ЛАБОРАТОРНАЯ РАБОТА 1.
Первая программа на языке ассемблера ARM
Краткие теоретические сведения
Структура ассемблерной программы
Каждый язык программирования имеет свои особенности. Язык ассемблера — самый низкоуровневый язык программирования, он ближе любых других приближен к архитектуре ЭВМ и ее аппаратным возможностям, позволяя получить к ним более полный доступ, нежели в языках высокого уровня, наподобие C, Java, Python и пр. Действия, которые может выполнять ассемблерная программа, делятся на две категории: инструкции центральному процессору и обращения к операционной системе (системные вызовы).
Инструкции являются словесным аналогом машинных команд и указывают, какие действия должны выполнять блоки процессора: загрузку данных из оперативной памяти, арифметические операции, сравнение чисел, пересылку управляющих байтов микроконтроллерам периферийных устройств и т. д. Каждое семейство процессоров имеет свою собственную систему команд, поэтому перенос ассемблерной программы на другую процессорную архитектуру фактически равноценен переписыванию с нуля.
Системные вызовы, т. е. обращения напрямую к ядру ОС, позволяют ассемблерной программе работать с файлами, динамически выделять память выполнять консольный ввод-вывод и совершать другие высокоуровневые (с точки зрения машинной архитектуры) действия. Подпрограммы ядра ОС, выполняющие все эти действия — обычно смесь кода на языке высокого уровня с фрагментами на ассемблере. В качестве языка высокого уровня в подавляющем большинстве операционных систем используется язык С. На ассемблере обычно программируются:
- архитектурно-зависимые части системы, т. е. такие, которые имеют принципиальные различия для разных процессорных архитектур;
- драйвера устройств, или по крайней мере те их части, которые отвечают за непосредственное взаимодействие с микроконтроллером соответствующего устройства;
- фрагменты кода, от которых требуется очень высокая скорость работы.
Наиболее простые микропроцессорные устройства обходятся вовсе без операционной системы, и в этом случае машинные команды — единственное, что доступно программисту. В более сложных устройствах работу программисту облегчает ОС, специально созданная или адаптированная для встраиваемой электроники. На текущий момент из универсальных ОС наиболее распространена в сегменте встраиваемой электроники система GNU/Linux — благодаря открытым исходным кодам, высокой масштабируемости и поддержке широкого спектра самых различных архитектур.
Ниже мы будем рассматривать программы для семейства микропроцессоров ARM, рассчитанные как на самостоятельную работу в микропроцессорном устройстве, так и на работу под управлением ОС GNU/Linux.
Как уже говорилось, без участия ОС ассемблерная программа обычно выполняет простые действия над данными, используя для этого инструкции, задающие команды блокам центрального процессора. Рассмотрим в качестве примера для архитектуры ARM такую программу, складывающую 2 операнда:
.text
start: @ Необязательная строка, обозначающая начало программы
mov r0, #5 @ Загрузка в регистр r0 значения «5»
mov r1, #4 @ Загрузка в регистр r1 значения 4
add r2, r1, r0 @ Складываем r0 и r1, ответ записываем в r2
stop: b stop @ Строка завершения программы
Прежде чем разбираться в действиях программы, рассмотрим на ее примере особенности синтаксиса ассемблера. В отличие от типичных высокоуровневых языков программирования, в ассемблерной программе каждая команда располагается на отдельной строке. Нельзя разместить несколько команд на одной строке, и не принято разбивать одну команду на несколько строк.
Синтаксис ассемблера GNU, который мы будем использовать далее, не является регистро-чувствительным, т. е. ассемблер не различает прописные и строчные буквы английского алфавита в именах команд и элементов данных. Команда может быть директивой – указанием транслятору, превращающему текст программы в машинный код. Многие директивы начинаются с точки. Кроме директив в программе еще бывают инструкции, т. к. команды процессору. Именно они и будут составлять машинный код программы.
Нужно отметить, что понятие «машинного кода» очень условно. Часто оно обозначает просто содержимое выполняемого файла, хранящего кроме собственно машинных команд еще и данные.
Каждая программа на ассемблере строится из инструкций, описанных следующим образом:
{метка} {инструкция|операнды} {@ комментарий}
Метка — необязательный параметр. Это символическое имя, указывающее на расположение инструкции или элемента данных в памяти. При трансляции имена меток заменяются на соответствующие им адреса. Имя метки должно состоять из букв, цифр, знаков _ и $.
Инструкция — непосредственно мнемоника (символьное имя) команды процессора.
Операнды — константы, адреса регистров, адреса в оперативной памяти.
Комментарий — необязательная часть, которая отбрасывается при трансляции и не влияет на исполнение программы. Обычно это текст, в котором программист поясняет назначение той или иной строки в программе.
Операнды
Поскольку обращения к оперативной памяти — достаточно медленная операция, в качестве аргументов команд процессора для выполнения различных вычислений и других действий используют обычно внутренние ячейки памяти процессора — регистры.
Процессор ARM имеет несколько наборов регистров, из которых в каждый момент времени доступны программисту 16. Размер каждого регистра равен машинному слову, т. е. 4 байта. В отличие от ячеек оперативной памяти, регистры имеют имена — от r0 до r15.
Большинство регистров могут использоваться программистом по своему усмотрению — это так называемые регистры общего назначения. Однако несколько регистров имеют специальное назначение:
r15— это указатель на следующую исполняемую команду, известный также как PC (англ. Program Counter). Над его содержимым можно выполнять разные арифметические и логические операции, и тем самым будет осуществляться переход по новому адресу, т.е. исполнение программы будет переходить на другие ветви алгоритма. В противном случае, по выполнении команды значение этого регистра будет автоматически увеличено на 4 байта, что означает переход к следующей команде в программе.r14содержит адрес возврата из подпрограммы и имеет также название LR, или Link Register.r13является указателем стека и также известен как SP (Stack Pointer).r12— IP или Intra-Procedure-call scratch register — используется компиляторами языка C особым образом для доступа к параметрам в стеке.
Помимо своего специального назначения, перечисленные 4 регистра могут быть аргументами инструкций процессора, участвуя тем самым в вычислительном процессе в точности так же, как регистры общего назначения.
Как уже упоминалось, процессор ARM имеет несколько наборов регистров. Это связано с тем, что существует несколько режимов работы процессора, и в зависимости от текущего режима работы доступен тот или иной банк регистров. Предполагается, что это избавляет программиста от необходимости сохранения значений регистров в оперативной памяти перед сменой режима.
Следующие режимы работы возможны для всех процессоров семейства ARM:
- режим приложения (USR, user mode);
- режим супервизора или режим операционной системы (SVC, supervisor mode);
- режим обработки прерывания (IRQ, interrupt mode);
- режим обработки «срочного прерывания» (FIRQ, fast interrupt mode).
Например, при возникновении прерывания процессор сам переходит к адресу программы обработчика прерываний и сам автоматически «переключает» банки регистров.
Процессоры ARM более продвинутых версий имеют еще дополнительные режимы:
- Abort (используется для обработки исключений доступа к памяти);
- Undefined (используется для реализации сопроцессора программным способом);
- System (режим привелигированных задач операционной системы).
Как переключаются банки регистров в зависимости от режима, видно из следующей таблицы:

Можно заметить, что регистры r0 — r7 одни и те же для всех режимов, а регистры r8 — r12 общие только для режимов USR, SVC, IRQ. Видно также, что режим FIRQ самый обособленный, у него больше всего собственных регистров. Это позволяет вне очереди обработать какое-то крайне срочное прерывание, не теряя времени на сохранение регистров в стек.
В младших моделях процессоров флаги хранятся в нескольких битах регистра r15 вместе с адресом инструкции. В более продвинутых процессорах семейства ARM все флаги и служебные биты расположены в отдельных регистрах, известных как Current Program Status Register (cpsr) и Saved Program Status Register (spsr). Для доступа к этим регистрам существуют отдельные команды. Это сделано, что бы расширить доступное адресное пространство программ.
Машинные команды
Как уже упоминалось, разным семействам процессоров соответствуют разные наборы машинных команд. Кроме того, в некоторые команды могут различаться в пределах одного семейства (например, отсутствовать у одних процессоров и присутствовать у других). Приведем в таблице несколько часто встречающихся команд процессоров ARM:
| Название | Действие | Пример | Действие |
add |
сложение | add r0, r1, r2 |
r0 = r1 + r2 |
sub |
вычитание | sub r0, r1, r2 |
r0 = r1 – r2 |
mul |
умножение | mul r0, r1, r2 |
r0 = r1 * r2 |
mov |
копирование данных | mov r0, r1 |
r0 = r1 |
ldr |
Загрузка данных из оперативной памяти | ldr r4, [r5] |
r4 = *(r5) |
Как видно, некоторые инструкции легко узнаваемы. Более подробно необходимые детали будут рассмотрены в следующих работах.
Особенности создания ассемблерной программы
В отличие от языков высокого уровня (ЯВУ) ассемблерная программа содержит только тот код, который ввел программист. Никаких дополнительных «оберток». Вся ответственность за «логичность» кода полностью лежит на плечах программиста.
Простой пример. Обычно подпрограммы заканчиваются командой возврата. Если в ЯВУ ее не задать явно, транслятор все равно добавит ее в конец подпрограммы. Ассемблерная подпрограмма без команды возврата не вернется в точку вызова, а будет выполнять код, следующий за подпрограммой, как будто он является ее продолжением. Еще пример. Можно попробовать «выполнить» данные вместо кода. Часто это лишено смысла. Но если программист это сделает, транслятор не выдаст никаких сообщений об ошибке, просто байты данных будут интерпретированы как коды каких-то машинных команд.
Из-за специфики программирования, а также по традиции, для создания программ на языке ассемблера обычно пользуются утилитами командной строки (хотя поддержка ассемблера и есть в некоторых универсальных интегрированных средах).
Весь процесс технического создания ассемблерной программы можно разбить на 4 шага (исключены этапы создания алгоритма, выбора структур данных и т.д.).
- Набор программы в текстовом редакторе и сохранение ее в отдельном файле. Каждый файл имеет имя и тип, называемый иногда расширением. Например, программа на C имеет расширение C, на Pascal – PAS, на языке ассемблера есть несколько вариантов, но мы будем использовать в работе расширение S.
- Обработка текста программы транслятором. На этом этапе текст превращается в машинный код, называемый объектным. Кроме того есть возможность получить листинг программы, содержащий кроме текста программы различную дополнительную информацию и таблицы, созданные транслятором. Тип объектного файла – O, файла листинга – LST. Этот этап называется трансляцией.
- Обработка полученного объектного кода компоновщиком. Тут программа «привязывается» к конкретным условиям выполнения на микропроцессорной системе. Полученный машинный код называется выполняемым. Выполняемый файл обычно не имеет расширения. Этот этап называется компоновкой или линковкой.
- Запуск программы. Если программа работает не совсем корректно, перед этим может присутствовать этап отладки программы при помощи специальной программы – отладчика. При нахождении ошибки приходится проводить коррекцию программы, возвращаясь к шагу 1.
Процесс создания ассемблерной программы можно изобразить в виде следующей схемы:

Конечной целью, напомним, является работоспособный файл в формате ELF (например, «add.elf»), выполняющий сложения чисел.
В отличие от обычных компьютерных программ, программы для встраиваемой электроники разрабатывают (редактируют исходный код, выполняют трансляцию и т. д.) на архитектуре, отличной от той, на которой программа должна выполняться. Трансляция текста программы в исполняемый код для другой платформы (не той, на которой исполняется транслятор), называется кросс-компиляцией, а сами программы, выполняющие эту трансляцию, известны как кросс-компиляторы (англ. cross compiler).
Кросс-компиляция широко используется, когда нужно получить код для платформы, экземпляров которой нет в наличии, когда компиляция на целевой платформе невозможна или нецелесообразна. Например, даже если к встраиваемой микропроцессорной системе удастся подключить дисплей и клавиатуру, установить на нее ОС и все необходимые программы — использование ее в качестве рабочей станции наверняка оставит у программиста негативные впечатления из-за невысокой вычислительной мощности и ограниченных объемов памяти.
Поэтому программы для встраиваемых систем создают и компилируют на персональном компьютере. Более того, даже проверка работоспособности программы может проходить без использования реального микропроцессорного устройства – особенно на ранних этапах. Для простоты, вместо конечного устройства можно использовать программу-эмулятор, которая будет имитировать процессор нужной архитектуры и все необходимые для его работы периферийные устройства. Поскольку имеющаяся в распоряжении программиста рабочая станция, как правило, обладает существенно большими ресурсами, программная эмуляция конечного устройства на ней и запуск разрабатываемой программы на этом виртуальном устройстве достаточно удобны.
В качестве эмулятора системы на процессоре ARM мы будем пользоваться программой QEMU. Это мощная и универсальная система эмуляции, поддерживающая широкий спектр архитектур, доступная на многих платформах, и вместе с тем не слишком сложная в использовании. Для компиляции же программы воспользуемся ассемблером и линковщиком из набора инструментов GNU binutils, входящих в состав многих Unix-подобных операционных систем и также доступных для платформы Windows.
Обратите внимание, что в отличие от основного компилятора и соответствующих ему инструментов, набор для кросс-компиляции не ставится по-умолчанию даже в Unix-подобных системах. Например, в дистрибутивах Linux для его установки требуется доустановить определенный пакет, в имени которого будет присутствовать слово binutils (или toolchain) и название архитектуры, для которой должна выполняться кросс-компиляция: в нашем случае, arm. Пакет qemu более стандартен; однако из-за того, что он поддерживает несколько архитектур, в некоторых дистрибутивах его разделяют на несколько пакетов: для эмуляции ARM-совместимых устройств, интелловской архитектуры и т. д.
Например, в Ubuntu Linux нужные нам кросскомпилятор и эмулятор QEMU можно установить следующей командой (используйте её, например, чтобы установить их на собственный ноутбук):
sudo apt-get install binutils-arm-linux-gnueabi qemuТранслятор GNU AS
GNU AS превращает текст программы в объектный код. Чтобы пакеты кросс-компиляции под разные архитектуры могли легко совмещаться на одной файловой системе, к имена утилит из одного пакета обычно имеют одинаковую приставку, поясняющую их принадлежность. Так, например, ассемблер as может быть доступен для вызова по имени arm-none-linux-gnueabi-as. Чтобы выяснить, какая приставка у кросс-компилятора, установленного в системе, можно набрать в командной arm и нажать клавишу табуляции, чтобы посмотреть варианты автодополнения для набранной части команды.
Имя файла с текстом программы для ассемблирования задается в командной строке. В простейшем случае это выглядит так:
arm-none-linux-gnueabi-as -o add.o add.sОпция -о определяет имя выходного файла. Текст программы из файла add.s преобразуется в объектный код, который запишется в файл add.o.
При успешной трансляции вы не увидите никаких сообщений; они появляются только как информация об ошибках или предупреждения. При наличии ошибок объектный файл не создается. Когда транслятор находит что-то нетипичным, он выдает предупреждения. Однако предупреждение не всегда следствие допущенной ошибки.
Полностью формат командной строки AS можно увидеть, набрав as --help. Для получения более подробной информации см. man as.
Компоновщик LD
Для того, чтобы получить исполняемую программу, ее необходимо передать на обработку компоновщику или, как его еще называют, линковщику:
arm-none-linux-gnueabi-ld -o add.elf add.o Ключ -о с последующим значением задает в данном случае имя создаваемого исполняемого файла.
Формат командной строки LD можно увидеть набрав ld --help. Для получения более подробной информации см. man ld.
Получение бинарного кода
Сохраним программу в файле add.s. Для сборки файла требуется сначала вызвать ассемблер GNU — программу «as»:
arm-none-linux-gnueabi-as -o add.o add.s
Далее, чтобы создать исполняемый файл, вызовем компоновщик «ld», как показано в следующей команде:
arm-none-linux-gnueabi-ld -Ttext=0x0 -o add.elf add.o
Здесь опция -Ttext = 0x0 определяет, что адреса должны быть присвоены меткам таким образом, чтобы инструкции начинались с нулевого адреса. Это нужно, поскольку мы собираемся запускать программу без использования операционной системы.
Для просмотра адресов, присвоенных различным меткам, можно использовать команду «nm»:
arm-none-linux-gnueabi-nm add.elfРезультатом выполнения команды будет список:
...
00000000 t start
0000000c t stopАдрес метки start это 0x0, так как это метка первой команды. Метка stop находится через 3 инструкции. Каждая инструкция составляет 4 байта. Таким образом метке stop присваивается адрес 12 (0xс в шестнадцатиричной нотации).
Выходной файл, созданный ld, имеет формат ELF. Доступны различные форматы хранения исполняемого кода. Формат ELF отлично работает в окружении операционной системы, но так как мы собираемся запустить программу на «голом железе», мы должны преобразовать его в более простой формат, называемый двоичным форматом.
В отличие от формата ELF, файл в двоичном формате содержит последовательные байты с определенного адреса в памяти, и больше никакой другой дополнительной информации.
Для преобразования различных форматов объектных файлов может использоваться команда «objcopy» из набора инструментов GNU. Общий вид команды:
objcopy -O <выходной формат> <файл-источник> <файл-приемник>Для преобразования файла add.elf в двоичный формат выполним следующую команду:
arm-none-linux-gnueabi-objcopy -O binary add.elf add.binМожно проверить размер созданного бинарного файла: он должен быть ровно 16 байт, поскольку в листинге 4 команды, и каждая занимает 4 байта. Проверку можно выполнить, например, командой «ls»:
Исполнение в QEMU
Когда процессор ARM сброшен в нулевое состояние, он начинает выполнение команд с адреса 0×0. На эмулируемой QEMU плате будет 16Мб флеш-памяти, расположенной по адресу 0×0. Поэтому, чтобы протестировать программу на эмулируемой плате, мы должны создать файл, представляющий собой образ flash-памяти объемом 16Мб. Формат файла образа предельно прост: чтобы получить байт из адреса X во flash-памяти, QEMU читает байт со смещением X в файле.
Воспользуемся командой «dd», чтобы скопировать 16Мб нулей из виртуального устройства «генератора нулей» /dev/zero в файл flash.bin . Данные копируются как блоки по 4К.
dd if=/dev/zero of=flash.bin bs=4096 count=4096Затем скопируем файл add.bin в начало образа flash-памяти с помощью следующей команды:
dd if=add.bin of=flash.bin bs=4096 conv=notruncЭто эквивалентно помещению bin-файла во flash-память платы.
Команда для вызова QEMU с нужными нам параметрами следующая:
qemu-system-arm -M connex -pflash flash.bin -nographic -serial /dev/nullПараметр -М connex указывает, что эмулируется плата connex. Опция -pflash указывает, что файл flash.bin представляет собой flash-память, -Nographic указывает на необязательность моделирования графического дисплея, а -serial /dev/null указывает, что последовательный порт платы connex подключается к /dev/null, т. е. не используется.
Запустив программу, мы можем использовать системную консоль QEMU для просмотра содержимого регистров. Так как на данном этапе QEMU не будет иметь интерфейса, так что управлять эмулируемой системой и просматривать её состояние будем при помощи терминала, из которого она была запущена.
Для просмотра содержимого регистров используется команда QEMU info registers, которая вводится сразу после вызова qemu-system-arm.
(qemu) info registers
R00=00000005 R01=00000004 R02=00000009 R03=00000000
R04=00000000 R05=00000000 R06=00000000 R07=00000000
R08=00000000 R09=00000000 R10=00000000 R11=00000000
R12=00000000 R13=00000000 R14=00000000 R15=0000000c PSR=400001d3 -Z-- A svc32
Порядок выполнения работы
- Создайте в своем домашнем каталоге новый подкаталог с именем asm_01. Создайте в нем текстовый файл add.s, и введите в него текст программы из первого раздела, пользуясь правилами оформления ассемблерных программ.
- Скомпилируйте программу и проверьте ее в эмуляторе:
- оттранслируйте полученный текст программы в объектный файл;
- выполните линковку объектного файла;
- преобразуйте отлинкованный файл в бинарный формат;
- разместите бинарный файл в файле образа flash-памяти;
- запустите получившийся образ виртуальной машины на выполнение в эмуляторе QEMU;
- проверьте результат выполнения через монитор QEMU.
- Измените в тексте программы что-либо. Повторите все подпункты пункта 2.
Контрольные вопросы
- Какие основные отличия ассемблерных программ от ЯВУ?
- В чем отличие инструкции от директивы?
- Каковы правила оформления программ на языке ассемблера?
- Расскажите о регистрах процессора ARM.
- Расскажите о режимах работы процессора ARM.
- Каковы этапы получения выполняемого файла?
- Каково назначение этапа трансляции?
- Каково назначение этапа компоновки?
- Как выполнить бинарный файл на ARM-устройстве без использования операционной системы?
- Какие аргументы эмулятора QEMU позволяют запускать программы для процессора ARM в виртуальной машине?
Разница между Директивой и Инструкцией
Ключевое отличие: Директива — это в основном приказ, обычно издаваемый органом. Директива может устанавливать политику, распределять обязанности, определять цели и делегировать полномочия тем, кто работает с авторитетной фигурой. Инструкции, с другой стороны, действуют как руководство. Они часто выглядят как последовательность шагов или этапов, которые необходимо выполнить один за другим. Инструкции в основном связаны с инструкцией или преподаванием.

Директивы и инструкции — это два термина, которые часто путают. Человек может быть необходим, чтобы следовать инструкциям или директивам. Итак, в чем именно разница между этими двумя и которые должны быть использованы, когда?
Dictionary.com определяет директиву как:
- Служение направлять; режиссура: директивный совет.
- Психология. Относится к типу психотерапии, при которой терапевт активно предлагает советы и информацию, а не имеет дело только с информацией, предоставленной пациентом.
- Авторитетная инструкция или указание; конкретный приказ: новая директива президента о внешней помощи.
В то время как инструкции определены как:
- Акт или практика инструктажа или обучения; образование.
- Знания или информация передаются.
- Предмет таких знаний или информации.
- Обычно инструкции. приказы или указания: инструкции находятся на обратной стороне коробки.
- Акт обеспечения авторитетных направлений.
- Компьютеры. Команда, данная компьютеру для выполнения определенной операции.

Основное различие между указаниями или инструкциями заключается в том, что директива — это в основном приказ, обычно издаваемый органом. Директива может устанавливать политику, распределять обязанности, определять цели и делегировать полномочия тем, кто работает с авторитетной фигурой. Директива может устанавливать или описывать политику, программу и / или организацию. Например: директива об учреждении государственного органа, директива об учреждении местной субсидии, директива об учреждении зарубежного офиса, директива об уменьшении потерь, директива об утилизации и т. Д.
Инструкции, с другой стороны, действуют как руководство. Они часто выглядят как последовательность шагов или этапов, которые необходимо выполнить один за другим. Инструкции в основном связаны с инструкцией или преподаванием. Следовательно, даны инструкции, чтобы научить кого-то чему-то. Например: инструкции по приготовлению пищи, инструкции по вязанию шарфа, инструкции по строительству кукольного домика, инструкции по завершению проекта, инструкции по написанию отчета, руководство по эксплуатации любых электронных устройств и т. Д.
Другой пример: Всемирная организация здравоохранения (ВОЗ) может издать директиву для конкретного региона, которая будет готова к вспышке. Он также предоставит инструкции о том, как местные жители могут быть лучше подготовлены к указанной вспышке и как справиться со вспышкой.
Рекомендуем
Похожие статьи
-

Разница между альпинизмом и скалолазанием
Ключевое отличие: альпинизм — это спорт или хобби, в котором человек поднимается или взбирается на гору. Он также известен как альпинизм или альпинизм. Скалолазание — это спорт, который требует, чтобы человек поднимался вверх и вниз по скале или каменной стене. Скалолазание или скалолазание — это часть альпинистского скалолазания, когда человеку может потребоваться взобраться на скалы, чтобы получить определенный пик при восхождении на гору. Альпинизм и скалолазание —
-
Разница между Twitter и Facebook
Ключевое отличие: Twitter и Facebook — это два разных сайта социальных сетей. Они существенно различаются по своему составу и способу их использования. Основное различие между ними заключается в том, что Facebook является службой социальных сетей, а Twitter — службой социальных сетей и услуг микроблогов. Twitter и Facebook — это две разные социальные сети. Они существенно различаются по своему составу и способу их использования. Основное различие между ними заключается в том, что Facebook является службой социальных сетей,
-
Разница между границей и депрессией
Ключевое отличие: пограничное расстройство личности — это психическое состояние, при котором люди испытывают безрассудное и импульсивное поведение, нестабильные настроения и отношения. Депрессия определяется как состояние плохого настроения и отвращения к активности. Это обычно вызвано биохимическим дисбалансом в мозге, который препятствует
-
Разница между гинекологом и акушером
Ключевое отличие: гинеколог — это врач, который заботится о репродуктивном здоровье женщин. С другой стороны, акушер — это врач, который оказывает помощь женщинам, особенно во время беременности и после рождения ребенка. Гинеколог — врач, изучающий проблемы репродуктивной системы женщины. Они в первую очередь заботятся о любых проблемах, связанных с яичниками, маткой, шейкой матки и влагалищем. Он
-
Разница между Селфи и Группой
Ключевое отличие: Селфи — это когда человек, который фотографирует себя с помощью камеры или телефона и публикует его на веб-сайте социальной сети. Групповой — это когда человек, который фотографирует себя с другими людьми с помощью камеры телефона и публикует ее на веб-сайте социальной сети. Слово «селфи», от популярного хэштега до названия популярной песни, покорило одержимый цифровой мир. От молодых людей на вечеринке с Эллен в Оскаре не так много людей, которые не слышали этого слова. Хотя это популярный термин, он по-прежн
-
Разница между приливной волной и цунами
Ключевое отличие: приливная волна — это, по сути, прилив, который поднимается достаточно быстро, чтобы появиться в форме волны. Это зависит исключительно от погоды и гравитации от Луны и Солнца. Цунами, с другой стороны, происходит, когда какое-то событие нарушает океан. Обычно они вызваны геологическими явлениями, такими как землетрясение, извержен
-
Разница между Lenovo IdeaPad Yoga 11 и iPad
Ключевое отличие: уникальным аспектом Lenovo IdeaPad Yoga 11 является то, что он представляет собой трансформируемый ноутбук с многорежимным дизайном на 360 градусов. Это позволяет устройству работать в четырех режимах проектирования. Это включает в себя режим ноутбука, планшетный режим, режим палатки и, наконец, режим ожидания. Lenovo IdeaPad Yoga 11 оснащен 11, 6-дюймовым дисплеем высокой четкости и весит 1
-
Разница между верой и верой
Основное различие: доверие и вера имеют более глубокий смысл, когда дело доходит до использования его в отношениях. Доверие на самом деле означает, что человек полностью доверяет другому человеку и может положиться на него во всем. Вера — это более временная концепция, которая требует, чтобы человек верил в человека в течение определенного периода времени. Верить также может означать, что что-то является правдой или кт
-
Разница между зоологией и геологией
Ключевое отличие: зоология и геология — это две совершенно разные области, которые связаны с биологией и экологическими исследованиями. Зоология — это наука о животных, связанная с биологией; в то время как геология — это изучение твердой Земли и ее компонентов, связанных с экологией. Зоология и геология — известные области, которые имеют дело с животными и науками о Земле. Это обширные исследования в их соответствующих отраслях и широко изучаются во всем мире. Зоология является жизненно важной областью в биолог









Выбор редакции
Разница между детским садом и детской
Основное различие: детский сад и ясли обозначают тип дошкольного учреждения, ориентированного на детей от трех до пяти лет. Обычно детский сад используется для обозначения дошкольного учреждения, ориентированного на детей от трех до пяти лет. Детский сад, с другой стороны, обозначает первый год обучения. Он ориентирован на детей 5 лет. Тем не менее, использование терминов варьируется от страны к стране. Иногда термины также используются взаи
Содержание:
1. Директивы компиляции
2. Инструкции препроцессора 1С
3. При запуске клиент-сервера 1С 8.3
1. Директивы компиляции
Директива препроцессора — это специальный способ указать командой препроцессору 1С, где будет выполнен код 1С. В качестве примера можно привести тот факт, что нельзя выдать пользователю диалоговое сообщение на сервере – это будет работать только на клиенте.
Директива 1С определяется символом «&».
Допустимые директивы 1С:
· &НаКлиенте (&AtClient)
· &НаСервере (&AtServer)
· &НаСервереБезКонтекста (&AtServerNoContext)
· &НаКлиентеНаСервереБезКонтекста(&AtClientAtServerNoContext)
· &НаКлиентеНаСервере (&AtClientAtServer)
В директивах 1С БезКонтекста недоступны реквизиты формы 1С 8.3 и экспортные переменные формы 1С, но доступен вызов процедур и функций 1С из серверных общих модулей 1С 8.3. По умолчанию если перед процедурой (функцией) ничего не указано, то применяется директива 1С &НаСервере. Перед одной процедурой (функцией) нельзя применять одновременно несколько директив компиляции. Также недопустимо наличие процедур (функций) с одинаковым именем, отличающихся только директивами компиляции.

2. Инструкции препроцессора 1С
Инструкции препроцессора 1С применяются для группировки кода, указания разрешения использования процедур (функций) на сервере и клиенте, а также в расширении при изменении части кода. Инструкции выполняются раньше директив компиляции. Ими можно ограничить любую часть модуля, но рекомендуется ограничивать только части методов. Инструкции препроцессора 1С обозначается в коде символом»#».
Для возможности свертки кода и группировки строк 1С применяется инструкция препроцессора 1С #Область. Обязательно указание имени области и инструкция, заканчивающаяся конструкцией #КонецОбласти.

3. При запуске клиент-сервера 1С 8.3
При использовании клиент–сервера 1С 8.3 для запуска платформы 1С:Предприятие 8 есть возможность выполнять различные процедуры (функции) или их части на сервере приложения 1С или на клиенте.

Конструкции НаСервере/Сервер и НаКлиенте/Клиент имеют в таком случае одинаковое значеие.

В расширении
В расширении в директиве 1С &ИзменениеИКонтроль используется инструкция препроцессора 1С #Вставка и #Удаление, которая позволяет частично изменить(добавить новые фрагменты или удалить) код процедуры (функции). Инструкция #Вставка заканчивается текстом #КонецВставки¸ Инструкция #Удаление заканчивается текстом #КонецУдаления.

Специалист компании «Кодерлайн»
Владимир Карцев
-
Структура программы на ассемблере
Программа на ассемблере представляет
собой совокупность блоков памяти,
называемых сегментами памяти.
Программа может состоять из одного или
нескольких таких блоков-сегментов.
Каждый сегмент содержит совокупность
предложений языка, каждое из которых
занимает отдельную строку кода программы.
Предложения ассемблера бывают четырех
типов:
-
команды или инструкции, представляющие
собой символические аналоги машинных
команд.
В процессе трансляции инструкции
ассемблера преобразуются в соответствующие
команды системы команд микропроцессора;
-
макрокоманды— оформляемые
определенным образом предложения
текста программы, замещаемые во время
трансляции другими предложениями; -
директивы, являющиеся указанием
транслятору ассемблера на выполнение
некоторых действий. У директив нет
аналогов в машинном представлении; -
строки комментариев, содержащие
любые символы, в том числе и буквы
русского алфавита. Комментарии
игнорируются транслятором.
Синтаксис ассемблера
Предложения, составляющие программу,
могут представлять собой синтаксическую
конструкцию, соответствующую команде,
макрокоманде, директиве или комментарию.
Для того чтобы транслятор ассемблера
мог распознать их, они должны формироваться
по определенным синтаксическим правилам.
Для этого лучше всего использовать
формальное описание синтаксиса языка
наподобие правил грамматики. Наиболее
распространенные способы подобного
описания языка программирования —
синтаксические диаграммыирасширенные
формы Бэкуса—Наура. Для практического
использования более удобнысинтаксические
диаграммы. К примеру, синтаксис
предложений ассемблера можно описать
с помощью синтаксических диаграмм,
показанных на следующих рисунках.
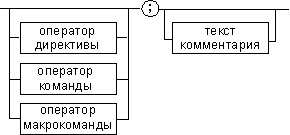
Рис. 1. Формат предложения
ассемблера

Рис. 2. Формат директив

Рис. 3. Формат команд и макрокоманд
На этих рисунках:
-
имя метки— идентификатор, значением
которого является адрес первого байта
того предложения исходного текста
программы, которое он обозначает; -
имя— идентификатор, отличающий
данную директиву от других одноименных
директив. В результате обработки
ассемблером определенной директивы
этому имени могут быть присвоены
определенные характеристики; -
код операции (КОП) и директива—
это мнемонические обозначения
соответствующей машинной команды,
макрокоманды или директивы транслятора; -
операнды— части команды, макрокоманды
или директивы ассемблера, обозначающие
объекты, над которыми производятся
действия. Операнды ассемблера описываются
выражениями с числовыми и текстовыми
константами, метками и идентификаторами
переменных с использованием знаков
операций и некоторых зарезервированных
слов.
Как использовать синтаксические
диаграммы?Очень просто: для этого
нужно всего лишь найти и затем пройти
путь от входа диаграммы (слева) к ее
выходу (направо). Если такой путь
существует, то предложение или конструкция
синтаксически правильны. Если такого
пути нет, значит эту конструкцию
компилятор не примет. При работе с
синтаксическими диаграммами обращайте
внимание на направление обхода,
указываемое стрелками, так как среди
путей могут быть и такие, по которым
можно идти справа налево. По сути,
синтаксические диаграммы отражают
логику работы транслятора при разборе
входных предложений программы.
Допустимыми символами при написании
текста программ являются:
-
все латинские буквы: A—Z, a—z.
При этом заглавные и строчные буквы
считаются эквивалентными; -
цифры от 0до9;
-
знаки ?, @, $, _, &;
-
разделители , . [ ] ( ) < > { } + / * % ! ‘ »
? = # ^.
Предложения ассемблера формируются из
лексем, представляющих собой
синтаксически неразделимые
последовательности допустимых символов
языка, имеющие смысл для транслятора.
Лексемамиявляются:
-
идентификаторы— последовательности
допустимых символов, использующиеся
для обозначения таких объектов программы,
как коды операций, имена переменных и
названия меток. Правило записи
идентификаторов заключается в следующем:
идентификатор может состоять из одного
или нескольких символов. В качестве
символов можно использовать буквы
латинского алфавита, цифры и некоторые
специальные знаки — _, ?, $, @. Идентификатор
не может начинаться символом цифры.
Длина идентификатора может быть до 255
символов, хотя транслятор воспринимает
лишь первые 32, а остальные игнорирует.
Регулировать длину возможных
идентификаторов можно с использованием
опции командной строкиmv. Кроме
этого существует возможность указать
транслятору на то, чтобы он различал
прописные и строчные буквы либо
игнорировал их различие (что и делается
по умолчанию). Для этого применяются
опции командной строки/mu, /ml, /mx; -
цепочки символов— последовательности
символов, заключенные в одинарные или
двойные кавычки; -
целые числав одной из следующих
систем счисления:двоичной, десятичной,
шестнадцатеричной. Отождествление
чисел при записи их в программах на
ассемблере производится по определенным
правилам:-
Десятичные числане требуют для
своего отождествления указания
каких-либо дополнительных символов,
например 25 или 139. -
Для отождествления в исходном тексте
программы двоичных чиселнеобходимо
после записи нулей и единиц, входящих
в их состав, поставить латинское “b”,
например 10010101b. -
Шестнадцатеричные числаимеют
больше условностей при своей записи:-
Во-первых, они состоят из цифр0…9, строчных и прописных букв
латинского алфавитаa, b,c,
d, e, fилиA, B, C,
D, E, F. -
Во-вторых, у транслятора могут
возникнуть трудности с распознаванием
шестнадцатеричных чисел из-за того,
что они могут состоять как из одних
цифр 0…9 (например 190845), так и начинаться
с буквы латинского алфавита (напримерef15). Для того чтобы «объяснить»
транслятору, что данная лексема не
является десятичным числом или
идентификатором, программист должен
специальным образом выделять
шестнадцатеричное число. Для этого
на конце последовательности
шестнадцатеричных цифр, составляющих
шестнадцатеричное число, записывают
латинскую букву “h”. Это обязательное
условие. Если шестнадцатеричное число
начинается с буквы, то перед ним
записывается ведущий ноль:0ef15h.
-
-
Таким образом, мы разобрались с тем, как
конструируются предложения программы
ассемблера. Но это лишь самый поверхностный
взгляд.
Практически каждое предложение
содержит описание объекта, над которым
или при помощи которого выполняется
некоторое действие. Эти объекты называются
операндами.
Их можно определить так:
операнды
— это объекты (некоторые значения,
регистры или ячейки памяти), на которые
действуют инструкции или директивы,
либо это объекты, которые определяют
или уточняют действие инструкций или
директив.
Операнды могут комбинироваться с
арифметическими, логическими, побитовыми
и атрибутивными операторами для расчета
некоторого значения или определения
ячейки памяти, на которую будет
воздействовать данная команда или
директива.
Возможно провести следующую классификацию
операндов:
Рассмотрим подробнее характеристику
операндов из приведенной классификации:
-
Постоянные или непосредственные
операнды— число, строка, имя или
выражение, имеющие некоторое фиксированное
значение. Имя не должно быть перемещаемым,
то есть зависеть от адреса загрузки
программы в память. К примеру, оно может
быть определено операторамиequили=.
-
num
equ 5imd
= num-2
mov
al,num ;эквивалентно mov al,5;5
здесь непосредственный операнд
add
[si],imd ; imd=3 —
непосредственный операнд
mov
al,5 ;5 — непосредственный операнд
В данном фрагменте определяются две
константы, которые затем используются
в качестве непосредственных операндов
в командах пересылки mov и сложения add.
-
Адресные операнды— задают физическое
расположение операнда в памяти с помощью
указания двух составляющих адреса:сегментаисмещения(рис. 4).

Рис. 4. Синтаксис описания
адресных операндов
К примеру:
-
mov
ax,0000h
mov
ds,ax
mov
ax,ds:0000h ;записать слово
в ax из области памяти по
;физическому
адресу 0000:0000
Здесь третья команда mov имеет адресный
операнд.
-
Перемещаемые операнды— любые
символьные имена, представляющие
некоторые адреса памяти. Эти адреса
могут обозначать местоположение в
памяти некоторых инструкции (если
операнд — метка) или данных (если операнд
— имя области памяти в сегменте данных).
Перемещаемые операнды отличаются от
адресных тем, что они не привязаны к
конкретному адресу физической памяти.
Сегментная составляющая адреса
перемещаемого операнда неизвестна и
будет определена после загрузки программы
в память для выполнения.
К примеру:
-
data
segmentmas_w
dw 25 dup (0)…
code
segment…
lea
si,mas_w ;mas_w —
перемещаемый
операнд
В этом фрагменте mas_w
— символьное имя, значением которого
является начальный адрес области памяти
размером 25 слов. Полный физический адрес
этой области памяти будет известен
только после загрузки программы в память
для выполнения.
-
Счетчик адреса— специфический
вид операнда. Он обозначается знаком$.
Специфика этого операнда в том, что
когда транслятор ассемблера встречает
в исходной программе этот символ, то он
подставляет вместо него текущее значение
счетчика адреса. Значение счетчика
адреса, или, как его иногда называют,
счетчика размещения, представляет
собой смещение текущей машинной команды
относительно начала сегмента кода.
В
формате листинга счетчику адреса
соответствует вторая или третья колонка
(в зависимости от того, присутствует
или нет в листинге колонка с уровнем
вложенности). Если взять в качестве
пример любой листинг, то видно, что при
обработке транслятором очередной
команды ассемблера счетчик адреса
увеличивается на длину сформированной
машинной команды. Важно правильно
понимать этот момент.
К примеру,
обработка директив ассемблера не влечет
за собой изменения счетчика. Директивы,
в отличие от команд ассемблера, — это
лишь указания транслятору на выполнение
определенных действий по формированию
машинного представления программы, и
для них транслятором не генерируется
никаких конструкций в памяти. В качестве
примера использования в команде значения
счетчика адреса можно привести следующий:
-
jmp
$+3 ;безусловный переход на команду
movcld
;длина команды cld составляет 1 байтmov
al,1
При использовании подобного выражения
для перехода не забывайте о длине самой
команды, в которой это выражение
используется, так как значение счетчика
адреса соответствует смещению в сегменте
команд данной, а не следующей за ней
команды. В нашем примере команда jmp
занимает 2 байта. Но будьте осторожны,
длина команды зависит от того, какие в
ней используются операнды. Команда с
регистровыми операндами будет короче
команды, один из операндов которой
расположен в памяти. В большинстве
случаев эту информацию можно получить,
зная формат машинной команды и анализируя
колонку листинга с объектным кодом
команды.
-
Регистровый операнд— это просто
имя регистра. В программе на ассемблере
можно использовать имена всех регистров
общего назначения и большинства
системных регистров.mov
al,4 ;константу 4 заносим в регистр almov
dl,pass+4 ;байт по адресу pass+4 в регистрdl
add
al,dl ;команда с регистровымиоперандами
-
Базовый и индексный операнды. Этот
тип операндов используется для реализациикосвенной
базовой,косвенной
индексной адресацииили
ихкомбинацийирасширений. -
Структурные операндыиспользуются
для доступа к конкретному элементу
сложного типа данных, называемогоструктурой. -
Записи(аналогично структурному
типу) используются для доступа к битовому
полю некоторойзаписи.
Операнды являются элементарными
компонентами, из которых формируется
часть машинной команды, обозначающая
объекты, над которыми выполняется
операция.
В более общем случае операнды
могут входить как составные части в
более сложные образования, называемые
выражениями.Выражения
представляют собой комбинации операндов
и операторов, рассматриваемые как единое
целое.
Результатом вычисления выражения может
быть адрес некоторой ячейки памяти или
некоторое константное (абсолютное)
значение.
Возможные типы операндов
мы уже рассмотрели. Перечислим теперь
возможные типы операторов
ассемблера и
синтаксические правила формирования
выражений ассемблера.
В табл.
2 приведены
поддерживаемые языком ассемблера
операторы и перечислены их приоритеты.
Дадим краткую характеристику операторов:
-
Арифметические операторы. К ним
относятся:-
унарные “+” и “–”;
-
бинарные “+” и “–”;
-
умножения “*”;
-
целочисленного деления “/”;
-
получения остатка от деления “mod”.
-
Эти операторы расположены на уровнях
приоритета 6, 7, 8 в табл.
2. Например,
-
tab_size
equ 50 ;размер массива в байтахsize_el
equ 2 ;размер элементов…
;вычисляется
число элементов массива и заносится
врегистр
cxmov
cx,tab_size / size_el ;оператор
“/”

Рис. 5. Синтаксис арифметических
операций
-
Операторы сдвигавыполняют сдвиг
выражения на указанное количество
разрядов (рис. 6). Например,
-
mask_b
equ 10111011…
mov
al,mask_b shr 3 ;al=00010111

Рис. 6. Синтаксис операторов
сдвига
-
Операторы сравнения(возвращают
значение “истина” или “ложь”)
предназначены для формирования
логических выражений (см. рис. 7 итабл.
1). Логическое значение
“истина” соответствует цифровой
единице, а “ложь” — нулю. Например,
-
tab_size
equ 30 ;размер таблицы…
mov
al,tab_size ge 50 ;загрузка
в
al 00h т.к.
tab_size < 50cmp
al,0 ;если
tab_size < 50, тоje
m1 ;переход на m1…
m1:
…
В этом примере если значение tab_size больше
или равно 50, то результат в al равен 0ffh,
а если tab_size меньше 50, то al равно 00h. Команда
cmp сравнивает значение al с нулем и
устанавливает соответствующие флаги
в flags/eflags. Команда je на основе анализа
этих флагов передает или не передает
управление на метку m1.

Рис. 7. Синтаксис операторов
сравнения
Таблица 1. Операторы
сравнения
|
Оператор |
Значение |
|
eq |
ИСТИНА, если |
|
ne |
ИСТИНА, если |
|
lt |
ИСТИНА, если |
|
le |
ИСТИНА, если |
|
gt |
ИСТИНА, если |
|
ge |
ИСТИНА, если |
-
Логические операторывыполняют
над выражениями побитовые операции
(рис. 8). Выражения должны быть абсолютными,
то есть такими, численное значение
которых может быть вычислено транслятором.
Например:
-
flags
equ 10010011mov
al,flags xor 01h
;al=10010010;пересылка в al поля flags с;инвертированным
правым битом

Рис. 8. Синтаксис логических
операторов
-
Индексный оператор[ ]. Не
удивляйтесь, но скобки тоже являются
оператором, и транслятор их наличие
воспринимает как указание сложить
значениевыражение_1за этими
скобками свыражение_2, заключенным
в скобки (рис. 9). Например,
-
mov
ax,mas[si] ;пересылка
слова по адресу mas+(si) в ;регистр ax
![]()
Рис. 9. Синтаксис индексного
оператора
Заметим, что в литературе
по ассемблеру принято следующее
обозначение: когда в
тексте речь идет о содержимом регистра,
то его название берут в круглые скобки.
Мы также будем придерживаться этого
обозначения.
К примеру, в нашем случае
запись в комментариях последнего
фрагмента программы mas + (si) означает
вычисление следующего выражения:
значение смещения символического имени
mas плюс содержимое регистра si.
-
Оператор переопределения типаptrприменяется для переопределения или
уточнения типа метки или переменной,
определяемых выражением (рис. 10).
Тип может принимать одно из следующих
значений: byte, word, dword, qword, tbyte, near, far.
Например,
-
d_wrd
dd 0…
mov
al,byte ptr d_wrd+1 ;пересылка второго байта
из двойного ;слова
Поясним этот фрагмент программы.
Переменная d_wrdимеет тип двойного
слова. Что делать, если возникнет
необходимость обращения не ко всей
переменной, а только к одному из входящих
в нее байтов (например, ко второму)? Если
попытаться сделать это командой
mov
al,d_wrd+1, то транслятор выдаст сообщение
о несовпадении типов операндов. Операторptrпозволяет непосредственно в
команде переопределить тип и выполнить
команду.
![]()
Рис. 10. Синтаксис оператора
переопределения типа
-
Оператор переопределения сегмента:(двоеточие) заставляет вычислять
физический адрес относительно конкретно
задаваемой сегментной составляющей:
“имя сегментного регистра”, “имя
сегмента” из соответствующей директивы
SEGMENT или “имя группы” (рис. 11). Этот
момент очень важен, поэтому поясню его
подробнее. При обсуждении сегментации
мы говорили о том, что микропроцессор
на аппаратном уровне поддерживает три
типа сегментов — кода, стека и данных.
В чем заключается такая аппаратная
поддержка? К примеру, для выборки на
выполнение очередной команды
микропроцессор должен обязательно
посмотреть содержимое сегментного
регистра cs и только его. А в этом регистре,
как мы знаем, содержится (пока еще не
сдвинутый) физический адрес начала
сегмента команд. Для получения адреса
конкретной команды микропроцессору
остается умножить содержимое cs на 16
(что означает сдвиг на четыре разряда)
и сложить полученное 20-битное значение
с 16-битным содержимым регистра ip.
Примерно то же самое происходит и тогда,
когда микропроцессор обрабатывает
операнды в машинной команде. Если он
видит, что операнд — это адрес (эффективный
адрес, который является только частью
физического адреса), то он знает, в каком
сегменте его искать — по умолчанию это
сегмент, адрес начала которого записан
в сегментном регистреds.
А что же с сегментом стека? Посмотрите
раздел «Программная
модель микропроцессора»,
там, где мы описывали назначение регистров
общего назначения.
В контексте нашего
рассмотрения нас интересуют регистрыspиbp. Если микропроцессор видит
в качестве операнда (или его части, если
операнд — выражение) один из этих
регистров, то по умолчанию он формирует
физический адрес операнда используя в
качестве его сегментной составляющей
содержимое регистраss. Что подразумевает
термин“по умолчанию”? Вспомните“рефлексы”, о которых мы говорили
на уроке 1. Это набор микропрограмм в
блоке микропрограммного управления,
каждая из которых выполняет одну из
команд в системе машинных команд
микропроцессора. Каждая микропрограмма
работает по своему алгоритму. Изменить
его, конечно же, нельзя, но можно чуть-чуть
подкорректировать. Делается это с
помощью необязательного поляпрефикса
машинной команды(см.формат
машинной команды). Если мы
согласны с тем, как работает команда,
то это поле отсутствует. Если же мы хотим
внести поправку (если, конечно, она
допустима для конкретной команды) в
алгоритм работы команды, то необходимо
сформировать соответствующий префикс.Префикспредставляет собой
однобайтовую величину, численное
значение которой определяет ее назначение.
Микропроцессор распознает по указанному
значению, что этот байт является
префиксом, и дальнейшая работа
микропрограммы выполняется с учетом
поступившего указания на корректировку
ее работы. Сейчас нас интересует один
из них —префикс замены (переопределения)
сегмента. Его назначение состоит в
том, чтобы указать микропроцессору (а
по сути, микропрограмме) на то, что мы
не хотим использовать сегмент по
умолчанию. Возможности для подобного
переопределения, конечно, ограничены.
Сегмент команд переопределить нельзя,
адрес очередной исполняемой команды
однозначно определяется парой cs:ip. А
вот сегменты стека и данных — можно.
Для этого и предназначен оператор “:”.
Транслятор ассемблера, обрабатывая
этот оператор, формирует соответствующий
однобайтовый префикс замены сегмента.
Например,
-
.code
…
jmp
met1 ;обход обязателен, иначе
поле ind;будет
трактоваться как очередная командаind
db 5
;описание поля данных в сегменте
командmet1:
…
mov
al,cs:ind ;переопределение сегмента
позволяет работать с данными,
определенными внутри сегмента кода

Рис. 11. Синтаксис оператора
переопределения сегмента
-
Оператор именования типаструктуры.(точка) также заставляет транслятор
производить определенные вычисления,
если он встречается в выражении. -
Оператор получения сегментной
составляющей адреса выраженияsegвозвращает физический адрес сегмента
для выражения (рис. 12), в качестве которого
могут выступать метка, переменная, имя
сегмента, имя группы или некоторое
символическое имя.
![]()
Рис. 12. Синтаксис оператора
получения сегментной составляющей
-
Оператор получения смещения выраженияoffsetпозволяет получить значение
смещения выражения (рис. 13) в байтах
относительно начала того сегмента, в
котором выражение определено.
![]()
Рис. 13. Синтаксис оператора
получения смещения
Например,
-
.data
pole
dw 5…
.code
…
mov
ax,seg pole
mov
es,ax
mov
dx,offset pole ;теперь
в
паре
es:dx полный
адрес
pole
Как и в языках высокого уровня, выполнение
операторов ассемблера при вычислении
выражений осуществляется в соответствии
с их приоритетами (см. табл. 2). Операции
с одинаковыми приоритетами выполняются
последовательно слева направо. Изменение
порядка выполнения возможно путем
расстановки круглых скобок, которые
имеют наивысший приоритет.
Таблица
2. Операторы и их приоритет
|
Оператор |
Приоритет |
|
length, size, |
1 |
|
. |
2 |
|
: |
3 |
|
ptr, offset, seg, type, this |
4 |
|
high, low |
5 |
|
+, — (унарные) |
6 |
|
*, /, mod, shl, |
7 |
|
+, -, (бинарные) |
8 |
|
eq, ne, lt, le, gt, ge |
9 |
|
not |
10 |
|
and |
11 |
|
or, xor |
12 |
|
short, type |
13 |
Директивы компиляции и инструкции препроцессору
Директивы компиляции и инструкции препроцессору их назначение и отличия
Данный вид меток используется для указания в каком месте и какой код будет создан. Чтобы было удобнее увидеть различия и назначение директив и инструкций данные сведены в таблицу
| тип | Инструкции препроцессора | Директивы компиляции |
| порядок выполнения | 1 | 2 |
| Где используется | Модуль УФ, Общие модули и модули объектов | Модуль формы, модуль команды, общий модуль управляемого приложения |
| По умолчанию | — | &НаСервере |
| Используемые термы | Сервер=НаСервере, Клиент, НаКлиенте, МобильноеПриложениеКлиент, МобильноеПриложениеСервер, ТолстыйКлиентОбычноеПриложение, ТолстыйКлиентУправляемоеПриложение, ВнешнееСоединение, ТонкийКлиент, ВебКлиент | &НаСервере, &НаКлиенте, &НаСервереБезКонтекста, &НаКлиентеНаСервереБезКонтекста, &НаКлиентеНаСервере |
| Совместимость | Рекомендация от 1С использовать Инструкции препроцессора внутри процедур и функций | |
| Назначение | для разграничения какой клиент будет использовать код | Для управления взаимодействием клиента и сервера (можно управлять контекстом) |
| К чему применяются | Может быть обрамлен любой кусок кода | Указываются только перед процедурами/функциями и переменными |
Как видно из таблицы инструкции препроцессору исполняются первыми и их задача глобально определить где будет исполняться код, на клиенте, сервере, мобильном приложении и т.д.
Назначение директив компиляции это управление клиент-серверным взаимодействием. Здесь уже идет более тонкая настройка по распределению нагрузки между клиентом и сервером — кто какие функции будет обрабатывать. Также здесь возможна работа по управлению контекстом для уменьшения нагрузки на систему.
Недостаточно прав для комментирования
this is basically a tutorial question to ask since am a beginner I would like to what is a difference between the using statement we use at start of our C# code to include assembly and namespaces
like this:
using System.Web.Services;
and when we write inside the code within the method or code.
like this:
using (SqlDataAdapter adapter = new SqlDataAdapter(cmd))
is there any difference or they both are same, any guidance would be helpful and appreciated.
![]()
O.C.
6,6411 gold badge25 silver badges26 bronze badges
asked Aug 3, 2011 at 8:16
![]()
7
The first (Using Directive) is to bring a namespace into scope.
This is for example, so you can write
StringBuilder MyStringBuilder = new StringBuilder();
rather than
System.Text.StringBuilder MyStringBuilder = new System.Text.StringBuilder();
The second (Using Statement) one is for correctly using (creating and disposing) an object implementing the IDisposable interface.
For example:
using (Font font1 = new Font("Arial", 10.0f))
{
byte charset = font1.GdiCharSet;
}
Here, the Font type implements IDisposable because it uses unmanaged resources that need to be correctly disposed of when we are no-longer using the Font instance (font1).
answered Aug 3, 2011 at 8:18
![]()
George DuckettGeorge Duckett
31.5k8 gold badges97 silver badges161 bronze badges
2
using (SqlDataAdapter adapter = new SqlDataAdapter(cmd))
This using disposes the adapter object automatically once the control leaves the using block.
This is equivalent to the call
SqlDataAdapter adapter = new SqlDataAdapter(cmd)
adapter.dispose();
See official documentation on this:
http://msdn.microsoft.com/en-us/library/yh598w02(v=vs.71).aspx
answered Aug 3, 2011 at 8:19
![]()
Madhur AhujaMadhur Ahuja
22.1k14 gold badges70 silver badges124 bronze badges
3
They are about as different as you can get.
The first shows intent to use things within a namespace.
The second takes a reference to a disposable object and ensures it is disposed, no matter what happens (like implementing try/finally)
answered Aug 3, 2011 at 8:19
![]()
Moo-JuiceMoo-Juice
38k10 gold badges76 silver badges126 bronze badges
I’m sure someone will spend a great deal of time answering what amounts to a Google search but here are a couple of links to get you started.
The using Statement (C# Reference) ensures that Dispose is called even if an exception occurs while you are calling methods on the object.
To allow the use of types in a namespace so that you do not have to qualify the use of a type in that namespace use using Directive (C# Reference).
You may find that MSDN is a great resource to spend some time browsing.
answered Aug 3, 2011 at 8:22
![]()
McArtheyMcArthey
1,60430 silver badges61 bronze badges