
Доброго времени суток, друзья!
Изучение настоящей шпаргалки не сделает вас мастером SQL, но позволит получить общее представление об этом языке программирования и возможностях, которые он предоставляет. Рассматриваемые в шпаргалке возможности являются общими для всех или большинства диалектов SQL.
Для более полного погружения в SQL рекомендую изучить эти руководства по MySQL и PostgreSQL от Метанита. Они хороши тем, что просты в изучении и позволяют быстро начать работу с названными СУБД.
Официальная документация по MySQL.
Официальная документация по PostreSQL (на русском языке).
Свежий туториал по SQL от Codecamp.
Свежая шпаргалка по SQL в формате PDF.
При обнаружении ошибок, опечаток и неточностей, не стесняйтесь писать мне в личку.
Содержание
- Что такое SQL?
- Почему SQL?
- Процесс SQL
- Команды SQL
- Что такое таблица?
- Что такое поле?
- Что такое запись или строка?
- Что такое колонка?
Что такое NULL?- Ограничения
- Целостность данных
- Нормализация БД
- Синтаксис SQL
- Типы данных
- Операторы
- Выражения
- Создание БД
- Удаление БД
- Выбор БД
- Создание таблицы
- Удаление таблицы
- Добавление колонок
- Выборка полей
Предложение WHEREОператоры ANDиOR- Обновление полей
- Удаление записей
Предложения LIKEиREGEXПредложение TOP/LIMIT/ROWNUMПредложения ORDER BYиGROUP BYКлючевое слово DISTINCT- Соединения
Предложение UNIONПредложение UNION ALL- Синонимы
- Индексы
- Обновление таблицы
- Очистка таблицы
- Представления
HAVING- Транзакции
- Временные таблицы
- Клонирование таблицы
- Подзапросы
- Последовательности
Что такое SQL?
SQL — это язык структурированных запросов (Structured Query Language), позволяющий хранить, манипулировать и извлекать данные из реляционных баз данных (далее — РБД, БД).
↥ Наверх
Почему SQL?
SQL позволяет:
- получать доступ к данным в системах управления РБД
- описывать данные (их структуру)
- определять данные в БД и управлять ими
- взаимодействовать с другими языками через модули SQL, библиотеки и предваритальные компиляторы
- создавать и удалять БД и таблицы
- создавать представления, хранимые процедуры (stored procedures) и функции в БД
- устанавливать разрешения на доступ к таблицам, процедурам и представлениям
↥ Наверх
Процесс SQL
При выполнении любой SQL-команды в любой RDBMS (Relational Database Management System — система управления РБД, СУБД, например, PostgreSQL, MySQL, MSSQL, SQLite и др.) система определяет наилучший способ выполнения запроса, а движок SQL определяет способ интерпретации задачи.
В данном процессе участвует несколького компонентов:
- диспетчер запросов (Query Dispatcher)
- движок оптимизации (Optimization Engines)
- классический движок запросов (Classic Query Engine)
- движок запросов SQL (SQL Query Engine) и т.д.
Классический движок обрабатывает все не-SQL-запросы, а движок SQL-запросов не обрабатывает логические файлы.
↥ Наверх
Команды SQL
Стандартными командами для взаимодействия с РБД являются CREATE, SELECT, INSERT, UPDATE, DELETE и DROP. Эти команды могут быть классифицированы следующим образом:
DDL— язык определения данных (Data Definition Language)
DML— язык изменения данных (Data Manipulation Language)
DCL— язык управления данными (Data Control Language)
Обратите внимание: использование верхнего регистра в названиях команд SQL — это всего лишь соглашение, большинство СУБД нечувствительны к регистру. Тем не менее, форма записи инструкций, когда названия команд пишутся большими буквами, а названия таблиц, колонок и др. — маленькими, позволяет быстро определять назначение производимой с данными операции.
↥ Наверх
Что такое таблица?
Данные в СУБД хранятся в объектах БД, называемых таблицами (tables). Таблица, как правило, представляет собой коллекцию связанных между собой данных и состоит из определенного количества колонок и строк.
Таблица — это самая распространенная и простая форма хранения данных в РБД. Вот пример таблицы с пользователями (users):
↥ Наверх
Что такое поле?
Каждая таблица состоит из небольших частей — полей (fields). Полями в таблице users являются userId, userName, age, city и status. Поле — это колонка таблицы, предназначенная для хранения определенной информации о каждой записи в таблице.
Обратите внимание: вместо userId и userName можно было бы использовать id и name, соответственно. Но при работе с несколькими объектами, содержащими свойство id, бывает сложно понять, какому объекту принадлежит идентификатор, особенно, если вы, как и я, часто прибегаете к деструктуризации. Что касается слова name, то оно часто оказывается зарезервизованным, т.е. уже используется в среде, в которой выполняется код, поэтому я стараюсь его не использовать.
↥ Наверх
Что такое запись или строка?
Запись или строка (record/row) — это любое единичное вхождение (entry), существующее в таблице. В таблице users 5 записей. Проще говоря, запись — это горизонтальное вхождение в таблице.
↥ Наверх
Что такое колонка?
Колонка (column) — это вертикальное вхождение в таблице, содержащее всю информацию, связанную с определенным полем. В таблице users одной из колонок является city, которая содержит названия городов, в которых проживают пользователи.
↥ Наверх
Что такое нулевое значение?
Нулевое значение (NULL) — это значение поля, которое является пустым, т.е. нулевое значение — это значение поля, не имеющего значения. Важно понимать, что нулевое значение отличается от значения 0 и от значения поля, содержащего пробелы (`). Поле с нулевым значением - это такое поля, которое осталось пустым при создании записи. Также, следует учитывать, что в некоторых СУБД пустая строка (») — этоNULL`, а в некоторых — это разные значения.
↥ Наверх
Ограничения
Ограничения (constraints) — это правила, применяемые к данным. Они используются для ограничения данных, которые могут быть записаны в таблицу. Это обеспечивает точность и достоверность данных в БД.
Ограничения могут устанавливаться как на уровне колонки, так и на уровне таблицы.
Среди наиболее распространенных ограничений можно назвать следующие:
NOT NULL— колонка не может иметь нулевое значениеDEFAULT— значение колонки по умолчаниюUNIQUE— все значения колонки должны быть уникальнымиPRIMARY KEY— первичный или основной ключ, уникальный идентификатор записи в текущей таблицеFOREIGN KEY— внешний ключ, уникальный идентификатор записи в другой таблице (таблице, связанной с текущей)CHECK— все значения в колонке должны удовлетворять определенному условиюINDEX— быстрая запись и извлечение данных
Любое ограничение может быть удалено с помощью команды ALTER TABLE и DROP CONSTRAINT + название ограничения. Некоторые реализации предоставляют сокращения для удаления ограничений и возможность отключать ограничения вместо их удаления.
↥ Наверх
Целостность данных
В каждой СУБД существуют следующие категории целостности данных:
- целостность объекта (Entity Integrity) — в таблице не должно быть дубликатов (двух и более строк с одинаковыми значениями)
- целостность домена (Domain Integrity) — фильтрация значений по типу, формату или диапазону
- целостность ссылок (Referential integrity) — строки, используемые другими записями (строки, на которые в других записях имеются ссылки), не могут быть удалены
- целостность, определенная пользователем (User-Defined Integrity) — дополнительные правила
↥ Наверх
Нормализация БД
Нормализация — это процесс эффективной организации данных в БД. Существует две главных причины, обуславливающих необходимость нормализации:
- предотвращение записи в БД лишних данных, например, хранения одинаковых данных в разных таблицах
- обеспечение «оправданной» связи между данными
Нормализация предполагает соблюдение нескольких форм. Форма — это формат структурирования БД. Существует три главных формы: первая, вторая и, соответственно, третья. Я не буду вдаваться в подробности об этих формах, при желании, вы без труда найдете необходимую информацию.
↥ Наверх
Синтаксис SQL
Синтаксис — это уникальный набор правил и рекомендаций. Все инструкции SQL должны начинаться с ключевого слова, такого как SELECT, INSERT, UPDATE, DELETE, ALTER, DROP, CREATE, USE, SHOW и т.п. и заканчиваться точкой с запятой (;) (точка с запятой не входит в синтаксис SQL, но ее наличия, как правило, требуют консольные клиенты СУБД для обозначения окончания ввода команды). SQL не чувствителен к регистру, т.е. SELECT, select и SeLeCt являются идентичными инструкицями. Исключением из этого правила является MySQL, где учитывается регистр в названии таблицы.
Примеры синтаксиса
-- выборка
SELECT col1, col2, ...colN
FROM tableName;
SELECT DISTINCT col1, col2, ...colN
FROM tableName;
SELECT col1, col2, ...colN
FROM tableName
WHERE condition;
SELECT col1, col2, ...colN
FROM tableName
WHERE condition1 AND|OR condition2;
SELECT col2, col2, ...colN
FROM tableName
WHERE colName IN (val1, val2, ...valN);
SELECT col1, col2, ...colN
FROM tableName
WHERE colName BETWEEN val1 AND val2;
SELECT col1, col2, ...colN
FROM tableName
WHERE colName LIKE pattern;
SELECT col1, col2, ...colN
FROM tableName
WHERE condition
ORDER BY colName [ASC|DESC];
SELECT SUM(colName)
FROM tableName
WHERE condition
GROUP BY colName;
SELECT COUNT(colName)
FROM tableName
WHERE condition;
SELECT SUM(colName)
FROM tableName
WHERE condition
GROUP BY colName
HAVING (function condition);
-- создание таблицы
CREATE TABLE tableName (
col1 datatype,
col2 datatype,
...
colN datatype,
PRIMARY KEY (одна или более колонка)
);
-- удаление таблицы
DROP TABLE tableName;
-- создание индекса
CREATE UNIQUE INDEX indexName
ON tableName (col1, col2, ...colN);
-- удаление индекса
ALTER TABLE tableName
DROP INDEX indexName;
-- получение описания структуры таблицы
DESC tableName;
-- очистка таблицы
TRUNCATE TABLE tableName;
-- добавление/удаление/модификация колонок
ALTER TABLE tableName ADD|DROP|MODIFY colName [datatype];
-- переименование таблицы
ALTER TABLE tableName RENAME TO newTableName;
-- вставка значений
INSERT INTO tableName (col1, col2, ...colN)
VALUES (val1, val2, ...valN)
-- обновление записей
UPDATE tableName
SET col1 = val1, col2 = val2, ...colN = valN
[WHERE condition];
-- удаление записей
DELETE FROM tableName
WHERE condition;
-- создание БД
CREATE DATABASE [IF NOT EXISTS] dbName;
-- удаление БД
DROP DATABASE [IF EXISTS] dbName;
-- выбор БД
USE dbName;
-- завершения транзакции
COMMIT;
-- отмена изменений
ROLLBACK;↥ Наверх
Типы данных
Каждая колонка, переменная и выражение в SQL имеют определенный тип данных (data type). Основные категории типов данных:
Точные числовые
Приблизительные числовые
Дата и время
Строковые символьные
Строковые символьные (юникод)
Бинарные
Смешанные
↥ Наверх
Операторы
Оператор (operators) — это ключевое слово или символ, которые, в основном, используются в инструкциях WHERE для выполнения каких-либо операций. Они используются как для определения условий, так и для объединения нескольких условий в инструкции.
В дальнейших примерах мы будем исходить из предположения, что переменная a имеет значение 10, а b — 20.
Арифметические
Операторы сравнения
Логические операторы
↥ Наверх
Выражения
Выражение (expression) — это комбинация значений, операторов и функций для оценки (вычисления) значения. Выражения похожи на формулы, написанные на языке запросов. Они могут использоваться для извлечения из БД определенного набора данных.
Базовый синтаксис выражения выглядит так:
SELECT col1, col2, ...colN
FROM tableName
WHERE [condition|expression];Существуют различные типы выражений: логические, числовые и выражения для работы с датами.
Логические
Логические выражения извлекают данные на основе совпадения с единичным значением.
SELECT col1, col2, ...colN
FROM tableName
WHERE выражение для поиска совпадения с единичным значением;Предположим, что в таблице users имеются следующие записи:
Выполняем поиск активных пользователей:
SELECT * FROM users WHERE status = active;Результат:
Числовые
Используются для выполнения арифметических операций в запросе.
SELECT numericalExpression as operationName
[FROM tableName
WHERE condition];Простой пример использования числового выражения:
SELECT (10 + 5) AS addition;Результат:
Существует несколько встроенных функций, таких как count(), sum(), avg(), min(), max() и др. для выполнения так называемых агрегирующих вычислений данных таблицы или колонки.
SELECT COUNT(*) AS records FROM users;Результат:
AVG— вычисляет среднее значениеSUM— вычисляет сумму значенийMIN— вычисляет наименьшее значениеMAX— вычисляет наибольшее значениеCOUNT— вычисляет количество записей в таблице
Также существует несколько встроенных функций для работы со строками:
CONCAT— объединение строкLENGTH— возвращает количество символов в строкеTRIM— удаляет пробелы в начале и конце строкиSUBSTRING— извлекает подстроку из строкиREPLACE— заменяет подстроку в строкеLOWER— переводит символы строки в нижний регистрUPPER— переводит символы строки в верхний регистр и т.д.
с числами:
ROUND— округляет числоTRUNCATE— обрезает дробное число до указанного количества знаков после запятойCEILING— возвращает наименьшее целое число, которое больше или равно текущему значениюFLOOR— возвращает наибольшее целое число, которое меньше или равно текущему значениюPOWER— возводит число в указанную степеньSQRT— возвращает квадратный корень числаRAND— генерирует случайное число с плавающей точкой в диапазоне от 0 до 1
Выражения для работы с датами
Эти выражения, как правило, возвращают текущую дату и время.
SELECT CURRENT_TIMESTAMP;Результат:
CURRENT_TIMESTAMP — это и выражение, и функция (CURRENT_TIMESTAMP()). Другая функция для получения текущей даты и времени — NOW().
Другие функции для получения текущей даты и времени:
CURDATE/CURRENT_DATE— возвращает текущую датуCURTIME/CURRENT_TIME— возвращает текущее время и т.д.
Функции для разбора даты и времени:
DAYOFMONTH(date)— возвращает день месяца в виде числаDAYOFWEEK(date)— возвращает день недели в виде числаDAYOFYEAR(date)— возвращает номер дня в годуMONTH(date)— возвращает месяцYEAR(date)— возвращает годLAST_DAY(date)— возвращает последний день месяца в виде датыHOUR(time)— возвращает часMINUTE(time)— возвращает минутыSECOND(time)— возвращает секунды и др.
Функции для манипулирования датами:
DATE_ADD(date, interval)— выполняет сложение даты и определенного временного интервалаDATE_SUB(date, interval)— выполняет вычитание из даты определенного временного интервалаDATEDIFF(date1, date2)— возвращает разницу в днях между двумя датамиTO_DAYS(date)— возвращает количество дней с 0-го дня годаTIME_TO_SEC(time)— возвращает количество секунд с полуночи и др.
Для форматирования даты и времени используются функции DATE_FORMAT(date, format) и TIME_FORMAT(date, format), соответственно.
↥ Наверх
Создание БД
Для создания БД используется инструкция CREATE DATABASE.
CREATE DATABASE dbName;
-- или
CREATE DATABASE IF NOT EXISTS dbName;Условие IF NOT EXISTS позволяет избежать получения ошибки при попытке создания БД, которая уже существует.
Название БД должно быть уникальным в пределах СУБД.
Создаем БД testDB:
CREATE DATABASE testDB;Получаем список БД:
SHOW DATABASES;Результат:
↥ Наверх
Удаление БД
Для удаления БД используется инструкция DROP DATABASE.
DROP DATABASE dbName;
-- или
DROP DATABASE IF EXISTS dbName;Условие IF EXISTS позволяет избежать получения ошибки при попытке удаления несуществующей БД.
Удаляем testDB:
DROP DATABASE testDB;Обратите внимание: при удалении БД уничтожаются все данные, которые в ней хранятся, так что будьте предельно внимательны при использовании данной команды.
Проверяем, что БД удалена:
SHOW DATABASES;Для получения списка таблиц используется инструкция SHOW TABLES.
Результат:
↥ Наверх
Выбор БД
При наличии нескольких БД, перед выполнением каких-либо операций, необходимо выбрать БД. Для этого используется инструкция USE.
USE dbName;Предположим, что мы не удаляли testDB. Тогда мы можем выбрать ее так:
USE testDB;↥ Наверх
Создание таблицы
Создание таблицы предполагает указание названия таблицы и определение колонок таблицы и их типов данных. Для создания таблицы используется инструкция CREATE TABLE.
CREATE TABLE tableName (
col1 datatype,
col2 datatype,
...
colN datatype,
PRIMARY KEY (хотя бы одна колонка)
);Для создания таблицы путем копирования другой таблицы используется сочетание CREATE TABLE и SELECT.
Пример создания таблицы users, где первичным ключом являются идентификаторы пользователей, а поля для имени и возраста пользователя не могут быть нулевыми:
CREATE TABLE users (
userId INT,
userName VARCHAR(20) NOT NULL,
age INT NOT NULL,
city VARCHAR(20),
status VARCHAR(8),
PRIMARY KEY (id)
);Проверяем, что таблица была создана:
DESC users;Результат:
↥ Наверх
Удаление таблицы
Для удаления таблицы используется инструкция DROP TABLE.
Обратите внимание: при удалении таблицы, навсегда удаляются все хранящиеся в ней данные, индексы, триггеры, ограничения и разрешения, так что будьте предельно внимательны при использовании данной команды.
Удаляем таблицу users:
DROP TABLE users;Теперь, если мы попытаемся получить описание users, то получим ошибку:
DESC users;
-- ERROR 1146 (42S02): Table 'testDB.users' doesn't exist↥ Наверх
Добавление колонок
Для добавления в таблицу колонок используется инструкция INSERT INTO.
INSERT INTO tableName (col1, col2, ...colN)
VALUES (val1, val2, ...valN);Названия колонок можно не указывать, однако, в этом случае значения должны перечисляться в правильном порядке.
INSERT INTO tableName VALUES (val1, val2, ...valN);Во избежание ошибок, рекомендуется всегда перечислять названия колонок.
Предположим, что мы не удаляли таблицу users. Заполним ее пользователями:
INSERT INTO users (userId, userName, age, city, status)
VALUES (1, 'Igor', 25, 'Moscow', 'active');
INSERT INTO users (userId, userName, age, city, status)
VALUES (2, 'Vika', 26, 'Ekaterinburg', 'inactive');
INSERT INTO users (userId, userName, age, city, status)
VALUES (3, 'Elena', 27, 'Ekaterinburg', 'active');В таблицу можно добавлять несколько строк за один раз.
INSERT INTO users (userId, userName, age, city, status)
VALUES
(1, 'Igor', 25, 'Moscow', 'active'),
(2, 'Vika', 26, 'Ekaterinburg', 'inactive'),
(3, 'Elena', 27, 'Ekaterinburg', 'active');Также, как было отмечено, при добавлении строки названия полей можно опускать:
INSERT INTO users
VALUES (4, 'Oleg', 28, 'Moscow', 'inactive');Результат:
Заполнение таблицы с помощью другой таблицы
INSERT INTO tableName [(col1, col2, ...colN)]
SELECT col1, col2, ...colN
FROM anotherTable
[WHERE condition];↥ Наверх
Выборка полей
Для выборки полей из таблицы используется инструкция SELECT. Она возвращает данные в виде результирующей таблицы (результирующего набора, result-set).
SELECT col1, col2, ...colN
FROM tableName;Для выборки всех полей используется такой синтаксис:
SELECT * FROM tableName;Произведем выборку полей userId, userName и age из таблицы users:
SELECT userId, userName, age FROM users;Результат:
↥ Наверх
Предложение WHERE
Предложение WHERE используется для фильтрации возвращаемых данных. Оно используется совместно с SELECT, UPDATE, DELETE и другими инструкциями.
SELECT col1, col2, ...col2
FROM tableName
WHERE condition;Условие (condition), которому должны удовлетворять возвращаемые записи, определяется с помощью операторов сравнения или логических операторов типа >, <, =, NOT, LIKE и т.д.
Сделаем выборку полей userId, userName и age активных пользователей:
SELECT userId, userName, age
FROM users
WHERE status = 'active';Результат:
Сделаем выборку полей userId, age и city пользователя с именем Vika.
SELECT userId, age, city
FROM users
WHERE userName = 'Vika';Результат:
Обратите внимание: строки в предложении WHERE должны быть обернуты в одинарные кавычки (''), а числа, напротив, указываются как есть.
↥ Наверх
Операторы AND и OR
Конъюнктивный оператор AND и дизъюнктивный оператор OR используются для соединения нескольких условий при фильтрации данных.
AND
SELECT col1, col2, ...colN
FROM tableName
WHERE condition1 AND condition2 ...AND conditionN;Возвращаемые записи должны удовлетворять всем указанным условиям.
Сделаем выборку полей userId, userName и age активных пользователей старше 26 лет:
SELECT userId, userName, age
FROM users
WHERE status = active AND age > 26;Результат:
OR
SELECT col1, col2, ...colN
FROM tableName
WHERE condition1 OR condition2 ...OR conditionN;Возвращаемые записи должны удовлетворять хотя бы одному условию.
Сделаем выборку тех же полей неактивных пользователей или пользователей, младше 27 лет:
SELECT userId, userName, age
FROM users
WHERE status = inactive OR age < 27;Результат:
↥ Наверх
Обновление полей
Для обновления полей используется инструкция UPDATE ... SET. Эта инструкция, обычно, используется в сочетании с предложением WHERE.
UPDATE tableName
SET col1 = val1, col2 = val2, ...colN = valN
[WHERE condition];Обновим возраст пользователя с именем Igor:
UPDATE users
SET age = 30
WHERE username = 'Igor';Если в данном случае опустить WHERE, то будет обновлен возраст всех пользователей.
↥ Наверх
Удаление записей
Для удаления записей используется инструкция DELETE. Эта инструкция также, как правило, используется в сочетании с предложением WHERE.
DELETE FROM tableName
[WHERE condition];Удалим неактивных пользователей:
DELETE FROM users
WHERE status = 'inactive';Если в данном случае опустить WHERE, то из таблицы users будут удалены все записи.
↥ Наверх
Предложения LIKE и REGEX
LIKE
Предложение LIKE используется для сравнения значений с помощью операторов с подстановочными знаками. Существует два вида таких операторов:
- проценты (
%) - нижнее подчеркивание (
_)
% означает 0, 1 или более символов. _ означает точно 1 символ.
SELECT col1, col2, ...colN FROM tableName
WHERE col LIKE 'xxx%'
-- или
WHERE col LIKE '%xxx%'
-- или
WHERE col LIKE '%xxx'
-- или
WHERE col LIKE 'xxx_'
-- и т.д.Примеры:
Сделаем выборку неактивных пользователей:
SELECT * FROM users
WHERE status LIKE 'in%';Результат:
Сделаем выборку пользователей 30 лет и старше:
SELECT * FROM users
WHERE age LIKE '3_';Результат:
REGEX
Предложение REGEX позволяет определять регулярное выражение, которому должна соответствовать запись.
SELECT col1, col2, ...colN FROM tableName
WHERE colName REGEXP регулярное выражение;В регулярное выражении могут использоваться следующие специальные символы:
^— начало строки$— конец строки.— любой символ[символы]— любой из указанных в скобках символов[начало-конец]— любой символ из диапазона|— разделяет шаблоны
Сделаем выборку пользователей с именами Igor и Vika:
SELECT * FROM users
WHERE userName REGEXP 'Igor|Vika';Результат:
↥ Наверх
Предложение TOP/LIMIT/ROWNUM
Данные предложения позволяют извлекать указанное количество или процент записей с начала таблицы. Разные СУБД поддерживают разные предложения.
SELECT TOP number|percent col1, col2, ...colN
FROM tableName
[WHERE condition];Сделаем выборку первых трех пользователей:
SELECT TOP 3 * FROM users;Результат:
В mysql:
SELECT * FROM users
LIMIT 3, [offset];Параметр offset (смещение) определяет количество пропускаемых записей. Например, так можно извлечь первых двух пользователей, начиная с третьего:
SELECT * FROM users
LIMIT 2, 2;В oracle:
SELECT * FROM users
WHERE ROWNUM <= 3;↥ Наверх
Предложения ORDER BY и GROUP BY
ORDER BY
Предложение ORDER BY используется для сортировки данных по возрастанию (ASC) или убыванию (DESC). Многие СУБД по умолчанию выполняют сортировку по возрастанию.
SELECT col1, col2, ...colN
FROM tableName
[WHERE condition]
[ORDER BY col1, col2, ...colN] [ASC | DESC];Обратите внимание: колонки для сортировки должны быть указаны в списке колонок для выборки.
Сделаем выборку пользователей, отсортировав их по городу и возрасту:
SELECT * FROM users
ORDER BY city, age;Результат:
Теперь выполним сортировку по убыванию:
SELECT * FROM users
ORDER BY city, age DESC;Определим собственный порядок сортировки по убыванию:
SELECT * FROM users
ORDER BY (CASE city
WHEN 'Ekaterinburg' THEN 1
WHEN 'Moscow' THEN 2
ELSE 100 END) ASC, city DESC;GROUP BY
Предложение GROUP BY используется совместно с инструкцией SELECT для группировки записей. Оно указывается после WHERE и перед ORDER BY.
SELECT col1, col2, ...colN
FROM tableName
WHERE condition
GROUP BY col1, col2, ...colN
ORDER BY col1, col2, ...colN;Сгруппируем активных пользователей по городам:
SELECT city, COUNT(city) AS amount FROM users
WHERE status = active
GROUP BY city
ORDER BY city;Результат:
↥ Наверх
Ключевое слово DISTINCT
Ключевое слово DISTINCT используется совместно с инструкцией SELECT для возврата только уникальных записей (без дубликатов).
SELECT DISTINCT col1, col2, ...colN
FROM tableName
[WHERE condition];Сделаем выборку городов проживания пользователей:
SELECT DISTINCT city
FROM users;Результат:
↥ Наверх
Соединения
Соединения (joins) используются для комбинации записей двух и более таблиц.
Предположим, что кроме users, у нас имеется таблица orders с заказами пользователей следующего содержания:
Сделаем выборку полей userId, userName, age и amount из наших таблиц посредством их соединения:
SELECT userId, userName, age, amount
FROM users, orders
WHERE users.userId = orders.userId;Результат:
При соединении таблиц могут использоваться такие операторы, как =, <, >, <>, <=, >=, !=, BETWEEN, LIKE и NOT, однако наиболее распространенным является =.
Существуют разные типы объединений:
INNER JOIN— возвращает записи, имеющиеся в обеих таблицахLEFT JOIN— возвращает записи из левой таблицы, даже если такие записи отсутствуют в правой таблицеRIGHT JOIN— возвращает записи из правой таблицы, даже если такие записи отсутствуют в левой таблицеFULL JOIN— возвращает все записи объединяемых таблицCROSS JOIN— возвращает все возможные комбинации строк обеих таблицSELF JOIN— используется для объединения таблицы с самой собой
↥ Наверх
Предложение UNION
Предложение/оператор UNION используется для комбинации результатов двух и более инструкций SELECT. При этом, возвращаются только уникальные записи.
В случае с UNION, каждая инструкция SELECT должна иметь:
- одинаковый набор колонок для выборки
- одинаковое количество выражений
- одинаковые типы данных колонок и
- одинаковый порядок колонок
Однако, они могут быть разной длины.
SELECT col1, col2, ...colN
FROM table1
[WHERE condition]
UNION
SELECT col1, col2, ...colN
FROM table2
[WHERE condition];Объединим наши таблицы users и orders:
SELECT userId, userName, amount, date
FROM users
LEFT JOIN orders
ON users.useId = orders.userId
UNION
SELECT userId, userName, amount, date
FROM users
RIGHT JOIN orders
ON users.userId = orders.userId;Результат:
↥ Наверх
Предложение UNION ALL
Предложение UNION ALL также используется для объединения результатов двух и более инструкций SELECT. При этом, возвращаются все записи, включая дубликаты.
SELECT col1, col2, ...colN
FROM table1
[WHERE condition]
UNION ALL
SELECT col1, col2, ...colN
FROM table2
[WHERE condition];Существует еще два предложения, похожих на UNION:
INTERSECT— используется для комбинации результатов двух и болееSELECT, но возвращаются только строки из первогоSELECT, совпадающие со строками из второгоSELECTEXCEPT|MINUS— возвращаются только строки из первогоSELECT, отсутствующие во второмSELECT
↥ Наверх
Синонимы
Синонимы (aliases) позволяют временно изменять названия таблиц и колонок. «Временно» означает, что новое название используется только в текущем запросе, в БД название остается прежним.
Синтаксис синонима таблицы:
SELECT col1, col2, ...colN
FROM tableName AS aliasName
[WHERE condition];Синтаксис синонима колонки:
SELECT colName AS aliasName
FROM tableName
[WHERE condition];Пример использования синонимов таблиц:
SELECT U.userId, U.userName, U.age, O.amount
FROM users AS U, orders AS O
WHERE U.userId = O.userId;Результат:
Пример использования синонимов колонок:
SELECT userId AS user_id, userName AS user_name, age AS user_age
FROM users
WHERE status = active;Результат:
↥ Наверх
Индексы
Создание индексов
Индексы — это специальные поисковые таблицы (lookup tables), которые используются движком БД в целях более быстрого извлечения данных. Проще говоря, индекс — это указатель или ссылка на данные в таблице.
Индексы ускоряют работу инструкции SELECT и предложения WHERE, но замедляют работу инструкций UPDATE и INSERT. Индексы могут создаваться и удаляться, не оказывая никакого влияния на данные.
Для создания индекса используется инструкция CREATE INDEX, позволяющая определять название индекса, индексируемые колонки и порядок индексации (по возрастанию или по убыванию).
К индексам можно применять ограничение UNIQUE для того, чтобы обеспечить их уникальность.
Синтаксис создания индекса:
CREATE INDEX indexName ON tableName;Синтаксис создания индекса для одной колонки:
CREATE INDEX indexName
ON tableName (colName);Синтакис создания уникальных индексов (такие индексы используются не только для повышения производительности, но и для обеспечения согласованности данных):
CREATE UNIQUE INDEX indexName
ON tableName (colName);Синтаксис создания индексов для нескольких колонок (композиционный индекс):
CREATE INDEX indexName
ON tableName (col1, col2, ...colN);Решение о создании индексов для одной или нескольких колонок следует принимать на основе того, какие колонки будут часто использоваться в запросе WHERE в качестве условия для сортировки строк.
Для ограничений PRIMARY KEY и UNIQUE автоматически создаются неявные индексы.
Удаление индексов
Для удаления индексов используется инструкция DROP INDEX:
DROP INDEX indexName;Несмотря на то, что индексы предназначены для повышения производительности БД, существуют ситуации, в которых их использования лучше избегать.
К таким ситуациям относится следующее:
- индексы не должны использоваться в маленьких таблицах
- в таблицах, которые часто и в большом объеме обновляются или перезаписываются
- в колонках, которые содержат большое количество нулевых значений
- в колонках, над которыми часто выполняются операции
↥ Наверх
Обновление таблицы
Команда ALTER TABLE используется для добавления, удаления и модификации колонок существующей таблицы. Также эта команда используется для добавления и удаления ограничений.
Синтаксис:
-- добавление новой колонки
ALTER TABLE tableName ADD colName datatype;
-- удаление колонки
ALTER TABLE tableName DROP COLUMN colName;
-- изменение типа данных колонки
ALTER TABLE tableName MODIFY COLUMN colName newDatatype;
-- добавление ограничения `NOT NULL`
ALTER TABLE tableName MODIFY colName datatype NOT NULL;
-- добавление ограничения `UNIQUE`
ALTER TABLE tableName
ADD CONSTRAINT myUniqueConstraint UNIQUE (col1, col2, ...colN);
-- добавление ограничения `CHECK`
ALTER TABLE tableName
ADD CONSTRAINT myUniqueConstraint CHECK (condition);
-- добавление первичного ключа
ALTER TABLE tableName
ADD CONSTRAINT myPrimaryKey PRIMARY KEY (col1, col2, ...colN);
-- удаление ограничения
ALTER TABLE tableName
DROP CONSTRAINT myUniqueContsraint;
-- mysql
ALTER TABLE tableName
DROP INDEX myUniqueContsraint;
-- удаление первичного ключа
ALTER TABLE tableName
DROP CONSTRAINT myPrimaryKey;
-- mysql
ALTER TABLE tableName
DROP PRIMARY KEY;Добавляем в таблицу users новую колонку — пол пользователя:
ALTER TABLE users ADD sex char(1);Удаляем эту колонку:
ALTER TABLE users DROP sex;↥ Наверх
Очистка таблицы
Команда TRUNCATE TABLE используется для очистки таблицы. Ее отличие от DROP TABLE состоит в том, что сохраняется структура таблицы (DROP TABLE полностью удаляет таблицу и все ее данные).
TRUNCATE TABLE tableName;Очищаем таблицу users:
TRUNCATE TABLE users;Проверяем, что users пустая:
SELECT * FROM users;
-- Empty set (0.00 sec)↥ Наверх
Представления
Представление (view) — это не что иное, как инструкция, записанная в БД под определенным названием. Другими словами, представление — это композиция таблицы в форме предварительно определенного запроса.
Представления могут содержать все или только некоторые строки таблицы. Представление может быть создано на основе одной или нескольких таблиц (это зависит от запроса для создания представления).
Представления — это виртутальные таблицы, позволяющие делать следующее:
- структурировать данные способом, который пользователи находят наиболее естественным или интуитивно понятным
- ограничивать доступ к данным таким образом, что пользователь может просматривать и (иногда) модифицировать только то, что ему нужно и ничего более
- объединять данные из нескольких таблиц для формирования отчетов
Создание представления
Для создания представления используется инструкция CREATE VIEW. Как было отмечено, представления могут создаваться на основе одной или нескольких таблиц, и даже на основе другого представления.
CREATE VIEW viewName AS
SELECT col1, col2, ...colN
FROM tableName
[WHERE condition];Создаем представление для имен и возраста пользователей:
CREATE VIEW usersView AS
SELECT userName, age
FROM users;Получаем данные с помощью представления:
SELECT * FROM usersView;Результат:
WITH CHECK OPTION
WITH CHECK OPTION — это настройка инструкции CREATE VIEW. Она позволяет обеспечить соответствие всех UPDATE и INSERT условию, определенном в представлении.
Если условие не удовлетворяется, выбрасывается исключение.
CREATE VIEW usersView AS
SELECT userName, age
FROM users
WHERE age IS NOT NULL
WITH CHECK OPTION;Обновление представления
Представление может быть обновлено при соблюдении следующих условий:
SELECTне содержит ключевого словаDISTINCTSELECTне содержит агрегирующих функцийSELECTне содержит функций установки значенийSELECTне содержит операций установки значенийSELECTне содержит предложенияORDER BYFROMне содержит больше одной таблицыWHEREне содержит подзапросы- запрос не содержит
GROUP BYилиHAVING - вычисляемые колонки не обновляются
- все ненулевые колонки из базовой таблицы включены в представление в том же порядке, в каком они указаны в запросе
INSERT
Пример обновления возраста пользователя с именем Igor в представлении:
UPDATE usersView
SET age = 31
WHERE userName = 'Igor';Обратите внимание: обновление строки в представлении приводит к ее обновлению в базовой таблице.
В представление могут добавляться новые строки с помощью команды INSERT. При выполнении этой команды должны соблюдаться те же правила, что и при выполнении команды UPDATE.
С помощью команды DELETE можно удалять строки из представления.
Удаляем из представления пользователя, возраст которого составляет 26 лет:
DELETE FROM usersView
WHERE age = 26;Обратите внимание: удаление строки в представлении приводит к ее удалению в базовой таблице.
Удаление представления
Для удаления представления используется инструкция DROP VIEW:
DROP VIEW viewName;Удаляем представление usersView:
DROP VIEW usersView;↥ Наверх
HAVING
Предложение HAVING используется для фильтрации результатов группировки. WHERE используется для применения условий к колонкам, а HAVING — к группам, созданным с помощью GROUP BY.
HAVING должно указываться после GROUP BY, но перед ORDER BY (при наличии).
SELECT col1, col2, ...colN
FROM table1, table2, ...tableN
[WHERE condition]
GROUP BY col1, col2, ...colN
HAVING condition
ORDER BY col1, col2, ...colN;↥ Наверх
Транзакции
Транзакция — это единица работы или операции, выполняемой над БД. Это последовательность операций, выполняемых в логическом порядке. Эти операции могут запускаться как пользователем, так и какой-либо программой, функционирующей в БД.
Транзакция — это применение одного или более изменения к БД. Например, при создании/обновлении/удалении записи мы выполняем транзакцию. Важно контролировать выполнение таких операций в целях обеспечения согласованности данных и обработки возможных ошибок.
На практике, запросы, как правило, не отправляются в БД по одному, они группируются и выполняются как часть транзакции.
Свойства транзакции
Транзакции имеют 4 стандартных свойства (ACID):
- атомарность (atomicity) — все операции транзакции должны быть успешно завершены. В противном случае, транзакция прерывается, а все изменения отменяются (происходит откат к предыдущему состоянию)
- согласованность (consistency) — состояние должно изменться в полном соответствии с операциями транзакции
- изоляция или автономность (isolation) — транзакции не зависят друг от друга и не оказывают друг на друга никакого влияния
- долговечность (durability) — результат звершенной транзакции должен сохраняться при поломке системы
Управление транзакцией
Для управления транзакцией используются следующие команды:
BEGIN|START TRANSACTION— запуск транзакцииCOMMIT— сохранение измененийROLLBACK— отмена измененийSAVEPOINT— контрольная точка для отмены измененийSET TRANSACTION— установка характеристик текущей транзакции
Команды для управления транзакцией могут использоваться только совместно с такими запросами как INSERT, UPDATE и DELETE. Они не могут использоваться во время создания и удаления таблиц, поскольку эти операции автоматически отправляются в БД.
Удаляем пользователя, возраст которого составляет 26 лет, и отправляем изменения в БД:
BEGIN TRANSACTION
DELETE FROM users
WHERE age = 26;
COMMIT;Удаляем пользователя с именем Oleg и отменяем эту операцию:
BEGIN
DELETE FROM users
WHERE username = 'Oleg';
ROLLBACK;Контрольные точки создаются с помощью такого синтаксиса:
SAVEPOINT savepointName;Возврат к контрольной точке выполняется так:
ROLLBACK TO savepointName;Выполняем три запроса на удаление данных из users, создавая контрольные точки перед каждый удалением:
START TRANSACTION
SAVEPOINT sp1;
DELETE FROM users
WHERE age = 26;
SAVEPOINT sp2;
DELETE FROM users
WHERE userName = 'Oleg';
SAVEPOINT sp3;
DELETE FROM users
WHERE status = 'inactive';Отменяем два последних удаления, возвращаясь к контрльной точке sp2, созданной после первого удаления:
ROLLBACK TO sp2;Делаем выборку пользователей:
SELECT * FROM users;Результат:
Как видим, из таблицы был удален только пользователь с возрастом 26 лет.
Для удаление контрольной точки используется команда RELEASE SAVEPOINT. Естественно, после удаления контрольной точки, к ней нельзя будет вернуться с помощью ROLLBACK TO.
Команда SET TRANSACTION используется для инициализации транзакции, т.е. начала ее выполнения. При этом, можно определять некоторые характеристики транзакции. Например, так можно определить уровень доступа транзакции (доступна только для чтения или для записи тоже):
SET TRANSACTION [READ WRITE | READ ONLY];↥ Наверх
Временные таблицы
Некоторые СУБД поддерживают так называемые временные таблицы (temporary tables). Такие таблицы позволяют хранить и обрабатывать промежуточные результаты с помощью таких же запросов, как и при работе с обычными таблицами.
Временные таблицы могут быть очень полезными при необходимости хранения временных данных. Одной из главных особенностей таких таблиц является то, что они удаляются по завершении текущей сессии. При запуске скрипта временная таблица удаляется после завершения выполнения этого скрипта. При доступе к БД с помощью клиентской программы, такая таблица будет удалена после закрытия этой программы.
Временная таблица создается с помощью инструкции CREATE TEMPORARY TABLE, в остальном синтаксис создания таких таблиц идентичен синтаксису создания обычных таблиц.
Временная таблица удаляется точно также, как и обычная таблица, с помощью инструкции DROP TABLE.
↥ Наверх
Клонирование таблицы
Может возникнуть ситуация, когда потребуется получить точную копию существующей таблицы, а CREATE TABLE или SELECT окажется недостаточно в силу того, что мы хотим получить не только идентичную структуру, но также индексы, значения по умолчанию и т.д. копируемой таблицы.
В mysql, например, это можно сделать так:
- вызываем команду
SHOW CREATE TABLEдля получения инструкции, выполненной при создании таблицы, включая индексы и прочее - меняем название таблицы и выполняем запрос. Получаем точную копию таблицы
- опционально: если требуется содержимое копируемой таблицы, можно также использовать инструкции
INSERT INTOилиSELECT
↥ Наверх
Подзапросы
Подзапрос — это внутренний (вложенный) запрос другого запроса, встроенный (вставленный) с помощью WHERE или других инструкций.
Подзапрос используется для получения данных, которые будут использованы основным запросом в качестве условия для фильтрации возвращаемых записей.
Подзапросы могут использоваться в инструкциях SELECT, INSERT, UPDATE и DELETE, а также с операторами =, <, >, >=, <=, IN, BETWEEN и т.д.
Правила использования подзапросов:
- они должны быть обернуты в круглые скобки
- подзапрос должен содержать только одну колонку для выборки, если основной запрос не содержит несколько таких колонок, которые сравниваются в подзапросе
- в подзапросе нельзя использовать команду
ORDER BY, это можно сделать в основном запросе. В подзапросе для заменыORDER BYможно использоватьGROUP BY - подзапросы, возвращающие несколько значений, могут использоваться только с операторами, которые работают с наборами значений, такими как
IN - список
SELECTне может содержать ссылки на значения, которые оцениваются (вычисляются) какBLOB,ARRAY,CLOBилиNCLOB - подзапрос не может быть сразу передан в функцию для установки значений
- команду
BETWEENнельзя использовать совместно с подзапросом. Тем не менее, в самомподзапросе указанную команду использовать можно
Подзапросы, обычно, используются в инструкции SELECT.
SELECT col1, col2, ...colN
FROM table1, table2, ...tableN
WHERE colName operator
(SELECT col1, col2, ...colN
FROM table1, table2, tableN
[WHERE condition]);Пример:
SELECT * FROM users
WHERE userId IN (
SELECT userId FROM users
WHERE status = 'active'
);Результат:
Подзапросы могут использоваться в инструкции INSERT. Эта инструкция добавляет в таблицу данные, возвращаемые подзапросом. При этом, данные, возвращаемые подзапросом, могут быть модифицированы любыми способами.
INSERT INTO tableName col1, col2, ...colN
SELECT col1, col2, ...colN
FROM table1, table2, ...tableN
[WHERE operator [value]];Подзапросы могут использоваться в инструкции UPDATE. При этом, данные из подзапроса могут использоваться для обновления любого количества колонок.
UPDATE tableName
SET col = newVal
[WHERE operator [value]
(
SELECT colName
FROM tableName
[WHERE condition]
)
];Данные, возвращаемые подзапросом, могут использоваться и для удаления записей.
DELETE FROM tableName
[WHERE operator [value]
(
SELECT colName
FROM tableName
[WHERE condition]
)
];↥ Наверх
Последовательности
Последовательность — это набор целых чисел (1, 2, 3 и т.д.), генерируемых автоматически. Последовательности часто используются в БД, поскольку многие приложения нуждаются в уникальных значениях, используемых для идентификации строк.
Приведенные ниже примеры рассчитаны на mysql.
Простейшим способом определения последовательности является использование AUTO_INCREMENT при создании таблицы:
CREATE TABLE tableName (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
PRIMARY KEY (id),
-- другие строки
);Для того, чтобы заново пронумеровать строки с помощью автоматически генерируемых значений (например, при удалении большого количества строк), можно удалить колонку, содержащую такие значения и создать ее заново. Обратите внимание: такая таблица не должна быть частью объединения.
ALTER TABLE tableName DROP id;
ALTER TABLE tableName
ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST,
ADD PRIMARY KEY (id);По умолчанию значения, генерируемые с помощью AUTO_INCREMENT, начинаются с 1. Для того, чтобы установить другое начальное значение достаточно указать, например, AUTO_INCREMENT = 100 — в этом случае нумерация строк начнется со 100.
↥ Наверх

От автора: SQL регламентируется уникальным набором правил и рекомендаций под общим названием Синтаксис. В этой статье мы полностью опишем базовый синтаксис SQL.
Все инструкции SQL начинаются с ключевых слов, таких как SELECT, INSERT, UPDATE, DELETE, ALTER, DROP, CREATE, USE, SHOW, и все инструкции заканчиваются точкой с запятой (;).
Наиболее важный момент, который следует помнить — операторы и инструкции SQL нечувствительны к регистру. Это означает, что SELECT и select имеют одинаковый смысл в операторах SQL. Однако не забывайте, что регистр имеет значение в названиях таблиц. Поэтому, если вы работаете с MySQL, вам нужно указывать названия таблиц так, как они заданы в базе данных.
Различные синтаксисы в SQL
Все примеры, приведенные в этом руководстве, были протестированы на сервере MySQL.
Инструкция SQL SELECT
|
SELECT столбец1, столбец 2…. столбец N FROM имя_таблицы; |
Условие SQL DISTINCT
|
SELECT DISTINCT столбец1, столбец2….столбецN FROM имя_таблицы; |
Условие SQL WHERE
|
SELECT столбец1, столбец2….столбецN FROM имя_таблицы WHERE УСЛОВИЕ; |
Условие SQL AND/OR
|
SELECT столбец1, столбец2….столбецN FROM имя_таблицы WHERE УСЛОВИЕ-1 {AND|OR} УСЛОВИЕ-2; |
Условие SQL IN
|
SELECT столбец1, столбец2….столбецN FROM имя_таблицы WHERE имя_столбца IN (значение-1, значение-2,...значение-N); |
Условие SQL BETWEEN
|
SELECT столбец1, столбец2….столбецN FROM имя_таблицы WHERE имя_столбца BETWEEN значение-1 AND значение-2; |
Условие SQL LIKE
|
SELECT столбец1, столбец2….столбецN FROM имя_таблицы WHERE имя_столбца LIKE { ШАБЛОН }; |
Условие SQL ORDER BY
|
SELECT столбец1, столбец2….столбецN FROM имя_таблицы WHERE УСЛОВИЕ ORDER BY имя_столбца {ASC|DESC}; |
Условие SQL GROUP BY
|
SELECT SUM(имя_столбца) FROM имя_таблицы WHERE УСЛОВИЕ GROUP BY имя_столбца; |
Условие SQL COUNT
|
SELECT COUNT(имя_столбца) FROM имя_таблицы WHERE УСЛОВИЕ; |
Условие SQL HAVING
|
SELECT SUM(имя_столбца) FROM имя_таблицы WHERE УСЛОВИЕ GROUP BY имя_столбца HAVING (арифметическая функция УСЛОВИЕ); |
Инструкция SQL CREATE TABLE
|
CREATE TABLE имя_таблицы( столбец1 тип данных, столбец2 тип данных, столбец3 тип данных, ..... столбецN тип данных, PRIMARY KEY( один или более столбцов ) ); |
Инструкция SQL DROP TABLE
|
DROP TABLE имя_таблицы; Инструкция SQL CREATE INDEX CREATE UNIQUE INDEX имя_индекса ON имя_таблицы ( столбец1, столбец2,...столбецN); |
Инструкция SQL DROP INDEX
|
ALTER TABLE имя_таблицы DROP INDEX имя_индекса; |
Инструкция SQL DESC
Инструкция SQL TRUNCATE TABLE
|
TRUNCATE TABLE имя_таблицы; |
Инструкция SQL ALTER TABLE
|
ALTER TABLE имя_таблицы {ADD|DROP|MODIFY} имя_столбца {тип_данных}; |
Инструкция SQL ALTER TABLE
|
ALTER TABLE имя_таблицы RENAME TO новое_имя_таблицы; |
Инструкция SQL INSERT INTO
|
INSERT INTO имя_таблицы( столбец1, столбец2….столбецN) ЗНАЧЕНИЕS ( значение1, значение2….значениеN); |
Инструкция SQL UPDATE
|
UPDATE имя_таблицы SET столбец1 = значение1, столбец2 = значение2….столбецN=значениеN [ WHERE УСЛОВИЕ ]; |
Инструкция SQL DELETE
|
DELETE FROM имя_таблицы WHERE {УСЛОВИЕ}; |
Инструкция SQL CREATE DATABASE
|
CREATE DATABASE имя_базы_данных; |
Инструкция SQL DROP DATABASE
|
DROP DATABASE имя_базы_данных; |
Инструкция SQL USE
Инструкция SQL COMMIT
Инструкция SQL ROLLBACK
Источник: //www.tutorialspoint.com/
Редакция: Команда webformyself.
The syntax of the SQL programming language is defined and maintained by ISO/IEC SC 32 as part of ISO/IEC 9075. This standard is not freely available. Despite the existence of the standard, SQL code is not completely portable among different database systems without adjustments.
Language elements[edit]

A chart showing several of the SQL language elements that compose a single statement. This adds one to the population of the USA in the country table.
The SQL language is subdivided into several language elements, including:
- Keywords are words that are defined in the SQL language. They are either reserved (e.g.
SELECT,COUNTandYEAR), or non-reserved (e.g.ASC,DOMAINandKEY). List of SQL reserved words. - Identifiers are names on database objects, like tables, columns and schemas. An identifier may not be equal to a reserved keyword, unless it is a delimited identifier. Delimited identifiers means identifiers enclosed in double quotation marks. They can contain characters normally not supported in SQL identifiers, and they can be identical to a reserved word, e.g. a column named
YEARis specified as"YEAR".- In MySQL, double quotes are string literal delimiters by default instead. Enabling the
ansi_quotesSQL mode enforces the SQL standard behavior. These can also be used regardless of this mode through backticks:`YEAR`.
- In MySQL, double quotes are string literal delimiters by default instead. Enabling the
- Clauses, which are constituent components of statements and queries. (In some cases, these are optional.)[1]
- Expressions, which can produce either scalar values, or tables consisting of columns and rows of data
- Predicates, which specify conditions that can be evaluated to SQL three-valued logic (3VL) (true/false/unknown) or Boolean truth values and are used to limit the effects of statements and queries, or to change program flow.
- Queries, which retrieve the data based on specific criteria. This is an important element of SQL.
- Statements, which may have a persistent effect on schemata and data, or may control transactions, program flow, connections, sessions, or diagnostics.
- SQL statements also include the semicolon («;») statement terminator. Though not required on every platform, it is defined as a standard part of the SQL grammar.
- Insignificant whitespace is generally ignored in SQL statements and queries, making it easier to format SQL code for readability.
Operators[edit]
| Operator | Description | Example |
|---|---|---|
=
|
Equal to | Author = 'Alcott'
|
<>
|
Not equal to (many DBMSs accept != in addition to <>)
|
Dept <> 'Sales'
|
>
|
Greater than | Hire_Date > '2012-01-31'
|
<
|
Less than | Bonus < 50000.00
|
>=
|
Greater than or equal | Dependents >= 2
|
<=
|
Less than or equal | Rate <= 0.05
|
[NOT] BETWEEN [SYMMETRIC]
|
Between an inclusive range. SYMMETRIC inverts the range bounds if the first is higher than the second. | Cost BETWEEN 100.00 AND 500.00
|
[NOT] LIKE [ESCAPE]
|
Begins with a character pattern | Full_Name LIKE 'Will%'
|
| Contains a character pattern | Full_Name LIKE '%Will%'
|
|
[NOT] IN
|
Equal to one of multiple possible values | DeptCode IN (101, 103, 209)
|
IS [NOT] NULL
|
Compare to null (missing data) | Address IS NOT NULL
|
IS [NOT] TRUE or IS [NOT] FALSE
|
Boolean truth value test | PaidVacation IS TRUE
|
IS NOT DISTINCT FROM
|
Is equal to value or both are nulls (missing data) | Debt IS NOT DISTINCT FROM - Receivables
|
AS
|
Used to change a column name when viewing results | SELECT employee AS department1
|
Other operators have at times been suggested or implemented, such as the skyline operator (for finding only those rows that are not ‘worse’ than any others).
SQL has the case expression, which was introduced in SQL-92. In its most general form, which is called a «searched case» in the SQL standard:
CASE WHEN n > 0 THEN 'positive' WHEN n < 0 THEN 'negative' ELSE 'zero' END
SQL tests WHEN conditions in the order they appear in the source. If the source does not specify an ELSE expression, SQL defaults to ELSE NULL. An abbreviated syntax called «simple case» can also be used:
CASE n WHEN 1 THEN 'One' WHEN 2 THEN 'Two' ELSE 'I cannot count that high' END
This syntax uses implicit equality comparisons, with the usual caveats for comparing with NULL.
There are two short forms for special CASE expressions: COALESCE and NULLIF.
The COALESCE expression returns the value of the first non-NULL operand, found by working from left to right, or NULL if all the operands equal NULL.
is equivalent to:
CASE WHEN x1 IS NOT NULL THEN x1 ELSE x2 END
The NULLIF expression has two operands and returns NULL if the operands have the same value, otherwise it has the value of the first operand.
is equivalent to
CASE WHEN x1 = x2 THEN NULL ELSE x1 END
[edit]
Standard SQL allows two formats for comments: -- comment, which is ended by the first newline, and /* comment */, which can span multiple lines.
Queries[edit]
The most common operation in SQL, the query, makes use of the declarative SELECT statement. SELECT retrieves data from one or more tables, or expressions. Standard SELECT statements have no persistent effects on the database. Some non-standard implementations of SELECT can have persistent effects, such as the SELECT INTO syntax provided in some databases.[2]
Queries allow the user to describe desired data, leaving the database management system (DBMS) to carry out planning, optimizing, and performing the physical operations necessary to produce that result as it chooses.
A query includes a list of columns to include in the final result, normally immediately following the SELECT keyword. An asterisk («*«) can be used to specify that the query should return all columns of the queried tables. SELECT is the most complex statement in SQL, with optional keywords and clauses that include:
- The
FROMclause, which indicates the table(s) to retrieve data from. TheFROMclause can include optionalJOINsubclauses to specify the rules for joining tables. - The
WHEREclause includes a comparison predicate, which restricts the rows returned by the query. TheWHEREclause eliminates all rows from the result set where the comparison predicate does not evaluate to True. - The
GROUP BYclause projects rows having common values into a smaller set of rows.[clarification needed]GROUP BYis often used in conjunction with SQL aggregation functions or to eliminate duplicate rows from a result set. TheWHEREclause is applied before theGROUP BYclause. - The
HAVINGclause includes a predicate used to filter rows resulting from theGROUP BYclause. Because it acts on the results of theGROUP BYclause, aggregation functions can be used in theHAVINGclause predicate. - The
ORDER BYclause identifies which column[s] to use to sort the resulting data, and in which direction to sort them (ascending or descending). Without anORDER BYclause, the order of rows returned by an SQL query is undefined. - The
DISTINCTkeyword[3] eliminates duplicate data.[4] - The
OFFSETclause specifies the number of rows to skip before starting to return data. - The
FETCH FIRSTclause specifies the number of rows to return. Some SQL databases instead have non-standard alternatives, e.g.LIMIT,TOPorROWNUM.
The clauses of a query have a particular order of execution,[5] which is denoted by the number on the right hand side. It is as follows:
SELECT <columns> |
5. |
FROM <table> |
1. |
WHERE <predicate on rows> |
2. |
GROUP BY <columns> |
3. |
HAVING <predicate on groups> |
4. |
ORDER BY <columns> |
6. |
OFFSET |
7. |
FETCH FIRST |
8. |
The following example of a SELECT query returns a list of expensive books. The query retrieves all rows from the Book table in which the price column contains a value greater than 100.00. The result is sorted in ascending order by title. The asterisk (*) in the select list indicates that all columns of the Book table should be included in the result set.
SELECT * FROM Book WHERE price > 100.00 ORDER BY title;
The example below demonstrates a query of multiple tables, grouping, and aggregation, by returning a list of books and the number of authors associated with each book.
SELECT Book.title AS Title, count(*) AS Authors FROM Book JOIN Book_author ON Book.isbn = Book_author.isbn GROUP BY Book.title;
Example output might resemble the following:
Title Authors ---------------------- ------- SQL Examples and Guide 4 The Joy of SQL 1 An Introduction to SQL 2 Pitfalls of SQL 1
Under the precondition that isbn is the only common column name of the two tables and that a column named title only exists in the Book table, one could re-write the query above in the following form:
SELECT title, count(*) AS Authors FROM Book NATURAL JOIN Book_author GROUP BY title;
However, many[quantify] vendors either do not support this approach, or require certain column-naming conventions for natural joins to work effectively.
SQL includes operators and functions for calculating values on stored values. SQL allows the use of expressions in the select list to project data, as in the following example, which returns a list of books that cost more than 100.00 with an additional sales_tax column containing a sales tax figure calculated at 6% of the price.
SELECT isbn, title, price, price * 0.06 AS sales_tax FROM Book WHERE price > 100.00 ORDER BY title;
Subqueries[edit]
Queries can be nested so that the results of one query can be used in another query via a relational operator or aggregation function. A nested query is also known as a subquery. While joins and other table operations provide computationally superior (i.e. faster) alternatives in many cases, the use of subqueries introduces a hierarchy in execution that can be useful or necessary. In the following example, the aggregation function AVG receives as input the result of a subquery:
SELECT isbn, title, price FROM Book WHERE price < (SELECT AVG(price) FROM Book) ORDER BY title;
A subquery can use values from the outer query, in which case it is known as a correlated subquery.
Since 1999 the SQL standard allows WITH clauses for subqueries, i.e. named subqueries, usually called common table expressions (also called subquery factoring). CTEs can also be recursive by referring to themselves; the resulting mechanism allows tree or graph traversals (when represented as relations), and more generally fixpoint computations.
Derived table[edit]
A derived table is the use of referencing an SQL subquery in a FROM clause. Essentially, the derived table is a subquery that can be selected from or joined to. The derived table functionality allows the user to reference the subquery as a table. The inline view is also referred to as an inline view or a subselect.
In the following example, the SQL statement involves a join from the initial «Book» table to the derived table «sales». This derived table captures associated book sales information using the ISBN to join to the «Book» table. As a result, the derived table provides the result set with additional columns (the number of items sold and the company that sold the books):
SELECT b.isbn, b.title, b.price, sales.items_sold, sales.company_nm FROM Book b JOIN (SELECT SUM(Items_Sold) Items_Sold, Company_Nm, ISBN FROM Book_Sales GROUP BY Company_Nm, ISBN) sales ON sales.isbn = b.isbn
Null or three-valued logic (3VL)[edit]
The concept of Null allows SQL to deal with missing information in the relational model. The word NULL is a reserved keyword in SQL, used to identify the Null special marker. Comparisons with Null, for instance equality (=) in WHERE clauses, results in an Unknown truth value. In SELECT statements SQL returns only results for which the WHERE clause returns a value of True; i.e., it excludes results with values of False and also excludes those whose value is Unknown.
Along with True and False, the Unknown resulting from direct comparisons with Null thus brings a fragment of three-valued logic to SQL. The truth tables SQL uses for AND, OR, and NOT correspond to a common fragment of the Kleene and Lukasiewicz three-valued logic (which differ in their definition of implication, however SQL defines no such operation).[6]
|
|
|
|
There are however disputes about the semantic interpretation of Nulls in SQL because of its treatment outside direct comparisons. As seen in the table above, direct equality comparisons between two NULLs in SQL (e.g. NULL = NULL) return a truth value of Unknown. This is in line with the interpretation that Null does not have a value (and is not a member of any data domain) but is rather a placeholder or «mark» for missing information. However, the principle that two Nulls aren’t equal to each other is effectively violated in the SQL specification for the UNION and INTERSECT operators, which do identify nulls with each other.[7] Consequently, these set operations in SQL may produce results not representing sure information, unlike operations involving explicit comparisons with NULL (e.g. those in a WHERE clause discussed above). In Codd’s 1979 proposal (which was basically adopted by SQL92) this semantic inconsistency is rationalized by arguing that removal of duplicates in set operations happens «at a lower level of detail than equality testing in the evaluation of retrieval operations».[6] However, computer-science professor Ron van der Meyden concluded that «The inconsistencies in the SQL standard mean that it is not possible to ascribe any intuitive logical semantics to the treatment of nulls in SQL.»[7]
Additionally, because SQL operators return Unknown when comparing anything with Null directly, SQL provides two Null-specific comparison predicates: IS NULL and IS NOT NULL test whether data is or is not Null.[8] SQL does not explicitly support universal quantification, and must work it out as a negated existential quantification.[9][10][11] There is also the <row value expression> IS DISTINCT FROM <row value expression> infixed comparison operator, which returns TRUE unless both operands are equal or both are NULL. Likewise, IS NOT DISTINCT FROM is defined as NOT (<row value expression> IS DISTINCT FROM <row value expression>). SQL:1999 also introduced BOOLEAN type variables, which according to the standard can also hold Unknown values if it is nullable. In practice, a number of systems (e.g. PostgreSQL) implement the BOOLEAN Unknown as a BOOLEAN NULL, which the standard says that the NULL BOOLEAN and UNKNOWN «may be used interchangeably to mean exactly the same thing».[12][13]
Data manipulation[edit]
The Data Manipulation Language (DML) is the subset of SQL used to add, update and delete data:
INSERTadds rows (formally tuples) to an existing table, e.g.:
INSERT INTO example (column1, column2, column3) VALUES ('test', 'N', NULL);
UPDATEmodifies a set of existing table rows, e.g.:
UPDATE example SET column1 = 'updated value' WHERE column2 = 'N';
DELETEremoves existing rows from a table, e.g.:
DELETE FROM example WHERE column2 = 'N';
MERGEis used to combine the data of multiple tables. It combines theINSERTandUPDATEelements. It is defined in the SQL:2003 standard; prior to that, some databases provided similar functionality via different syntax, sometimes called «upsert».
MERGE INTO table_name USING table_reference ON (condition) WHEN MATCHED THEN UPDATE SET column1 = value1 [, column2 = value2 ...] WHEN NOT MATCHED THEN INSERT (column1 [, column2 ...]) VALUES (value1 [, value2 ...])
Transaction controls[edit]
Transactions, if available, wrap DML operations:
START TRANSACTION(orBEGIN WORK, orBEGIN TRANSACTION, depending on SQL dialect) marks the start of a database transaction, which either completes entirely or not at all.SAVE TRANSACTION(orSAVEPOINT) saves the state of the database at the current point in transaction
CREATE TABLE tbl_1(id int); INSERT INTO tbl_1(id) VALUES(1); INSERT INTO tbl_1(id) VALUES(2); COMMIT; UPDATE tbl_1 SET id=200 WHERE id=1; SAVEPOINT id_1upd; UPDATE tbl_1 SET id=1000 WHERE id=2; ROLLBACK to id_1upd; SELECT id from tbl_1;
COMMITmakes all data changes in a transaction permanent.ROLLBACKdiscards all data changes since the lastCOMMITorROLLBACK, leaving the data as it was prior to those changes. Once theCOMMITstatement completes, the transaction’s changes cannot be rolled back.
COMMIT and ROLLBACK terminate the current transaction and release data locks. In the absence of a START TRANSACTION or similar statement, the semantics of SQL are implementation-dependent.
The following example shows a classic transfer of funds transaction, where money is removed from one account and added to another. If either the removal or the addition fails, the entire transaction is rolled back.
START TRANSACTION; UPDATE Account SET amount=amount-200 WHERE account_number=1234; UPDATE Account SET amount=amount+200 WHERE account_number=2345; IF ERRORS=0 COMMIT; IF ERRORS<>0 ROLLBACK;
Data definition[edit]
The Data Definition Language (DDL) manages table and index structure. The most basic items of DDL are the CREATE, ALTER, RENAME, DROP and TRUNCATE statements:
CREATEcreates an object (a table, for example) in the database, e.g.:
CREATE TABLE example( column1 INTEGER, column2 VARCHAR(50), column3 DATE NOT NULL, PRIMARY KEY (column1, column2) );
ALTERmodifies the structure of an existing object in various ways, for example, adding a column to an existing table or a constraint, e.g.:
ALTER TABLE example ADD column4 INTEGER DEFAULT 25 NOT NULL;
TRUNCATEdeletes all data from a table in a very fast way, deleting the data inside the table and not the table itself. It usually implies a subsequent COMMIT operation, i.e., it cannot be rolled back (data is not written to the logs for rollback later, unlike DELETE).
DROPdeletes an object in the database, usually irretrievably, i.e., it cannot be rolled back, e.g.:
Data types[edit]
Each column in an SQL table declares the type(s) that column may contain. ANSI SQL includes the following data types.[14]
- Character strings and national character strings
CHARACTER(n)(orCHAR(n)): fixed-width n-character string, padded with spaces as neededCHARACTER VARYING(n)(orVARCHAR(n)): variable-width string with a maximum size of n charactersCHARACTER LARGE OBJECT(n [ K | M | G | T ])(orCLOB(n [ K | M | G | T ])): character large object with a maximum size of n [ K | M | G | T ] charactersNATIONAL CHARACTER(n)(orNCHAR(n)): fixed width string supporting an international character setNATIONAL CHARACTER VARYING(n)(orNVARCHAR(n)): variable-widthNCHARstringNATIONAL CHARACTER LARGE OBJECT(n [ K | M | G | T ])(orNCLOB(n [ K | M | G | T ])): national character large object with a maximum size of n [ K | M | G | T ] characters
For the CHARACTER LARGE OBJECT and NATIONAL CHARACTER LARGE OBJECT data types, the multipliers K (1 024), M (1 048 576), G (1 073 741 824) and T (1 099 511 627 776) can be optionally used when specifying the length.
- Binary
BINARY(n): Fixed length binary string, maximum length n.BINARY VARYING(n)(orVARBINARY(n)): Variable length binary string, maximum length n.BINARY LARGE OBJECT(n [ K | M | G | T ])(orBLOB(n [ K | M | G | T ])): binary large object with a maximum length n [ K | M | G | T ].
For the BINARY LARGE OBJECT data type, the multipliers K (1 024), M (1 048 576), G (1 073 741 824) and T (1 099 511 627 776) can be optionally used when specifying the length.
- Boolean
BOOLEAN
The BOOLEAN data type can store the values TRUE and FALSE.
- Numerical
INTEGER(orINT),SMALLINTandBIGINTFLOAT,REALandDOUBLE PRECISIONNUMERIC(precision, scale)orDECIMAL(precision, scale)DECFLOAT(precision)
For example, the number 123.45 has a precision of 5 and a scale of 2. The precision is a positive integer that determines the number of significant digits in a particular radix (binary or decimal). The scale is a non-negative integer. A scale of 0 indicates that the number is an integer. For a decimal number with scale S, the exact numeric value is the integer value of the significant digits divided by 10S.
SQL provides the functions CEILING and FLOOR to round numerical values. (Popular vendor specific functions are TRUNC (Informix, DB2, PostgreSQL, Oracle and MySQL) and ROUND (Informix, SQLite, Sybase, Oracle, PostgreSQL, Microsoft SQL Server and Mimer SQL.))
- Temporal (datetime)
DATE: for date values (e.g.2011-05-03).TIME: for time values (e.g.15:51:36).TIME WITH TIME ZONE: the same asTIME, but including details about the time zone in question.TIMESTAMP: This is aDATEand aTIMEput together in one variable (e.g.2011-05-03 15:51:36.123456).TIMESTAMP WITH TIME ZONE: the same asTIMESTAMP, but including details about the time zone in question.
The SQL function EXTRACT can be used for extracting a single field (seconds, for instance) of a datetime or interval value. The current system date / time of the database server can be called by using functions like CURRENT_DATE, CURRENT_TIMESTAMP, LOCALTIME, or LOCALTIMESTAMP. (Popular vendor specific functions are TO_DATE, TO_TIME, TO_TIMESTAMP, YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, DAYOFYEAR, DAYOFMONTH and DAYOFWEEK.)
- Interval (datetime)
YEAR(precision): a number of yearsYEAR(precision) TO MONTH: a number of years and monthsMONTH(precision): a number of monthsDAY(precision): a number of daysDAY(precision) TO HOUR: a number of days and hoursDAY(precision) TO MINUTE: a number of days, hours and minutesDAY(precision) TO SECOND(scale): a number of days, hours, minutes and secondsHOUR(precision): a number of hoursHOUR(precision) TO MINUTE: a number of hours and minutesHOUR(precision) TO SECOND(scale): a number of hours, minutes and secondsMINUTE(precision): a number of minutesMINUTE(precision) TO SECOND(scale): a number of minutes and seconds
Data control[edit]
The Data Control Language (DCL) authorizes users to access and manipulate data.
Its two main statements are:
GRANTauthorizes one or more users to perform an operation or a set of operations on an object.REVOKEeliminates a grant, which may be the default grant.
Example:
GRANT SELECT, UPDATE ON example TO some_user, another_user; REVOKE SELECT, UPDATE ON example FROM some_user, another_user;
Notes[edit]
- ^ ANSI/ISO/IEC International Standard (IS). Database Language SQL—Part 2: Foundation (SQL/Foundation). 1999.
- ^ «Transact-SQL Reference». SQL Server Language Reference. SQL Server 2005 Books Online. Microsoft. 2007-09-15. Retrieved 2007-06-17.
- ^
SAS 9.4 SQL Procedure User’s Guide. SAS Institute. 2013. p. 248. ISBN 9781612905686. Retrieved 2015-10-21.Although the UNIQUE argument is identical to DISTINCT, it is not an ANSI standard.
- ^
Leon, Alexis; Leon, Mathews (1999). «Eliminating duplicates — SELECT using DISTINCT». SQL: A Complete Reference. New Delhi: Tata McGraw-Hill Education (published 2008). p. 143. ISBN 9780074637081. Retrieved 2015-10-21.[…] the keyword DISTINCT […] eliminates the duplicates from the result set.
- ^ «What Is The Order Of Execution Of An SQL Query? — Designcise.com». www.designcise.com. 29 June 2015. Retrieved 2018-02-04.
- ^ a b Hans-Joachim, K. (2003). «Null Values in Relational Databases and Sure Information Answers». Semantics in Databases. Second International Workshop Dagstuhl Castle, Germany, January 7–12, 2001. Revised Papers. Lecture Notes in Computer Science. Vol. 2582. pp. 119–138. doi:10.1007/3-540-36596-6_7. ISBN 978-3-540-00957-3.
- ^ a b Ron van der Meyden, «Logical approaches to incomplete information: a survey» in Chomicki, Jan; Saake, Gunter (Eds.) Logics for Databases and Information Systems, Kluwer Academic Publishers ISBN 978-0-7923-8129-7, p. 344
- ^ ISO/IEC. ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC.
- ^ Negri, M.; Pelagatti, G.; Sbattella, L. (February 1989). «Semantics and problems of universal quantification in SQL». The Computer Journal. 32 (1): 90–91. doi:10.1093/comjnl/32.1.90. Retrieved 2017-01-16.
- ^ Fratarcangeli, Claudio (1991). «Technique for universal quantification in SQL». ACM SIGMOD Record. 20 (3): 16–24. doi:10.1145/126482.126484. S2CID 18326990. Retrieved 2017-01-16.
- ^ Kawash, Jalal (2004) Complex quantification in Structured Query Language (SQL): a tutorial using relational calculus; Journal of Computers in Mathematics and Science Teaching ISSN 0731-9258 Volume 23, Issue 2, 2004 AACE Norfolk, Virginia. Thefreelibrary.com
- ^ C. Date (2011). SQL and Relational Theory: How to Write Accurate SQL Code. O’Reilly Media, Inc. p. 83. ISBN 978-1-4493-1640-2.
- ^ ISO/IEC 9075-2:2011 §4.5
- ^ «ISO/IEC 9075-1:2016: Information technology – Database languages – SQL – Part 1: Framework (SQL/Framework)».
SQL
(Structured
Query
Language)
– структурированный язык запросов –
является инструментом, предназначенным
для выборки и обработки информации,
содержащейся в компьютерной базе данных.
SQL
является языком программирования,
применяемым для организации взаимодействия
пользователя с базой данных (рис.
44).
SQL
работает только с реляционными базами
данных и предоставляет пользователю
следующие функциональные возможности:
-
изменение
структуры представления данных; -
выборка
данных из базы данных; -
обработка
базы данных, т. е. добавление новых
данных, изменение, удаление имеющихся
данных; -
управление
доступом к базе данных; -
совместное
использование базы данных пользователями,
работающими параллельно; -
обеспечение
целостности базы данных.
SQL
– это не полноценный компьютерный язык
типа PASCAL,
C++,
JAVA.
Еще раз отметим, что SQL,
также как и QBE,
является непроцедурным языком. С помощью
SQL
описываются свойства и взаимосвязи
сущностей (объектов, переменных и т. п.
), но не алгоритмы решения задачи. Он не
содержит условных операторов, операторов
цикла, организации подпрограмм,
ввода-вывода и т. п. В связи с этим SQL
автономно не используется. Инструкции
SQL
встраиваются в программу, написанную
на традиционном языке программирования
и дают возможность получить доступ к
базам данных (встроенный
SQL).
Кроме того, из таких языков, С, C++,
JAVA
инструкции SQL
можно посылать СУБД в явном виде,
используя интерфейс вызовов функций. 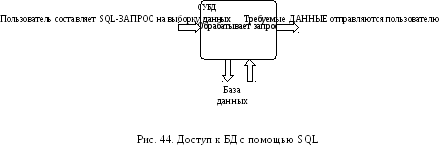
Язык
SQL
является многофункциональным языком.
Во-первых, SQL
используется в качестве языка интерактивных
запросов пользователей с целью выборки
данных и в качестве встроенного языка
программирования баз данных. Кроме
того, SQL
используется в качестве языка
администрирования БД для определения
структуры базы данных и управления
доступом к данным, находящимся на
сервере; в качестве языка создания
приложений клиент/сервер, доступа к
данным в среде Internet,
распределенных баз данных.
С
помощью SQL
можно динамически
изменять и расширять структуру базы
данных даже в то время, когда пользователи
работают с ее содержимым. Таким образом,
SQL
обеспечивает максимальную гибкость.
Статические
языки определения данных запрещают
доступ к БД во время изменения ее
структуры
Официальный
стандарт языка SQL
был опубликован ANSI
и ISO
в 1986 г. В дальнейшем,
он был расширен стандартами SQL-89 (1989 г.)
и SQL-92 (1992 г.). Действующая версия стандарта
SQL:1999 была принята ANSI и ISO в конце 1999 г. В
настоящее время ведется работа над
стандартом для SQL3, содержащим
объектно-ориентированные расширения.
Кроме
перечисленных выше версий языка SQL для
универсальных ЭВМ
существует множество версий типа
«клиент-сервер», а также версий SQL
для персональных компьютеров.
Основные инструкции языка sql
Основные
задачи, решаемые средствами языка SQL
– манипулирование различными объектами
базы данных (таблицами, индексами,
представлениями и т. д.) и манипулирование
данными, хранящимися в таблицах базы
данных. В связи с этим, язык SQL
принято делить на две части: язык
определения данных DDL
и язык манипулирования данными DML.
Основные инструкции языка SQL
представлены в табл.
10.
При
описании синтаксиса инструкций будем
использовать следующие правила:
-
каждая
инструкция начинается с команды
–
ключевого
слова, описывающего действие, выполняемое
инструкцией (например, CREATE
– создать, DELETE
– удалить и т. д.); -
после
команды следует одно или несколько
предложений,
описывающих данные, с которыми работает
инструкция, или содержащих дополнительную
информацию о действии, выполняемом
инструкцией. Каждое предложение
начинается с ключевого слова, например,
WHERE
(где), FROM
(откуда), INTO
(куда), HAVING
(имеющий); -
в
квадратные скобки «[…]»
заключены необязательные элементы; -
вертикальная
черта «|» , разделяющая два элемента,
указывает на то, что в инструкции
используется либо один элемент, либо
второй; -
в
фигурные скобки «{…}»заключаются
элементы, разделенные вертикальной
чертой; -
троеточие
означает, что далее в инструкции либо
следует выражение, либо повторяются
элементы, указанные перед тремя
точками.
Таблица
10
Инструкции
языка SQL
|
Вид |
Название |
Назначение |
|
DDL |
CREATE |
Добавление |
|
DROP |
Удаление |
|
|
ALTER |
Изменение |
|
|
CREATE |
Создание |
|
|
DROP |
Удаление |
|
|
CREATE |
Создание |
|
|
DROP |
Удаление |
|
|
GRAND |
Назначение |
|
|
REVOKE |
Удаление |
|
|
CREATE |
Добавление |
|
|
DROP |
Удаление |
|
|
DML |
SELECT |
Выборка |
|
UPDATE |
Обновление |
|
|
INSERT |
Вставка |
|
|
DELETE |
Удаление |
Рассмотрим
основные инструкции языка SQL.
Инструкция
создания
таблицы
имеет формат вида:
CREATE
TABLE
<имя таблицы>
(<имя
столбца> <тип данных> [NOT
NULL]
[,<имя
столбца> <тип данных> [NOT
NULL]]…
)
После
выполнения инструкции появляется новая
таблица, которой присваивается имя,
указанное в инструкции. Имя таблицы
(как и имена других объектов – столбцов
и пользователей) согласно стандарту
ANSI/ISO
должны содержать от 1 до 18 символов,
начинаться с буквы и не содержать
пробелов или специальных символов
пунктуации (на практике поддержка имен
в различных СУБД реализована по-разному).
Обязательными
операндами данной инструкции являются
имя создаваемой таблицы и имя хотя бы
одного столбца с указанием типа данных,
хранимых в этом столбце. SQL
поддерживает различные типы данных:
целые числа, числа с плавающей запятой,
строки символов, значения даты и времени
и др. В общем случае в современных СУБД
могут использоваться самые разнообразные
дополнительные типы данных, расширяющие
базовый набор SQL.
При
создании таблицы для отдельных столбцов
могут указываться некоторые дополнительные
правила контроля вводимых в них значений.
Конструкция – NOT
NULL
(не пустое) служит именно таким целям и
для столбца таблицы означает, что в этом
столбце должно быть непустое (определенное)
значение.
Пример
3.28. Создание
таблицы
Пусть
требуется определить таблицу ORDERS
и ее столбцы. Инструкция для определения
таблицы может иметь следующий вид:
CREATE
TABLE ORDERS
(ORDER_NUM
INTEGER NOT NULL, CUST_NUM INTEGER NOT NULL, PROD_ID INTEGER NOT
NULL, QTY INTEGER NOT NULL, DATE_ORDER DATE NOT NULL)
где
INTEGER
обозначает тип данных целое число, а
DATE – тип данных, обозначающих значения
даты.
В
процессе работы у пользователей возникает
необходимость добавить в таблицу
информацию. Инструкция
изменения
структуры таблицы
имеет формат вида:
ALTER
TABLE
<имя таблицы>
{ADD|ALTER|DROP}
<имя столбца> [<тип данных>]
[NOT
NULL]
[,{ADD|ALTER|DROP}
<имя столбца> [<тип данных>]
[NOT
NULL],..]
Изменение
структуры таблицы может состоять в
добавлении (ADD),
изменении (ALTER)
или удалении (DROP)
одного или нескольких столбцов таблицы.
Пример
3.29. Добавление
столбца таблицы
Добавим
в созданную ранее таблицу CUST
столбец CUST_PHN,
содержащий телефоны клиентов. Для этого
следует записать инструкцию вида:
ALTER
TABLE
CUST
ADD
CUST_PHN
CHAR
(10)
Пример
3.30. Удаление
столбца
Удалим
из таблицы PROD
столбец STORE.
(Примеры рассматриваются без учета
ограничений целостности).
ALTER
TABLE
PROD
DROP
STORE
Инструкция
удаления
таблицы имеет формат вида:
DROP
TABLE
<имя та6лицы>
Например,
для удаления таблицы с именем SALE
достаточно записать оператор вида:
DROP
TABLE
SALE
Одним
из структурных элементов физической
памяти является индекс.
Индекс – это средство, обеспечивающее
быстрый доступ к строкам таблицы на
основе значений одного или нескольких
столбцов. В индексе хранятся значения
данных и указатели на строки, где эти
данные встречаются. Данные в индексе
располагаются в убывающем или в
возрастающем порядке, чтобы СУБД могла
быстро найти требуемое значение. Затем
по указателю СУБД сможет быстро определить
строку, содержащую требуемое значение.
Инструкция
создания
индекса
имеет формат вида:
CREATE
[UNIQUE]
INDEX
<имя индекса> ОN <имя таблицы> (<имя
столбца> [ ASC|
DESC]
[,<имя
столбца> [ASC|
DESC],…
)
Оператор
позволяет создать индекс для одного
или нескольких столбцов заданной таблицы
с целью ускорения выполнение запросных
и поисковых операций с таблицей. Для
одной таблицы можно создать несколько
индексов.
Необязательная
опция UNIQUE
обеспечивает запрет задания совпадающих
значений для индекса. По существу,
создание индекса с указанием признака
UNIQUE
означает определение ключа в созданной
ранее таблице.
При
создании индекса можно задать порядок
автоматической сортировки значений в
столбцах – в порядке возрастания ASC
(по умолчанию), или в порядке убывания
DESC.
Для разных столбцов можно задавать
различный порядок сортировки.
Пример
3.31. Создание
индекса
Пусть
из таблице CUST
часто извлекаются данные по названию
фирм-клиентов. Можно создать индекс
main_index
для сортировки названий фирм-клиентов
в алфавитном порядке по возрастанию.
Оператор
создания
индекса
может
иметь
вид:
CREATE
INDEX main_index ON CUST
(CUST_NAME)
Инструкция
удаления
индекса
имеет формат вида:
DROP
INDEX<имя
индекса>
Эта
инструкция позволяет удалять созданный
ранее индекс с соответствующим именем.
Так, например, для уничтожения индекса
main_index
к таблице CUST
достаточно записать инструкцию DROP
INDEX
main_index.
Кроме
таблиц и индексов существуют другие
объекты базы данных, например,
представления. Представление является
«виртуальной» таблицей, содержащей
набор столбцов одной или нескольких
таблиц. Однако, в отличие от таблицы,
представление как совокупность значений
в базе данных реально не существует.
Представление определяется как запрос
на выборку данных, которому присвоили
имя и сохранили в базе данных. Представление
позволяет пользователю увидеть результаты
сохраненного запроса.
Инструкция
создания
представления
имеет формат вида:
CREATE
VIEW<имя
представления>
[(<имя
столбца> [,<имя столбца> ]…)]
AS
<оператор SELECT>
При
необходимости можно задать имя для
каждого столбца создаваемого представления.
Список имен столбцов должен содержать
столько элементов, сколько столбцов
содержится в запросе. Если список имен
в инструкции отсутствует, то каждый
столбец представления получает имя
соответствующего столбца запроса.
Пример
3.32. Создание
представления
Необходимо
создать представление c
именем CUSTINF
таблицы
CUST,
включающее только названия клиентов и
их номера.
CREATE
VIEW CUSTINF
AS
SELECT CUST_NUM, CUST_NAME
FROM
CUST
Создать
представление ORDER_CUS,
показывающее заказы сделанные клиентом
3105.
CREATE
VIEW ORDER_CUS
AS
SELECT
FROM
ORDERS
WHERE
CUST_NUM=3105
Инструкция
удаления
представления
имеет формат
вида:
DROP
VIEW
<имя представления>
Оператор
позволяет удалить созданное ранее
представление. Заметим, что при этом
таблицы, участвующие в запросе, удалению
не подлежат. Удаление представления
ORDER_CUS
производится инструкцией вида:
DROP
VIEW
ORDER_CUS
Представления
широко применяются для ограничения
доступа пользователей ко всей информации
в таблицах базы данных.
Пример
3.33. Использование
инструкции GRAND
и REVOKE
Можно
определить права доступа к таблицам
базы данных с помощью инструкций GRAND
и REVOKE.
Например, инструкция
GRAND
INSERT
ON
CUST
TO
PETROV
разрешает
сотруднику Петрову ввод данных в таблицу
CUST.
Следующая
инструкция отменяет привилегии сотрудника
Иванова на изменение данных о клиентах
и чтение информации о них
REVOKE
UPDATE, SELECT
ON
CUST
TO
IVANOV
Запросы
являются фундаментом SQL.
Многие разработчики используют SQL
исключительно в качестве инструмента
для создания запросов. Поэтому важнейшей
инструкцией является инструкция
SELECT,
которая используется для построения
SQL-запросов:
SELECT
[ALL | DISTINCT]<список
данных>
FROM
<список таблиц>
[WHERE
<условие отбора>]
[GROUP
BY
<имя столбца> [,<имя столбца>]… ]
[HAVING
<условие поиска>]
[ORDER
BY
<спецификация> [,<спецификация>]…]
Оператор
SELECT
позволяет производить выборку и
вычисления над данными из одной или
нескольких таблиц. В предложении
SELECT
указывается список возвращаемых
столбцов, разделенных запятыми. Для
каждого элемента из списка в ответной
таблице будет создан один столбец.
Ответная таблица может иметь (ALL),
или не иметь (DISTINCT)
повторяющиеся строки. По умолчанию в
ответную таблицу включаются все строки,
в том числе и повторяющиеся. Список
данных может содержать выражения над
столбцами, показывающие, что наряду с
выборкой данных выполняются вычисления,
результаты которого попадают в новый
(создаваемый) столбец ответной таблицы
В
отборе данных участвуют записи одной
или нескольких таблиц, перечисленных
в списке предложения FROM.
Такие таблицы называют исходными
таблицами запроса.
При
использовании в списках данных имен
столбцов нескольких таблиц для указания
принадлежности столбца некоторой
таблице применяют конструкцию вида:
<имя таблицы>.<имя столбца>.
Предложение
WHERE
задает условия, которым должны
удовлетворять строки в результирующей
таблице. Вслед за ключевым словом WHERE
указывается логическое выражение
<условие
отбора>.
Его элементами могут быть имена столбцов,
операции сравнения, арифметические
операции, логические операции (И, ИЛИ,
НЕТ), скобки, специальные функции LIKE
и т.д.
Предложение
GROUP
BY
содержит список столбцов, которые
используются для группировки строк.
Группой
называются строки с совпадающими
значениями в столбцах, перечисленных
за ключевыми словами GROUP
BY.
Для сгруппированных данных можно
использовать статистические функции:
AVG
(среднее значение в группе), МАХ
(максимальное значение в группе), MIN
(минимальное значение в группе), SUM
(сумма
значений в группе), COUNT
(число значений в группе).
Вслед
за предложением HAVING
указывается логическое выражение
<условия поиска>, определяющее, какие
из отобранных и сгруппированных строк
будут отображаться в результирующем
наборе данных. Правила записи аналогичны
правилам формирования <условия отбора>
предложения WHERE.
Предложение
ORDER
BY
задает порядок сортировки результирующего
множества строк. Обычно каждая
<спецификация> аналогична соответствующей
конструкции оператора CREATE
INDEX
и представляет собой конструкцию вида:
<имя столбца> [ ASC
| DESC].
Пример
3.34. Выбор
строк
Пусть
требуется вывести названия товаров и
их цену. Инструкцию выбора можно записать
следующим образом:
SELECT
PROD_NAME, PRICE
FROM
PROD
Пример
3.35. Выбор с
условием
Вывести
названия товаров, цена которых больше
100$. Инструкцию SELECT
для этого запроса можно
записать
так:
SELECT
PROD_NAME
FROM
PROD
WHERE
PRICE>100
Пример
3. 36. Выбор с
сортировкой
Строки
результатов запроса, как и строки таблицы
базы данных, не имеют определенного
порядка. Включив в инструкцию SELECT
предложение ORDER BY, можно отсортировать
результаты запроса.
Пусть
требуется вывести название клиентов и
годовой объем заказов. Последний столбец
отсортировать по возрастанию. По
умолчанию данные сортируются по
возрастанию.
SELECT
CUST_NAME, CUST_SUM
FROM
CUST
ORDER
BY CUST_SUM
Пример
3.37. Получение
итоговых данных
Каков
средний объем заказов?
Этот
запрос обеспечивает вычисление среднего
объема заказов, используя данные из
таблицы CUST
SELECT
AVG (CUST_SUM)
FROM
CUST
Пример
3.38. Вычисляемые
столбцы
Например,
требуется вычислить стоимость остатков
товара, хранящихся на складе. Данные
вывести по каждому товару. Значения
вычисляемых столбцов определяются на
основе выражения, указанного в списке
возвращаемых столбцов.
SELECT
PROD_NAME, PRICE, STORE, (PRICE* STORE)
FROM
PROD
Пусть
требуется увеличить цену каждого товара
на 5%. Запрос можно сформулировать
следующим образом:
SELECT
PROD_NAME, PRICE, (PRICE*1.05)
FROM
PROD
Во
многих СУБД реализованы дополнительные
арифметические операции, операции над
строками, встроенные функции для работы
со значениями даты и времени.
Например,
требуется вывести номер заказа, месяц
и год его поставки. Запрос
выглядит
следующим
образом:
SELECT
ORDER_NUM, MONTH (DATE_ORDER), YEAR (DATE_ORDER)
FROM
ORDERS
Пример
3.39. Выбор
всех столбцов
Иногда
требуется получить содержимое всех
столбцов таблицы. С учетом этого в SQL
разрешается использовать вместо списка
возвращаемых столбцов символ «*».
SELECT
*
FROM
ORDERS
Пример
3.40. Повторяющиеся
строки
Результаты
запроса могут содержать повторяющиеся
строки. Например, требуется вывести
номера клиентов, сделавших заказы, из
таблицы ORDERS.
Клиенты 3101, 3105, 3103 сделали более, чем по
одному заказу, поэтому строки с их
номерами будут повторяться. Для исключения
повторяющихся строк используется
предикат DISTINCT.
SELECT
DISTINCT
CUST_NUM
FROM
ORDERS
Пример
3.41. Выбор с
группированием
Пусть
требуется найти минимальное и максимальное
заказанное количество для каждого из
видов товаров. Оператор SELECT
для этого запроса имеет вид:
SELECT
PROD_ID,
MIN
(QTY
), MAX
(QTY
)
FROM
ORDERS
GROUP
BY PROD_ID
Запрос
выполняется следующим образом: заказы
делятся на группы, по одной группе на
каждый товар. Затем для каждой группы
вычисляется максимальное и минимальное
значения столбца QTY
по всем строкам, входящим в группу, и
генерируется одна итоговая строка
результатов.
Пример
3.42. Условия
отбора групп
Предложение
HAVING
можно использовать для отбора групп
строк, участвующих в запросе. Пусть
требуется найти максимальное заказанное
количество каждого товара. Общее
количество заказанного товара не должно
превышать 20.
SELECT
PROD_ID, MAX (QTY )
FROM
ORDERS
GROUP
BY PROD_ID
HAVING
SUM
(QTY
)<=20
При
реализации данного запроса, вначале
заказы разделяются на группы по видам
товаров. Затем исключаются те группы,
в которых общее количество заказанного
товара превышает 20. И после этого в
оставшихся группах определяется
максимальное заказанное количество
каждого товара.
Пример
3.43.
Многотабличные запросы
На
практике, многие запросы считывают
информацию сразу из нескольких таблиц
базы данных. Например, необходимо вывести
список всех заказов, а также название
клиента, сделавшего заказ. Инструкция
SELECT
должна содержать условие отбора, которое
определяет связь между столбцами таблиц
ORDERS
и CUST.
SELECT
ORDER_NUM, CUST_NAME, PROD_ID, QTY, DATE_ORDER
FROM
ORDERS, CUST
WHERE
CUST.CUST_NUM=ORDERS.CUST_NUM
Приведенный
запрос отличается от предыдущих,
во-первых, тем, что предложение FROM
содержит не
одну, а две таблицы. Во-вторых, в условии
отбора WHERE
CUST.CUST_NUM=ORDERS.CUST_NUM
сравниваются столбцы из двух различных
таблиц. Эти столбцы называются связанными.
В
данном примере, столбцы, используемые
из разных таблиц, имеют одинаковые
имена. В этом случае необходимо указывать
полные имена столбцов, которые однозначно
определяют их местонахождение.
Инструкция
на изменения
строк имеет
формат вида:
UPDATE
<имя таблицы>
SET
<имя столбца> = {<выражение> | NULL}
[,SET
<имя столбца> = {<выражение> |
NULL}…
]
[WHERE
<условие>]
Инструкция
UPDATE
обновляет значения в определенных
предложением SET
столбцах таблицы для тех строк, которые
удовлетворяют условию, заданному
предложением WHERE.
Новые
значения столбцов могут быть пустыми
(NULL),
либо вычисляться в соответствии с
арифметическим выражением.
Пример
3.44. Изменение
строк
Пусть
необходимо увеличить на 15% цену только
тех товаров, которые стоят меньше 100$.
Запрос, сформулированный с помощью
оператора UPDATE,
может выглядеть так:
UPDATE
PROD
SET
PRICE=( PRICE*1.15)
WHERE
PRICE
<=100
Инструкция
для вставки
новых строк
имеет форматы двух видов:
INSERT
INTO
<имя таблицы> [(<список столбцов>)]
VALUES
(<список значений>)
и
INSERT
INTO
<имя таблицы> [(<список столбцов>)]
<предложение
SELECT>
В
первом формате оператор INSERT
предназначен для одной строки с заданными
значениями в столбцах. Порядок перечисления
имен столбцов должен соответствовать
порядку значений, перечисленных в списке
предложения VALUES.
Если <список столбцов> опущен, то в
<списке значений> должны быть
перечислены все значения в порядке
столбцов структуры таблицы.
Во
втором формате оператор INSERT
предназначен для ввода в заданную
таблицу новых
строк, отобранных из другой таблицы с
помощью предложения SELECT.
Пример
3.45.
Ввести
в таблицу CUST
строку, содержащую сведения о новом
клиенте. Для этого можно записать
инструкцию такого вида:
INSERT
INTO
CUST
1.4. Инструкции и имена
SQL представлен множеством инструкций, каждая из которых предписывает СУБД выполнить определенное действие: создать таблицу, извлечь данные, добавить в таблицу новые данные и т. п. Инструкция SQL начинается с команды – ключевого слова, описывающего действие, выполняемое инструкцией. Типичными являются команды
CREATE (создать), INSERT (добавить), SELECT (выбрать), DELETE (удалить). Следом за командой указывается одно или несколько предложений. Предложение описывает данные, с которыми должна работать инструкция, или уточняет действие, выполняемое инструкцией. Предложения в инструкции делятся на обязательные и необязательные.
Каждое предложение начинается с ключевого слова, например – WHERE (где), FROM (откуда), INTO (куда). Многие предложения в качестве параметров содержат имена таблиц или столбцов; некоторые из них могут содержать дополнительные ключевые слова, константы и выражения.
У каждого объекта в базе данных есть уникальное имя. Имена используются в инструкциях SQL и указывают, над каким объектом базы данных инструкция должна выполнить действие. В соответствии со стандартом ANSI/ISO имена в SQL могут содержать от 1 до 18 символов, начинаться с буквы и не должны включать пробелов или специальных символов пунктуации. В стандарте SQL2 максимальное число символов в
Лекция «Лекция 7» также может быть Вам полезна.
имени увеличено до 128. На практике в различных СУБД поддержка именования реализована по – разному: в DB2, например, имена пользователей не могут превышать восьми символов, а имена таблиц и столбцов могут быть более длинными. В различных СУБД также существуют и различные подходы к использованию в именах специальных
символов. В инструкциях SQL могут использоваться как полные имена объектов, так и короткие. Полное имя таблицы (в отличие от короткого) содержит имя пользователя и короткое имя таблицы, разделенные точкой:
< Имя_пользователя >. < Имя_таблицы >
При этом уникальность именования таблицы сохраняется в случае, если в рамках одной базы данных разные пользователи создают таблицы с одинаковыми именами.
Полное имя столбца в свою очередь состоит из полного ( или короткого) имени таблицы, которой принадлежит столбец, и короткого имени столбца, разделенных точкой: <Имя_пользователя>.<Имя_таблииы>.<Имя_столбца> или <Имя таблицы>.<Имя столбиа>
В рамках одной таблицы не может быть определено двух столбцов с одинаковыми именами, но в разных таблицах это возможно. При этом в инструкциях SQL необходимо использовать полное именование столбцов.