Вероятно, вы слышали о языке XML и вам известно множество причин, по которым его необходимо использовать в вашей организации. Но что именно представляет собой XML? В этой статье объясняется, что такое XML и как он работает.
В этой статье
-
Пометки, разметка и теги
-
Отличительные черты XML
-
Правильно сформированные данные
-
Схемы
-
Преобразования
-
XML в системе Microsoft Office
Пометки, разметка и теги
Чтобы понять XML, полезно понимать идею пометки данных. Люди создавали документы на протяжении многих лет и на протяжении всего времени они их помечали. Например, преподаватели могут постоянно пометить документы учащихся. Учащиеся могут перемещать абзацы, уточнять предложения, исправлять опечатки и так далее. Пометка документа определяет структуру, смысл и внешний вид сведений в документе. Если вы когда-либо использовали функцию «Отслеживание изменений» в Microsoft Office Word, то использовали компьютеризированную форму пометки.
В мире информационных технологий термин «пометка» превратился в термин «разметка». При разметке используются коды, называемые тегами (или иногда токенами), для определения структуры, визуального оформления и — в случае XML — смысла данных.
Текст этой статьи в формате HTML является хорошим примером применения компьютерной разметки. Если в Microsoft Internet Explorer щелкнуть эту страницу правой кнопкой мыши и выбрать команду Просмотр HTML-кода, вы увидите читаемый текст и теги HTML, например <p> и <h2>. В HTML- и XML-документах теги легко распознать, поскольку они заключены в угловые скобки. В исходном тексте этой статьи теги HTML выполняют множество функций, например определяют начало и конец каждого абзаца (<p> … </p>) и местоположение рисунков.
Отличительные черты XML
Документы в форматах HTML и XML содержат данные, заключенные в теги, но на этом сходство между двумя языками заканчивается. В формате HTML теги определяют оформление данных — расположение заголовков, начало абзаца и т. д. В формате XML теги определяют структуру и смысл данных — то, чем они являются.
При описании структуры и смысла данных становится возможным их повторное использование несколькими способами. Например, если у вас есть блок данных о продажах, каждый элемент в котором четко определен, то можно загрузить в отчет о продажах только необходимые элементы, а другие данные передать в бухгалтерскую базу данных. Иначе говоря, можно использовать одну систему для генерации данных и пометки их тегами в формате XML, а затем обрабатывать эти данные в любых других системах вне зависимости от клиентской платформы или операционной системы. Благодаря такой совместимости XML является основой одной из самых популярных технологий обмена данными.
Учитывайте при работе следующее:
-
HTML нельзя использовать вместо XML. Однако XML-данные можно заключать в HTML-теги и отображать на веб-страницах.
-
Возможности HTML ограничены предопределенным набором тегов, общим для всех пользователей.
-
Правила XML разрешают создавать любые теги, требуемые для описания данных и их структуры. Допустим, что вам необходимо хранить и совместно использовать сведения о домашних животных. Для этого можно создать следующий XML-код:
<?xml version="1.0"?> <CAT> <NAME>Izzy</NAME> <BREED>Siamese</BREED> <AGE>6</AGE> <ALTERED>yes</ALTERED> <DECLAWED>no</DECLAWED> <LICENSE>Izz138bod</LICENSE> <OWNER>Colin Wilcox</OWNER> </CAT>
Как видно, по тегам XML понятно, какие данные вы просматриваете. Например, ясно, что это данные о коте, и можно легко определить его имя, возраст и т. д. Благодаря возможности создавать теги, определяющие почти любую структуру данных, язык XML является расширяемым.
Но не путайте теги в данном примере с тегами в HTML-файле. Например, если приведенный выше текст в формате XML вставить в HTML-файл и открыть его в браузере, то результаты будут выглядеть следующим образом:
Izzy Siamese 6 yes no Izz138bod Colin Wilcox
Веб-браузер проигнорирует теги XML и отобразит только данные.
Правильно сформированные данные
Вероятно, вы слышали, как кто-то из ИТ-специалистов говорил о «правильно сформированном» XML-файле. Правильно сформированный XML-файл должен соответствовать очень строгим правилам. Если он не соответствует этим правилам, XML не работает. Например, в предыдущем примере каждый открывающий тег имеет соответствующий закрывающий тег, поэтому в данном примере соблюдено одно из правил правильно сформированного XML-файла. Если же удалить из файла какой-либо тег и попытаться открыть его в одной из программ Office, то появится сообщение об ошибке и использовать такой файл будет невозможно.
Правила создания правильно сформированного XML-файла знать необязательно (хотя понять их нетрудно), но следует помнить, что использовать в других приложениях и системах можно лишь правильно сформированные XML-данные. Если XML-файл не открывается, то он, вероятно, неправильно сформирован.
XML не зависит от платформы, и это значит, что любая программа, созданная для использования XML, может читать и обрабатывать XML-данные независимо от оборудования или операционной системы. Например, при применении правильных тегов XML можно использовать программу на настольном компьютере для открытия и обработки данных, полученных с мейнфрейма. И, независимо от того, кто создал XML-данные, с ними данными можно работать в различных приложениях Office. Благодаря своей совместимости XML стал одной из самых популярных технологий обмена данными между базами данных и пользовательскими компьютерами.
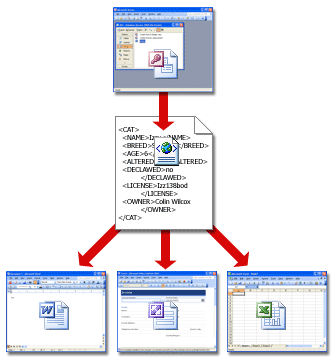
В дополнение к правильно сформированным данным с тегами XML-системы обычно используют два дополнительных компонента: схемы и преобразования. В следующих разделах описывается, как они работают.
Схемы
Не пугайтесь термина «схема». Схема — это просто XML-файл, содержащий правила для содержимого XML-файла данных. Файлы схем обычно имеют расширение XSD, тогда как для файлов данных XML используется расширение XML.
Схемы позволяют программам проверять данные. Они формируют структуру данных и обеспечивают их понятность создателю и другим людям. Например, если пользователь вводит недопустимые данные, например текст в поле даты, программа может предложить ему исправить их. Если данные в XML-файле соответствуют правилам в схеме, для их чтения, интерпретации и обработки можно использовать любую программу, поддерживающую XML. Например, как показано на приведенном ниже рисунке, Excel может проверять данные <CAT> на соответствие схеме CAT.
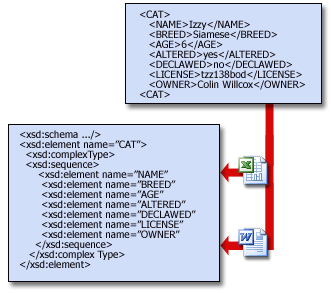
Схемы могут быть сложными, и в данной статье невозможно объяснить, как их создавать. (Кроме того, скорее всего, в вашей организации есть ИТ-специалисты, которые знают, как это делать.) Однако полезно знать, как выглядят схемы. Следующая схема определяет правила для набора тегов <CAT> … </CAT>:
<xsd:element name="CAT">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="NAME" type="xsd:string"/>
<xsd:element name="BREED" type="xsd:string"/>
<xsd:element name="AGE" type="xsd:positiveInteger"/>
<xsd:element name="ALTERED" type="xsd:boolean"/>
<xsd:element name="DECLAWED" type="xsd:boolean"/>
<xsd:element name="LICENSE" type="xsd:string"/>
<xsd:element name="OWNER" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
Не беспокойтесь, если в примере не все понятно. Просто обратите внимание на следующее:
-
Строковые элементы в приведенном примере схемы называются объявлениями. Если бы требовались дополнительные сведения о животном, например его цвет или особые признаки, то специалисты отдела ИТ добавили бы к схеме соответствующие объявления. Систему XML можно изменять по мере развития потребностей бизнеса.
-
Объявления являются мощным средством управления структурой данных. Например, объявление <xsd:sequence> означает, что теги, такие как <NAME> и <BREED>, должны следовать в указанном выше порядке. С помощью объявлений можно также проверять типы данных, вводимых пользователем. Например, приведенная выше схема требует ввода положительного целого числа для возраста кота и логических значений (TRUE или FALSE) для тегов ALTERED и DECLAWED.
-
Если данные в XML-файле соответствуют правилам схемы, то такие данные называют допустимыми. Процесс контроля соответствия XML-файла данных правилам схемы называют (достаточно логично) проверкой. Большим преимуществом использования схем является возможность предотвратить с их помощью повреждение данных. Схемы также облегчают поиск поврежденных данных, поскольку при возникновении такой проблемы обработка XML-файла останавливается.
Преобразования
Как говорилось выше, XML также позволяет эффективно использовать и повторно использовать данные. Механизм повторного использования данных называется преобразованием XSLT (или просто преобразованием).
Вы (или ваш ИТ-отдел) можете также использовать преобразования для обмена данными между серверными системами, например между базами данных. Предположим, что в базе данных А данные о продажах хранятся в таблице, удобной для отдела продаж. В базе данных Б хранятся данные о доходах и расходах в таблице, специально разработанной для бухгалтерии. База данных Б может использовать преобразование, чтобы принять данные от базы данных A и поместить их в соответствующие таблицы.
Сочетание файла данных, схемы и преобразования образует базовую систему XML. На следующем рисунке показана работа подобных систем. Файл данных проверяется на соответствие правилам схемы, а затем передается любым пригодным способом для преобразования. В этом случае преобразование размещает данные в таблице на веб-странице.
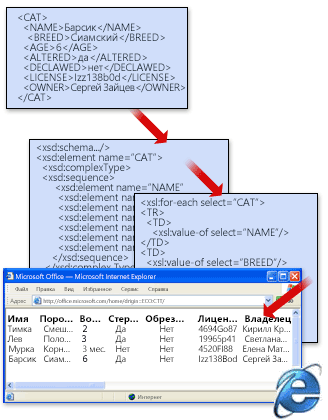
В следующем примере кода показан один из способов написания преобразования. Она загружает данные <CAT> в таблицу на веб-странице. В этом примере суть не в том, чтобы показать, как написать преобразование, а в том, чтобы показать одну форму, которую может принять преобразование.
<?xml version="1.0"?>
<xsl:stylesheet version="1.0">
<TABLE>
<TR>
<TH>Name</TH>
<TH>Breed</TH>
<TH>Age</TH>
<TH>Altered</TH>
<TH>Declawed</TH>
<TH>License</TH>
<TH>Owner</TH>
</TR>
<xsl:for-each select="CAT">
<TR ALIGN="LEFT" VALIGN="TOP">
<TD>
<xsl:value-of select="NAME"/>
</TD>
<TD>
<xsl:value-of select="BREED"/>
</TD>
<TD>
<xsl:value-of select="AGE"/>
</TD>
<TD>
<xsl:value-of select="ALTERED"/>
</TD>
<TD>
<xsl:value-of select="DECLAWED"/>
</TD>
<TD>
<xsl:value-of select="LICENSE"/>
</TD>
<TD>
<xsl:value-of select="OWNER"/>
</TD>
</TR>
</xsl:for-each>
</TABLE>
В этом примере показано, как может выглядеть текст одного из типов преобразования, но помните, что вы можете ограничиться четким описанием того, что вам нужно от данных, и это описание может быть сделано на вашем родном языке. Например, вы можете пойти в отдел ИТ и сказать, что необходимо напечатать данные о продажах для конкретных регионов за последние два года, и что эти сведения должны выглядеть так-то и так-то. После этого специалисты отдела могут написать (или изменить) преобразование, чтобы выполнить вашу просьбу.
Корпорация Майкрософт и растущее число других компаний создают преобразования для различных задач, что делает использование XML еще более удобным. В будущем, скорее всего, можно будет скачать преобразование, отвечающее вашим потребностям без дополнительной настройки или с небольшими изменениями. Это означает, что со временем использование XML будет требовать все меньше и меньше затрат.
XML в системе Microsoft Office
Профессиональные выпуски Office обеспечивают всестороннюю поддержку XML. Начиная с Microsoft Office 2007, в Microsoft Office используются форматы файлов на основе XML, например DOCX, XLSX и PPTX. Поскольку XML-данные хранятся в текстовом формате вместо запатентованного двоичного формата, ваши клиенты могут определять собственные схемы и использовать ваши данные разными способами без лицензионных отчислений. Дополнительные сведения о новых форматах см. в сведениях о форматах Open XML и расширениях имен файлов. К другим преимуществам относятся:
-
Меньший размер файлов. Новый формат использует ZIP и другие технологии сжатия, поэтому размер файла на 75 процентов меньше, чем в двоичных форматах, применяемых в более ранних версиях Office.
-
Более простое восстановление данных и большая безопасность. Формат XML может быть легко прочитан пользователем, поэтому если файл поврежден, его можно открыть в Блокноте или другой программе для просмотра текста и восстановить хотя бы часть данных. Кроме того, новые файлы более безопасны, потому что они не могут содержать код Visual Basic для приложений (VBA). Если новый формат используется для создания шаблонов, то элементы ActiveX и макросы VBA находятся в отдельном, более безопасном разделе файла. Кроме того, можно удалять личные данные из документов с помощью таких средств, как инспектор документов. Дополнительные сведения об использовании инспектора документов см. в статье Удаление скрытых и персональных данных при проверке документов.
Пока все хорошо, но что делать, если у вас есть данные XML без схемы? У Office программ, которые поддерживают XML, есть свои подходы к работе с данными. Например, Excel выдаст схему, если вы откроете XML-файл, который еще не имеет такой схемы. Excel затем вы можете загрузить эти данные в XML-таблицу. Для сортировки, фильтрации или добавления вычислений в данные можно использовать XML-списки и таблицы.
Включение средств XML в Office
По умолчанию вкладка «Разработчик» не отображается. Ее необходимо добавить на ленту для использования команд XML в Office.
-
В Office 2016, Office 2013 или Office 2010: Отображение вкладки «Разработчик».
-
В Office 2007: Отображение вкладки разработчика или запуск в режиме разработчика.
Введение в XML¶
XML ( англ. eXtensible Markup Language) — расширяемый язык разметки,
предназначенный для хранения и передачи данных.
Простейший XML-документ выглядит следующим образом:
<?xml version="1.0" encoding="windows-1251"?> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price></price> </book>
Первая строка — это XML декларация. Здесь определяется версия XML (1.0) и кодировка файла. На следующей строке описывается корневой элемент документа <book> (открывающий тег). Следующие 4 строки описывают дочерние элементы корневого элемента ( title, author, year, price). Последняя строка определяет конец корневого элемента </book> (закрывающий тег).
Документ XML состоит из элементов (elements). Элемент начинается открывающим тегом (start-tag) в угловых скобках, затем идет содержимое (content) элемента, после него записывается закрывающий тег (end-teg) в угловых скобках.
Информация, заключенная между тегами, называется содержимым или значением элемента: <author>Erik T. Ray</author>. Т.е. элемент author принимает значение Erik T. Ray. Элементы могут вообще не принимать значения.
Элементы могут содержать атрибуты, так, например, открывающий тег <title lang="en"> имеет атрибут lang, который принимает значение en. Значения атрибутов заключаются в кавычки (двойные или ординарные).
Некоторые элементы, не содержащие значений, допустимо записывать без закрывающего тега. В таком случае символ / ставится в конце открывающего тега:
<name first="Иван" second="Петрович" />
Структура XML¶
XML документ должен содержать корневой элемент. Этот элемент является «родительским» для всех других элементов.
Все элементы в XML документе формируют иерархическое дерево. Это дерево начинается с корневого элемента и разветвляется на более низкие уровни элементов.
Все элементы могут иметь подэлементы (дочерние элементы):
<корневой> <потомок> <подпотомок>.....</подпотомок> </потомок> </корневой>
Правила синтаксиса (Валидность)¶
Структура XML документа должна соответствовать определенным правилам.
XML документ отвечающий этим правилам называется валидным (англ.
Valid — правильный) или синтаксически верным. Соответственно, если
документ не отвечает правилам, он является невалидным .
Основные правила синтаксиса XML:
- Теги XML регистрозависимы — теги XML являются регистрозависимыми. Так, тег
<Letter>не то же самое, что тег<letter>.
Открывающий и закрывающий теги должны определяться в одном регистре:
<Message>Это неправильно</message> <message>Это правильно</message>
- XML элементы должны соблюдать корректную вложенность:
<b><i>Некорректная вложенность</b></i> <b><i>Корректная вложенность</i></b>
- У XML документа должен быть корневой элемент — XML документ должен содержать один элемент, который будет родительским для всех других элементов. Он называется корневым элементом.
Примечание
В большинстве XML файлов отчетов для ФНС корневым элементом является
<Файл></Файл>. После закрывающего тега</Файл>больше ничего быть не должно.
- Значения XML атрибутов должны заключаться в кавычки:
<note date="12/11/2007">Корректная запись</note> <note date=12/11/2007>Некорреткная запись</note>
Сущности¶
Некоторые символы в XML имеют особые значения и являются служебными. Если вы поместите,
например, символ < внутри XML элемента, то будет
сгенерирована ошибка, так как парсер интерпретирует его, как начало
нового элемента.
В примере ниже будет сгенерирована ошибка, так как в значении "ООО<Мосавтогруз>" атрибута НаимОрг содержатся символы < и >.
<НПЮЛ ИННЮЛ="7718962261" КПП="771801001" НаимОрг="ООО<Мосавтогруз>"/>
Также ошибка будет сгенерирована и в слудющем примере, если название организации взять в обычные кавычки (английские двойные):
<НПЮЛ ИННЮЛ="7718962261" КПП="771801001" НаимОрг="ООО"Мосавтогруз""/>
Чтобы ошибки не возникали, нужно заменить символ < на его
сущность. В XML существует 5 предопределенных сущностей:
| Сущность | Символ | Значение |
|---|---|---|
< |
< |
меньше, чем |
> |
> |
больше, чем |
& |
& |
амперсанд |
' |
' |
апостроф |
" |
" |
кавычки |
Примечание
Только символы < и & строго запрещены в XML. Символ > допустим, но лучше его всегда заменять на сущность.
Таким образом, корректными будут следующие формы записей:
<НПЮЛ ИННЮЛ="7718962261" КПП="771801001" НаимОрг="ООО"Мосавтогруз""/>
или
<НПЮЛ ИННЮЛ="7718962261" КПП="771801001" НаимОрг="ООО«Мосавтогруз»"/>
В последнем примере английские двойные кавычки заменены на французские кавычки («ёлочки»), которые не являются служебными символами.
Поиск информации в XML файлах (XPath)¶
XPath ( англ. XML Path Language) — язык запросов к элементам
XML-документа. XPath расширяет возможности работы с XML.
XML имеет древовидную структуру. В документе всегда имеется корневой
элемент (инструкция <?xml version=”1.0”?> к дереву отношения не имеет).
У элемента дерева всегда существуют потомки и предки, кроме корневого
элемента, у которого предков нет, а также тупиковых элементов (листьев
дерева), у которых нет потомков. Каждый элемент дерева находится на
определенном уровне вложенности (далее — «уровень»). У элементов на
одном уровне бывают предыдущие и следующие элементы.
Это очень похоже на организацию каталогов в файловой системе, и строки
XPath, фактически, — пути к «файлам» — элементам. Рассмотрим пример
списка книг:
<?xml version="1.0" encoding="windows-1251"?> <bookstore> <book category="COOKING"> <title lang="it">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
XPath запрос /bookstore/book/price вернет следующий результат:
<price>30.00</price> <price>29.99</price> <price>39.95</price>
Сокращенная форма этого запроса выглядит так: //price.
С помощью XPath запросов можно искать информацию по атрибутам. Например,
можно найти информацию о книге на итальянском языке: //title[@lang="it"] вернет <title lang="it">Everyday Italian</title>.
Чтобы получить больше информации, необходимо модифицировать запрос //book[title[@lang="it"]] вернет:
<book category="COOKING"> <title lang="it">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book>
В приведенной ниже таблице представлены некоторые выражения XPath и
результат их работы:
| Выражение XPath | Результат |
|---|---|
/bookstore/book[1] |
Выбирает первый элемент book, который является потомком элемента bookstore |
/bookstore/book[position()<3] |
Выбирает первые два элемента book, которые являются потомками элемента bookstore |
//title[@lang] |
Выбирает все элементы title с атрибутом lang |
//title[@lang=’en’] |
Выбирает все элементы title с атрибутом lang, который имеет значение en |
/bookstore/book[price>35.00] |
Выбирает все элементы book, которые являются потомками элемента bookstore и которые содержать элемент price со значением больше 35.00 |
/bookstore/book[price>35.00]/title |
Выбирает все элементы title элементов book элементов bookstore, которые содержать элемент price со значением больше 35.00 |
Кодировки¶
И еще один важный момент, который стоит рассмотреть — кодировки. Существует множество кодировок, о них подробнее можно прочитать в статье Набор
символов.
Самыми распространенными кириллическими кодировками являются Windows-1251 и UTF-8. Последняя является одним из стандартов, но большая часть ФНС отчетности имеет кодировку Windows-1251.
В XML файле кодировка объявляется в декларации:
<?xml version="1.0" encoding="windows-1251"?>
Часто можно столкнуться с ситуацией, когда текстовый редаткор некорректно распознает кодировку и отображает кракозябры. В такой случае, необходимо выбрать кодировку вручную, для этого выполните:
| Программа | Кодировка |
|---|---|
| Notepad++ | «Документ → Кодировка» |
| Geany | «Документ → Установить кодировку» |
| Firefox | «Вид → Кодировка» |
| Chrome | «Настройка → Дополнительные инструменты → Кодировка» |
Примечание
В большинстве случаев при работе с русскоязычными файлами помогает переключение кодировки на Windows-1251 или UTF-8. Если все равно не удается прочитать содержимое XML документа, стоит открыть его в Mozilla Firefox, он отлично распознает кодировки.
Если ничего не помогает, вполне возможно, что файл был поврежден.
XSD схема¶
XML Schema — язык описания структуры XML-документа, его также называют XSD. Как большинство языков описания XML, XML Schema была задумана для определения правил, которым должен подчиняться документ. Но, в отличие от других языков, XML Schema была разработана так, чтобы её можно было использовать в создании программного обеспечения для обработки документов XML.
После проверки документа на соответствие XML Schema читающая программа может создать модель данных документа, которая включает:
- словарь (названия элементов и атрибутов);
- модель содержания (отношения между элементами и атрибутами и их структура);
- типы данных.
Каждый элемент в этой модели ассоциируется с определённым типом данных, позволяя строить в памяти объект, соответствующий структуре XML-документа. Языкам объектно-ориентированного программирования гораздо легче иметь дело с таким объектом, чем с текстовым файлом.
Подробнее об XSD смотрите:
- XML Schema
- XSD — умный XML
Если вы тестируете API, то должны знать про два основных формата передачи данных:
- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.
Сегодня я расскажу вам про XML.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:
Что такое API — общее знакомство с API
Что такое JSON — второй популярный формат
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.

Содержание
- Как устроен XML
- Теги
- Корневой элемент
- Значение элемента
- Атрибуты элемента
- XML пролог
- XSD-схема
- Практика: составляем свой запрос
- Well Formed XML
- 1. Есть корневой элемент
- 2. У каждого элемента есть закрывающийся тег
- 3. Теги регистрозависимы
- 4. Правильная вложенность элементов
- 5. Атрибуты оформлены в кавычках
- Итого
Как устроен XML
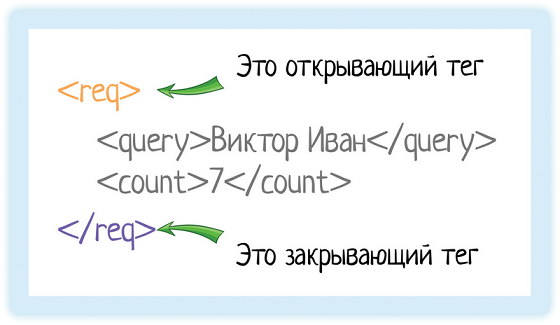
Возьмем пример из документации подсказок Дадаты по ФИО:
<req>
<query>Виктор Иван</query>
<count>7</count>
</req>И разберемся, что означает эта запись.

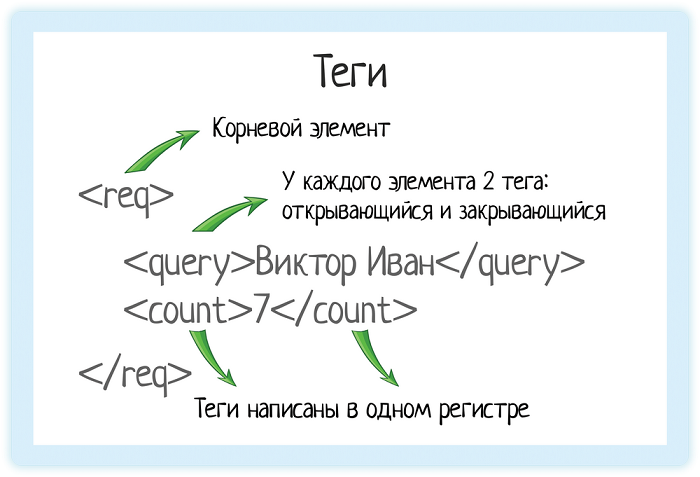
Теги
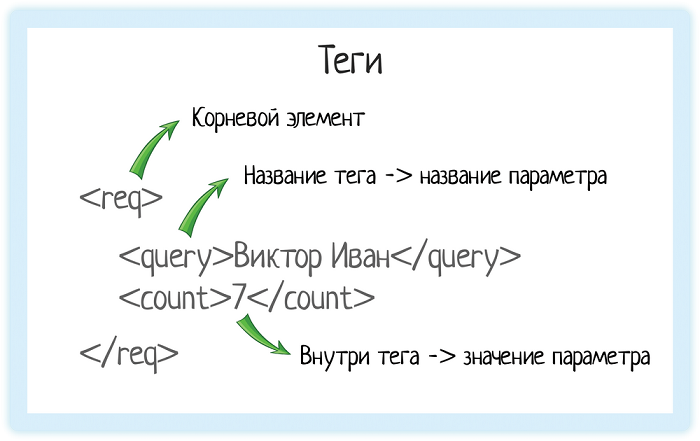
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
<tag>
Текст внутри угловых скобок — название тега.
Тега всегда два:
- Открывающий — текст внутри угловых скобок
<tag> - Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое:
Москва
*
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!

Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».

Он мог бы называться по другому:
<main><sugg>Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.

Внутри — значение запроса.
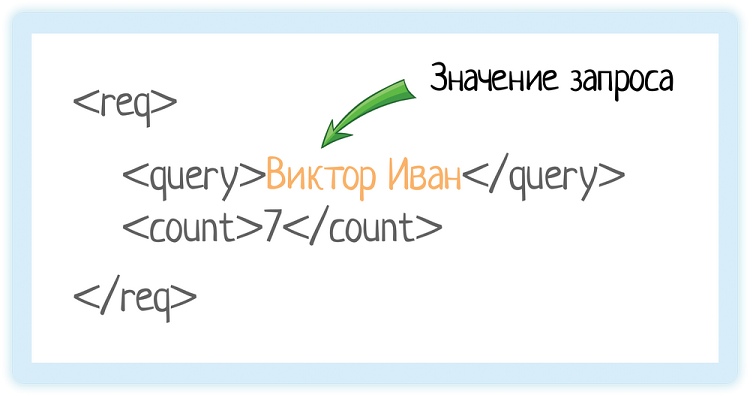
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
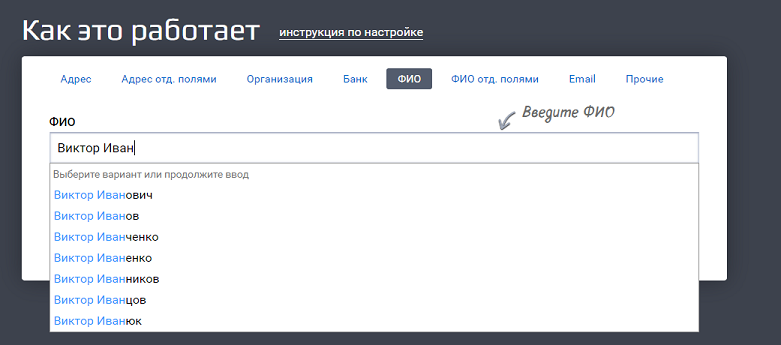
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.
См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.
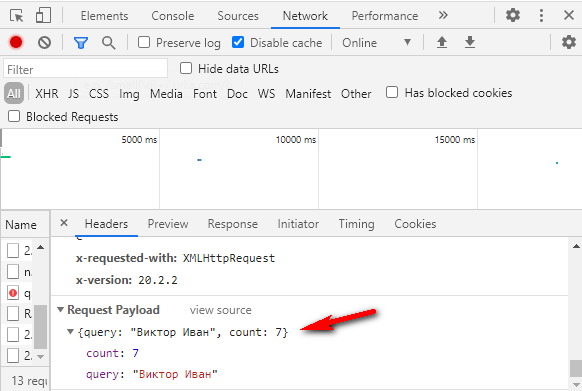
Обратите внимание:
- Виктор Иван — строка
- 7 — число
Но оба значения идут
без
кавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
название_атрибута = «значение атрибута»Например:
<query attr1=“value 1”>Виктор Иван</query>
<query attr1=“value 1” attr2=“value 2”>Виктор Иван</query>
Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<field name=“name">Олег </field>
<field name="birthdate">02.01.1980</field>
<attribute type="PHONE" rawId="AL.2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>Давайте разберем эту запись. У нас есть основной элемент party.

У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!

Внутри party есть элементы field.

У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.

Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.

У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл…
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?

Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
<?xml version="1.0" encoding="UTF-8"?>Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
UTF-8 — кодировка XML документов по умолчанию.
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.
Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- …
Теперь, когда к нам приходит какой-то запрос, он сперва проверяется на корректность по схеме. Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…
Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.

Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!

А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.
Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.

Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
А теперь давайте посмотрим, как схема может выглядеть! Возьмем для примера метод doRegister в Users. Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
<xs:element name="doRegister ">
<xs:complexType>
<xs:sequence>
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>А в WSDl сервиса она записана еще проще:
<message name="doRegisterRequest">
<part name="email" type="xsd:string"/>
<part name="name" type="xsd:string"/>
<part name="password" type="xsd:string"/>
</message>Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:complexType name="Test">
<xsd:sequence>
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
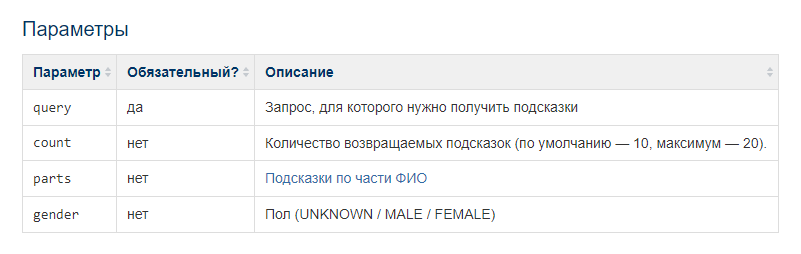
Что, если я хочу, чтобы мне вернулись только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req>
<query>Виктор Иван</query>
<count>7</count>
</req>В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
<req>
<query>Ан</query>
<count>7</count>
</req>Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
<req>
<query>Ан</query>
<count>7</count>
<gender>FEMALE</gender>
</req>Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
<req>
<query>Ан</query>
<gender>FEMALE</gender>
</req>Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.
И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!
2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.
Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>Это тоже самое, что передать в нем пустое значение
<name></name>Аналогично сервер может вернуть нам пустое значение тега. Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
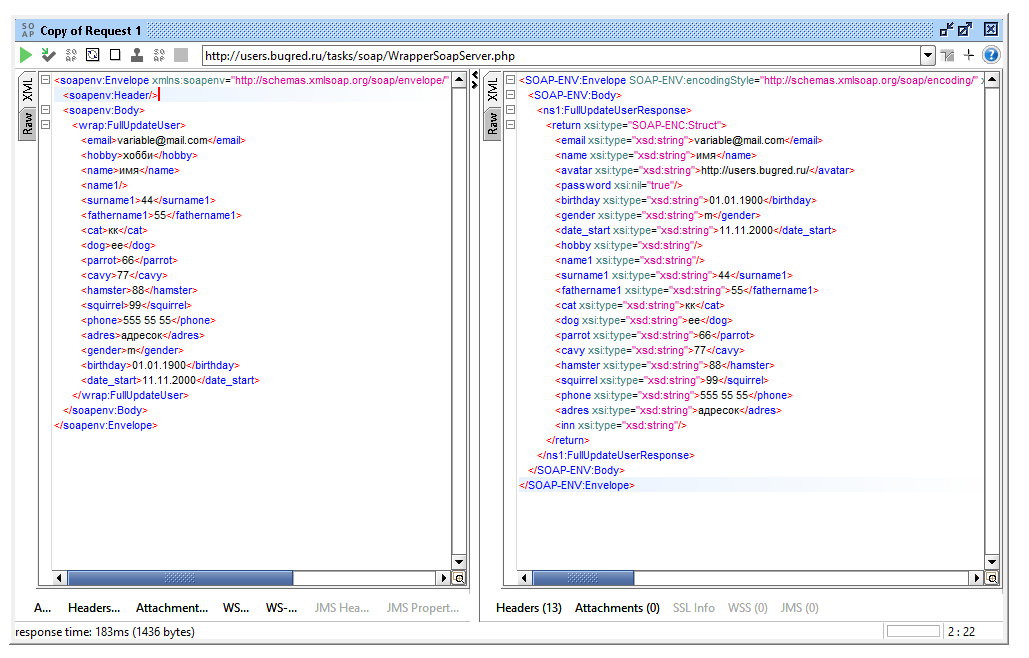
Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.
А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
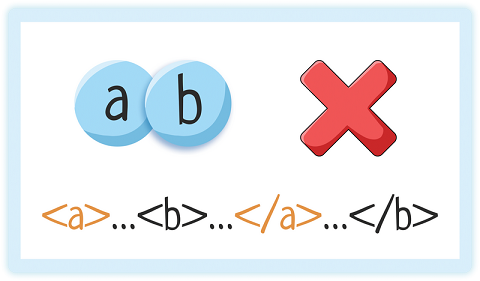
4. Правильная вложенность элементов
Элементы могут идти друг за другом

Один элемент может быть вложен в другой

Но накладываться друг на друга элементы НЕ могут!
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
<query attr1=“123”>Виктор Иван</query>
<query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>Для тестирования пробуем передать его без кавычек:
<query attr1=123>Виктор Иван</query>Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.
Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.

Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XML
Учебник по XML
Изучаем XML. Эрик Рэй (книга по XML)
Заметки о XML и XLST
Что такое JSON — второй популярный формат
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
XML — Overview
XML stands for Extensible Markup Language. It is a text-based markup language derived from Standard Generalized Markup Language (SGML).
XML tags identify the data and are used to store and organize the data, rather than specifying how to display it like HTML tags, which are used to display the data. XML is not going to replace HTML in the near future, but it introduces new possibilities by adopting many successful features of HTML.
There are three important characteristics of XML that make it useful in a variety of systems and solutions −
-
XML is extensible − XML allows you to create your own self-descriptive tags, or language, that suits your application.
-
XML carries the data, does not present it − XML allows you to store the data irrespective of how it will be presented.
-
XML is a public standard − XML was developed by an organization called the World Wide Web Consortium (W3C) and is available as an open standard.
XML Usage
A short list of XML usage says it all −
-
XML can work behind the scene to simplify the creation of HTML documents for large web sites.
-
XML can be used to exchange the information between organizations and systems.
-
XML can be used for offloading and reloading of databases.
-
XML can be used to store and arrange the data, which can customize your data handling needs.
-
XML can easily be merged with style sheets to create almost any desired output.
-
Virtually, any type of data can be expressed as an XML document.
What is Markup?
XML is a markup language that defines set of rules for encoding documents in a format that is both human-readable and machine-readable. So what exactly is a markup language? Markup is information added to a document that enhances its meaning in certain ways, in that it identifies the parts and how they relate to each other. More specifically, a markup language is a set of symbols that can be placed in the text of a document to demarcate and label the parts of that document.
Following example shows how XML markup looks, when embedded in a piece of text −
<message> <text>Hello, world!</text> </message>
This snippet includes the markup symbols, or the tags such as <message>…</message> and <text>… </text>. The tags <message> and </message> mark the start and the end of the XML code fragment. The tags <text> and </text> surround the text Hello, world!.
Is XML a Programming Language?
A programming language consists of grammar rules and its own vocabulary which is used
to create computer programs. These programs instruct the computer to perform specific tasks. XML does not qualify to be a programming language as it does not perform any computation or algorithms. It is usually stored in a simple text file and is processed by special software that is capable of interpreting XML.
XML — Syntax
In this chapter, we will discuss the simple syntax rules to write an XML document. Following is a complete XML document −
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
You can notice there are two kinds of information in the above example −
-
Markup, like <contact-info>
-
The text, or the character data, Tutorials Point and (040) 123-4567.
The following diagram depicts the syntax rules to write different types of markup and text in an XML document.
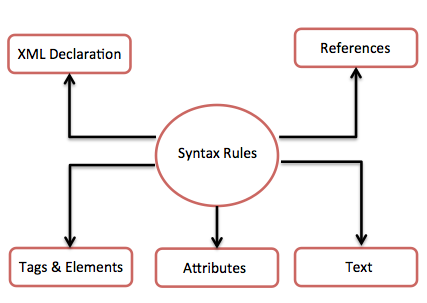
Let us see each component of the above diagram in detail.
XML Declaration
The XML document can optionally have an XML declaration. It is written as follows −
<?xml version = "1.0" encoding = "UTF-8"?>
Where version is the XML version and encoding specifies the character encoding used in the document.
Syntax Rules for XML Declaration
-
The XML declaration is case sensitive and must begin with «<?xml>» where «xml» is written in lower-case.
-
If document contains XML declaration, then it strictly needs to be the first statement of the XML document.
-
The XML declaration strictly needs be the first statement in the XML document.
-
An HTTP protocol can override the value of encoding that you put in the XML declaration.
Tags and Elements
An XML file is structured by several XML-elements, also called XML-nodes or XML-tags.
The names of XML-elements are enclosed in triangular brackets < > as shown below −
<element>
Syntax Rules for Tags and Elements
Element Syntax − Each XML-element needs to be closed either with start or with end elements as shown below −
<element>....</element>
or in simple-cases, just this way −
<element/>
Nesting of Elements − An XML-element can contain multiple XML-elements as its children, but the children elements must not overlap. i.e., an end tag of an element must have the same name as that of the most recent unmatched start tag.
The Following example shows incorrect nested tags −
<?xml version = "1.0"?> <contact-info> <company>TutorialsPoint </contact-info> </company>
The Following example shows correct nested tags −
<?xml version = "1.0"?> <contact-info> <company>TutorialsPoint</company> <contact-info>
Root Element − An XML document can have only one root element. For example, following is not a correct XML document, because both the x and y elements occur at the top level without a root element −
<x>...</x> <y>...</y>
The Following example shows a correctly formed XML document −
<root> <x>...</x> <y>...</y> </root>
Case Sensitivity − The names of XML-elements are case-sensitive. That means the name of the start and the end elements need to be exactly in the same case.
For example, <contact-info> is different from <Contact-Info>
XML Attributes
An attribute specifies a single property for the element, using a name/value pair. An XML-element can have one or more attributes. For example −
<a href = "http://www.tutorialspoint.com/">Tutorialspoint!</a>
Here href is the attribute name and http://www.tutorialspoint.com/ is attribute value.
Syntax Rules for XML Attributes
-
Attribute names in XML (unlike HTML) are case sensitive. That is, HREF and href are considered two different XML attributes.
-
Same attribute cannot have two values in a syntax. The following example shows incorrect syntax because the attribute b is specified twice
−
<a b = "x" c = "y" b = "z">....</a>
-
Attribute names are defined without quotation marks, whereas attribute values must always appear in quotation marks. Following example demonstrates incorrect xml syntax
−
<a b = x>....</a>
In the above syntax, the attribute value is not defined in quotation marks.
XML References
References usually allow you to add or include additional text or markup in an XML document. References always begin with the symbol «&» which is a reserved character and end with the symbol «;». XML has two types of references −
-
Entity References − An entity reference contains a name between the start and the end delimiters. For example & where amp is name. The name refers to a predefined string of text and/or markup.
-
Character References − These contain references, such as A, contains a hash mark (“#”) followed by a number. The number always refers to the Unicode code of a character. In this case, 65 refers to alphabet «A».
XML Text
The names of XML-elements and XML-attributes are case-sensitive, which means the name of start and end elements need to be written in the same case. To avoid character encoding problems, all XML files should be saved as Unicode UTF-8 or UTF-16 files.
Whitespace characters like blanks, tabs and line-breaks between XML-elements and between the XML-attributes will be ignored.
Some characters are reserved by the XML syntax itself. Hence, they cannot be used directly. To use them, some replacement-entities are used, which are listed below −
| Not Allowed Character | Replacement Entity | Character Description |
|---|---|---|
| < | < | less than |
| > | > | greater than |
| & | & | ampersand |
| ‘ | ' | apostrophe |
| « | " | quotation mark |
XML — Documents
An XML document is a basic unit of XML information composed of elements and other markup in an orderly package. An XML document can contains wide variety of data. For example, database of numbers, numbers representing molecular structure or a mathematical equation.
XML Document Example
A simple document is shown in the following example −
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
The following image depicts the parts of XML document.

Document Prolog Section
Document Prolog comes at the top of the document, before the root element. This section contains −
- XML declaration
- Document type declaration
You can learn more about XML declaration in this chapter − XML Declaration
Document Elements Section
Document Elements are the building blocks of XML. These divide the document into a hierarchy of sections, each serving a specific purpose. You can separate a document into multiple sections so that they can be rendered differently, or used by a search engine. The elements can be containers, with a combination of text and other elements.
You can learn more about XML elements in this chapter − XML Elements
XML — Declaration
This chapter covers XML declaration in detail. XML declaration contains details that prepare an XML processor to parse the XML document. It is optional, but when used, it must appear in the first line of the XML document.
Syntax
Following syntax shows XML declaration −
<?xml version = "version_number" encoding = "encoding_declaration" standalone = "standalone_status" ?>
Each parameter consists of a parameter name, an equals sign (=), and parameter value inside a quote. Following table shows the above syntax in detail −
| Parameter | Parameter_value | Parameter_description |
|---|---|---|
| Version | 1.0 | Specifies the version of the XML standard used. |
| Encoding | UTF-8, UTF-16, ISO-10646-UCS-2, ISO-10646-UCS-4, ISO-8859-1 to ISO-8859-9, ISO-2022-JP, Shift_JIS, EUC-JP | It defines the character encoding used in the document. UTF-8 is the default encoding used. |
| Standalone | yes or no | It informs the parser whether the document relies on the information from an external source, such as external document type definition (DTD), for its content. The default value is set to no. Setting it to yes tells the processor there are no external declarations required for parsing the document. |
Rules
An XML declaration should abide with the following rules −
-
If the XML declaration is present in the XML, it must be placed as the first line in the XML document.
-
If the XML declaration is included, it must contain version number attribute.
-
The Parameter names and values are case-sensitive.
-
The names are always in lower case.
-
The order of placing the parameters is important. The correct order is: version, encoding and standalone.
-
Either single or double quotes may be used.
-
The XML declaration has no closing tag i.e. </?xml>
XML Declaration Examples
Following are few examples of XML declarations −
XML declaration with no parameters −
<?xml >
XML declaration with version definition −
<?xml version = "1.0">
XML declaration with all parameters defined −
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
XML declaration with all parameters defined in single quotes −
<?xml version = '1.0' encoding = 'iso-8859-1' standalone = 'no' ?>
XML — Tags
Let us learn about one of the most important part of XML, the XML tags. XML tags form the foundation of XML. They define the scope of an element in XML. They can also be used to insert comments, declare settings required for parsing the environment, and to insert special instructions.
We can broadly categorize XML tags as follows −
Start Tag
The beginning of every non-empty XML element is marked by a start-tag. Following is an
example of start-tag −
<address>
End Tag
Every element that has a start tag should end with an end-tag. Following is an example of end-tag −
</address>
Note, that the end tags include a solidus («/») before the name of an element.
Empty Tag
The text that appears between start-tag and end-tag is called content. An element which has no content is termed as empty. An empty element can be represented in two ways as follows −
A start-tag immediately followed by an end-tag as shown below −
<hr></hr>
A complete empty-element tag is as shown below −
<hr />
Empty-element tags may be used for any element which has no content.
XML Tags Rules
Following are the rules that need to be followed to use XML tags −
Rule 1
XML tags are case-sensitive. Following line of code is an example of wrong syntax </Address>, because of the case difference in two tags, which is treated as erroneous syntax in XML.
<address>This is wrong syntax</Address>
Following code shows a correct way, where we use the same case to name the start and the end tag.
<address>This is correct syntax</address>
Rule 2
XML tags must be closed in an appropriate order, i.e., an XML tag opened inside another element must be closed before the outer element is closed. For example −
<outer_element>
<internal_element>
This tag is closed before the outer_element
</internal_element>
</outer_element>
XML — Elements
XML elements can be defined as building blocks of an XML. Elements can behave as containers to hold text, elements, attributes, media objects or all of these.
Each XML document contains one or more elements, the scope of which are either delimited by start and end tags, or for empty elements, by an empty-element tag.
Syntax
Following is the syntax to write an XML element −
<element-name attribute1 attribute2> ....content </element-name>
where,
-
element-name is the name of the element. The name its case in the start and end tags must match.
-
attribute1, attribute2 are attributes of the element separated by white spaces. An attribute defines a property of the element. It associates a name with a value, which is a string of characters. An attribute is written as −
name = "value"
name is followed by an = sign and a string value inside double(» «) or single(‘ ‘) quotes.
Empty Element
An empty element (element with no content) has following syntax −
<name attribute1 attribute2.../>
Following is an example of an XML document using various XML element −
<?xml version = "1.0"?>
<contact-info>
<address category = "residence">
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</address>
</contact-info>
XML Elements Rules
Following rules are required to be followed for XML elements −
-
An element name can contain any alphanumeric characters. The only punctuation mark allowed in names are the hyphen (-), under-score (_) and period (.).
-
Names are case sensitive. For example, Address, address, and ADDRESS are different names.
-
Start and end tags of an element must be identical.
-
An element, which is a container, can contain text or elements as seen in the above example.
XML — Attributes
This chapter describes the XML attributes. Attributes are part of XML elements. An element can have multiple unique attributes. Attribute gives more information about XML elements. To be more precise, they define properties of elements. An XML attribute is always a name-value pair.
Syntax
An XML attribute has the following syntax −
<element-name attribute1 attribute2 > ....content.. < /element-name>
where attribute1 and attribute2 has the following form −
name = "value"
value has to be in double (» «) or single (‘ ‘) quotes. Here, attribute1 and attribute2 are unique attribute labels.
Attributes are used to add a unique label to an element, place the label in a category, add a Boolean flag, or otherwise associate it with some string of data. Following example demonstrates the use of attributes −
<?xml version = "1.0" encoding = "UTF-8"?> <!DOCTYPE garden [ <!ELEMENT garden (plants)*> <!ELEMENT plants (#PCDATA)> <!ATTLIST plants category CDATA #REQUIRED> ]> <garden> <plants category = "flowers" /> <plants category = "shrubs"> </plants> </garden>
Attributes are used to distinguish among elements of the same name, when you do not want to create a new element for every situation. Hence, the use of an attribute can add a little more detail in differentiating two or more similar elements.
In the above example, we have categorized the plants by including attribute category and assigning different values to each of the elements. Hence, we have two categories of plants, one flowers and other shrubs. Thus, we have two plant elements with different attributes.
You can also observe that we have declared this attribute at the beginning of XML.
Attribute Types
Following table lists the type of attributes −
| Attribute Type | Description |
|---|---|
| StringType | It takes any literal string as a value. CDATA is a StringType. CDATA is character data. This means, any string of non-markup characters is a legal part of the attribute. |
| TokenizedType |
This is a more constrained type. The validity constraints noted in the grammar are applied after the attribute value is normalized. The TokenizedType attributes are given as −
|
| EnumeratedType |
This has a list of predefined values in its declaration. out of which, it must assign one value. There are two types of enumerated attribute −
|
Element Attribute Rules
Following are the rules that need to be followed for attributes −
-
An attribute name must not appear more than once in the same start-tag or empty-element tag.
-
An attribute must be declared in the Document Type Definition (DTD) using an Attribute-List Declaration.
-
Attribute values must not contain direct or indirect entity references to external entities.
-
The replacement text of any entity referred to directly or indirectly in an attribute value must not contain a less than sign (<)
XML — Comments
This chapter explains how comments work in XML documents. XML comments are similar to HTML comments. The comments are added as notes or lines for understanding the purpose of an XML code.
Comments can be used to include related links, information, and terms. They are visible only in the source code; not in the XML code. Comments may appear anywhere in XML code.
Syntax
XML comment has the following syntax −
<!--Your comment-->
A comment starts with <!— and ends with —>. You can add textual notes as comments between the characters. You must not nest one comment inside the other.
Example
Following example demonstrates the use of comments in XML document −
<?xml version = "1.0" encoding = "UTF-8" ?>
<!--Students grades are uploaded by months-->
<class_list>
<student>
<name>Tanmay</name>
<grade>A</grade>
</student>
</class_list>
Any text between <!— and —> characters is considered as a comment.
XML Comments Rules
Following rules should be followed for XML comments −
- Comments cannot appear before XML declaration.
- Comments may appear anywhere in a document.
- Comments must not appear within attribute values.
- Comments cannot be nested inside the other comments.
XML — Character Entities
This chapter describes the XML Character Entities. Before we understand the Character Entities, let us first understand what an XML entity is.
As put by W3 Consortium the definition of an entity is as follows −
«The document entity serves as the root of the entity tree and a starting-point for an XML processor».
This means, entities are the placeholders in XML. These can be declared in the document prolog or in a DTD. There are different types of entities and in this chapter we will discuss Character Entity.
Both, HTML and XML, have some symbols reserved for their use, which cannot be used as content in XML code. For example, < and > signs are used for opening and closing XML tags. To display these special characters, the character entities are used.
There are few special characters or symbols which are not available to be typed directly from the keyboard. Character Entities can also be used to display those symbols/special characters.
Types of Character Entities
There are three types of character entities −
- Predefined Character Entities
- Numbered Character Entities
- Named Character Entities
Predefined Character Entities
They are introduced to avoid the ambiguity while using some symbols. For example, an ambiguity is observed when less than ( < ) or greater than ( > ) symbol is used with the angle tag (<>). Character entities are basically used to delimit tags in XML. Following is a list of pre-defined character entities from XML specification. These can be used to express characters without ambiguity.
-
Ampersand − &
-
Single quote − '
-
Greater than − >
-
Less than − <
-
Double quote − "
Numeric Character Entities
The numeric reference is used to refer to a character entity. Numeric reference can either be in decimal or hexadecimal format. As there are thousands of numeric references available, these are a bit hard to remember. Numeric reference refers to the character by its number in the Unicode character set.
General syntax for decimal numeric reference is −
&# decimal number ;
General syntax for hexadecimal numeric reference is −
&#x Hexadecimal number ;
The following table lists some predefined character entities with their numeric values −
| Entity name | Character | Decimal reference | Hexadecimal reference |
|---|---|---|---|
| quot | « | " | " |
| amp | & | & | & |
| apos | ‘ | ' | ' |
| lt | < | < | < |
| gt | > | > | > |
Named Character Entity
As it is hard to remember the numeric characters, the most preferred type of character
entity is the named character entity. Here, each entity is identified with a name.
For example −
-
‘Aacute’ represents capital
 character with acute accent.
character with acute accent. -
‘ugrave’ represents the small
with grave accent.
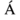 character with acute accent.
character with acute accent.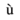 with grave accent.
with grave accent.XML — CDATA Sections
In this chapter, we will discuss XML CDATA section. The term CDATA means, Character Data. CDATA is defined as blocks of text that are not parsed by the parser, but are otherwise recognized as markup.
The predefined entities such as <, >, and & require typing and are generally difficult to read in the markup. In such cases, CDATA section can be used. By using CDATA section, you are commanding the parser that the particular section of the document contains no markup and should be treated as regular text.
Syntax
Following is the syntax for CDATA section −
<![CDATA[ characters with markup ]]>
The above syntax is composed of three sections −
-
CDATA Start section − CDATA begins with the nine-character delimiter <![CDATA[
-
CDATA End section − CDATA section ends with ]]> delimiter.
-
CData section − Characters between these two enclosures are interpreted as characters, and not as markup. This section may contain markup characters (<, >, and &), but they are ignored by the XML processor.
Example
The following markup code shows an example of CDATA. Here, each character written inside the CDATA section is ignored by the parser.
<script>
<![CDATA[
<message> Welcome to TutorialsPoint </message>
]] >
</script >
In the above syntax, everything between <message> and </message> is treated as character data and not as markup.
CDATA Rules
The given rules are required to be followed for XML CDATA −
- CDATA cannot contain the string «]]>» anywhere in the XML document.
- Nesting is not allowed in CDATA section.
XML — WhiteSpaces
In this chapter, we will discuss whitespace handling in XML documents. Whitespace is a collection of spaces, tabs, and newlines. They are generally used to make a document more readable.
XML document contains two types of whitespaces — Significant Whitespace and Insignificant Whitespace. Both are explained below with examples.
Significant Whitespace
A significant Whitespace occurs within the element which contains text and markup present together. For example −
<name>TanmayPatil</name>
and
<name>Tanmay Patil</name>
The above two elements are different because of the space between Tanmay and Patil. Any program reading this element in an XML file is obliged to maintain the distinction.
Insignificant Whitespace
Insignificant whitespace means the space where only element content is allowed. For example −
<address.category = "residence">
or
<address....category = "..residence">
The above examples are same. Here, the space is represented by dots (.). In the above
example, the space between address and category is insignificant.
A special attribute named xml:space may be attached to an element. This indicates that whitespace should not be removed for that element by the application. You can set this attribute to default or preserve as shown in the following example −
<!ATTLIST address xml:space (default|preserve) 'preserve'>
Where,
-
The value default signals that the default whitespace processing modes of an application are acceptable for this element.
-
The value preserve indicates the application to preserve all the whitespaces.
XML — Processing
This chapter describes the Processing Instructions (PIs). As defined by the XML 1.0 Recommendation,
«Processing instructions (PIs) allow documents to contain instructions for applications. PIs are not part of the character data of the document, but MUST be passed through to the application.
Processing instructions (PIs) can be used to pass information to applications. PIs can appear anywhere in the document outside the markup. They can appear in the prolog, including the document type definition (DTD), in textual content, or after the document.
Syntax
Following is the syntax of PI −
<?target instructions?>
Where
-
target − Identifies the application to which the instruction is directed.
-
instruction − A character that describes the information for the application to process.
A PI starts with a special tag <? and ends with ?>. Processing of the contents ends immediately after the string ?> is encountered.
Example
PIs are rarely used. They are mostly used to link XML document to a style sheet. Following is an example −
<?xml-stylesheet href = "tutorialspointstyle.css" type = "text/css"?>
Here, the target is xml-stylesheet. href=»tutorialspointstyle.css» and type=»text/css» are data or instructions the target application will use at the time of processing the given XML document.
In this case, a browser recognizes the target by indicating that the XML should be transformed before being shown; the first attribute states that the type of the transform is XSL and the second attribute points to its location.
Processing Instructions Rules
A PI can contain any data except the combination ?>, which is interpreted as the closing delimiter. Here are two examples of valid PIs −
<?welcome to pg = 10 of tutorials point?> <?welcome?>
XML — Encoding
Encoding is the process of converting unicode characters into their equivalent binary representation. When the XML processor reads an XML document, it encodes the document depending on the type of encoding. Hence, we need to specify the type of encoding in the XML declaration.
Encoding Types
There are mainly two types of encoding −
- UTF-8
- UTF-16
UTF stands for UCS Transformation Format, and UCS itself means Universal Character Set. The number 8 or 16 refers to the number of bits used to represent a character. They are either 8(1 to 4 bytes) or 16(2 or 4 bytes). For the documents without encoding information, UTF-8 is set by default.
Syntax
Encoding type is included in the prolog section of the XML document. The syntax for UTF-8 encoding is as follows −
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
The syntax for UTF-16 encoding is as follows −
<?xml version = "1.0" encoding = "UTF-16" standalone = "no" ?>
Example
Following example shows the declaration of encoding −
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
In the above example encoding=»UTF-8″, specifies that 8-bits are used to represent the characters. To represent 16-bit characters, UTF-16 encoding can be used.
The XML files encoded with UTF-8 tend to be smaller in size than those encoded with UTF-16 format.
XML — Validation
Validation is a process by which an XML document is validated. An XML document is said to be valid if its contents match with the elements, attributes and associated document type declaration(DTD), and if the document complies with the constraints expressed in it. Validation is dealt in two ways by the XML parser. They are −
- Well-formed XML document
- Valid XML document
Well-formed XML Document
An XML document is said to be well-formed if it adheres to the following rules −
-
Non DTD XML files must use the predefined character entities for amp(&), apos(single quote), gt(>), lt(<), quot(double quote).
-
It must follow the ordering of the tag. i.e., the inner tag must be closed before closing the outer tag.
-
Each of its opening tags must have a closing tag or it must be a self ending tag.(<title>….</title> or <title/>).
-
It must have only one attribute in a start tag, which needs to be quoted.
-
amp(&), apos(single quote), gt(>), lt(<), quot(double quote) entities other than these must be declared.
Example
Following is an example of a well-formed XML document −
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?> <!DOCTYPE address [ <!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)> ]> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
The above example is said to be well-formed as −
-
It defines the type of document. Here, the document type is element type.
-
It includes a root element named as address.
-
Each of the child elements among name, company and phone is enclosed in its self explanatory tag.
-
Order of the tags is maintained.
Valid XML Document
If an XML document is well-formed and has an associated Document Type Declaration (DTD), then it is said to be a valid XML document. We will study more about DTD in the chapter XML — DTDs.
XML — DTDs
The XML Document Type Declaration, commonly known as DTD, is a way to describe XML language precisely. DTDs check vocabulary and validity of the structure of XML documents against grammatical rules of appropriate XML language.
An XML DTD can be either specified inside the document, or it can be kept in a separate document and then liked separately.
Syntax
Basic syntax of a DTD is as follows −
<!DOCTYPE element DTD identifier [ declaration1 declaration2 ........ ]>
In the above syntax,
-
The DTD starts with <!DOCTYPE delimiter.
-
An element tells the parser to parse the document from the specified root element.
-
DTD identifier is an identifier for the document type definition, which may be the path to a file on the system or URL to a file on the internet. If the DTD is pointing to external path, it is called External Subset.
-
The square brackets [ ] enclose an optional list of entity declarations called Internal Subset.
Internal DTD
A DTD is referred to as an internal DTD if elements are declared within the XML files. To refer it as internal DTD, standalone attribute in XML declaration must be set to yes. This means, the declaration works independent of an external source.
Syntax
Following is the syntax of internal DTD −
<!DOCTYPE root-element [element-declarations]>
where root-element is the name of root element and element-declarations is where you declare the elements.
Example
Following is a simple example of internal DTD −
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?> <!DOCTYPE address [ <!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)> ]> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
Let us go through the above code −
Start Declaration − Begin the XML declaration with the following statement.
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?>
DTD − Immediately after the XML header, the document type declaration follows, commonly referred to as the DOCTYPE −
<!DOCTYPE address [
The DOCTYPE declaration has an exclamation mark (!) at the start of the element name. The DOCTYPE informs the parser that a DTD is associated with this XML document.
DTD Body − The DOCTYPE declaration is followed by body of the DTD, where you declare elements, attributes, entities, and notations.
<!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone_no (#PCDATA)>
Several elements are declared here that make up the vocabulary of the <name> document. <!ELEMENT name (#PCDATA)> defines the element name to be of type «#PCDATA». Here #PCDATA means parse-able text data.
End Declaration − Finally, the declaration section of the DTD is closed using a closing bracket and a closing angle bracket (]>). This effectively ends the definition, and thereafter, the XML document follows immediately.
Rules
-
The document type declaration must appear at the start of the document (preceded only by the XML header) − it is not permitted anywhere else within the document.
-
Similar to the DOCTYPE declaration, the element declarations must start with an exclamation mark.
-
The Name in the document type declaration must match the element type of the root element.
External DTD
In external DTD elements are declared outside the XML file. They are accessed by specifying the system attributes which may be either the legal .dtd file or a valid URL. To refer it as external DTD, standalone attribute in the XML declaration must be set as no. This means, declaration includes information from the external source.
Syntax
Following is the syntax for external DTD −
<!DOCTYPE root-element SYSTEM "file-name">
where file-name is the file with .dtd extension.
Example
The following example shows external DTD usage −
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?> <!DOCTYPE address SYSTEM "address.dtd"> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
The content of the DTD file address.dtd is as shown −
<!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)>
Types
You can refer to an external DTD by using either system identifiers or public identifiers.
System Identifiers
A system identifier enables you to specify the location of an external file containing DTD declarations. Syntax is as follows −
<!DOCTYPE name SYSTEM "address.dtd" [...]>
As you can see, it contains keyword SYSTEM and a URI reference pointing to the location of the document.
Public Identifiers
Public identifiers provide a mechanism to locate DTD resources and is written as follows −
<!DOCTYPE name PUBLIC "-//Beginning XML//DTD Address Example//EN">
As you can see, it begins with keyword PUBLIC, followed by a specialized identifier. Public identifiers are used to identify an entry in a catalog. Public identifiers can follow any format, however, a commonly used format is called Formal Public Identifiers, or FPIs.
XML — Schemas
XML Schema is commonly known as XML Schema Definition (XSD). It is used to describe and validate the structure and the content of XML data. XML schema defines the elements, attributes and data types. Schema element supports Namespaces. It is similar to a database schema that describes the data in a database.
Syntax
You need to declare a schema in your XML document as follows −
Example
The following example shows how to use schema −
<?xml version = "1.0" encoding = "UTF-8"?>
<xs:schema xmlns:xs = "http://www.w3.org/2001/XMLSchema">
<xs:element name = "contact">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
<xs:element name = "phone" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
The basic idea behind XML Schemas is that they describe the legitimate format that an XML document can take.
Elements
As we saw in the XML — Elements chapter, elements are the building blocks of XML document. An element can be defined within an XSD as follows −
<xs:element name = "x" type = "y"/>
Definition Types
You can define XML schema elements in the following ways −
Simple Type
Simple type element is used only in the context of the text. Some of the predefined simple types are: xs:integer, xs:boolean, xs:string, xs:date. For example −
<xs:element name = "phone_number" type = "xs:int" />
Complex Type
A complex type is a container for other element definitions. This allows you to specify which child elements an element can contain and to provide some structure within your XML documents. For example −
<xs:element name = "Address">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
<xs:element name = "phone" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
In the above example, Address element consists of child elements. This is a container for other <xs:element> definitions, that allows to build a simple hierarchy of elements in the XML document.
Global Types
With the global type, you can define a single type in your document, which can be used by all other references. For example, suppose you want to generalize the person and company for different addresses of the company. In such case, you can define a general type as follows −
<xs:element name = "AddressType">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>
Now let us use this type in our example as follows −
<xs:element name = "Address1">
<xs:complexType>
<xs:sequence>
<xs:element name = "address" type = "AddressType" />
<xs:element name = "phone1" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name = "Address2">
<xs:complexType>
<xs:sequence>
<xs:element name = "address" type = "AddressType" />
<xs:element name = "phone2" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
Instead of having to define the name and the company twice (once for Address1 and once for Address2), we now have a single definition. This makes maintenance simpler, i.e., if you decide to add «Postcode» elements to the address, you need to add them at just one place.
Attributes
Attributes in XSD provide extra information within an element. Attributes have name and type property as shown below −
<xs:attribute name = "x" type = "y"/>
XML — Tree Structure
An XML document is always descriptive. The tree structure is often referred to as XML Tree and plays an important role to describe any XML document easily.
The tree structure contains root (parent) elements, child elements and so on. By using tree structure, you can get to know all succeeding branches and sub-branches starting from the root. The parsing starts at the root, then moves down the first branch to an element, take the first branch from there, and so on to the leaf nodes.
Example
Following example demonstrates simple XML tree structure −
<?xml version = "1.0"?>
<Company>
<Employee>
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
<Address>
<City>Bangalore</City>
<State>Karnataka</State>
<Zip>560212</Zip>
</Address>
</Employee>
</Company>
Following tree structure represents the above XML document −
In the above diagram, there is a root element named as <company>. Inside that, there is one more element <Employee>. Inside the employee element, there are five branches named <FirstName>, <LastName>, <ContactNo>, <Email>, and <Address>. Inside the <Address> element, there are three sub-branches, named <City> <State> and <Zip>.
XML — DOM
The Document Object Model (DOM) is the foundation of XML. XML documents have a hierarchy of informational units called nodes; DOM is a way of describing those nodes and the relationships between them.
A DOM document is a collection of nodes or pieces of information organized in a hierarchy. This hierarchy allows a developer to navigate through the tree looking for specific information. Because it is based on a hierarchy of information, the DOM is said to be tree based.
The XML DOM, on the other hand, also provides an API that allows a developer to add, edit, move, or remove nodes in the tree at any point in order to create an application.
Example
The following example (sample.htm) parses an XML document («address.xml») into an XML DOM object and then extracts some information from it with JavaScript −
<!DOCTYPE html>
<html>
<body>
<h1>TutorialsPoint DOM example </h1>
<div>
<b>Name:</b> <span id = "name"></span><br>
<b>Company:</b> <span id = "company"></span><br>
<b>Phone:</b> <span id = "phone"></span>
</div>
<script>
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/xml/address.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
document.getElementById("name").innerHTML=
xmlDoc.getElementsByTagName("name")[0].childNodes[0].nodeValue;
document.getElementById("company").innerHTML=
xmlDoc.getElementsByTagName("company")[0].childNodes[0].nodeValue;
document.getElementById("phone").innerHTML=
xmlDoc.getElementsByTagName("phone")[0].childNodes[0].nodeValue;
</script>
</body>
</html>
Contents of address.xml are as follows −
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
Now let us keep these two files sample.htm and address.xml in the same directory /xml and execute the sample.htm file by opening it in any browser. This should produce the following output.

Here, you can see how each of the child nodes is extracted to display their values.
XML — Namespaces
A Namespace is a set of unique names. Namespace is a mechanisms by which element and attribute name can be assigned to a group. The Namespace is identified by URI(Uniform Resource Identifiers).
Namespace Declaration
A Namespace is declared using reserved attributes. Such an attribute name must either be xmlns or begin with xmlns: shown as below −
<element xmlns:name = "URL">
Syntax
-
The Namespace starts with the keyword xmlns.
-
The word name is the Namespace prefix.
-
The URL is the Namespace identifier.
Example
Namespace affects only a limited area in the document. An element containing the declaration and all of its descendants are in the scope of the Namespace. Following is a simple example of XML Namespace −
<?xml version = "1.0" encoding = "UTF-8"?> <cont:contact xmlns:cont = "www.tutorialspoint.com/profile"> <cont:name>Tanmay Patil</cont:name> <cont:company>TutorialsPoint</cont:company> <cont:phone>(011) 123-4567</cont:phone> </cont:contact>
Here, the Namespace prefix is cont, and the Namespace identifier (URI) as www.tutorialspoint.com/profile. This means, the element names and attribute names with the cont prefix (including the contact element), all belong to the www.tutorialspoint.com/profile namespace.
XML — Databases
XML Database is used to store huge amount of information in the XML format. As the use of XML is increasing in every field, it is required to have a secured place to store the XML documents. The data stored in the database can be queried using XQuery, serialized, and exported into a desired format.
XML Database Types
There are two major types of XML databases −
- XML- enabled
- Native XML (NXD)
XML — Enabled Database
XML enabled database is nothing but the extension provided for the conversion of XML document. This is a relational database, where data is stored in tables consisting of rows and columns. The tables contain set of records, which in turn consist of fields.
Native XML Database
Native XML database is based on the container rather than table format. It can store large amount of XML document and data. Native XML database is queried by the XPath-expressions.
Native XML database has an advantage over the XML-enabled database. It is highly capable to store, query and maintain the XML document than XML-enabled database.
Example
Following example demonstrates XML database −
<?xml version = "1.0"?>
<contact-info>
<contact1>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact1>
<contact2>
<name>Manisha Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 789-4567</phone>
</contact2>
</contact-info>
Here, a table of contacts is created that holds the records of contacts (contact1 and contact2), which in turn consists of three entities − name, company and phone.
XML — Viewers
This chapter describes THE various methods to view an XML document. An XML document can be viewed using a simple text editor or any browser. Most of the major browsers supports XML. XML files can be opened in the browser by just double-clicking the XML document (if it is a local file) or by typing the URL path in the address bar (if the file is located on the server), in the same way as we open other files in the browser. XML files are saved with a «.xml» extension.
Let us explore various methods by which we can view an XML file. Following example (sample.xml) is used to view all the sections of this chapter.
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
Text Editors
Any simple text editor such as Notepad, TextPad, or TextEdit can be used to create or view an XML document as shown below −
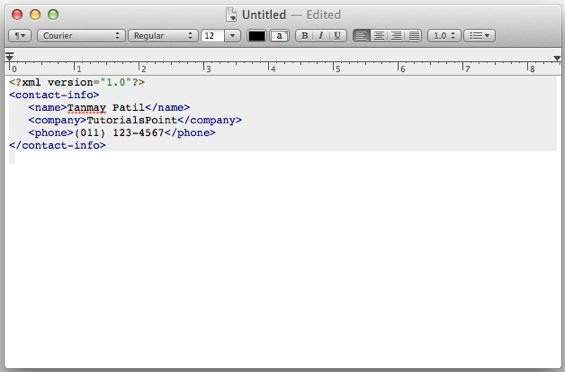
Firefox Browser
Open the above XML code in Chrome by double-clicking the file. The XML code displays
coding with color, which makes the code readable. It shows plus(+) or minus (-) sign at
the left side in the XML element. When we click the minus sign (-), the code hides. When
we click the plus (+) sign, the code lines get expanded. The output in Firefox is as shown below −

Chrome Browser
Open the above XML code in Chrome browser. The code gets displayed as shown below −

Errors in XML Document
If your XML code has some tags missing, then a message is displayed in the browser. Let us try to open the following XML file in Chrome −
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
In the above code, the start and end tags are not matching (refer the contact_info tag), hence an error message is displayed by the browser as shown below −
XML — Editors
XML Editor is a markup language editor. The XML documents can be edited or created using existing editors such as Notepad, WordPad, or any similar text editor. You can also find a professional XML editor online or for downloading, which has more powerful editing features such as −
- It automatically closes the tags that are left open.
- It strictly checks syntax.
- It highlights XML syntax with colour for increased readability.
- It helps you write a valid XML code.
- It provides automatic verification of XML documents against DTDs and Schemas.
Open Source XML Editors
Following are some open source XML editors −
-
Online XML Editor − This is a light weight XML editor which you can use online.
-
Xerlin − Xerlin is an open source XML editor for Java 2 platform released under an Apache license. It is a Java based XML modelling application, for creating and editing XML files easily.
-
CAM — Content Assembly Mechanism − CAM XML Editor tool comes with XML+JSON+SQL Open-XDX sponsored by Oracle.
XML — Parsers
XML parser is a software library or a package that provides interface for client applications to work with XML documents. It checks for proper format of the XML document and may also validate the XML documents. Modern day browsers have built-in XML parsers.
Following diagram shows how XML parser interacts with XML document −
The goal of a parser is to transform XML into a readable code.
To ease the process of parsing, some commercial products are available that facilitate the breakdown of XML document and yield more reliable results.
Some commonly used parsers are listed below −
-
MSXML (Microsoft Core XML Services) − This is a standard set of XML tools from Microsoft that includes a parser.
-
System.Xml.XmlDocument − This class is part of .NET library, which contains a number of different classes related to working with XML.
-
Java built-in parser − The Java library has its own parser. The library is designed such that you can replace the built-in parser with an external implementation such as Xerces from Apache or Saxon.
-
Saxon − Saxon offers tools for parsing, transforming, and querying XML.
-
Xerces − Xerces is implemented in Java and is developed by the famous open source Apache Software Foundation.
XML — Processors
When a software program reads an XML document and takes actions accordingly, this is called processing the XML. Any program that can read and process XML documents is known as an XML processor. An XML processor reads the XML file and turns it into in-memory structures that the rest of the program can access.
The most fundamental XML processor reads an XML document and converts it into an internal representation for other programs or subroutines to use. This is called a parser, and it is an important component of every XML processing program.
Processor involves processing the instructions, that can be studied in the chapter Processing Instruction.
Types
XML processors are classified as validating or non-validating types, depending on whether or not they check XML documents for validity. A processor that discovers a validity error must be able to report it, but may continue with normal processing.
A few validating parsers are − xml4c (IBM, in C++), xml4j (IBM, in Java), MSXML (Microsoft, in Java), TclXML (TCL), xmlproc (Python), XML::Parser (Perl), Java Project X (Sun, in Java).
A few non-validating parsers are − OpenXML (Java), Lark (Java), xp (Java), AElfred (Java), expat (C), XParse (JavaScript), xmllib (Python).
XML – это расширяемый язык разметки. Он создан для формирования логической структуры данных, их хранения и передачи в максимально удобном виде не только для компьютера, но и для человека. Выделяется простотой и ясностью синтаксиса. При помощи XML можно описывать документы через тэги.
Данная статья расскажет об особенностях XML-языка, а также о его ключевых элементах. Предстоит разобраться в тэгах и атрибутах, без которых формирование итогового кода документа не представляется возможным. Информация будет полезна как разработчикам, так и тестировщикам программного обеспечения.
Области применения и возможности
XML – простой и понятный язык разметки. Он используется везде, где необходимо выделение логического содержимого документа для дальнейшей обработки. Соответствующий формат является рекомендованным Консорциумом Всемирной паутины (W3C). За счет данной особенности XML используется в API при формировании серверных ответов.
XML предусматривает следующие возможности:
- формирование разметки текста по смыслу – от важных к второстепенным блокам;
- запись иерархии;
- хранение типовых данных – настройки программ, названия (заголовки), скрипты и иные элементы;
- создание текстов для машинного обучения;
- хранение результатов использования текстовых редакторов.
Иерархии XML применяются в самых разных языках разработки:
- OWL и RDF – для описания структур и ресурсов имеющихся каталогов;
- HTML – отображение страниц в интернете;
- WSDL – обращение к удаленным веб-серверам и приложениям;
- SVG – формирование векторных изображений (картинок).
Рассматриваемый язык – это средство обмена данными, обработки и упорядочения информации.
Особенности
XML чем-то напоминает HTML. Данные языки нужно использовать совместно – они дополняют друг друга. Рассматриваемый расширяемый ЯП имеет следующие особенности:
- Приложения, написанные на нем, будут работать, даже если часть данных будет стерта или добавлена. Он хорошо подходит для создания новых версий файлов, а также иных электронных элементов.
- Все собранные сведения будут храниться в виде текста. Это делает их программно- и машинно-независимыми.
- Код синтаксически прост и понятен. Он легко читается не только компьютерами, но и человеком. Высокий уровень читаемости является одним из главных преимуществ.
- Размеры XML-документов больше бинарного представления аналогичных данных.
- Гибкость и отсутствие жестких ограничений при формировании документов. Это означает, что для одних и тех же структур поддерживается множество способов интерпретации.
XML документ должен быть открыт одним из текстовых редакторов. Считать информацию удастся как при помощи специальных приложением, так и «Блокнотом» в Windows.
Стандарты
Перед тем как изучать теги XML, а также остальные его элементы, нужно учесть существование так называемых стандартов. Так называются расширения, при помощи которых удается получить дополнительные возможности для работы с XML-документами.
Наиболее популярными из них являются такие элементы как:
- XPath – расширение, упрощающее навигацию по XML-документам;
- AJAX – помогает изменять веб-страницу без ее перезапуска;
- XSLT – конвертирование .xml в другие форматы;
- XML DOM – используется для получения, изменения, добавления, а также удаления отдельных элементов из исходного документа;
- XQuery – инструмент обработки данных;
- DTD – расширение, при помощи которого можно определить список разрешенных элементов для сущности в исходном файле.
XML-документ – это информация, заключенная в теги. Он может быть создан в обычном текстовом редакторе.
Введение в синтаксис
Структура файла XML является древовидной. Это значит, что в них используются наборы тегов, внутри которых тоже могут располагаться теги с теми или иными параметрами. Самый верхнеуровневый узел – это корень. Все, что располагается под ним – листья.
При написании кода XML tags заключаются в скобки «<» и «>». Ниже – наглядный пример структуры типичного XML-документа.

При формировании исходного кода необходимо помнить следующие правила и принципы:
- Файл может включать в себя элемент под названием «пролог». Он будет располагаться в верхней части исходного кода. Заданный пример в первой строке указывает, что используется xml version 1.0, а также кодировка (encoding) UTF-8. Этот элемент полезен, если в исходном файле задействован текст на нескольких языках.
- Корневой элемент в XML является обязательным. Он называется «root». В заданном примере им выступает <claim>.
- Все компоненты, включая корневой элемент в XML, должны заключаться в кавычки, но и иметь закрывающие теги. Они помечаются дополнительным символом – слешем.
- Регистр для тегов XML имеет значение.
- Правила синтаксиса языка указывают, что значения атрибутов должны быть заключены в кавычки. Атрибут – это характеристика тегов XML. Любые tags могут иметь атрибуты. В предложенном примере это version и encoding.
- Реестр – не единственная «проблема» при написании кода. Вложенность тегов контролируется. Это значит, что исходный код всегда должен содержат открывающий тег и закрывающий. В противном случае код будет обработан некорректно.
Правила синтаксиса XML учитывают все символы форматирования, включая пробелы, запятые и иные элементы.
Пространство имен
В XML-коде иногда могут встречаться одинаковые по написанию объекты. Пример – Claim. Этот элемент – и жалоба, и обращение. Системе необходимо сообщить, какие принципы обработки данных применить в первом случае, а какие – во втором объекте.

Для этого используется так называемое пространство имен. Оно позволяет избежать конфликтов наименования элементов. Задается в качестве значений атрибутов XML. Пример – есть корневой элемент root. Он имеет несколько атрибутов. Для примера – два.
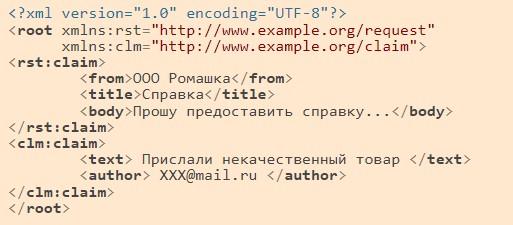
Теперь нужно указать, что «xmlns:…/request» – это обращение, а «xmlns:…/claim» — жалобы. Остается добавить префиксы в соответствующий блоки исходного кода. Обработчик выдаст корректный результат обработки.
Правила декларации
XML-документы могут содержать дополнительно такой элемент как декларация. Это и есть «пролог». Для его формирования у tag существуют следующие правила:
- Регистр имеет значение. Начинается декларация с <? xml>. Все элементы в записи должны быть строчными.
- При формировании пролога важно соблюдение порядка параметров. Сначала пишется версия, затем – кодировка и тип.
- Допускается использование в синтаксисе не только двойных, но и одинарных кавычек.
- Если в документе есть пролог, он должен выступать первым утверждением всего файла.
- Протоколы HTTP способны переопределять значения кодировки, указанной при формировании XML-файла.
Эти простые правила помогут быстрее и эффективнее создавать коды без лишних ошибок компиляции.
Теги
Теги в XML – это основные элементы (узлы) исходного кода. Их имена заключаются в треугольные скобки. Правила синтаксиса указывают на то, что каждый XML-элемент должен быть закрыт начальным или конечным элементом.


Выше – два примера реализации грамотного синтаксиса рассматриваемого языка. Он поддерживает вложенность. Так называется ситуация, когда внутри элемента tag размещаются другие теги. Дочерние элементы не должны перекрываться – конечный тэг должен быть с точно таким же именем, как и у самого последнего непревзойденного начального tag.
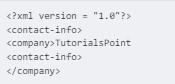
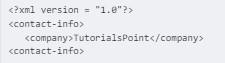
Выше – примеры неправильного и правильного формирования вложенности.
Существуют так называемые пустые теги. Текст, который возникает между начальным и конечным тегами – это контент. Элемент без содержимого называется пустым. Он может быть представлен несколькими способами:
- Начальной меткой, за которой сразу следует конечная. Форма представления – <hr></hr>.
- Полным тегом пустого элемента. Запись имеет следующую форму представления – <hr />.
Такие элементы используются для компонентов исходного кода, которые не имеют в своем составе никакого содержимого.
Элементы
Элемент – это своеобразный «строительный блок» XML-документа. Обладают различным поведением. Могут вести себя как контейнеры для хранения элементов, атрибутов, медиа-объектов, а также текста. Элементы включены в состав каждого XML-файла. Область их действия обозначается начальным и конечным тэгами.
Задаются по форме:
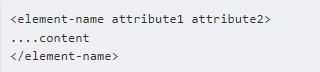
Здесь element name – это имя элемента. Оно должно быть одинаковым в начальных и конечных тегах. Чувствительно к регистру. Attribute1 и attribute2 – это атрибуты (attributes) элемента. Они в программном коде разделены пробелами. Служат для определения свойств того или иного компонента. Связывает имя со значением, представленной строкой символов.
Здесь рекомендуется запомнить следующие правила:
- Имя элемента может включать в себя буквы и цифры. Знаки препинания не поддерживаются. Исключение составляет дефис, а также нижнее подчеркивание и точка.
- Имена чувствительны к регистру. Не только в XML элементах, но и во всем документе.
- Начальный и конечный теги компонента должны совпадать друг с другом.
Один элемент может включать в себя разные типы данных. Он иногда содержит не только обычный текст, но и другие компоненты.
Атрибуты
Атрибут (attribute) – компонент, который задает одно свойство для элемента при помощи пары имя-значение. Таких составляющих у XML tag может быть несколько:

В предложенном выше примере href выступает именем атрибута, а адрес веб-страницы – его значением.
При формировании атрибутов и элементов в XML необходимо помнить, что:
- Регистр важен для обоих компонентов.
- Один и тот же атрибут не может обладать несколькими значениями.
- Имя (заголовок) атрибута прописывается без кавычек. Значения – только в них.
- Атрибуты и элементы XML тесно связаны между собой. Первые используются для различения вторых, если компоненты кода обладают одними и теми же именами.
- Имя атрибута не должно появляться в начальном теге или теге пустого элемента больше одного раза.
- Атрибуты объявляются в определении типа документа. Для этого используется список.
- Значения могут включать в себя не только прямые значения, но и ссылки (прямые/косвенные) на сущности внешних объектов.

Атрибуты необходимы для добавления уникальных меток к элементам, а также их дальнейшего размещения в категории. Эти компоненты помогают добавлять логически флаги и иные связывания elements со строками данных.

Выше – пример использования атрибутов. Также стоит запомнить, что атрибуты:
- не могут включать в себя множественные значения в отличие от элементов;
- не поддерживают древовидные структуры;
- сложно расширяемые;
- достаточно трудно читать и обслуживать.
Элементы рекомендуется использовать непосредственно для данных, а XML атрибуты – для иной информации.
Типы
Атрибуты могут быть нескольких типов:
| Тип атрибута | Характеристика |
| String | Строка. В качестве значения атрибута XML может выступать любая буквенная строка. CDATA – символьные данные. Это указывает на то, что любая строка символов без разметки становится частью атрибута. |
| TokenizedType | Могут быть представлены несколькими способами:ID – указание элемента кода в качестве уникального;IDREF – применяется для ссылки на идентификатор, который был предопределен для другого элемента;ENTITY – атрибут представляет сущность извне внутри файла;IDREFS – ссылка на все идентификаторы элемента;ENTITIES – атрибут представляет внешние объекты;NMTOKEN – то же самое, что и CDATA, но с ограничениями данных, используемых в качестве части атрибута. |
| EnumeratedType | Значения могут быть NotationType или перечисление. Первый вариант ссылается на Notation, объявленный в XML. Второй определяет список значений, которым должно удовлетворять значение атрибута. |
Выше – таблица, которая поможет лучше узнать типы атрибутов.
Сущности
Рассматривая инструкции по обработке XML файлов, необходимо обратить внимание на сущности. Они тоже тесно связаны с элементами и атрибутами.
Сущность – это символы, которые имеют особое значение. При вписывании в тэг XML будут обрабатываться и выдавать тот или иной результат.

Код, написанный выше, приведет к ошибке. Чтобы она не возникала, необходимо заменить символ «<» на его сущность. В данном случае исправленный и корректный код будет иметь такую запись:

Всего в XML предусматриваются 5 сущностей:
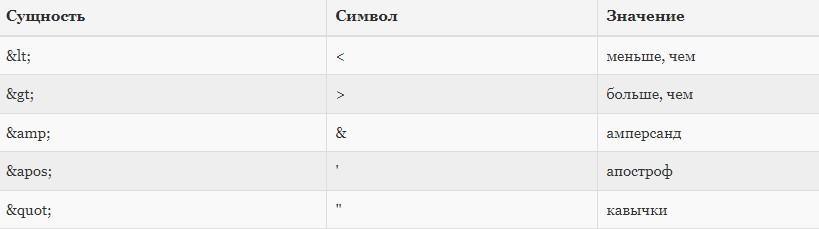
Строго запрещены только символы «амперсанд» и «меньше». Остальные символьные записи можно использовать без сущностей, но это может привести к ошибкам обработки исходного кода.
Комментарии
Комментарии XML похожи на аналогичные элементы в HTML. Они могут быть добавлены в исходный код в качестве примечаний. Необходимы для того, чтобы теги в XML файле стали более понятными. Нацелены на разъяснение исходного кода.
Комментарии используются для включения связанных ссылок, информации и подсказок. Они видны только в исходном коде. Появляются в любом месте XML-кода.
Синтаксис: <! — комментарий — >.
Вкладывать комментарии друг в друга нельзя. Также необходимо запомнить, что:
- комментарии не могут быть определены до объявления XML;
- в исходном документе комментарии можно использовать в любом месте;
- не допускается использование соответствующего элемента в значениях атрибутов.
XML похож на HTML. Далее предстоит выяснить, что лучше использовать при программировании.
HTML или XML
HTML и XML – два схожих между собой языка. Они дополняют друг друга, хоть и отличаются по назначению. XML используется для хранения и передачи данных, HTML – для их корректного отображения на экране.
Теги в HTML являются предопределенными. Браузеры знают о них максимум информации, за счет чего при считывании происходит отображение данных. В XML эти элементы описываются разработчиком. Браузеры об этих элементах ничего не знает.
XML-файлы легко преобразуются в HTML. При передаче информации с сервера в браузеры, соответствующий процесс реализовывается автоматически. Разработчикам рекомендуется использовать эти языки в связке друг с другом.
Как освоить языки разметки
Независимо от того, какой именно язык программирования заинтересовал пользователя, он смогут пройти обучающие онлайн курсы, чтобы быстро освоить выбранное направление. Пример – от образовательного центра OTUS.
Преимуществами дистанционных курсов служат:
- сжатые сроки обучения и материал, поданный в понятной даже новичкам форме;
- кураторство;
- домашние задания и богатая практика;
- возможность совмещения с работой и семьей;
- возможность получить помощь при трудоустройстве по выбранному IT-направлению.
Пользователь сможет выбрать один или несколько курсов для одновременного изучения. В конце будет выдан электронный сертификат, подтверждающий навыки. Вместе с компьютерными дистанционными курсами будет легко понять, как составлять заголовок в коде, что значит «note date» и int, а также как компилировать приложения на устройствах.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus! Также обратите внимание на курсы по тестированию в Otus. Присутствуют варианты как для продвинутых, так и для начинающих пользователей.