances, I mean more than one SQL Server on a machine or pc. Only one of them will be the default instance with just the name of the server or PC. The other instances are called as named instances. The named instances needs to be specified with the instance name along with the server or computer’s name.
Here MACWINDOWS is the server name and MSSQLSERVER2 is the instance name.
In case if the SQL Server is in the same machine along with the SSMS then you can just enter “.” to connect to the default local instance of the SQL server. Another option is to enter “local” in opening and closing brackets.
Even though my SQL server is installed in the same PC as the SSMS, I’m entering the PC’s name followed by a slash and the instance name. This is because, I have more than one instance of SQL Server in my PC.
Authentication
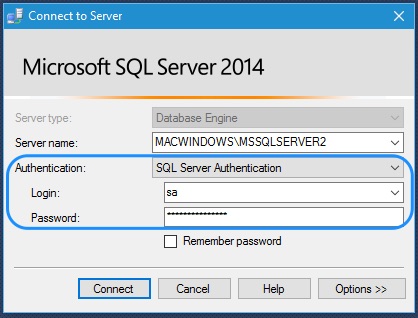
The next field is the authentication type. There are 2 types of authentication, the windows authentication and the SQL Server authentication.
- If you select windows authentication, then the login process will use the current logged in windows user credentials.
- If you select SQL Server authentication, then you have to enter the SQL server login password. If this is a fresh installation of SQL server, then login with the user name “sa” and password you have provided during the SQL Server installation.
Remember Password
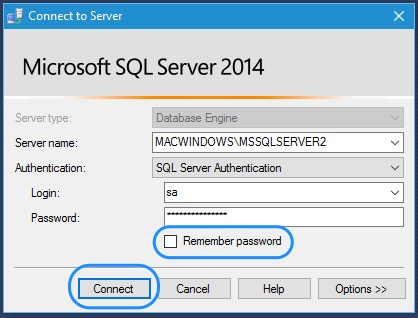
The last and the optional field is Remember password. If you have to frequently use SSMS in your secured PC or workstation, then use the remember password option.
Finally press the Connect button to connect to the SQL Server Database Engine. Now you will be logged in to the SQL Server Management Studio.
SQL Server Management Studio Components
The SQL Server Management Studio’s User Interface is divided into 2 major panels. The object explorer window and the document window.
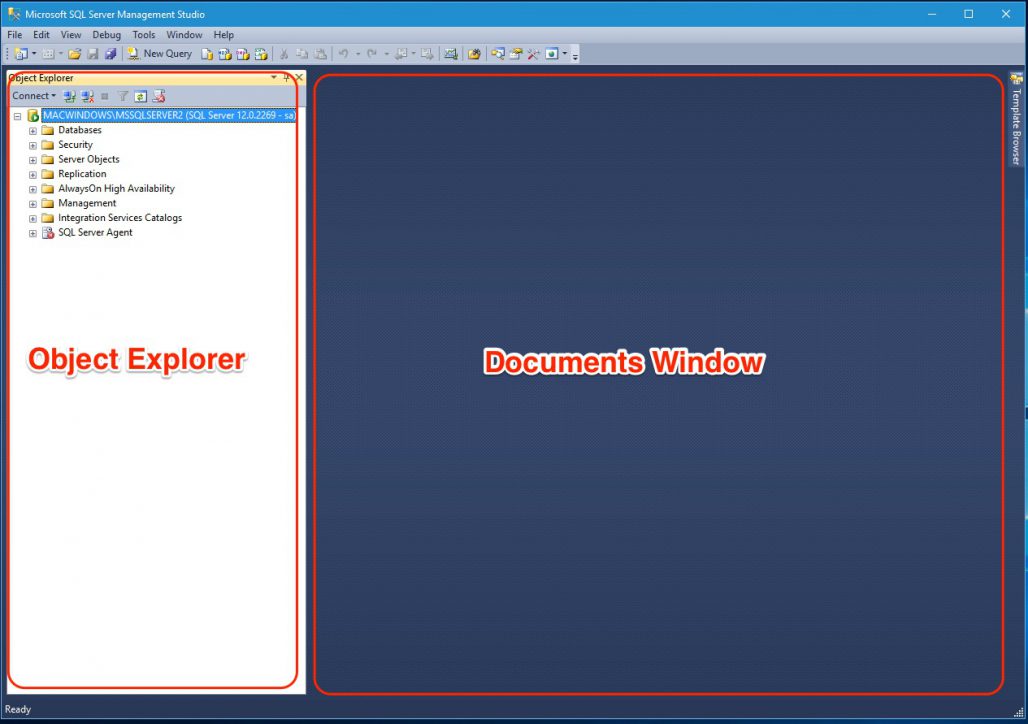
Object Explorer Window
- The panel you are seeing in the left side is the Object Explorer.
- Object Explorer lists down all the connected servers, their databases and other database objects and SQL Server Agent in tree structure.
- The objects other than database you can see in this window are security and logins, roles and credentials, etc.
- In the management section, you can see the database management objects like the maintenance plan, backup manager, SQL Server logs, etc.
- In SQL Server agent section, you can see the SQL jobs, alerts and error logs.
- After logging in to SSMS, if you want to connect to another server:
- Press the connect icon at the top of the Object explorer window.

- The SSMS login window will pop-up.
- In the login window, type in the other SQL Server name, enter the authentication details and press Connect.
- Now the SQL server will be connected and added to the tree view in the object explorer.
- If you want to remove the SQL server from the object explorer tree view, Select the SQL server you want to remove and press the disconnect icon, the disconnect icon is next to the connect icon. On disconnecting, the SQL server will disappear from the tree view.

- Press the connect icon at the top of the Object explorer window.
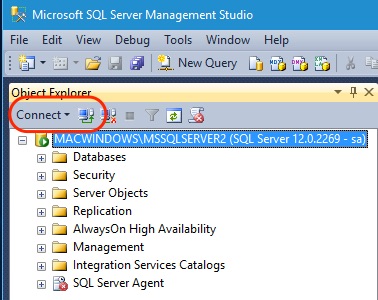
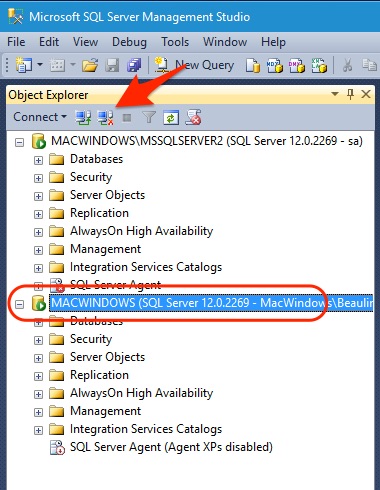
Document Window
The documents window panel is the most important part of the Management Studio, it shows the Object explorer details window, SQL query editor window, browser window, etc..
Object Explorer Details Window
The object explorer details window, as the name suggests, will show the details of the object you select in the Object explorer.
- To open object explorer detail window, go to the View menu and select Object Explorer Details.
- The details widow will open in the panel right to the object explorer.
- This window will show the details of the object you are selecting in the Object explorer.

- Most of the details displayed in the details window is also available in the properties pop-up screen.

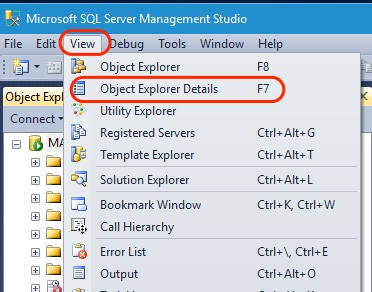
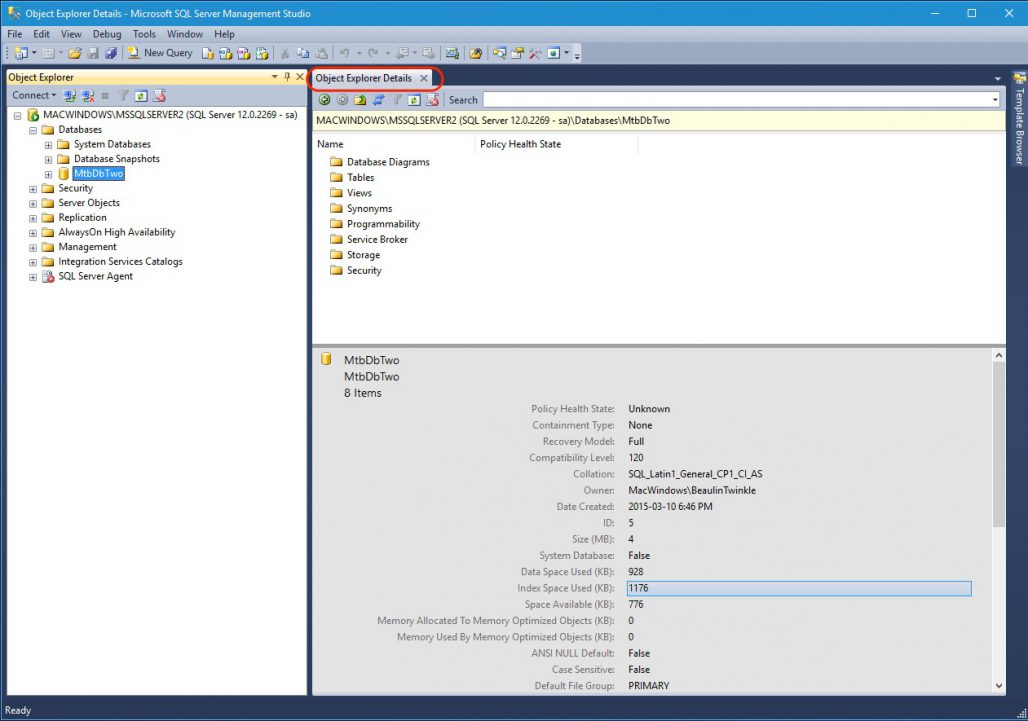
Properties Window
- To launch the properties screen, select an object, right-click. From the right-click menu select properties.

- This pop-up window show the detailed properties of the selected object.

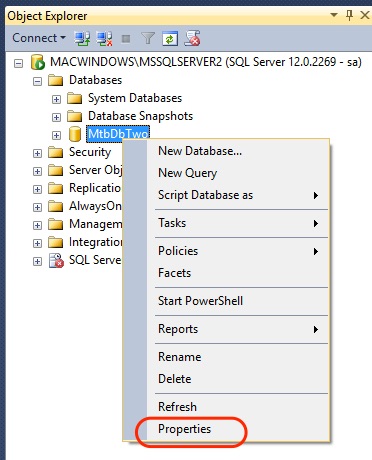
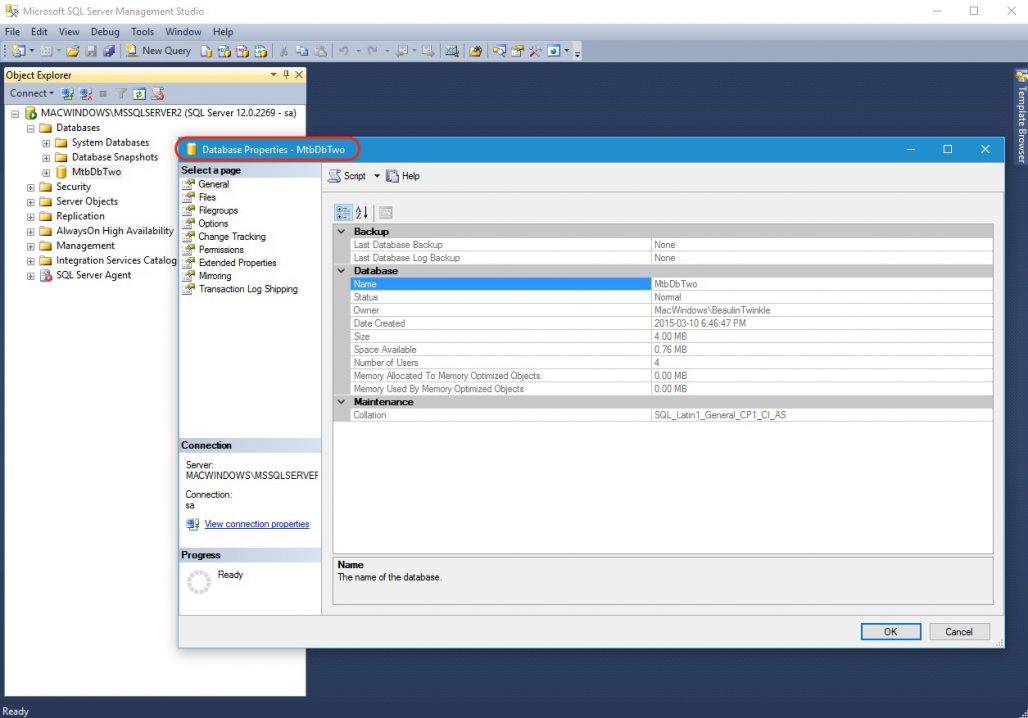
Conclusion Of Part-1
With this I’m completing the part 1 of the SQL Server Management Studio Session. In the next session we will have the Part-2 of SQL Server Management Studio.
Contents of SQL Server Management Studio Part-2
- SQL Query editor Window.
- Changing Windows Layout.
- Some editing tools.
- Registered Servers.
- And about templates, solutions and scripting projects.
Go to Part-2 of SQL Server Management Studio Tutorial.
Reference
- SQL Server Management Studio in Microsoft Docs.
In the big picture, you need to:
- Download the free Microsoft SQL Server Management Studio and install it, accepting the defaults
- Connect to your SQL Server
- Create a low-privileged login so that you don’t accidentally drop objects
- Learn to switch back & forth between the low-privileged account and your regular one
Let’s get started!
1. Download and install SSMS (but not on the server itself)
The first step is really easy: go here to get the latest version of SSMS and install it. If you already have a version of SSMS, the installer will automatically update it to the latest version. It doesn’t matter what version of SQL Server you’re running in production: as long as you’re running a currently supported version of SQL Server (2012 & newer as of this writing), you always wanna run the latest version of SSMS, which will include a ton of bug fixes.
Do this installation on your desktop or laptop, not on the SQL Server itself. Over time, you’ll learn that running SSMS (as with any other app) on the SQL Server itself will slow it down. You wouldn’t remote desktop into the SQL Server and start playing Fortnite, now, would you? Don’t answer that. You probably would. You’re the kind of person who reads this blog, after all, and I … let’s just stop there. Install SSMS on your desktop.
2. Connect to your SQL Server
After launching SSMS, you get a connection dialog:

Server name – the DNS name or IP address where your SQL Server answers connection requests. This is usually the same as the server name itself, but if you have fancier setups like named instances or non-default port numbers, you’ll need to specify those here.
Authentication – probably Windows, try that first. If that fails, you either don’t have access to the server, or it’s configured with SQL authentication. You might have a username & password on a post-it note somewhere, like from the person who installed it, and it might have a username of “sa”. In that case, go ahead and use that for now. In the next step, we’ll set you up a low-privilege account.
Click Connect, and you’ll be handsomely rewarded with a window that looks like this:

At this point, you’re able to do … all kinds of dangerous things, actually. We need to fix that so you don’t do something stupid.
3. Create yourself a low-privileged login.
Start a new query by clicking File, New, Database Engine Query, or right-click on the SQL Server name and click New Query:

You’ll get an empty new-query window. Copy/paste the below into your new query window so we can find out if you have Windows-only authentication turned on:
|
SELECT SERVERPROPERTY(‘IsIntegratedSecurityOnly’) |
If the result is 1, that means your SQL Server only allows Windows logins. In that case, I deeply apologize, but I’m not covering that yet in the scope of this blog post.
If the result is 0, good news! You can create SQL logins. To do that, copy/paste the below into your new-query window, and note that you have some changes to make:
|
USE [master] GO CREATE LOGIN [brent_readonly] WITH PASSWORD=N‘changeme’, DEFAULT_DATABASE=[tempdb], CHECK_EXPIRATION=ON, CHECK_POLICY=ON GO GRANT VIEW SERVER STATE TO [brent_readonly]; GO |
Change brent_readonly to be whatever username you want: typically your regular username, but append _readonly to it so you know that it’s your less-privileged account. Note that you have to change “brent_readonly” in two places.
Change the password from “changeme” to whatever you want.
If you get an error that says:
|
Msg 15118, Level 16, State 1, Line 3 Password validation failed. The password does not meet the operating system policy requirements because it is not complex enough. |
Then you need to use a more complex password.
Finally, let’s make sure the new login can’t write anything in your existing databases. Copy/paste this in, change brent_readonly to your login name (note that it’s in 3 places), and run it:
|
sp_msforeachdb ‘USE [?]; CREATE USER [brent_readonly] FOR LOGIN [brent_readonly]; ALTER ROLE [db_denydatawriter] ADD MEMBER [brent_readonly];’ |
That only affects the databases you have in place today. If someone restores a database into this environment, you’ll be able to write to it. If you’ve got some time and you’re willing to roll up your sleeves a little, here’s how to deny writes in all new databases long term.
4. Learn to switch back & forth between accounts.
Now that you have a low-privileged account, you’re going to want to use this by default when you connect into SQL Servers with Management Studio. This helps prevent you accidentally causing a resume-generating event.
Close SSMS, and reopen it again. This time, at the connection dialog:

Choose SQL Server authentication because we created a new SQL login, and then type in your low-privileged username and password. Click Connect, and you’re now working a little more safely, without the superpowers of your regular domain login.
If you do need to switch over to your regular high-permission account, you could close SSMS entirely and reopen it, but there’s an easier way. To change accounts for the current query window, click the change-connection button at the top right. It looks like a plug/unplug button:

That’ll give you the connect-to-server dialog box. Note that the login change only affects the currently open query window: that’s the safest way to minimize the damage. Then, as soon as you’re done doing high-permissions stuff, close that window, and you’re back to your regular low-permission stuff.
Next steps for learning
Now that you have an account that’s safe to use for learning, here are a few next steps of tools to explore on how to get to know your SQL Server better.
- How I Configure SQL Server Management Studio – my setup tips
- sp_Blitz – totally free health check script that warns you about dangerous things in your SQL Server that may present problems later
- How to do a health check – my free process for writing up a SQL Server’s health and performance issues